Android ashmem 原理分析
源码基于:Andoird U + Kernel-5.10
0. 简介
ashmem 称为匿名共享内存(Anonymous Shared Memory),它以驱动程序的形式实现在内核空间中。它有两个特点:
-
能否辅助内存管理系统来有效地管理不再使用的内存块(pin / unpin);
-
通过Binder进程间通信机制来实现内存共享;
虽然 Binder机制已经可以实现了跨进程的高效通信,但是Binder 通信所允许的数据是有限制的(如下代码),如果需要大量数据交互就有限制了。
frameworks/native/libs/binder/ProcessState.cpp//限制了大小为
#define BINDER_VM_SIZE ((1 * 1024 * 1024) - sysconf(_SC_PAGE_SIZE) * 2)ashmem 系统大概分三层:
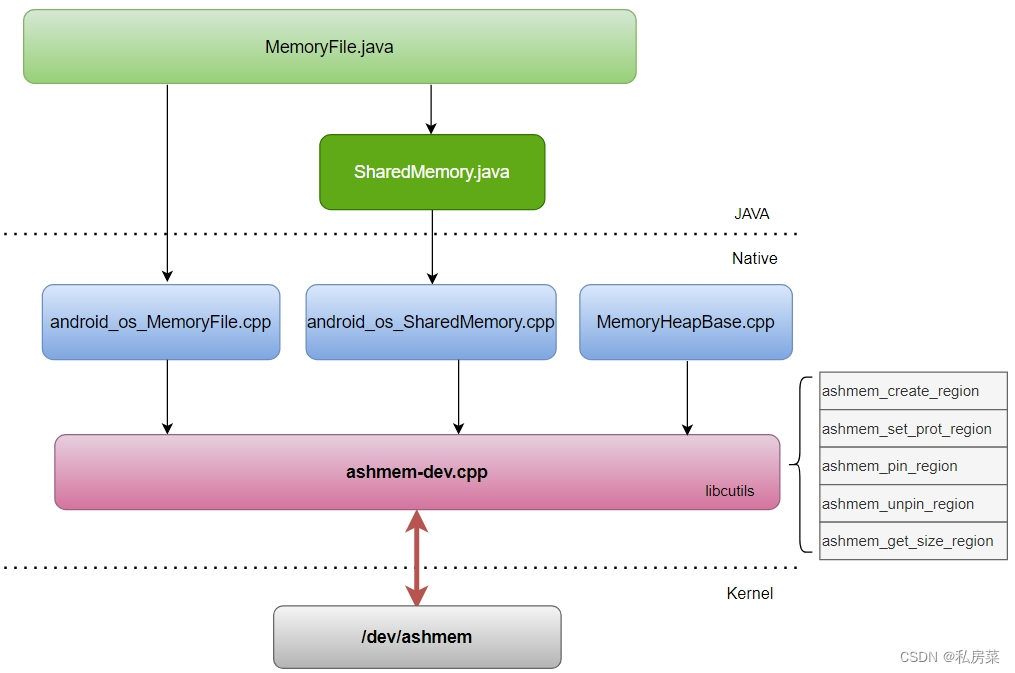
-
Java 层使用 MemoryFile.java 或 SharedMemory.java 来创建ashmem 共享内存;
-
Native 层分两部分:
-
一部分是从Java 层调下来的 JNI 接口,另外是给Native 层使用的MemoryHeapBase.cpp 文件;
-
另一部分是ashmem 的lib,实现的函数定义在 ashmem-dev.cpp 文件中;
-
-
Kernel 层就是 ashmem 的驱动,ashmem 的核心就是通过驱动来管理共享内存;
1. ashmem 驱动原理分析
源码:drivers/staging/android/ashmem.c
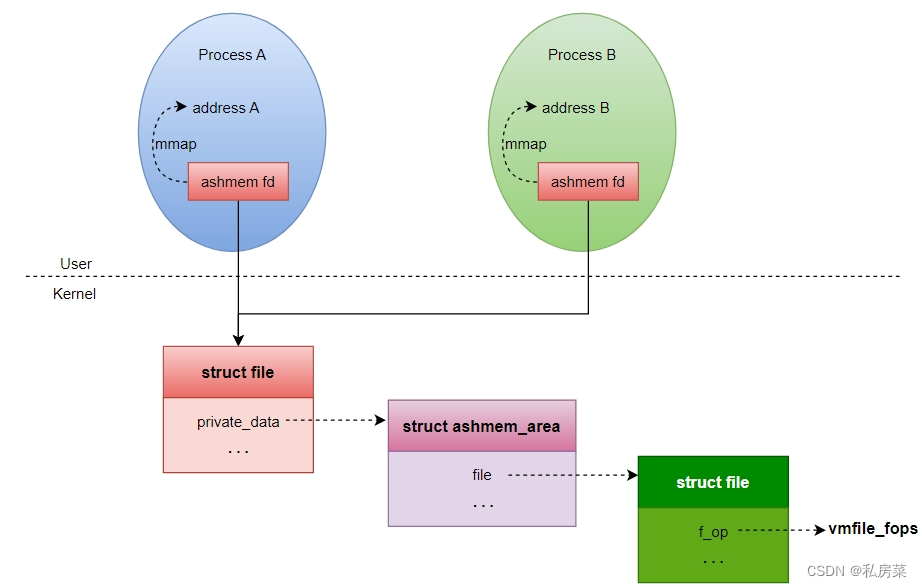
-
用户层都是通过fd 进行mmap 进行映射;
-
虽然 fd 在不同的进程可能不相同,但其对应的 file 结构是相同的;
-
file 结构中的成员 private_data 指向 ashmem_area,这就是匿名共享内存的核心数据结构;
-
ashmem_area 中的file 是映射的实际文件,通过shmem_file_setup() 函数创建,并指定其fops 为shmem_file_operations,该 fops 也被存在 ashmem 中的静态局部变量 vmfile_fops 中;
-
vmfile_fops 只初始化一次,后面再次调用 ashmem_mmap() 函数时将直接使用;
1.1 ashmem 的重要数据结构和变量
1.1.1 变量 ashmem_misc
static struct miscdevice ashmem_misc = {.minor = MISC_DYNAMIC_MINOR,.name = "ashmem",.fops = &ashmem_fops,
};在 ashmem 驱动初始化的时候会调用 misc_register() 进行注册,详细可以查看 ashmem_init() 函数。
该设备中指定的 file_operations 是 ashmem_fops,如下。
1.1.2 变量 ashmem_fops
static const struct file_operations ashmem_fops = {.owner = THIS_MODULE,.open = ashmem_open, //节点文件open函数.release = ashmem_release, //节点文件结构被释放时会调用release函数.read_iter = ashmem_read_iter, .llseek = ashmem_llseek,.mmap = ashmem_mmap, //节点文件的mmap函数.unlocked_ioctl = ashmem_ioctl, //节点文件的ioctl函数
#ifdef CONFIG_COMPAT.compat_ioctl = compat_ashmem_ioctl, //32位用户系统调用64位驱动的ioctl函数时使用
#endif
#ifdef CONFIG_PROC_FS.show_fdinfo = ashmem_show_fdinfo, //查询/proc/pid/fdinfos/[fd]时打印
#endif
};compat_ioctl 对于64bit 的驱动必须要实现的ioctl,当有32 bit 的用户层调用 ioctl() 时,会callback 到这里,否则会返回 Not a typewriter 的错误。
64bit 用户层调用 64bit 驱动,或者 32bit 用户层调用 32bit 驱动时,都是callback unlocked_ioctl 函数。
show_fdinfo 函数用于查询 /proc/<pid>/fdinfos/<fd> 时打印,例如:
phone_shift:/ # cat /proc/967/fdinfo/34
pos: 0
flags: 0400002
mnt_id: 45
ino: 1210
inode: 6146
name: gralloc_shared_memory
size: 24041.1.3 struct ashmem_area
struct ashmem_area {char name[ASHMEM_FULL_NAME_LEN]; //共享内存区域的名称,在/proc/<pid>/maps中携带struct list_head unpinned_list; //用以串联所有的 ashmem_areastruct file *file; //该共享内存的实际filesize_t size; //该共享内存的大小unsigned long prot_mask; //该共享内存文件的属性,包括r、w、x
};驱动中通过该数据结构管理所有的共享内存区域,每个共享内存区域都有一个名字,前缀是ASHMEM_NAME_PREFIX (dev/ashmem/),这个名字通过 /proc/<pid>/maps 查看到,例如:
130|phone_shift:/ # cat /proc/967/maps | grep ashmem
76b525e000-76b526e000 rw-s 00000000 00:01 13 /dev/ashmem/MessageQueue (deleted)
76b5309000-76b5319000 rw-s 00000000 00:01 2057 /dev/ashmem/MessageQueue (deleted)
76b55c2000-76b55c3000 rw-s 00000000 00:01 3095 /dev/ashmem/gralloc_shared_memory (deleted)
76b55c4000-76b55c5000 rw-s 00000000 00:01 4099 /dev/ashmem/gralloc_shared_memory (deleted)这是 hwc 进程中 ashmem 对应的 vma。在申请ashmem 的时候,都会指定其 name。
每个ashmem 都会在临时文件系统 tmpfs 中对应一个文件,也就是成员变量 file,并且通过 prot_mask 指定文件访问的权限,该 ashmem 在初始化的时候 prot_mask 被指定为 PROT_MASK,后期根据实际情况可以通过接口进行修改。
#define PROT_MASK (PROT_EXEC | PROT_READ | PROT_WRITE)ashmem 机制中,需要使用内存块(ashmem_range) 时需要调用ashmem_pin() 函数进行锁定,不被使用的内存会解除锁定。
如果内存块(ashmem_range) 解除锁定,会将这些内存块(ashmem_range) 添加到 asma->unpinned_list 链表中,且添加到 ashmem_lru_list 中便于内存紧张时进行回收。但是两个链表的插入方式不同:
-
asma->unpinned_list 是将 ashmem_range 的地址从大到小串联起来;
-
ashmem_lru_list 是按照LRU 方式将最新的 ashmem_range 插入到链表尾;
1.1.4 struct ashmem_range
struct ashmem_range {struct list_head lru; //串联链表使用struct list_head unpinned; //用以标记是否加入unpinned liststruct ashmem_area *asma; //该块内存归属于ashmem_areasize_t pgstart; //内存的起始pagesize_t pgend; //内存的结尾page,这块内存区间是[pgstart, pgend]unsigned int purged; //标记这块区间是否被回收
};ashmem_range 可以理解为 ashmem_area 中的内存块。
每个 ashmem_area 会被分成很多的小块(ashmem_range),这些小块会有两种状态:pin 和 unpin。如果该内存块为 unpin,则该内存块会被添加到 ashmem_area 中的 unpinned_list 链表中,通过成员变量 unpinned。
每个小块的内存区间是 [pgstart, pgend]。
1.1.5 struct ashmem_pin
struct ashmem_pin {__u32 offset; /* offset into region, in bytes, page-aligned */__u32 len; /* length forward from offset, in bytes, page-aligned */
};提供给用户的结构体,标记 pin/unpin 时的内存区域,但是有一定要求:
-
len 可以为0,这样内存空间 ashmem_area 从 offset 之后的所有空间;
-
offset和 len 需要页对齐;
-
offset + len 不能超过 32位无符号数;
-
offset + len 不能超过 ashmem_area 空间;
1.1.6 ashmem_lru_list
/* LRU list of unpinned pages, protected by ashmem_mutex */
