使用Python处理Excel数据:去除列中的双引号
目录
引言
技术背景
步骤概述
代码示例
案例分析
扩展内容
1. 处理多个列中的双引号
2. 处理大型Excel文件
3. 自定义函数处理数据
4. 错误处理和日志记录
结论
引言
在当今信息爆炸的时代,数据已经成为了各个行业最宝贵的资源之一。而Excel,作为一种广泛使用的电子表格软件,成为了数据存储和分析的重要工具。然而,当数据从各种来源导入Excel时,可能会遇到格式不一致或包含不需要的字符(如双引号)的情况。对于Python用户来说,利用Python强大的数据处理能力,可以轻松处理这些问题。本文将详细介绍如何使用Python从Excel中读取数据,去除列中的双引号,并将处理后的数据写回Excel文件。

技术背景
Python作为一种高级编程语言,拥有众多强大的库和工具,可以方便地处理各种类型的数据。在处理Excel数据时,Python提供了多种解决方案。其中,pandas是一个功能强大的数据分析库,它提供了读取和写入Excel文件的功能,通过read_excel和to_excel方法,可以轻松地将Excel表格数据转换为DataFrame对象,并进行各种数据操作。此外,对于需要更底层操作Excel文件(如修改样式或处理大型文件)的情况,可以使用openpyxl、xlrd/xlwt等库。
步骤概述
- 导入必要的库:首先,我们需要导入pandas库,以便使用其提供的Excel读写功能。如果需要进行更复杂的Excel操作,还可以导入openpyxl等库。
- 读取Excel文件:使用pandas的read_excel方法读取Excel文件,并将数据加载到DataFrame对象中。这个方法允许我们指定要读取的工作表名称、列名等参数。
- 处理数据:对包含双引号的列应用字符串替换操作,去除双引号。这可以通过pandas的str.replace方法实现,该方法允许我们指定要替换的字符串和替换后的字符串。
- 写回Excel文件:使用pandas的to_excel方法将处理后的数据写回Excel文件。这个方法允许我们指定输出文件的名称、工作表名称等参数。
- (可选)使用openpyxl进行更复杂的操作:如果需要进行更复杂的Excel操作(如修改单元格样式、合并多个工作表等),可以使用openpyxl库。openpyxl提供了对Excel文件底层的操作,可以实现对单元格、工作表、工作簿等的精细控制。
代码示例
下面是一个简单的代码示例,演示了如何使用Python读取Excel文件,去除列中的双引号,并将处理后的数据写回Excel文件。
import pandas as pd # 读取Excel文件
df = pd.read_excel('input.xlsx', sheet_name='Sheet1') # 假设要处理的列名为'ColumnWithQuotes'
# 使用str.replace方法去除双引号
df['ColumnWithQuotes'] = df['ColumnWithQuotes'].str.replace('"', '') # 将处理后的数据写回Excel文件
df.to_excel('output.xlsx', index=False, sheet_name='Sheet1') # 如果需要更复杂的Excel操作,可以使用openpyxl库
# 这里仅作为示例,不详细展开
# from openpyxl import Workbook
# wb = Workbook()
# ws = wb.active
# ...(此处省略openpyxl的使用示例)
# wb.save('output_with_openpyxl.xlsx')在上面的代码中,我们首先使用pd.read_excel方法读取名为input.xlsx的Excel文件,并将数据加载到DataFrame对象df中。然后,我们假设要处理的列名为ColumnWithQuotes,并使用str.replace方法将该列中的双引号替换为空字符串,从而去除双引号。最后,我们使用to_excel方法将处理后的数据写回到一个新的Excel文件output.xlsx中。注意,在调用to_excel方法时,我们指定了index=False参数,以避免将DataFrame的索引写入Excel文件。
案例分析
假设我们有一个包含销售数据的Excel文件sales_data.xlsx,其中一个名为ProductDescription的列包含产品的描述信息。然而,由于某些原因,这些描述信息都被双引号包围起来,如下所示:
ID ProductName ProductDescription Price
1 ProductA "This is a great product!" 100
2 ProductB "Another awesome product" 150
3 ProductC "Don't miss this deal!" 80
这些双引号对于后续的数据分析来说是不必要的,甚至可能导致错误。因此,我们需要使用Python去除这些双引号。
