【机器学习】大模型在机器学习中的应用:从深度学习到生成式人工智能的演进
🔒文章目录:
💥1.引言
☔2.大模型概述
🚲3.大模型在深度学习中的应用
🛴4.大模型在生成式人工智能中的应用
👊5.大模型的挑战与未来展望
💥1.引言
随着数据量的爆炸性增长和计算能力的提升,大模型在机器学习领域的应用日益广泛。这些模型不仅推动了深度学习技术的发展,还为生成式人工智能的崛起提供了强大动力。本文章将探讨大模型在机器学习中的应用,并分析其如何影响未来人工智能的发展方向。

☔2.大模型概述
大模型通常指的是具有庞大参数和复杂结构的机器学习模型。这些模型通过在大规模数据集上进行训练,能够学习到丰富的特征表示和复杂的映射关系。
大模型在众多领域都有广泛的应用,包括但不限于自然语言处理、计算机视觉、语音识别等。在自然语言处理领域,大模型可以用于文本分类、情感分析、机器翻译等任务;在计算机视觉领域,大模型可以实现高质量的图像识别和生成;在语音识别领域,大模型可以准确地将语音信号转换为文本。而在深度学习中,大模型往往表现为深度神经网络,如卷积神经网络(CNN)、循环神经网络(RNN)和变换器(Transformer)等。

🚲3.大模型在深度学习中的应用
大模型在深度学习中的应用已经变得日益广泛和深入,其庞大的参数规模和复杂的结构赋予了其强大的数据处理和学习能力,为深度学习领域的多个任务提供了有效的解决方案。
图像识别与生成:大模型在图像识别领域取得了显著成果,如人脸识别、物体检测等。同时,基于大模型的生成式对抗网络(GAN)能够实现高质量的图像生成,为创意产业提供了有力支持。
自然语言处理:在自然语言处理领域,大模型如BERT、GPT等已成为主流。这些模型通过预训练方式学习大量文本数据,进而实现文本分类、情感分析、机器翻译等任务。
语音识别与合成:大模型在语音识别和合成方面同样展现出强大的能力。通过深度学习技术,大模型能够准确识别语音信号并转换为文本,同时能够生成高质量的语音合成结果。
在深度学习中,大模型在语音识别和语音生成中的应用通常涉及复杂的模型结构和数据处理流程。由于实际应用的模型通常是大型框架或库的一部分,这里我无法直接提供完整的代码实现,但可以给出大致的代码框架和概念,以及使用这些框架的示例代码片段。
语音识别(Automatic Speech Recognition, ASR)
在语音识别中,大模型通常用于将语音信号转换为文本。一个流行的框架是TensorFlow或PyTorch,结合诸如Kaldi或Hugging Face的Transformers等库。
示例代码片段(伪代码):
import tensorflow as tffrom tensorflow.keras.models import load_model# 加载预训练的大模型(这里假设是一个ASR模型)asr_model = load_model('path_to_pretrained_asr_model')# 读取音频文件audio_file = 'path_to_audio_file.wav'# 将音频文件转换为模型可以处理的特征(如MFCC)audio_features = extract_audio_features(audio_file)# 预处理特征,以满足模型的输入要求preprocessed_features = preprocess_features(audio_features)# 使用模型进行语音识别predicted_text = asr_model.predict(preprocessed_features)# 后处理预测的文本(如解码)final_text = postprocess_predicted_text(predicted_text)print("Recognized Text:", final_text)语音生成(Text-to-Speech, TTS)
在语音生成中,大模型通常用于将文本转换为语音信号。常见的框架和库与语音识别相似,但模型结构和处理流程有所不同。
示例代码片段(伪代码):
import torch from transformers import Tacotron2Processor, Tacotron2ForConditionalGeneration# 加载预训练的语音生成模型和处理器 processor = Tacotron2Processor.from_pretrained('path_to_pretrained_tts_model') model = Tacotron2ForConditionalGeneration.from_pretrained('path_to_pretrained_tts_model')# 要转换的文本 input_text = "Hello, how are you?"# 对文本进行预处理 input_ids = processor.text_to_input_ids(input_text) input_lengths = torch.tensor([len(input_ids)], dtype=torch.long)# 使用模型进行语音生成 outputs = model.generate(input_ids=torch.tensor([input_ids]), attention_mask=input_lengths)# 将模型输出转换为音频波形 audio = processor.decode(outputs[0], sampling_rate=processor.config.sampling_rate)# 保存或播放生成的音频 with open('generated_audio.wav', 'wb') as f: f.write(audio.numpy())请注意,上述代码只是示意性的,并且使用了伪代码和一些假设的函数名。在实际应用中,你需要使用适当的库(如TensorFlow或PyTorch),并且需要按照所选库的文档和API进行实现。此外,还需要准备适当的数据集来训练模型,或者使用已经预训练的模型。
由于大模型的复杂性和所需的计算资源,实际应用中通常会使用现成的深度学习框架和工具来简化开发过程。如果你打算使用特定的大模型进行语音识别或语音生成,建议查看该模型的官方文档或相关教程,以获取更详细的信息和具体的代码示例。