static LIST_HEAD(ashmem_lru_list);static unsigned long lru_count;在 ashmem_pin() 或这 ashmem_unpin() 中会分配新的 ashmem_range 对象,该结构体中成员 lru 用以串联链表并存放在 ashmem_lru_list 这个全局链表中,便于在内存使用紧张的时候进行回收。
与 ashmem_lru_list 对应的还有 lru_count 用于统计该 list 中页面数量。
1.2 ashmem 初始化
static int __init ashmem_init(void)
{int ret = -ENOMEM;ashmem_area_cachep = kmem_cache_create("ashmem_area_cache",sizeof(struct ashmem_area),0, 0, NULL);if (!ashmem_area_cachep) {pr_err("failed to create slab cache\n");goto out;}ashmem_range_cachep = kmem_cache_create("ashmem_range_cache",sizeof(struct ashmem_range),0, 0, NULL);if (!ashmem_range_cachep) {pr_err("failed to create slab cache\n");goto out_free1;}ret = misc_register(&ashmem_misc);if (ret) {pr_err("failed to register misc device!\n");goto out_free2;}ret = register_shrinker(&ashmem_shrinker);if (ret) {pr_err("failed to register shrinker!\n");goto out_demisc;}pr_info("initialized\n");return 0;out_demisc:misc_deregister(&ashmem_misc);
out_free2:kmem_cache_destroy(ashmem_range_cachep);
out_free1:kmem_cache_destroy(ashmem_area_cachep);
out:return ret;
}
device_initcall(ashmem_init);
代码比较清晰,主要做了几件事:
-
创建两个 slab cache:ashmem_area_cache 和 ashmem_range_cache,后面struct ashmem_area 和 struct ashmem_range 都是从slab 中分配内存;
-
misc_register() 函数注册 ashmem 设备;
-
register_shrinker() 注册回收函数,当内存不足时系统会通过 shrink_slab() 函数轮训系统中所有调用 register_shrinker() 注册的回收函数;
1.3 ashmem_open()
static int ashmem_open(struct inode *inode, struct file *file)
{struct ashmem_area *asma;int ret;ret = generic_file_open(inode, file);if (ret)return ret;asma = kmem_cache_zalloc(ashmem_area_cachep, GFP_KERNEL);if (!asma)return -ENOMEM;INIT_LIST_HEAD(&asma->unpinned_list);memcpy(asma->name, ASHMEM_NAME_PREFIX, ASHMEM_NAME_PREFIX_LEN);asma->prot_mask = PROT_MASK;file->private_data = asma;return 0;
}用户通过 open("/dev/ashmem") 函数进而触发该函数,主要目的是创建一个 ashmem_area 并初始化。
注意三点:
-
ashmem_area 名称初始化就有了,默认是 “/dev/ashmem/”;
-
默认ashmem_area 对应的共享文件是 PROT_MASK 权限;
-
ashmem_area 会被记录到 file->private_data 中;
1.4 ashmem_release()
static int ashmem_release(struct inode *ignored, struct file *file)
{struct ashmem_area *asma = file->private_data;struct ashmem_range *range, *next;mutex_lock(&ashmem_mutex);list_for_each_entry_safe(range, next, &asma->unpinned_list, unpinned)range_del(range);mutex_unlock(&ashmem_mutex);if (asma->file)fput(asma->file);kmem_cache_free(ashmem_area_cachep, asma);return 0;
}当最后一个打开设备的用户执行 close() 系统调用时,内核会调用驱动设定的 fops->release() 函数。对应 ashmem 驱动来说就是调用 ashmem_release() 函数。
主要做了三件事情:
-
遍历所有的 unpinned_list,将其中的 range 内存都释放掉;
-
fput() 将文件的计数减 1,如果发现 f_count为0了,那么将其对应的struct file结构删除。与其对应的是 fget() 函数,用以获取 struct file 结构并将 f_count 计数加 1;
-
释放ashmem_area 内存;
1.5 ashmem_mmap()
static int ashmem_mmap(struct file *file, struct vm_area_struct *vma)
{static struct file_operations vmfile_fops;struct ashmem_area *asma = file->private_data;int ret = 0;mutex_lock(&ashmem_mutex);/* user needs to SET_SIZE before mapping *///用户在调用mmap进行映射之前需要先调用 set_size()函数配置大小,否则无法mmapif (!asma->size) {ret = -EINVAL;goto out;}/* requested mapping size larger than object size *///要求ashmem_area的size大于请求mapping的大小if (vma->vm_end - vma->vm_start > PAGE_ALIGN(asma->size)) {ret = -EINVAL;goto out;}/* requested protection bits must match our allowed protection mask *///检测需要映射的vma的保护权限是否超过了ashmem_area的权限if ((vma->vm_flags & ~calc_vm_prot_bits(asma->prot_mask, 0)) &calc_vm_prot_bits(PROT_MASK, 0)) {ret = -EPERM;goto out;}vma->vm_flags &= ~calc_vm_may_flags(~asma->prot_mask);//这是ashmem_mmap()函数的核心处理,创建一个临时文件if (!asma->file) {char *name = ASHMEM_NAME_DEF;struct file *vmfile;struct inode *inode;//临时文件名默认/dev/ashmem,但如果asma->name已经配置好,则使用asma->nameif (asma->name[ASHMEM_NAME_PREFIX_LEN] != '\0')name = asma->name;/* ... and allocate the backing shmem file *///利用linux原生的shmem,在tmpfs中创建一个临时文件,该文件只对内核态可见,用户态不可见vmfile = shmem_file_setup(name, asma->size, vma->vm_flags);if (IS_ERR(vmfile)) {ret = PTR_ERR(vmfile);goto out;}//临时文件初始化vmfile->f_mode |= FMODE_LSEEK;inode = file_inode(vmfile);lockdep_set_class(&inode->i_rwsem, &backing_shmem_inode_class);//更新asma->file,此后的共享内存对应临时文件asma->file = vmfile;//更新临时文件的fops,覆盖掉mmap函数,临时文件mmap不再做任何事情//并且,要覆盖掉get_unmapped_area接口,获取进程没有映射的内存空间//vmfile_fops为staic,只需要更新一次if (!vmfile_fops.mmap) {vmfile_fops = *vmfile->f_op; //拿到vmfile的 fops,准备更新vmfile_fops.mmap = ashmem_vmfile_mmap;vmfile_fops.get_unmapped_area =ashmem_vmfile_get_unmapped_area;}//每次创建的临时文件的fops都使用vmfile_fopsvmfile->f_op = &vmfile_fops;}get_file(asma->file);//如果该vma已经处于共享状态,调用shmem_zero_setup()配置vma->vm_ops为shmem_vm_ops//vma->vm_file在后面会更新掉if (vma->vm_flags & VM_SHARED) {ret = shmem_zero_setup(vma);if (ret) {fput(asma->file);goto out;}} else {vma_set_anonymous(vma);}//vma->vm_file将指定到asma->file,即指定到创建好的临时vmfileif (vma->vm_file)fput(vma->vm_file);vma->vm_file = asma->file;out:mutex_unlock(&ashmem_mutex);return ret;
