Python库之Scrapy的高级用法深度解析
Python库之Scrapy的高级用法深度解析
引言
Scrapy是一个强大的Web爬虫框架,它提供了丰富的功能和灵活的扩展性,使得在Python中编写爬虫变得简单而高效。本文将深入探讨Scrapy的高级用法,帮助读者充分利用Scrapy的强大功能。
目录
- 引言
- Scrapy架构概述
- 高级Spider编写
- 异步处理
- 动态网站爬取
- 深度优先与广度优先爬取
- 项目中间件的使用
- 请求中间件
- 响应中间件
- 异常处理
- Pipeline的应用
- 清洗数据
- 去重
- 数据存储
- Scrapy的并发与性能优化
- 并发设置
- 延迟处理
- 异步IO
- 分布式爬虫部署
- Scrapyd
- Scrapy-Redis
- Scrapy与其他工具的集成
- Selenium
- PyQuery
- APScheduler
- Scrapy实战案例分析
- 结语
- 参考文献
Scrapy架构概述
Scrapy的架构主要由以下几个组件构成:
- Spiders:负责解析响应并提取数据,生成Item。
- Items:用于定义爬取的数据结构。
- Pipelines:处理Spider返回的Item,如清洗、验证、存储到数据库等。
- Engine:控制整个爬虫的数据流处理。
- Downloader:负责下载网页内容。
- Scheduler:调度下载任务,排队等待下载。
- Downloader Middlewares:处理引擎与下载器之间的请求和响应。
高级Spider编写
异步处理
Scrapy支持异步处理,可以通过async def定义异步的回调函数。
import scrapyclass AsyncSpider(scrapy.Spider):name = 'async'start_urls = ['http://example.com']async def parse(self, response):# 异步处理逻辑pass
动态网站爬取
对于动态网站,可以结合Selenium进行爬取。
from scrapy import Spider
from selenium import webdriverclass DynamicSpider(Spider):name = 'dynamic'def __init__(self):self.driver = webdriver.PhantomJS()def parse(self, response):self.driver.get(response.url)# 等待页面加载完成self.driver.implicitly_wait(10)item = MyItem()item['data'] = self.driver.page_sourcereturn item
深度优先与广度优先爬取
通过设置DEPTH_PRIORITY和BREADTH_FIRST,可以控制爬取的策略。
# settings.py
DEPTH_PRIORITY = 1
SCHEDULER_DISK_QUEUE = 'scrapy.squeues.PickleFifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeues.FifoMemoryQueue'
项目中间件的使用
请求中间件
请求中间件可以对请求进行预处理,如添加Cookies、Headers等。
# middlewares.pyclass MyCustomMiddleware(object):def process_request(self, request, spider):request.headers['User-Agent'] = 'My Custom User Agent'
响应中间件
响应中间件可以对响应进行后处理,如自动处理重定向。
# middlewares.pyclass MyCustomMiddleware(object):def process_response(self, request, response, spider):# 自定义处理逻辑return response
异常处理
中间件也可以用于异常处理,确保爬虫的稳定性。
# middlewares.pyclass MyCustomMiddleware(object):def process_exception(self, request, exception, spider):# 对异常进行处理pass
Pipeline的应用
清洗数据
Pipeline可以用来清洗爬取的数据,去除不需要的字段或转换数据格式。
# pipelines.pyclass MyPipeline(object):def process_item(self, item, spider):item['field'] = item['field'].strip()return item
去重
使用Pipeline实现去重,避免存储重复数据。
# pipelines.pyclass DuplicatesPipeline(object):def __init__(self):self.ids_seen = set()def process_item(self, item, spider):if item['id'] in self.ids_seen:return Noneself.ids_seen.add(item['id'])return item
数据存储
Pipeline也常用于将数据存储到数据库。
# pipelines.pyclass MyPipeline(object):def open_spider(self, spider):self.db = SomeDatabase()def close_spider(self, spider):self.db.close()def process_item(self, item, spider):self.db.save(item)return item
Scrapy的并发与性能优化
并发设置
Scrapy的并发可以通过设置来调整,以达到最优性能。
# settings.py
CONCURRENT_REQUESTS = 32
DOWNLOAD_DELAY = 0.25
延迟处理
适当的延迟可以防止被封IP。
# settings.py
DOWNLOAD_DELAY = 1
RANDOMIZE_DOWNLOAD_DELAY = True
异步IO
使用异步IO库,如aiohttp,可以进一步提高Scrapy的并发性能。
分布式爬虫部署
Scrapyd
Scrapyd是一个应用,允许你部署Scrapy爬虫作为一个服务,并运行它们。
- 安装Scrapyd:
pip install scrapyd - 运行Scrapyd服务器:
scrapyd - 部署爬虫到Scrapyd。
Scrapy-Redis
Scrapy-Redis是一个集成了Scrapy和Redis的库,它允许Scrapy项目使用Redis作为消息队列。
- 安装Scrapy-Redis:
pip install scrapy-redis - 配置Scrapy项目使用Scrapy-Redis。
Scrapy与其他工具的集成
Selenium
Scrapy可以与Selenium集成,处理动态加载的JavaScript内容。
PyQuery
PyQuery是一个使Python像jQuery一样的库,可以与Scrapy结合使用,简化HTML文档的查询和操作。
APScheduler
APScheduler是一个Python库,用于在Python应用程序中运行定时任务,可以与Scrapy集成,实现定时爬取。
Scrapy实战案例分析
本文将通过一个或多个实战案例,展示Scrapy高级用法的应用,包括项目结构设计、Spider编写、Pipeline实现、性能优化等。
结语
Scrapy作为Python中一个非常流行的爬虫框架,其高级用法可以极大地提升爬虫的性能和效率。通过深入理解Scrapy的架构和组件,合理利用其高级特性,可以构建出功能强大、稳定可靠的爬虫系统。
参考文献
- Scrapy官方文档:https://docs.scrapy.org/
- Scrapy-Redis GitHub仓库:https://github.com/scrapy/scrapy-redis
- APScheduler官方文档:https://apscheduler.readthedocs.io/en/stable/
请注意,这是一个关于Scrapy高级用法的文章概要。由于篇幅限制,每个部分的具体内容需要根据实际需求进一步扩展和详细编写。在实际编写时,可以添加具体的代码示例、配置说明、性能测试数据和案例分析等,以提供更加全面和深入的解析。
相关文章:

Python库之Scrapy的高级用法深度解析
Python库之Scrapy的高级用法深度解析 引言 Scrapy是一个强大的Web爬虫框架,它提供了丰富的功能和灵活的扩展性,使得在Python中编写爬虫变得简单而高效。本文将深入探讨Scrapy的高级用法,帮助读者充分利用Scrapy的强大功能。 目录 引言Scr…...
Rust Tarui 中的 Scrcpy 客户端,旨在提供控制安卓设备的鼠标和按键映射,类似于游戏模拟器。
Scrcpy-mask 为了实现电脑控制安卓设备,本人使用 Tarui Vue 3 Rust 开发了一款跨平台桌面客户端。该客户端能够提供可视化的鼠标和键盘按键映射配置。通过按键映射实现了实现类似安卓模拟器的多点触控操作,具有毫秒级响应速度。该工具可广泛用于电脑控…...

【shell】脚本练习题
案例: 1. for ping测试指网段的主机 网段由用户输入,例如用户输入192.168.2 ,则ping 192.168.2.10 --- 192.168.2.20 UP: /tmp/host_up.txt Down: /tmp/host_down.txt 2. 使用case实现成绩优良差的判断 1. for ping测试指…...

微信小程序uniapp+django洗脚按摩足浴城消费系统springboot
原生wxml开发对Node、预编译器、webpack支持不好,影响开发效率和工程构建。所以都会用uniapp框架开发 前后端分离,后端给接口和API文档,注重前端,接近原生系统 使用Navicat或者其它工具,在mysql中创建对应名称的数据库࿰…...

超链接的魅力:HTML中的 `<a>` 标签全方位探索!
🌐超链接的魅力:HTML中的 标签全方位探索! 🏞️基础营地:认识 <a> 标签🛠️基本语法📚属性扩展 🚀实战演练:超链接的多样玩法🌈内链与外链Ὄ…...

与优秀者同行,“复制经验”是成功的最快捷径
富在术数不在劳身,利在局势不在力耕。我们始终相信,与优秀者同行,“复制经验”才是走向成功的最快“捷径”! 酷雷曼合作商交流会 作为酷雷曼合作商帮扶体系里的重要一环,合作商交流会是总部专门为合作商们搭建的一个博采众长、相…...

