quartz定时任务
Quartz
数据结构
quartz采用完全二叉树:除了最后一层每一层节点都是满的,而且最后一层靠左排列。
二叉树节点个数规则:每层从左开始,第一层只有一个,就是2的0次幂,第二层两个就是2的1次幂,第三层4个就是2的2次幂,…
quartz采用二叉树的数据结构,因为二叉树有小顶堆与大顶堆的特性,即把最小或者最大的节点放到最上面,而quartz总是要先执行最快到时间的,所以quartz去小顶堆的顶点去拿最快到期的任务去执行。
java没有支持二叉树的代码,quartz将二叉树放入数组,从顶点开始,依照自上而下从左到右的方式存入数组中。
quartz创建新的定时任务时会放入数组最后,也就是二叉树最下层,然后会将这个任务节点与父节点作比较,比父节点小就上浮,直到不小于父节点为止;
quartz执行了顶点最快到期的任务后会将顶点删除,然后将最下面的节点放到顶点,然后与相邻下一层的最小节点比较,大于它则下沉,直到沉到没有小于它的节点
整体架构
Job
定义
定时任务业务类,用于执行业务逻辑,你可以只创建一个job类,然后创建多个与该job关联的JobDetail实例,每一个实例都有自己的属性集和JobDataMap,最后,将所有的实例都加到scheduler中。
Job分为有状态(保存数据)和无状态(不保存数据),有状态的Job为StatefulJob接口,无状态的为Job接口。
使用
需要实现Job接口重写execute方法
import org.quartz.*;public class MyJob implements Job {@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException { //业务代码}
}生命周期:每次在调度器在执行job的时候,他是在execute()方法前创建一个新的job实例(JobDetail)。当调用完之后,关联的job对象实例会被释放,释放之后将会被垃圾回收机制回收
JobDetail
定义
job的实例,封装job并描述job的细节,job为实际执行的业务,一个job可对应多个jobdetail
使用
//MyJob为实际业务类,可以从 jobDetail1 中获取任务信息
JobDetail jobDetail1 = JobBuilder.newJob(MyJob.class).build();
JobDataMap
定义
存储数据对象,用于定时任务执行时使用,在job实例对象被执行时调用,可同时用于JobDetail与Trigger
使用
通过
.usingJobData("key","value")
或
.JobDataMap.Put("myclass", myclass)
方法赋值,
还可以用此方法直接给Job业务类成员变量赋值
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)/**可以在业务类MyJob中通过context.getJobDetail().getJobDataMap()获取*/.usingJobData("job","jobDetail")/**可以直接赋值到业务类MyJob的name属性中*/.usingJobData("name","jobDetail").usingJobData("count1",0).build();//也可以用 jobDetail.JobDataMap.Put("myclass", myclass);Trigger trigger = TriggerBuilder.newTrigger()/**可以在业务类MyJob中通过context.getTrigger().getJobDataMap()获取*/.usingJobData("trigger","trigger")/**会覆盖JobDetail中对业务类MyJob的name属性的赋值*/.usingJobData("name","trigger").startNow().withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1).repeatForever()).build();
在业务Job类中通过JobDetailMap的getString("key")获取
public class MyJob implements Job {private String name;public void setName(String name) {this.name = name;}@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {System.out.println("name:"+name);//从触发器获取JobDataMap triggerMap = context.getTrigger().getJobDataMap();//从任务获取JobDataMap jobDetailMap = context.getJobDetail().getJobDataMap();System.out.println("jobDetailMap:"+jobDetailMap.getString("job"));System.out.println("triggerMap:"+triggerMap.getString("trigger"));}
}
/*** 获取JobDetail与Trigger的JobDataMap,并拼到一个map中,但是key重复会覆盖* */
JobDataMap mergeMap = context.getMergedJobDataMap();序列化问题
如果你使用的是持久化的存储机制(JDBCJobStore),在决定JobDataMap中存放什么数据的时候需要小心,因为JobDataMap中存储的对象都会被序列化,因此很可能会导致类的版本不一致的问题;Java的标准类型都很安全,如果你已经有了一个类的序列化后的实例,某个时候,别人修改了该类的定义,此时你需要确保对类的修改没有破坏兼容性;更多细节,参考下方描述。另外,你也可以配置JDBC-JobStore和JobDataMap,使得map中仅允许存储基本类型和String类型的数据,这样可以避免后续的序列化问题。
Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。当实现java.io.Serializable接口的实体(类)没有显式地定义一个名为serialVersionUID,类型为long的变量时,Java序列化机制会根据编译的class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,只有同一次编译生成的class才会生成相同的serialVersionUID 。即:我们没有显式指定一个版本号serialVersionUID,在修改序列化的类后就会反序列化失败。我们应该总是显式指定一个版本号,这样做的话我们不仅可以增强对序列化版本的控制,而且也提高了代码的可移植性。因为不同的JVM有可能使用不同的策略来计算这个版本号,那样的话同一个类在不同的JVM下也会认为是不同的版本。
Trigger
触发器,定义定时任务触发规则,即时间。
Trigger的公共属性
trigger的公共属性有:
jobKey属性:当trigger触发时被执行的job的身份;startTime属性:设置trigger第一次触发的时间;该属性的值是java.util.Date类型,表示某个指定的时间点;有些类型的trigger,会在设置的startTime时立即触发,有些类型的trigger,表示其触发是在startTime之后开始生效。比如,现在是1月份,你设置了一个trigger–“在每个月的第5天执行”,然后你将startTime属性设置为4月1号,则该trigger第一次触发会是在几个月以后了(即4月5号)。endTime属性:表示trigger失效的时间点。比如,”每月第5天执行”的trigger,如果其endTime是7月1号,则其最后一次执行时间是6月5号。
优先级(priority)
如果你的trigger很多(或者Quartz线程池的工作线程太少),Quartz可能没有足够的资源同时触发所有的trigger;这种情况下,你可能希望控制哪些trigger优先使用Quartz的工作线程,要达到该目的,可以在trigger上设置priority属性。比如,你有N个trigger需要同时触发,但只有Z个工作线程,优先级最高的Z个trigger会被首先触发。如果没有为trigger设置优先级,trigger使用默认优先级,值为5;priority属性的值可以是任意整数,正数、负数都可以。
注意:只有同时触发的trigger之间才会比较优先级。10:59触发的trigger总是在11:00触发的trigger之前执行。
注意:如果trigger是可恢复的,在恢复后再调度时,优先级与原trigger是一样的。
错过触发(misfire Instructions)
trigger还有一个重要的属性misfire;如果scheduler关闭了,或者Quartz线程池中没有可用的线程来执行job,此时持久性的trigger就会错过(miss)其触发时间,即错过触发(misfire)。
导致misfire有三个原因:
- 所有工作线程都忙于运行其他作业(可能具有更高的优先级)
- 调度程序本身已关闭
- 该作业是在过去的开始时间安排的(可能是编码错误)
不同类型的trigger,有不同的misfire机制。**它们默认都使用“智能机制(smart policy)”,**即根据trigger的类型和配置动态调整行为。当scheduler启动的时候,查询所有错过触发(misfire)的持久性trigger。然后根据它们各自的misfire机制更新trigger的信息。当你在项目中使用Quartz时,你应该对各种类型的trigger的misfire机制都比较熟悉,这些misfire机制在JavaDoc中有说明。关于misfire机制的细节,会在讲到具体的trigger时作介绍。
所有的trigger都有一个Trigger.MISFIRE_INSTRUCTION_SMART_POLICY '智能机制(smart policy)'策略可以使用,该策略也是所有trigger的默认策略。如果使用smart policy,SimpleTrigger会根据实例的配置及状态,在所有MISFIRE策略中动态选择一种Misfire策略。
日历示例(calendar)
Quartz的Calendar对象(不是java.util.Calendar对象)可以在定义和存储trigger的时候与trigger进行关联。Calendar用于从trigger的调度计划中排除时间段。比如,可以创建一个trigger,每个工作日的上午9:30执行,然后增加一个Calendar,排除掉所有的商业节日。
org.quartz.impl.calendar包下BaseCalendar
为高级的 Calendar 实现了基本的功能,实现了 org.quartz.Calendar 接口AnnualCalendar
排除年中一天或多天CronCalendar
日历的这种实现排除了由给定的CronExpression表达的时间集合。 例如,您可以使用此日历使用表达式“* * 0-7,18-23?* *”每天排除所有营业时间(上午8点至下午5点)。 如果CronTrigger具有给定的cron表达式并且与具有相同表达式的CronCalendar相关联,则日历将排除触发器包含的所有时间,并且它们将彼此抵消。DailyCalendar
您可以使用此日历来排除营业时间(上午8点 - 5点)每天。 每个DailyCalendar仅允许指定单个时间范围,并且该时间范围可能不会跨越每日边界(即,您不能指定从上午8点至凌晨5点的时间范围)。 如果属性invertTimeRange为false(默认),则时间范围定义触发器不允许触发的时间范围。 如果invertTimeRange为true,则时间范围被反转 - 也就是排除在定义的时间范围之外的所有时间。HolidayCalendar
特别的用于从 Trigger 中排除节假日MonthlyCalendar
排除月份中的指定数天,例如,可用于排除每月的最后一天WeeklyCalendar
排除星期中的任意周几,例如,可用于排除周末,默认周六和周日
使用Calendar的步骤较为简单:
第一步,创建Calendar, 并添加到Scheduler中。
DailyCalendar calendar = new DailyCalendar("9:22:00","9:30:00");
scheduler.addCalendar("calendar", calendar, false, false);
第二步,使用TriggerBuilder方法时,添加modifiedbyCalendar,参数为calendar的名称。
return TriggerBuilder.newTrigger().withIdentity("test trigger", "test").startNow().withSchedule(simpleSchedule().repeatSecondlyForTotalCount(6).withIntervalInMinutes(1)).modifiedByCalendar("calendar").build();
Trigger种类
五种类型的 Trigger(2.3.2版本):SimpleTrigger,CronTrigger,CalendarIntervalTrigger,DailyTimeIntervalTrigger,MutableTrigger,OperableTrigger
最常用的:
| SimpleTrigger(简单触发器) | 进行简单的触发,仅需触发一次或者以固定时间间隔周期执行:如每日的5点执行一次;每分钟执行一次 |
|---|---|
