GBDT、XGBoost、LightGBM算法详解
文章目录
- 一、GBDT (Gradient Boosting Decision Tree) 梯度提升决策树
- 1.1 回归树
- 1.2 梯度提升树
- 1.3 Shrinkage
- 1.4 调参
- 1.5 GBDT的适用范围
- 1.6 优缺点
- 二、XGBoost (eXtreme Gradient Boosting)
- 2.1 损失函数
- 2.2 正则项
- 2.3 打分函数计算
- 2.4 分裂节点
- 2.5 算法过程
- 2.6 参数详解
- 2.7 XGBoost VS GBDT
- 三、LightGBM
- 3.1 LightGBM原理
- 3.2 Lightgbm的一些其它特性
一、GBDT (Gradient Boosting Decision Tree) 梯度提升决策树
GBDT是一种迭代的决策树算法,是一种基于boosting增强策略的加法模型,由多棵决策树组成。每次迭代都学习一棵CART树来拟合之前 t − 1 t − 1 t−1 棵树的预测结果与训练样本真实值的残差,最终所有树的结论累加起来做最终答案。GBDT在被提出之初就和SVM一起被认为是泛化能力较强的算法。
XGBoost对GBDT进行了一系列优化,比如损失函数进行了二阶泰勒展开、目标函数加入正则项、支持并行和默认缺失值处理等,在可扩展性和训练速度上有了巨大的提升,但其核心思想没有大的变化。
GBDT主要由三个概念组成:
- Regression Decision Tree(即DT)
- Gradient Boosting(即GB)
- Shrinkage(缩减)
1.1 回归树
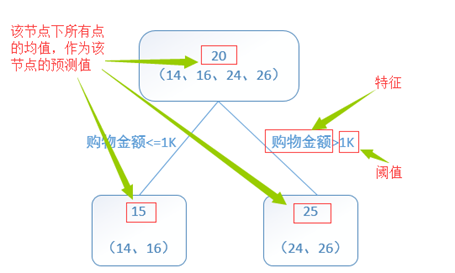
回归树总体流程类似于分类树,区别在于,回归树的每一个节点都会得到一个预测值。以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化平方误差,来找到最可靠的分枝依据。
关于回归树,具体可参考CART中对回归树的介绍:决策树之CART(分类回归树)详解
1.2 梯度提升树
提升树是迭代多棵回归树来共同决策。当采用平方误差损失函数时,每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树。残差的意义如公式:残差 = 真实值 - 预测值。
GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。
举个例子:训练一个提升树模型来预测年龄。简单起见训练集只有4个人,A,B,C,D,他们的年龄分别是14,16,24,26。其中A、B分别是高一和高三学生;C,D分别是应届毕业生和工作两年的员工。如果是用一棵传统的回归决策树来训练,会得到如下图1所示结果:
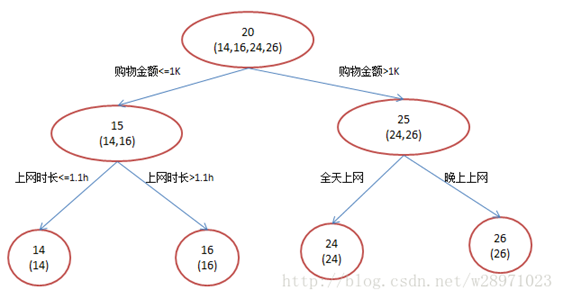
现在我们使用GBDT来训练,由于数据太少,我们限定叶子节点最多有两个,即每棵树都只有一个分枝,并且限定只学两棵树。我们会得到如下图2所示结果:
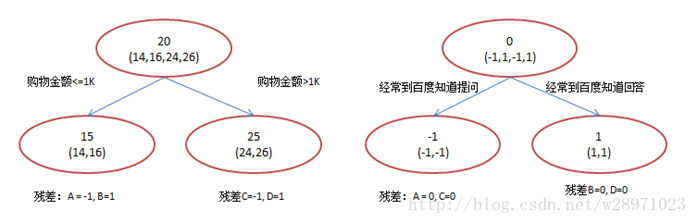
在第一棵树分枝和图1一样,由于A,B年龄较为相近,C,D年龄较为相近,他们被分为两拨,每拨用平均年龄作为预测值。A,B,C,D的残差分别为-1,1,-1,1。然后我们拿残差替代A,B,C,D的原值,到第二棵树去学习,如果我们的预测值和它们的残差相等,则只需把第二棵树的结论累加到第一棵树上就能得到真实年龄了。第二棵树只有两个值1和-1,直接分成两个节点。此时所有人的残差都是0,即每个人都得到了真实的预测值。
A: 14岁高一学生,购物较少,经常提问题;预测年龄A = 15 – 1 = 14
B: 16岁高三学生;购物较少,经常回答问题;预测年龄B = 15 + 1 = 16
C: 24岁应届毕业生;购物较多,经常提问题;预测年龄C = 25 – 1 = 24
D: 26岁工作两年员工;购物较多,经常回答问题;预测年龄D = 25 + 1 = 26
为什么要用梯度提升决策树?
我们发现图1为了达到100%精度使用了3个feature(上网时长、时段、网购金额),其中分枝“上网时长>1.1h” 很显然已经过拟合了。用上网时间是不是>1.1小时来判断所有人的年龄很显然是有悖常识的;相对来说图2的boosting虽然用了两棵树,但其实只用了2个feature就搞定了,后一个feature是问答比例,显然图2的依据更靠谱
Boosting的最大好处在于,每一步的残差计算其实变相地增大了分错instance的权重,而已经分对的instance则都趋向于0。这样后面的树就能越来越专注那些前面被分错的instance。
那么哪里体现了Gradient呢?其实回到第一棵树结束时,无论此时的cost function是什么,是均方差还是均差,只要它以误差作为衡量标准,残差向量(-1, 1, -1, 1)都是它的全局最优方向,这就是Gradient。
1.3 Shrinkage
Shrinkage(缩减)认为,每次走一小步逐步逼近的结果要比每次迈一大步逼近结果更加容易避免过拟合。即它不完全信任每一个棵残差树,它认为每棵树只学到了真理的一小部分,累加的时候只累加一小部分,通过多学几棵树弥补不足。即
- 没用Shrinkage时:(yi表示第i棵树上y的预测值, y(1~i)表示前i棵树y的综合预测值)
y(i+1) = 残差(y1~yi), 其中: 残差(y1~yi) = y真实值 - y(1 ~ i)
y(1 ~ i) = SUM(y1, ..., yi)
- Shrinkage不改变第一个方程,只把第二个方程改为:
y(1 ~ i) = y(1 ~ i-1) + step * yi
即Shrinkage仍然以残差作为学习目标,但对于残差学习出来的结果,只累加一小部分(step*残差)逐步逼近目标。step一般都比较小,如0.01~0.001(注意该step非gradient的step),导致各个树的残差是渐变的而不是陡变的。直觉上这也很好理解,不像直接用残差一步修复误差,而是只修复一点点,其实就是把大步切成了很多小步。
本质上,Shrinkage为每棵树设置了一个weight,累加时要乘以这个weight,但和Gradient并没有关系。这个weight就是step。就像Adaboost一样,Shrinkage能减少过拟合发生也是经验证明的,目前还没有看到从理论的证明。
1.4 调参
- 树的个数 100~10000
- 叶子的深度 3~8
- 学习速率 0.01~1
- 叶子上最大节点树 20
- 训练采样比例 0.5~1
- 训练特征采样比例 sqrt(num)
1.5 GBDT的适用范围
该版本GBDT几乎可用于所有回归问题(线性/非线性),相对logistic regression仅能用于线性回归,GBDT的适用面非常广。亦可用于二分类问题(设定阈值,大于阈值为正例,反之为负例)。
1.6 优缺点
(1) 优点:
- 精度高
- 能处理非线性数据
- 能处理多特征类型
- 适合低维稠密数据
(2) 缺点:
- 并行麻烦(因为上下两颗树有联系)
- 多分类的时候 复杂度很大
二、XGBoost (eXtreme Gradient Boosting)
2.1 损失函数
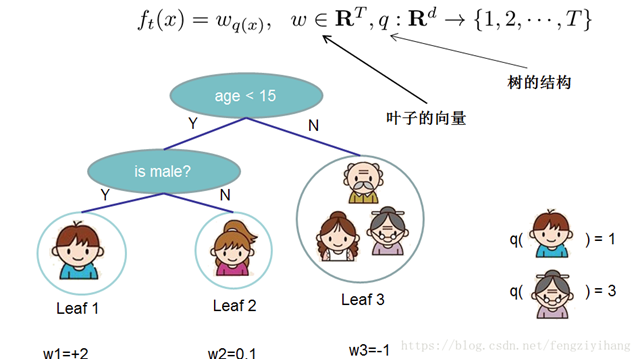
XGBOOST预测函数可表示为:
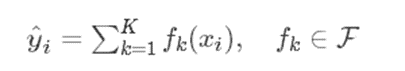
我们使用分部加法,可将此式变换为:

