学习MySQL(四):记录的增删改查
记录的增、删、改
-
增
-- 插入一条数据
INSERT INTO 表名(字段 1,字段2,字段3) VALUES(值 1,值2,值3)
INSERT INTO 表名 VALUES(值 1,值2,值3)-- 插入多条数据
INSERT INTO 表名(字段 1,字段2,字段3) VALUES(值 1,值2,值3),(值4,值5,值6)···
INSERT INTO 表名 VALUES(值 1,值2,值3),(值4,值5,值6)···-
删
-- 指定条件删除
DELETE FROM 表 WHERE 条件;-- 清空表
DELETE FROM 表;注:不加 WHERE条件,整个表数据都没了,慎用DELETE
思考:DROP TABLE与DELETE FROM 表的区别-
改
-- 更新一个字段
UPDATE 表名 SET 字段 =新值 WHERE 条件;-- 更新多个字段
UPDATE 表名 SET 字段 1 =新值 1,字段2 =新值 2 WHERE 条件;记录的单表查询
-- 语法:
SELECT DISTINCT 字段 1,字段 2 [,...] FROM 表名 WHERE 条件 GROUP BY field HAVING 筛选条件 ORDER BY filed LIMIT 条数-- 注:
GROUP BY field 根据什么进行分组,一般是某个字段或多个字段
ORDER BY field 根据什么进行排序,一般是某个字段或多个字段
HAVING主要配合GROUP BY使用,对分组后的数据进行过滤,里面可以使用聚合函数 WHERE是针对SELECT查询的过滤,各有区别和用处-- 优先级FROMWHEREGROUP BYSELECTDISTINCTHAVINGORDER BYLIMIT-- 解释说明:
1、先找到表:FROM
2、拿着WHERE指定的约束条件,去表中去除符合条件的一条条数据
3、将去除的数据进行分组GROUP BY,如果没有GROUP BY,则每行为一组
4、执行SELECT查询所指定的字段
5、若有DISTINCT则去重
6、将结果按照条件排序:ORDER BY
7、限制结果的显示条数:LIMIT-
例
-- 创建员工表
CREATE TABLE emp (id INT PRIMARY KEY auto_increment,emp_name CHAR ( 20 ) NOT NULL,sex enum ( "male", "female" ) NOT NULL DEFAULT "male",age INT ( 3 ) UNSIGNED NOT NULL DEFAULT 28,hire_date date NOT NULL,post CHAR ( 50 ),post_comment CHAR ( 100 ),salary DOUBLE ( 15, 2 ),office INT,depart_id INT
);-- 插入数据
-- 管理部
INSERT INTO emp ( emp_name, sex, age, hire_date, post, salary, office, depart_id )
VALUES( 'huahua', 'male', 18, '20170301', 'teacher', 7300.33, 401, 1 ),( 'weiwei', 'male', 78, '20150302', 'teacher', 10000000.31, 401, 1 ),( 'lala', 'male', 81, '20130305', 'teacher', 8300, 401, 1 ),( 'zhangsan', 'male', 16, '20170301', 'teacher', 3300, 401, 1 ),( 'liulaogen', 'male', 35, '20180506', 'teacher', 2100, 401, 1 ),( 'aal', 'female', 33, '20251015', 'teacher', 8300, 401, 1 ),( 'zhugeliang', 'male', 25, '20090623', 'teacher', 30000, 401, 1 ),
-- 以下是运维部( '歪歪', 'female', 48, '20150501', 'sale', 2300.13, 402, 2 ),( '丫丫', 'female', 38, '20110311', 'sale', 4300.35, 402, 2 ),( '梅梅', 'female', 18, '20160311', 'sale', 1300.25, 402, 2 ),( '丁丁', 'female', 28, '20220311', 'sale', 3300.65, 402, 2 ),
-- 以下是技术部( '七七', 'female', 38, '20120311', 'operation', 10300.65, 403, 3 ),( '卡卡', 'male', 20, '20180331', 'operation', 11000.65, 403, 3 ),( '程翔', 'female', 30, '20150321', 'operation', 11000.65, 403, 3 ),( '采薇', 'male', 18, '20140611', 'operation', 11000.65, 403, 3 ),( '玫瑰', 'female', 18, '20130312', 'operation', 11000.65, 403, 3 );简单查询
SELECT * FROM emp;-- 指定字段查询
SELECT emp_name, salary FROM emp;-- 去重查询
SELECT DISTINCT post FROM emp;-- 拼接字符串
SELECT concat( "姓名:", emp_name, "年龄:", age ) AS 信息 FROM emp;-- concat_ws() 第一个参数为分隔符
SELECT concat_ws( ":", emp_name, salary ) as 信息 FROM emp;-- 条件判断case when
SELECT emp_name, salary,
CASE WHEN salary >= 10000 THEN"高级技工" WHEN salary >= 5000 THEN"中级技工" ELSE "初级技工" END AS 职级
FROM emp;-- case when 结合聚合函数
SELECT office,count( CASE WHEN salary >= 10000 THEN emp_name ELSE NULL END ) AS 人数 FROM emp GROUP BY office;-- where表达,二者区别
SELECT office, count( emp_name ) AS 人数 FROM emp WHERE salary >= 10000 GROUP BY office;where条件筛选
- 比较运算符:> < >= <= <> !=
- between...and
- in("a","b","c")是否属于括号内的元素,满足其中一个就可以
- like ”%好“ 通配符: %表示任意字符(0个到n个), _表示一个字符
- 逻辑运算符and or not:多条件时使用
-- 男员工的相关信息
