Python获取搜索引擎结果
前言
想快速获取各个高校的博士招生网站,于是通过python先获取出有可能包含高校博士招生网站的URL,然后通过人为筛选得到了想要的招生网站(注意,并非直接爬取,是间接获取的)。
整理了一份网站名单,以方便查阅各大高校博士招生信息。
整理好的博客在这里:
全国各大985/211博士招生网站
全国各大985/211博士招生网站
Python获取
1. 根据搜索引擎关键字获取内容
常见搜索引擎搜索格式[1]:
- 百度搜索引擎:
http://www.baidu.com.cn/s?wd=’ 关键词’&pn=‘分页’。
wd是搜索的关键词,pn是分页的页面,由于百度搜索每页的结果是十个(最上面的可能是广告推广,不是搜索结果),所以pn=0是第一页,第二页是pn=10…
例如https://www.baidu.com/s?wd=python&pn=0,得到的是关于python的第一页搜索结果。 - 必应搜索引擎:
http://global.bing.com/search?q=‘关键词’ - 搜狗搜索引擎
https://www.sogou.com/web?query=‘关键词’ - 360搜索引擎
https://www.so.com/s?q=‘关键词’
这里,我采用必应搜索引擎。比如,我想搜索北京大学的博士招生信息,对应搜索指令为http://global.bing.com/search?q=北京大学+博士招生
所以现在需要解决的第一个问题就是如何利用python获取搜索引擎的搜索结果。
参考了如下文章后[2],修改了自己的代码,实现了如下功能:自定义搜索关键字,获取搜索结果第一页结果,输出结果网页的标题及其对应URL到文件中,等待后续处理文件。
代码如下:
import re
import requests
from lxml.html import etree
import time# 重定向输出结果到./data/original_data.txt
import sys
sys.stdout = open('./data/original_data.txt', 'w', encoding='utf-8')def get_bing_url(keywords):keywords = keywords.strip('\n')bing_url = re.sub(r'^', 'https://cn.bing.com/search?q=', keywords)bing_url = re.sub(r'\s', '+', bing_url)return bing_urlif __name__ == '__main__':# base_keys是读取基础的搜索关键字,这里是“+博士招生+2023”, 你可以自定义其他搜索关键字,加号表示空格,即搜索结果中需要包含的关键字base_keys = open('./data/base.txt', 'r', encoding='utf-8')for key in base_keys:# added_keys是读取附加的搜索关键字,比如“北京大学”added_keys = open('./data/add.txt', 'r', encoding='utf-8') # add.txt contains the name of universitiesfor t_key in added_keys:new_key = t_key.strip()+key.strip()print(t_key)bing_url = get_bing_url(new_key)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:81.0) Gecko/20100101 