其中K代表迭代K轮,方程左侧为预测值。映射fk如下(其中w为叶子节点的得分,q(xi)代表样本值xi 通过函数q(xi)映射到某个叶子节点):
目标函数:误差函数+正则化

所以目标函数就可变化为: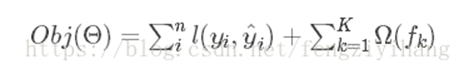
由前面的公式,我们知道:
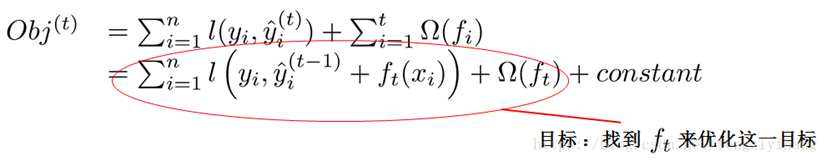
我们可以使用泰勒二阶展开:
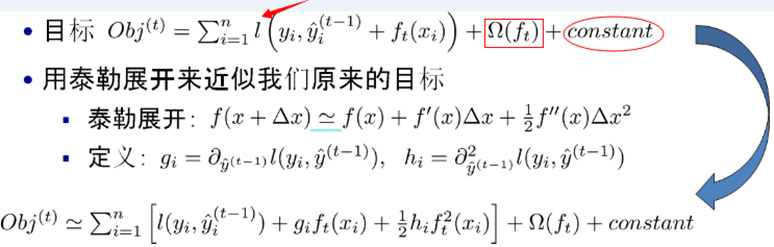
注:红色箭头指向的l为损失函数;红色方框为正则项,包括L1、L2;红色圆圈为常数项。xgboost利用泰勒展开做一个近似。最终的目标函数只依赖于每个数据点的在误差函数上的一阶导数和二阶导数。

