绿色智能:AI机器学习在环境保护中的深度应用与实践案例
🧑 博主简介:阿里巴巴嵌入式技术专家,深耕嵌入式+人工智能领域,具备多年的嵌入式硬件产品研发管理经验。
📒 博客介绍:分享嵌入式开发领域的相关知识、经验、思考和感悟,欢迎关注。提供嵌入式方向的学习指导、简历面试辅导、技术架构设计优化、开发外包等服务,有需要可加文末联系方式联系。
💬 博主粉丝群介绍:① 群内高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。
本地搭建类ChatGPT项目GPT4free并使用公网地址远程AI聊天
- 1. 前言:人工智能与绿色未来的交汇点
- 2. 相关概念与背景介绍
- 2.1 机器学习基础
- 2.2 环境保护的挑战
- 2.3 机器学习与环保的融合
- 3. 应用场景分析
- 3.1 气候预测与天气模式识别
- 3.1.1 概述
- 3.1.2 示例:使用LSTM进行气候预测
- 3.2 环境污染监测与管理
- 3.2.1 概述
- 3.2.2 示例:基于聚类分析的污染源识别
- 3.3 生物多样性保护
- 3.3.1 概述
- 3.3.2 示例:卷积神经网络(CNN)识别野生动物
- 5. 机器学习应用场景的深化
- 5.1 强化学习在资源管理中的应用
- 5.1.1 概述
- 5.1.2 示例:智能水资源管理系统
- 5.2 集成学习在污染预测中的优势
- 5.2.1 概述
- 5.2.2 示例:GBM预测空气污染指数
- 5.2.3 示例:随机森林预测空气污染指数(Python代码示例)
- 5.3 深度学习在环境图像识别中的应用
- 5.3.1 概述
- 5.3.2 示例:卫星图像分析森林砍伐
- 5.3.3 示例:使用卷积神经网络识别森林砍伐(Python代码示例,基于Keras)
- 5.4 自然语言处理(NLP)在环境政策分析中的作用
- 5.4.1 概述
- 5.4.2 示例:情感分析评估公众环保意识
- 5.4.3 示例代码
- 6. 总结:机器学习,绿色地球的智慧引擎

1. 前言:人工智能与绿色未来的交汇点
在这个全球气候变化日益严峻的时代,环境保护已成为人类面临的重大挑战之一。科技的发展,特别是人工智能(AI)和机器学习(ML)的崛起,为我们提供了前所未有的工具,去应对这些挑战。机器学习,凭借其在数据处理、模式识别和预测分析方面的强大能力,正逐渐成为环境保护领域的一股变革力量。本文将深入探讨机器学习如何赋能环境保护,通过分析气候数据、环境传感器数据,进行气候预测、天气模式识别,以及监测和减少环境污染,描绘出一幅利用技术守护地球的蓝图。
2. 相关概念与背景介绍
2.1 机器学习基础
机器学习是一种人工智能技术,它使计算机系统能够在不进行明确编程的情况下从数据中学习并改进其表现。通过训练模型,机器学习可以识别模式、做出预测、甚至自我优化,其核心在于算法、数据和计算能力的结合。
2.2 环境保护的挑战
环境保护面临的问题包括但不限于气候变化、空气和水污染、生物多样性丧失等。这些问题复杂且相互关联,需要综合性的解决方案。传统方法受限于数据收集和分析的难度,往往难以提供及时有效的干预措施。
2.3 机器学习与环保的融合
机器学习在环境保护中的应用,主要体现在以下几个方面:通过对海量环境数据的分析,识别环境变化的趋势和模式;预测极端天气事件,提高灾害预警的准确性;监测污染物排放,优化治理策略;以及保护生物多样性,预测物种分布变化等。