| CronTrigger(表达式触发器) | 进行复杂的触发:如每月的第几周第几天什么时候执行 |
/**StartAt() 表示触发器的时间表首次被触发的时间。它的值的类型是java.util.Date。EndAt() 指定触发器的不再被触发的时间。它的值是java.util.Date。
*/
Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1","trigger1")/**立即执行*/.startNow()/**简单调度,每秒执行一次*/.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1).repeatForever()).build();SimpleTrigger
SimpleTrigger可以满足的调度需求是:在具体的时间点执行一次;或者在具体的时间点执行,并且以指定的间隔重复执行若干次。
SimpleTrigger的属性包括:开始时间、结束时间、重复次数以及重复的间隔。重复次数,可以是0、正整数,以及常量SimpleTrigger.REPEAT_INDEFINITELY。重复的间隔,必须是0,或者long型的正数,表示毫秒。注意,如果重复间隔为0,trigger将会以重复次数并发执行(或者以scheduler可以处理的近似并发数)。
指定时间开始触发,不重复(执行一次):
SimpleTrigger trigger = (SimpleTrigger) newTrigger() .withIdentity("trigger1", "group1").startAt(myStartTime) // some Date .forJob("job1", "group1") // identify job with name, group strings.build();
指定时间触发,每隔10秒执行一次,重复10次:
trigger = newTrigger().withIdentity("trigger3", "group1").startAt(myTimeToStartFiring) // if a start time is not given (if this line were omitted), "now" is implied.withSchedule(simpleSchedule().withIntervalInSeconds(10).withRepeatCount(10)) // note that 10 repeats will give a total of 11 firings.forJob(myJob) // identify job with handle to its JobDetail itself .build();
5分钟以后开始触发,仅执行一次:
trigger = (SimpleTrigger) newTrigger() .withIdentity("trigger5", "group1").startAt(futureDate(5, IntervalUnit.MINUTE)) // use DateBuilder to create a date in the future.forJob(myJobKey) // identify job with its JobKey.build();
立即触发,每个5分钟执行一次,直到22:00:
trigger = newTrigger().withIdentity("trigger7", "group1").withSchedule(simpleSchedule().withIntervalInMinutes(5).repeatForever()).endAt(dateOf(22, 0, 0)).build();
建立一个触发器,将在下一个小时的整点触发,然后每2小时重复一次:
trigger = newTrigger().withIdentity("trigger8") // because group is not specified, "trigger8" will be in the default group.startAt(evenHourDate(null)) // get the next even-hour (minutes and seconds zero ("00:00")).withSchedule(simpleSchedule().withIntervalInHours(2).repeatForever())// note that in this example, 'forJob(..)' is not called which is valid // if the trigger is passed to the scheduler along with the job .build();scheduler.scheduleJob(trigger, job);
请查阅TriggerBuilder和SimpleScheduleBuilder提供的方法,以便对上述示例中未提到的选项有所了解。
TriggerBuilder(以及Quartz的其它builder)会为那些没有被显式设置的属性选择合理的默认值。比如:如果你没有调用withIdentity(..)方法,TriggerBuilder会为trigger生成一个随机的名称;如果没有调用startAt(..)方法,则默认使用当前时间,即trigger立即生效。
SimpleTrigger的Misfire策略常量:
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
MISFIRE_INSTRUCTION_FIRE_NOW
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT
在使用SimpleTrigger构造trigger时,misfire策略作为基本调度(simple schedule)的一部分进行配置(通过SimpleSchedulerBuilder设置):
trigger = newTrigger().withIdentity("trigger7", "group1").withSchedule(simpleSchedule().withIntervalInMinutes(5).repeatForever().withMisfireHandlingInstructionNextWithExistingCount()).build();
CronTrigger
CronTrigger通常比Simple Trigger更有用,如果您需要基于日历的概念而不是按照SimpleTrigger的精确指定间隔进行重新启动的作业启动计划。
使用CronTrigger,您可以指定号时间表,例如“每周五中午”或“每个工作日和上午9:30”,甚至“每周一至周五上午9:00至10点之间每5分钟”和1月份的星期五“。
即使如此,和SimpleTrigger一样,CronTrigger有一个startTime,它指定何时生效,以及一个(可选的)endTime,用于指定何时停止计划。
cron表达式生成器:https://cron.qqe2.com/
建立一个触发器,每隔两分钟,每天上午8点至下午5点之间:
trigger = newTrigger().withIdentity("trigger3", "group1").withSchedule(cronSchedule("0 0/2 8-17 * * ?")).forJob("myJob", "group1").build();
建立一个触发器,将在上午10:42每天发射:
trigger = newTrigger().withIdentity("trigger3", "group1").withSchedule(dailyAtHourAndMinute(10, 42)).forJob(myJobKey).build();
或者:
trigger = newTrigger().withIdentity("trigger3", "group1").withSchedule(cronSchedule("0 42 10 * * ?")).forJob(myJobKey).build();
建立一个触发器,将在星期三上午10:42在TimeZone(系统默认值)之外触发:
trigger = newTrigger().withIdentity("trigger3", "group1").withSchedule(weeklyOnDayAndHourAndMinute(DateBuilder.WEDNESDAY, 10, 42)).forJob(myJobKey).inTimeZone(TimeZone.getTimeZone("America/Los_Angeles")).build();
或者:
trigger = newTrigger().withIdentity("trigger3", "group1").withSchedule(cronSchedule("0 42 10 ? * WED")).inTimeZone(TimeZone.getTimeZone("America/Los_Angeles")).forJob(myJobKey).build();
CronTrigger的Misfire指令常数
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
MISFIRE_INSTRUCTION_DO_NOTHING
MISFIRE_INSTRUCTION_FIRE_NOW
在构建CronTriggers时,您可以将misfire指令指定为简单计划的一部分(通过CronSchedulerBuilder):
trigger = newTrigger().withIdentity("trigger3", "group1").withSchedule(cronSchedule("0 0/2 8-17 * * ?").withMisfireHandlingInstructionFireAndProceed()).forJob("myJob", "group1").build();
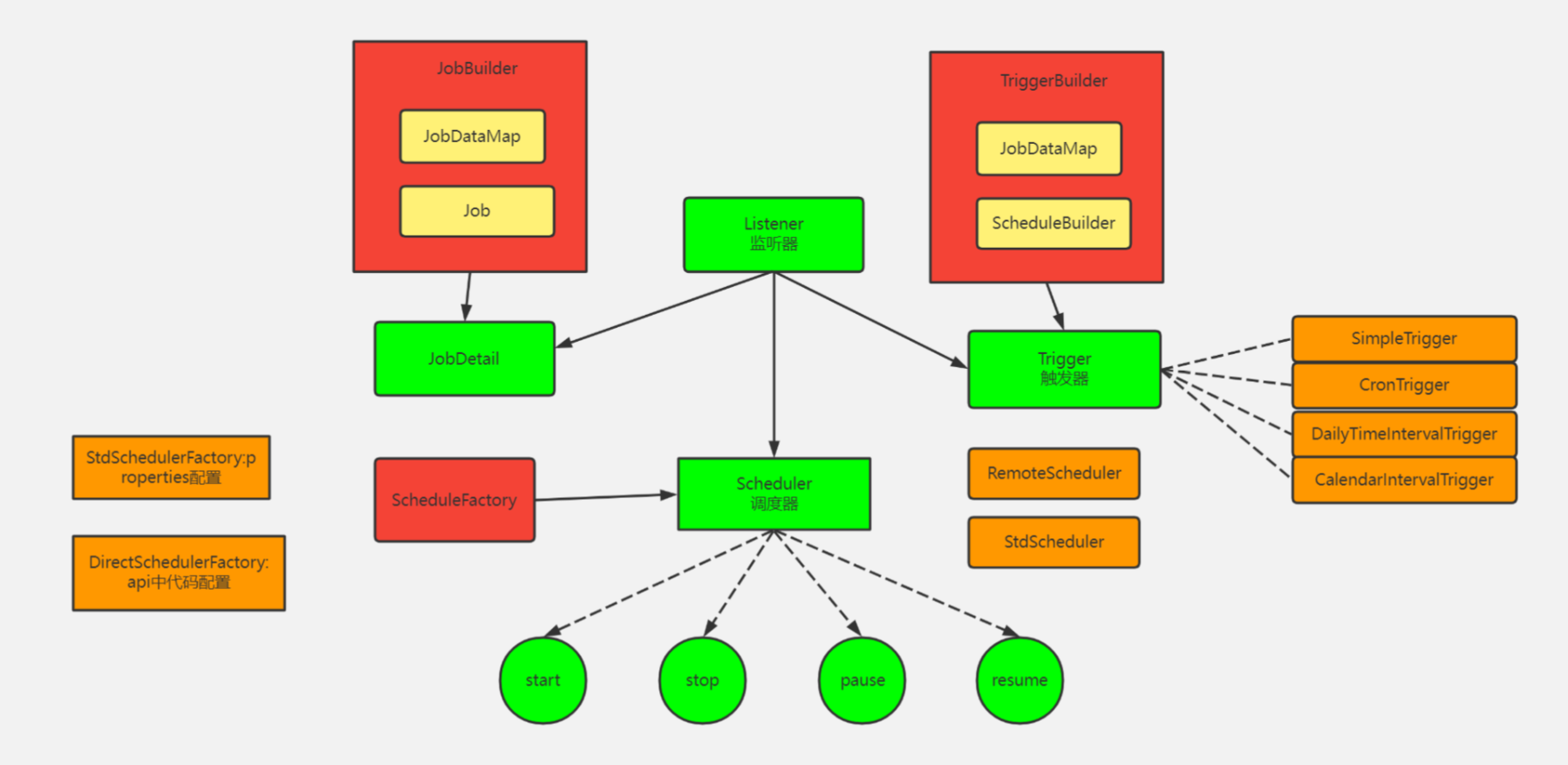
Scheduler
定义
调度器,通过线程池进行任务调度,按照Trigger定义的时间执行Job,它是单例的。
Scheduler 中的方法主要分为三大类:
- 操作调度器本身,例如调度器的启动
start()、调度器的关闭shutdown()。 - 操作
Trigger,例如pauseTriggers()、resumeTrigger()。 - 操作
Job,例如scheduleJob()、unscheduleJob()、rescheduleJob()
使用
默认情况下,StdSchedulerFactory从当前工作目录加载“quartz.properties”文件。如果加载失败,那么就会尝试加载org/quartz包下的“quartz.properties”文件。如果不想用默认的文件,你可以定义一个系统属性“org.quartz.properties”指向你想要的文件。
try {Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();//加载quartz自带的org.quartz.properties//结合了jobDetail与trigger进行调度scheduler.scheduleJob(jobDetail,trigger);scheduler.start();} catch (SchedulerException e) {e.printStackTrace();}
Scheduler 的生命期
Scheduler 的生命期,从 SchedulerFactory 创建它时开始,到 Scheduler 调用shutdown() 方法时结束;Scheduler 被创建后,可以增加、删除和列举 Job 和 Trigger,以及执行其它与调度相关的操作(如暂停 Trigger)。但是,Scheduler 只有在调用 start() 方法后,才会真正地触发 trigger(即执行 job)
Scheduler 创建
Scheduler接口有两个实现类,分别为StdScheduler(标准默认调度器)和RemoteScheduler(远程调度器)
常用的是StdSchedulerFactory
1.通过DirectSchedulerFactory创建一个实例:
public static void main(String[] args) {try {DirectSchedulerFactory schedulerFactory = DirectSchedulerFactory.getInstance();// 表示以3个工作线程初始化工厂schedulerFactory.createVolatileScheduler(3);Scheduler scheduler = schedulerFactory.getScheduler(); } catch (SchedulerException e) {e.printStackTrace();}}
创建步骤:
1、通过DirectSchedulerFactory的getInstance方法得到拿到实例
2、调用createXXX方法初始化工厂
3、调用工厂实例的getScheduler方法拿到调度器实例
可以看出,DirectSchedulerFactory是通过createXXX方法传递配置参数来初始化工厂,这种初始化方式是一种硬编码,在工作中用到的情况会很少。
2.使用StdSchedulerFactory工厂创建
此工厂是依赖一系列的属性来决定如何创建调度器实例的。
属性提供的方式有三种:
1、通过java.util.Properties属性实例
2、通过外部属性文件提供
