7个常见的SQL慢查询问题及其解决方法
大家好,得益于摩尔定律,计算机性能已大幅提升,加上数据库的进步以及微服务所倡导的各种反模式设计,因此现在编写复杂SQL查询的机会越来越少。业界已经开始提倡不要进行专门的SQL优化,因为节省下来的资源并不足以抵消员工的工资成本。本文将介绍7个常见的SQL慢查询语句,并解释如何优化它们的性能。
1.LIMIT语句
分页是最常用的方案之一,但也容易出现问题。例如对于以下简单的语句,DBA通常建议的解决方案是添加一个包含type、name和create_time字段的复合索引。这样,条件和排序就可以有效利用索引,从而显著提高性能。
SELECT *
FROM operation
WHERE type = 'SQLStats'AND name = 'SlowLog'
ORDER BY create_time
LIMIT 1000, 10;
这可能会解决90%以上DBA的问题,但是当LIMIT子句变成“LIMIT 1000000, 10”时,程序员仍会抱怨“为什么在只查询10条记录的时候,速度还这么慢” 。要知道,数据库不知道第1000000条记录从何处开始,所以即使有索引,它仍需要从头开始计算。在大多数情况下,这个性能问题是由于懒惰编程造成的。
在前端数据浏览或批量导出大量数据的场景中,可以使用上一页的最大值作为查询参数。SQL可以重新设计如下:
SELECT *
FROM operation
WHERE type = 'SQLStats'
AND name = 'SlowLog'
AND create_time > '2017-03-16 14:00:00'
ORDER BY create_time
LIMIT 10;
采用这种新设计后,查询时间保持不变,不会随着数据量的增加而变化。
2.隐式转换
SQL语句中另一个常见的错误是查询变量和字段定义的类型不匹配,以下面的语句为例:
mysql> explain extended SELECT *> FROM my_balance b> WHERE b.bpn = 14000000123> AND b.isverified IS NULL ;
mysql> show warnings;
| Warning | 1739 | Cannot use ref access on index 'bpn' due to type or collation conversion on field 'bpn'
在这种情况下,字段bpn被定义为varchar(20),而MySQL的策略是在比较之前将字符串转换为数字。这会导致函数被应用到表字段上,从而使索引失效。
这种情况可能是由应用程序框架自动填充参数造成的,而不是程序员的本意。如今,应用程序框架通常都很复杂,虽然它们提供了便利,但也可能带来隐患。
3.连接更新和删除
尽管MySQL 5.6引入了物化,但它只优化了SELECT语句。对于UPDATE或DELETE语句,需要使用JOIN手动重写。
例如,请看下面的UPDATE语句。MySQL实际上执行了一个循环/嵌套子查询(DEPENDENT SUBQUERY),执行时间可想而知。
UPDATE operation o
SET status = 'applying'
WHERE o.id IN (SELECT idFROM (SELECT o.id,o.statusFROM operation oWHERE o.group = 123AND o.status NOT IN ( 'done' )ORDER BY o.parent,o.idLIMIT 1) t);
执行计划如下:
+----+--------------------+-------+-------+---------------+---------+---------+-------+------+-----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------------+-------+-------+---------------+---------+---------+-------+------+-----------------------------------------------------+
| 1 | PRIMARY | o | index | | PRIMARY | 8 | | 24 | Using where; Using temporary |
| 2 | DEPENDENT SUBQUERY | | | | | | | | Impossible WHERE noticed after reading const tables |
| 3 | DERIVED | o | ref | idx_2,idx_5 | idx_5 | 8 | const | 1 | Using where; Using filesort |
+----+--------------------+-------+-------+---------------+---------+---------+-------+------+-----------------------------------------------------+
将其重写为JOIN后,子查询的选择类型从DEPENDENT SUBQUERY变为DERIVED,执行时间显著得从7秒缩短到2毫秒。
UPDATE operation oJOIN (SELECT o.id,o.statusFROM operation oWHERE o.group = 123AND o.status NOT IN ( 'done' )ORDER BY o.parent,o.idLIMIT 1) tON o.id = t.id
SET status = 'applying';
简化后的执行计划如下:
+----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------------------------------+
| 1 | PRIMARY | | | | | | | | Impossible WHERE noticed after reading const tables |
| 2 | DERIVED | o | ref | idx_2,idx_5 | idx_5 | 8 | const | 1 | Using where; Using filesort |
+----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------------------------------+
4.混合排序
MySQL无法利用索引进行混合排序,但是在某些场景下,仍然可以使用特殊方法来提高性能。
SELECT *
FROM my_order oINNER JOIN my_appraise a ON a.orderid = o.id
ORDER BY a.is_reply ASC,a.appraise_time DESC