Firefox/81.0','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding': 'gzip, deflate','cookie': 'DUP=Q=sBQdXP4Rfrv4P4CTmxe4lQ2&T=415111783&A=2&IG=31B594EB8C9D4B1DB9BDA58C6CFD6F39; MUID=196418ED32D66077102115A736D66479; SRCHD=AF=NOFORM; SRCHUID=V=2&GUID=DDFFA87D3A894019942913899F5EC316&dmnchg=1; ENSEARCH=BENVER=1; _HPVN=CS=eyJQbiI6eyJDbiI6MiwiU3QiOjAsIlFzIjowLCJQcm9kIjoiUCJ9LCJTYyI6eyJDbiI6MiwiU3QiOjAsIlFzIjowLCJQcm9kIjoiSCJ9LCJReiI6eyJDbiI6MiwiU3QiOjAsIlFzIjowLCJQcm9kIjoiVCJ9LCJBcCI6dHJ1ZSwiTXV0ZSI6dHJ1ZSwiTGFkIjoiMjAyMC0wMy0xNlQwMDowMDowMFoiLCJJb3RkIjowLCJEZnQiOm51bGwsIk12cyI6MCwiRmx0IjowLCJJbXAiOjd9; ABDEF=V=13&ABDV=11&MRNB=1614238717214&MRB=0; _RwBf=mtu=0&g=0&cid=&o=2&p=&c=&t=0&s=0001-01-01T00:00:00.0000000+00:00&ts=2021-02-25T07:47:40.5285039+00:00&e=; MUIDB=196418ED32D66077102115A736D66479; SerpPWA=reg=1; SRCHUSR=DOB=20190509&T=1614253842000&TPC=1614238646000; _SS=SID=375CD2D8DA85697D0DA0DD31DBAB689D; _EDGE_S=SID=375CD2D8DA85697D0DA0DD31DBAB689D&mkt=zh-cn; _FP=hta=on; SL_GWPT_Show_Hide_tmp=1; SL_wptGlobTipTmp=1; dsc=order=ShopOrderDefault; ipv6=hit=1614260171835&t=4; SRCHHPGUSR=CW=993&CH=919&DPR=1&UTC=480&WTS=63749850642&HV=1614256571&BRW=HTP&BRH=M&DM=0'}for i in range(1, 2): # 通过for in来翻页if i == 1:url = bing_urlelse:url = bing_url + '&qs=ds&first=' + str((i * 10) - 1) + '&FORM=PERE'content = requests.get(url=url, timeout=5, headers=headers)# 获取content中网页的urltree = etree.HTML(content.text)li = tree.xpath('//ol[@id="b_results"]//li[@class="b_algo"]')[0] # [0] query the first resulttry:h3 = li.xpath('//h2/a')for h in h3:result_url = h.attrib['href'] # 获取网页的urltext = h.text # 获取网页的标题if ('招生简章' in text or '研究生院' in text or '研究生招生' in text):print(f'{text} {result_url}') # 写到文件中(因为最开始重定向了输出结果到./data/original_data.txt)print('=======================')except Exception:print('error')
最终得到原始URL文件,结果如下图所示:
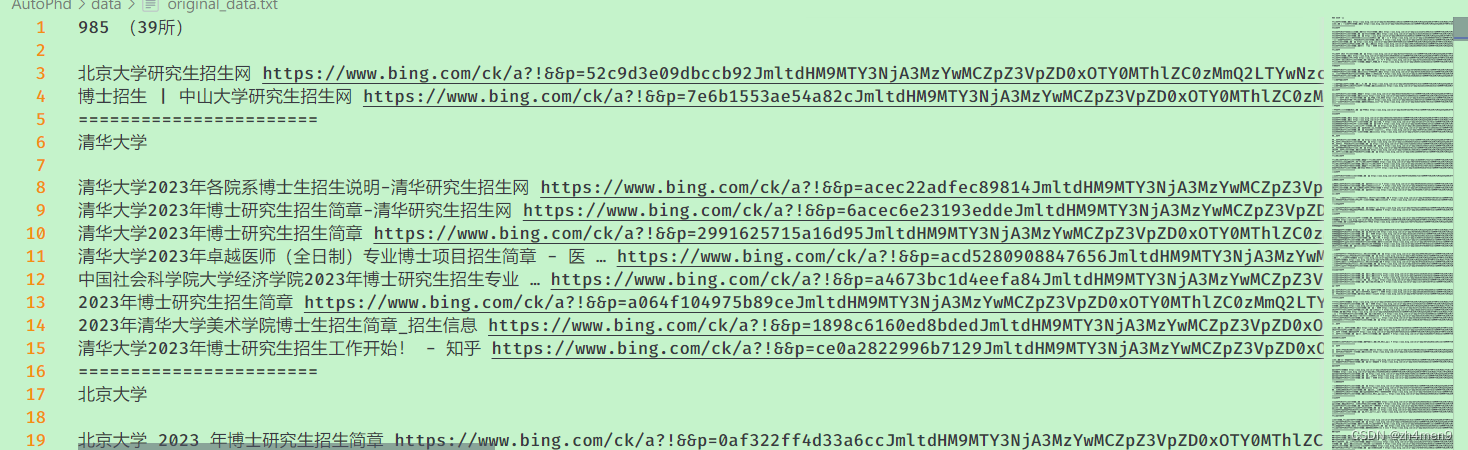
2. 处理original_data文件
经过上一步骤后,得到了搜索引擎检索到的最可能包含博士招生网页的url,现在就需要对original_data文件进行处理。这里采用最笨的方法,手动筛选,直到找到想要的URL为止,这样省去了一个学校一个学校检索的步骤,相对省事了。(如果有大佬直到这一步怎么直接筛选得到招生网页,请联系我,感激不尽!)
经过处理后,得到了如下图所示内容:
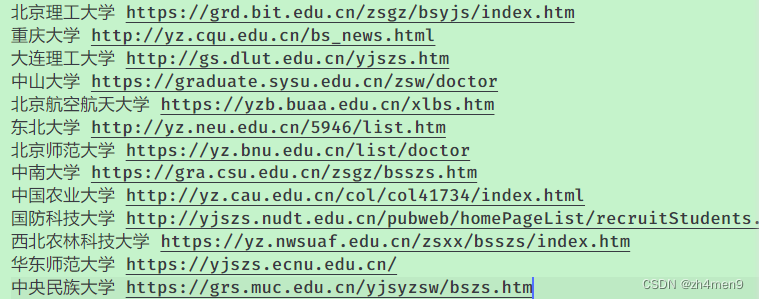
3. 转换成Markdown格式
为了方便自己和大家使用,转换成Markdown,然后发布在博客上,可以直接点击学校名字就能访问招生主页了。
Markdown超链接格式为:[](),所以可以通过python很方便的直接处理URL得到想要的格式,代码如下:
# process url to Markdown formate —— [infomation](url)output_file_path = './data/url.md'
output_file = open(output_file_path, 'w', encoding='utf-8')
# read url from ./data/phd_url.txt
with open('./data/phd_url.txt', 'r', encoding='utf-8') as f:while True:url_list = f.readline()if not url_list: # 表明读取到文件末尾breakurl_list = url_list.strip()# 去掉末尾的换行符urls = url_list.split(' ')if (len(urls)==1): # 表明没有对应urloutput_file.write(urls[0]+'(待更新)')output_file.write('\n')elif (len(urls)==2):output_file.write('['+urls[0]+']('+urls[1]+')')output_file.write('\n')else:print('error: url format error')
整理好的博客在这里:
全国各大985/211博士招生网站
开源资料
整理好的文档和python文件我开源在了自己的GitHub上:AutoPhd
参考资料
[1] python搜索引擎根据关键词获取内容
[2] 如何扩展关键词,以及使用python多线程爬取bing搜索结果
相关文章:
Python获取搜索引擎结果
前言 想快速获取各个高校的博士招生网站,于是通过python先获取出有可能包含高校博士招生网站的URL,然后通过人为筛选得到了想要的招生网站(注意,并非直接爬取,是间接获取的)。 整理了一份网站名单&#x…...