3、通过有属性文件内容的 java.io.InputStream 文件流提供
public static void main(String[] args) {try {StdSchedulerFactory schedulerFactory = new StdSchedulerFactory();// 第一种方式 通过Properties属性实例创建Properties props = new Properties();props.put(StdSchedulerFactory.PROP_THREAD_POOL_CLASS, "org.quartz.simpl.SimpleThreadPool");props.put("org.quartz.threadPool.threadCount", 5);schedulerFactory.initialize(props);// 第二种方式 通过传入文件名// schedulerFactory.initialize("my.properties");// 第三种方式 通过传入包含属性内容的文件输入流// InputStream is = new FileInputStream(new File("my.properties"));// schedulerFactory.initialize(is);// 获取调度器实例Scheduler scheduler = schedulerFactory.getScheduler();} catch (Exception e) {e.printStackTrace();}}
JobStore数据库连接
Jobstore用来存储任务和触发器相关的信息,例如所有任务的名称、数量、状态等等。Quartz中有两种存储任务的方式,一种在在内存,一种是在数据库。详细见下方。
其他
QuartzSchedulerThread:负责执行向QuartzScheduler注册的触发Trigger的工作的线程。
ThreadPool:Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提供运行效率。
QuartzSchedulerResources:包含创建QuartzScheduler实例所需的所有资源(JobStore,ThreadPool等)。
SchedulerFactory :用于获取调度器实例。
JobStore: 通过类实现的接口,这些类要为org.quartz.core.QuartzScheduler的使用提供一个org.quartz.Job和org.quartz.Trigger存储机制。作业和触发器的存储应该以其名称和组的组合为唯一性。
QuartzScheduler :这是Quartz的核心,它是org.quartz.Scheduler接口的间接实现,包含调度org.quartz.Jobs,注册org.quartz.JobListener实例等的方法。
Scheduler :这是Quartz Scheduler的主要接口,代表一个独立运行容器。调度程序维护JobDetails和触发器的注册表。 一旦注册,调度程序负责执行作业,当他们的相关联的触发器触发(当他们的预定时间到达时)。
Trigger :具有所有触发器通用属性的基本接口,描述了job执行的时间出发规则。 - 使用TriggerBuilder实例化实际触发器。
JobDetail :传递给定作业实例的详细信息属性。 JobDetails将使用JobBuilder创建/定义。
Job:要由表示要执行的“作业”的类实现的接口。只有一个方法 void execute(jobExecutionContext context)
(jobExecutionContext 提供调度上下文各种信息,运行时数据保存在jobDataMap中)
Job有个子接口StatefulJob ,代表有状态任务。有状态任务不可并发,前次任务没有执行完,后面任务处于阻塞等到。
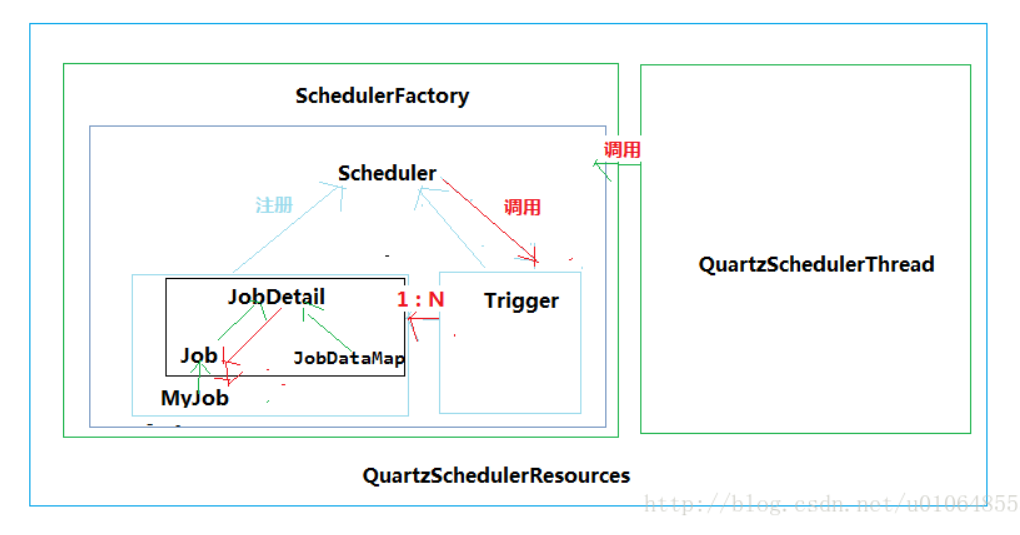
一个job可以被多个Trigger 绑定,但是一个Trigger只能绑定一个job!
Scheduler可以同时调度多组Trigger 及JobDetail
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();scheduler.scheduleJob(jobDetail,trigger);scheduler.scheduleJob(jobDetail,trigger);scheduler.start();
Job并发及持久化
@DisallowConcurrentExecution
将该注解加到job类上,告诉Quartz不要并发地执行同一个job定义(这里指特定的job类)的多个实例。
此注解加在Job类上,但实际运行生效的是JobDetail
scheduler是默认多线程并发访问资源的, 可以避免争抢及定时任务堵塞.
比如前一个任务没执行完,间隔时间就过了,又来了下一个,此时下一个正常执行,不等上一个执行完再执行除非使用@DisallowConcurrentExecution注解
此注解会保证必须上一个任务执行完成后在执行下一个,即使超过了间隔时间,如果超时,会在执行完立刻执行下一次,不会再等过了间隔时间再执行.
比如间隔为1秒,上个任务执行了3秒,3秒后会立即执行下一个任务,而不是等4秒再执行
@PersistJobDataAfterExecution
Job分为有状态(保存数据)和无状态(不保存数据),有状态的Job为StatefulJob接口,无状态的为Job接口。
无状态任务在执行时,拥有自己的JobDataMap拷贝,对JobData的更改不会影响下次的执行。而有状态任务共享同一个JobDataMap实例,每次任务执行对JobDataMap所做的更改都会保存下来,后面的执行可以看到这个更改。也就是每次执行任务后都会对后面的执行发生影响。
正因为这个原因,无状态的Job可以并发执行,而有状态的StatefulJob不能并发执行,这意味着如果前次的StatefulJob还没有执行完毕,下一次的任务将阻塞等待,直到前次任务执行完毕。有状态任务比无状态任务需要考虑更多的因素,程序往往拥有更高的复杂度,因此除非必要,应该尽量使用无状态的Job。
在quartz的2.3.2版本中,StatefulJob已取消,可以使用@PersistJobDataAfterExecution实现有状态
@PersistJobDataAfterExecution:告诉Quartz在成功执行了Job实现类的execute方法后(没有发生任何异常),更新JobDetail中JobDataMap的数据,使得该JobDetail实例在下一次执行的时候,JobDataMap中是更新后的数据,而不是更新前的旧数据。
而有状态任务共享共享同一个JobDataMap实例,每次任务执行对JobDataMap所做的更改会保存下来,后面的执行可以看到这个更改,也即每次执行任务后都会对后面的执行发生影响。
以下代码示例中JobDetail的count会累加,Trigger不会:
public class TestJob {public static void main(String[] args) {JobDetail jobDetail = JobBuilder.newJob(MyJob.class).withIdentity("job1","group1").usingJobData("count1",0).build();int count=0;Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1","trigger1").usingJobData("count",count)/**立即执行*/.startNow()/**简单调度,每秒执行一次*/.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1).repeatForever()).build();try {Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();scheduler.scheduleJob(jobDetail,trigger);scheduler.start();} catch (SchedulerException e) {e.printStackTrace();}}
}
@PersistJobDataAfterExecution //只对JobDetail有持久化作用,对Trigger没有
public class MyJob implements Job {private String name;public void setName(String name) {this.name = name;}@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {JobDataMap triggerMap = context.getTrigger().getJobDataMap();JobDataMap jobDetailMap = context.getJobDetail().getJobDataMap();triggerMap.put("count",triggerMap.getInt("count")+1);jobDetailMap.put("count1",jobDetailMap.getInt("count1")+1);System.out.println("triggerMap count:"+triggerMap.getInt("count"));System.out.println("jobDetailMap count:"+jobDetailMap.getInt("count1"));}
}
使用建议:
如果你使用了@PersistJobDataAfterExecution注解,则强烈建议你同时使用@DisallowConcurrentExecution注解,因为当同一个job(JobDetail)的两个实例被并发执行时,由于竞争,JobDataMap中存储的数据很可能是不确定的。
JobStore数据库连接
Jobstore用来存储任务和触发器相关的信息,例如所有任务的名称、数量、状态等等。Quartz中有两种存储任务的方式,一种在在内存,一种是在数据库。
RAMJobStore
Quartz默认的 JobStore是 RAMJobstore,也就是把任务和触发器信息运行的信息存储在内存中,用到了 HashMap、TreeSet、HashSet等等数据结构。
如果程序崩溃或重启,所有存储在内存中的数据都会丢失。所以我们需要把这些数据持久化到磁盘。
JDBCJobStore
JDBCJobStore可以通过 JDBC接口,将任务运行数据保存在数据库中。
DataSource设置有两种方法:
一种方法是让Quartz创建和管理DataSource,即在quartz.properties中配置数据源;
另一种是由Quartz正在运行的应用程序服务器管理的DataSource,通过应用管理数据源,比如springboot应用在yml中设置数据库连接,在quartz中注入DataSource使用。
示例为quartz.properties:
#数据库中 quartz表的表名前缀
org.quartz.jobStore.tablePrefix:QRTZ_
#数据源名字,要与下方配置名字一致
org.quartz.jobStore.dataSource:myDS
#配置数据源(此处是否可以不定义而是定义在application.properties中? 待试验)
org.quartz.dataSource.myDS.driver:com.mysql.jdbc.Driver
org.quartz.dataSource.myDS.URL:jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8
org.quartz.dataSource.myDS.user:root
org.quartz.dataSource.myDS.password:123456
org.quartz.dataSource.myDS.validationQuery=select 0 from dual
配置JDBCJobStore以使用DriverDelegate,即数据库代理
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
接下来,您需要通知JobStore您正在使用的表前缀(如上所述)。
使用表前缀配置JDBCJobStore
org.quartz.jobStore.tablePrefix = QRTZ_
JDBC的实现方式有两种,JobStoreSupport类的两个子类:
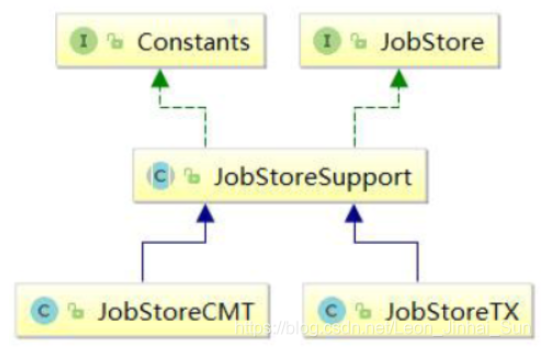
JobStoreTX:在独立的程序中使用,自己管理事务,不参与外部事务。
org.quartz.jobStore.class:org.quartz.impl.jdbcjobstore.JobStoreTX
JobStoreCMT:(Container Managed Transactions (CMT),如果需要容器管理事务时,使用它。使用 JDBCJobSotre时,需要配置数据库信息:
org.quartz.jobStore.class:org.quartz.impl.jdbcjobstore.JobStoreCMT
注意问题
后台报错Table 'seata_order.qrtz_locks' doesn't exist:
检查两处地方,第一处是application中的
spring.datasource.url=jdbc:mysql://42.193.104.62:3306/***? # ***应为对应数据库的名字