LIMIT 0, 20;
执行计划显示的是全表扫描:
+----+-------------+-------+--------+-------------+---------+---------+---------------+---------+-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra
+----+-------------+-------+--------+-------------+---------+---------+---------------+---------+-+
| 1 | SIMPLE | a | ALL | idx_orderid | NULL | NULL | NULL | 1967647 | Using filesort |
| 1 | SIMPLE | o | eq_ref | PRIMARY | PRIMARY | 122 | a.orderid | 1 | NULL |
+----+-------------+-------+--------+---------+---------+---------+-----------------+---------+-+
由于is_reply只有0和1两种状态,可以将其重写如下,从而将执行时间从1.58秒缩短到2毫秒:
SELECT *
FROM ((SELECT *FROM my_order oINNER JOIN my_appraise aON a.orderid = o.idAND is_reply = 0ORDER BY appraise_time DESCLIMIT 0, 20)UNION ALL(SELECT *FROM my_order oINNER JOIN my_appraise aON a.orderid = o.idAND is_reply = 1ORDER BY appraise_time DESCLIMIT 0, 20)) t
ORDER BY is_reply ASC,appraisetime DESC
LIMIT 20;
5.EXISTS语句
在处理EXISTS子句时,MySQL仍然使用嵌套子查询进行执行。以下面的SQL语句为例:
SELECT *
FROM my_neighbor nLEFT JOIN my_neighbor_apply sraON n.id = sra.neighbor_idAND sra.user_id = 'xxx'
WHERE n.topic_status < 4AND EXISTS(SELECT 1FROM message_info mWHERE n.id = m.neighbor_idAND m.inuser = 'xxx')AND n.topic_type <> 5;
+----+--------------------+-------+------+-----+------------------------------------------+---------+-------+---------+ -----+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra
+----+--------------------+-------+------+ -----+------------------------------------------+---------+-------+---------+ -----+
| 1 | PRIMARY | n | ALL | | NULL | NULL | NULL | 1086041 | Using where |
| 1 | PRIMARY | sra | ref | | idx_user_id | 123 | const | 1 | Using where |
| 2 | DEPENDENT SUBQUERY | m | ref | | idx_message_info | 122 | const | 1 | Using index condition; Using where |
+----+--------------------+-------+------+ -----+------------------------------------------+---------+-------+---------+ -----+
通过删除EXISTS子句并将其更改为JOIN, 我们可以避免嵌套子查询,并将执行时间从1.93秒减少到1毫秒。
SELECT *
FROM my_neighbor nINNER JOIN message_info mON n.id = m.neighbor_idAND m.inuser = 'xxx'LEFT JOIN my_neighbor_apply sraON n.id = sra.neighbor_idAND sra.user_id = 'xxx'
WHERE n.topic_status < 4AND n.topic_type <> 5;
新的执行计划如下:
+----+-------------+-------+--------+ -----+------------------------------------------+---------+ -----+------+ -----+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+ -----+------------------------------------------+---------+ -----+------+ -----+
| 1 | SIMPLE | m | ref | | idx_message_info | 122 | const | 1 | Using index condition |
| 1 | SIMPLE | n | eq_ref | | PRIMARY | 122 | ighbor_id | 1 | Using where |
| 1 | SIMPLE | sra | ref | | idx_user_id | 123 | const | 1 | Using where |
+----+-------------+-------+--------+ -----+------------------------------------------+---------+ -----+------+ -----+
6.条件下推
在某些情况下,外部查询条件无法下推到复杂的视图或子查询中:
-
聚合子查询。
-
带有LIMIT的子查询。
-
UNION或UNION ALL子查询。
-
输出字段中的子查询。
请看下面的语句,其中的条件会影响聚合子查询:
SELECT *
FROM (SELECT target,Count(*)FROM operationGROUP BY target) t
WHERE target = 'rm-xxxx';