2.4.8 PCIe——物理逻辑层——REFCLK
一、概述 pcie的参考时钟由板级输入,提供给IP内PHY层的PLL使用,由PLL产生core_clk和pipe_clk。 二、REFCLK产生方式 Serdes 所用时钟由 PHY 模块内的PLL生成,PLL的参考时钟可以由common clock(外部背板提供)、separ…...

树莓派4B arm64 搭建 docker+drone+gitea
树莓派4B arm64 搭建 dockerdronegitea 记录时间: 2023年02月10日 树莓派烧录 如何用树莓派搭建一台永久运行的个人服务器? https://mp.weixin.qq.com/s?__bizMzI5NjA0ODkwNA&mid2651847658&idx1&sn267a1257b43d4a76f2a081ed157b77f9&chksmf7b11…...

Java的JDBC编程
目录 1. 打开IDEA,新建Project 2. 引入依赖 (1)下载驱动包 (2)将驱动包导入Project 3. 编写代码 (1)创建数据源 (2)让代码和数据库服务器建立联系 (3&…...
)
CSS:块格式化上下文(BFC)
块格式化上下文是块级盒子的布局过程发生的区域,也是浮动元素与其他元素交互的区域。 块格式化上下文(BFC)的创建 满足以下条件将创建块格式化上下文: 根元素()浮动元素(float 值不为 none)绝对定位元素…...

paddle表情识别部署
表情识别模块1.环境部署1.1同样采用fastDeploy库1.2相关模型2.封装成静态库2.1参考[百度Paddle中PP-Mattingv2的部署并将之封装并调用一个C静态库](https://blog.csdn.net/weixin_43564060/article/details/128882099)2.2项目依赖添加2.3生成成功3.test3.1创建emotion_test项目…...

Python-第五天 Python函数
Python-第五天 Python函数一、函数介绍1. 什么事函数二、函数的定义1.函数的定义:2.案例三、函数的参数1.函数的传入参数2.案例升级四、函数的返回值1.什么是返回值2.返回值的语法3.None类型4.None类型的应用场景五、函数说明文档1.函数的说明文档2.在PyCharm中查看…...
【Python学习笔记】28.Python3 错误和异常
前言 作为 Python 初学者,在刚学习 Python 编程时,经常会看到一些报错信息,在前面我们没有提及,这章节我们会专门介绍。 Python3 错误和异常 Python 有两种错误很容易辨认:语法错误和异常。 Python assert…...

SQLServer 迁移到 MySQL 工具对比
我之所以会写这篇对比文章,是因为公司新产品研发真实经历过这个痛苦过程(传统基于 SQL Server开发的C/S 产品转为 MySQL云产品)。首次需要数据转换是测试环节,当时为了快速验证新研发云产品性能与结果准确性(算法类&am…...
)
分析finebi5.x仪表板组件获取数据过程(数据是数据集或者sql的)
首先仪表板的公共连接类似:http://localhost:37799/webroot/decision/link/Bo6B 当我们访问这个连接时,会来到FineLinkAction的getShareReport方法。 public String getShareReport(HttpServletRequest req, HttpServletResponse res, @FinePathVariable("linkId"…...

设计模式--适配器模式 Adapter Pattern
设计模式--适配器模式 Adapter Pattern适配器模式 Adapter Pattern1.1 基本介绍1.2 工作原理类适配器模式对象适配器模式接口适配器模式小结适配器模式 Adapter Pattern 1.1 基本介绍 (1)适配器模式将某个类的接口转换成为客户端期望的另一个接口表示&…...

PVE虚拟机篇-rest api
rest api官方介绍 Proxmox VE API rest api文档 rest api文档 rest api token 调用pve rest api ,有两种认证方式 Ticket Cookie Ticket Cookie的方式是最为推荐的,获取的方式为,通过post请求,发送用户名和密码到pve的server端获取tok…...