按照上面的代码示例,我们可以编写一个Python脚本,来读取sales_data.xlsx文件,去除ProductDescription列中的双引号,并将处理后的数据写回到一个新的Excel文件clean_sales_data.xlsx中。
完整代码实现
import pandas as pd # 读取Excel文件
df = pd.read_excel('sales_data.xlsx', sheet_name='Sheet1') # 去除'ProductDescription'列中的双引号
df['ProductDescription'] = df['ProductDescription'].str.replace('"', '') # 将处理后的数据写回新的Excel文件
df.to_excel('clean_sales_data.xlsx', index=False, sheet_name='Sheet1') print("数据清洗完成,已保存到clean_sales_data.xlsx文件。")扩展内容
1. 处理多个列中的双引号
如果Excel文件中存在多个列都包含双引号,我们可以使用循环或列表推导式来一次性处理这些列。
# 假设'Description1', 'Description2'等列都包含双引号
columns_with_quotes = ['Description1', 'Description2', 'ProductDescription'] # 使用列表推导式去除这些列中的双引号
for col in columns_with_quotes: df[col] = df[col].str.replace('"', '')2. 处理大型Excel文件
当处理大型Excel文件时,内存消耗可能成为一个问题。pandas的read_excel方法支持按块读取数据(使用chunksize参数),这样可以在不加载整个文件到内存的情况下处理数据。
chunksize = 1000 # 设置块大小
chunks = [] # 按块读取数据
for chunk in pd.read_excel('large_sales_data.xlsx', sheet_name='Sheet1', chunksize=chunksize): # 去除双引号 chunk['ProductDescription'] = chunk['ProductDescription'].str.replace('"', '') # 将处理后的块添加到列表中 chunks.append(chunk) # 将所有块合并为一个DataFrame
df = pd.concat(chunks, ignore_index=True) # 将合并后的数据写回Excel文件
df.to_excel('clean_large_sales_data.xlsx', index=False, sheet_name='Sheet1')3. 自定义函数处理数据
当需要执行更复杂的数据清洗或转换操作时,可以编写自定义函数来处理数据。
def clean_data(text): # 在这里可以添加更多的数据清洗逻辑 text = text.strip() # 去除字符串两端的空白字符 text = text.replace('"', '') # 去除双引号 return text # 应用自定义函数到指定列
df['ProductDescription'] = df['ProductDescription'].apply(clean_data)4. 错误处理和日志记录
在实际应用中,数据清洗过程可能会遇到各种错误或异常情况。因此,添加错误处理和日志记录功能可以提高代码的健壮性和可维护性。
import logging # 配置日志记录器
logging.basicConfig(filename='data_cleaning.log', level=logging.INFO) try: # 读取和处理Excel数据(省略具体代码) # ...
except Exception as e: # 记录错误信息到日志文件 logging.exception("An error occurred during data cleaning: %s", str(e))结论
通过本文的介绍,我们了解了如何使用Python从Excel文件中读取数据,去除列中的双引号,并将处理后的数据写回Excel文件。我们详细讨论了pandas库在处理Excel数据时的强大功能,并提供了多个代码示例和案例来演示如何应用这些功能。此外,我们还探讨了如何处理大型Excel文件、自定义数据清洗函数以及添加错误处理和日志记录功能等扩展内容。这些技术和方法对于数据科学家和数据分析师来说是非常实用的,可以帮助他们更高效地进行数据处理和分析工作。
相关文章:
使用Python处理Excel数据:去除列中的双引号
目录 引言 技术背景 步骤概述 代码示例 案例分析 扩展内容 1. 处理多个列中的双引号 2. 处理大型Excel文件 3. 自定义函数处理数据 4. 错误处理和日志记录 结论 引言 在当今信息爆炸的时代,数据已经成为了各个行业最宝贵的资源之一。而Excel,…...