}当第一次mmap 时,会通过 shmem_file_setup() 在tmpfs 文件系统中创建一个临时文件(也许只是内核中的一个inode 节点)。该临时文件 vmfile 创建好之后会覆盖 asma->file,至此ashmem 与该vmfile 对应,ashmem 机制真正使用的map 对象就是该临时文件vmfile。
1.6 ashmem_ioctl()
涉及的命令有:
drivers/staging/android/uapi/ashmem.h#define __ASHMEMIOC 0x77#define ASHMEM_SET_NAME _IOW(__ASHMEMIOC, 1, char[ASHMEM_NAME_LEN])
#define ASHMEM_GET_NAME _IOR(__ASHMEMIOC, 2, char[ASHMEM_NAME_LEN])
#define ASHMEM_SET_SIZE _IOW(__ASHMEMIOC, 3, size_t)
#define ASHMEM_GET_SIZE _IO(__ASHMEMIOC, 4)
#define ASHMEM_SET_PROT_MASK _IOW(__ASHMEMIOC, 5, unsigned long)
#define ASHMEM_GET_PROT_MASK _IO(__ASHMEMIOC, 6)
#define ASHMEM_PIN _IOW(__ASHMEMIOC, 7, struct ashmem_pin)
#define ASHMEM_UNPIN _IOW(__ASHMEMIOC, 8, struct ashmem_pin)
#define ASHMEM_GET_PIN_STATUS _IO(__ASHMEMIOC, 9)
#define ASHMEM_PURGE_ALL_CACHES _IO(__ASHMEMIOC, 10)具体实现可以查看源码,主要来看下 pin 和 unpin:
static long ashmem_ioctl(struct file *file, unsigned int cmd, unsigned long arg)
{struct ashmem_area *asma = file->private_data;long ret = -ENOTTY;switch (cmd) {...case ASHMEM_PIN:case ASHMEM_UNPIN:case ASHMEM_GET_PIN_STATUS:ret = ashmem_pin_unpin(asma, cmd, (void __user *)arg);break;}return ret;
}1.7 ashmem_pin_unpin()
static int ashmem_pin_unpin(struct ashmem_area *asma, unsigned long cmd,void __user *p)
{struct ashmem_pin pin;size_t pgstart, pgend;int ret = -EINVAL;struct ashmem_range *range = NULL;//用户等调用pin/unpin时,会传递ashmem_pin类型的参数if (copy_from_user(&pin, p, sizeof(pin)))return -EFAULT;//当调用pin/unpin接口时,创建一个ashmem_range对象if (cmd == ASHMEM_PIN || cmd == ASHMEM_UNPIN) {range = kmem_cache_zalloc(ashmem_range_cachep, GFP_KERNEL);if (!range)return -ENOMEM;}mutex_lock(&ashmem_mutex);//等待回收的完成wait_event(ashmem_shrink_wait, !atomic_read(&ashmem_shrink_inflight));//如果临时文件vmfile还没有创建好,无法进行pin/unpin操作if (!asma->file)goto out_unlock;//pin.len的值可以设为0,即从pin.offset之后的全部内存if (!pin.len)pin.len = PAGE_ALIGN(asma->size) - pin.offset;//偏移地址和大小要求页对齐if ((pin.offset | pin.len) & ~PAGE_MASK)goto out_unlock;//需要操作内存末尾地址不能超出if (((__u32)-1) - pin.offset < pin.len)goto out_unlock;//需要操作内存末尾地址不能超过ashmem_area指定的sizeif (PAGE_ALIGN(asma->size) < pin.offset + pin.len)goto out_unlock;//操作区间需要页对齐pgstart = pin.offset / PAGE_SIZE;pgend = pgstart + (pin.len / PAGE_SIZE) - 1;switch (cmd) {case ASHMEM_PIN:ret = ashmem_pin(asma, pgstart, pgend, &range);break;case ASHMEM_UNPIN:ret = ashmem_unpin(asma, pgstart, pgend, &range);break;case ASHMEM_GET_PIN_STATUS:ret = ashmem_get_pin_status(asma, pgstart, pgend);break;}out_unlock:mutex_unlock(&ashmem_mutex);if (range)kmem_cache_free(ashmem_range_cachep, range);return ret;
}pin/unpin 对于 offset 和 len 有一定的要求:
-
len 可以为0,这样内存空间 ashmem_area 从 offset 之后的所有空间;
-
offset和len 需要页对齐;
-
offset + len 不能超过 32位无符号数;
-
offset + len 不能超过 ashmem_area 空间;
ashmem 机制中,正在使用的 ashmem_range 需要 pin,不被使用的 ashmem_range 需要 unpin。unpin 的ashmem_range 会添加到 asma->unpinned_list 链表中,且该 ashmem_range 会被添加到ashmem_lru_list 中。
pin 和 unpin 只是改变相关状态标记,并不会改变已经 mapping 的地址空间,因此,用户可以在unpin 后重新pin 住内存块。
注意:
函数的返回值为实际处理函数的范围值,有两种情况:ASHMEM_NOT_PURGED 和ASHMEM_WAS_PURGED。ASHMEM_NOT_PURGED 表示该内存块物理内存没有被回收。
1.7.1 ashmem_unpin()
static int ashmem_unpin(struct ashmem_area *asma, size_t pgstart, size_t pgend,struct ashmem_range **new_range)
{struct ashmem_range *range, *next;unsigned int purged = ASHMEM_NOT_PURGED;restart:list_for_each_entry_safe(range, next, &asma->unpinned_list, unpinned) {/* short circuit: this is our insertion point */if (range_before_page(range, pgstart))break;/** The user can ask us to unpin pages that are already entirely* or partially pinned. We handle those two cases here.*/if (page_range_subsumed_by_range(range, pgstart, pgend))return 0;if (page_range_in_range(range, pgstart, pgend)) {pgstart = min(range->pgstart, pgstart);pgend = max(range->pgend, pgend);purged |= range->purged;range_del(range);goto restart;}}range_alloc(asma, range, purged, pgstart, pgend, new_range);return 0;
}如 struct ashmem_area 中所述,一块匿名共享内存中的所有解锁内存块,都是按照地址从大到小的顺序保存在 unpinned_list 中。
该函数的目的是将该内存块(ashmem_range) 添加到 asma->unpinned_list 和 ashmem_lru_list 链表中。
当内存块插入到 asma->unpinned_list 时会考虑内存合并,有如下几种处理方式(绿色是old,红色是new):