MobaXterm使用私钥远程登陆linux
秘钥的形式使用MobaXterm 远程连接 linux 服务器 MobaXterm使用私钥远程登陆linux just填写远程主机 不指定用户 勾选使用私钥 选择私钥即可 1.使用秘钥连接 远程linux 服务器的好处 只需要第一次添加秘钥,并输入密码后,以后再连接就不需要再输入密码…...
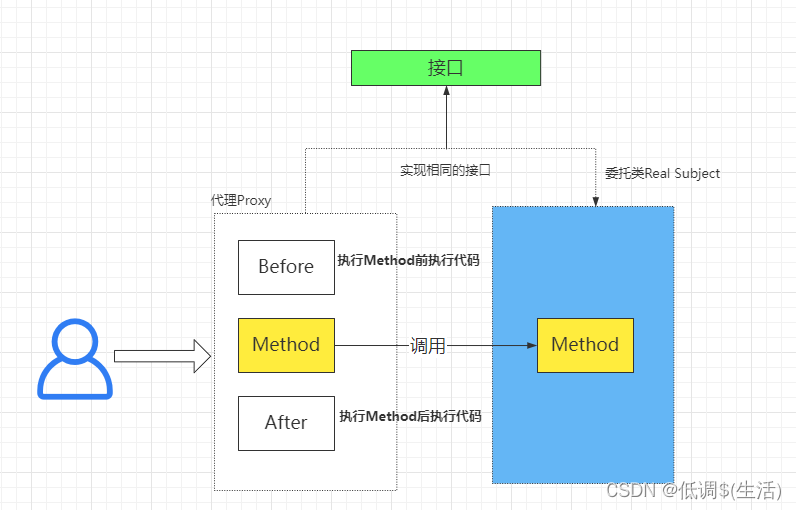
Java设计模式(23种设计模式 重点介绍一些常用的)
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。行为型模式,共十一种:…...
JVM(5):虚拟机性能分析和故障解决工具概述
1 工具概述 作为一个java程序员,最基本的要求就是用java语言编写程序,并能够在jvm虚拟机上正常运行,但是在实际开发过程中,我们所有的程序由于各种各样的原因,并不是总能够正常运行,经常会发生故障或者程序…...
vue3插槽solt 使用
背景增加组件的复用性,个人体验组件化还是react 方便。 Vue插槽solt如何传递具名插槽的数据给子组件? 一、solt 原理 知其然知其所以然 Vue的插槽(slots)是一种分发内容的机制,允许你在组件模板中定义可插入的内容…...

正则项学习笔记
目录 1. L2 正则化 岭回归 1.1 L2 norm计算例子 2. L1 正则化 3. 弹性网正则化 4. Dropout 1. L2 正则化 岭回归 在 PyTorch 中,L2 正则化通常通过设置优化器的 weight_decay 参数实现。以下是一个简单的例子: 介绍博文: 正则化(1)&a…...

Django自定义模板标签与过滤器
title: Django自定义模板标签与过滤器 date: 2024/5/17 18:00:02 updated: 2024/5/17 18:00:02 categories: 后端开发 tags: Django模版自定义标签过滤器开发模板语法Python后端前端集成Web组件 Django模板系统基础 1. Django模板语言概述 Django模板语言(DTL&…...
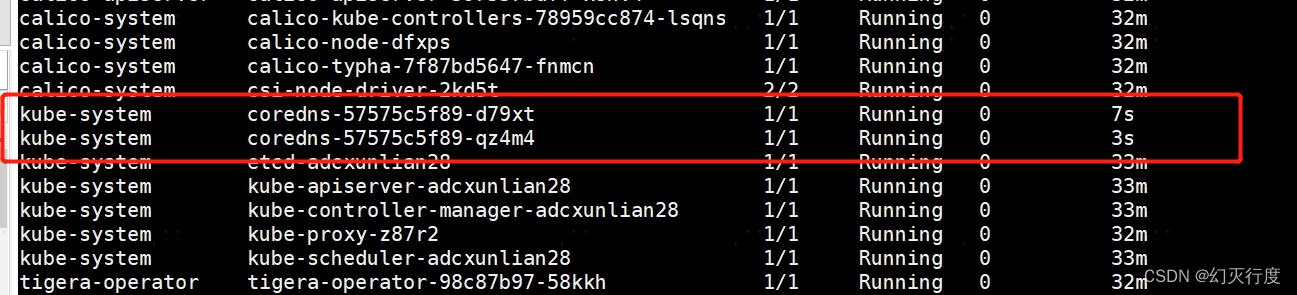
k8s集群安装后CoreDNS 启动报错plugin/forward: no nameservers found
安装k8s过程中遇到的问题: 基本信息 系统版本:ubuntu 22.04 故障现象: coredns 报错:plugin/forward: no nameservers found 故障排查: #检查coredns的配置,发现有一条转发到/etc/resolv.conf的配置…...
AI图片过拟合如何处理?答案就在其中!
遇到难题不要怕!厚德提问大佬答! 厚德提问大佬答8 你是否对AI绘画感兴趣却无从下手?是否有很多疑问却苦于没有大佬解答带你飞?从此刻开始这些问题都将迎刃而解!你感兴趣的话题,厚德云替你问,你解…...