🛴4.大模型在生成式人工智能中的应用
大模型在生成式人工智能中的应用广泛且深入,主要体现在以下几个方面:
首先,大模型在文本生成领域发挥着关键作用。以GPT系列模型为例,这些模型能够生成高质量的文章、新闻报道、故事情节等文本内容。它们不仅理解语言的内在规律和模式,还能通过学习和归纳大量的数据来优化自己的预测能力和准确性。这使得大模型在辅助写作、翻译、对话生成等场景中表现出色,为文本生成任务提供了高效且准确的解决方案。
其次,大模型在计算机视觉领域也有着重要的应用。例如,基于大模型的图像生成算法能够生成风格独特的艺术图像,用于图像增强、艺术创作等领域。此外,大模型还可以应用于图像识别、目标检测等任务,提高了计算机视觉系统的准确性和效率。
除了文本和图像生成,大模型还在音频、视频等其他多媒体内容的生成中发挥着作用。它们能够理解和处理复杂的多媒体数据,生成高质量的音频和视频内容,为多媒体内容的创作和编辑提供了更多可能性。
以下是一些示例代码片段,用于说明大模型在音频和视频生成中的潜在应用。请注意,这些代码片段是示意性的,并且可能需要根据实际使用的模型和库进行调整。
音频生成
在音频生成中,可以使用诸如WaveNet、Tacotron等模型来生成高质量的音频波形。这些模型通常基于深度学习框架(如TensorFlow或PyTorch)进行实现。
import torch from transformers import WavenetForConditionalGeneration# 加载预训练的音频生成模型 model = WavenetForConditionalGeneration.from_pretrained('path_to_pretrained_wavenet_model')# 假设我们有一些条件信息(如文本、梅尔频谱等),这些可以作为输入给模型 # 在这个例子中,我们使用随机的条件输入作为示意 condition_input = torch.randn(1, model.config.num_mel_bins, model.config.max_position_embeddings)# 使用模型生成音频波形 output_audio = model.generate(condition_input)# 保存生成的音频文件 with open('generated_audio.wav', 'wb') as f:f.write(output_audio.numpy())请注意,实际的条件输入需要根据模型和任务来定义。在Tacotron模型中,条件输入通常是文本对应的特征编码;在WaveNet模型中,可以是梅尔频谱图等。
视频生成
视频生成是一个更为复杂的任务,通常涉及对图像序列的建模和生成。大模型可以通过对图像和视频数据的理解和学习来生成视频帧。这可能需要使用专门的视频生成模型,如VideoGAN或MoCoGAN。
视频生成的具体实现将涉及图像序列的处理、深度学习模型的设计和训练。下面是一个非常简化的代码片段,用于说明视频生成的概念:
import torch from some_video_generation_library import VideoGenerationModel# 加载预训练的视频生成模型 model = VideoGenerationModel.from_pretrained('path_to_pretrained_video_generation_model')# 假设我们有一些初始帧或条件输入 # 在这个例子中,我们使用随机噪声作为输入 initial_frames = torch.randn(1, 3, model.config.height, model.config.width)# 使用模型生成视频帧序列 generated_frames = model.generate(initial_frames)# 保存生成的视频帧序列(这里需要额外的步骤来将帧序列转换为视频文件) # ...请注意,上述代码中的
some_video_generation_library和VideoGenerationModel都是假设存在的库和模型类。在现实中,视频生成是一个前沿且复杂的领域,通常需要使用专门的库和模型,并且可能需要大量的计算资源和时间来进行训练和生成。由于视频生成是一个高度专业化的领域,通常需要自定义模型、数据预处理和生成后处理步骤。因此,实际应用中的代码会更加复杂,并可能涉及到视频编码/解码、帧间一致性维护等多个方面的处理。
再次强调,这些代码片段仅用于说明概念,并不构成实际可用的实现。在实际应用中,你需要根据所选的模型和库查阅相关文档,以获取准确的实现方法和代码示例。
此外,大模型还在自然语言处理、知识推理、情感分析等多个生成式人工智能领域展现出强大的能力。它们能够通过深度学习和大规模数据处理来提取和表示知识,进而实现复杂的推理和分析任务。
然而,大模型在生成式人工智能中的应用也面临一些挑战。例如,随着模型规模的增大,其所需的计算资源和存储空间也在不断增加,这对硬件设备和基础设施提出了更高的要求。同时,如何确保大模型生成的内容的准确性和可靠性也是一个需要解决的问题。
所以大模型在我们的生成式人工智能中应用广泛且具有重要价值。随着技术的不断发展和进步,相信大模型将在未来为更多领域带来创新和突破。

