H800基础能力测试
H800基础能力测试
- 参考链接
- A100、A800、H100、H800差异
- H100详细规格
- H100 TensorCore FP16 理论算力计算公式
- 锁频
- 安装依赖
- pytorch FP16算力测试
- cublas FP16算力测试
- 运行cuda-samples
本文记录了H800基础测试步骤及测试结果
参考链接
- NVIDIA H100 Tensor Core GPU Architecture
- How to calculate the Tensor Core FP16 performance of H100?
- NVIDIA H100 PCIe 80 GB
- NVIDIA H800 Tensor Core GPU
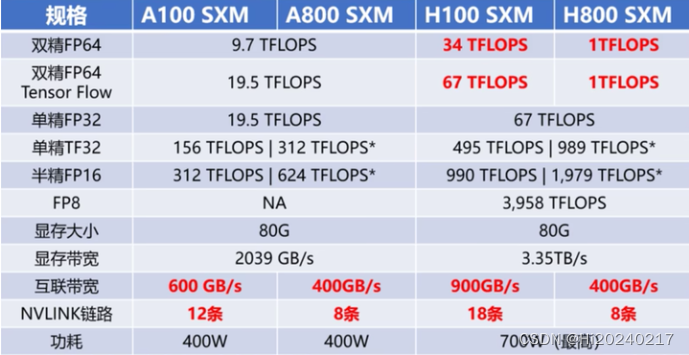
A100、A800、H100、H800差异
H100详细规格
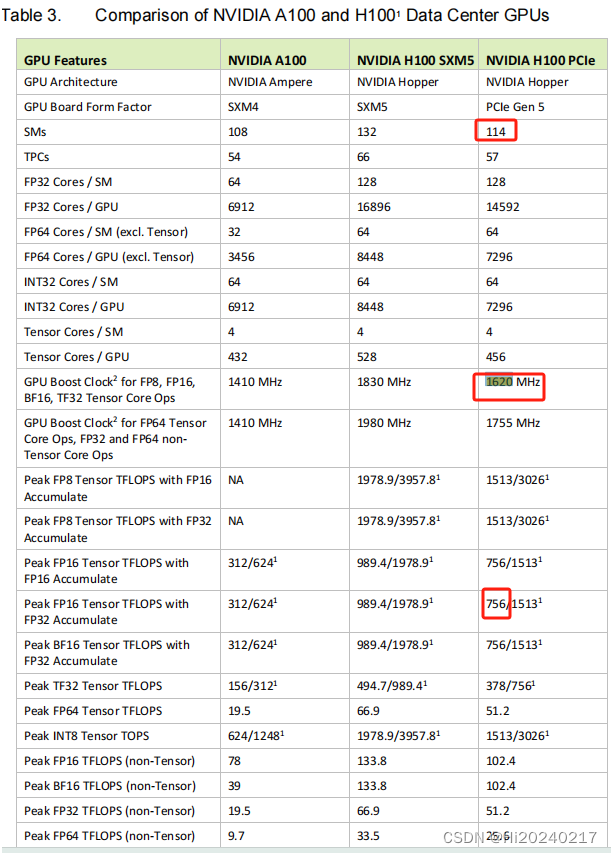
H100 TensorCore FP16 理论算力计算公式
- 4096 FLOP/clk per SM.
- The H100 PCIE has 114 SMs
- 114 x 4096 = 466944 FLOP/clk
- BoostClock:1620MHz
- 114 x 4096 x1620M/1000/1000=756 TFLOPS
- 当前的卡最大频率为1980–> 114 x 4096 x1980M/1000/1000=924 TFLOPS
锁频
nvidia-smi -q -d SUPPORTED_CLOCKS
nvidia-smi -lgc 1980,1980
nvidia-smi --lock-memory-clocks-deferred=2619
安装依赖
pip3 install https://github.com/cupy/cupy/releases/download/v13.1.0/cupy_cuda12x-13.1.0-cp310-cp310-manylinux2014_x86_64.whl
pip3 install pycuda
pytorch FP16算力测试
tee torch_flops.py <<-'EOF'
import pycuda.autoinit
import pycuda.driver as cuda
import torch
import timedef benchmark_pytorch_fp16(M,N,K, num_runs):# 确保使用 GPU 并设置数据类型为半精度浮点数 (float16)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')dtype = torch.float16# 生成随机矩阵A = torch.randn((M, K), device=device, dtype=dtype)B = torch.randn((K, N), device=device, dtype=dtype) # 预热 GPU,进行一次矩阵乘法C = torch.matmul(A, B) # 记录开始时间start_time = time.time() # 多次进行矩阵乘法,计算 FLOPSstart = cuda.Event()end = cuda.Event()start.record() for _ in range(num_runs):C = torch.mm(A, B) end.record()torch.cuda.synchronize() elapsed_time = start.time_till(end) / num_runs # 计算 GFLOPSnum_operations = 2 * M*N*Kgflops = num_operations / (elapsed_time * 1e-3) / 1e12 return elapsed_time, gflops# 记录结束时间end_time = time.time() # 计算平均运行时间elapsed_time = (end_time - start_time) / num_runs # 计算总的 FLOPstotal_flops = 2 * M*K*N # 计算 GFLOPSgflops = total_flops / elapsed_time / 1e12 return elapsed_time, gflops
# 设置矩阵大小和运行次数
num_runs = 32
M=2048
N=2048
K=40960
for i in range(5):# 运行基准测试elapsed_time, gflops = benchmark_pytorch_fp16(M,N,K, num_runs)# 输出结果print(f"Num:{i} 矩阵乘法大小: {M}x{K}X{N} 平均运行时间: {elapsed_time:.6f} 秒 TFLOPS: {gflops:.2f}")time.sleep(0.1)
EOF
python3 torch_flops.py
输出(790/924=85%)
Num:0 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.441580 秒 TFLOPS: 778.11
Num:1 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.430380 秒 TFLOPS: 798.36
Num:2 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.430523 秒 TFLOPS: 798.09
Num:3 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.430742 秒 TFLOPS: 797.69
Num:4 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.430283 秒 TFLOPS: 798.54
cublas FP16算力测试
tee cublas_flops.py <<-'EOF'
import cupy as cp
import numpy as np
from cupy._core import _dtype
from cupy.cuda import cublas
from time import time
from ctypes import c_void_p, c_float, cast, pointer, byref
import pycuda.autoinit