SELECT * FROM emp WHERE sex = 'male';-- 薪资大于等于1万,部门为管理部的员工信息
SELECT * FROM emp WHERE salary >= 10000 AND office = 401;-- between...and 都是闭区间
SELECT * FROM emp WHERE salary BETWEEN 1000.37 AND 3500;-- like 模糊查询 %表示任意字符,_表示一个字符
SELECT * FROM emp WHERE emp_name LIKE '%h%';
SELECT * FROM emp WHERE emp_name LIKE '_h%';-- in/not in
SELECT * FROM emp WHERE office IN ( 401, 402 );-- is null/ is not null
SELECT * FROM emp WHERE office IS NOT NULL;group by 分组
-- 每个部门的员工人数,分组字段于查询字段要保持一致
SELECT office,count( emp_name ) AS 员工个数 FROM emp GROUP BY office;-- group_concat
SELECT office,group_concat( emp_name ) AS 员工个数 FROM emp GROUP BY office;-- 常用聚合函数
count() 计数
sum() 求和
avg() 求平均
max() 最大值
min() 最小值having分组后过滤条件
-- 查找大于5个员工数以上的部门
SELECT office, count( emp_name ) AS 员工个数 FROM emp GROUP BY office HAVING count( emp_name )> 5;order by排序
-- 排序,默认升序ASC,降序DESC
SELECT * FROM emp ORDER BY salary;-- 多列排序,字段越靠前,优先级越高
SELECT * FROM emp ORDER BY post,salary DESC;limit
m,n m从第几条开始,n显示前多少条,m若等于0则默认不写
-- 从0开始,显示前三 select from emp limit 3;-- 从0开始,显示前三
SELECT * FROM emp LIMIT 3;-- 从第2条开始,显示三条
SELECT * FROM emp LIMIT 2, 3;-- 从第2条开始,显示三条
SELECT * FROM emp LIMIT 2, 3;记录的多表查询
笛卡尔积:交叉连接把表合并,没有其他操作
SELECT * FROM emp_new,dep;内连接:join
SELECT e.name,e.sex,e.age,d.name 部门名称 FROM emp_new AS e
JOIN dep AS d ON e.dep_id = d.id;左连接:left join
SELECTe.NAME,e.sex,e.age,d.NAME AS 部门名称
FROMemp_new AS eLEFT JOIN dep AS d ON e.dep_id = d.id;右连接: right join
SELECTe.NAME,e.sex,e.age,d.NAME AS 部门名称
FROMemp_new AS eRIGHT JOIN dep AS d ON e.dep_id = d.id;全外连接: union/union all
SELECTe.NAME,e.sex,e.age,d.NAME 部门名称
FROMemp_new AS eLEFT JOIN dep AS d ON e.dep_id = d.id UNION
SELECTe.NAME,e.sex,e.age,d.NAME 部门名称
FROMemp_new AS eRIGHT JOIN dep AS d ON e.dep_id = d.id;子查询: in/not in/exits
- 子查询是将一个查询语句嵌套在另一个查询语句中
- 内层查询语句的查询结果,可以为外层查询语句提供查询条件
- 子查询中可以包含:in、not in、exists、not exists等关键字
- 还可以包含比较运算符:=、!=、>、<等
-- 查询平均年龄在25岁以上的部门名
SELECT NAME FROM dep WHERE id IN ( SELECT dep_id FROM emp_new GROUP BY dep_id HAVING avg ( age )>25 );-- 查询技术部员工姓名
SELECT id,NAME FROM emp_new WHERE dep_id = ( SELECT id FROM dep WHERE NAME = "技术" );-- 联系方式
SELECT emp_new.id,emp_new.NAME,dep.NAME FROM emp_new
JOIN ( SELECT id, NAME FROM dep WHERE NAME = "技术" ) dep ON emp_new.dep_id = dep.id;-- 查询不足1人的部门名(子查询得到的是有人部门的id)--》换句话说就是查询没有人的部门
SELECT id,NAME FROM dep WHERE id NOT IN ( SELECT dep_id FROM emp_new GROUP BY dep_id HAVING count( id )>= 1 );-- dep表中是否存在dep_id=203
SELECT * FROM emp_new WHERE EXISTS ( SELECT id FROM dep WHERE id = 203 );示例数据
CREATE TABLE dep ( id INT PRIMARY KEY, NAME CHAR ( 20 ) );
CREATE TABLE emp_new (id INT PRIMARY KEY auto_increment,NAME CHAR ( 20 ),sex enum ( "male", "female" ) NOT NULL DEFAULT "male",age INT,dep_id INT
);-- 插入数据
INSERT INTO dep
VALUES( 200, '技术' ), ( 201, '人力资源' ), ( 202, '销售' ), ( 203, '运营' );
INSERT INTO emp_new ( NAME, sex, age, dep_id )
VALUES( 'ailsa', 'male', 18, 200 ),( 'lala', 'female', 48, 201 ),( 'huahua', 'male', 38, 201 ),( 'zhangsan', 'female', 28, 202 ),( 'lisi', 'male', 18, 200 ),( 'shenteng', 'female', 38, 204 );来自: 学习MySQL(四):记录的增删改查
相关文章:
:记录的增删改查)
学习MySQL(四):记录的增删改查
记录的增、删、改 增 -- 插入一条数据 INSERT INTO 表名(字段 1,字段2,字段3) VALUES(值 1,值2,值3) INSERT INTO 表名 VALUES(值 1,值2,值3&am…...