👊5.大模型的挑战与未来展望
尽管大模型在机器学习领域取得了显著成果,但仍面临一些挑战。首先,大模型的训练需要大量的计算资源和时间,这使得其在实际应用中受到一定限制。其次,大模型可能存在过拟合和泛化能力较差的问题,需要采用合适的正则化技术和优化算法进行改进。
未来,随着计算能力的提升和算法的优化,大模型有望在更多领域发挥重要作用。同时,随着数据隐私和安全问题的日益突出,如何在保护用户隐私的前提下利用大模型进行学习和推理将成为未来研究的重要方向。此外,将大模型与其他先进技术(如强化学习、迁移学习等)相结合,有望推动机器学习领域取得更多突破性进展。
总之,大模型在机器学习中的应用正日益广泛,为深度学习和生成式人工智能的发展提供了强大动力。未来,随着技术的不断进步和应用的拓展,大模型有望在更多领域展现其独特价值,推动人工智能技术的快速发展!

相关文章:
【机器学习】大模型在机器学习中的应用:从深度学习到生成式人工智能的演进
🔒文章目录: 💥1.引言 ☔2.大模型概述 🚲3.大模型在深度学习中的应用 🛴4.大模型在生成式人工智能中的应用 👊5.大模型的挑战与未来展望 💥1.引言 随着数据量的爆炸性增长和计算能力的提…...
营销短信XML接口对接发送示例
在现代社会中,通信技术日新月异,其中,短信作为一种快速、简便的通信方式,仍然在日常生活中占据着重要的地位。为了满足各种应用场景的需求,短信接口应运而生,成为了实现高能有效通信的关键。 短信接口是一种…...

【C语言刷题系列】求一个数组中两个元素a和b的和最接近整数m
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:C语言刷题系列 目录 一、问题描述 二、解题思路 解题思路: 解题步骤: 三、C语言代码实现及测试 一、问题描述 给定一…...

Python pdf2imges -- pdf文件转图片
pdf文件转图片,需要安装PyMuPDF包,具体PyMuPDF包介绍可以参考:Python 处理 PDF 的神器 -- PyMuPDF import fitz # pip install PyMuPDF# PDF转换为IMG统一管理 def pdf_to_images(pdf_path, img_path, filename):"""pdf_p…...

分布式版本控制工具 git
git 是什么 分布式版本控制工具。github 是代码托管平台。 git 有什么用 保存文件的所有修改记录。使用版本号(sha1 哈希值) 进行区分。随时可浏览历史版本记录。可还原到历史指定版本。对比不同版本的文件差异。 为什么要使用 git 多人协作开发一个大…...

Flutter 中的 ExpansionTile 小部件:全面指南
Flutter 中的 ExpansionTile 小部件:全面指南 在 Flutter 应用中,ExpansionTile 是一个常用的折叠列表项,它允许用户点击标题来展开或折叠更多的内容。这个组件在实现可折叠列表、FAQ 部分或显示详情信息时非常有用。本文将详细介绍 Expansi…...

二进制的协议的测试程序
一、引子 由于要调试二进制私有协议,不想用C重头到尾写,用C写工程量有点大,因此想找一个比较简单的工具,postman无法实现,外界的几乎找不到合适的工具,只能考虑手写一个。 前面写了一个python通过tcp协议发…...