0基础如何进入IT行业
目录 引言 一、了解IT行业 1.1 IT行业概述 1.2 IT行业的职业前景 二、选择适合的学习路径 2.1 自学 2.2 参加培训班 2.3 高等教育 三、学习基础技能 3.1 编程语言 3.2 数据结构与算法 3.3 计算机基础知识 四、实践与项目经验 4.1 开源项目 4.2 个人项目 4.3 实习…...
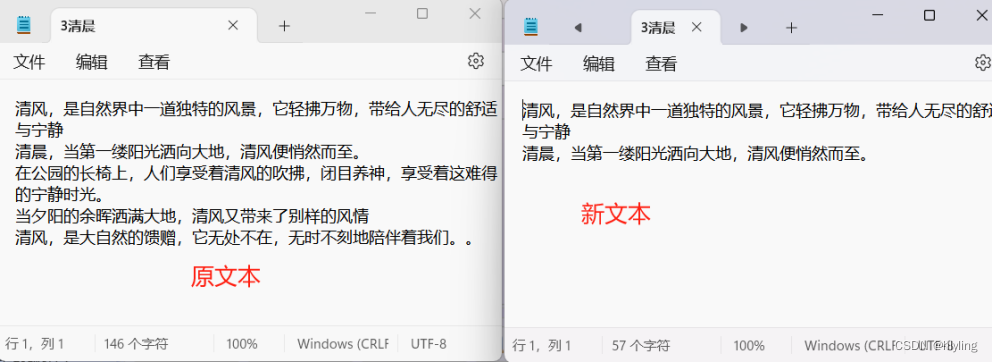
一键批量提取TXT文档前N行,高效处理海量文本数据,省时省力新方案!
大量的文本信息充斥着我们的工作与生活。无论是研究资料、项目文档还是市场报告,TXT文本文档都是我们获取和整理信息的重要来源。然而,面对成百上千个TXT文档,如何快速提取所需的关键信息,提高工作效率,成为了许多人头…...

Java-常见面试题收集(十六)
二十五 RocketMQ 1 消息队列介绍 消息队列,简称 MQ(Message Queue),它其实就指消息中间件,当前业界比较流行的开源消息中间件包括:RabbitMQ、RocketMQ、Kafka。(一个使用队列来通信的组件&…...
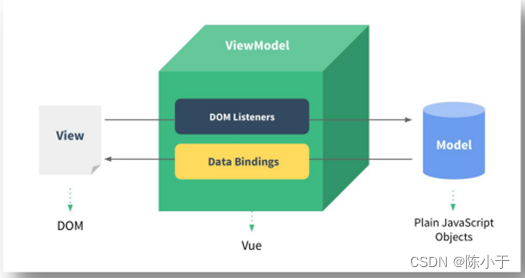
vue从入门到精通(四):MVVM模型
一,MVVM MVVM(Model–view–viewmodel)是一种软件架构模式。MVVM有助于将图形用户界面的开发与业务逻辑或后端逻辑(数据模型)的开发分离开来。详见MVVM 二,Vue中的MVVM Vue虽然没有完全遵循 MVVM 模型,但是 Vue 的设…...