import pycuda.driver as cudadef cublas_fp16_strided_batched_gemm(M,N,K, batch_size, num_runs):# 创建随机半精度矩阵并转换为 CuPy 数组cp.cuda.Device(0).use()A = cp.random.randn(batch_size, M, K).astype(cp.float16)B = cp.random.randn(batch_size, K, N).astype(cp.float16)C = cp.empty((batch_size, M, N), dtype=cp.float16)# 创建 cuBLAS 句柄handle = cublas.create() # 标量 alpha 和 betaalpha = np.array(1, dtype=np.float16)beta = np.array(0, dtype=np.float16) cublas.setMathMode(handle, cublas.CUBLAS_TENSOR_OP_MATH)algo = cublas.CUBLAS_GEMM_DEFAULT_TENSOR_OP try:# Warm-up (预热)for j in range(1):cublas.gemmStridedBatchedEx(handle,cublas.CUBLAS_OP_N, cublas.CUBLAS_OP_N,M, N, K,alpha.ctypes.data, A.data.ptr,_dtype.to_cuda_dtype(A.dtype,True), M, M * K,B.data.ptr, _dtype.to_cuda_dtype(B.dtype,True), K, K * N,beta.ctypes.data, C.data.ptr, _dtype.to_cuda_dtype(C.dtype,True), M, M * N,batch_size,_dtype.to_cuda_dtype(C.dtype,True), algo)cp.cuda.Device(0).synchronize() # 实际基准测试start = cuda.Event()end = cuda.Event()start.record()start_time = time()for _ in range(num_runs):cublas.gemmStridedBatchedEx(handle,cublas.CUBLAS_OP_N, cublas.CUBLAS_OP_N,M, N, K,alpha.ctypes.data, A.data.ptr,_dtype.to_cuda_dtype(A.dtype,True), M, M * K,B.data.ptr, _dtype.to_cuda_dtype(B.dtype,True), K, K * N,beta.ctypes.data, C.data.ptr, _dtype.to_cuda_dtype(C.dtype,True), M, M * N,batch_size,_dtype.to_cuda_dtype(C.dtype,True), algo)end.record()cp.cuda.Device(0).synchronize()end_time = time() except cp.cuda.runtime.CUDARuntimeError as e:print(f"CUDA 运行时错误: {e}")cublas.destroy(handle)return None, None elapsed_time = start.time_till(end) / num_runs # 计算 GFLOPSnum_operations = 2 * M*N*K*batch_sizegflops = num_operations / (elapsed_time * 1e-3) / 1e12 return elapsed_time, gflops elapsed_time = (end_time - start_time) / num_runsnum_ops = 2*M*K*N*batch_sizegflops = num_ops / elapsed_time / 1e12 cublas.destroy(handle) return elapsed_time, gflops
num_runs = 32
M=2048
N=2048
K=40960
matrix_size = 1
for i in range(5):elapsed_time, gflops = cublas_fp16_strided_batched_gemm(M,N,K,matrix_size,num_runs)print(f"Num:{i} 矩阵乘法大小: {M}x{K}X{N} 平均运行时间: {elapsed_time:.6f} 秒 TFLOPS: {gflops:.2f}")
EOF
python3 cublas_flops.py
输出(817/924=88%)
Num:0 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.421070 秒 TFLOPS: 816.01
Num:1 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.420407 秒 TFLOPS: 817.30
Num:2 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.420305 秒 TFLOPS: 817.50
Num:3 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.420304 秒 TFLOPS: 817.50
Num:4 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.420554 秒 TFLOPS: 817.01
运行cuda-samples
git clone https://www.github.com/nvidia/cuda-samples
cd cuda-samples/Samples/1_Utilities/deviceQuery
make clean && make
./deviceQuery
cd ../bandwidthTest/
make clean && make
./bandwidthTest
cd ../../4_CUDA_Libraries/batchCUBLAS/
make clean && make
./batchCUBLAS -m8192 -n8192 -k8192 --device=0
输出
Device 0: "NVIDIA H800"CUDA Driver Version / Runtime Version 12.2 / 12.2CUDA Capability Major/Minor version number: 9.0Total amount of global memory: 81008 MBytes (84942979072 bytes)(132) Multiprocessors, (128) CUDA Cores/MP: 16896 CUDA CoresGPU Max Clock rate: 1980 MHz (1.98 GHz)Memory Clock rate: 2619 MhzMemory Bus Width: 5120-bitL2 Cache Size: 52428800 bytesMaximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layersMaximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layersTotal amount of constant memory: 65536 bytesTotal amount of shared memory per block: 49152 bytesTotal shared memory per multiprocessor: 233472 bytesTotal number of registers