多线程事务
一、业务场景 我们在工作中经常会到往数据库里插入大量数据的工作,但是既需要保证数据的一致性,又要保证程序执行的效率。因此需要在多线程中使用事务,这样既可以保证数据的一致性,又能保证程序的执行效率。但是spring自带的Trans…...
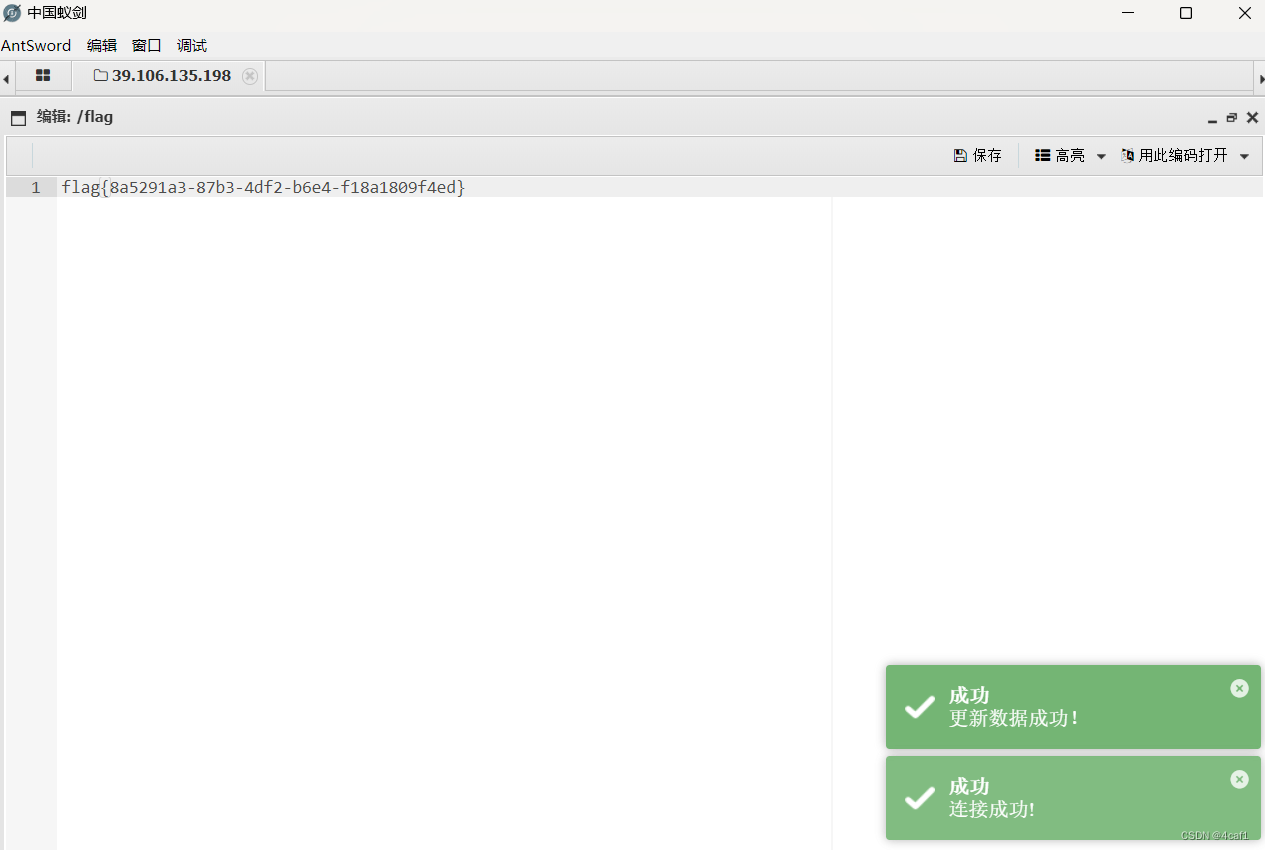
春秋云境CVE-2020-26048
简介 CuppaCMS是一套内容管理系统(CMS)。 CuppaCMS 2019-11-12之前版本存在安全漏洞,攻击者可利用该漏洞在图像扩展内上传恶意文件,通过使用文件管理器提供的重命名函数的自定义请求,可以将图像扩展修改为PHP…...
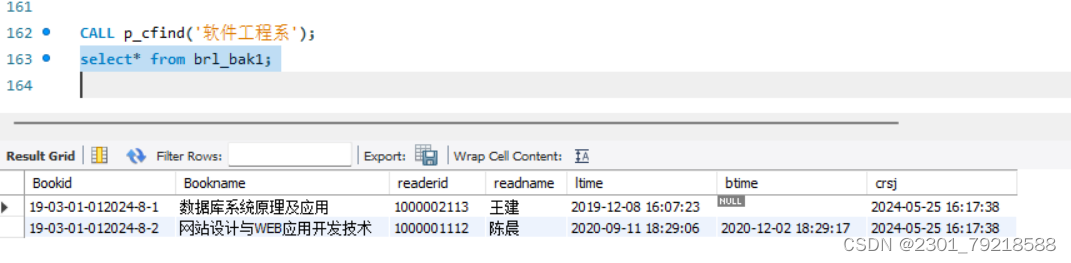
MySQL 带游标的存储过程(实验报告)