如何使用Python进行网页爬取
Python爬虫案例可以有很多种,但我会为你提供一个简单的案例,该案例使用Python的requests库来爬取一个网页的内容,并使用BeautifulSoup库来解析HTML并提取特定的信息。 假设我们要从某个新闻网站(例如:示例网站&#x…...
设计模式)
Spring的IOC(Inversion of Control)设计模式
Spring的IOC(Inversion of Control)是一种设计模式,它通过控制反转的思想来降低组件之间的耦合度。在Spring框架中,IOC容器负责管理应用程序中的对象,使得对象之间的依赖关系由容器来维护和注入。 以下是Spring IOC的…...

深度学习知识点总结
深度学习是机器学习领域中的一个重要研究方向,它致力于模拟人脑的学习过程,使机器能够像人一样具有分析学习能力,识别文字、图像和声音等数据。以下是深度学习的一些关键知识点总结: 定义与目标: 深度学习是学习样本数…...

以色列人Andi Gutmans开发的php zend
虽然目前php语言不行了【相关的文章前几年已经有人发过】,但这不是重点,重点是zend引擎的东西具有极大的技术价值,负责zend引擎实现的大佬都现在差不多都是40,50岁左右了,从1997,1998,2000到202…...
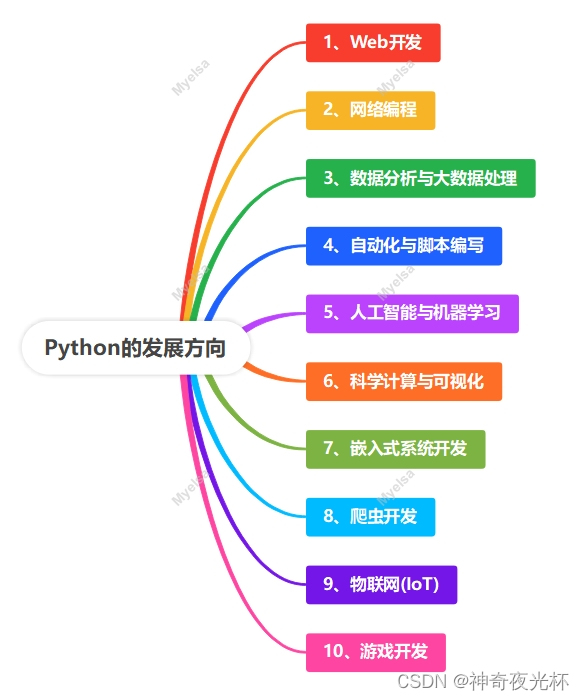
Python筑基之旅-溯源及发展
目录 一、Python的起源 二、Python的版本更替及变化 三、Python的优缺点 四、Python的发展方向 五、Python之禅 六、推荐专栏/主页: 1、Python函数之旅:Functions 2、Python算法之旅:Algorithms 3、个人主页:https://mye…...