+----+-------------+------------+-------+---------------+-------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+---------------+-------------+---------+-------+------+-------------+
| 1 | PRIMARY | n | ALL | NULL | NULL | NULL | NULL | 1086041 | Using where |
| 1 | PRIMARY | sra | ref | NULL | idx_user_id | 123 | const | 1 | Using where |
| 2 | DEPENDENT SUBQUERY | m | ref | NULL | idx_message_info | 122 | const | 1 | Using index condition; Using where |
+----+-------------+------------+-------+---------------+-------------+---------+-------+------+-------------+
通过删除EXISTS子句并将其更改为JOIN,我们可以避免嵌套子查询并将执行时间从1.93秒减少到1毫秒。
SELECT *
FROM my_neighbor nINNER JOIN message_info mON n.id = m.neighbor_idAND m.inuser = 'xxx'LEFT JOIN my_neighbor_apply sraON n.id = sra.neighbor_idAND sra.user_id = 'xxx'
WHERE n.topic_status < 4AND n.topic_type <> 5;
新的执行计划如下:
+----+-------------+-------+--------+ -----+------------------------------------------+---------+ -----+------+ -----+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+ -----+------------------------------------------+---------+ -----+------+ -----+
| 1 | SIMPLE | m | ref | | idx_message_info | 122 | const | 1 | Using index condition |
| 1 | SIMPLE | n | eq_ref | | PRIMARY | 122 | ighbor_id | 1 | Using where |
| 1 | SIMPLE | sra | ref | | idx_user_id | 123 | const | 1 | Using where |
+----+-------------+-------+--------+ -----+------------------------------------------+---------+ -----+------+ -----+
7.提前缩小范围
以下经过部分优化的示例(左连接中的主表作为主查询条件):
SELECT a.*,c.allocated
FROM (SELECT resourceidFROM my_distribute dWHERE isdelete = 0AND cusmanagercode = '1234567'ORDER BY salecode limit 20) a
LEFT JOIN(SELECT resourcesid, sum(ifnull(allocation, 0) * 12345) allocatedFROM my_resourcesGROUP BY resourcesid) c
ON a.resourceid = c.resourcesid;
很明显,子查询c是对整个表进行聚合查询,在处理大量表时可能会导致性能下降。
事实上,对于子查询c,左连接的结果集只关心可以与主表的resourceid匹配的数据。因此我们可以将语句重写如下,将执行时间从2秒减少到2毫秒:
SELECT a.*,c.allocated
FROM (SELECT resourceidFROM my_distribute dWHERE isdelete = 0AND cusmanagercode = '1234567'ORDER BY salecode limit 20) a
LEFT JOIN(SELECT resourcesid, sum(ifnull(allocation, 0) * 12345) allocatedFROM my_resources r,(SELECT resourceidFROM my_distribute dWHERE isdelete = 0AND cusmanagercode = '1234567'ORDER BY salecode limit 20) aWHERE r.resourcesid = a.resourcesidGROUP BY resourcesid) c
ON a.resourceid = c.resourcesid;
然而子查询a在SQL语句中出现了多次,这种方法不仅会产生额外的成本,而且也会使语句变得更加复杂。可以使用WITH语句来简化它:
WITH a AS
(SELECT resourceidFROM my_distribute dWHERE isdelete = 0AND cusmanagercode = '1234567'ORDER BY salecode limit 20)
SELECT a.*,c.allocated
FROM a
LEFT JOIN(SELECT resourcesid, sum(ifnull(allocation, 0) * 12345) allocatedFROM my_resources r,aWHERE r.resourcesid = a.resourcesidGROUP BY resourcesid) c
ON a.resourceid = c.resourcesid;数据库编译器生成的执行计划决定了SQL语句的实际执行方式,但是编译器只能尽力提供服务,没有一个数据库编译器是完美的,上述情况在其他数据库中也同样存在。了解了数据库编译器的特性,我们就能绕过它的限制,编写出高性能的SQL语句。
在设计数据模型和编写SQL语句时,将算法思维或算法意识引入到这个过程非常重要。在编写复杂的SQL语句时,养成使用WITH语句的习惯可以简化语句,减轻数据库的负担。
最后,下面是SQL语句的执行顺序:
FROMONJOINWHEREGROUP BYHAVINGSELECT
DISTINCTORDER BYLIMIT相关文章:

7个常见的SQL慢查询问题及其解决方法
大家好,得益于摩尔定律,计算机性能已大幅提升,加上数据库的进步以及微服务所倡导的各种反模式设计,因此现在编写复杂SQL查询的机会越来越少。业界已经开始提倡不要进行专门的SQL优化,因为节省下来的资源并不足以抵消员…...

《Rust奇幻之旅:从Java和C++开启》第1章Hello world 1/5
讲动人的故事,写懂人的代码 很多程序员都在自学Rust。 🤕但Rust的学习曲线是真的陡,让人有点儿怵头。 程序员工作压力大,能用来自学新东西的时间简直就是凤毛麟角。 📕目前,在豆瓣上有7本Rust入门同类书。它们虽有高分评价,但仍存在不足。 首先,就是它们介绍的Rust新…...
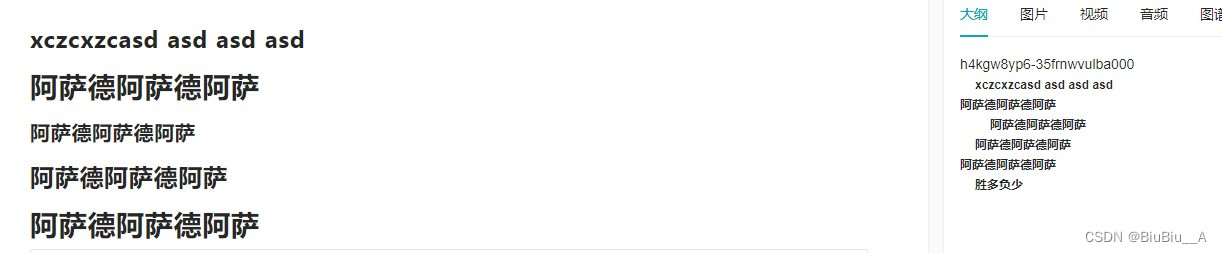
将富文本编辑器中的H标签处理成树形结构,支持无限层级
做富文本编辑器时,需要将文本里的标题整理成树形数据, // 这里是数据结构 const data [{"id": "hkyrq2ndc-36yttda0lme00","text": "阿萨德阿萨德阿萨","level": 1,"depth": 1,},{"…...
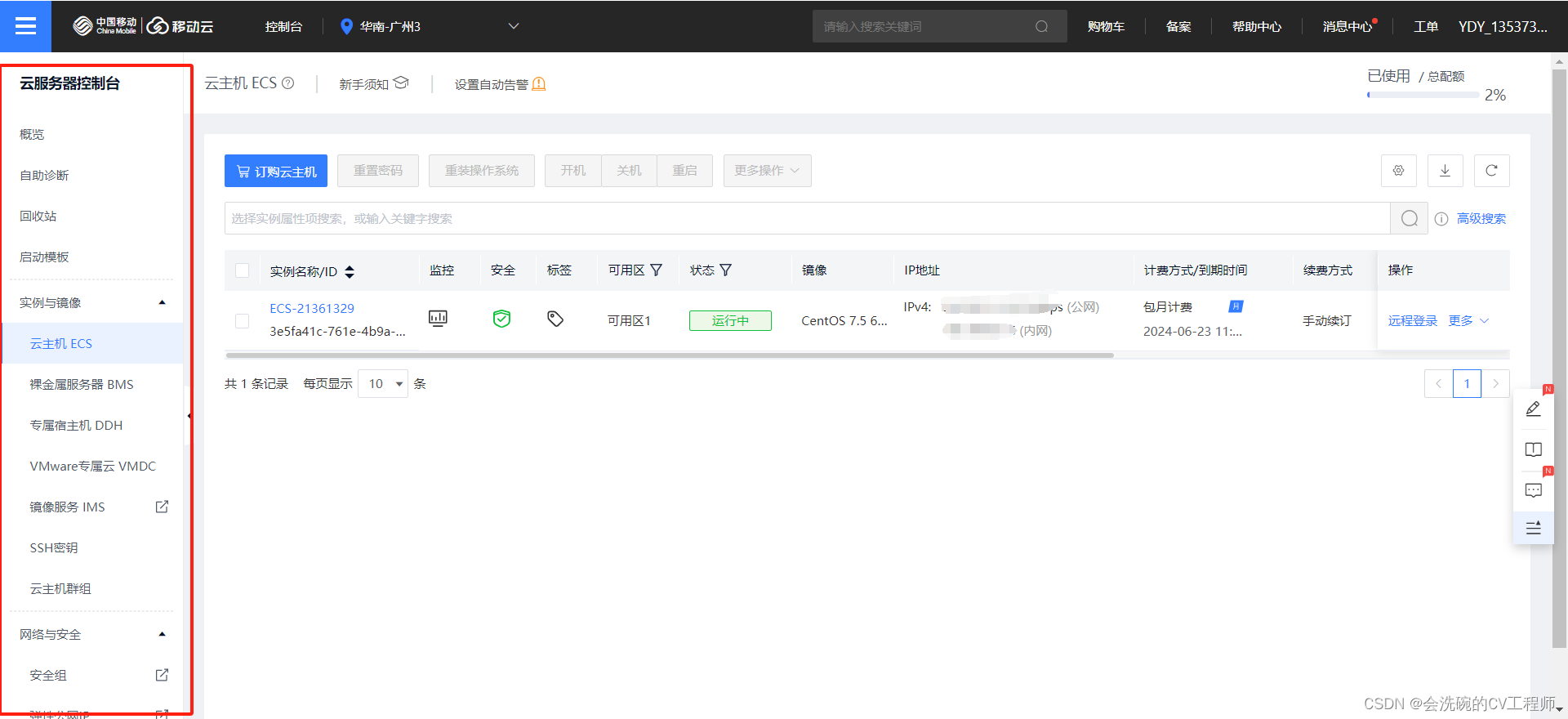
探索移动云:我的ES与Kibana之旅
目录 引言: 如何免费体验移动云产品 登录并完成实名认证 选择试用ECS云主机 安全组配置 安装Elasticsearch和Kibana 安装Elasticsearch 编辑安装kibana 测试结果 使用感觉 引言: 移动云技术产品的发展已经取得了巨大的进步。云数融合、A1、大…...