一、实验名称: 带游标的存储过程 二、实验日期: 2024 年 5月 25 日 三、实验目的: 掌握MySQL带游标的存储过程的创建及调用; 四、实验用的仪器和材料: 硬件:PC电脑一台; 配置࿱…...
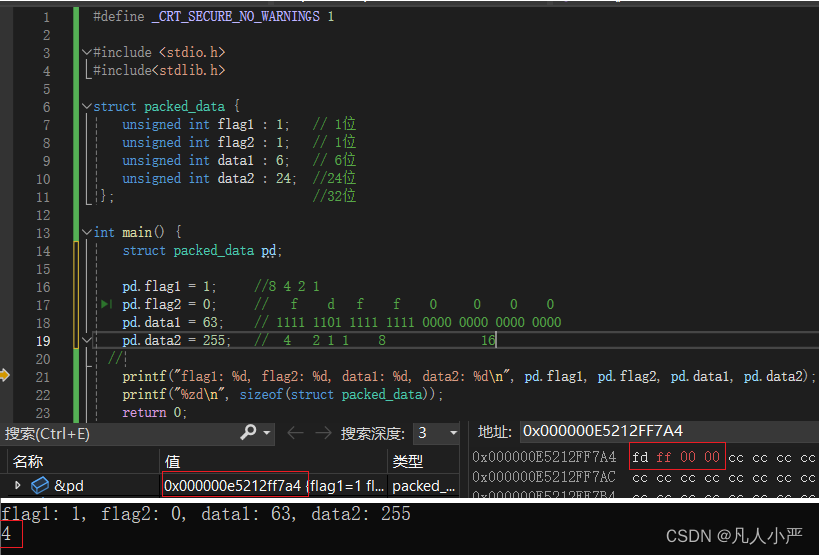
结构体(位段)内存分配
结构体由多个数据类型的成员组成。那编译器分配的内存是不是所有成员的字节数总和呢? 首先,stu的内存大小并不为29个字节,即证明结构体内存不是所有成员的字节数和。 其次,stu成员中sex的内存位置不在21,即可推测…...
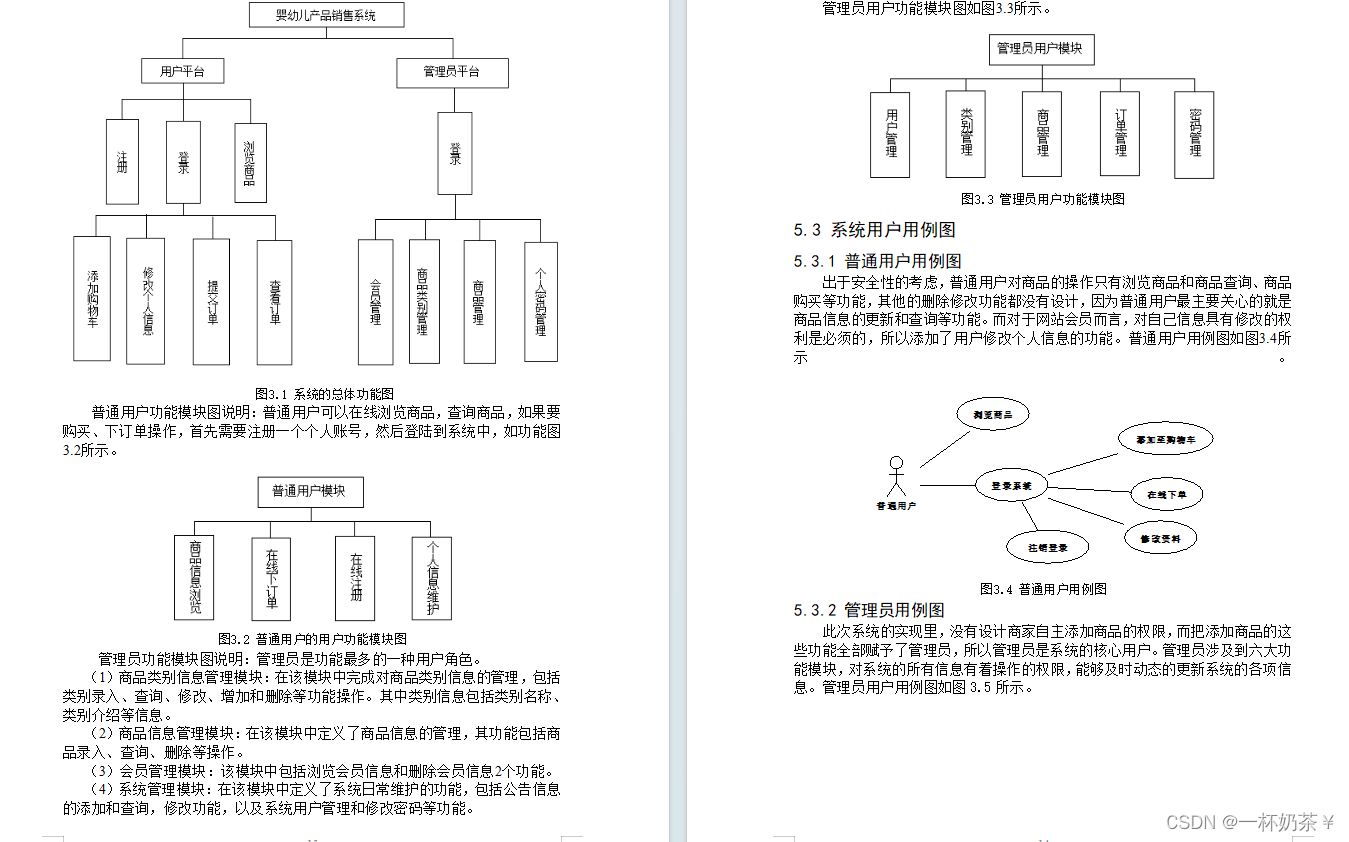
基于SSH的母婴用品销售管理系统带万字文档
文章目录 母婴商城系统一、项目演示二、项目介绍三、系统部分功能截图四、万字论文参考五、部分代码展示六、底部获取项目源码和万字论文参考(9.9¥带走) 母婴商城系统 一、项目演示 母婴商城系统 二、项目介绍 基于SSH的母婴商城系统 系统…...