2.2 正则项
接下来我们使用L2构建正则化函数:
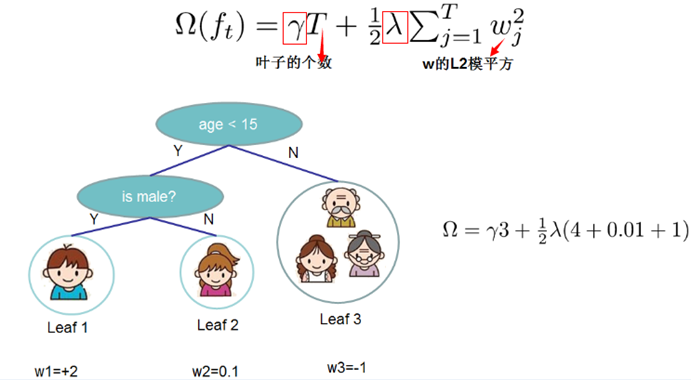
xgboost树的复杂度包含了两个部分:
(1) 叶子节点的个数T
(2) 叶子节点的得分w的L2正则(相当于针对每个叶结点的得分增加L2平滑,目的是为了避免过拟合)
考虑到正则项表达式为: 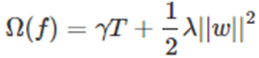
我们可以把之前的目标函数进行如下变形:
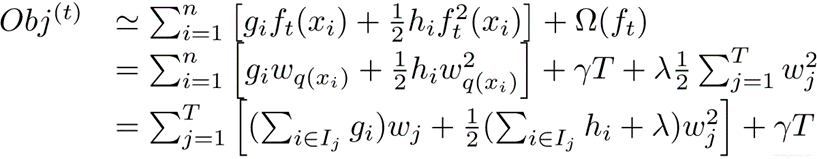
其中g是一阶导数,h是二阶导数。 I j I_j Ij被定义为每个叶节点j上面样本下标的集合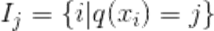 ,q(xi)要表达的是:每个样本值xi 都能通过函数q(xi)映射到树上的某个叶子节点,从而通过这个定义把两种累加统一到了一起。
,q(xi)要表达的是:每个样本值xi 都能通过函数q(xi)映射到树上的某个叶子节点,从而通过这个定义把两种累加统一到了一起。
接着,我们可以定义:
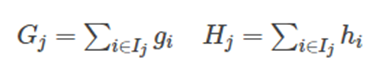
最终公式可以化简为:
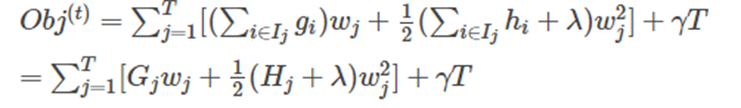
通过对 w j w_j wj 求导等于0,可以得到:
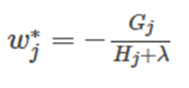
然后把 w j w_j wj 最优解代入得到:
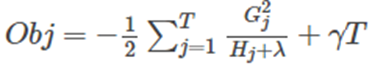
2.3 打分函数计算
Obj代表了当我们指定一个树的结构的时候,我们在目标上面最多减少多少。我们可以把它叫做 结构分数(structure score)。结构分数值越小,代表这个树的结构越好。
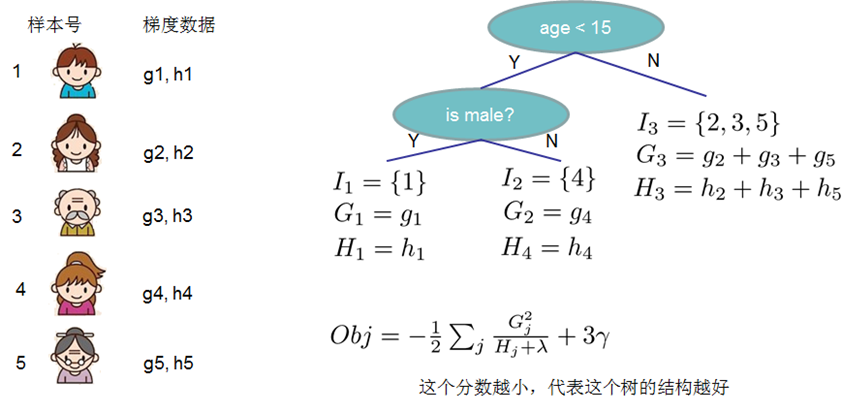
2.4 分裂节点
对于一个叶子节点如何进行分裂,xgboost作者在其原始论文中给出了两种分裂节点的方法
(1) 枚举所有不同树结构的贪心法
不断地枚举不同树的结构,然后利用打分函数来寻找出一个最优结构的树,接着加入到模型中,不断重复这样的操作。利用枚举法来得到最优树结构集合,其结构很复杂,所以通常选择贪心法。从树深度0开始,每一节点都遍历所有的特征,比如年龄、性别等等,然后对于某个特征,先按照该特征里的值进行排序,然后线性扫描该特征进而确定最好的分割点,最后对所有特征进行分割后,我们选择所谓的增益Gain最高的那个特征。
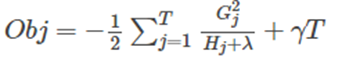
在之前求出的目标函数表达式中,G/(H+λ) 表示着每一个叶子节点对当前模型损失的贡献程度,融合一下,得到Gain的计算表达式,如下所示:
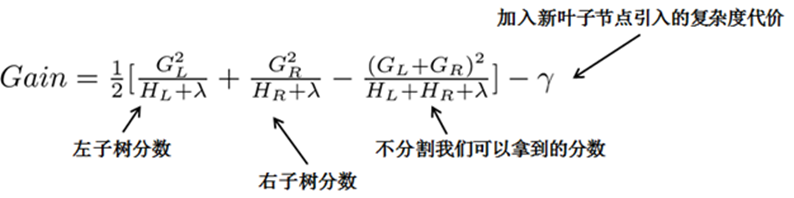
其中GL为原叶节点左儿子的误差函数一阶导数之和;GL为原叶节点右儿子的误差函数一阶导数之和。
例如分裂点a:

但由于又引进了一个新的量复杂度代价,所以增益衡量是否引进行的分裂还有一些问题,我们可以设置一个阀值,小于于阀值不引入新的分裂,大于阀值引入新的分裂。
2.5 算法过程
- 不断地进行特征分裂来生成一棵树。每次添加一棵树,其实是学习一个新函数,去拟合上次预测的残差。
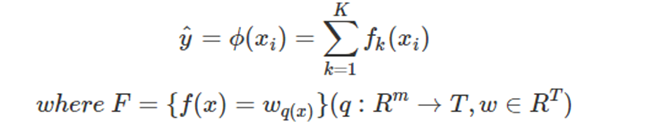
注: W q ( x ) W_{q(x)} Wq(x)为叶子节点q的分数,对应了所有K棵回归树的集合,而f(x)为其中一棵回归树。
-
当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数。
-
最后只需要将每棵树对应的分数加起来就是该样本的预测值。
2.6 参数详解
(1) General Parameters(常规参数)
- booster [default=gbtree]:基分类器。gbtree: tree-based models; gblinear: linear models
- silent [default=0]:设置成1则没有运行信息输出,最好是设置为0.
- nthread [default to maximum number of threads available if not set]:线程数
(2) Booster Parameters(模型参数)
- eta [default=0.3]: shrinkage参数,用于更新叶子节点权重时,乘以该系数,避免步长过大。参数值越大,越可能无法收敛。把学习率eta设置得小一些,小学习率可以使得后面的学习更加仔细。
- min_child_weight [default=1]:这个参数默认是 1,是每个叶子里面h的和至少是多少,对正负样本不均衡时的0-1分类而言,假设h 在0.01附近,min_child_weight为1 意味着叶子节点中最少需要包含100个样本。这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易overfitting。
- max_depth [default=6]: 每颗树的最大深度,树高越深,越容易过拟合。
- max_leaf_nodes: 最大叶结点数,与max_depth作用有点重合。
- gamma [default=0]:后剪枝时,用于控制是否后剪枝的参数。
- max_delta_step [default=0]:这个参数在更新步骤中起作用,如果取0表示没有约束,如果取正值则使得更新步骤更加保守。可以防止做太大的更新步子,使更新更加平缓。
- subsample [default=1]:样本随机采样,较低的值使得算法更加保守,防止过拟合,但是太小的值也会造成欠拟合。
- colsample_bytree [default=1]:列采样,对每棵树的生成用的特征进行列采样。一般设置为:0.5-1
- lambda [default=1]:控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
- alpha [default=0]:控制模型复杂程度的权重值的 L1 正则项参数,参数值越大,模型越不容易过拟合。
- scale_pos_weight [default=1]:如果取值大于0的话,在类别样本不平衡的情况下有助于快速收敛。
(3) Learning Task Parameters(学习任务参数)
-
objective [default=reg:linear]:定义最小化损失函数类型,常用参数:
- binary: logistic – logistic regression for binary classification, returns predicted probability (not class)
- multi: softmax – multiclass classification using the softmax objective, returns predicted class (not probabilities) . You also need to set an additional num_class (number of classes) parameter defining the number of unique classes
- multi: softprob – same as softmax, but returns predicted probability of each data point belonging to each class.
-
eval_metric [default according to objective]:The metric to be used for validation data.
The default values are rmse for regression and error for classification. Typical values are:- rmse – root mean square error
- mae – mean absolute error
- logloss – negative log-likelihood
- error – Binary classification error rate (0.5 threshold)
- merror – Multiclass classification error rate
- mlogloss – Multiclass logloss
- auc: Area under the curve
-
seed [default=0]:
- The random number seed. 随机种子,用于产生可复现的结果
2.7 XGBoost VS GBDT
(1) 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的logistic回归(分类问题)或者线性回归(回归问题)。
(2) 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
(3) xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
(4) Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
(5) 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
(6) 对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
(7) xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点)。xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能。在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
(8) 可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
三、LightGBM
3.1 LightGBM原理
传统的boosting算法(如GBDT和XGBoost)已经有相当好的效率,但在效率和可扩展性上不能满足现在的需求,主要的原因就是传统的boosting算法需要对每一个特征都要扫描所有的样本点来选择最好的切分点,这是非常的耗时。
为了解决这种在大样本高维度数据的环境下耗时的问题,Lightgbm使用了如下两种解决办法:
- GOSS(Gradient-based One-Side Sampling, 基于梯度的单边采样)。不是使用所用的样本点来计算梯度,而是对样本进行采样来计算梯度。
- EFB(Exclusive Feature Bundling, 互斥特征捆绑)。不是使用所有的特征来进行扫描获得最佳的切分点,而是将某些特征进行捆绑在一起来降低特征的维度,使得寻找最佳切分点的消耗减少。
这样大大的降低的处理样本的时间复杂度,但在精度上,通过大量的实验证明,在某些数据集上使用Lightgbm并不损失精度,甚至有时还会提升精度。
3.2 Lightgbm的一些其它特性
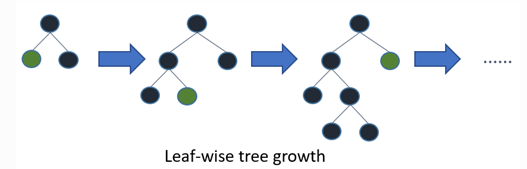
(1) Leaf-wise的决策树生长策略
大部分决策树的学习算法通过 level-wise 策略生长树,即一次分裂同一层的叶子,不加区分的对待同一层的叶子。而实际上很多叶子的分裂增益较低没必要进行分裂,带来了没必要的开销。如下图:
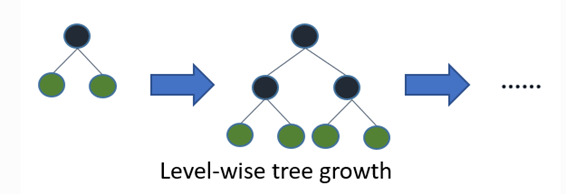
LightGBM 通过 leaf-wise 策略来生长树。每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。但是,当样本量较小的时候,leaf-wise 可能会造成过拟合。所以,LightGBM 可以利用额外的参数max_depth来限制树的深度并避免过拟合。
(2) 类别特征值的最优分割
对于类别型的数据,我们通常将类别特征转化为one-hot编码。 然而,对于学习树来说这不是个好的解决方案。原因是,对于一个基数较大的类别特征,学习树会生长的非常不平衡,并且需要非常深的深度才能来达到较好的准确率。
(3)Lightgbm中的并行学习
(3.1) 特征并行
传统的特征并行算法: 旨在于在并行化决策树中的寻找最佳切分点,主要流程如下:
- 垂直切分数据(不同的Worker有不同的特征集);
- 在本地特征集寻找最佳切分点 {特征,阈值};
- 在各个机器之间进行通信,拿出自己的最佳切分点,然后从所有的最佳切分点中推举出一个最好的切分点,作为全局的切分点;
- 以最佳划分方法对数据进行划分,并将数据划分结果传递给其他Worker;
- 其他Worker对接受到的数据进一步划分。
传统的特征并行方法主要不足: - 存在计算上的局限,传统特征并行无法加速特征切分(时间复杂度为 )。 因此,当数据量很大的时候,难以加速。
- 需要对划分的结果进行通信整合,其额外的时间复杂度约为。(一个数据一个字节)
LightGBM中的特征并行: 不再垂直划分数据,即每个Worker都持有全部数据。 因此,LighetGBM中没有数据划分结果之间通信的开销,各个Worker都知道如何划分数据。 而且,样本量也不会变得更大,所以,使每个机器都持有全部数据是合理的。
LightGBM 中特征并行的流程如下:
- 每个Worker都在本地特征集上寻找最佳划分点{特征,阈值};
- 本地进行各个划分的通信整合并得到最佳划分;
- 执行最佳划分。
然而,该特征并行算法在数据量很大时仍然存在计算上的局限。因此,建议在数据量很大时使用数据并行。
(3.2) 数据并行
传统的数据并行算法:
- 水平划分数据;
- Worker以本地数据构建本地直方图;
- 将所有Worker的本地直方图整合成全局整合图;
- 在全局直方图中寻找最佳切分,然后执行此切分。
传统数据并行的不足:高通讯开销。
LightGBM中的数据并行: 通过减少数据并行过程中的通讯开销,来减少数据并行的开销:
- 不同于传统数据并行算法中的,整合所有本地直方图以形成全局直方图的方式,LightGBM 使用Reduce scatter的方式对不同Worker的不同特征(不重叠的)进行整合。 然后Worker从本地整合直方图中寻找最佳划分并同步到全局的最佳划分中。
- 如上面提到的,LightGBM 通过直方图做差法加速训练。 基于此,我们可以进行单叶子的直方图通讯,并且在相邻直方图上使用做差法。
相关文章:
GBDT、XGBoost、LightGBM算法详解
文章目录 一、GBDT (Gradient Boosting Decision Tree) 梯度提升决策树1.1 回归树1.2 梯度提升树1.3 Shrinkage1.4 调参1.5 GBDT的适用范围1.6 优缺点 二、XGBoost (eXtreme Gradient Boosting)2.1 损失函数2.2 正则项2.3 打分函数计算2.4 分裂节点2.5 算法过程2.6 参数详解2.7…...