3. 应用场景分析
3.1 气候预测与天气模式识别
3.1.1 概述
借助机器学习算法,如神经网络和随机森林,可以从历史气象数据中学习并预测温度、降水量等气候变量的未来趋势。此外,通过分析卫星图像和地面观测数据,可以识别出复杂的天气模式,如厄尔尼诺现象,为农业规划、水资源管理和灾害预防提供依据。
3.1.2 示例:使用LSTM进行气候预测
import numpy as np
from keras.models import Sequential
from keras.layers import LSTM, Dense# 假设data是处理过的气候数据,shape为(samples, timesteps, features)
timesteps = data.shape[1]
features = data.shape[2]model = Sequential()
model.add(LSTM(50, input_shape=(timesteps, features)))
model.add(Dense(1)) # 预测单一气候变量model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(data, targets, epochs=100, batch_size=16, validation_split=0.2)
3.2 环境污染监测与管理
3.2.1 概述
通过部署传感器网络收集空气质量、水质等实时数据,结合机器学习模型,可以精准识别污染源、预测污染物扩散趋势,并优化治理策略。例如,利用异常检测算法识别工业排放异常,或使用回归模型预测污染物浓度变化。
3.2.2 示例:基于聚类分析的污染源识别
from sklearn.cluster import KMeans
import pandas as pd# 假设df为包含多项环境监测指标的DataFrame
X = df.values# 应用K-means聚类算法识别潜在的污染区域
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)# 将聚类结果添加到原始数据中
df['Cluster'] = kmeans.labels_
3.3 生物多样性保护
3.3.1 概述
利用机器学习分析遥感图像和生态数据,可以预测物种分布、评估栖息地质量,以及监测生态系统的变化。这有助于制定保护策略,减少人类活动对生物多样性的影响。
3.3.2 示例:卷积神经网络(CNN)识别野生动物
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense# 构建CNN模型用于动物图片分类
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(img_width, img_height, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(num_classes, activation='softmax'))model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(training_set, labels, epochs=25, batch_size=32, validation_data=(test_set, test_labels))
当然可以。为了进一步丰富文章的技术深度,下面我将更深入地探讨几种在环境保护中应用广泛的机器学习算法和技术点,以及它们如何促进环境数据的高效分析与应用。
5. 机器学习应用场景的深化
5.1 强化学习在资源管理中的应用
5.1.1 概述
强化学习(RL)是一种通过试错过程学习最佳行为策略的方法,特别适合解决动态决策问题。在环境保护中,它可用于水资源分配、能源管理等资源优化问题。通过定义状态空间(如水库水位、电力需求)、动作空间(如抽水量、发电量)和奖励函数(如最大化经济效益同时最小化环境影响),RL算法能自动学习最优策略。
5.1.2 示例:智能水资源管理系统
利用Q-Learning算法设计一个智能系统,根据当前水库水位、天气预报和历史用水数据,自动调整供水策略,以确保水资源的有效利用和供需平衡,同时减少因过度抽取地下水引起的环境问题。
5.2 集成学习在污染预测中的优势
5.2.1 概述
集成学习通过组合多个基础模型(如决策树)的预测结果,以提高整体预测性能。在环境污染预测中,集成方法如随机森林、梯度提升机(GBM)能够处理非线性关系,提高模型的准确性和鲁棒性。
5.2.2 示例:GBM预测空气污染指数
构建一个梯度提升机模型,集成数百棵决策树,分别学习不同特征(如风速、湿度、工业活动水平)对PM2.5浓度的影响,实现对未来几天空气质量的高精度预测,从而为公众健康防护和政府决策提供支持。
5.2.3 示例:随机森林预测空气污染指数(Python代码示例)
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import pandas as pd# 假设df为包含历史空气质量数据的DataFrame,包括温度、湿度、风速等特征和PM2.5浓度目标变量
features = ['temperature', 'humidity', 'wind_speed']
target = 'pm2_5'# 数据预处理
X = df[features]
y = df[target]# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建随机森林模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)# 训练模型
rf_model.fit(X_train, y_train)# 预测
predictions = rf_model.predict(X_test)# 打印预测结果(示例省略了评估步骤)
print(predictions[:5])
5.3 深度学习在环境图像识别中的应用
5.3.1 概述
深度学习,尤其是卷积神经网络(CNN),在图像和视频数据处理上表现出色。在环境保护领域,它被用来识别卫星图像中的森林覆盖变化、海洋塑料垃圾分布、甚至是野生动物的种群动态。
5.3.2 示例:卫星图像分析森林砍伐
利用预训练的ResNet模型进行迁移学习,通过微调最后几层,使其适应森林覆盖变化的识别任务。模型可以识别不同年份的卫星图像序列,精确标注出森林损失区域,帮助监测非法砍伐活动,及时采取保护措施。
5.3.3 示例:使用卷积神经网络识别森林砍伐(Python代码示例,基于Keras)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import os# 数据准备假设
train_dir = 'path/to/train'
validation_dir = 'path/to/validation'
image_size = (150, 150)
batch_size = 32
num_classes = 2 # 假设有"森林"和"非森林"两类# 构建模型