-
A:新添加的内存块地址大于最大range,将直接添加到asma->unpinned_list 头部;
-
B:新添加的内存块完全处于某range 中,不做任何处理,原先的range 已经unpinned 了;
-
C、D、E:三种情况是合并的情况,都会将原先range 与新的range 进行合并,并将原先range删掉,保留新的range;
1.7.2 ashmem_pin()
static int ashmem_pin(struct ashmem_area *asma, size_t pgstart, size_t pgend,struct ashmem_range **new_range)
{struct ashmem_range *range, *next;int ret = ASHMEM_NOT_PURGED;list_for_each_entry_safe(range, next, &asma->unpinned_list, unpinned) {/* moved past last applicable page; we can short circuit */if (range_before_page(range, pgstart))break;if (page_range_in_range(range, pgstart, pgend)) {ret |= range->purged;/* Case #1: Easy. Just nuke the whole thing. */if (page_range_subsumes_range(range, pgstart, pgend)) {range_del(range);continue;}/* Case #2: We overlap from the start, so adjust it */if (range->pgstart >= pgstart) {range_shrink(range, pgend + 1, range->pgend);continue;}/* Case #3: We overlap from the rear, so adjust it */if (range->pgend <= pgend) {range_shrink(range, range->pgstart,pgstart - 1);continue;}/** Case #4: We eat a chunk out of the middle. A bit* more complicated, we allocate a new range for the* second half and adjust the first chunk's endpoint.*/range_alloc(asma, range, range->purged,pgend + 1, range->pgend, new_range);range_shrink(range, range->pgstart, pgstart - 1);break;}}return ret;
}ashmem机制中的一个内存块,最开始一定处于锁定状态,被解锁之后会被放入到 asma->unpinned_list 中。该函数的目的是遍历该 unpinned_list,寻找和指定的pgstart和pgend 相交或包含的内存块,对其进行重新锁定。
同ashmem_unpinned(),仍然将处理方式分为如下几种(绿色是old,红色是new):