第二处是数据库的配置文件,是否开启了不区分大小写
quartz表
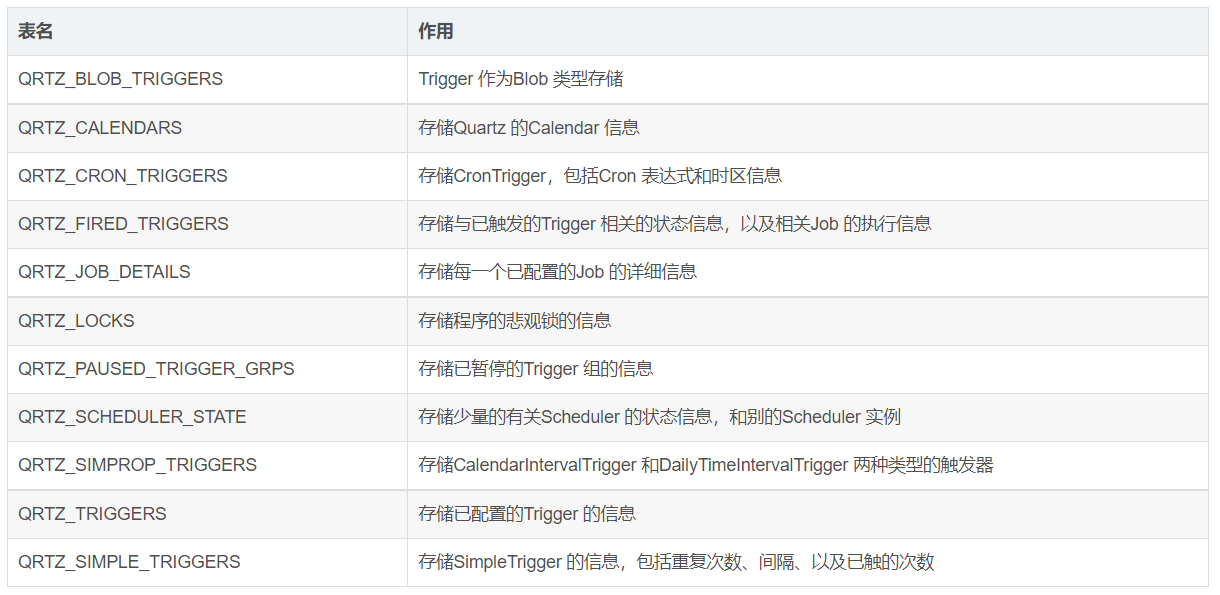
在官网的 Downloads链接中,提供了 11张表的建表语句: quartz-2.2.3-distribution\quartz-2.2.3\docs\dbTables
2.3的版本在这个路径下:src\org\quartz\impl\jdbcjobstore
表名与作用:
配置文件详解
线程池配置
#是要使用的ThreadPool实现的名称。Quartz附带的线程池是“org.quartz.simpl.SimpleThreadPool”,并且几乎能够满足几乎每个用户的需求。它有非常简单的行为,并经过很好的测试。它提供了一个固定大小的线程池。
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool#可用于并发执行作业的线程数,至少为1(无默认值)
org.quartz.threadPool.threadCount=5#设置线程的优先级,可以是Thread.MIN_PRIORITY(即1)和Thread.MAX_PRIORITY(这是10)之间的任何int 。默认值为Thread.NORM_PRIORITY(5)。
org.quartz.threadPool.threadPriority=1#使池中的线程创建为守护进程线程。默认为“false”
org.quartz.threadPool.makeThreadsDaemons=false#在工作池中的线程名称的前缀将被附加一个数字。
org.quartz.threadPool.threadNamePrefix=1#可以是java线程的有效名称的任何字符串。如果未指定此属性,线程将接收调度程序的名称(“org.quartz.scheduler.instanceName”)加上附加的字符#串“_QuartzSchedulerThread”。
org.quartz.scheduler.threadName = _QuartzSchedulerThread
JobStore配置
# 数据保存方式为数据库持久化,并由quartz自己管理事务
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX# 数据保存方式为数据库持久化,并由容器管理事务
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreCMT# 数据库代理类,一般org.quartz.impl.jdbcjobstore.StdJDBCDelegate可以满足大部分数据库
#用于完全符合JDBC的驱动程序,可用于oracle、mysql
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#对于Microsoft SQL Server和Sybase
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.MSSQLDelegate
#其他参见官方文档#数据库中 quartz表的表名前缀
org.quartz.jobStore.tablePrefix:QRTZ_
#数据源名字,要与下方配置名字一致
org.quartz.jobStore.dataSource:myDS
#配置数据源
org.quartz.dataSource.myDS.driver=com.mysql.jdbc.Driver
org.quartz.dataSource.myDS.URL=jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8
org.quartz.dataSource.myDS.user=root
org.quartz.dataSource.myDS.password=123456
#是可选的SQL查询字符串,用于检测连接是否失败。
org.quartz.dataSource.myDS.validationQuery=select 0 from dual#当调查器检测到JobStore中的连接丢失(例如数据库)时,调度程序重试等待时间(以毫秒为单位)
org.quartz.scheduler.dbFailureRetryInterval = 6000其他配置
#使JobDataMaps中的所有值都将是“字符串”,避免了序列化问题
org.quartz.jobStore.useProperties=false#定义了触发器应该多长时间才被认为触发失败,默认为60000(一分钟)
org.quartz.jobStore.misfireThreshold = 60000#Scheduler一次获取trigger的最大数量。默认值为1。这个数字越大,触发效率越高(在有许多trigger需要同时触发的场景下),但是在集群节点之间可能会有负
#载均衡的代价。如果这个属性的值大于1,且使用JDBCJobStore,那么属性“org.quartz.jobStore.acquireTriggersWithinLock”必须设置true,以避免数据损
#坏。
org.quartz.scheduler.batchTriggerAcquisitionMaxCount = 1#防止多个线程同时拉取相同的trigger的情况,也就避免的重复调度的危险
org.quartz.jobStore.acquireTriggersWithinLock = true
集群配置
#是否加入集群 true是 false否
org.quartz.jobStore.isClustered = true# 调度标识名 集群中每一个实例都必须使用相同的名称
org.quartz.scheduler.instanceName = ClusterQuartz# 调度器ID设置为自动获取 每一个必须不同
org.quartz.scheduler.instanceId= AUTO#仅当org.quartz.scheduler.instanceId设置为“AUTO” 时才使用。默认为“org.quartz.simpl.SimpleInstanceIdGenerator”,它根据主机名和时间戳生成实例#ID。其他IntanceIdGenerator实现包括SystemPropertyInstanceIdGenerator(它从系统属性“org.quartz.scheduler.instanceId”获取实例ID,#HostnameInstanceIdGenerator使用本地主机名
org.quartz.scheduler.instanceIdGenerator.class = org.quartz.simpl.SimpleInstanceIdGenerator
其他参考
https://blog.csdn.net/bobozai86/article/details/123777036核心机制
流程
Quartz的核心流程大致分为三个阶段:
- 获取调度实例阶段
- 通过
getScheduler方法根据配置文件加载配置和初始化,创建线程池ThreadPool(默认是SimpleThreadPool,用来执行Quartz调度任务),创建调度器QuartzScheduler,创建调度线程QuartzSchedulerThread,并将调度线程初始状态设置为暂停状态。
- 通过
- 绑定JobDetail和Trigger阶段
Scheduler将任务添加到JobStore中,如果是使用数据库存储信息,这时候会把任务持久化到Quartz核心表中,同时也会对实现JobListener的监听者通知任务已添加
- 启动调度器阶段
Scheduler会调用QuartzScheduler的Start()方法,这时候会把调度线程从暂停切为启动状态,通知QuartzSchedulerThread正式干活。QuartzSchedulerThread会从SimpleThreadPool查看下有多少可用工作线程,然后找JobStore去拿下一批符合条件的待触发的Trigger任务列表,包装成FiredTriggerBundle。通过JobRunShellFactory创建FiredTriggerBundle的执行线程实例JobRunShell,然后把JobRunShell实例交给SimpleThreadPool的工作线程去执行。SimpleThreadPool会从可用线程队列拿出对应数量的线程,去调用JobRunShell的run()方法,此时会执行任务类的execute方法 :job.execute(JobExecutionContext context)。
线程模型
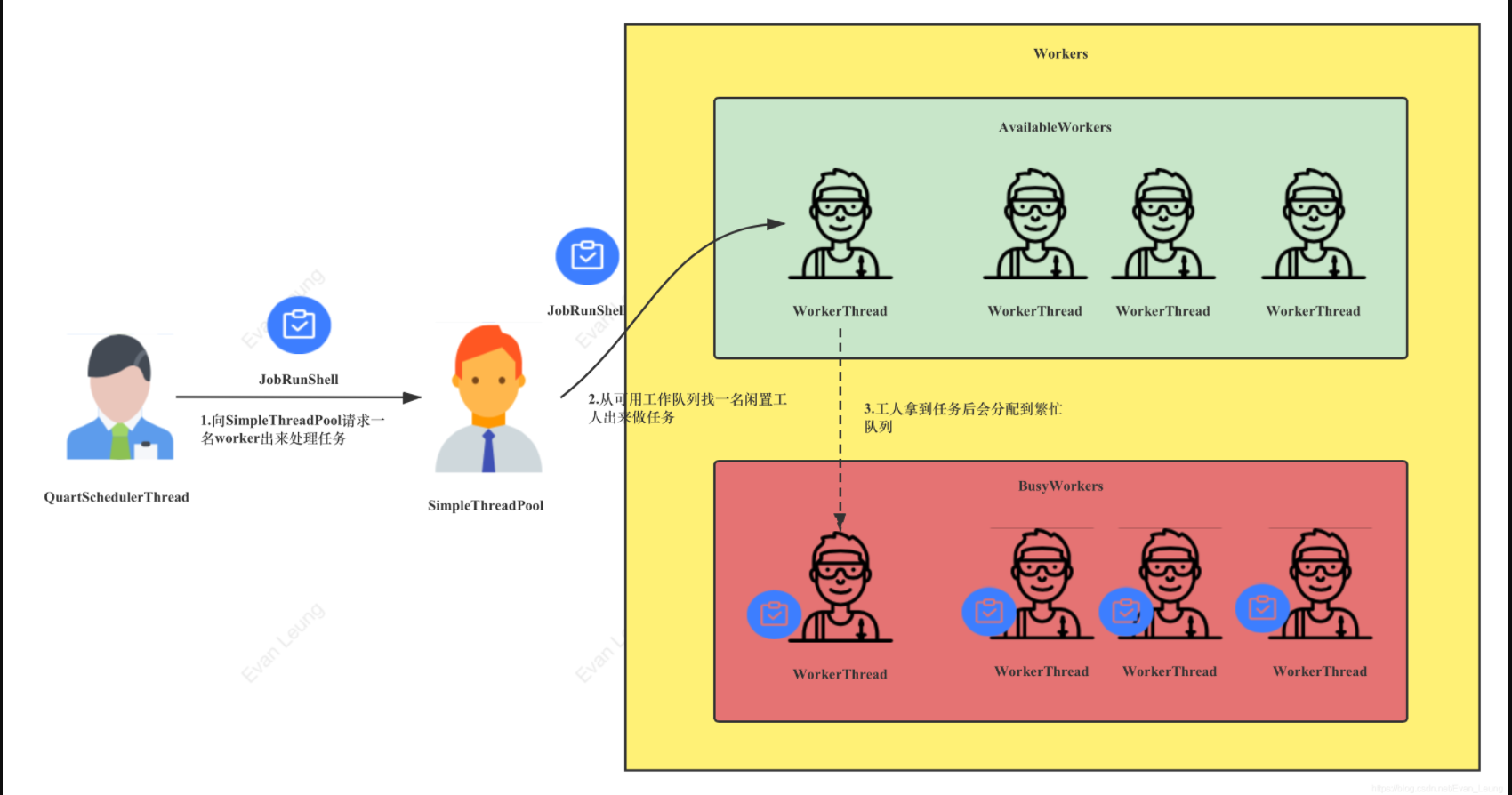
SimpleThreadPool:包工头,管理所有WorkerThreadWorkerThread:工人, 执行JobRunShellJobRunShell:任务,任务中有run()方法,会执行业务类的execute方法 :job.execute(JobExecutionContext context)。QuartSchedulerThread:项目经理,获取即将触发的Trigger,将JobRunShell交给SimpleThreadPool,由SimpleThreadPool调用WorkerThread执行JobRunShell
Quartz集群进程间如何通信
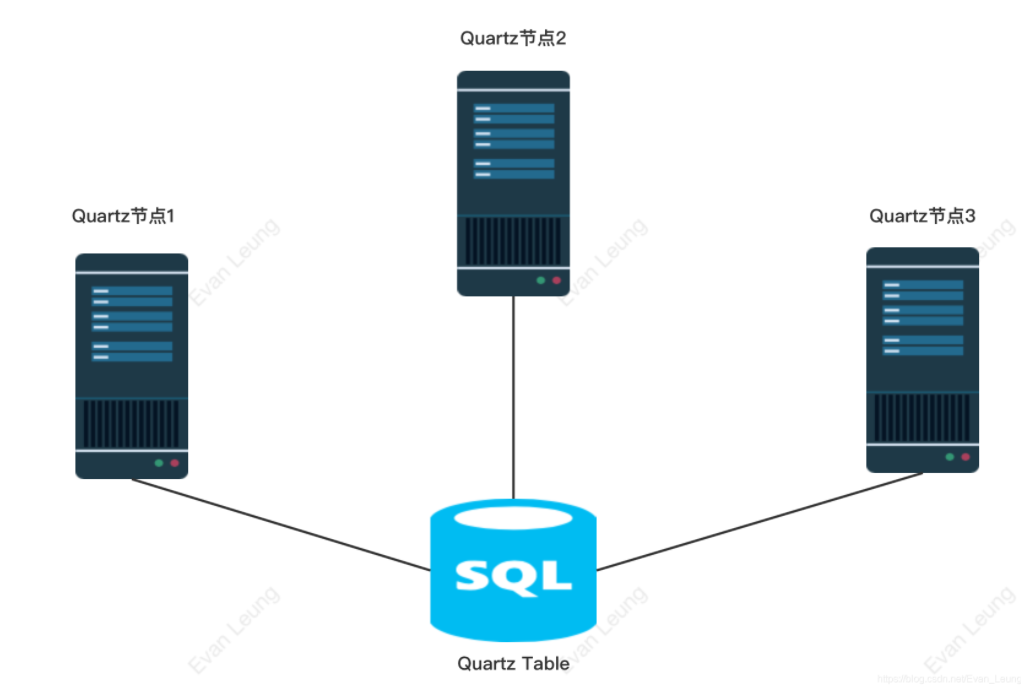
Quartz集群之间是通过数据库几张核心的Quartz表进行通信
Quartz集群如何保证高并发下不重复跑
Quartz有多个节点同时在运行,而任务是共享的,这时候肯定存在资源竞争问题,容易造成并发问题,Quartz节点之间是否存在分布式锁去控制?
Quartz是通过数据库去作为分布式锁来控制多进程并发问题,Quartz加锁的地方很多,Quartz是使用悲观锁的方式进行加锁,让在各个instance操作Trigger任务期间串行,这里挑选核心的代码来看看它是符合利用数据库防止并发的。
使用数据库锁需要在quartz.properties中加以下配置,让集群生效Quartz才会对多个instance进行并发控制
org.quartz.jobStore.isClustered = true
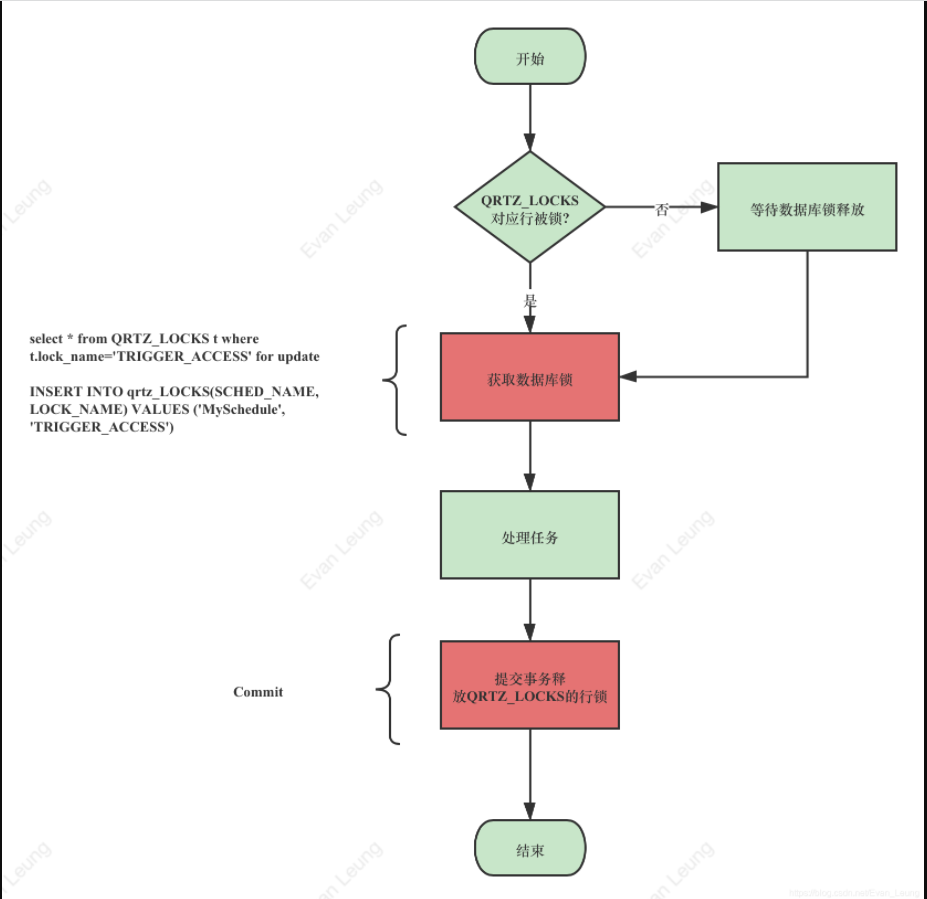
QRTZ_LOCKS 表,它会为每个调度器创建两行数据,获取 Trigger 和触发 Trigger 是两把锁,加锁入口在JobStoreSupport类中,Quartz提供的锁表,为多个节点调度提供分布式锁,实现分布式调度,默认有2个锁
| SCHED_NAME | LOCK_NAME |
|---|---|
| Myscheduler | STATE_ACCESS |
| Myscheduler | TRIGGER_ACCESS |
STATE_ACCESS主要用在scheduler定期检查是否失效的时候,保证只有一个节点去处理已经失效的scheduler;
TRIGGER_ACCESS主要用在TRIGGER被调度的时候,保证只有一个节点去执行调度
Quartz集群如何保证高并发下不漏跑
有时候Quartz可能会错过我们的调度任务:
- 服务重启,没能及时执行任务,就会misfire
- 工作线程去运行优先级更高的任务,就会misfire
- 任务的上一次运行还没结束,下一次触发时间到达,就会misfire
Quartz可提供了一些补偿机制应对misfire情况,用户可以根据需要选择对应的策略,
Quartz常见问题
服务器始终不一致问题
常见异常:
This scheduler instance (SchedulerName) is still active but was recovered by another instance in the cluster
解决:
同步所有集群节点的时间然后重启服务
Quartz集群负载不均衡
Quartz集群是采用抢占式加锁方式去处理任务,因此你会看到每个节点的任务处理日志并不是均衡分配的,很可能一个节点会抢占大量任务导致负载过重,但是这一点官方并没有解决。
错过预定触发时间
常见异常:
Handling 1 trigger(s) that missed their scheduled fire-time
解决:
很可能是你线程数设置太少,而任务执行时间太长,超过的misfire阈值,导致线程池没有可用线程而错过了触发事件。尝试把配置文件线程数调大org.quartz.threadPool.threadCount 或者把misfire阈值调大org.quartz.jobStore.misfireThreshold
简单使用
写业务类job
import org.quartz.*;@DisallowConcurrentExecution
@PersistJobDataAfterExecution //只对JobDetail有持久化作用,对Trigger没有