【考研数学】李林《880》是什么难度水平强化够用吗
880是公认的质量高,但要是刷的方法不对,心态直接炸裂!🙉 我24年二战就是用的 880660 的黄金搭档,143分逆袭上岸211!(为什么说逆袭呢,因为我23年一战数学83,妥妥的菜鸡&am…...

Flutter 中的 AnimatedAlign 小部件:全面指南
Flutter 中的 AnimatedAlign 小部件:全面指南 在 Flutter 中,动画是增强用户界面和提升用户体验的强大工具。AnimatedAlign 是 Flutter 提供的一个动画组件,它允许你动画化子组件的对齐方式。这在实现动态布局变化、响应式设计或交互式动画时…...

(Qt) 默认QtWidget应用包含什么?
文章目录 ⭐前言⭐创建🛠️选择一个模板🛠️Location🛠️构建系统🛠️Details🛠️Translation🛠️构建套件(Kit)🛠️汇总 ⭐项目⚒️概要⚒️构建步骤⚒️清除步骤 ⭐Code🔦untitled…...

测试环境KDE组件漏洞修复
yarn白名单方案 解决漏洞: 方案: 此方式主要使用iptables的功能,对yarn的resourceManager服务的8088端口进行访问ip限制,目的限制8088端口只允许集群内ip访问。 #分别在两台resourceManager节点执行以下步骤ssh kde-offline1 #安装iptables服务,并启动设置为开机自启 yum …...
微服务下认证授权框架的探讨
前言 市面上关于认证授权的框架已经比较丰富了,大都是关于单体应用的认证授权,在分布式架构下,使用比较多的方案是--<应用网关>,网关里集中认证,将认证通过的请求再转发给代理的服务,这种中心化的方式并不适用于微服务,这里讨论另一种方案--<认证中心>,利用jwt去中…...
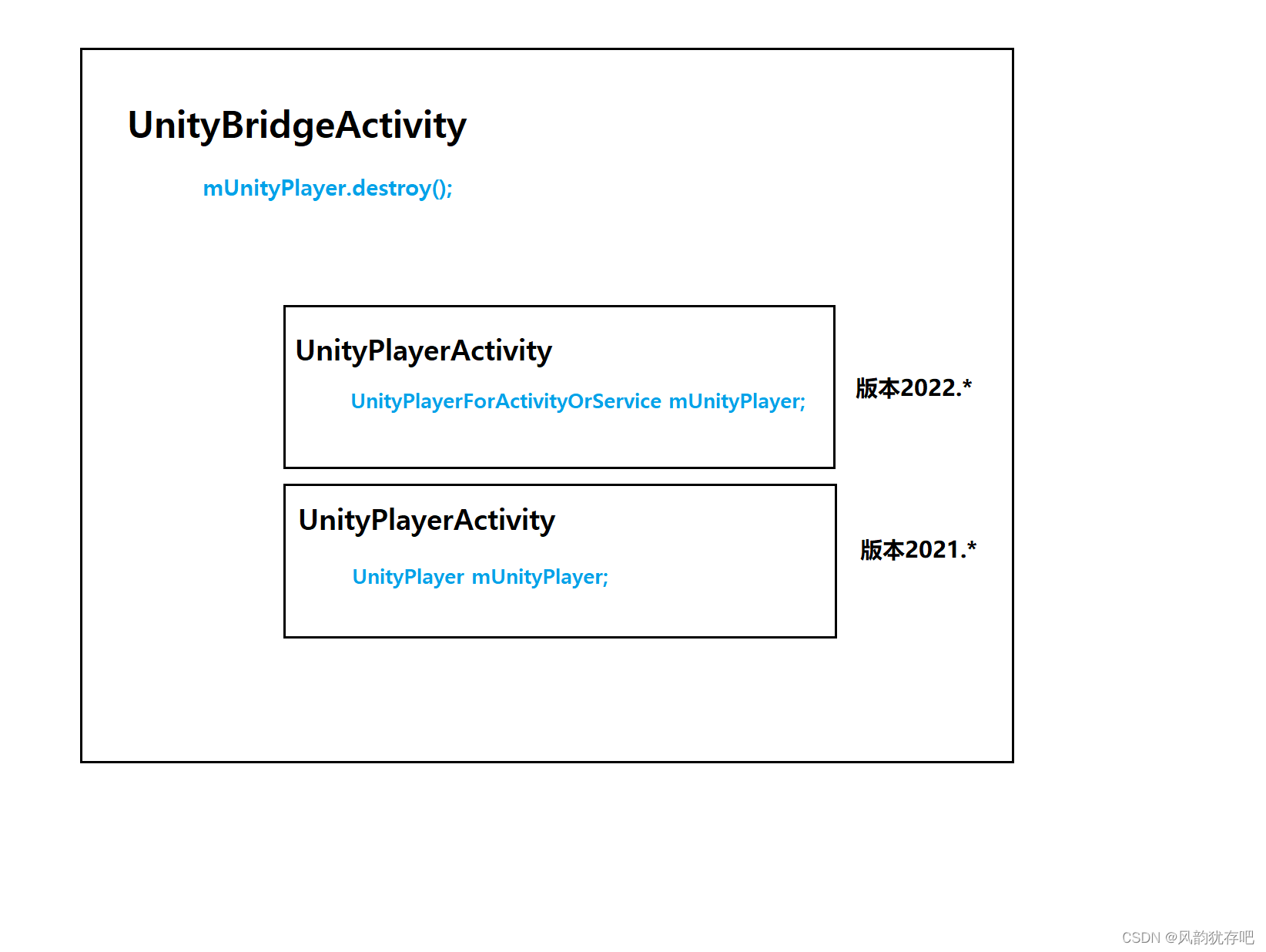