A:需要pinned 的内存块不在 asma->unpinned_list 中,那不用过多考虑;
B:需要pinned 的内存块完全包含range中,继续轮询确认是否与其他range有交叉;
C、D:并不会删除range 后再重新分配,而是直接修改 range->pgstart 和 range->pgend,并相应的减少 LRU list中的页面数量;
E:这种情况比较特殊,会将range 切成两块,[range->pgstart, pgstart) 算在原来的range 中,(pgend, range->pgend] 算到new range中;
2. ashmem 在进程间共享的原理
假设进程 A 调用 open() 函数打开 /dev/ashmem,这样会得到一个匿名共享内存的一个struct file 和文件描述符,假如是 file1 和 fd1. 然后进程 B 通过 Binder 进程间通信机制请求进程 A 将fd1 返回给它,但 fd1 只在进程 A 中有效,因此 Binder 驱动程序在进程B 中创建一个新的描述符 fd2,使得fd2 也指向 file1,最后再将 fd2 返回给进程 B。这样描述符 fd1 和 fd2 就指向同一个文件结构体 file1,即指向同一个匿名共享内存。
3. ashmem 注意点
-
ashmem 机制相当于Linux 共享内存的扩展,扩展后使用更加便捷;
-
Android 中通过 binder 机制将 ashmem 的 fd 进行传递,增加安全性,同时避免了 buffer 拷贝,效率提升;
-
ashmem 不会占用Dalvik heap 和 Native heap,所以不会导致 OOM;
-
ashmem 占用空间的计算,是计算到第一个创建它的进程中,其他进程不会将 ashmem 计算在内;
参考:
https://www.kancloud.cn/alex_wsc/androids/477718
https://blog.csdn.net/vviccc/article/details/123237169
https://blog.csdn.net/run068/article/details/121695036
https://www.cjcbill.com/2019/04/15/android-ashmem/
https://blog.51cto.com/u_9420214/6331901
相关文章:
Android ashmem 原理分析
源码基于:Andoird U Kernel-5.10 0. 简介 ashmem 称为匿名共享内存(Anonymous Shared Memory),它以驱动程序的形式实现在内核空间中。它有两个特点: 能否辅助内存管理系统来有效地管理不再使用的内存块(pin / unpin); 通过Bind…...
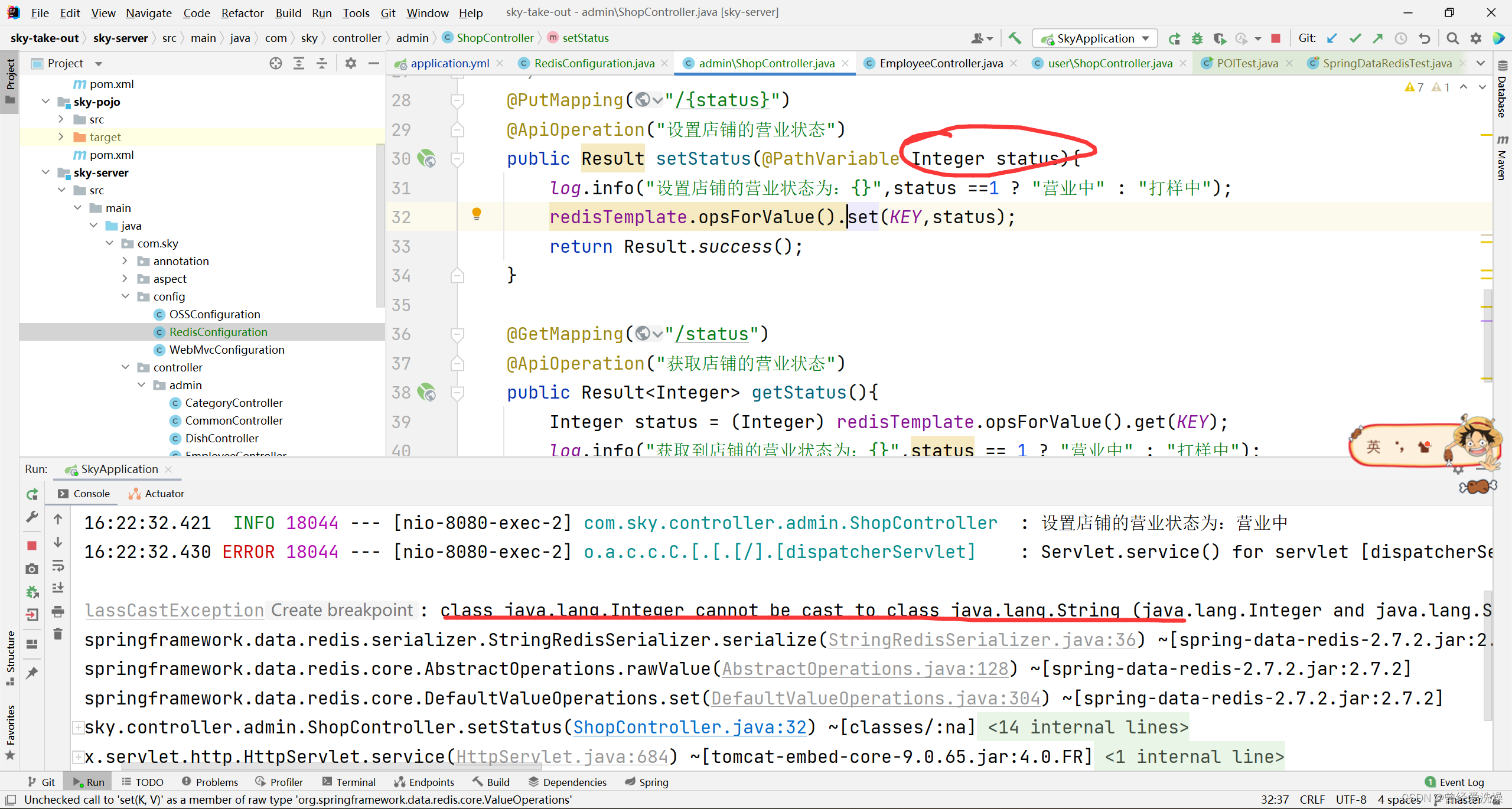
redis报错500
之前自己举一反三把value也给序列化了: 然后报错了: 原因是这里传入的是Integer类型,序列化的话就变为string类型了...