model = Sequential([Conv2D(32, (3, 3), activation='relu', input_shape=image_size + (3,)),MaxPooling2D(pool_size=(2, 2)),Conv2D(64, (3, 3), activation='relu'),MaxPooling2D(pool_size=(2, 2)),Conv2D(128, (3, 3), activation='relu'),MaxPooling2D(pool_size=(2, 2)),Flatten(),Dense(512, activation='relu'),Dropout(0.5),Dense(num_classes, activation='softmax')
])model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 数据增强
train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest')validation_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_dir,target_size=image_size,batch_size=batch_size,class_mode='binary')validation_generator = validation_datagen.flow_from_directory(validation_dir,target_size=image_size,batch_size=batch_size,class_mode='binary')# 训练模型(示例中省略了实际训练步骤,以避免过长)
# model.fit(train_generator, epochs=20, validation_data=validation_generator)5.4 自然语言处理(NLP)在环境政策分析中的作用
5.4.1 概述
自然语言处理技术可以帮助解析大量政策文档、新闻报道和社交媒体内容,提取关键信息,如环境法规的变化、公众对特定环保议题的态度等,为政策制定者提供数据支持。
5.4.2 示例:情感分析评估公众环保意识
运用BERT模型进行情感分析,对社交媒体上关于“塑料减排”话题的帖子进行情绪倾向分类。通过量化正面和负面情绪的比例,评估公众对塑料污染问题的关注度和态度变化,指导环保宣传策略的调整。
5.4.3 示例代码
以下是一个使用Hugging Face的transformers库和BERT模型进行情感分析的基本示例。这里以预训练的BERT模型为例,进行二分类任务(正面情绪vs负面情绪):
from transformers import BertTokenizer, BertForSequenceClassification
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
from sklearn.model_selection import train_test_split
import pandas as pd# 假设df为包含社交媒体帖子的DataFrame,其中'text'列为帖子内容,'sentiment'列为人工标注的情感标签(例如,0为负面,1为正面)
tweets = df['text'].tolist()
labels = df['sentiment'].tolist()# 数据预处理
class TweetDataset(Dataset):def __init__(self, tweets, labels, tokenizer, max_len):self.tweets = tweetsself.labels = labelsself.tokenizer = tokenizerself.max_len = max_lendef __len__(self):return len(self.tweets)def __getitem__(self, item):tweet = str(self.tweets[item])label = self.labels[item]encoding = self.tokenizer.encode_plus(tweet,add_special_tokens=True,max_length=self.max_len,return_token_type_ids=False,pad_to_max_length=True,return_attention_mask=True,return_tensors='pt',)return {'tweet_text': tweet,'input_ids': encoding['input_ids'].flatten(),'attention_mask': encoding['attention_mask'].flatten(),'labels': torch.tensor(label, dtype=torch.long)}# 准备数据加载器(示例中省略了划分训练集和测试集的具体代码)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
max_len = 128
dataset = TweetDataset(tweets, labels, tokenizer, max_len)
data_loader = DataLoader(dataset, batch_size=32)# 加载预训练模型并进行微调(这里仅展示了模型定义和前向传播示例,实际微调过程包括损失计算、反向传播和优化)
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)# 假设一个训练循环,这里省略了具体的训练步骤
for data in data_loader:inputs = {key: val.to(device) for key, val in data.items() if key != 'tweet_text'}outputs = model(**inputs)# 后续步骤包括计算损失、反向传播、优化等这个示例展示了如何使用预训练的BERT模型进行情感分析的基本框架。实际应用时,你需要根据具体任务细化数据预处理、模型微调的步骤,并进行模型评估与优化。由于模型微调和训练通常需要大量计算资源,建议在配备GPU的环境中进行。
6. 总结:机器学习,绿色地球的智慧引擎
机器学习作为一把钥匙,打开了环境保护的新视角和策略,它使我们能够以前所未有的精度和效率监测环境变化、预测未来趋势,并采取行动。从气候预测到环境污染控制,再到生物多样性的保护,机器学习的应用不仅加深了我们对环境的理解,也为可持续发展提供了科学依据和技术支持。未来,随着技术的不断进步和数据的持续积累,我们有理由相信,机器学习将在环境保护领域发挥更加深远的影响,引领我们向一个更加绿色、健康的地球迈进。然而,技术应用的同时,伦理、隐私和数据质量等问题也不容忽视,需要我们在推动技术进步的同时,保持审慎和责任感。
相关文章:
绿色智能:AI机器学习在环境保护中的深度应用与实践案例
🧑 博主简介:阿里巴巴嵌入式技术专家,深耕嵌入式人工智能领域,具备多年的嵌入式硬件产品研发管理经验。 📒 博客介绍:分享嵌入式开发领域的相关知识、经验、思考和感悟,欢迎关注。提供嵌入式方向…...
)
Java高级面试精粹:问题与解答集锦(二)
Java面试问题及答案 1. 什么是Java内存模型(JMM)?它的作用是什么? 答案: Java内存模型(JMM)定义了Java虚拟机(JVM)在计算机内存中的工作方式,包括程序计数器…...