使用 ASM 修改字段类型,解决闪退问题
问题 我的问题是什么? 在桥接类 UnityBridgeActivity 中处理不同 unity 版本调用 mUnityPlayer.destroy(); 闪退问题。 闪退日志如: 闪退日志说在 UnityBridgeActivity中找不到类型为 UnityPlayer 的属性 mUnityPlayer。 我们知道,Android…...
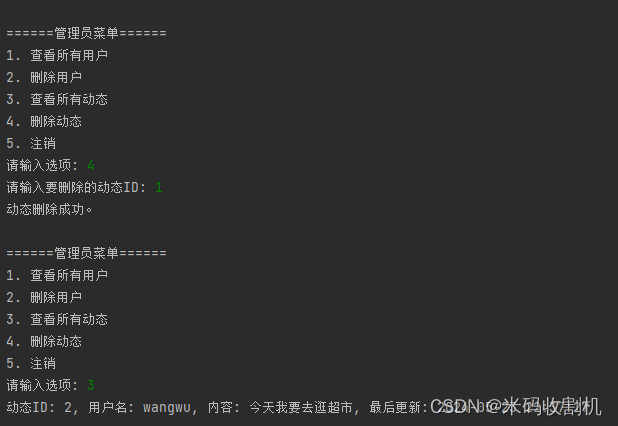
【python】python社交交友平台系统设计与实现(源码+数据库)【独一无二】
👉博__主👈:米码收割机 👉技__能👈:C/Python语言 👉公众号👈:测试开发自动化【获取源码商业合作】 👉荣__誉👈:阿里云博客专家博主、5…...
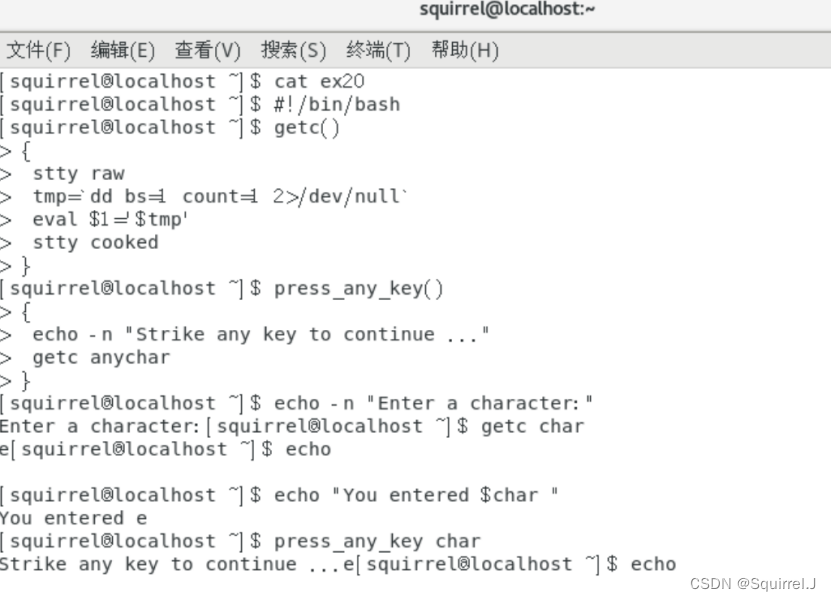
Linux 实验报告3-4
(大家好,今天我们来学习Linux的相关知识,大家可以在评论区进行互动答疑哦~加油!💕) 目录 实验三 vi编辑器 一、实验目的 二、实验内容 三、主要实验步骤 实验报告 1.进入 vi。 2.建立一个文件&…...
网络安全之BGP详解
BGP;边界网关协议 使用范围;BGP范围,在AS之间使用的协议。 协议的特点(算法):路径矢量型,没有算法。 协议是否传递网络掩码:传递网络掩码,支持VLSM,CIDR …...
-查询优化(8)-嵌套联接优化)
【MySQL精通之路】SQL优化(1)-查询优化(8)-嵌套联接优化
主博客: 【MySQL精通之路】SQL优化(1)-查询优化-CSDN博客 上一篇: 【MySQL精通之路】SQL优化(1)-查询优化(7)-嵌套循环联接-CSDN博客 下一篇: 【MySQL精通之路】SQL优化(1)-查询优化(9)-外部联接优化-CSDN博客 与SQL标准相比,…...