GPT-3
论文:Language Models are Few-Shot Learners(巨无霸OpenAI GPT3 2020) 摘要 最近的工作表明,通过对大量文本进行预训练,然后对特定任务进行微调,在许多NLP任务和基准方面取得了实质性进展。虽然这种方法…...

MATLAB数组
文章目录 数组创建通过冒号创建一维数组通过logspace函数创建一维数组通过linspace函数创建一维数组 通过randperm生成随机整数排列运算算术运算关系运算逻辑运算优先顺序 矩阵创建矩阵操作下标引用矩阵信息提取删除与扩展合并矩阵元素的运算矩阵运算 数组 在MATLAB中一般使用…...
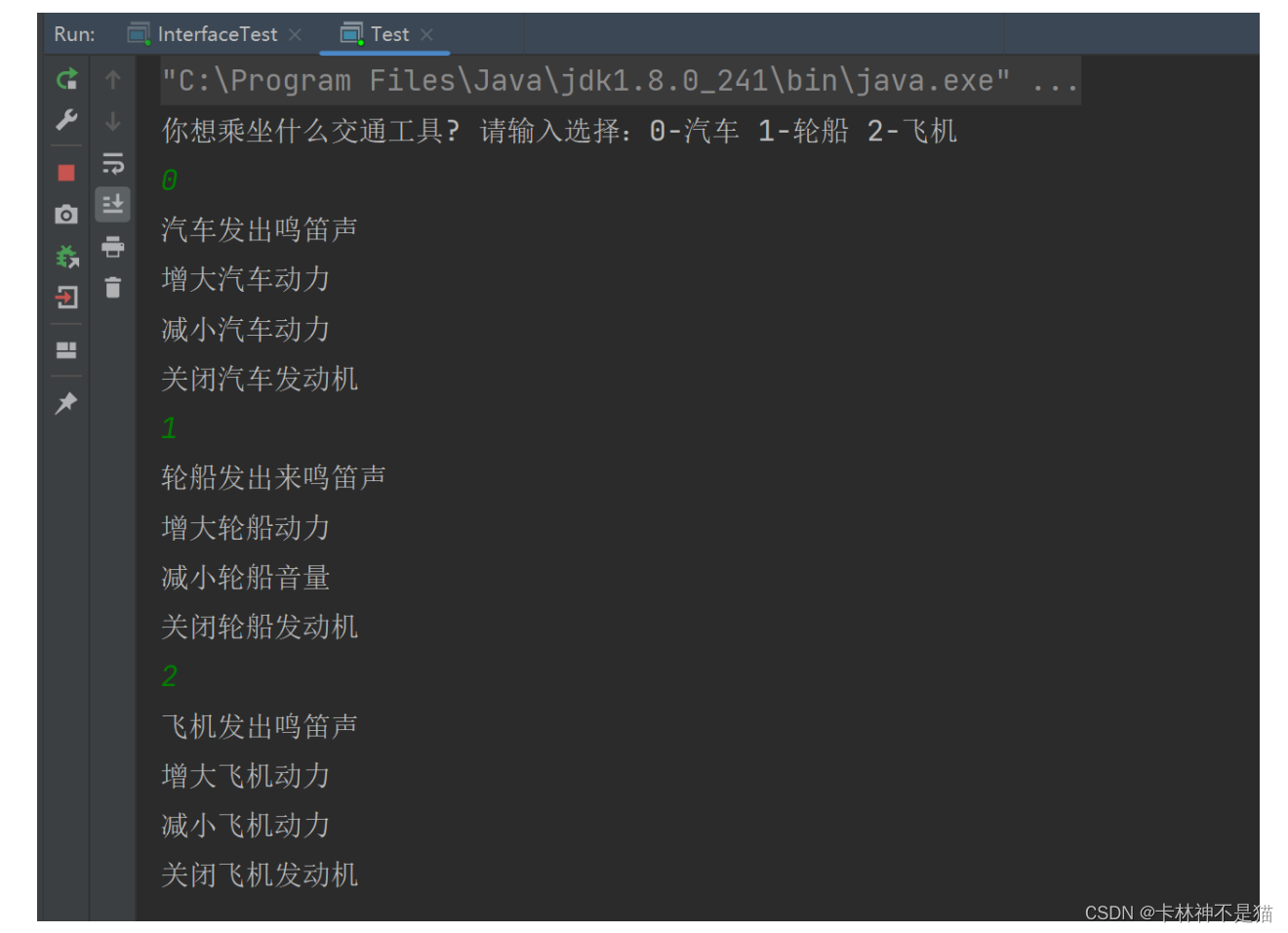
JAVA实验项目(二): 抽象类、接口的定义与使用
实验项目二 抽象类、接口的定义与使用 Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊&…...

