高并发缓存服务的构建要点与陷阱
1. 缓存基础与特征
在讨论高并发环境下构建缓存服务的问题前,我们需要先了解缓存的基础和特征。缓存(Cache)是一种高速数据存储层,它可以存储临时数据,以便将来的请求能更快地获取到这些数据。从本质上讲,缓存是一种数据复制技术,旨在提高数据访问速度,减少后端系统的负载。
1.1 缓存的定义
缓存是在软件架构中非常关键的部分,尤其是在需要处理高并发、大量数据读取的场景下。一般而言,缓存会存储应用程序最频繁访问的数据。这些数据可以是静态的,比如HTML页面、图片、视频等;也可以是动态生成的,如数据库查询结果。
1.2 缓存的主要特征
- 访问速度: 缓存存储是基于内存的,因此访问速度远快于磁盘存储。
- 数据时效性: 缓存中的数据可能不是最新的,需要合理的策略来维护数据的时效性。
- 资源有限: 相对于后端的数据存储系统,缓存资源通常较少,需要有效地利用可用空间。
1.3 缓存的作用和优势
缓存的主要目的是减少对原始数据源的直接访问,从而降低延迟和负载。这种间接访问的方式可以带来以下几个优势:
- 提高应用性能: 通过减少数据访问的延迟,缓存可以显著提高应用程序的运行效率。
- 降低后端负担: 缓存在满足大部分读取请求的条件下,可以显著减少数据库或文件系统的压力。
- 提高用户体验: 快速响应的应用程序可以提高用户的满意度和粘性。
2. 缓存命中率的影响因素
缓存命中率是衡量缓存效能的重要指标之一,它决定了缓存对后端数据存储的访问压力以及整体系统性能的优化程度。理解影响缓存命中率的因素,有助于我们构建更高效的缓存策略。
2.1 缓存设计的策略与算法
- 淘汰策略: 如LRU(最近最少使用)、FIFO(先进先出)等,影响数据在缓存中停留的时间。
- 一致性哈希: 减少缓存集群中节点变更带来的缓存失效问题。
- 请求合并: 等待短时间内的多个相同请求,一次性从后端获取数据并更新缓存,减少访问后端的次数。
2.2 数据访问模式对命中率的影响
- 读写比例: 高读取比例的应用更适合使用缓存。
- 数据更新频率: 高频更新的数据可能不适合缓存,或者需要特殊的处理策略。
- 数据热度分布: 识别和优化访问热点,避免热点集中造成的缓存命中率下降。
2.3 网络和存储系统性能的影响
- 网络延迟: 跨网络请求数据会导致缓存更新延迟,影响命中率。
- 存储性能: 后端存储的I/O性能直接影响缓存填充的速度。
3. 提高缓存命中率的策略
提高缓存命中率对于优化系统性能和用户体验至关重要。以下是一些有效的策略和方法。
3.1 数据预加载和预热
预加载是在系统启动时预先将数据加载到缓存中的策略,而预热是指在数据被实际需要之前,根据预测模式将其加载到缓存中。
- 使用背景任务定期检查并更新热点数据。
- 根据历史访问模式,预测并加载可能成为热点的数据。
- 在发布新版本或进行系统维护后,重新加载关键数据到缓存中。
3.2 缓存粒度的调整
合理的缓存粒度可以提高存储效率和命中率。
- 精细化缓存可以减少不必要的数据加载,但会增加维护成本。
- 粗粒度缓存利于管理,但可能引入无关数据,浪费缓存空间。
- 根据业务需要,动态调整缓存粒度。
3.3 缓存依赖和数据一致性管理
处理缓存依赖关系和确保数据一致性对缓存系统是一项挑战。
- 采用消息队列等技术,当数据发生变更时,异步更新相关缓存。
- 规定数据一致性级别,按需使用强一致性或最终一致性策略。
- 设计多级缓存系统,如一级为热点数据缓存,二级为常规缓存,有效分担数据一致性的压力。
4. 缓存的分类与应用场景
缓存可以根据存储位置、管理方式和范围等因素被分类。各种类型的缓存在不同的应用场景中表现出独特的效能和作用。
4.1 本地缓存和分布式缓存
本地缓存通常存在于单个系统或服务中,易于管理,响应速度快,但在分布式系统中容易出现数据不一致。
分布式缓存则跨多个系统或服务,可以支持更大规模的数据和高并发访问,但实现更复杂,需要处理数据同步与一致性问题。
4.2 缓存的常见形态:内存缓存、文件缓存、数据库级缓存
- 内存缓存,如Redis、Memcached,实现快速访问,适合频繁读写的场景。
- 文件缓存,将数据存储于文件系统中,相对简单,但速度慢于内存缓存。
- 数据库级缓存,如MySQL的Query Cache,用于缓存查询结果,减少对数据库的直接访问。
4.3 不同业务场景下的缓存应用实例
- 电商平台中,用于商品信息、价格展示的快速访问。
- 社交网络,缓存用户的时间线和动态内容。
- 实时数据分析,缓存频繁查询和计算的结果,提高数据处理能力。
5. 高并发场景下缓存面临的挑战
在高并发的生产环境中,缓存服务需要面对多种挑战,这些挑战可能会严重影响应用的性能和稳定性。以下是一些常见问题以及应对策略。
5.1 缓存穿透与雪崩效应
缓存穿透现象指的是查询不存在的数据导致请求直接到达数据库,可以通过布隆过滤器或空对象缓存机制来预防。
缓存雪崩是指当缓存服务不可用或大量缓存同时失效时,所有的请求都会落到数据库上,造成数据库压力急剧增大。应对策略包括设置不同的数据过期时间、使用熔断限流机制等。
5.2 热点数据处理
在高并发场景中,某些键值对可能会成为热点数据被频繁访问。可以利用复制、分片技术或引入更多层级的缓存来分散对热点数据的访问压力。
5.3 缓存的伸缩性与容错性
缓存服务必须能够水平扩展来响应不断增长的负载,并且在某个节点失败时,仍然能保持服务不被中断。这需要缓存架构设计时考虑到集群管理、数据分片和复制。
5.4 微服务环境下的缓存架构考量
在微服务架构中,缓存策略需要适应服务的解耦和动态伸缩。合理的策略可能包括独立缓存服务、API网关层的缓存等策略。