基于机器学习模型预测信用卡潜在用户(XGBoost、LightGBM和Random Forest)
基于机器学习模型预测信用卡潜在用户(XGBoost、LightGBM和Random Forest) 随着数据科学和机器学习的发展,越来越多的企业开始利用这些技术来提高运营效率。在这篇博客中,我将分享如何利用机器学习模型来预测信用卡的潜在客户。此…...
)
java 通过 microsoft graph 调用outlook(三)
这次会添加一个Reply接口, 并且使用6.10.0版本 直接上代码 一, POM <!-- office 365 --><dependency><groupId>com.microsoft.graph</groupId><artifactId>microsoft-graph</artifactId><version>6.1…...
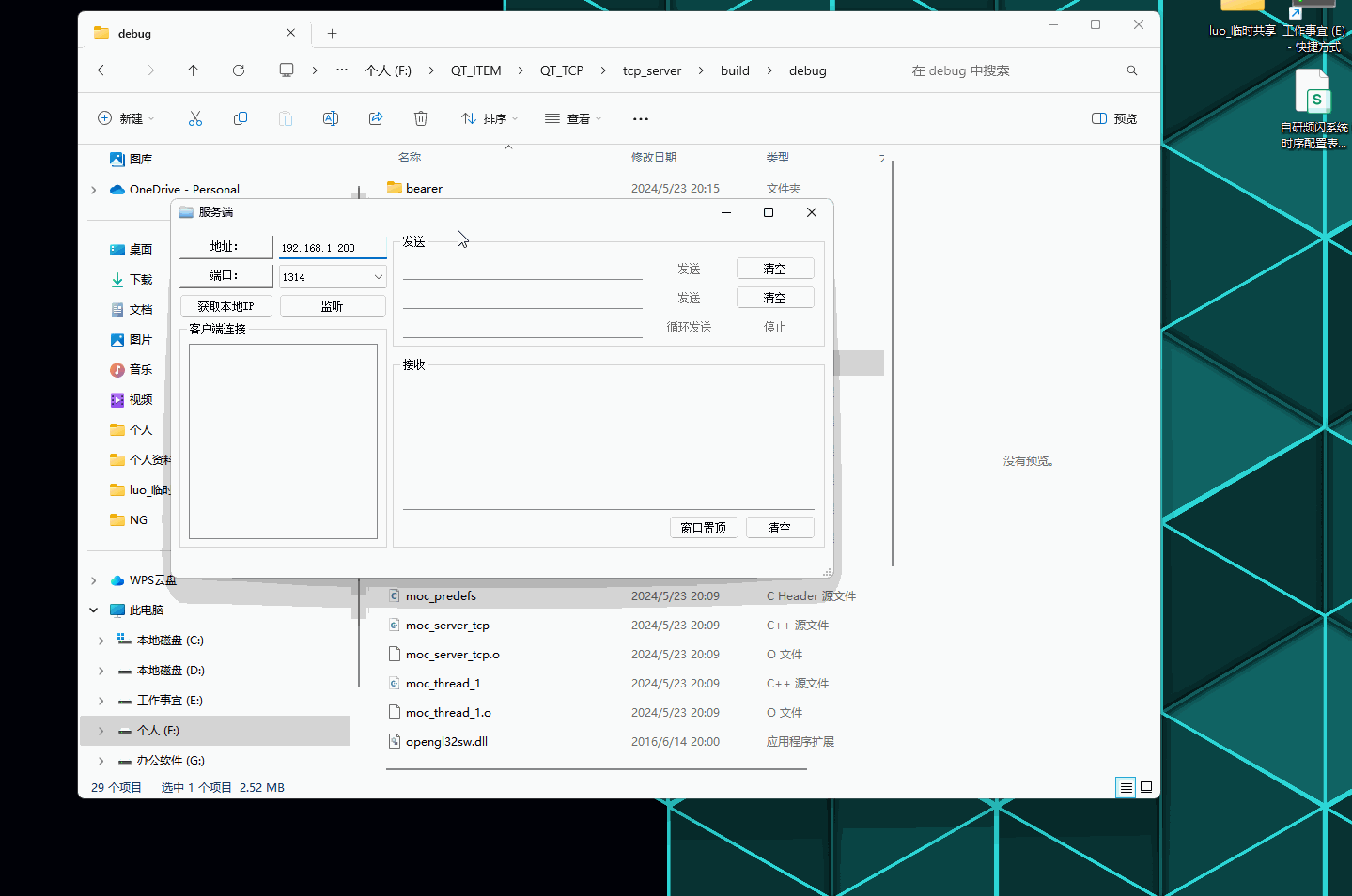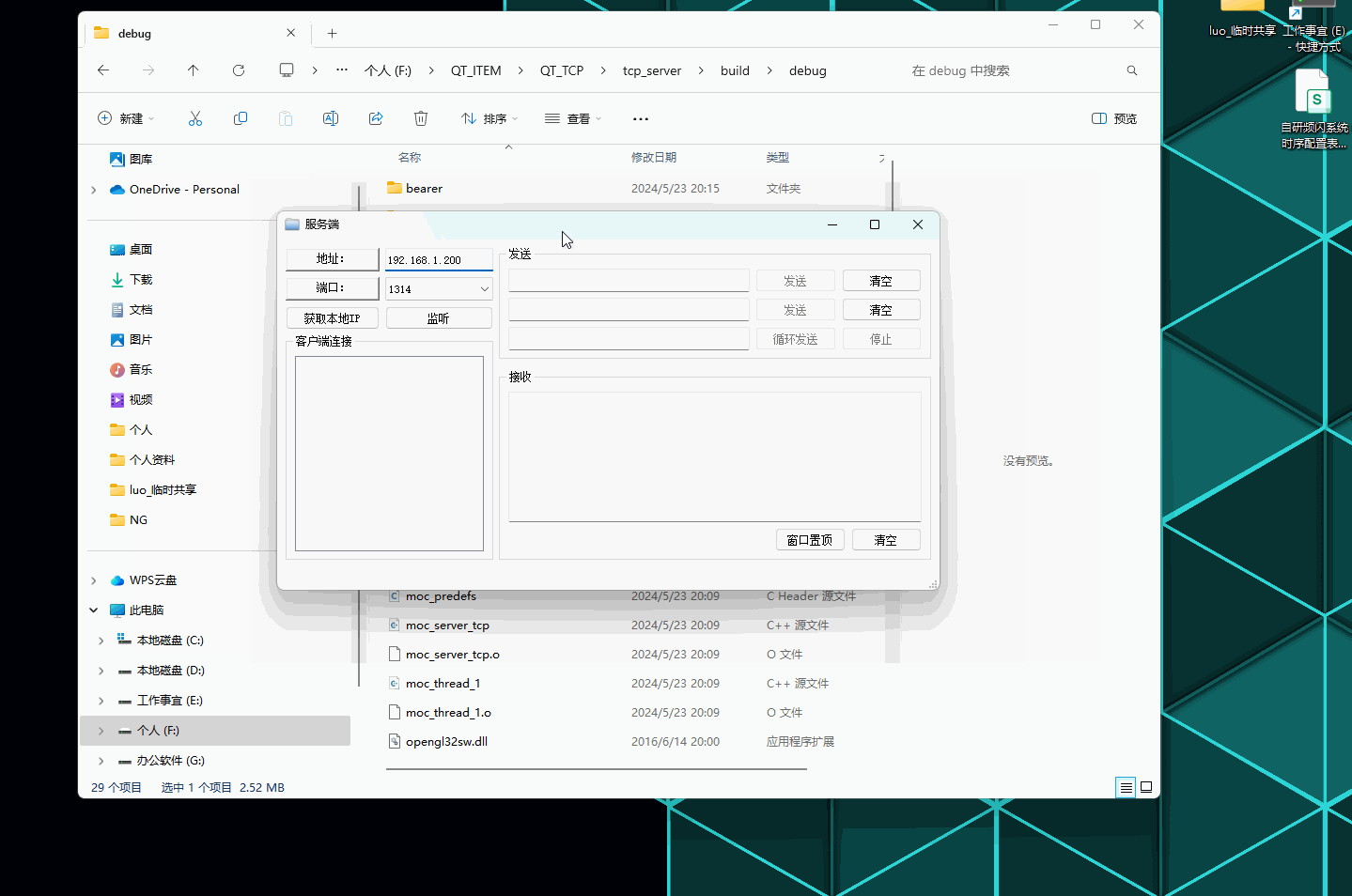