网页打开:为什么国内用新标签页,国外用当前页?
想写这个话题很久了,因为用百度和Google搜索时,打开搜索结果链接时的交互差异,几乎每天都要提醍我一下。 网页打开——这个交互,在设计里,算是极微小,但影响极广泛的操作设计。甚至,因此形成了…...
)
用户运营4大核心(C端版)
1、用户运营是什么 产品好比歌手,运营好比经纪公司,运营就是让一个有潜质的产品,从“草根”发展成“明星”!C端用户的产品忠诚度不高,用户运营更要维护好“粉丝”关系,从“单向的吸引”发展成“双向的进步…...
SBM模型、超效率SBM模型代码及案例数据(补充操作视频)
01、数据简介 SBM(Slack-Based Measure)模型是一种数据包络分析(Data Envelopment Analysis, DEA)的方法,用于评估决策单元(Decision Making Units, DMUs)的效率。而超效率SBM模型是对SBM模型的…...
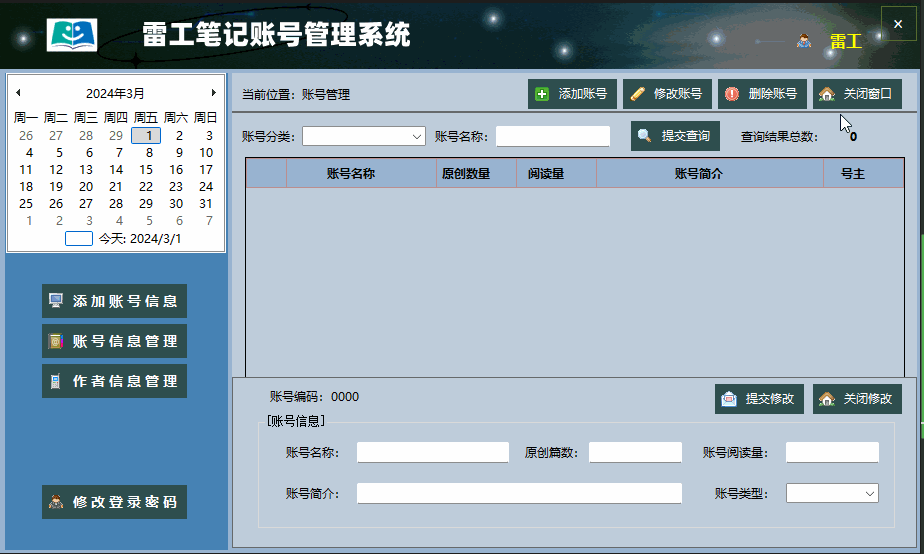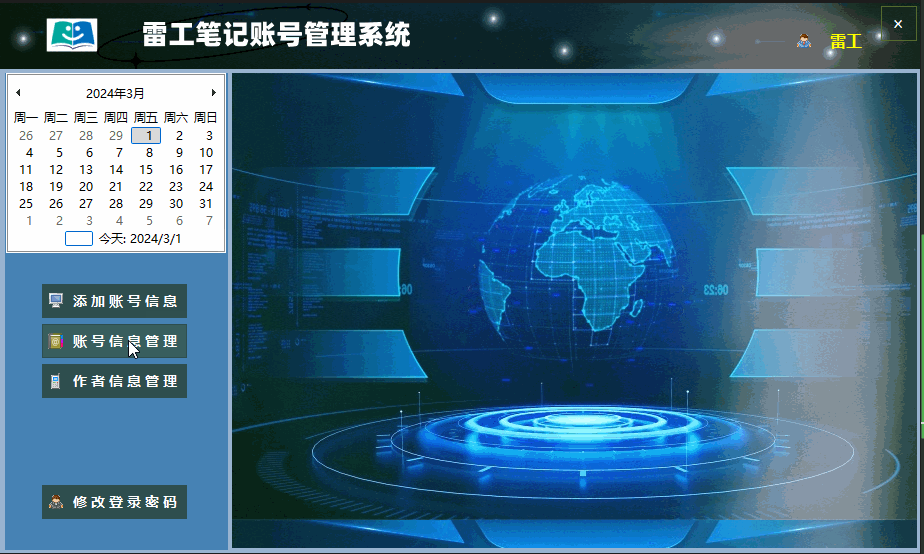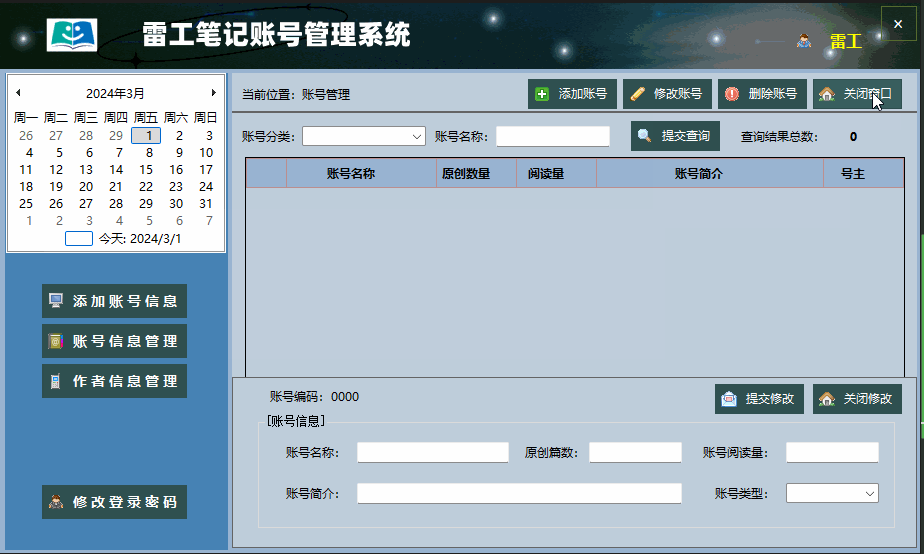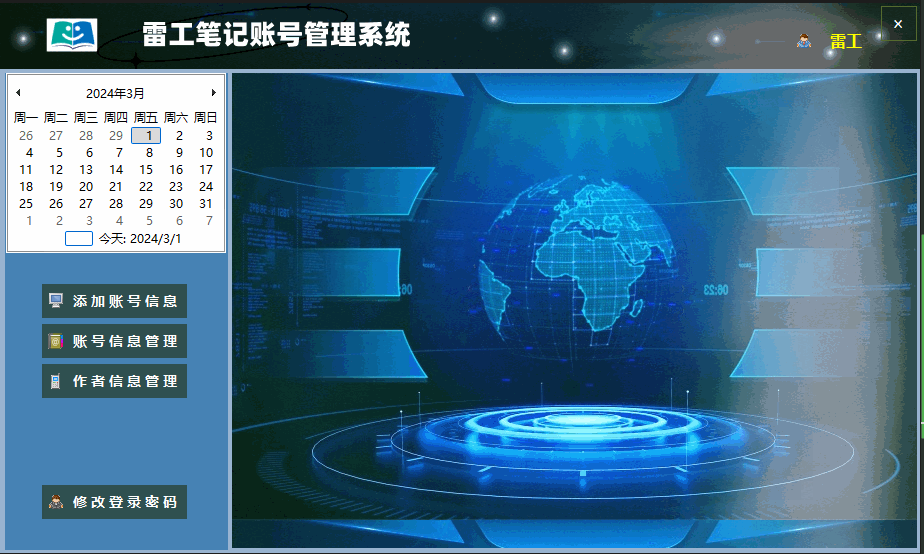
C#知识|上位机子窗体嵌入主窗体方法(实例)
哈喽,你好啊,我是雷工! 上位机开发中,经常会需要将子窗体嵌入到主窗体, 本节练习C#中在主窗体的某个容器中打开子窗体的方法。 01 需求说明 本节练习将【账号管理】子窗体在主窗体的panelMain容器中打开。 账号管理子窗体如下: 主窗体的panelMain容器位置如图: 02 实现…...