6. 实战经验分享
6.1 缓存系统设计的思路和方法
在对某电商平台的缓存系统进行设计时,阿里P9工程师重视对数据热点的预判和监控。他们采用动态数据分布和负载均衡的方法,保证系统在高流量期间的稳定性。
实战案例
- 动态缓存分片: 为了平衡不同缓存节点的压力,他们实现了自适应缓存分片策略。以下是模拟该策略的简化代码:
// 伪代码示例 - 动态缓存分片策略
public class DynamicCacheSharding {private final ConcurrentHashMap<String, String> cacheData = new ConcurrentHashMap<>();private final List<CacheNode> cacheNodes;public DynamicCacheSharding(List<CacheNode> nodes) {this.cacheNodes = nodes;}public void putData(String key, String value) {CacheNode node = selectNodeForKey(key);node.putData(key, value);}private CacheNode selectNodeForKey(String key) {// 根据某种算法选择合适的节点(例如一致性哈希算法)// 省略具体实现细节}// 缓存节点类static class CacheNode {void putData(String key, String value) {// 这里将数据放入对应的缓存节点}}
}
6.2 缓存问题的实际案例分析
在实际工作中,我也曾遇到一个缓存穿透问题,即大量请求查询不存在的数据,导致对数据库的直接压力剧增。为了解决这个问题,特别实现了一个带有布隆过滤器的缓存层,如下所示:
// 伪代码示例 - 布隆过滤器防止缓存穿透
public class BloomFilterCache {private final BloomFilter<String> filter;private final ConcurrentHashMap<String, String> cacheData = new ConcurrentHashMap<>();public BloomFilterCache() {filter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), expectedInsertions);}public String getData(String key) {if (!filter.mightContain(key)) {return null; // 布隆过滤器中不存在的数据,直接返回null}return cacheData.getOrDefault(key, null);}public void putData(String key, String value) {filter.put(key);cacheData.put(key, value);}
}
6.3 缓存服务的优化和调整策略
当面对热点数据处理问题时,他们采取了引入多级缓存机制,将热点数据依据访问频率放入不同层级的缓存,以此来控制数据加载对后端数据库的影响。
改进措施
- 多级缓存机制: 根据数据的访问频率和更新频率,将数据分配到不同级别的缓存中。热门数据存在于第一级缓存,即内存中,而不那么常访问的数据存储在第二级缓存,如SSD或其他快速存储设备中。
- 热点数据识别与优先级调整: 使用机器学习模型动态识别当前的热点数据,并调整这些数据在缓存中的优先级,以保证高速访问。
以下是模拟多级缓存策略的简化代码示例:
// 伪代码示例 - 多级缓存机制
public class MultiLevelCache {private final CacheLevel firstLevelCache;private final CacheLevel secondLevelCache;public MultiLevelCache(CacheLevel firstLevel, CacheLevel secondLevel) {this.firstLevelCache = firstLevel;this.secondLevelCache = secondLevel;}public String getData(String key) {String data = firstLevelCache.getData(key);if (data == null) {data = secondLevelCache.getData(key);if (data != null) {// 如果第二级缓存有数据,更新到第一级缓存firstLevelCache.putData(key, data);}}return data;}static class CacheLevel {ConcurrentHashMap<String, String> storage = new ConcurrentHashMap<>();public String getData(String key) {return storage.get(key);}public void putData(String key, String value) {storage.put(key, value);}}
}
通过这样的设计,热点数据能够得到更快的响应,同时系统也能防止大量非热点数据请求打压数据库。
相关文章:

高并发缓存服务的构建要点与陷阱
1. 缓存基础与特征 在讨论高并发环境下构建缓存服务的问题前,我们需要先了解缓存的基础和特征。缓存(Cache)是一种高速数据存储层,它可以存储临时数据,以便将来的请求能更快地获取到这些数据。从本质上讲,…...

Electron学习笔记(五)
文章目录 相关笔记笔记说明 七、系统1、系统对话框2、自定义窗口菜单3、系统右键菜单4、快捷键(1)、监听网页按键事件 (窗口需处于激活状态)(2)、监听全局按键事件 (窗口无需处于激活状态)(3)、补充:自定义窗口菜单快捷…...

【jest 调试 - vscode debug】
jest 测试typescript,如果想对测试文件本身断点调试。 安装jest相关依赖 # jest本体 npm install --save-dev jest # jest的类型声明 npm install --save-dev types/jest # typescript中使用 npm install --save-dev ts-jestlaunch.json 配置参考 {"type&qu…...
华为OD机试【分奖金】(java)(100分)
1、题目描述 公司老板做了一笔大生意,想要给每位员工分配一些奖金,想通过游戏的方式来决定每个人分多少钱。按照员工的工号顺序,每个人随机抽取一个数字。按照工号的顺序往后排列,遇到第一个数字比自己数字大的,那么&…...
27- ESP32-S3 USB虚拟串口(USB-OTG 外设介绍)
ESP32-S3 USB虚拟串口详解 USB-OTG 外设介绍 USB-OTG: USB-OTG是一种USB规范,允许嵌入式系统(如手机、平板电脑、单片机系统等)在没有主机(如个人电脑)的情况下直接相互通信,同时也能够作为传…...

PostgreSQL查看sql的执行计划
PostgreSQL查看sql的执行计划 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:5777在PostgreSQL中,查看…...

macOS Ventura 13如何设置定时重启(命令行)
文章目录 macOS Ventura 13如何设置定时重启(命令行)前言具体设置步骤及命令解释其他 macOS Ventura 13如何设置定时重启(命令行) 前言 由于升级 macOS 13 Ventura 之后,之前在节能里面通过鼠标点击设置开机关机的方法不能用了,现在只能用命令设置开机…...

【sass简介以及如何安装使用】
Sass(Syntactically Awesome Stylesheets)是一个层叠样式表(CSS)预处理器,它扩展了CSS的语法,并增加了许多有用的功能,如变量、嵌套、混合(Mixin)、继承以及模块化的结构…...
)
Git版本控制工具的原理及应用详解(四)
本系列文章简介: 随着软件开发的复杂性不断增加,版本控制成为了开发团队中不可或缺的工具之一。在过去的几十年里,版本控制工具经历了各种发展和演变,其中Git无疑是目前最受欢迎和广泛应用的版本控制工具之一。 Git的出现为开发者…...