JVM内存模型最新面试题(持续更新)
问题:java中创建的对象一般放在哪里?(全流程包含从创建到回收) 回答 大部分对象在堆中,这个基本都知道; 少部分对象是会在栈中的,比如作用域不局限于方法内的方法内部变量,这类对象的特征一般就是生命周期…...

Nginx wss to ws 折腾记
jssip 或 sipml5 <----wss--->nginx<---ws---->fs(5066) fs_cli -x sofia loglevel all 9 日志如下: REGISTER sip:192.168.43.135 SIP/2.0 Via: SIP/2.0/WSS df7jal23ls0d.invalid;branchz9hG4bKurFnCK9qJuXQlSrbszSL1S6wbCokKlLr;rport From: <…...

Java入门基础学习笔记22——程序流程控制
程序流程控制:控制程序的执行顺序。 程序有哪些执行顺序? 顺序、分支和循环。 分支结构: if、switch 循环: for、while、do-while 顺序结构是程序中最简单最基本的流程控制,没有特定的语法结构,按照代码…...

java医院信息系统HIS源码SaaS模式Java版云HIS系统 接口技术RESTful API + WebSocket + WebService
java医院信息系统HIS源码SaaS模式Java版云HIS系统 接口技术RESTful API WebSocket WebService 云HIS是基于云计算的医疗卫生信息系统(Cloud-Based Healthcare Information System),它运用云计算、大数据、物联网等新兴信息技术,…...

2024年成都高新区支持企业申报国家、省级、市级大数据产业发展、新一代信息技术与制造业融合发展、工业互联网推广应用等试点示范项目申报对象条件和奖补
一、申报对象 (一)本政策支持注册地址、税收关系在成都高新区,具有独立法人资格的企业。 (二)管理规范,无不良信用记录,自觉遵守安全生产、环境保护等方面的法律法规,近三年未发生…...

让《行列视》解放数据力量,提升业务洞察
在当今信息化浪潮下,数据已经成为企业发展的核心驱动力之一。如何更好地管理和利用数据,已成为企业发展过程中亟需解决的问题之一。而报表工具作为数据可视化和分析的利器,正逐渐受到企业的重视和青睐。 一、《行列视》作为报表工具的重要性…...

LeetCode 每日一题 ---- 【2244.完成所有任务需要的最少轮数】
LeetCode 每日一题 ---- 【2244.完成所有任务需要的最少轮数】 2244.完成所有任务需要的最少轮数方法:哈希表贪心 2244.完成所有任务需要的最少轮数 方法:哈希表贪心 用哈希表统计每个等级出现的次数 每次处理优先消费 3 个,m % 3 后&#…...

【RAG 去噪】引入 NLI 模型来为 RAG 去噪
论文:Making Retrieval-Augmented Language Models Robust to Irrelevant Context ⭐⭐⭐ ICLR 2024, arXiv:2310.01558 Code: github.com/oriyor/ret-robust 论文速读 这篇论文引入 NLI(Natural Language Inference)模型来判定 retrieved d…...
SQLite利用事务实现批量插入(提升效率)
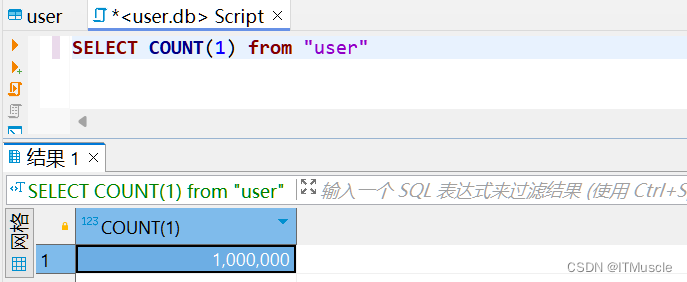
在尝试过SQLite批量插入一百万条记录,执行时长高达20多分钟后,就在想一个问题,这样的性能是不可能被广泛应用的,更不可能出现在真实的生产环境中,那么对此应该如何优化一下呢? 首先分析一下批量插入的逻辑 …...

使用Python处理Excel数据:去除列中的双引号
目录 引言 技术背景 步骤概述 代码示例 案例分析 扩展内容 1. 处理多个列中的双引号 2. 处理大型Excel文件 3. 自定义函数处理数据 4. 错误处理和日志记录 结论 引言 在当今信息爆炸的时代,数据已经成为了各个行业最宝贵的资源之一。而Excel,…...

未来互联网:Web3的技术革新之路
引言 随着技术的不断发展和社会的日益数字化,互联网作为信息交流和社交媒介的重要平台已经成为我们生活中不可或缺的一部分。然而,传统的互联网架构在数据安全、隐私保护和去中心化等方面存在着诸多挑战。为了解决这些问题,Web3技术应运而生…...

【练习】分治--快排思想
🎥 个人主页:Dikz12🔥个人专栏:算法(Java)📕格言:吾愚多不敏,而愿加学欢迎大家👍点赞✍评论⭐收藏 目录 颜色分类 题目描述 题解 代码实现 排序数组 题目描述 题解 代码…...