未来互联网:Web3的技术革新之路
引言 随着技术的不断发展和社会的日益数字化,互联网作为信息交流和社交媒介的重要平台已经成为我们生活中不可或缺的一部分。然而,传统的互联网架构在数据安全、隐私保护和去中心化等方面存在着诸多挑战。为了解决这些问题,Web3技术应运而生…...

【练习】分治--快排思想
🎥 个人主页:Dikz12🔥个人专栏:算法(Java)📕格言:吾愚多不敏,而愿加学欢迎大家👍点赞✍评论⭐收藏 目录 颜色分类 题目描述 题解 代码实现 排序数组 题目描述 题解 代码…...

Unity读书系列《Unity高级编程:主程手记》——C#技术要点
文章目录 前言一、业务逻辑优化技巧二、Unity3d中C#的底层原理三、List底层源码剖析四、Dictionary底层源码剖析五、浮点数的精度问题六、委托、事件、装箱、拆箱七、算法总结 前言 本文旨在总结某一概念的性质,并引出相关的技术要点。如果读者希望深入了解相关技术…...
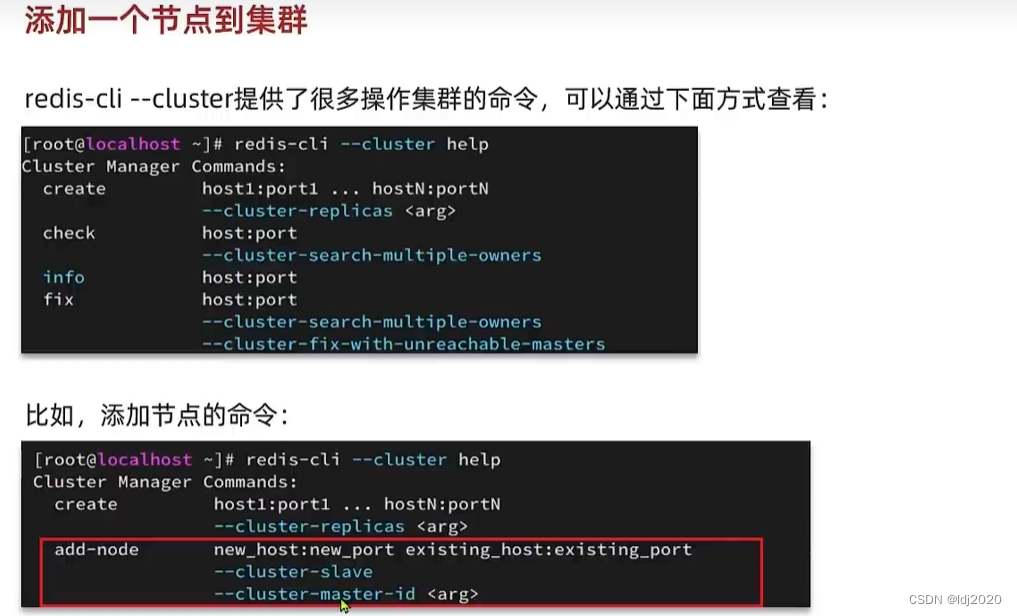
Redis分片集群
哨兵集群虽然解决了高可用和高并发读问题,但是还是有缺陷 1. 因为是主节点是单节点,并发写存在瓶颈 2.数据量大了每个节点存储相同的数据,造成内存紧张,资源浪费 redis.conf文件 port 6379 # 开启集群功能 cluster-enabled yes…...

Math.Round()函数说明
Math.Round()并不是严格意义上的是四舍五入函数。它默认的执行的是“银行家舍入”算法,即四舍六入五取偶。概括为:四舍六入五考虑、五后非零就进一,五后皆零看奇偶,五前为偶应舍去、五前为奇要进一。 当为5时,取离着最…...

001 定期同步mysql数据到es 删除数据库记录同时删除es记录 es全文搜索分词和高亮
文章目录 ProductController.javaProduct.javaElasticsearchSyncListener.javaProductElasticSearchMapper.javaProductMapper.javaProductDeletedEvent.javaProductServiceImpl.javaSyncProductService.javaIProductService.javaElasticSearchSpringDemoApplication.javaServl…...