public class MyJob implements Job {private String name;public void setName(String name) {this.name = name;}@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {System.out.println("name:"+name);//从触发器中获取数据JobDataMap triggerMap = context.getTrigger().getJobDataMap();//从任务中获取数据JobDataMap jobDetailMap = context.getJobDetail().getJobDataMap();System.out.println("jobDetailMap:"+jobDetailMap.getString("job"));System.out.println("triggerMap:"+triggerMap.getString("trigger"));/*** 获取JobDetail与Trigger的JobDataMap,并拼到一个map中,但是key重复会覆盖* */JobDataMap mergeMap = context.getMergedJobDataMap();triggerMap.put("count",triggerMap.getInt("count")+1);jobDetailMap.put("count1",jobDetailMap.getInt("count1")+1);System.out.println("triggerMap count:"+triggerMap.getInt("count"));System.out.println("jobDetailMap count:"+jobDetailMap.getInt("count1"));}
}
定义触发器与业务实例,并调度
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;public class TestJob {public static void main(String[] args) {JobDetail jobDetail = JobBuilder.newJob(MyJob.class).withIdentity("job1","group1")/**可以在业务类MyJob中通过context.getJobDetail().getJobDataMap()获取*/.usingJobData("job","jobDetail")/**可以直接赋值到业务类MyJob的name属性中*/.usingJobData("name","jobDetail").usingJobData("count1",0).build();int count=0;Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1","trigger1")/**可以在业务类MyJob中通过context.getTrigger().getJobDataMap()获取*/.usingJobData("trigger","trigger").usingJobData("count",count)/**会覆盖JobDetail中对业务类MyJob的name属性的赋值*///.usingJobData("name","trigger")/**立即执行*/.startNow()/**简单调度,每秒执行一次*/.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1).repeatForever()).build();try {Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();scheduler.scheduleJob(jobDetail,trigger);/*** scheduler是默认多线程并发访问资源的, 可以避免争抢及定时任务堵塞* 比如前一个任务没执行完,间隔时间就过了,又来了下一个,此时下一个正常执行,不等上一个执行完再执行** 除非使用@DisallowConcurrentExecution注解* 此注解会保证必须上一个任务执行完成后在执行下一个,即使超过了间隔时间,如果超时,会在执行完立刻执行下一次,不会再等过了间隔时间* 再执行,比如间隔为1秒,执行了3秒,3秒后会立即执行,而不是等4秒再执行* */scheduler.start();} catch (SchedulerException e) {e.printStackTrace();}}
}
quartz整合springboot
pom
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-autoconfigure</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-quartz</artifactId></dependency></dependencies>
业务类定义
import org.quartz.DisallowConcurrentExecution;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.quartz.PersistJobDataAfterExecution;
import org.springframework.scheduling.quartz.QuartzJobBean;import java.util.Date;@PersistJobDataAfterExecution
@DisallowConcurrentExecution
public class QuartzJob extends QuartzJobBean {@Overrideprotected void executeInternal(JobExecutionContext context) throws JobExecutionException {try {Thread.sleep(2000);System.out.println(context.getScheduler().getSchedulerInstanceId());System.out.println("taskname="+context.getJobDetail().getKey().getName());System.out.println("执行时间="+new Date());} catch (Exception e) {e.printStackTrace();}}
}
配置类
import org.quartz.Scheduler;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.config.PropertiesFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;import javax.sql.DataSource;
import java.io.IOException;
import java.util.Properties;
import java.util.concurrent.Executor;@Configuration
public class SchedulerConfig {/*** 注入应用的数据源* */@Autowiredprivate DataSource dataSource;/*** 配置线程池* Runtime.getRuntime().availableProcessors() 获取的是cpu核心线程数也就是计算资源。* */@Beanpublic Executor schedulerThreadPool(){ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(Runtime.getRuntime().availableProcessors());executor.setMaxPoolSize(Runtime.getRuntime().availableProcessors());executor.setQueueCapacity(Runtime.getRuntime().availableProcessors());return executor;}/*** 从自定义的properties加载quartz配置* */@Beanpublic Properties quartzProperties() throws IOException {PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();propertiesFactoryBean.setLocation(new ClassPathResource("/spring-quartz.properties"));propertiesFactoryBean.afterPropertiesSet();return propertiesFactoryBean.getObject();}/*** 创建schedulerFactoryBean工厂实例用于获取scheduler* */@Beanpublic SchedulerFactoryBean schedulerFactoryBean() throws IOException {SchedulerFactoryBean factory = new SchedulerFactoryBean();factory.setSchedulerName("cluster_scheduler");factory.setDataSource(dataSource);factory.setApplicationContextSchedulerContextKey("application");factory.setQuartzProperties(quartzProperties());factory.setTaskExecutor(schedulerThreadPool());factory.setStartupDelay(0);return factory;}/*** 从工厂实例获取scheduler* */@Beanpublic Scheduler scheduler() throws IOException {return schedulerFactoryBean().getScheduler();}
}
创建调度及触发
import org.quartz.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationListener;
import org.springframework.context.event.ContextRefreshedEvent;
import org.springframework.stereotype.Component;/*** ApplicationListener< ContextRefreshedEvent> 一般被用于在项目初始化动作完成后执行的自己业务拓展动作* 实现onApplicationEvent(ContextRefreshedEvent event)方法,应用一启动就会执行此方法* */
@Component
public class StartApplicationListener implements ApplicationListener<ContextRefreshedEvent> {@Autowiredprivate Scheduler scheduler;@Overridepublic void onApplicationEvent(ContextRefreshedEvent event) {try {TriggerKey triggerKey = TriggerKey.triggerKey("trigger1","group1");Trigger trigger = scheduler.getTrigger(triggerKey);if(trigger == null){trigger = TriggerBuilder.newTrigger().withIdentity(triggerKey).withSchedule(CronScheduleBuilder.cronSchedule("0/10 * * * * ?")).startNow().build();JobDetail jobDetail = JobBuilder.newJob(QuartzJob.class).withIdentity("job1","group1").build();scheduler.scheduleJob(jobDetail,trigger);}TriggerKey triggerKey2 = TriggerKey.triggerKey("trigger2","group2");Trigger trigger2 = scheduler.getTrigger(triggerKey2);if(trigger2 == null) {trigger2 = TriggerBuilder.newTrigger().withIdentity(triggerKey2).withSchedule(CronScheduleBuilder.cronSchedule("0/10 * * * * ?")).startNow().build();JobDetail jobDetail2 = JobBuilder.newJob(QuartzJob.class).withIdentity("job2", "group2").build();scheduler.scheduleJob(jobDetail2, trigger2);}scheduler.start();} catch (SchedulerException e) {e.printStackTrace();}}
}
相关文章:
quartz定时任务
Quartz 数据结构 quartz采用完全二叉树:除了最后一层每一层节点都是满的,而且最后一层靠左排列。 二叉树节点个数规则:每层从左开始,第一层只有一个,就是2的0次幂,第二层两个就是2的1次幂,第三…...
——选择结构与循环结构)
Python基础学习笔记(五)——选择结构与循环结构
目录 程序的组织结构条件选择结构1. 单分支结构2. 双分支结构3. 多分支结构4. 嵌套(分支)结构5. 无内容执行6. 条件表达式 循环结构1. 可迭代对象2. range()函数3. for循环语句4. while循环语句5. 结束语句 程序的组织结构 程序的组织结构主要有以下三种…...