【汇编】算术指令
一、加法指令 (一)各加法指令的格式及操作 加法指令可做字或字节运算 (1)加法指令 ADD 格式:ADD DST,SRC执行的操作:(DST) ← (SRC)(DST) (2)带进位加法指令 ADC 格式…...

如何知晓自己手机使用状况-入网时长
手机入网时长查询的重要性 在当今的数字化时代,手机已经成为我们日常生活中不可或缺的一部分。从通讯、娱乐到工作,手机几乎涵盖了生活的各个方面。而在手机使用过程中,了解手机的入网时长信息显得尤为重要。本文将深入探讨手机入网时长查询…...

机器学习 - 决策树
1. 决策树基础 定义与概念 决策树是一种监督学习算法,主要用于分类和回归任务。它通过学习从数据特征到输出标签的映射规则,构建一个树形结构。在分类问题中,决策树的每个叶节点代表一个类别。 案例分析 假设我们有一个关于天气和是否进行…...
ML模型实战及经验总结(更新中))
【scikit-learn007】主成分分析(Principal Component Analysis, PCA)ML模型实战及经验总结(更新中)
1.一直以来想写下基于scikit-learn训练AI算法的系列文章,作为较火的机器学习框架,也是日常项目开发中常用的一款工具,最近刚好挤时间梳理、总结下这块儿的知识体系。 2.熟悉、梳理、总结下scikit-learn框架主成分分析(Principal C…...
还在花钱订购SSL证书吗?out啦!
SSL(Secure Sockets Layer)证书,以及其后续版本TLS(Transport Layer Security)证书,扮演了保护用户数据免遭窃听和篡改的核心角色。这些证书能够确保数据在客户端与服务器之间传输时的加密性与完整性&#…...

【GoLang基础】函数体的注意事项和细节讨论
在 Go 语言(Golang)中,函数是程序的基本构建块之一。理解函数的定义和使用是掌握 Go 语言的重要步骤。下面是关于 Go 语言中函数体的详细解释,包括函数的定义、参数传递、返回值以及闭包等方面。 1. 函数的定义 在 Go 语言中&am…...
YOLOv8训练流程-原理解析[目标检测理论篇]
关于YOLOv8的主干网络在YOLOv8网络结构介绍-CSDN博客介绍了,为了更好地学习本章内容,建议先去看预测流程的原理分析YOLOv8原理解析[目标检测理论篇]-CSDN博客,再次把YOLOv8网络结构图放在这里,方便随时查看。 1.前言 YOLOv8训练…...