AI图书推荐:ChatGPT全面指南—用AI帮你更健康、更富有、更智慧
你是否在努力改善你的健康? 你是否长期遭受财务困难? 你想丰富你的思想、身体和灵魂吗? 如果是这样,那么这本书就是为你准备的。 《ChatGPT全面指南—用AI帮你更健康、更富有、更智慧》(CHATGPT Chronicles AQuick…...
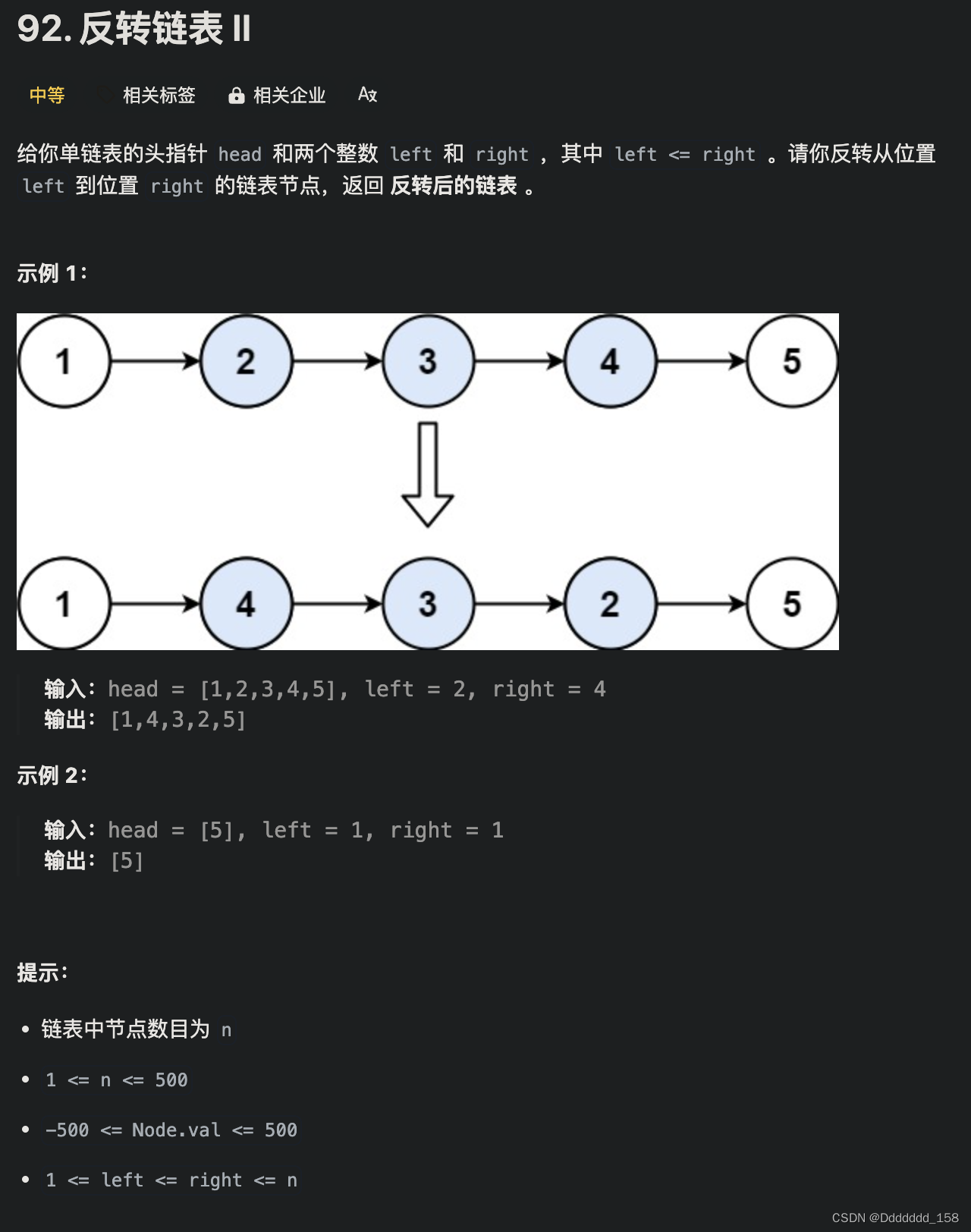
C++ | Leetcode C++题解之第92题反转链表II
题目: 题解: class Solution { public:ListNode *reverseBetween(ListNode *head, int left, int right) {// 设置 dummyNode 是这一类问题的一般做法ListNode *dummyNode new ListNode(-1);dummyNode->next head;ListNode *pre dummyNode;for (i…...
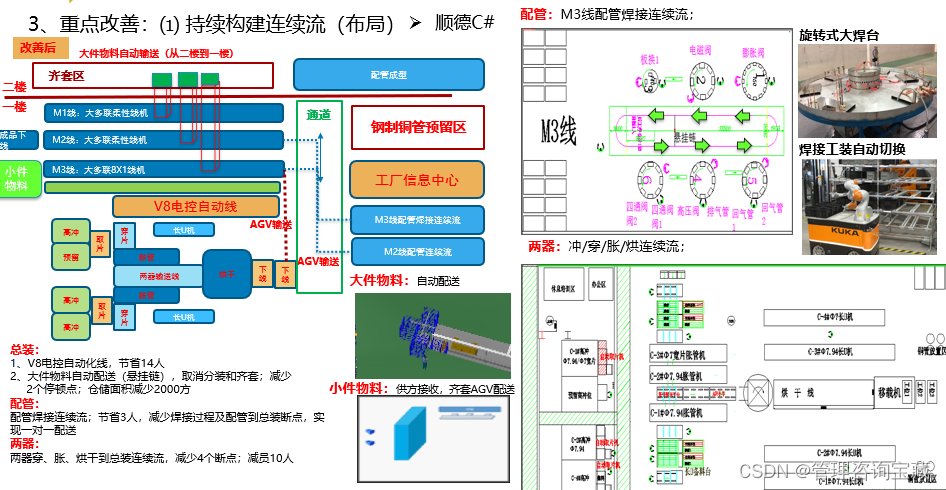
【管理咨询宝藏99】离散制造智能工厂战略规划方案
本报告首发于公号“管理咨询宝藏”,如需阅读完整版报告内容,请查阅公号“管理咨询宝藏”。 【管理咨询宝藏99】离散制造智能工厂战略规划方案 【格式】PDF版本 【关键词】智能制造、先进制造业转型、数字化转型 【核心观点】 - 推进EHS、品质一致性、生…...