java 线程执行原理,java线程在jvm中执行流程
java 线程执行原理,java线程在jvm中执行流程 从jvm视角看java线程执行过程 ##首先thread.c注册jni函数 JNIEXPORT void JNICALL Java_java_lang_Thread_registerNatives(JNIEnv *env, jclass cls) {(*env)->RegisterNatives(env, cls, methods, ARRAY_LENGTH(…...
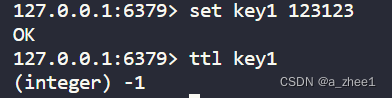
[Redis]基本全局命令
Redis存储方式介绍 在 Redis 中数据是以键值对的凡事存储的,键(Key)和值(Value)是基本的数据存储单元。以下是对 Redis 键值对的详细讲解: 键(Key): 类型:…...

【Linux】- HBase集群部署 [19]
简介 apache HBase是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。 和Redis一样,HBase是一款KeyValue型存储的数据库。 不过和Redis涉及方向不同 Redis设计为少量数据,超快检索HBase设计为海量数据,快速检索 HBase在大数据邻域…...

js如何遍历FormData的值
遍历FormData的值,一般有2种方法:forEach 和 for...of entries const data new FormData();data.append(aaa, 111); data.append(bbb, 222);// 方法1 data.forEach((value, key) > {console.log(key, value); }) 输出 aaa 111 和 bbb 222// 方法2 …...

