AI--构建检索增强生成 (RAG) 应用程序
LLM 所实现的最强大的应用之一是复杂的问答 (Q&A) 聊天机器人。这些应用程序可以回答有关特定源信息的问题。这些应用程序使用一种称为检索增强生成 (RAG) 的技术。
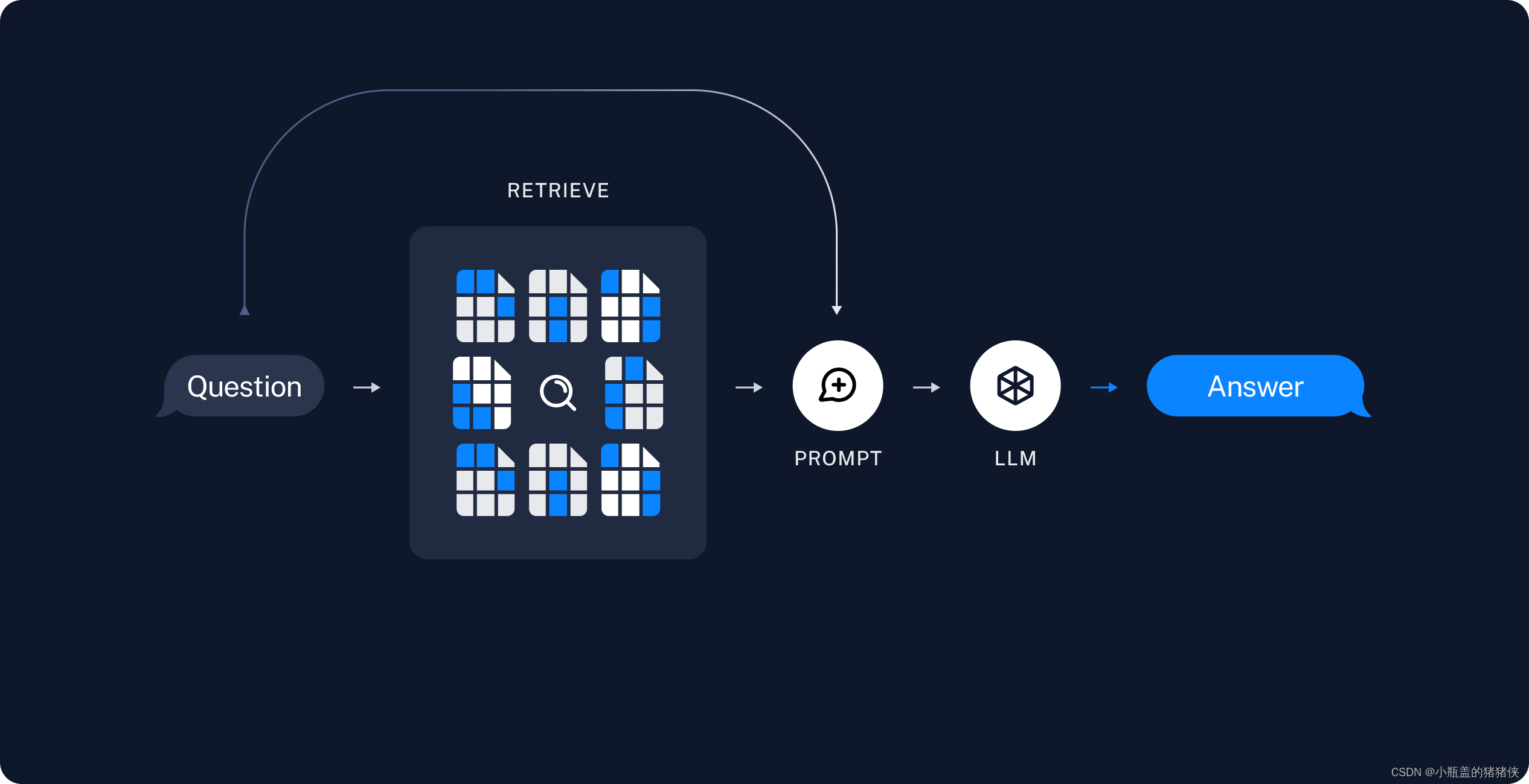
典型的 RAG 应用程序有两个主要组件
- 索引:从源中提取数据并对其进行索引的管道。这通常在线下进行。
- 检索和生成:实际的 RAG 链,它在运行时接受用户查询并从索引中检索相关数据,然后将其传递给模型。
从原始数据到答案最常见的完整序列如下:
- 加载:首先我们需要加载数据。这是通过DocumentLoaders完成的。
- 拆分:文本拆分器将大块内容拆分Documents成小块内容。这对于索引数据和将数据传递到模型都很有用,因为大块内容更难搜索,并且不适合模型的有限上下文窗口。
- 存储:我们需要一个地方来存储和索引我们的分割,以便以后可以搜索它们。这通常使用VectorStore和Embeddings模型来完成