java8 Stream使用中的一些实践
文章目录 使用Stream将List转换为Map时key冲突问题使用Stream时得到List的size为不为0,元素Object为null问题 使用Stream将List转换为Map时key冲突问题 如下: 把userList转换为userMap id为key user 为value 由于user2和user3的id相同,所以会…...

入门篇:Kafka基础知识·
目录 一、Kafka简介 二、Kafka核心组件 三、Kafka安装与配置 1.下载与解压 2.配置环境变量 3.配置server.properties 4.启动Kafka服务 四、Kafka基本操作 1.创建Topic 2.查看Topic列表 3.发送消息 4.接收消息 五、Kafka进阶使用 1.消息持久化与存储 2.消息顺序与…...
SWAT模型高阶应用暨SWAT模型无资料地区建模、不确定分析及气候、土地利用变化对水资源与面源污染影响分析
原文链接:SWAT模型高阶应用暨SWAT模型无资料地区建模、不确定分析及气候、土地利用变化对水资源与面源污染影响分析https://mp.weixin.qq.com/s?__bizMzUzNTczMDMxMg&mid2247604401&idx4&snd2d39846dce07bee765c820de1cf92f3&chksmfa821956cdf5904…...
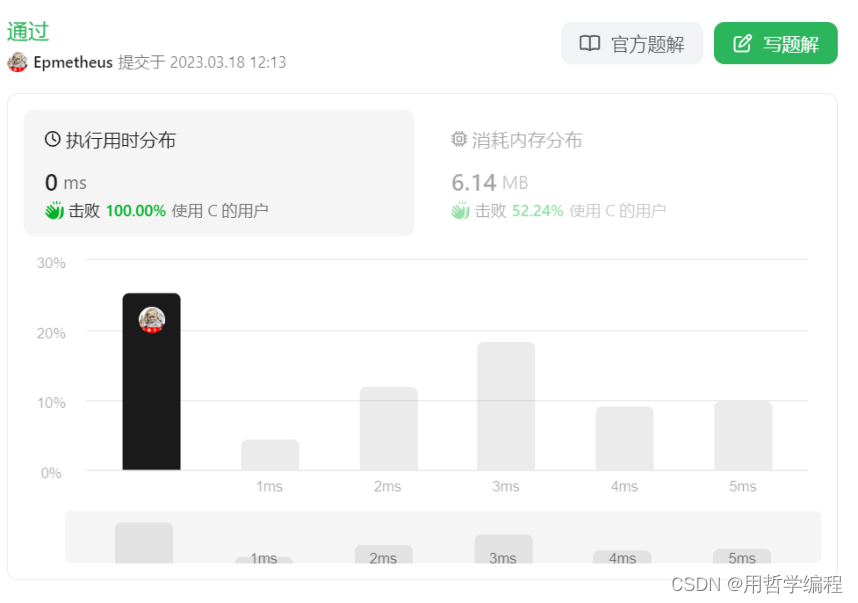
每日一题——力扣206. 反转链表(举一反三、思想解读)
一个认为一切根源都是“自己不够强”的INTJ 个人主页:用哲学编程-CSDN博客专栏:每日一题——举一反三题目链接 目录 菜鸡写法编辑 代码点评 代码分析 时间复杂度 空间复杂度 专业点评 另一种方法编辑 代码点评 代码逻辑 时间复杂度 空间…...