30V降8V、12V、24V3.5A车充降压芯片IC H4112 5V-30V
H4112确实是一款功能强大的异步降压型DC-DC转换器,它具备多种出色的特性和优势,使得它在电源管理领域有着广泛的应用。以下是对H4112主要特性和功能的详细解释: 内置30V耐压MOS: H4112内部集成了30V耐压的MOS管,这有…...
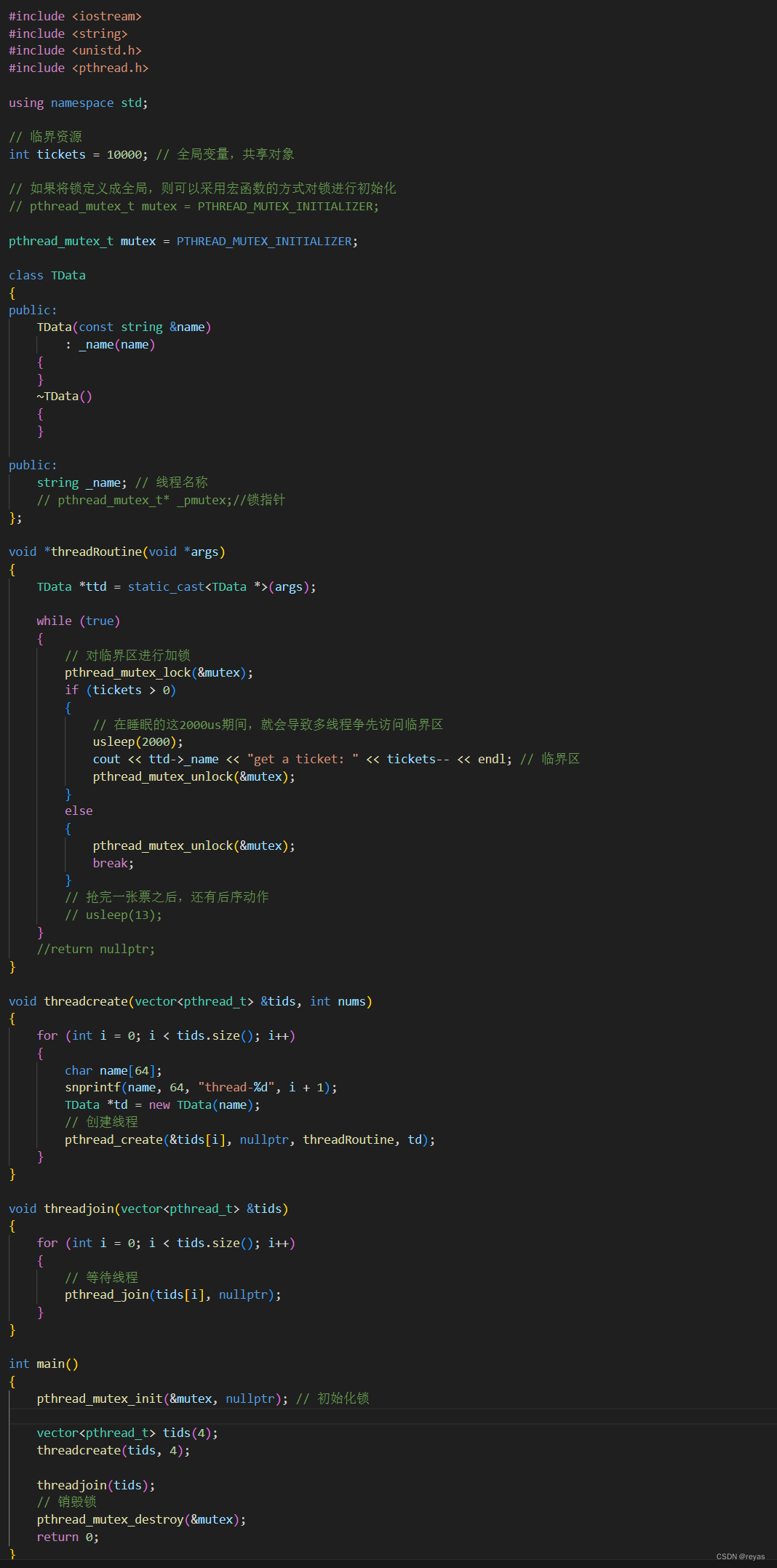
保护共享资源的方法(互斥锁)
我最近开了几个专栏,诚信互三! > |||《算法专栏》::刷题教程来自网站《代码随想录》。||| > |||《C专栏》::记录我学习C的经历,看完你一定会有收获。||| > |||《Linux专栏》࿱…...

