【论文阅读】 YOLOv10: Real-Time End-to-End Object Detection
文章目录
- Abstract
- Introduction
- Related Work
- Methodology
- Consistent Dual Assignments for NMS-free Training (无NMS训练的一致性双重任务分配)
- Holistic Efficiency-Accuracy Driven Model Design (效率-精度驱动的整体模型设计)
- Experiment
- Conclusion
YOLOv10:实时端到端的目标检测
GitHub
paper
单位:清华大学
Abstract
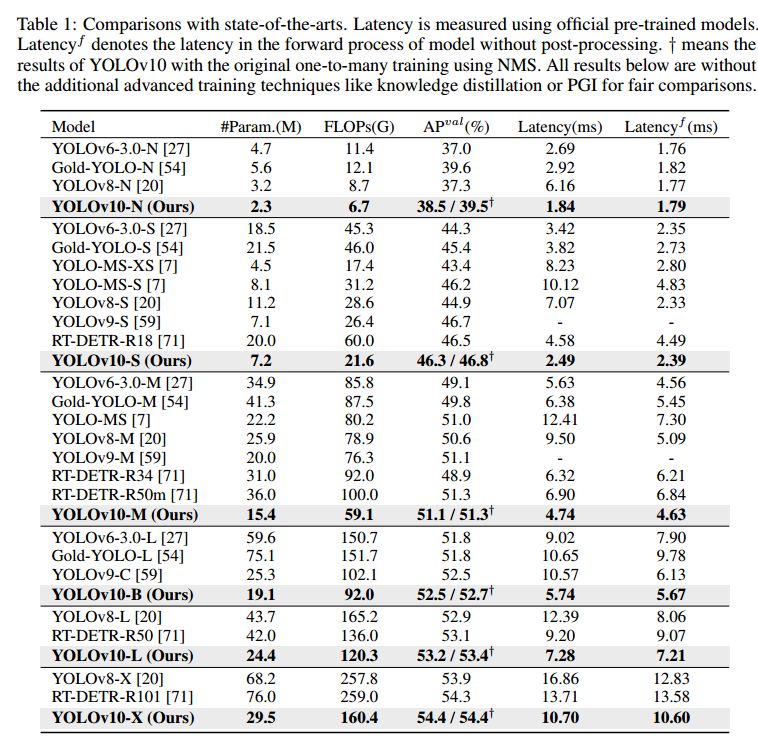
在过去几年中,YOLOs 因其在计算成本和检测性能之间的有效平衡而成为实时目标检测领域的主流模式。研究人员对 YOLOs 的架构设计、优化目标、数据增强策略等进行了探索,并取得了显著进展。然而,后处理对非最大抑制(NMS)的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生了不利影响。此外,YOLOs 中各种组件的设计缺乏全面彻底的检查,导致明显的计算冗余,限制了模型的能力。这使得效率不尽如人意,性能还有很大的提升空间。在这项工作中,我们旨在从后处理和模型架构两方面进一步推进 YOLO 的性能-效率边界。为此,我们首先提出了用于 YOLOs 无 NMS 训练的一致双分配,它同时带来了有竞争力的性能和较低的推理延迟。此外,我们还为 YOLOs 引入了效率-精度驱动的整体模型设计策略。我们从效率和准确性两个角度全面优化了 YOLO 的各个组成部分,从而大大降低了计算开销,提高了能力。我们努力的成果是用于实时端到端目标检测的新一代 YOLO 系列,被称为 YOLOv10。大量实验表明,YOLOv10 在各种模型规模下都实现了最先进的性能和效率。例如,在 COCO 上相似的 AP 下,我们的 YOLOv10-S 比 RT-DETR-R18 快 1.8 倍,同时参数和 FLOPs 数量少 2.8 倍。与 YOLOv9-C 相比,在性能相同的情况下,YOLOv10-B 的延迟减少了 46%,参数减少了 25%。
Introduction
实时目标检测一直是计算机视觉领域的研究热点。
YOLOs 的检测流程由两部分组成:**模型前向处理和 NMS 后处理。**然而,这两部分仍存在缺陷,导致精度-延迟边界不理想。
具体来说,YOLO 在训练过程中通常采用一对多的标签分配策略,即一个地面实况对象对应多个正样本。尽管这种方法性能优越,但在推理过程中,NMS 必须选择最佳的正向预测。这就降低了推理速度,使性能对 NMS 的超参数非常敏感,从而阻碍了 YOLOs 实现最佳端到端部署。解决这一问题的方法之一是采用最近推出的端到端 DETR 架构 。例如,RT-DETR 提出了一种高效的混合编码器和不确定性最小的查询选择,将 DETR 推向了实时应用领域。然而,部署 DETR 本身的复杂性阻碍了它在准确性和速度之间达到最佳平衡的能力。另一条思路是探索基于 CNN 的端到端检测,通常利用一对一分配策略来抑制冗余预测 。然而,这些方法通常会引入额外的推理开销,或实现次优性能。