Vue插槽solt如何传递具名插槽的数据给子组件?
在Vue中,你可以通过作用域插槽(scoped slots)来传递数据给子组件。这同样适用于具名插槽。首先,你需要在子组件中定义一个具名插槽,并通过v-slot指令传递数据。例如: 子组件(ChildComponent.vu…...
小程序-收货地址管理模块实现
页面结构代码: address-form.vue --->新建地址和修改地址页面 <template><view class"content"><form><!-- 表单内容 --><view class"form-item"><text class"label">收货人</text>…...
)
【星海随笔】微信小程序(三)
网络数据请求 1.小程序中网络数据请求的限制 出于安全性方面的考虑,小程序官方对 数据接口的请求 做出了如下 两个限制: ① 只能请求 HTTPS 类型的接口 ② 必须将 接口的域名 添加到 信任列表 中 微信小程序只能请求 https 类型的接口 且需要请求的域名必须提前进行设置后,才可…...
pip(包管理器) for Python
pip是什么 pip是Python的包安装程序,即python包管理器。您可以使用 pip 从Python包索引和其他索引安装包。 1. pip 安装 python 包 pip install 包名 例如:pip install pymssql : 使用pip安装数据库驱动包 pymssql 2.pip 卸载 python 包 pi…...

Ubuntu上安装Maven
在Ubuntu上安装Maven的步骤如下: 更新包索引: sudo apt update 安装Maven: sudo apt install maven 验证安装是否成功: mvn -version 以上步骤将会安装Maven并添加到系统路径中,你可以通过运行mvn -version来验…...
java中使用svnkit实现文件的版本管理
java中使用svnkit实现文件的版本管理 一、引入svnKit依赖二、初始化仓库工厂类二、使用svnkit创建本地存储仓库三、svn基本原子操作四、通过原子方法实现简单svn相应操作 一、引入svnKit依赖 <dependency><groupId>org.tmatesoft.svnkit</groupId><artifa…...
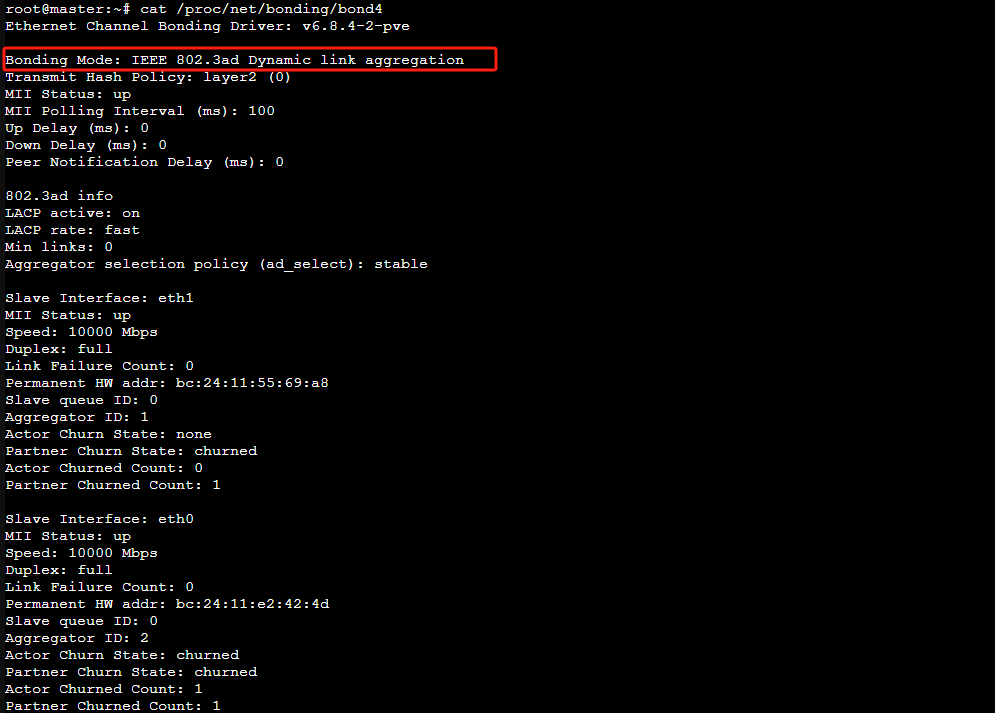
了解 Linux 网络卡绑定:提高网络性能与冗余性
在现代 IT 基础设施中,网络性能和可靠性至关重要。对于许多企业和个人用户来说,确保网络的高可用性和冗余性是首要任务之一。Linux 提供了一个强大的解决方案——网络卡绑定(Network Interface Card Bonding,简称 NIC Bonding&…...