available per block: 65536Warp size: 32Maximum number of threads per multiprocessor: 2048Maximum number of threads per block: 1024Max dimension size of a thread block (x,y,z): (1024, 1024, 64)Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)Maximum memory pitch: 2147483647 bytesTexture alignment: 512 bytesConcurrent copy and kernel execution: Yes with 3 copy engine(s)Run time limit on kernels: NoIntegrated GPU sharing Host Memory: NoSupport host page-locked memory mapping: YesAlignment requirement for Surfaces: YesDevice has ECC support: EnabledDevice supports Unified Addressing (UVA): YesDevice supports Managed Memory: YesDevice supports Compute Preemption: YesSupports Cooperative Kernel Launch: YesSupports MultiDevice Co-op Kernel Launch: YesDevice PCI Domain ID / Bus ID / location ID: 0 / 215 / 0Compute Mode:< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
-----------------------------------------------------------------------------------------------------[CUDA Bandwidth Test] - Starting...
Running on...Device 0: NVIDIA H800Quick ModeHost to Device Bandwidth, 1 Device(s)PINNED Memory TransfersTransfer Size (Bytes) Bandwidth(GB/s)32000000 55.2Device to Host Bandwidth, 1 Device(s)PINNED Memory TransfersTransfer Size (Bytes) Bandwidth(GB/s)32000000 55.3Device to Device Bandwidth, 1 Device(s)PINNED Memory TransfersTransfer Size (Bytes) Bandwidth(GB/s)32000000 2085.3Result = PASS-----------------------------------------------------------------------------------------------------==== Running single kernels ====Testing sgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0xbf800000, -1) beta= (0x40000000, 2)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 0.04317784 sec GFLOPS=25464.7
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0x0000000000000000, 0) beta= (0x0000000000000000, 0)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 0.00023699 sec GFLOPS=4.63952e+06
@@@@ dgemm test OK==== Running N=10 without streams ====Testing sgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0xbf800000, -1) beta= (0x00000000, 0)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 0.22819090 sec GFLOPS=48183.9
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 11.56301594 sec GFLOPS=950.887
@@@@ dgemm test OK==== Running N=10 with streams ====Testing sgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0x40000000, 2) beta= (0x40000000, 2)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 0.23047590 sec GFLOPS=47706.1
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 11.38687706 sec GFLOPS=965.595
@@@@ dgemm test OK==== Running N=10 batched ====Testing sgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0x3f800000, 1) beta= (0xbf800000, -1)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 0.21581888 sec GFLOPS=50946
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0xbff0000000000000, -1) beta= (0x4000000000000000, 2)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 11.38980007 sec GFLOPS=965.348
@@@@ dgemm test OKTest Summary
0 error(s)
相关文章:
H800基础能力测试
H800基础能力测试 参考链接A100、A800、H100、H800差异H100详细规格H100 TensorCore FP16 理论算力计算公式锁频安装依赖pytorch FP16算力测试cublas FP16算力测试运行cuda-samples 本文记录了H800基础测试步骤及测试结果 参考链接 NVIDIA H100 Tensor Core GPU Architecture…...