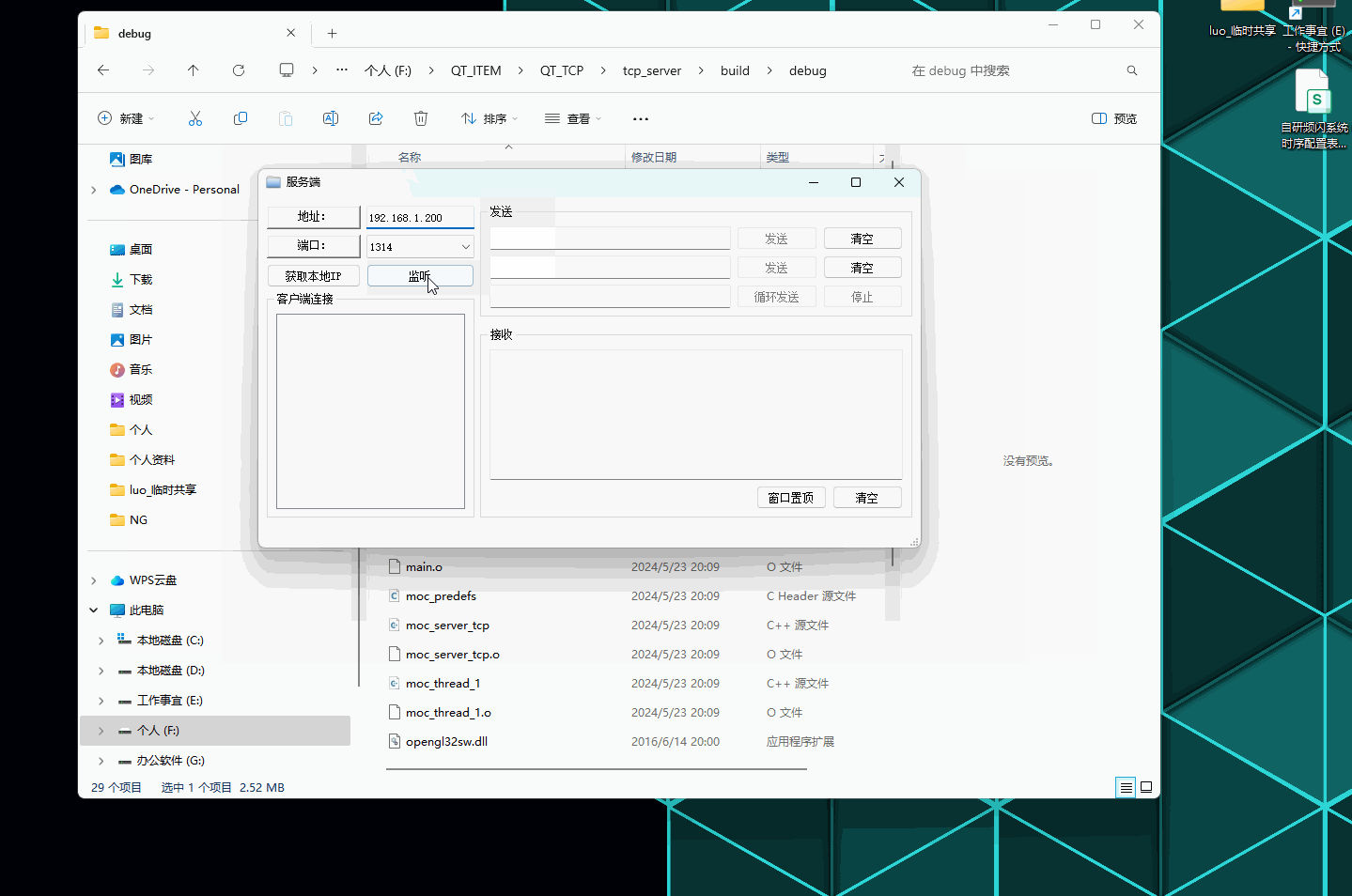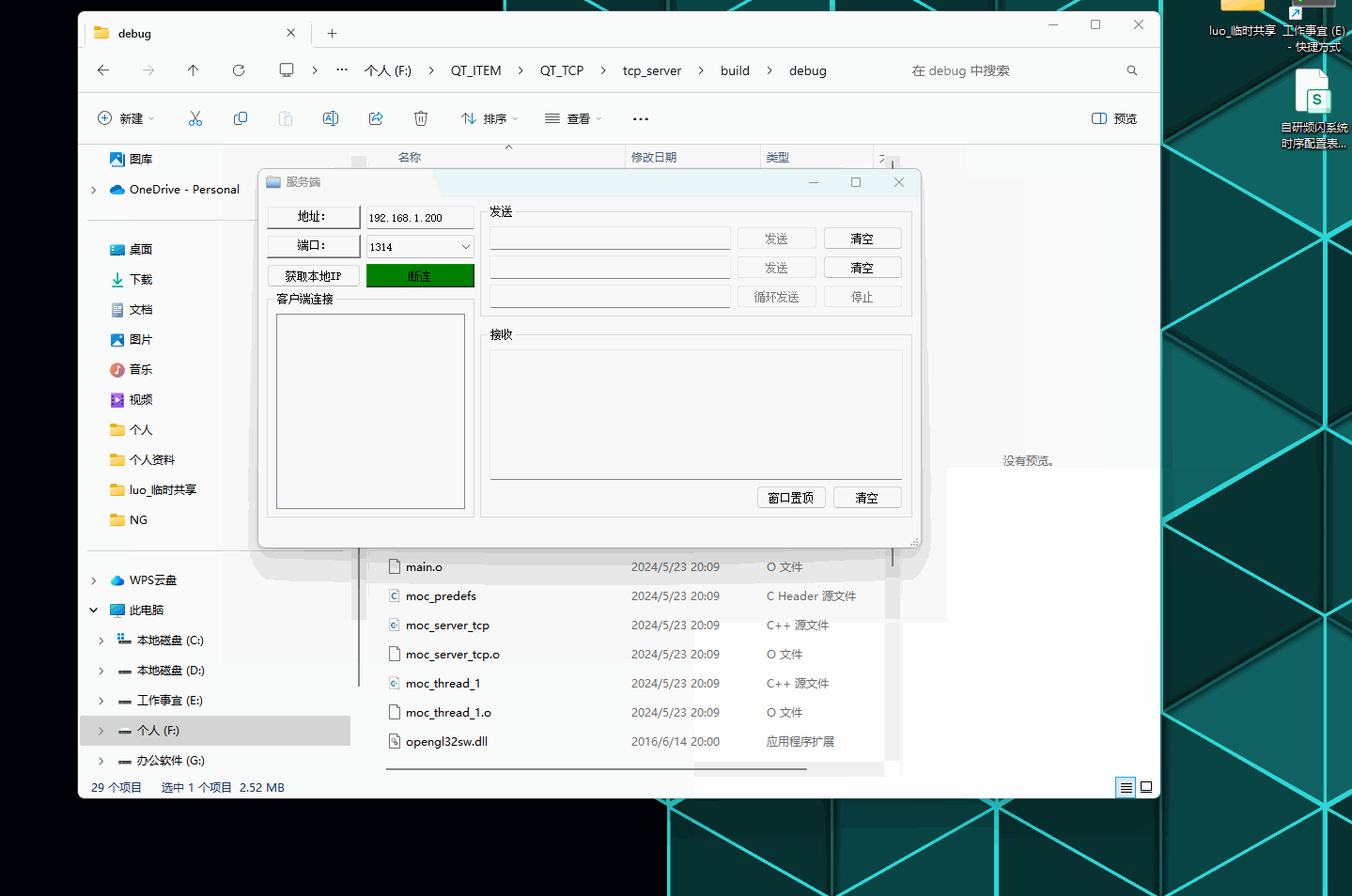
QT--TCP网络通讯工具编写记录
QT–TCP网络通讯工具编写记录 文章目录 QT--TCP网络通讯工具编写记录前言演示如下:一、服务端项目文件:【1.1】server_tcp.h 服务端声明文件【1.2】thread_1.h 线程处理声明文件【1.3】main.cpp 执行源文件【1.4】server_tcp.cpp 服务端逻辑实现源文件【…...