检索和生成
4. 检索:根据用户输入,使用检索器从存储中检索相关分割。
5. 生成:ChatModel / LLM使用包含问题和检索到的数据的提示生成答案
#创建embedding 模型
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.vectorstores.utils import DistanceStrategy
from config import EMBEDDING_PATH# init embedding model
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'batch_size': 64, 'normalize_embeddings': True}embed_model = HuggingFaceEmbeddings(model_name=EMBEDDING_PATH,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs)#导入相关库
from langchain_openai import ChatOpenAI
import bs4
from langchain import hub
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_text_splitters import RecursiveCharacterTextSplitterchat = ChatOpenAI()loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))),
)
docs = loader.load()documents = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200).split_documents(docs)vetorstors = FAISS.from_documents(documents,embed_model)retriever = vetorstors.as_retriever()promt = hub.pull("rlm/rag-prompt")promtdef format_docs(docs):return "\n\n".join(doc.page_content for doc in docs)#创建链
chain =({"context":retriever | format_docs ,"question":RunnablePassthrough()}| promt| chat| StrOutputParser()
)chain.invoke("What is Task Decomposition?")
输出结果
‘Task decomposition is the process of breaking down a problem into multiple thought steps to create a tree structure. It can be achieved through LLM with simple prompting, task-specific instructions, or human inputs. The goal is to transform big tasks into smaller and simpler steps to enhance model performance on complex tasks.’
首先:这些组件(retriever、prompt、chat等)中的每一个都是Runnable的实例。这意味着它们实现相同的方法——例如sync和async .invoke、、.stream或.batch——这使得它们更容易连接在一起。它们可以通过运算符|连接到RunnableSequence(另一个 Runnable)。
当遇到|操作符时,LangChain 会自动将某些对象转换为 Runnable。这里,format_docs转换为RunnableLambda"context" ,带有和的字典"question"转换为RunnableParallel。细节并不重要,重要的是,每个对象都是一个 Runnable。
让我们追踪一下输入问题如何流经上述可运行程序。
正如我们在上面看到的,输入prompt预计是一个带有键"context"和 的字典"question"。因此,该链的第一个元素构建了可运行对象,它将根据输入问题计算这两个值:
retriever | format_docs: 将文本传递给检索器,生成Document对象,然后将Document对象format_docs生成字符串;
RunnablePassthrough()不变地通过输入问题。
内置Chain
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplatesystem_prompt = ("You are an assistant for question-answering tasks. ""Use the following pieces of retrieved context to answer ""the question. If you don't know the answer, say that you ""don't know. Use three sentences maximum and keep the ""answer concise.""\n\n""{context}"
)prompt = ChatPromptTemplate.from_messages([("system", system_prompt),("human", "{input}"),]
)question_answer_chain = create_stuff_documents_chain(chat, prompt)
rag_chain = create_retrieval_chain(retriever, question_answer_chain)response = rag_chain.invoke({"input":"What is Task Decomposition?"})
print(response)
输出结果:
{‘input’: ‘What is Task Decomposition?’, ‘context’: [Document(page_content=‘Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like “Steps for XYZ.\n1.”, “What are the subgoals for achieving XYZ?”, (2) by using task-specific instructions; e.g. “Write a story outline.” for writing a novel, or (3) with human inputs.’, metadata={‘source’: ‘https://lilianweng.github.io/posts/2023-06-23-agent/’}), Document(page_content=‘Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.’, metadata={‘source’: ‘https://lilianweng.github.io/posts/2023-06-23-agent/’}), Document(page_content=‘Fig. 2. Examples of reasoning trajectories for knowledge-intensive tasks (e.g. HotpotQA, FEVER) and decision-making tasks (e.g. AlfWorld Env, WebShop). (Image source: Yao et al. 2023).\nIn both experiments on knowledge-intensive tasks and decision-making tasks, ReAct works better than the Act-only baseline where Thought: … step is removed.