说些什么好呢
大一:提前学C和C。学完语法去洛谷或者Acwing二选一,刷300道左右题目。主要培养编程思维,让自己的逻辑能够通过代码实现出来。 现在对算法有点感兴趣但是没有天赋,打不了acm,为就业做准备咯。 大二(算法竞赛)࿱…...

1301-习题1-1高等数学
1. 求下列函数的自然定义域 自然定义域就是使函数有意义的定义域。 常见自然定义域: 开根号 x \sqrt x x : x ≥ 0 x \ge 0 x≥0自变量为分式的分母 1 x \frac{1}{x} x1: x ≠ 0 x \ne 0 x0三角函数 tan x cot x \tan x \cot x …...
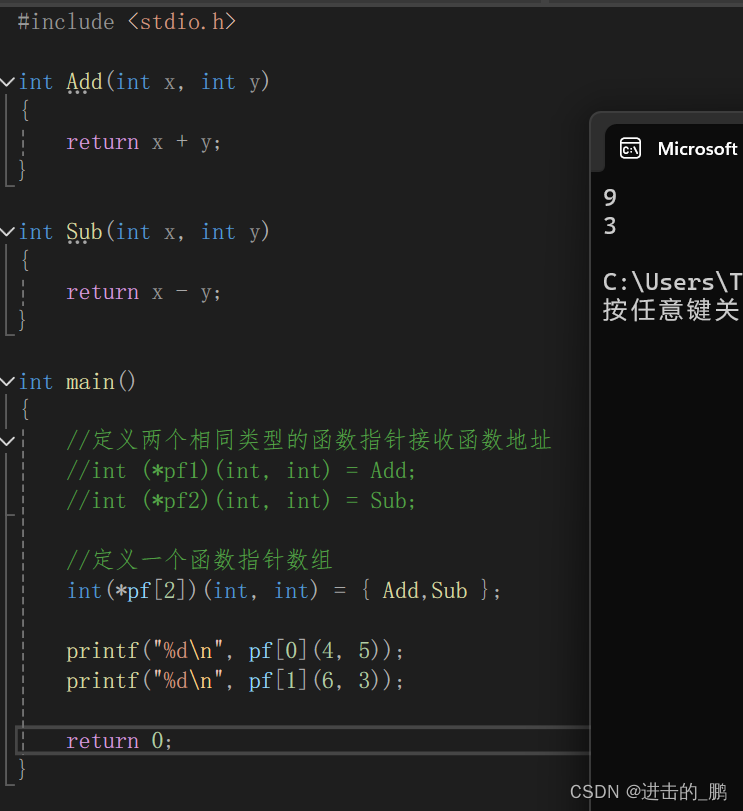
C语言之指针进阶(3),函数指针
目录 前言: 一、函数指针变量的概念 二、函数指针变量的创建 三、函数指针变量的使用 四、两段特殊代码的理解 五、typedef 六、函数指针数组 总结: 前言: 本文主要讲述C语言指针中的函数指针,包括函数指针变量的概念、创建…...