如何解决爬虫的IP地址受限问题?
使用代理IP池、采用动态IP更换策略、设置合理的爬取时间间隔和模拟正常用户行为,是解决爬虫IP地址受限问题的主要策略。代理IP池是通过集合多个代理IP来分配爬虫任务,从而避免相同的IP地址对目标网站进行高频次访问,减少被目标网站封禁的风险…...

harmony 文件上传
图片上传 1, 获取文件,这里指的是图片 在鸿蒙内部有一个API pick选择器,实现文件保存和文件选择的功能, 使用pick对象创建PhotoViewPicker实例 传入必要的参数,如选择图片的数量,和弹出窗口的位置…...

什么是安全左移如何实现安全左移
文章目录 一、传统软件开发面临的安全挑战二、什么是安全左移四、安全左移与安全开发生命周期(SDL)三、安全左移对开发的挑战五、从DevOps到DevSecOps六、SDL与DevSecOps 一、传统软件开发面临的安全挑战 传统软件开发面临的安全挑战主要包括以下几个方…...

将PCD点云投影到BEV平面得到图片
前言 点云数据作为一种丰富的三维空间信息表达方式,通常用于自动驾驶、机器人导航和三维建模等领域。然而,点云数据的直观性不如二维图像,这限制了它在一些需要快速视觉反馈的应用场景中的使用。本文将探讨如何将点云数据转换为二维图像&…...
)
计算机笔记14(续20个)
230.色彩的种类就是色相 饱和度就是彩度除以明度 231.RISC是精简指令集,CISC是复杂指令集 232.世界上第一台数字计算机,奠定了至今仍在使用计算机体系结构 233.数据传输中,电路交换的传输延迟最小 234.定点整数的小数点约定在最低…...

docker 使用桥接网
在Docker中使用桥接网络,你可以创建一个新的桥接网络或者使用默认的桥接网络(如果已经存在的话)。以下是创建新桥接网络和连接容器到这个网络的示例命令: 1.创建一个新的桥接网络(如果你想创建一个新的)&a…...

1金融风控相关业务介绍
金融风控相关业务介绍 学习目标 知道常见信贷风险知道机器学习风控模型的优势知道信贷领域常用术语含义1 信贷&风控介绍 信贷业务,就是贷款业务,是商业银行和互联网金融公司最重要的资产业务和主要赢利手段 通过放款收回本金和利息,扣除成本后获得利润。贷款平台预测有…...

521源码-免费教程-经常用到的Vue.js的Vue@Cli入门指导
更多网站源码学习教程,请点击👉-521源码-👈获取最新资源:521源码-网站源码-资源素材-免费下载 Vue.js是一款流行的JavaScript框架,它使得构建交互式的Web界面变得简单和快捷。VueCli是Vue.js官方提供的脚手架工具&…...

大数据技术原理(二):搭建hadoop伪分布式集群这一篇就够了
(实验一 搭建hadoop伪分布式) -------------------------------------------------------------------------------------------------------------------------------- 一、实验目的 1.理解Hadoop伪分布式的安装过程 实验内容涉及Hadoop平台的搭建和…...

中间件是什么?信创中间件有哪些牌子?哪家好用?
当今社会,中间件的重要性日益凸显,尤其是在信创背景下,选择适合的中间件产品对于推动企业数字化转型和升级具有重要意义。今天我们就来聊聊中间件是什么?信创中间件有哪些牌子?哪家好用?仅供参考哈…...

python实现520表白图案
今天是520哦,作为程序员有必要通过自己的专业知识来向你的爱人表达下你的爱意。那么python中怎么实现绘制520表白图案呢?这里给出方法: 1、使用图形库(如turtle) 使用turtle模块,你可以绘制各种形状和图案…...
【Linux】-Flink分布式内存计算集群部署[21]
注意: 本节的操作,需要前置准备好Hadoop生态集群,请先部署好Hadoop环境 简介 Flink同spark一样,是一款分布式内存计算引擎,可以支撑海量数据的分布式计算 Flink在大数据体系同样是明星产品,作为新一代的…...
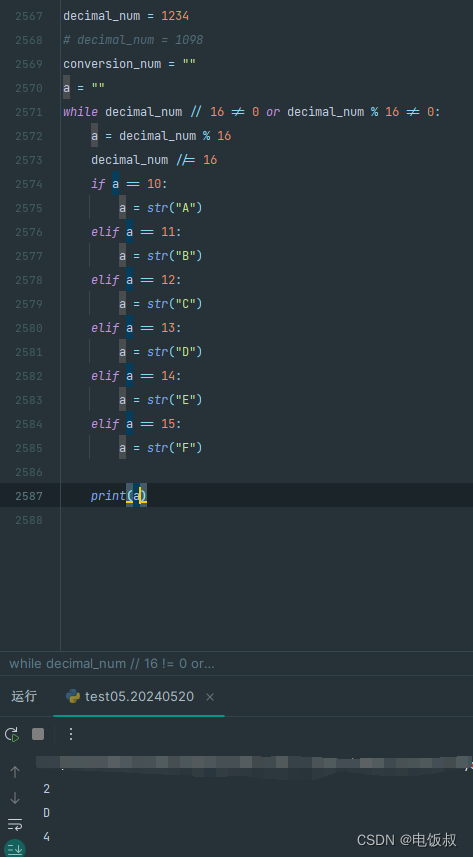
《python程序语言设计》2018版第5章第44题利用python循环进行十进制变十六进制,依然是44题的旧问题。倒着打出来的16进制
它似乎也有上一道题同样道问题。就是结果可能是倒着的。我还不能用超纲的办法。似乎上一个问题的难点又传到了下面 note: 我建立了一个method_a的变量干脆把整数除16的第一次放到循环外。 这样是不是可以解决呢? 我感觉还是在整除和除于的概念中,没有解脱…...