此外,模型结构设计仍然是 YOLOs 面临的一个基本挑战,它对精度和速度有重要影响。为了实现更高效、更有效的模型架构,研究人员探索了不同的设计策略。为提高特征提取能力,骨干网采用了多种主要计算单元,包括 DarkNet [43, 44, 45]、CSPNet [2]、EfficientRep [27] 和 ELAN [56, 58] 等。对于颈部,则探索了 PAN [35]、BiC [27]、GD [54] 和 RepGFPN [65] 等增强多尺度特征融合的方法。此外,还研究了模型缩放策略[56, 55]和重新参数化[10, 27]技术。虽然这些努力取得了显著进展,但仍缺乏从效率和准确性两个角度对 YOLOs 中各种组件的全面检测。因此,在 YOLOs 中仍然存在相当多的计算冗余,导致参数利用效率低下和效率不理想。此外,由此产生的受限模型能力也会导致性能低下,为提高精度留下了很大的空间。
在这项工作中,我们的目标是解决这些问题,并进一步推进 YOLO 的精度-速度界限。我们的目标是后处理和整个检测管道中的模型架构。为此,我们首先解决了后处理中的冗余预测问题,提出了无 NMS YOLOs 的一致双重分配策略,即双重标签分配和一致匹配度量。它使模型在训练过程中享受丰富而和谐的监督,同时在推理过程中无需 NMS,从而以高效率获得有竞争力的性能。其次,我们通过对 YOLOs 中的各个组件进行全面检查,为模型架构提出了效率-精度驱动的整体模型设计策略。在效率方面,我们提出了轻量级分类头、空间信道解耦下采样和等级引导块设计,以减少显性计算冗余,实现更高效的架构。在精度方面,我们探索了大核卷积,并提出了有效的部分自注意模块,以增强模型能力,在低成本的情况下利用潜在的性能改进。
基于这些方法,我们成功地实现了具有不同模型尺度的新型实时端到端检测器系列,即 YOLOv10-N / S / M / B / L / X。
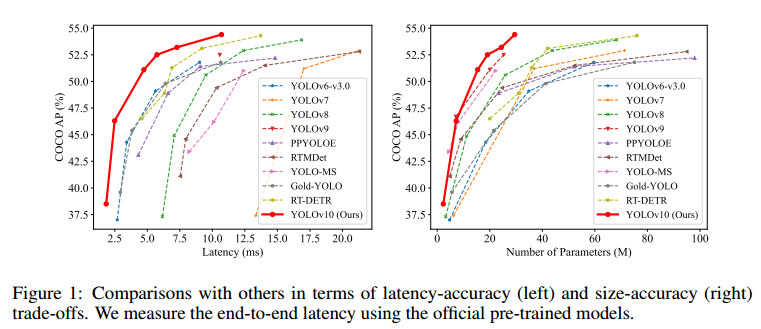
如图 1 所示,在性能相似的情况下,我们的 YOLOv10-S / X 比 RT-DETRR18 / R101 分别快 1.8 倍和 1.3 倍。与 YOLOv9-C 相比,YOLOv10-B 在性能相同的情况下减少了 46% 的延迟。此外,YOLOv10 还表现出高效的参数利用率。我们的 YOLOv10-L / X 性能分别比 YOLOv8-L / X 高出 0.3 AP 和 0.5 AP,参数数量分别少 1.8 倍和 2.3 倍。OLOv10-M与 YOLOv9-M / YOLO-MS 相比,AP 与 YOLOv9-M / YOLO-MS 相似,参数分别减少了 23% 和 31%。
Related Work
Methodology
Consistent Dual Assignments for NMS-free Training (无NMS训练的一致性双重任务分配)