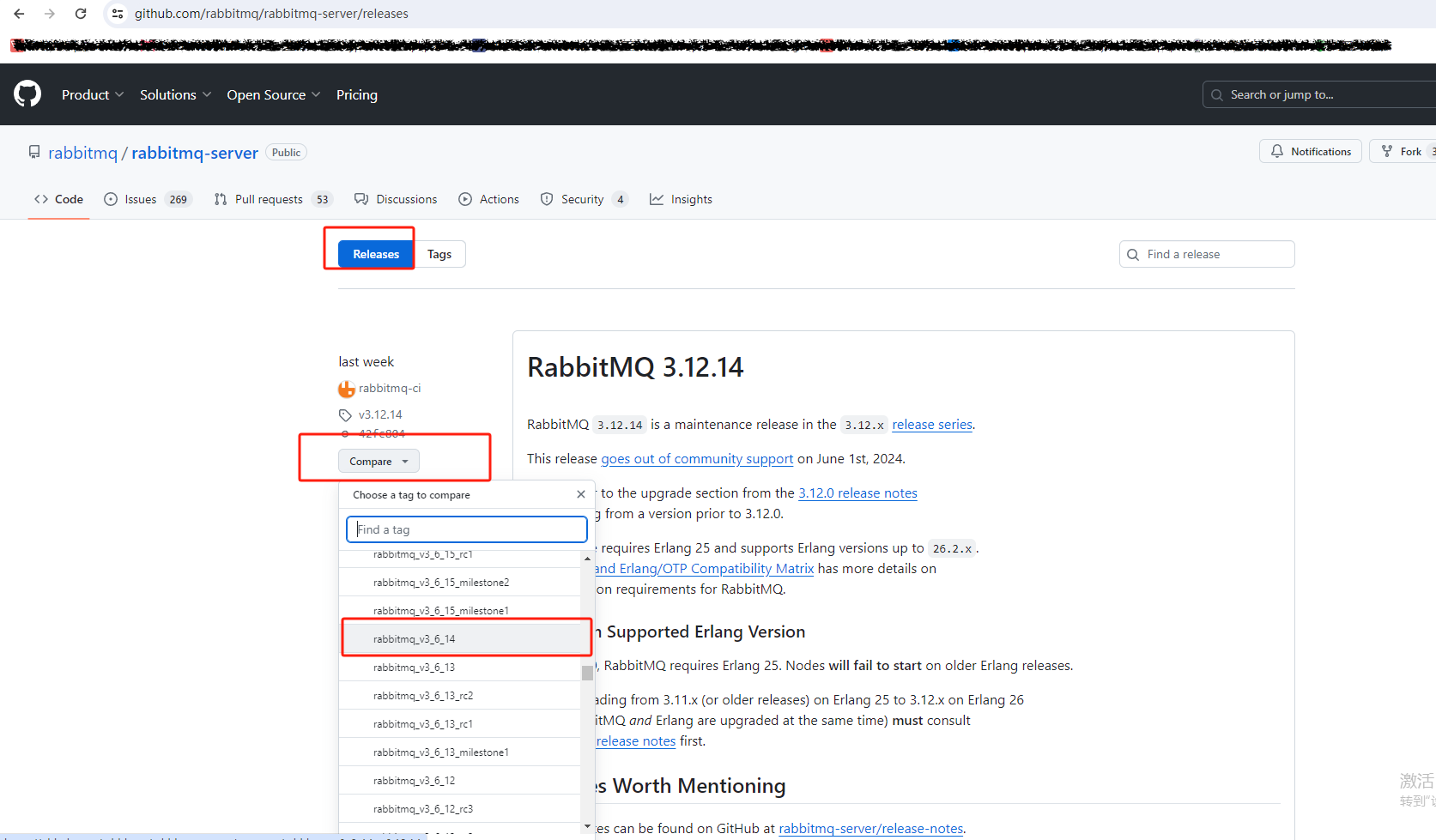
RabbitMQ安装及配套Laravel使用
MQ MQ 全称 Message Queue(消息队列),是在消息的传输过程中保存消息的容器。多用于系统之间的异步通信。 为什么需要mq: 解耦:MQ能够使各个系统或组件之间解耦,降低它们之间的耦合度,提高系统的灵活性和可维护性异步处理:通过MQ可以实现异步处理,提高系统响应速度和吞…...
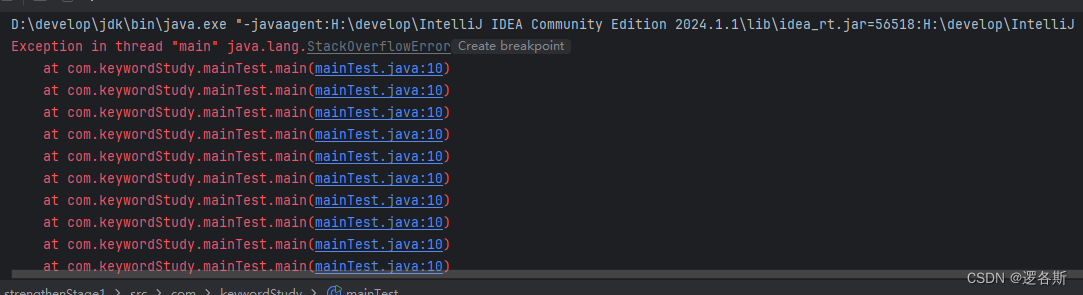
java在类的定义中创建自己的对象?
当在main方法中新建自身所在类的对象,并调用main方法时,会不断循环调用main方法,直到栈溢出 package com.keywordStudy;public class mainTest {static int value 33;public static void main(String[] args) throws Exception{String[] sn…...