【C语言】明析部分C语言内存函数
目录 1.memcpy 2.memmove 3.memset 4.memcmp 以下都是内存函数,作用单位均是字节 1.memcpy memcpy是C/C语言中的一个内存拷贝函数,其原型为: void* memcpy(void* dest, const void* src, size_t n);目标空间(字节)…...
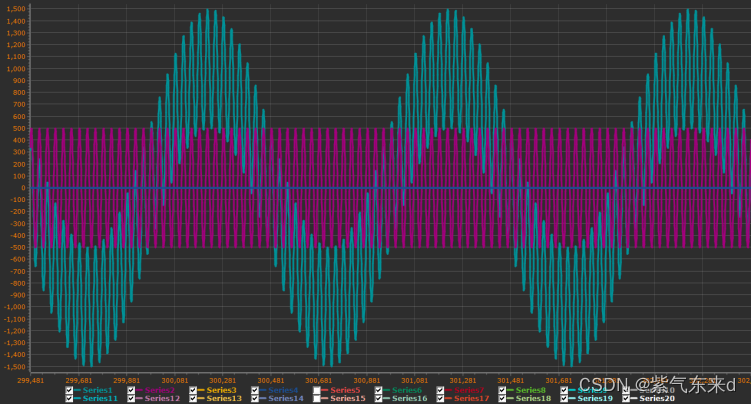
一阶数字高通滤波器
本文的主要内容包含一阶高通滤波器公式的推导和数字算法的实现以及编程和仿真 1 计算公式推导 1.1.2 算法实现及仿真 利用python实现的代码如下: import numpy as np # from scipy.signal import butter, lfilter, freqz import matplotlib.pyplot as plt #2pifW…...
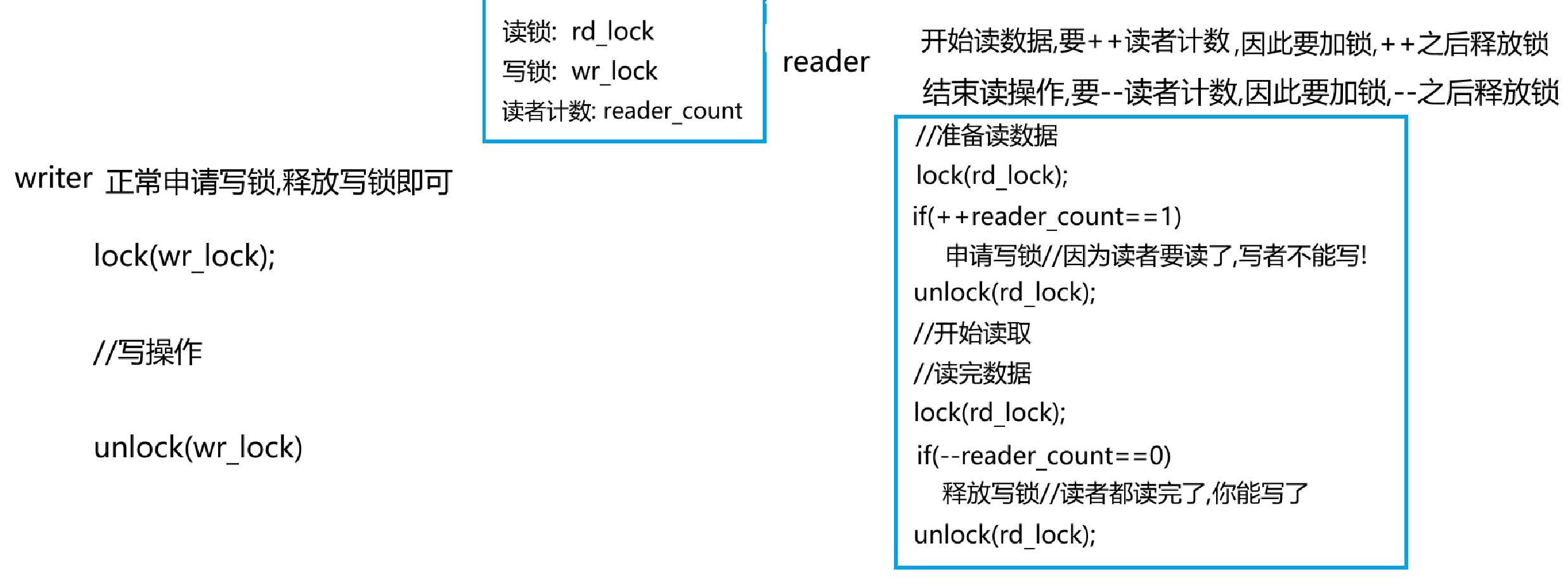
Linux多线程系列2: 模拟封装简易语言级线程库,线程互斥和锁,线程同步和条件变量,线程其他知识点
Linux多线程系列2: 模拟封装简易语言级线程库,线程互斥和互斥锁,线程同步和条件变量,线程其他知识点 1.前言 一.模拟C11线程库自己封装简易语言级线程库1.实现框架2.迅速把构造等等函数写完3.start和work1.尝试一2.尝试二3.最终版本4.给出代码 二.模拟实现多线程(为编写线程池做…...
VUE3-form表单保存附件与基本信息
element-ui代码 <el-dialog :title"上传附件" v-model"dialogAdds.visible" width"500px" append-to-body> <el-form-item label"唯一标识"> <dict-tag v-if"form.groupId" :options"unique_identifica…...