提供一个c# winform的多语言框架源码,采用json格式作为语言包,使用简单易于管理加载且不卡UI,支持“语言分级”管理
提供一个c# winform的多语言框架源码,采用json格式作为语言包,不使用resx资源,当然本质一样的,你也可以改为resx 一、先看下测试界面 演示了基本的功能:切换语言,如何加载语言,如何分级加载语…...
Docker常见命令
创建并运行容器 例子:docker安装运行mysql docker run -d \ --name mysql \ -p 3306:3306 \ -e TZAsia/Shanghai \ -e MYSQL_ROOT_PASSWORDroot \ -v /root/data/mysql/data:/var/lib/mysql \ -v /root/data/mysql/init:/docker-entrypoint-initdb.d \ -v /root/d…...

别再乱用userdel -r了!UOS Server用户管理避坑指南与最佳实践
UOS Server用户管理深度避坑指南:从原理到实践的全面解析 在国产化操作系统UOS Server的运维实践中,用户与组管理看似基础却暗藏玄机。许多中级运维工程师往往在删除测试账户、修改用户属性或调整组关系时遭遇意想不到的问题——残留的配置文件导致后续创…...

H3CSE 高性能园区网:生成树保护机制
H3CSE 高性能园区网:生成树保护机制一、生成树保护机制1. BPDU保护1.1 边缘端口特点及问题端口基础特性存在的安全隐患1.2 BPDU保护机制核心防护逻辑机制运行优势1.3 BPDU保护配置配置使用规范H3C设备配置命令2. 根桥保护2.1 根桥保护机制2.2 根桥保护配置要求2.3 根…...

量子计算与人工智能融合:技术原理与应用前景
1. 量子计算与人工智能融合的技术全景量子计算与人工智能(AI)的交叉领域正在重塑计算技术的边界。作为一名长期跟踪量子计算发展的技术研究者,我见证了从早期理论构想到如今实验室原型机的演进历程。量子计算利用量子比特的叠加与纠缠特性&am…...

Python循环语句从入门到精通:for和while核心用法详解
编程里,循环属于绕不开的基础操作,Python当中,for与while看似简单,然而不少人写着写着就会卡住,特别是在嵌套、break以及continue的配合方面容易出错。本文助力你理清这两种循环的核心逻辑,结合实际场景讲透…...

长尾关键词自动化扩展:从1个种子词到1000个长尾词
长尾关键词是SEO的蓝海。我开发了一套系统,能从1个种子词自动扩展到1000个长尾词,并且评估每个词的竞争度和价值。这篇文章分享完整方案。一、长尾词扩展的方法 1.1 搜索建议扩展 def expand_keywords_from_suggestions(seed: str, api_key: str, depth:…...

成都制造企业SRM和ERP数据对不上,AI协同先治理什么?
系统都上线了,为什么协同还是慢不少成都制造企业已经有ERP,也陆续上了SRM、WMS、MES或QMS。采购订单在线审批,供应商可以在SRM里报价,仓库可以扫码入库,质量部门也有检验记录。可一到真实协同,问题仍然反复…...

harmonyos-ai-skill:让 Cursor 按 ArkTS 规范写鸿蒙,不再瞎编 API
端侧 Kit、MCP 接线都写过之后,写代码的人仍会遇到:Cursor 生成「像 React 的 ArkTS」、编造不存在的 Kit 名。社区项目 harmonyos-ai-skill 用可安装知识包,把 API 11 / DevEco 6 约束塞进 AI 工具链。 1. 问题:通用大模型不懂你…...
 - 第二期)
【期刊征稿 | 录用后最快当月见刊,刊后1个月检索,且检索稳定】第九届艺术、教育与管理国际学术会议(ICAEM 2026) - 第二期
录用后最快当月见刊,刊后1个月检索,且检索稳定 | 含ISSN号,DOI,封面目录 第九届艺术、教育与管理国际学术会议(ICAEM 2026) - 第二期 2026 9th International Conference on Arts, Education and Management 2026年…...
)
用随机森林实现手写英文字母识别(Python实战)
1. 项目概述:用随机森林搞定手写信件识别,这事儿比你想象中更接地气 “How To Perform Letter Recognition in Python Using Random Forest Classifier”——这个标题乍看像教科书里的章节名,但实际拆开来看,它直指一个非常具体、…...

Playwright Python3.7+安装失败根因与一次成功配置指南
1. 为什么Playwright在Python3.7环境下总“装不上”?——这不是你的pip问题,是环境认知偏差 你刚在新配的Mac M2上敲下 pip install playwright ,终端卡在 Building wheel for playwright... 十分钟不动;或者Windows上反复提示…...