【HarmonyOS4学习笔记】《HarmonyOS4+NEXT星河版入门到企业级实战教程》课程学习笔记(九)
课程地址: 黑马程序员HarmonyOS4NEXT星河版入门到企业级实战教程,一套精通鸿蒙应用开发 (本篇笔记对应课程第 16 节) P16《15.ArkUI-状态管理-任务统计案例》 1、实现任务进度卡片 怎么让进度条和进度展示文本堆叠展示࿱…...

海山数据库(He3DB)数据仓库发展历史与架构演进:(一)传统数仓
从1990年代Bill Inmon提出数据仓库概念后经过四十多的发展,经历了早期的PC时代、互联网时代、移动互联网时代再到当前的云计算时代,但是数据仓库的构建目标基本没有变化,都是为了支持企业或者用户的决策分析,包括运营报表、企业营…...

开发者专属提示词库:提升AI协作效率的实战指南
1. 项目概述:一个为开发者量身定制的提示词宝库如果你是一名开发者,无论是前端、后端、运维还是算法工程师,我相信你都或多或少地接触过像 ChatGPT 这类大型语言模型。它们能写代码、解 Bug、解释概念,甚至帮你设计架构。但很多时…...

保姆级教程:用CH34xSerCfg修改USB转串口芯片的VID/PID,解决驱动冲突和串口号固定问题
嵌入式开发实战:用CH34xSerCfg定制USB转串口设备标识与驱动管理 当你的工作台上同时连接着五个相同型号的USB转TTL模块,Windows设备管理器里COM端口像走马灯一样随机变换编号时;当团队协作开发中,每个成员需要固定识别自己的调试设…...

SOCD Cleaner终极指南:彻底解决游戏键盘方向冲突的免费开源神器
SOCD Cleaner终极指南:彻底解决游戏键盘方向冲突的免费开源神器 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 还在为格斗游戏中同时按下W和S导致角色卡顿而烦恼吗?或者在射击游戏急停转…...

Touchpoint:命令行工具集中管理工作上下文,提升开发效率
1. 项目概述:一个被低估的开发者效率工具如果你和我一样,日常开发工作需要在多个代码仓库、项目管理工具(如Jira、Linear)、文档平台(如Confluence、Notion)和沟通软件(如Slack)之间…...

5大优势解析:如何高效使用免费离线OCR工具
5大优势解析:如何高效使用免费离线OCR工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 项目…...

荣品RV1126 SDK编译避坑指南:从环境配置到分区调整,手把手解决常见编译错误
RV1126 SDK编译实战:从环境搭建到分区优化的全流程解决方案 1. 开发环境配置与初始化 RV1126开发环境的搭建是整个开发流程的第一步,也是后续所有工作的基础。一个稳定、高效的开发环境能够显著提升开发效率,减少不必要的错误。 首先需要确保…...

Windows驱动清理终极指南:用DriverStore Explorer安全释放数十GB磁盘空间
Windows驱动清理终极指南:用DriverStore Explorer安全释放数十GB磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你的Windows电脑是否经常提示C盘空间不足ÿ…...

平衡车PID积分饱和问题
你发现了PID最致命的坑! 你说的完全正确:积分(Ki)是累加的,会无限叠加,直接让PWM爆掉、车猛冲、失控! 这就是积分饱和 —— 99%初学者死在这里。 我现在彻底讲透积分为什么炸、怎么修复、平衡车…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十四)用户指引自助教学源码—东方仙盟
软件教学引导功能说明书未来之窗昭和仙君 - cyberwin_fairyalliance_webquery一、功能概述软件教学引导功能主要用于为用户提供软件操作的引导,通过一系列步骤逐步引导用户完成软件的重要操作。该功能会创建遮罩层、高亮框和提示框,引导用户点击特定元素…...

从二维到三维:DIY LED视频立方体构建全攻略
1. 项目概述:从平面到立体的视觉革命几年前,当我第一次成功点亮一整面由32x32 RGB LED面板组成的视频墙时,那种由1024个像素点共同编织出的动态画面所带来的震撼,至今记忆犹新。但作为一个热衷于将技术推向边界的创作者࿰…...