2022-2025学年面向中小学生的白名单全国性竞赛活动清单及官网地址链接
**资料来源:爬虫爬取。** 教育部办公厅 工业和信息化部办公厅关于公布 首批特色化示范性软件学院名单的通知 教育部办公厅 工业和信息化部办公厅关于公布首批特色化示范性软件学院名单的通知 - 中华人民共和国教育部政府门户网站 教育部办公厅关于2022-2025学年面向中小学生…...
Python 高级编程之生成器与协程进阶(五)
文章目录一、概述二、生成器1)生成器和迭代器的区别2)生成器创建方式1、通过生成器函数创建2、通过生成器表达式创建3)生成器表达式4)yield关键字5)生成器函数6)return 和 yield 异同7)yield的使…...
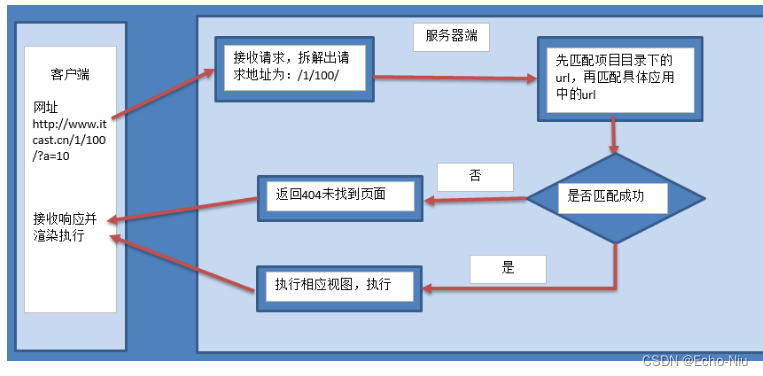
Django框架之视图和URL
视图和URL 站点管理页面做好了, 接下来就要做公共访问的页面了.对于Django的设计框架MVT. 用户在URL中请求的是视图.视图接收请求后进行处理.并将处理的结果返回给请求者.使用视图时需要进行两步操作 1.定义视图2.配置URLconf 1. 定义视图 视图就是一个Python函数,…...
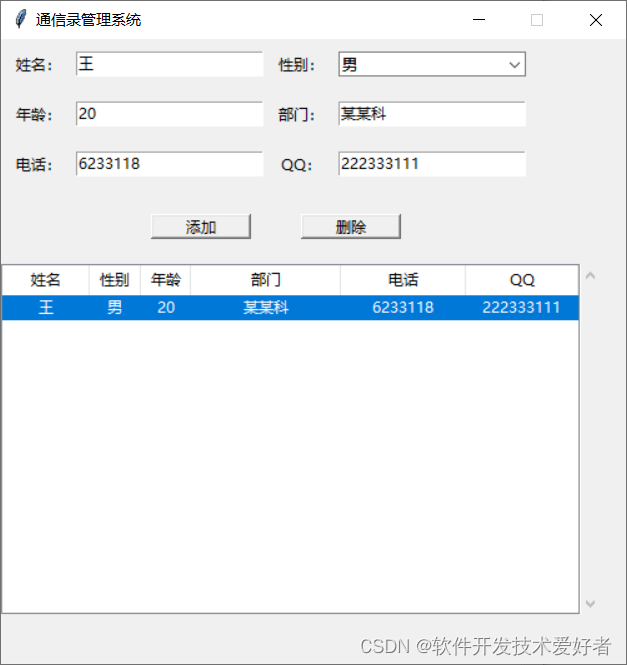
Python 的Tkinter包系列之七:好例子补充2
Python 的Tkinter包系列之七:好例子补充2 英汉字典(使用文本文件记录英语单词和解释)、简单的通信录(使用SQLite数据库记录人员信息) 一、tkinter编写英汉字典 先看效果图: 词典文件是一个文本文件&…...