Vue 快速入门:Vue初级
语法规则 前端渲染 渲染有几种方式:原生js、js模板、Vue模板语法 原生js 使用字符串拼接 js模板语法 Vue.js 模板语法概述 Vue.js 是一个用于构建用户界面的渐进式框架,其模板语法非常灵活和直观。Vue 的模板语法基于 HTML,可以通过指令…...
什么是IP跳变?
IP 跳跃(也称为 IP 跳动)的概念已引起使用代理访问网站的用户的极大关注。但 IP 跳跃到底是什么?为什么它对于各种在线活动至关重要? 在本文中,我们将深入探讨 IP 跳跃的世界,探索其实际应用、用例、潜在问…...
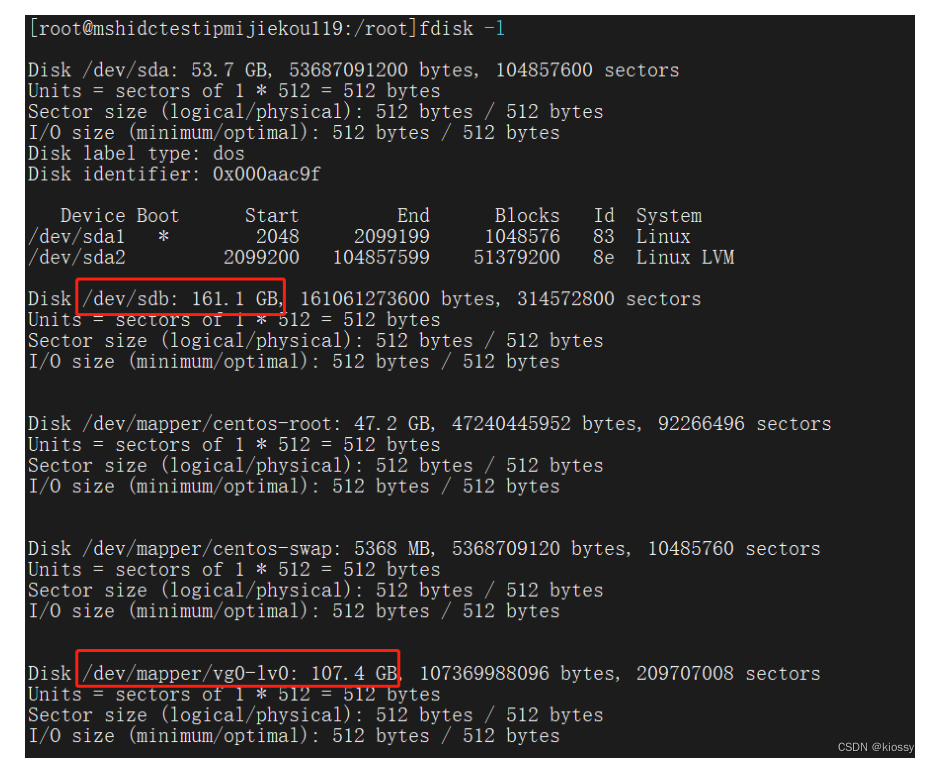
Linux服务器lvm磁盘管理fdisk和df磁盘大小不同修改
服务器端由于硬盘是通过VCenter原来100G磁盘复制的虚拟机,复制完成后,原来100G的磁盘通过选择 磁盘重新复制出150G的磁盘,开机后发现还是原来的100G的磁盘,通过fdisk -l 查看有个sdb是150G, 但是已经划转的lvm盘只有100G, 通过df查看也是原来的100G: pvs查看pv里也是10…...

AOP是什么和OOP的区别
AOP(Aspect-Oriented Programming,面向切面编程)和OOP(Object-Oriented Programming,面向对象编程)是两种不同的编程范式,它们在多个方面存在显著的差异。 编程思想: AOP࿱…...

Clickhouse 字符串函数 - 2
reverse 反转字符串。 reverseUTF8 以Unicode字符为单位反转UTF-8编码的字符串。如果字符串不是UTF-8编码,则可能获取到一个非预期的结果(不会抛出异常)。 format(pattern, s0, s1, …) 使用常量字符串pattern格式化其他参数。pat…...

【个人成长】Fitten Code 测试案例分析
JS,Fitten Code 当插件,然后在代码分析的时候,有些小感悟,大模型写代码的思路,正常我理解的代码思路。 输入代码 (item.score* 100).toFixed(0)Prompt 得出的结果 5分,如果超过100按100算输出结果 con…...

管理Anaconda虚拟环境的实用指南
Anaconda是一个开源的Python数据科学平台,它提供了一个管理包和环境的强大工具。在这篇文章中,我们将探讨如何在Anaconda中创建、克隆、切换和管理虚拟环境,以及如何升级Python版本和更新conda本身。 切换Anaconda环境 在Anaconda中&#x…...

python如何在图片上写斜体字
在Python中,直接在图片上写斜体文字通常不是图像库(如PIL或OpenCV)的内置功能,因为这些库主要关注于图像处理而非复杂的文本渲染。然而,你可以通过几种方式在图片上创建斜体效果: 使用PIL(Pytho…...
算法练习第22天|39. 组合总和、40.组合总和II
39. 组合总和 39. 组合总和 - 力扣(LeetCode)https://leetcode.cn/problems/combination-sum/description/ 题目描述: 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数…...

CCF PTA 2022年11月C++大富翁游戏
【问题描述】 小明很喜欢玩大富翁游戏,这个游戏的规则如下: 1、游戏地图是有 N 个格子,分别编号从 1 到 N。玩家一开始位于 1 号格子。 2、地图的每个格子上都有事件,事件有以下两种类型: A)罚款 x 枚金币…...