无线网络安全技术基础
无线网络安全技术基础 无线网络安全风险和隐患 随着无线网络技术广泛应用,其安全性越来越引起关注.无线网络的安全主要有访问控制和数据加密,访问控制保证机密数据只能由授权用户访问,而数据加密则要求发送的数据只能被授权用户所接受和使用。 无线网络在数据传输时以微波进…...
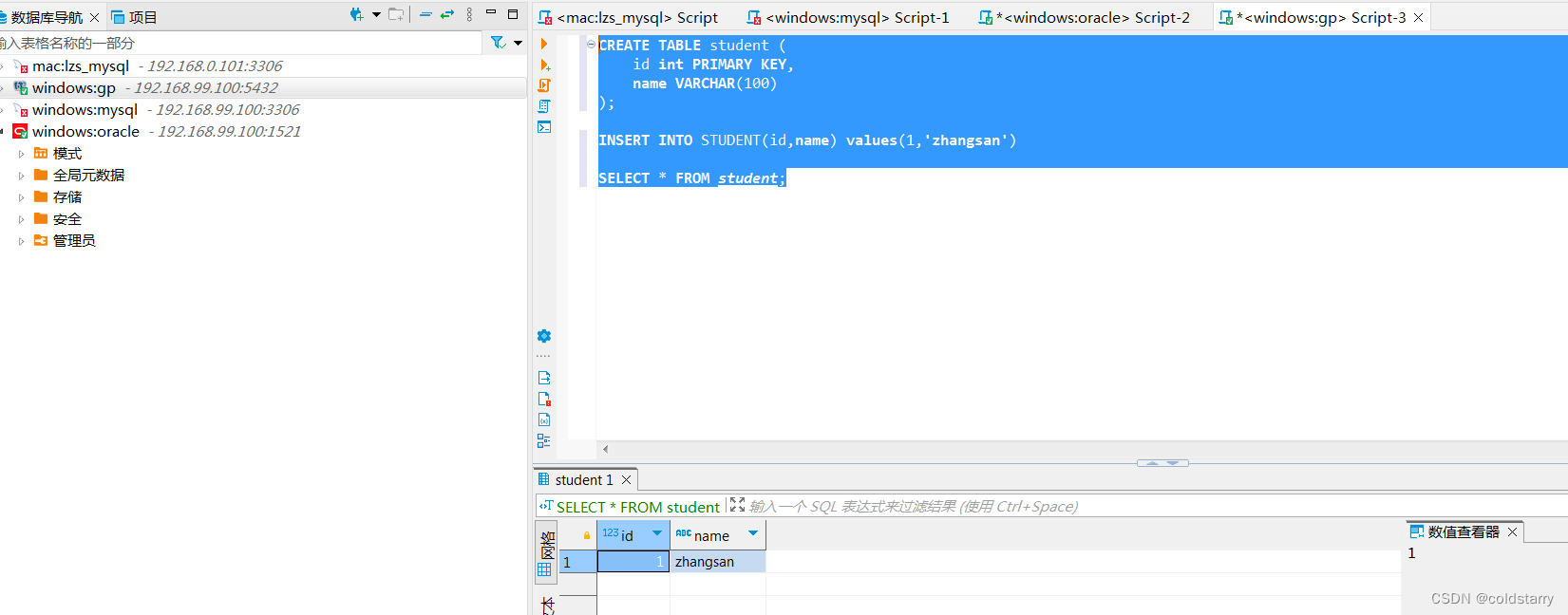
sheng的学习笔记-docker部署Greenplum
目录 docker安装gp数据库 mac版本 搭建gp数据库 连接数据库 windows版本 搭建gp数据库 连接数据库 docker安装gp数据库 mac版本 搭建gp数据库 打开终端,输入代码,查看版本 ocker search greenplum docker pull projectairws/greenplum docker…...

【投稿资讯】区块链会议CCF A -- SP 2025 截止6.6、11.14 附录用率
会议名称:46th IEEE Symposium on Security and Privacy( S&P) CCF等级:CCF A类学术会议 类别:网络与信息安全 录用率:2023年 195/1147,2024年录用了17篇和区块链相关的论文 Topics of interest inc…...

C++哪些函数不能被声明为虚函数
在C中,某些函数不能被声明为虚函数。下面详细解释哪些函数不能被声明为虚函数,并通过代码示例进行说明。 C哪些函数不能被声明为虚函数 不能声明为虚函数的函数示例代码及解释一、构造函数不能是虚函数二、静态成员函数不能是虚函数三、友元函数不能是虚…...

vue中数据已经改变了,但是table里面内容没更新渲染!
解决方案: 给table或者el-table标签上添加一个动态key值,只要数据发生改变,key值变动一下即可 标签上: :key“timeStamp” 初始data:timeStamp:0, 更新数据:this.timeStamp 这样每次更新数据ÿ…...