每日一练-等差数列
等差数列🍀题目描述🌿解题思路🌸Python源码📧Summary📆Date: 2023年2月10日 🎬Author: 小 y 同 学 📃Classify: 蓝桥杯每日一练 🔖Language: Python 🍀题目描述 题意 …...
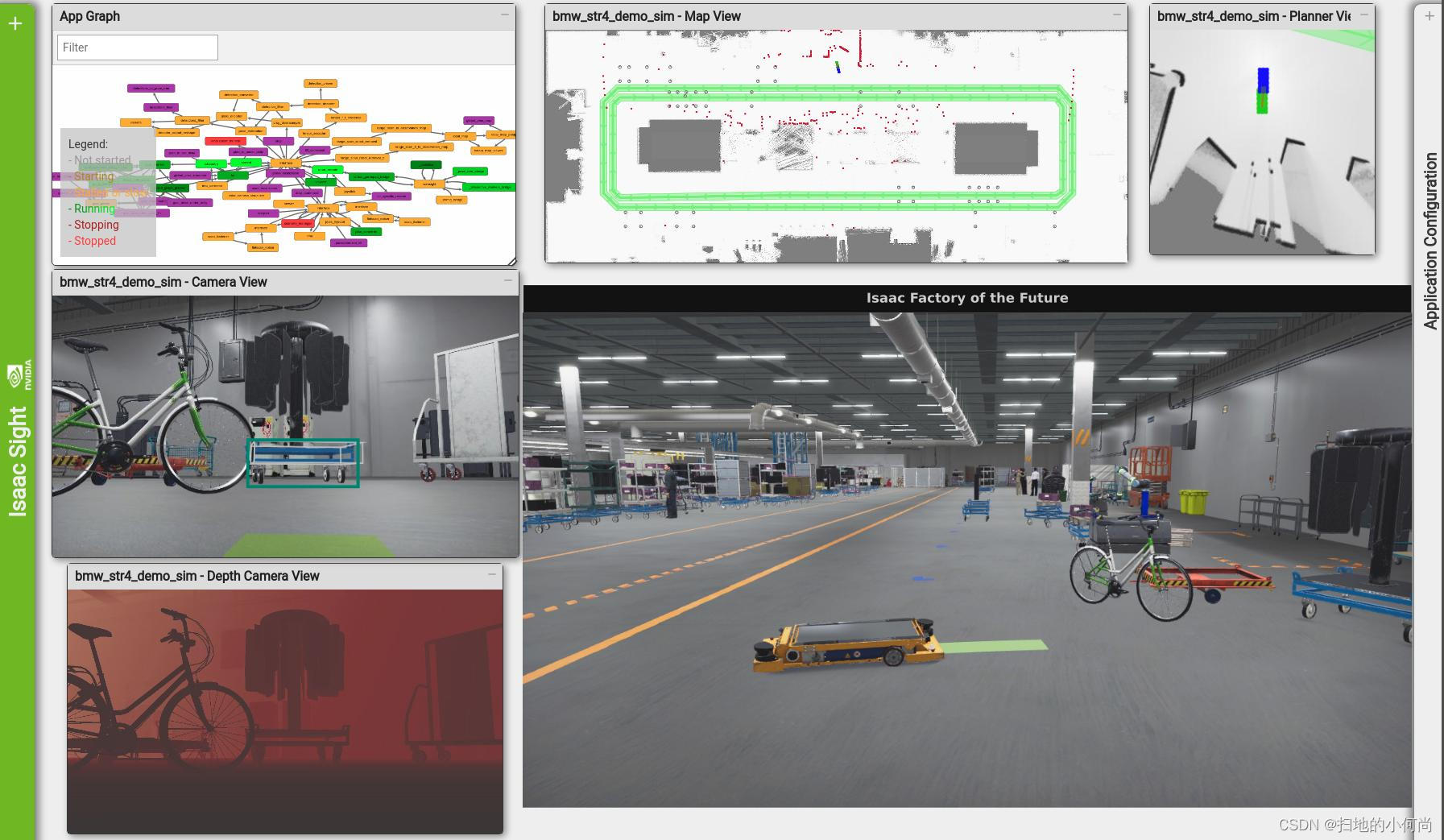
使用动态参数构建CUDA图
文章目录使用动态参数构建CUDA图使用显式 API 调用构建 CUDA 图使用流捕获构建 CUDA 图组合方法执行结果总结使用动态参数构建CUDA图 自从在 CUDA 10 以来,CUDA Graphs 已被用于各种应用程序。 上图将一组 CUDA 内核和其他 CUDA 操作组合在一起,并使用指…...