2024/5/24 Day38 greedy 435. 无重叠区间 763.划分字母区间 56. 合并区间
2024/5/24 Day38 greedy 435. 无重叠区间 763.划分字母区间 56. 合并区间 遇到两个维度权衡的时候,一定要先确定一个维度,再确定另一个维度。如果两个维度一起考虑一定会顾此失彼。 重叠区间问题 435. 无重叠区间 题目链接 435 给定一个区间的集合 i…...

【python】使用函数名而不加括号是什么情况?
使用函数名而不加括号通常是为了表示对函数本身的引用,而不是调用函数。这种用法通常出现在下面这几种情况: 作为回调函数传递:将函数名作为参数传递给其他函数,以便在需要时调用该函数。例如,在事件处理程序或高阶函数…...

全文检索ElasticSearch简介
1 全文检索 1.1 什么是全文检索 全文检索是一种通过对文本内容进行全面索引和搜索的技术。它可以快速地在大量文本数据中查找包含特定关键词或短语的文档,并返回相关的搜索结果。全文检索广泛应用于各种信息管理系统和应用中,如搜索引擎、文档管理系统、电子邮件客户端、新闻…...
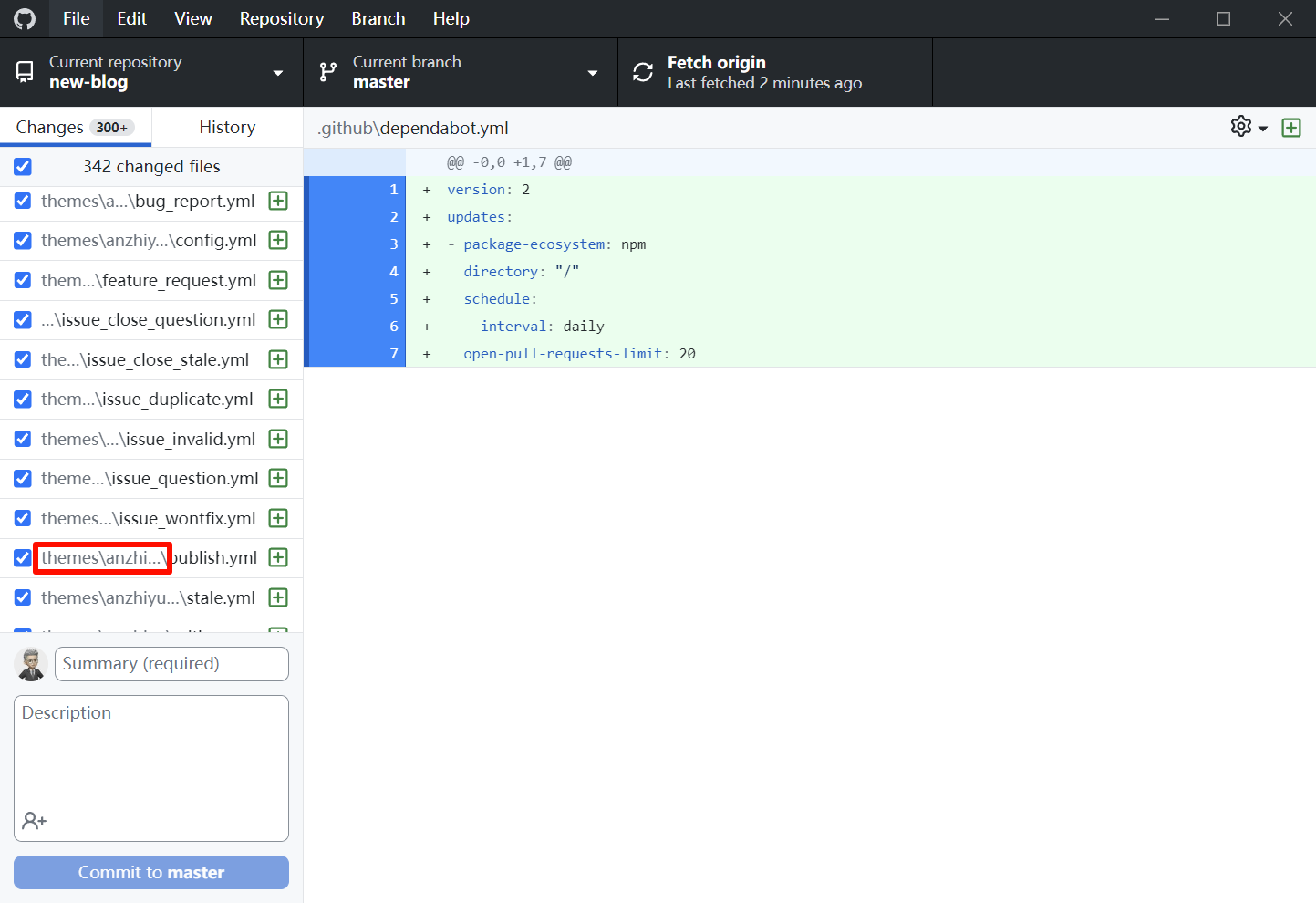
Github上传时报错The file path is empty的解决办法
问题截图 文件夹明明不是空的,却怎么都上传不上去。 解决方案: 打开隐藏文件的开关,删除原作者的.git文件 如图所示: 上传成功!...
Adobe Bridge BR v14.0.3 安装教程 (多媒体文件组织管理工具)
Adobe系列软件安装目录 一、Adobe Photoshop PS 25.6.0 安装教程 (最流行的图像设计软件) 二、Adobe Media Encoder ME v24.3.0 安装教程 (视频和音频编码渲染工具) 三、Adobe Premiere Pro v24.3.0 安装教程 (领先的视频编辑软件) 四、Adobe After Effects AE v24.3.0 安装…...