\nReflexion (Shinn & Labash 2023) is a framework to equips agents with dynamic memory and self-reflection capabilities to improve reasoning skills. Reflexion has a standard RL setup, in which the reward model provides a simple binary reward and the action space follows the setup in ReAct where the task-specific action space is augmented with language to enable complex reasoning steps. After each action a t a_t at, the agent computes a heuristic h t h_t ht and optionally may decide to reset the environment to start a new trial depending on the self-reflection results.’, metadata={‘source’: ‘https://lilianweng.github.io/posts/2023-06-23-agent/’}), Document(page_content=‘Here are a sample conversation for task clarification sent to OpenAI ChatCompletion endpoint used by GPT-Engineer. The user inputs are wrapped in {{user input text}}.\n[\n {\n “role”: “system”,\n “content”: “You will read instructions and not carry them out, only seek to clarify them.\nSpecifically you will first summarise a list of super short bullets of areas that need clarification.\nThen you will pick one clarifying question, and wait for an answer from the user.\n”\n },\n {\n “role”: “user”,\n “content”: “We are writing {{a Super Mario game in python. MVC components split in separate files. Keyboard control.}}\n”\n },\n {\n “role”: “assistant”,’, metadata={‘source’: ‘https://lilianweng.github.io/posts/2023-06-23-agent/’})], ‘answer’: ‘Task decomposition involves breaking down a complex task into smaller and simpler steps to make it more manageable. This technique allows models or agents to utilize more computational resources at test time by thinking step by step. By decomposing tasks, models can better understand and interpret the thinking process involved in solving difficult problems.’}
create_stuff_documents_chain
def create_stuff_documents_chain(llm: LanguageModelLike,prompt: BasePromptTemplate,*,output_parser: Optional[BaseOutputParser] = None,document_prompt: Optional[BasePromptTemplate] = None,document_separator: str = DEFAULT_DOCUMENT_SEPARATOR,
) -> Runnable[Dict[str, Any], Any]:_validate_prompt(prompt)_document_prompt = document_prompt or DEFAULT_DOCUMENT_PROMPT_output_parser = output_parser or StrOutputParser()def format_docs(inputs: dict) -> str:return document_separator.join(format_document(doc, _document_prompt) for doc in inputs[DOCUMENTS_KEY])return (RunnablePassthrough.assign(**{DOCUMENTS_KEY: format_docs}).with_config(run_name="format_inputs")| prompt| llm| _output_parser).with_config(run_name="stuff_documents_chain")
从源代码看出来,就是chain
create_retrieval_chain
def create_retrieval_chain(retriever: Union[BaseRetriever, Runnable[dict, RetrieverOutput]],combine_docs_chain: Runnable[Dict[str, Any], str],
) -> Runnable:if not isinstance(retriever, BaseRetriever):retrieval_docs: Runnable[dict, RetrieverOutput] = retrieverelse:retrieval_docs = (lambda x: x["input"]) | retrieverretrieval_chain = (RunnablePassthrough.assign(context=retrieval_docs.with_config(run_name="retrieve_documents"),).assign(answer=combine_docs_chain)).with_config(run_name="retrieval_chain")return retrieval_chain
create_retrieval_chain调用过程就是先检索,然后调用combine_docs_chain
相关文章:
AI--构建检索增强生成 (RAG) 应用程序
LLM 所实现的最强大的应用之一是复杂的问答 (Q&A) 聊天机器人。这些应用程序可以回答有关特定源信息的问题。这些应用程序使用一种称为检索增强生成 (RAG) 的技术。 典型的 RAG 应用程序有两个主要组件 索引:从源中提取数据并对其进行索引的管道。这通常在线下…...
QT7_视频知识点笔记_4_文件操作,Socket通信:TCP/UDP
1.事件分发器,事件过滤器(重要程度:一般) event函数 2.文件操作(QFile) 实现功能:点击按钮,弹出对话框,并且用文件类读取出内容输出显示在控件上。 #include <QFi…...
智慧社区管理系统:打造便捷、安全、和谐的新型社区生态
项目背景 在信息化、智能化浪潮席卷全球的今天,人们对于生活品质的需求日益提升,期待居住环境能与科技深度融合,实现高效、舒适、安全的生活体验。在此背景下,智慧社区管理系统应运而生,旨在借助现代信息技术手段&…...
CustomTkinter:便捷美化Tkinter的UI界面(附模板)
CustomTkinter是一个基于Tkinter的Python用户界面库。 pip3 install customtkinter它提供了各种UI界面常见的小部件。这些小部件可以像正常的Tkinter小部件一样创建和使用,也可以与正常的Tkinter元素一起使用。 它的优势如下: CustomTkinter的小部件和…...