Unity读书系列《Unity高级编程:主程手记》——C#技术要点
文章目录 前言一、业务逻辑优化技巧二、Unity3d中C#的底层原理三、List底层源码剖析四、Dictionary底层源码剖析五、浮点数的精度问题六、委托、事件、装箱、拆箱七、算法总结 前言 本文旨在总结某一概念的性质,并引出相关的技术要点。如果读者希望深入了解相关技术…...
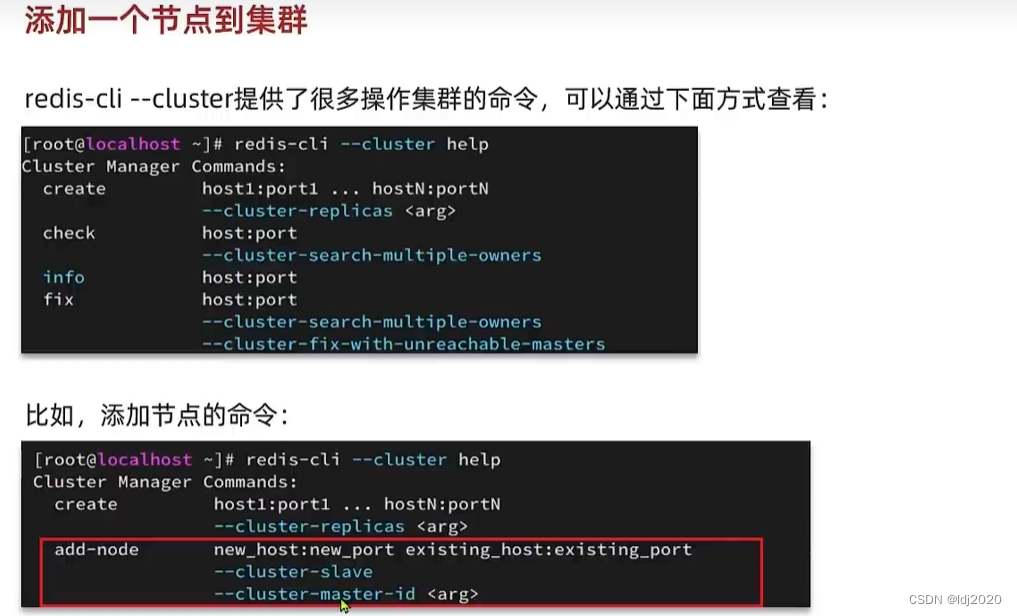
Redis分片集群
哨兵集群虽然解决了高可用和高并发读问题,但是还是有缺陷 1. 因为是主节点是单节点,并发写存在瓶颈 2.数据量大了每个节点存储相同的数据,造成内存紧张,资源浪费 redis.conf文件 port 6379 # 开启集群功能 cluster-enabled yes…...

Math.Round()函数说明
Math.Round()并不是严格意义上的是四舍五入函数。它默认的执行的是“银行家舍入”算法,即四舍六入五取偶。概括为:四舍六入五考虑、五后非零就进一,五后皆零看奇偶,五前为偶应舍去、五前为奇要进一。 当为5时,取离着最…...
)
大模型查询质量评估新范式(Perplexity算法底层逻辑首次公开)
更多请点击: https://codechina.net 第一章:大模型查询质量评估新范式(Perplexity算法底层逻辑首次公开) Perplexity(困惑度)并非仅是语言模型训练阶段的监控指标,而是当前大模型查询质量评估中…...

N_m3u8DL-RE:跨平台流媒体下载终极指南,三行命令破解加密视频
N_m3u8DL-RE:跨平台流媒体下载终极指南,三行命令破解加密视频 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/…...
)
Apple Music断供后歌单全没?别慌!用iTunes导出的XML文件+Excel手动抢救歌单(保姆级图文教程)
Apple Music断供后歌单全没?别慌!用iTunes导出的XML文件Excel手动抢救歌单(保姆级图文教程) 当你发现Apple Music因断供导致精心收藏的歌单全部消失时,那种心情就像突然失去了多年的音乐记忆。别担心,这份…...

Google 的 IDE 演进小史
不知道你平时用的 IDE 是什么?小七的工程师同事有在用 Vim 的,也有 Emacs 党,IntelliJ 全家桶也有人在用,用得最多的可能是 VS Code。只要代码能写好、工具链能跑通,似乎大家没有必要使用同一个 IDE。 Google 早年也是…...
的3D视觉原理与应用)
从‘看见’到‘看懂’:手把手拆解RGB-D摄像头(如Intel Realsense)的3D视觉原理与应用
从‘看见’到‘看懂’:手把手拆解RGB-D摄像头的3D视觉原理与应用 当你第一次看到RGB-D摄像头生成的彩色点云在屏幕上旋转时,那种将现实世界数字化的震撼感令人难忘。但真正让这种设备发挥价值的,是理解它如何将光信号转化为三维坐标的完整技术…...

告别假进度条!UE5蓝图实战:用自定义AssetManager实现真实关卡加载进度
UE5蓝图实战:打造真实关卡加载进度系统 在虚幻引擎5(UE5)游戏开发中,流畅的关卡加载体验对玩家沉浸感至关重要。许多开发者会遇到"假进度条"问题——进度条看似在动,实则与真实加载进度无关。本文将手把手教…...

Overleaf实战:利用multicol宏包实现LaTeX文档的灵活分栏布局
1. 为什么需要分栏布局? 第一次用LaTeX写论文时,我被期刊模板要求"双栏排版"整懵了。单栏文档写得好好的,突然要在同一页并排显示两列内容,还要处理图片表格的跨栏问题。传统\twocolumn命令虽然简单,但调整…...

C++中如何调用C语言的代码实现
为什么要是用 extern "C"在进行C开发的时候,由于C、C编译规则是不同的。C编译函数方法是 使用mangle的技术 。123456789101112void func(int age) {}void func(int age, int height) {}/*如果有这两个函数要被调用,在C语言中函数重载是不允许的…...
)
从新手到认证专家:NotebookLM总结能力跃迁路径图(含Google官方未公开的评估矩阵V2.1)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM总结能力跃迁路径总览 NotebookLM 是 Google 推出的面向研究者与开发者的情境化 AI 助手,其核心突破在于将用户上传的文档(PDF、TXT、Google Docs)转化为可…...

别再只盯着RRT了!关节空间六次多项式规划,可能是更简单的机械臂避障方案
关节空间六次多项式规划:机械臂避障的优雅解法 在工业机器人领域,路径规划一直是核心挑战之一。当机械臂需要在充满障碍物的环境中工作时,传统基于笛卡尔空间的规划方法常常面临逆运动学奇异、轨迹不平滑等问题。而基于关节空间的六次多项式规…...