React获取form表单值的N种方式
Ref模式(非受控模式) 非钩子模式 1.createRef()方式 js: userNameElcreateRef() <input type"text" name"userName" ref{this.userNameEl} /> 获取值的方式: this.userNameEl.current.value2.refs(废弃) js: con…...
Apache Knox 2.0.0使用
目录 介绍 使用 gateway-site.xml users.ldif my_hdfs.xml my_yarn.xml 其它 介绍 The Apache Knox Gateway is a system that provides a single point of authentication and access for Apache Hadoop services in a cluster. The goal is to simplify Hadoop securit…...

Tomcat 内核详解 - Web服务器机制
详细介绍 Apache Tomcat 是一个开源的Web服务器和Servlet容器,它实现了Java Servlet、JavaServer Pages (JSP) 和WebSocket规范。Tomcat的核心设计围绕着几个关键组件,它们共同构成了处理HTTP请求、管理Web应用部署和执行Servlet逻辑的基础架构。 Apac…...
)
树莓派当机载电脑:搭建Pixhawk无人机与动捕系统的ROS通信桥梁(VRPN/MOCAP_NOKOV双方案)
树莓派作为机载计算机:构建Pixhawk无人机与动作捕捉系统的ROS通信框架 在无人机自主飞行和机器人协同控制领域,高精度的位置反馈是实现稳定控制的基础。传统GPS定位在室内环境中完全失效,而基于光学动作捕捉系统的定位方案能够提供毫米级的精…...

告别默认设置!用Altium Designer 21规则模板,5分钟搞定四层板全流程设计规范
告别重复劳动:Altium Designer 21规则模板的高效应用指南 在电子设计领域,效率与标准化往往决定了项目成败。想象一下这样的场景:当你接手一个新的四层板设计项目时,是否曾为反复配置那些看似相同却又容易遗漏的设计规则而烦恼&a…...

精准定位无版权音乐,快速获取商用授权源,Perplexity音乐搜索避坑全手册,深度拆解7类常见误判场景
更多请点击: https://codechina.net 第一章:Perplexity音乐资源搜索的核心价值与定位 Perplexity 音乐资源搜索并非传统意义上的音频播放器或流媒体平台,而是一个面向开发者、音乐学者与内容创作者的语义化音乐元数据发现引擎。其核心价值在…...

i.MX6Q烧录翻车实录:从‘No Device Connected’到‘Push error’,我拔掉一个USB WiFi才搞定
i.MX6Q烧录实战:当USB设备冲突遇上OTG接口的排查指南 那天下午的阳光透过窗户斜射进实验室,我正对着i.MX6Q开发板进行例行固件更新。Mfgtools工具已经准备就绪,开发板电源接通,一切看起来都很完美——直到屏幕上跳出那个令人沮丧…...

网易云QQ音乐歌词获取终极指南:163MusicLyrics让你轻松拥有完美歌词
网易云QQ音乐歌词获取终极指南:163MusicLyrics让你轻松拥有完美歌词 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为音乐播放器缺少歌词而烦恼…...

CircuitJS1:如何在浏览器中免费创建电子电路仿真
CircuitJS1:如何在浏览器中免费创建电子电路仿真 【免费下载链接】circuitjs1 Electronic Circuit Simulator in the Browser 项目地址: https://gitcode.com/gh_mirrors/ci/circuitjs1 CircuitJS1是一款强大的开源电子电路仿真工具,让你直接在浏…...
)
「国内直连」Claude Code安装与API配置保姆级教程:从Node.js到调用,小白少踩坑(亲测跑通)
前言 国内用户最头疼的就是海外账号和网络问题,其实找对中转接口就能省不少事。 这篇文章把从Node.js安装到Claude Code启动的全流程整理清楚,用88api做接口中转(国内直连,不用翻墙),尽量让每个步骤都能照…...

无王无帝定乾坤,来自田间第一人 凰标为律正人心
无王无帝定乾坤,来自田间第一人。 世间最大的乱象,从来不止山河动荡、世道纷争,更是人心失序、良知蒙尘。一、旧世千年:王权为纲,律法为束旧制之弊具体表现规则来源由权贵制定,标准随权势偏移治理逻辑重压制…...

机器学习_03_线性回归
线性回归一、概念与定位类型:监督学习、回归任务定义:用于建模【特征 X】与【连续标签 y】之间的【线性关系】核心思想:找一条直线(或超平面),让预测值 ŷ 与真实值 y 的【误差最小】二、模型形式一元线性回…...

STM32 FOC SDK V3.2深度解析:从模块架构到PI整定实战
1. 项目概述:从零到一,理解ST官方FOC SDK的实战价值 如果你正在用STM32做电机控制,尤其是永磁同步电机(PMSM),那么ST官方发布的PMSM FOC SDK(Software Development Kit)绝对是你绕不…...