掌握C++回调:按值捕获、按引用捕获与弱引用
文章目录 一、按引用捕获和按值捕获1.1 原理1.2 案例 二、弱引用2.1 原理2.2 案例一2.3 案例二:使用base库的弱引用 三、总结 在C回调中,当使用Lambda表达式捕获外部变量时,有两种捕获方式:按值捕获和按引用捕获。 一、按引用捕获…...

抖音运营_如何做出优质的短视频
目录 一 短视频内容的构成 1 图像 2 字幕 3 声音 4 特效 5 描述 6 评论 二 短视频的热门类型 1 颜值圈粉类 2 知识教学类 3 幽默搞笑类 4 商品展示类 5 才艺技能类 6 评论解说类 三 热门短视频的特征 1 产生共鸣 2 正能量 3 紧跟热点话题 4 富有创意 四 短视…...

Day21:Leetcode513.找树左下角的值 +112. 路径总和 113.路径总和ii + 106.从中序与后序遍历序列构造二叉树
LeetCode:513.找树左下角的值 解决方案: 1.思路 在遍历一个节点时,需要先把它的非空右子节点放入队列,然后再把它的非空左子节点放入队列,这样才能保证从右到左遍历每一层的节点。广度优先搜索所遍历的最后一个节点…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南
终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否渴望享受WeMod Pro会员的所…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

【紧急预警】Lindy衰减临界点已提前至第8.3个月!2024最新《营销自动化寿命健康度白皮书》限时开放前500份
更多请点击: https://kaifayun.com 第一章:Lindy衰减临界点的理论重构与实证突破 Lindy效应传统上描述“越老越长寿”的非线性生存规律,但其在现代软件系统、开源生态与协议层技术栈中的适用边界正遭遇结构性挑战。本文首次将Lindy模型从静…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...

接口测试用例设计:超详细防御体系与分层校验实践
1. 为什么“超详细”三个字在接口测试用例里不是修饰词,而是生死线我带过三支不同行业的测试团队——金融支付、SaaS中台、IoT设备管理平台。每次新人入职第一周,我都会收走他们写的前5条接口测试用例,逐行标红批注。不是因为格式不对&#x…...

Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间
Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经面对C盘爆红的警告束手无…...

红外信号逆向工程:破解电磁炉协议实现抽油烟机智能联动
1. 项目概述:当电磁炉与抽油烟机“对话”厨房里的自动化,听起来像是未来智能家居的专属,但其实很多乐趣和便利就藏在身边已有的设备里。我最近给家里的厨房换上了一台新的电磁炉,在翻阅说明书时,偶然发现了一个名为“h…...

抖音下载器深度解析:零基础轻松批量下载无水印视频
抖音下载器深度解析:零基础轻松批量下载无水印视频 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...