【qt】纯代码界面设计
界面设计目录 一.界面设计的三种方式1.使用界面设计器2.纯代码界面设计3.混合界面设计 二.纯代码进行界面设计1.代码界面设计的总思路2.创建项目3.设计草图4.添加组件指针5.初始化组件指针6.添加组件到窗口①水平布局②垂直布局③细节点 7.定义槽函数8.初始化信号槽9.实现槽函数…...

【深度学习】SDXL中的Offset Noise,Diffusion with Offset Noise,带偏移噪声的扩散
https://www.crosslabs.org//blog/diffusion-with-offset-noise 带有偏移噪声的扩散 针对修改后的噪声进行微调,使得稳定扩散能够轻松生成非常暗或非常亮的图像。 作者:尼古拉斯古藤伯格 | 2023年1月30日 马里奥兄弟使用稳定扩散挖掘隧道。左图显示了未…...
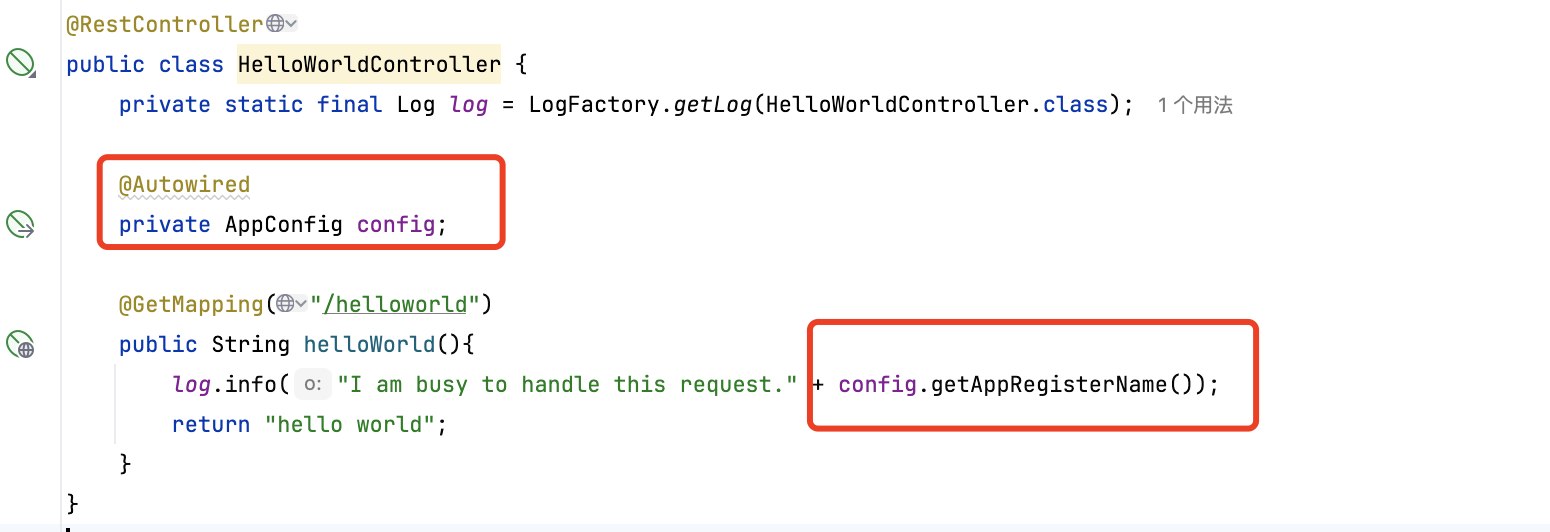
开发属于自己的Spring Boot Starter-18
为什么要开发专用的Spring Boot Starter Spring在通常使用时,一般是通过pom.xml文件中引入相关的jar包,然后再通过application.yml文件配置初始化bean的配置,但随着项目越来越复杂或是项目组中的应用数量越来越多,可能会带来几个…...