2024年618购物狂欢节即将来袭!精选五款超值入手数码好物!
618购物狂欢盛宴即将落幕,是时候展现我们的购物智慧了!在追求价格优惠的同时,我们更应看重商品的品质与实用性。面对琳琅满目的选择,如何筛选出真正值得拥有的好物呢?为了让大家的购物之旅更加轻松愉快,以下…...

中国AI独角兽资本大冒险
成立不过一年多时间,月之暗面已然成为中国大模型赛道上,最炙手可热的明星公司。 5月21日,华尔街见闻获悉,月之暗面将按照投前估值30亿美元(合217.3亿人民币)进行融资,完成后依然会是当前中国估…...
项目十二:简单的python基础爬虫训练
许久未见,甚是想念,今日好运,为你带好运。ok,废话不多说,希望这门案例能带你直接快速了解并运用。🎁💖 基础流程 第一步:安装需要用到的requests库,命令如下 pip inst…...

OpenGL学习入门及开发环境搭建
最近学习OpenGL开发,被各种openGL库搞得晕头转向,什么glut, glew glfw glad等等。 可以参考这边博客:OpenGL 下面的 glut freeglut glfw 都是个啥_glx wgl的中文-CSDN博客 glfw是glut的升级版,跨平台的主要处理窗口 事件相关。 glad是glew…...