实战使用Java代码操作Redis
实战使用Java代码操作Redis 1. 背景说明2. 单连接方式3. 连接池方式1. 背景说明 在工作中, 如果有一批数据需要初始化, 最方便的方法是使用代码操作Redis进行初始化。 Redis提供了多种语言的API交互方式, 这里以Java代码为例进行分析。 使用Java代码操作 Redis 需要借助…...

微信小程序之九宫格抽奖
1.实现效果 2. 实现步骤 话不多说,直接上代码 /**index.wxml*/ <view class"table-list flex fcc fwrap"><block wx:for"{{tableList}}" wx:key"id"><view class"table-item btn fcc {{isTurnOver?:grayscale…...
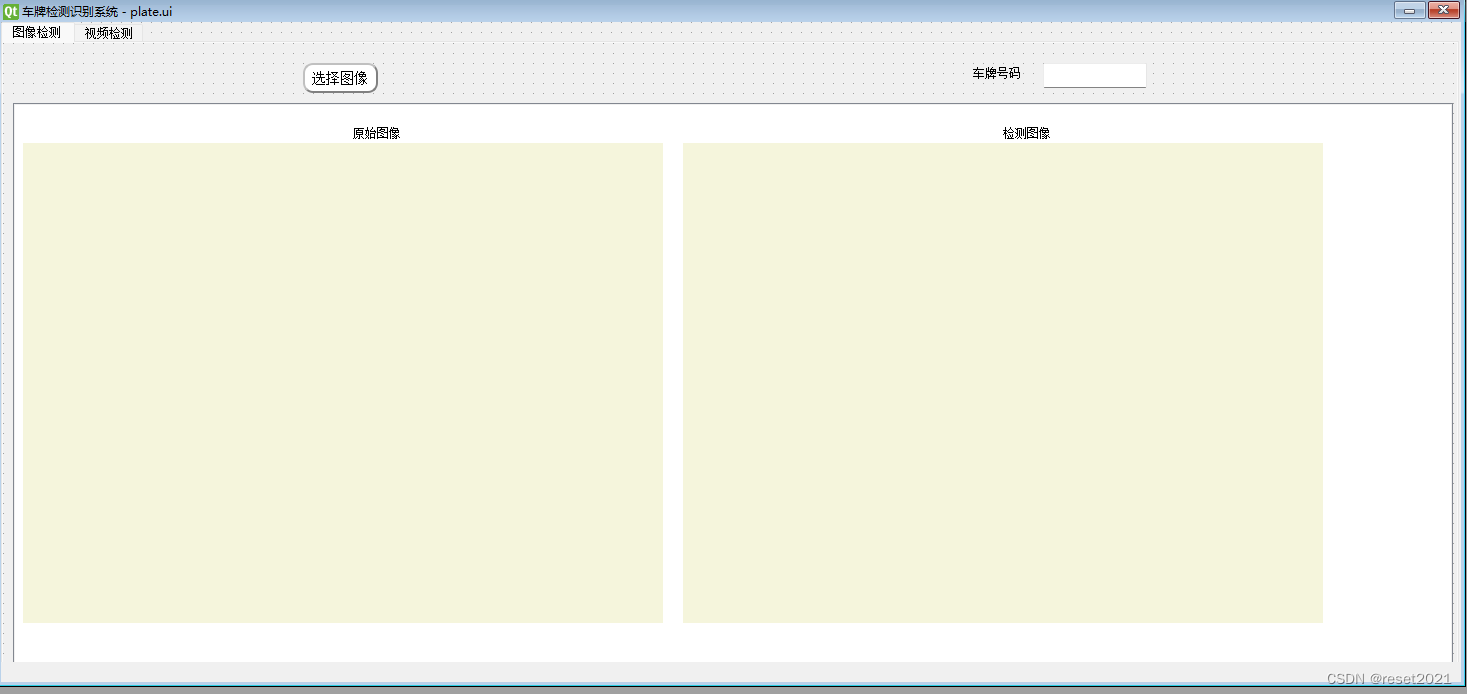
车牌检测识别功能实现(pyqt)
在本专题前面相关博客中已经讲述了 pyqt + yolo + lprnet 实现的车牌检测识别功能。带qt界面的。 本博文将结合前面训练好的模型来实现车牌的检测与识别。并用pyqt实现界面。最终通过检测车牌检测识别功能。 1)、通过pyqt5设计界面 ui文件如下: <?xml version="1…...