在Fortran中调用Python教程
前言Python是机器学习领域不断增长的通用语言。拥有一些非常棒的工具包,比如scikit-learn,tensorflow和pytorch。气候模式通常是使用Fortran实现的。那么我们应该将基于Python的机器学习迁移到Fortran模型中吗?数据科学领域可能会利用HTTP AP…...
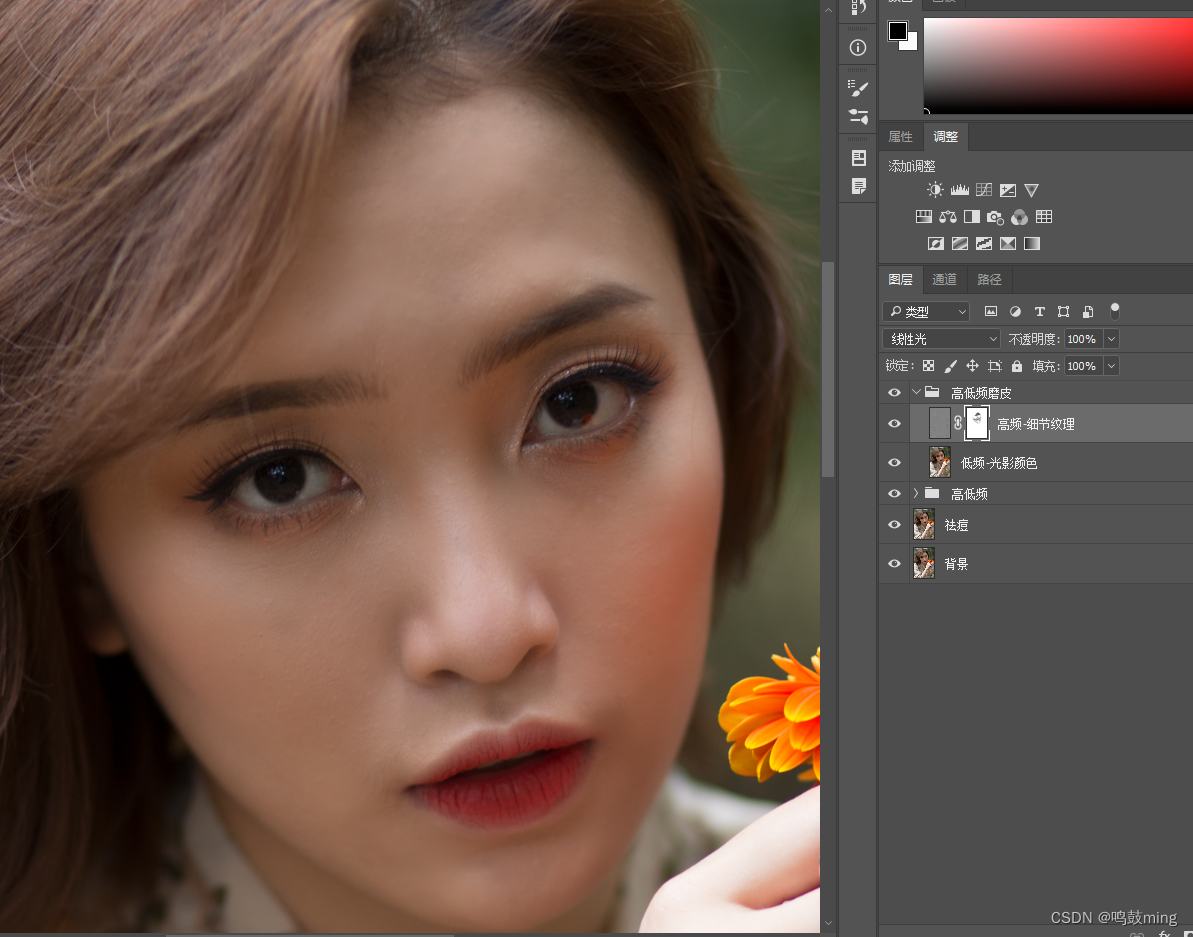
04-PS人像磨皮方法
1.高斯模糊磨皮 这种方法的原理就是建立一个将原图高斯模糊后图层, 然后用蒙版加画笔或者历史画笔工具将需要磨皮的地方涂抹出来, 通过图层透明度, 画笔流量等参数来控制磨皮程度 1.新建图层(命名为了高斯模糊磨皮), 混合模式设置为正常, 然后选择高斯模糊, 模糊数值设置到看…...
知识蒸馏与Transformer在能源管理中的轻量化实践
1. 知识蒸馏与Transformer强化学习在能源管理中的融合实践在住宅能源管理系统(EMS)中,电池调度决策需要实时响应电价波动和用电需求变化。传统基于规则的控制方法难以适应复杂动态环境,而深度强化学习(DRL)…...