three.js能实现啥效果?看过来,这里都是它的菜(08)
在Three.js中实现旋转动画的原理是通过修改对象的旋转属性来实现的,通常使用渲染循环(render loop)来更新对象的旋转状态,从而实现动画效果。 具体的原理包括以下几个步骤: 创建对象:首先创建一个需要旋转…...
之整合mybatis)
SpringBoot(九)之整合mybatis
SpringBoot(九)之整合mybatis 文章目录 SpringBoot(九)之整合mybatisSpring整合mybatis回顾1. 引入依赖2. mybatis-config.xml SpringBoot整合mybatis1.引入依赖2. 配置数据源和 MyBatis 属性3. 配置 Mapper 接口4. 配置mapper.xm…...

【实战教程】使用Spring AOP和自定义注解监控接口调用
一、背景 随着项目的长期运行和迭代,积累的功能日益繁多,但并非所有功能都能得到用户的频繁使用或实际上根本无人问津。 为了提高系统性能和代码质量,我们往往需要对那些不常用的功能进行下线处理。 那么,该下线哪些功能呢&…...

算法学习之:Raft-分布式一致性/共识算法
基础介绍 Raft是什么? Raft is a consensus algorithm that is designed to be easy to understand. Its equivalent to Paxos in fault-tolerance and performance. The difference is that its decomposed into relatively independent subproblems, and it clea…...

彩色进度条(C语言版本)
.h文件 #include<stdio.h> #include<windows.h>#define NUM 101 #define LOAD_UP 50 #define LOAD_DOWN 60 #define SLEEP_SLOW 300 #define SLEEP_FAST 70 版本1:(初始版) //v1 #include "progress.h" int main() …...

C#和C++有什么区别?
C#和C都是广泛使用的编程语言,但它们在设计理念、应用场景和语法上有许多显著的区别。以下是一些关键区别的详细介绍: 1. 设计理念和目的 C: 设计目的:C是一种面向系统编程和应用程序开发的语言,具有高效性和灵活性…...
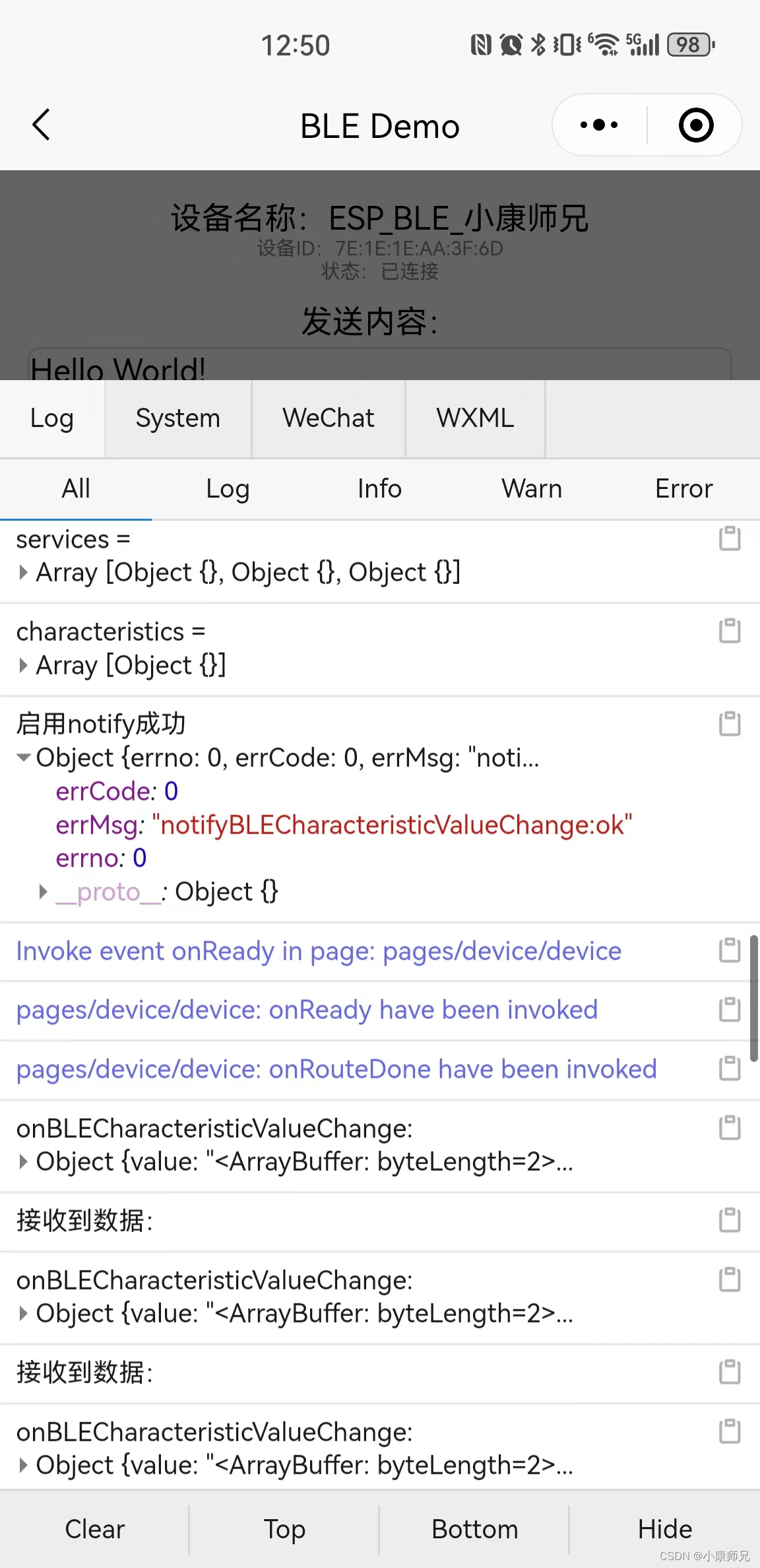
微信小程序报错:notifyBLECharacteristicValueChange:fail:nodescriptor的解决办法
文章目录 一、发现问题二、分析问题二、解决问题 一、发现问题 微信小程序报错:notifyBLECharacteristicValueChange:fail:nodescriptor 二、分析问题 这个提示有点问题,应该是该Characteristic的Descriptor有问题,而不能说nodescriptor。 …...

暗黑破坏神2终极角色编辑器:打造完美角色的完整指南
暗黑破坏神2终极角色编辑器:打造完美角色的完整指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 想要在暗黑破坏神2中体验完美的角色构建吗?厌倦了重复刷装备的枯燥过程…...

Poppler Windows版:PDF处理的终极简单方案
Poppler Windows版:PDF处理的终极简单方案 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows上的PDF处理工具而烦恼吗&…...
代码平台的方法)
在fnOS飞牛NAS上部署宝塔+NocoBase低(零)代码平台的方法
在fnOS飞牛NAS上部署宝塔NocoBase低(零)代码平台的方法 温馨提醒:本文全文免费,严禁盗用、二次收费行为! 更新日志: 2026/03/29 首次发布 2026/05/22 1、新增通过systemd托管进程,实现重启后自…...

抖音下载神器:如何免费批量下载无水印视频、音乐和图片
抖音下载神器:如何免费批量下载无水印视频、音乐和图片 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...

别再手动改Hex了!用Vector HexView的/remap命令,5分钟搞定固件地址重映射
嵌入式开发革命:Vector HexView自动化重映射技术实战指南 在汽车电子和物联网设备开发中,固件地址调整如同家常便饭。每当内存布局变更、Bootloader升级或外设地址重新分配时,嵌入式工程师们就不得不面对一项枯燥且容易出错的任务——手动修改…...

RK3576开发板RTC硬件扩展与Linux时间管理实战指南
1. 项目概述与核心价值在嵌入式开发中,尤其是在像RK3576这类高性能AIoT开发板上,一个稳定可靠的实时时钟(RTC)往往是项目从“玩具”走向“产品”的关键一步。它不仅仅是显示个时间那么简单,更是系统日志时间戳准确、定…...

Android主流架构演进:从MVC到MVI,聚焦MVVM核心实践
引言 在Android应用开发中,架构设计是确保代码可维护性、可测试性和可扩展性的关键。随着技术演进,主流架构从传统的MVC(Model-View-Controller)逐步过渡到MVP(Model-View-Presenter)、MVVM(Model-View-ViewModel),再到新兴的MVI(Model-View-Intent)。这种演进反映…...

Serverless多事件触发器:提升FaaS效率的关键技术
1. Serverless计算中的多事件触发器:突破传统FaaS的局限在当今云原生架构中,Serverless计算已成为构建弹性应用的重要范式。作为其核心组件的函数即服务(FaaS)平台,如AWS Lambda和Google Cloud Functions,通过事件驱动机制实现了资…...
)
Navicat Premium连不上SQL Server?别慌,先检查这两个最容易忽略的配置(附驱动安装)
Navicat Premium连接SQL Server的实战排错指南:从报错到畅通的完整解决方案 第一次用Navicat Premium连接SQL Server数据库时,那种期待又忐忑的心情我太熟悉了。明明按照教程一步步填写了IP、端口、用户名和密码,点击"测试连接"后却…...

AI时代软件工程教育:同理心融入技术课程的教学实践
1. 项目概述:当代码遇见人心最近几年,我一直在高校和培训机构里讲授软件工程相关的课程,从传统的软件生命周期、设计模式,到如今火热的敏捷开发、DevOps。一个越来越强烈的感受是:我们的技术教育,似乎正在与…...