使用MicroPython和pyboard开发板(15):使用LCD和触摸传感器
使用LCD和触摸传感器 pybaord的pyb对LCD设备也进行了封装,可以使用官方的LCD显示屏。将LCD屏连接到开发板,连接后。 使用LCD 先用REPL来做个实验,在MicroPython提示符中输入以下指令。请确保LCD面板连接到pyboard的方式正确。 >>…...

c++20 std::jthread 源码简单赏析与应用
std::jthread 说明: std::jthread 是 C20 中引入的一个新特性,它是线程库中的一个类,专门用于处理 std::thread 与 std::stop_token 和 std::stop_source 之间的交互,以支持更优雅和安全的线程停止机制。 std::stop_source控制…...

自动化测试里的数据驱动和关键字驱动思路的理解
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 初次接触自动化测试时,对数据驱动和关键字驱动不甚理解,觉得有点故弄玄须…...

【30天精通Prometheus:一站式监控实战指南】第6天:mysqld_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
亲爱的读者们👋 欢迎加入【30天精通Prometheus】专栏!📚 在这里,我们将探索Prometheus的强大功能,并将其应用于实际监控中。这个专栏都将为你提供宝贵的实战经验。🚀 Prometheus是云原生和DevOps的…...
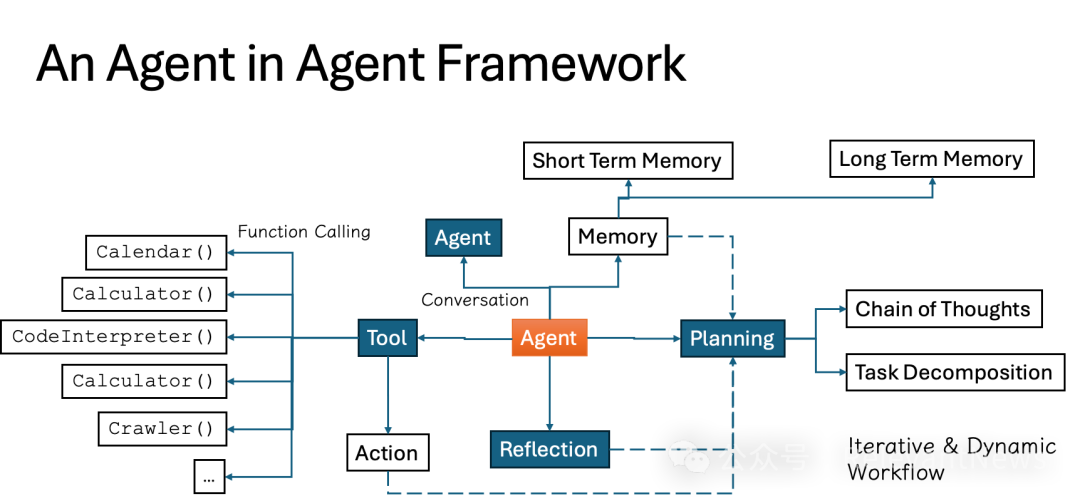
浅析智能体开发(第二部分):智能体设计模式和软件架构
大语言模型(LLM)驱动的智能体(AI Agent)展现出许多传统软件所不具备的特征。不仅与传统软件的设计理念、方法、工具和技术栈有显著的差异,AI原生(AI Native)的智能体还融入了多种新概念和技术。…...
Unity学习笔记---Transform组件
组件介绍 Transform组件在每个游戏对象中都存在,且只存在一个。该组件保存了游戏对象的位置、平移、旋转、缩放等信息。 组件相关方法 //获取当前游戏对象的Transform组件this.transform; getObject.transform; GetComponent<Transform>();//属性 gameObje…...
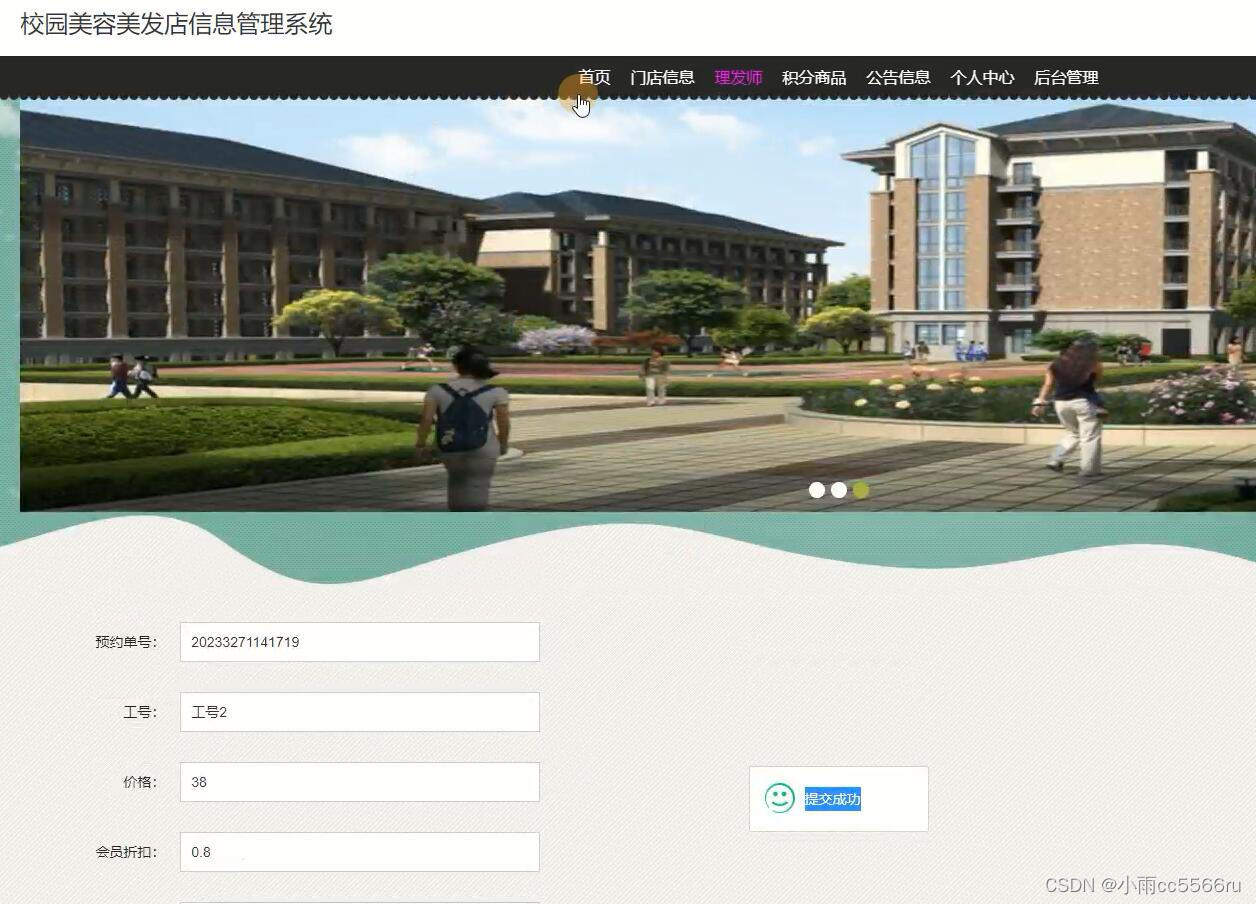
springboot+jsp校园理发店美容美发店信息管理系统0h29g
前台管理:会员管理、会员预定、开单点单、收银结帐、技师提成 后台管理:数据维护、物料管理、数据查询、报表分析、系统设置等 灵活的付款方式,支持现金、挂帐、会员卡,同时支持多种折扣方式并可按用户要求设置多种结帐类型善的充值卡管理模块:支持优惠卡…...