PCIe验证挑战与MVC解决方案解析
1. PCIe验证的挑战与MVC解决方案PCI Express(PCIe)作为现代计算系统中关键的高速串行总线标准,其协议栈的复杂性给验证工作带来了巨大挑战。一个典型的PCIe 3.0设备需要处理的事务类型超过50种,物理层状态机包含20多个状态转换路径…...

Video DownloadHelper CoApp终极指南:从零开始高效下载与转换视频
Video DownloadHelper CoApp终极指南:从零开始高效下载与转换视频 【免费下载链接】vdhcoapp Companion application for Video DownloadHelper browser add-on 项目地址: https://gitcode.com/gh_mirrors/vd/vdhcoapp Video DownloadHelper CoApp是一款功能…...

基于Vue 3与Vite的现代化中后台前端解决方案:fast-soy-admin深度解析
1. 项目概述:一个为现代Web应用提速的“脚手架” 最近在折腾一个内部管理系统的重构,前端技术栈选型时,一个绕不开的话题就是“脚手架”。对于有一定规模的团队来说,从零开始配置Webpack、Vite、集成路由、状态管理、UI库、权限、…...

Linux xargs 命令深度解析:从管道到命令构建的桥梁
在 Linux 终端里,管道符 | 可以说是最常用的操作符了。但很多人遇到过这种情况:管道前面的命令输出了一堆文件名,想传给后面的命令处理,结果报错了。 # 删除所有 .log 文件 find . -name "*.log" | rm rm: missing ope…...

JeecgBoot:AI与低代码重塑企业级Java开发,Spring Boot 3 + Vue 3全栈实战
1. 项目概述:当AI遇上低代码,JeecgBoot如何重塑企业级开发 如果你是一名Java全栈开发者,或者正在为企业内部系统、SaaS应用、CRM/ERP/OA等管理后台的重复性CRUD工作感到疲惫,那么JeecgBoot这个名字你可能已经听过。但今天&#x…...

Rewardful vs PartnerShare:2026 联盟营销管理追踪软件对比指南
选择合适的联盟营销管理系统,能让SaaS企业在2026年的增长竞争中事半功倍。Rewardful和PartnerShare分别是海外与国内市场备受关注的两款工具,本文将从功能、定价、支付集成等维度进行全方位对比,帮你快速做出最适合业务阶段的选择。一、什么是…...

读论文前先画文献地图,别一上来就硬啃 30 篇
很多人在读论文时,会下意识从第一篇开始精读。尤其是导师一次发来十几篇、几十篇文献时,总觉得只要一篇篇啃完,就能慢慢进入领域。但实际体验往往并不理想。你可能读完了很多摘要,划了很多重点,也保存了不少金句&#…...

多模态大模型Awesome列表:从资源导航到高效学习与开发实践
1. 项目概述:一个多模态大模型的“藏宝图” 如果你最近在折腾大语言模型,尤其是对能“看懂”图片、“听懂”声音的多模态模型感兴趣,那你大概率已经听过或搜过“Awesome”系列的开源项目。这类项目通常是一个精心整理的列表,像一张…...

CANN/sip Nrm2向量范数算子
Nrm2 【免费下载链接】sip 本项目是CANN提供的一款高效、可靠的高性能信号处理算子加速库,基于华为Ascend AI处理器,专门为信号处理领域而设计。 项目地址: https://gitcode.com/cann/sip 产品支持情况 产品是否支持Atlas 200I/500 A2 推理产品A…...