嵌入式学习——3——TCP-UDP 数据交互,握手,挥手
1、更新源 cd /etc/apt/ sudo cp sources.list sources.list.save 将原镜像备份 sudo vim sources.list 将原镜像修改成阿里源/清华源,如所述 阿里源 deb http://mirrors.aliyun.com/ubuntu/ bionic main …...

【LeetCode】【3】无重复字符的最长子串(1113字)
文章目录 [toc]题目描述样例输入输出与解释样例1样例2样例3 提示Python实现滑动窗口 个人主页:丷从心 系列专栏:LeetCode 刷题指南:LeetCode刷题指南 题目描述 给定一个字符串s,请你找出其中不含有重复字符的最长子串的长度 样…...

溪谷联运SDK功能全面解析
近期,备受用户关注的手游联运10.0.0版本上线了,不少用户也选择了版本更新,其中也再次迎来了SDK的更新。溪谷软件和大家一起盘点一下溪谷SDK的功能都有哪些吧。 一、溪谷SDK具有完整的运营功能和高度扩展性 1.登录:登录是SDK最基础…...

Vitis HLS 学习笔记--控制驱动TLP - Dataflow视图
目录 1. 简介 2. 功能特性 2.1 Dataflow Viewer 的功能 2.2 Dataflow 和 Pipeline 的区别 3. 具体演示 4. 总结 1. 简介 Dataflow视图,即数据流查看器。 DATAFLOW优化属于一种动态优化过程,其完整性依赖于与RTL协同仿真的完成。因此,…...