C中Mysql的基本api接口
一、初始化参数返回值 二、链接服务器三、执行SQL语句注意事项 四、获取结果集4.1mysql_affected_rows和mysql_num_rows4.2mysql_store_result与mysql_free_result注意事项注意事项整体的工作流程 4.3mysql_use_result()4.4mysql_field_count(…...

吵翻了!龙虾之父晒天价账单,一个月烧了 130 万美元,消耗 6030 亿 Token
前段时间,昆仑万维董事长方汉的一次访谈引发热议,他自曝“一个月才用 20 多亿,有点惭愧。” 他有位 CTO 朋友每月烧 600 亿 token,3 个月完成百名程序员七八年写的 800 万行代码。不过呢,今天小程程刷到一个更绝的案例…...
)
数据结构第7章图:课后习题全解析(选择题+综合题+算法设计题,含DFS/BFS遍历、拓扑排序、最小生成树)
第7章 图 课后习题一、单项选择题1. 设无向图的顶点个数为 n,则该图最多有(B )条边。A. n−1 B. n(n−1)/2 C. n(n1)/2 D. n(n−1)解析: 无向完全图边数最多,每对顶点之间有一条边,总边数为 n(n−1)/2。2. …...

对比直接使用厂商API,Taotoken在计费透明与用量观测上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API,Taotoken在计费透明与用量观测上的优势 当个人开发者或小型团队开始将大模型能力集成到自己的项目…...

数字图像处理入门:像素、通道与卷积操作的核心原理与实践
1. 项目概述:为什么“基本知识”是数字图像处理的基石刚入行做图像处理那会儿,我犯过一个典型的“新手错误”:拿到一张图,二话不说就开始调OpenCV的函数,什么高斯模糊、边缘检测、二值化,一顿操作猛如虎&am…...

Windows 11系统优化终极指南:免费提升性能与隐私保护的完整方案
Windows 11系统优化终极指南:免费提升性能与隐私保护的完整方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutt…...

为Claude Code配置Taotoken作为备用API服务商防止中断
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken作为备用API服务商防止中断 当您依赖Claude Code作为编程助手时,可能会遇到服务暂时不可用或…...

BepInEx.ConfigurationManager:3步打造专业级Unity插件配置界面
BepInEx.ConfigurationManager:3步打造专业级Unity插件配置界面 【免费下载链接】BepInEx.ConfigurationManager Plugin configuration manager for BepInEx 项目地址: https://gitcode.com/gh_mirrors/be/BepInEx.ConfigurationManager 你是否曾为Unity游戏…...

ASReview实战:用主动学习技术高效完成文献综述
1. 项目概述:当学术文献综述遇上主动学习如果你是一名研究生、科研人员,或者任何需要从海量文献中筛选出相关研究的人,那么“大海捞针”这个词你一定深有体会。面对动辄成千上万篇的论文标题和摘要,传统的人工筛选不仅耗时耗力&am…...

Linux内核安全加固:从编译配置构建系统防护基石
1. 项目概述:为什么我们需要关注内核安全配置?在服务器运维、嵌入式开发或者安全研究领域待久了,你可能会发现一个现象:很多系统被攻破,根源并不在于某个惊天动地的零日漏洞,而在于内核配置本身就没“锁好门…...

云原生技能图谱:构建开发者能力模型与学习路径
1. 项目概述:一个面向云原生时代的技能图谱仓库最近在整理团队内部的技术分享材料时,我偶然发现了一个在开发者社区里讨论度颇高的开源项目:prevu-cloud/skills。乍一看这个名字,你可能会觉得它只是一个普通的“技能列表”或者“学…...