树的非递归遍历(层序)
层序是采用队列的方式来遍历的 就比如说上面这颗树 他层序的就是:1 24 356 void LevelOrder(BTNode* root) {Que q;QueueInit(&q);if (root){QueuePush(&q, root);}while (!QueueEmpty(&q)){BTNode* front QueueFront(&q);QueuePop(&q);print…...
解决SpringBoot使用@Transactional进行RestTemplate远程调用导致查询数据记录为null的bug
开启事务过程中,如果远程调用查询当前已经开启但没有提交的事务,就会查不到数据。 示例代码 import lombok.RequiredArgsConstructor; import lombok.extern.slf4j.Slf4j; import org.springframework.transaction.annotation.Transactional; import o…...

pl/sql基础语法操作
oracle pl/sql语言(procedural language/sql)是结合了结构化查询与oracle自身过程控制为一体的强大语言。 语法执行块 语法结构: [ declare 可选 声明变量部分--declaration statements (1);]begin --执行部分--executable statements (2)…...

Vue 父组件向子组件传递数据
1、在子组件中,你需要声明你期望从父组件接收哪些props。这可以通过props选项完成,可以是一个数组或对象形式: export default {props: [message],props:{message:String }props: {message: String, // 类型检查count: {type: Nu…...

二十五、openlayers官网示例CustomOverviewMap解析——实现鹰眼地图、预览窗口、小窗窗口地图、旋转控件
官网demo地址: Custom Overview Map 这个示例展示了如何在地图上增加一个小窗窗口的地图并跟随着地图的旋转而旋转视角。 首先加载了一个地图。其中 DragRotateAndZoom是一个交互事件,它可以实现按住shift键鼠标拖拽旋转地图。 const map new Map({int…...

K8S Secret管理之SealedSecrets
1 关于K8S Secret 我们通常将应用程序使用的密码、API密钥保存在K8S Secret中,然后应用去引用。对于这些敏感信息,安全性是至关重要的,而传统的存储方式可能会导致密钥在存储、传输或使用过程中受到威胁,例如在git中明文存储密码…...

Gone框架介绍25 - Redis模块参考文档
文章目录 Redis 参考文档配置项import 和 bury使用分布是缓存 redis.Cache接口定义使用示例 使用分布式锁 redis.Locker接口定义使用示例 操作Key,使用 redis.Key接口定义 使用 Provider 注入 redis 接口使用示例 直接使用redis连接池接口定义使用示例 Redis 参考文…...

打破平台壁垒:Windows上安装APK文件的完整解决方案
打破平台壁垒:Windows上安装APK文件的完整解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过在Windows电脑上直接运行安卓应用ÿ…...

从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界
从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界 在计算机科学中,浮点数的表示和处理是一个既基础又关键的话题。对于从事系统编程、性能优化或逆向工程的开发者来说,理解浮点数在内存中的实际存储形式不仅能帮…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

AI驱动的Web可访问性审查:LLM如何成为你的自动化无障碍专家
1. 项目概述:一个为AI智能体而生,却意外照亮了所有人的可访问性审查工具 最近在折腾AI智能体(AI Agent)的开发,一个老问题又浮上水面:怎么确保我造出来的这个“数字员工”,能真正服务好所有人&…...

构建通用Docker工具镜像:从设计到实践的全流程指南
1. 项目概述:一个“反重力”的Docker镜像?看到这个镜像名runzhliu/docker-antigravity,很多人的第一反应可能是好奇和疑惑。在Docker Hub上,以“antigravity”(反重力)命名的镜像并不常见,它不像…...

ubantu安装vscode
在火狐浏览器中搜索vscode官网,找到.deb文件下载,下载完成后文件所在的位置为 主文件夹/下载 文件夹内。...

锂电池安全使用指南:从原理到实践,避免常见风险
1. 项目概述:从“能用”到“用好”的锂电安全课如果你玩过任何需要脱离电源线工作的电子项目,无论是给一个Arduino小车供电,还是驱动一架四轴飞行器,最终都绕不开一个核心问题:电源。从最基础的碱性电池,到…...

5分钟掌握Diablo Edit2:暗黑破坏神II角色编辑器的终极指南
5分钟掌握Diablo Edit2:暗黑破坏神II角色编辑器的终极指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 还在为暗黑破坏神II的刷装备烦恼吗?想要快速体验不同build的乐趣…...

taotoken api密钥的精细化管理与审计日志功能实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API密钥的精细化管理与审计日志功能实践 1. 引言 在团队或企业环境中使用大模型服务时,API密钥的管理与安全…...

FanControl深度实战指南:5分钟精通Windows风扇精准控制
FanControl深度实战指南:5分钟精通Windows风扇精准控制 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/f…...