蓝桥杯物联网竞赛_STM32L071KBU6_关于sizo of函数产生的BUG
首先现象是我在用LORA发送信息的时候,左边显示长度是8而右边接收到的数据长度却是4 我以为是OLED显示屏坏了,又或者是我想搞创新用了const char* 类型强制转换数据的原因,结果发现都不是 void Function_SendMsg( unsigned char* data){unsi…...
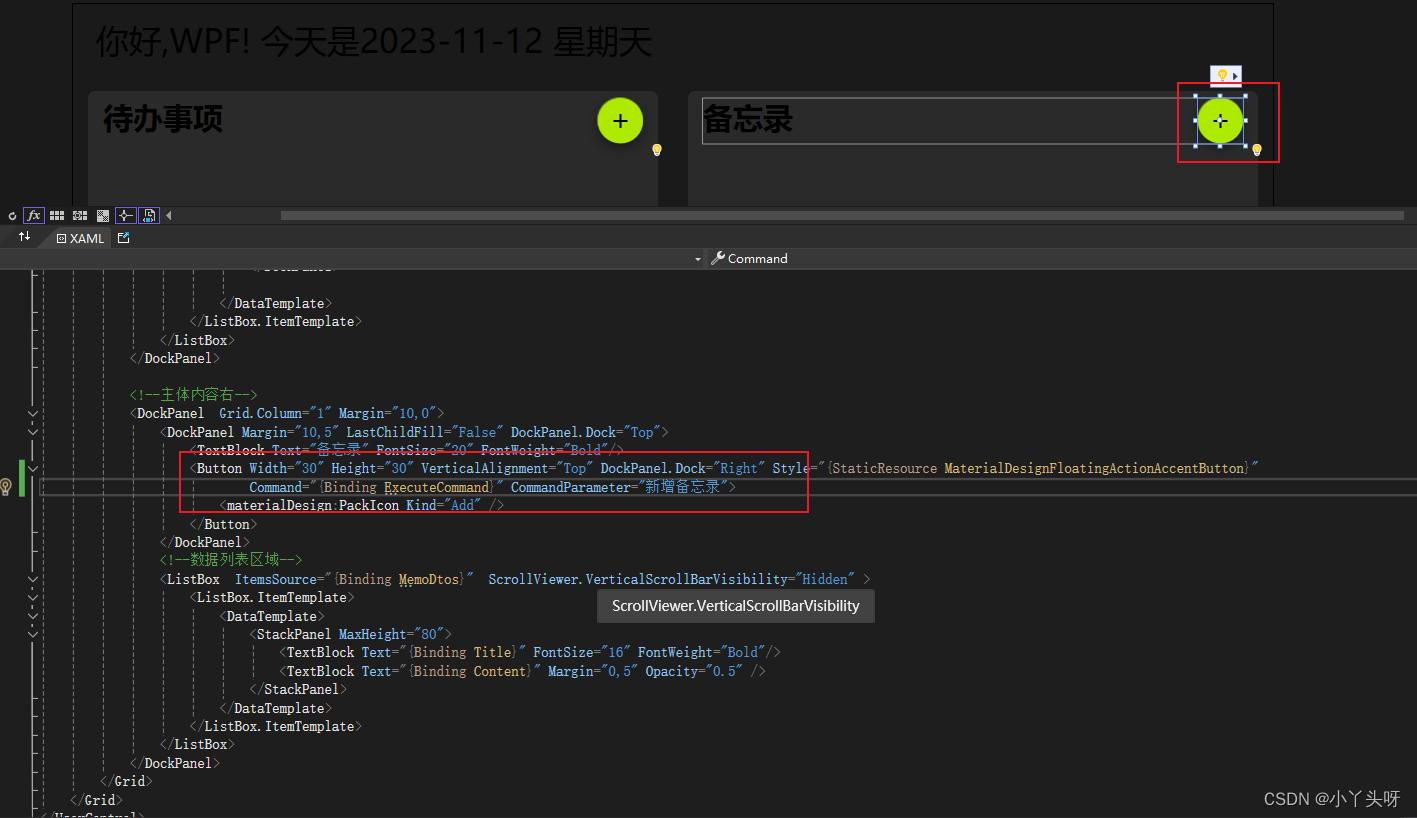
Wpf 使用 Prism 实战开发Day22
客户端添加IDialogService 弹窗服务 在首页点击添加备忘录或待办事项按钮的时候,希望有一个弹窗,进行相对应的内容添加操作。 一.在Views文件夹中,再创建一个Dialog 文件夹,用于放置备忘录和待办事项的弹窗界面。 1.1 备忘录&…...