如何一键下载推特上的所有媒体资源?X-Spider帮你轻松解决内容收集难题
如何一键下载推特上的所有媒体资源?X-Spider帮你轻松解决内容收集难题 【免费下载链接】x-spider A spider for X (Twitter) 项目地址: https://gitcode.com/gh_mirrors/xs/x-spider 你是否曾遇到过这种情况:在推特上看到了精美的图片、有趣的视频…...

从Scratch图形化到Python代码:用树莓派给LeArm机械臂做二次开发实战
从Scratch图形化到Python代码:用树莓派给LeArm机械臂做二次开发实战 当Scratch积木块拼接的机械臂动作开始显得单调时,便是时候揭开底层控制的神秘面纱了。本文将带您跨越图形化编程的舒适区,用树莓派的Python环境重新定义LeArm机械臂的智能—…...

高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题
高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题 解析几何作为高考数学的压轴题型,常常让考生望而生畏。面对复杂的计算和抽象的条件,如何在有限时间内快速找到突破口?极点极线理论作为高等几何中的重要工具&#x…...

LangGraph 并发执行不是开 Goroutine 那么简单:状态竞争与事务处理
LangGraph 并发执行不是开 Goroutine 那么简单:状态竞争与事务处理深度解析 元数据 关键词:LangGraph, 大语言模型工作流, 有状态并发, 状态一致性, 事务处理, 多Agent系统, 分布式状态管理 摘要:很多开发者初次接触LangGraph的并发特性时,会下意识将其等同于传统协程/线程…...

Arm Morello平台模型与CHERI安全扩展开发指南
1. Arm Morello平台模型概述Morello是Arm公司推出的实验性处理器架构,基于CHERI(Capability Hardware Enhanced RISC Instructions)安全扩展技术。这个平台模型本质上是一个功能准确的虚拟硬件环境,允许开发者在物理芯片问世前18-…...
)
乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓)
更多请点击: https://intelliparadigm.com 第一章:乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓) ElevenLabs 官方文档中仅标注 ur 为乌尔…...

MCP服务器开发指南:为AI助手构建安全可控的外部工具扩展
1. 项目概述:一个为AI助手赋能的MCP服务器最近在折腾AI应用开发的朋友,可能都绕不开一个词:MCP。全称是Model Context Protocol,你可以把它理解成一套标准化的“插件协议”。它让像Claude、Cursor这类AI助手,能够安全、…...

【STC8H】GPIO模式深度解析:从准双向到推挽,如何精准控制外设
1. STC8H的GPIO模式全景解析 第一次接触STC8H的GPIO配置时,我被那个神秘的PxM0和PxM1寄存器搞得晕头转向。直到有一次调试I2C通讯失败,才发现是开漏模式配置错误。这次教训让我明白,理解GPIO的四种工作模式,就像掌握不同武器的使用…...

基于WLED分段功能与激光切割的多层智能艺术灯板制作全攻略
1. 项目概述与核心价值如果你和我一样,对那种能随着音乐呼吸、或者能独立变换不同区域色彩的智能灯光装置着迷,那么你一定会喜欢这个项目。它远不止是把LED灯条粘在板子后面那么简单,而是将激光切割的精密工艺、分层的艺术设计,与…...

数据模型代码生成器:从OpenAPI/Schema自动生成Python类型安全模型
1. 项目概述:当数据模型遇上代码生成如果你经常和数据模型打交道,无论是OpenAPI规范、JSON Schema,还是数据库的DDL,那你一定体会过手动编写对应数据类(Data Class)或Pydantic模型的繁琐。一个字段类型写错…...