头歌实践教学平台:Junit实训入门篇
第2关:Junit注解 任务描述 给出一个带有注解的Junit代码及其代码打印输出,要求学员修改注解位置,让输出结果变为逆序。 相关知识 Junit注解 Java注解((Annotation)的使用方法是" 注解名" 。借助注解&a…...
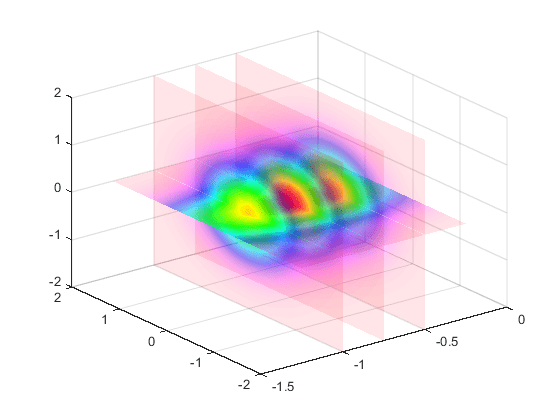
matlab使用教程(80)—修改图形对象的透明度
1.更改图像、填充或曲面的透明度 此示例说明如何修改图像、填充或曲面的透明度。 1.1坐标区框中所有对象的透明度 透明度值称为 alpha 值。使用 alpha 函数设置当前坐标区范围内所有图像、填充或曲面对象的透明度。指定一个介于 0(完全透明)和 1&#x…...

mysql bin 日志转成sql
首先确定mysql binlog 服务开启 SHOW VARIABLES LIKE log_bin; 找到binlog日志 find / -name mysql-bin.* -type f 下载下来 本地找到mysql安装位置的bin目录 在窗口路径处直接输入cmd 执行 mysqlbinlog --no-defaults --base64-outputdecode-rows -v --start-datetime&…...

将Taotoken作为统一网关整合到企业现有微服务架构中的设计考量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将Taotoken作为统一网关整合到企业现有微服务架构中的设计考量 当企业内部多个业务线或团队开始独立探索和应用大模型能力时&#…...

嘎嘎降AI和率零深度对比:2026年同为低价工具效果差距完整评测报告
嘎嘎降AI和率零深度对比:2026年同为低价工具效果差距完整评测报告 选工具之前做了一周功课,试用了三款,最后定了嘎嘎降AI(www.aigcleaner.com)。 4.8元,知网AI率从61%降到了5.3%,达标率99.26%…...

Postman登录接口响应为空?HTTP响应体未刷出的三层根因分析
1. 这不是Postman的问题,是接口通信链路上某个环节“失语”了你用Postman调后端登录接口,请求发出去了,状态码也回来了(比如200),但响应体里空空如也——没有JSON数据、没有token字段、甚至Response标签页里…...

智能自动化黑苹果配置:OpCore-Simplify全面解析
智能自动化黑苹果配置:OpCore-Simplify全面解析 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify OpCore-Simplify是一款革命性的黑苹果配置…...

PDFPatcher完全指南:用免费开源工具解决PDF格式难题的5个实战技巧
PDFPatcher完全指南:用免费开源工具解决PDF格式难题的5个实战技巧 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址:…...

如何利用Taotoken的账单追溯功能分析月度模型使用情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何利用Taotoken的账单追溯功能分析月度模型使用情况 对于依赖大模型API进行开发或运营的团队而言,清晰、透明的成本核…...

3步高效启用Windows Insider预览计划:免登录离线方案终极指南
3步高效启用Windows Insider预览计划:免登录离线方案终极指南 【免费下载链接】offlineinsiderenroll OfflineInsiderEnroll - A script to enable access to the Windows Insider Program on machines not signed in with Microsoft Account 项目地址: https://g…...

利用 Taotoken 的模型广场为你的智能客服场景挑选合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 的模型广场为你的智能客服场景挑选合适模型 构建智能客服或对话系统时,一个核心挑战是如何从众多大模型…...

从任务栏消失到界面混乱:如何用ExplorerPatcher拯救你的Windows 11体验
从任务栏消失到界面混乱:如何用ExplorerPatcher拯救你的Windows 11体验 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 你是否经历…...

ncmdump:网易云NCM音乐解密转换终极指南
ncmdump:网易云NCM音乐解密转换终极指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 在数字音乐时代,网易云音乐的NCM加密格式成为众多音乐爱好者的使用障碍。ncmdump作为一款高效的开源解密工具ÿ…...