遍历列表
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 遍历列表中的所有元素是常用的一种操作,在遍历的过程中可以完成查询、处理等功能。在生活中,如果想要去商场买一件衣服&#…...
创建vue工程、Vue项目的目录结构、Vue项目-启动、API风格
环境准备 介绍:create-vue是Vue官方提供的最新的脚手架工具,用于快速生成一个工程化的Vue项目create-vue提供如下功能: 统一的目录结构 本地调试 热部署 单元测试 集成打包依赖环境:NodeJS 安装NodeJS 一、 创建vue工程 npm 类…...

为了更全面地分析开发人员容易被骗的原因和提供更加深入的防范措施
为了更全面地分析开发人员容易被骗的原因和提供更加深入的防范措施,我们可以进一步探讨以下几个方面: 深入技术细节 不安全的代码注释和文档: 原因:开发人员在代码注释中可能会无意间透露敏感信息,如API密钥、密码或系…...
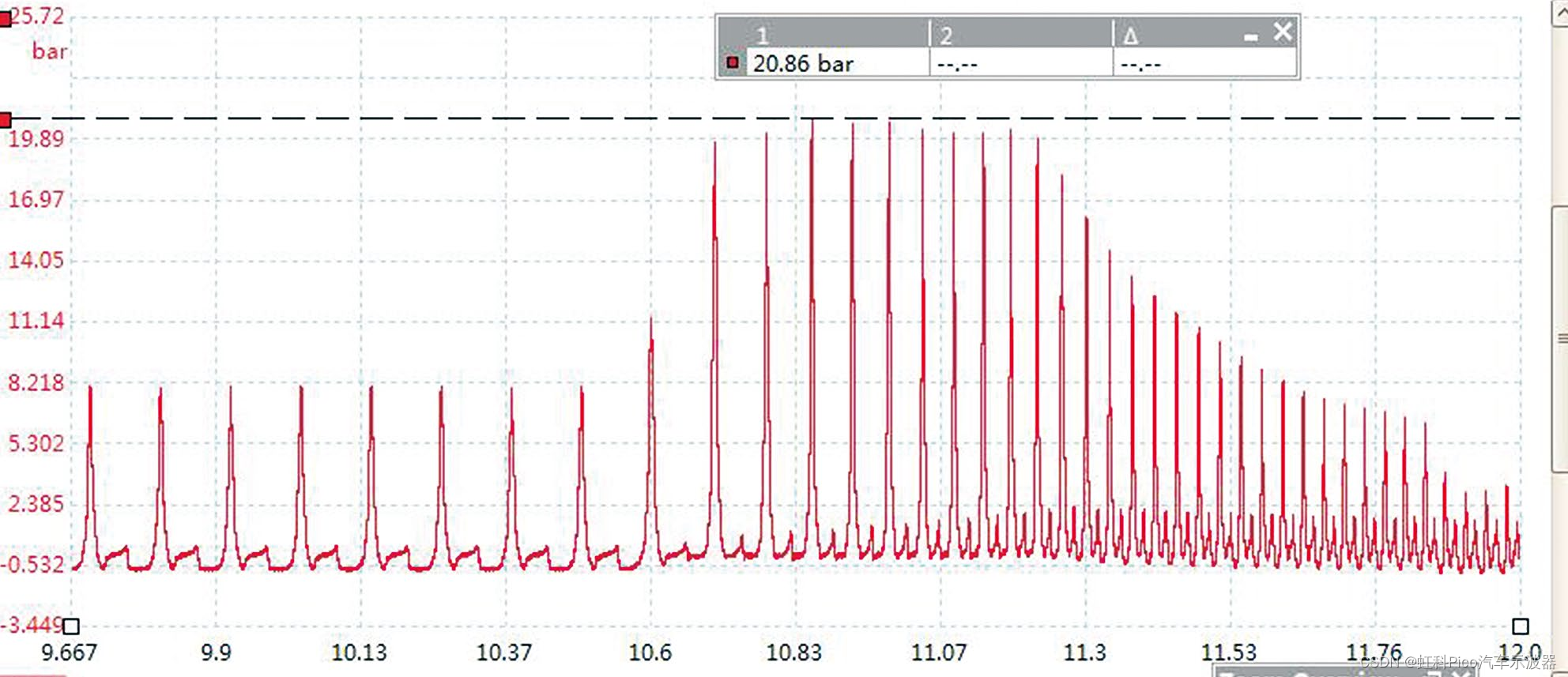
虹科Pico汽车示波器 | 免拆诊断案例 | 2020款奔驰G350车行驶中急加速时发动机抖动
故障现象 一辆2020款奔驰G350车,搭载264 920 发动机,累计行驶里程约为2.8万km。车主反映,行驶中急加速超车时发动机抖动,同时发动机故障灯闪烁,发动机加速无力。 故障诊断 接车后反复试车发现,故障只在…...