css - sass or scss ?
总的来说,Sass 和 SCSS 提供的功能是一样的,选择哪种语法主要取决于你的个人或团队的偏好。...

html5 笔记01
01 表单类型和属性 input的type属性 单行文本框: typetext 电子邮箱 : typeemail 地址路径 : type url 定义用于输入数字的字段: typenumber 手机号码: typetel 搜索框 : typesearch 定义颜色选择器 : typecolor 滑块控件 : typerange 定义日期 :typedate 定义输入时间的控件…...

E5063A是德科技e5063a网络分析仪
181-2461-8938产品概述: 简 述: E5063A 是低成本网络分析仪,可提供优化的性能和功能,适用于测试简单的无源器件,例如天线、电缆、滤波器和 PCB 等。它利用工业标准 ENA 系列始终如一的测量架构,能够极…...
)
【星海随笔】微信小程序(二)
WXML 模板语法 - 数据绑定 在data中定义页面的数据 在页面对应的 .js 文件中,把数据定义到 data 对象中即可: Page({data: {// 字符串类型的数据info: init data,// 数据类型的数据msgList: [{msg: hello},{msg: world}]} })Mustache 语法的格式 把 …...
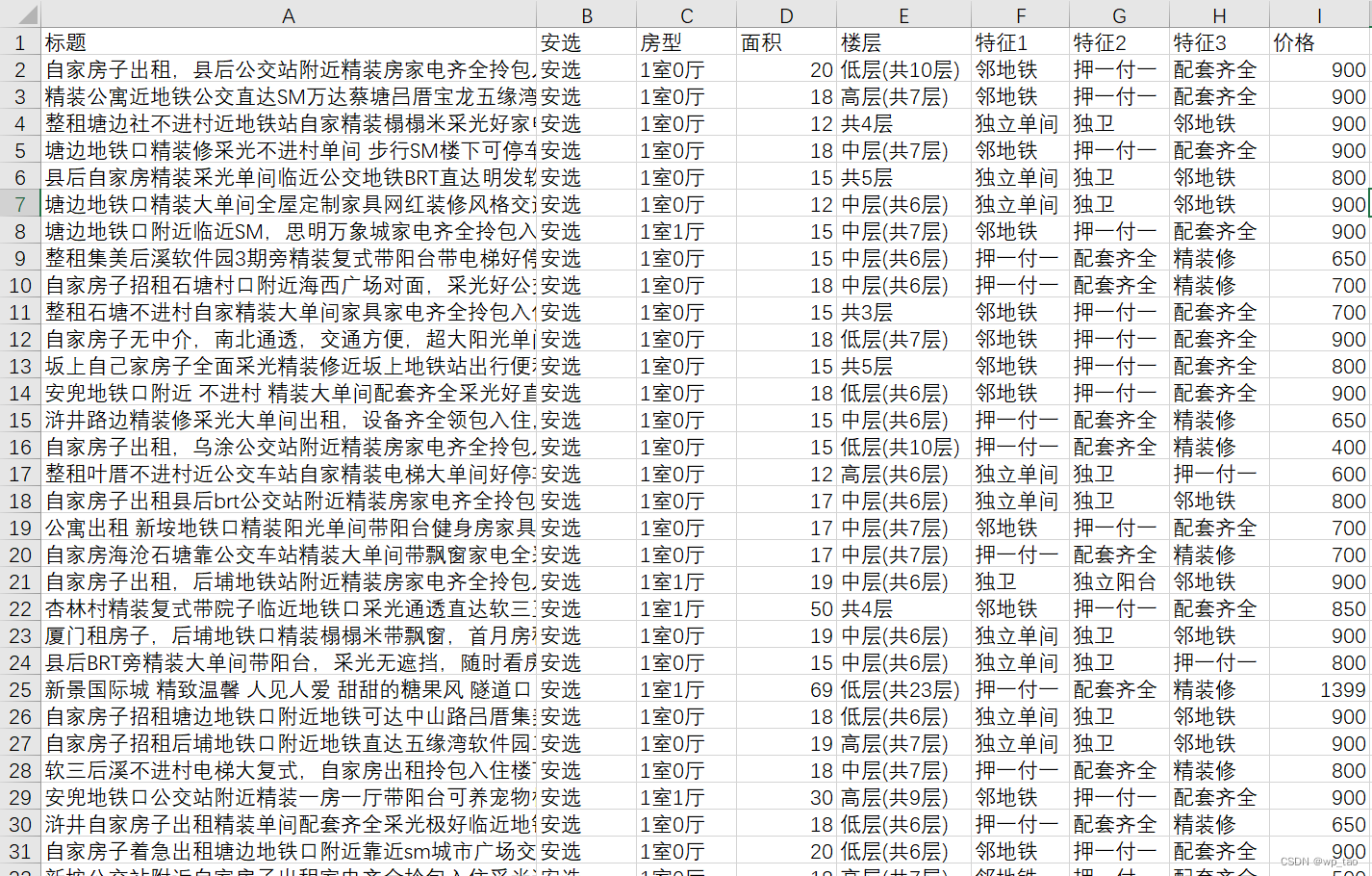
Python采集安居客租房信息
Python采集安居客租房信息 一、需求介绍二、完整代码一、需求介绍 本次采集的需求就是获取到页面中的所有信息: 将数据采集好之后保存为如下csv文件: 爬取的流程不再展开分析,完整代码附后。 二、完整代码 import csvimport requests from lxml import etreeclass Anju…...
Rust构造JSON和解析JSON
目录 一、Rust构造JSON和解析JSON 二、知识点 serde_json JSON 一、Rust构造JSON和解析JSON 添加依赖项 cargo add serde-json 代码: use serde_json::{Result, Value};fn main() -> Result<()>{//构造json结构 cpu_loadlet data r#"{"…...
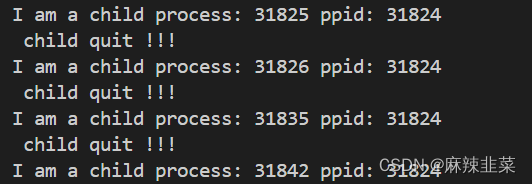
Linux 信号捕捉与处理
💓博主CSDN主页:麻辣韭菜💓 ⏩专栏分类:Linux知识分享⏪ 🚚代码仓库:Linux代码练习🚚 🌹关注我🫵带你学习更多Linux知识 🔝 目录 前言 1. 信号的处理时机 1.1用户…...

桂林电子科技大学计算机工程学院、广西北部湾大学计信学院莅临泰迪智能科技参观交流
5月18日,桂林电子科技大学计算机工程学院副院长刘利民、副书记杨美娜、毕业班辅导员黄秀娟、广西北部湾大学计信学院院长助理刘秀平莅临广东泰迪智能科技股份有限公司产教融合实训基地参观交流。泰迪智能科技副总经理施兴、广西分公司郑廷和、梁霜、培训业务部孙学镂…...
Qt笔记:动态处理多个按钮点击事件以更新UI
问题描述 在开发Qt应用程序时,经常需要处理多个按钮的点击事件,并根据点击的按钮来更新用户界面(UI),如下图。例如,你可能有一个包含多个按钮的界面,每个按钮都与一个文本框和一个复选框相关联…...