大模型落地竞逐,云计算大厂“百舸争流”
作者 | 辰纹 来源 | 洞见新研社 从ChatGPT到Sora,从图文到视频,从通用大模型到垂直大模型……经过了1年多时间的探索,大模型进入到以落地为先的第二阶段。 行业的躁动与资本的狂热相交汇,既造就了信仰派的脚踏实地,也…...

物体检测算法-R-CNN,SSD,YOLO
物体检测算法-R-CNN,SSD,YOLO 1 R-CNN2 SSD3 Yolo总结 1 R-CNN R-CNN(Region-based Convolutional Neural Network)是一种基于区域的卷积神经网络,是第一个成功将深度学习应用到目标检测上的算法。它主要由三个步骤组…...

区块链开发:区块链软件开发包装相关解析
区块链开发是指设计、构建和维护基于区块链技术的应用程序或系统的过程。区块链是一种分布式账本技术,它通过去中心化的方式记录和验证数据,确保数据的透明性、不可篡改性和安全性。区块链开发者使用各种编程语言和框架来创建这些应用程序。 在加密货币领…...

一个月速刷leetcodeHOT100 day07 轮转数组 除自身以外的乘积 找到字符串中所有字母异位词
轮转数组 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4,5] 向右轮转 3 步: […...

如何免费下载百度文库文档:三步搞定PDF保存的终极指南
如何免费下载百度文库文档:三步搞定PDF保存的终极指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要下载券…...

【人生底稿 28】新疆出差终章:几番波折终汇报,尽兴踏归津门路
三日游玩尽数落幕,忙碌工作正式回归。轻松的闲暇时光悄然收尾,紧绷的工作状态再次上线。整趟新疆之行,在起伏辗转中迎来最终收尾。一、深夜复盘材料,彻夜待汇报游玩结束回到酒店,我没有松懈休息,静下心重新…...

进化算法驱动机械爪设计优化:从原理到EvoClaw项目实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“EvoClaw”。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于“进化算法驱动的机械爪设计优化”的开源项目。简单来说,就是利用计算机…...

终极指南:如何在Mac上免费备份和导出微信聊天记录
终极指南:如何在Mac上免费备份和导出微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而懊恼?或是需要…...

镜像空间全域透视,赋能多维场景一体化透明数智治理技术白皮书
镜像空间全域透视,赋能多维场景一体化透明数智治理技术白皮书副标题:聚合动态三维实时重构、无感厘米级定位、全域跨镜连续追踪、身体指纹生物核验四大自研核心,一站式覆盖楼宇、仓储、硐室全场景透明智能管控前言当下城市建筑楼宇、物资仓储…...

如何快速解密网易云NCM文件:终极免费转换工具指南
如何快速解密网易云NCM文件:终极免费转换工具指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲,…...

解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南
解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 还在为《崩坏:星穹铁道》中重复的…...

Arm Morello平台模型与CHERI安全扩展开发指南
1. Arm Morello平台模型概述Morello是Arm公司推出的实验性处理器架构,基于CHERI(Capability Hardware Enhanced RISC Instructions)安全扩展技术。这个平台模型本质上是一个功能准确的虚拟硬件环境,允许开发者在物理芯片问世前18-…...

认识Python数据包套接字
如你所知,数据包格式套接字(Datagram Sockets)也叫“无连接的套接字”,在代码中使用 SOCK_DGRAM 表示。可以将 SOCK_DGRAM 比喻成高速移动的摩托车快递,它有以下特征:强调快速传输而非传输顺序;…...

AI Agent无障碍审查:自动化集成WCAG标准与axe-core实践
1. 项目概述:一个为AI助手打造的“无障碍”审查官最近在折腾AI应用开发,特别是那些能自动处理任务的智能体(AI Agent),发现一个挺有意思但容易被忽略的问题:我们费尽心思让AI能写代码、分析数据、生成报告&…...