4.7 Spark SQL函数分类与应用
本次实战涵盖了三大核心内容:内置函数、自定义函数(UDF)和开窗函数。 内置函数是数据处理的基础,包括字符串、日期、数学、聚合等10大类,可通过DataFrame API或SQL语句两种方式调用,满足多样化的数据转换需…...

DCIM管理系统是什么?它的应用价值与关键功能有哪些?
DCIM管理系统的定义与功能概述 是现代数据中心重要的工具,目的是融合IT管理与设备监控,进而实现高效的容量规划与设备维护。这个系统的核心组件包括实时监控、资产管理及环境监控功能,利用综合运用这些工具,操作人员能够快速识别…...
)
手把手教你用USB ISP下载器给Arduino Nano烧写Bootloader(含ProgISP软件详细配置)
手把手教你用USB ISP下载器为Arduino Nano烧录Bootloader 当你拿到一块全新的Arduino Nano开发板,或是遇到程序无法上传的"变砖"情况时,很可能需要重新烧写Bootloader。Bootloader是存储在微控制器中的一小段特殊程序,它负责与Ard…...

AI 工具规模化滥用下钓鱼攻击演化机理与闭环防御研究
【摘要】Cisco Talos 2026 年第一季度事件响应报告显示,生成式 AI 工具被大规模用于网络钓鱼产业化制造,钓鱼攻击重新成为威胁系统安全的首要挑战。随着机构漏洞修复能力提升,攻击重心从技术漏洞利用转向以人为核心的社会工程攻击,…...

深度技术解析:Lenovo Legion Toolkit 高级性能调优与系统集成指南
深度技术解析:Lenovo Legion Toolkit 高级性能调优与系统集成指南 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit …...

TPU加速GAN训练:从Colab实操到混合精度调优
1. 项目概述:为什么在Kaggle/Colab上用TPU训GAN不是“炫技”,而是刚需你有没有试过在笔记本电脑上跑一个DCGAN,等了47分钟,loss曲线刚抖两下,风扇就发出濒死的哀鸣?或者在普通GPU上训StyleGAN2,…...

RK3568开发板NFS服务器搭建:嵌入式Linux开发效率提升实战
1. 项目概述与核心价值最近在折腾一块瑞芯微的RK3568开发板,想在上面跑一些自己的应用。开发调试阶段,最头疼的就是每次修改完代码,都得重新编译、打包、烧录到板子上,这个过程不仅耗时,还容易打断思路。为了解决这个痛…...

TBP-9000-R0AE无风扇工控机:6网口4PoE+,严苛工业环境下的边缘计算与机器视觉平台
1. 项目概述:一台为严苛环境而生的工业“大脑”在工业自动化、机器视觉、轨道交通这些领域里,选一台靠谱的工控机,远比在办公室挑台电脑复杂得多。它不仅要算力够用,更得扛得住震动、耐得了高低温、接得了五花八门的工业设备&…...

DDD 中的代码组织:按技术层分 vs 按领域模块分,哪种才是正解?
前言 在实践领域驱动设计(DDD)时,你可能见过两种截然不同的代码组织方式:一种是传统的按技术层划分文件夹,另一种是按业务模块划分文件夹。两种写法的人都声称自己在做 DDD,那到底哪种更合理?本…...

benchmark-ips源码剖析:理解Ruby性能测试的内部机制
benchmark-ips源码剖析:理解Ruby性能测试的内部机制 【免费下载链接】benchmark-ips Provides iteration per second benchmarking for Ruby 项目地址: https://gitcode.com/gh_mirrors/be/benchmark-ips 什么是benchmark-ips? benchmark-ips是一…...