在训练过程中,YOLOs [20, 59, 27, 64] 通常利用 TAL [14] 为每个实例分配多个正样本。采用一对多的分配方式可以获得大量的监督信号,从而促进优化并获得卓越的性能。但是,这使得 YOLOs 必须依赖 NMS 的后处理,从而导致部署推理效率不理想。虽然之前的研究 [49, 60, 73, 5] 探索了一对一匹配来抑制冗余预测,但它们通常会引入额外的推理开销或产生次优性能。在这项工作中,我们提出了一种无 NMS 的 YOLOs 训练策略,它具有双标签分配和一致的匹配度量,实现了高效率和有竞争力的性能。
双标签分配。与一对多分配不同,一对一匹配只为每个真值分配一个预测,避免了 NMS 后处理。然而,这种方法会导致弱监督,从而使精度和收敛速度达不到最佳水平 [75]。幸运的是,这种缺陷可以通过一对多的分配来弥补 [5]。为此,我们为 YOLOs 引入了双标签分配,以结合两种策略的优点。具体来说,如图 2(a)所示,我们为 YOLOs 引入了另一种一对一头。它保留了与原来一对多分支相同的结构和优化目标,但利用一对一匹配来获得标签分配。在训练过程中,两个检测头与模型共同优化,让骨干和颈部享受一对多分配提供的丰富监督。在推理过程中,我们舍弃一对多检测头,利用一对一检测头进行预测。这样,端到端部署就可以实现 YOLO,而不会产生任何额外的推理成本。此外,在一对一匹配中,我们采用了前一个选择,这与匈牙利匹配[4]的性能相同,但额外的训练时间更少。
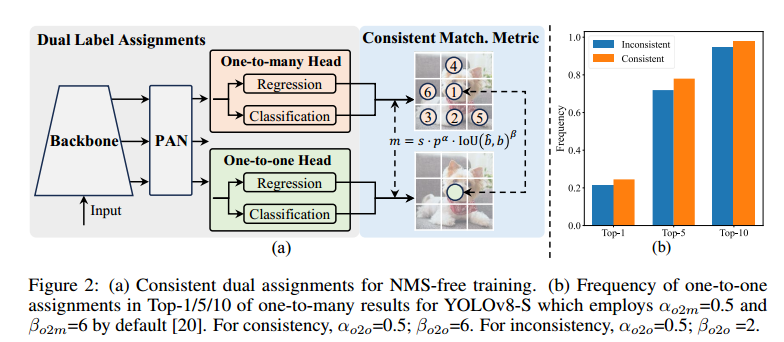
一致匹配度量。在分配过程中,一对一和一对多方法都会利用一个指标来定量评估预测和实例之间的一致程度。为了实现两个分支的预测感知匹配,我们采用了统一匹配度量,即
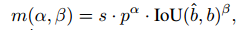
其中 p 是分类得分,ˆb 和 b 分别表示预测和真实的边界框。s 代表空间先验,表示预测的锚点是否在实例内 [20, 59, 27, 64]。α 和 β 是两个重要的超参数,用于平衡语义预测任务和位置回归任务的影响。我们将一对多指标和一对一指标分别记为
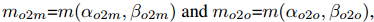
这些指标会影响两个标头的标签分配和监督信息。
在双标签分配中,一对多分支提供的监督信号比一对一分支丰富得多。直观地说,如果我们能协调一对一标头和一对多标头的监督,我们就能朝着一对多标头的优化方向优化一对一标头。因此,一对一标头可以在推理过程中提高样本质量,从而获得更好的性能。为此,我们首先分析了两个计算头之间的监督差距。由于训练过程中的随机性,我们在一开始就对两个 "头 "进行检查,这两个 "头 "以相同的值初始化并产生相同的预测,即一对一 "头 "和一对多 "头 "对每个预测-实例对产生相同的 p 和 IoU。我们注意到,两个分支的回归目标并不冲突,因为匹配的预测会共享相同的目标,而不匹配的预测则会被忽略。因此,监督差距在于不同的分类目标。给定一个实例,我们将其最大的预测 IoU 记为 u ∗ ,最大的一对多和一对一匹配分数分别记为 m∗ o2m 和 m∗ o2o。假设一对多分支产生正样本 Ω,一对一分支选择第 i 个预测,其指标为 mo2o,i=m∗ o2o、 然后,我们可以得出分类目标 to2m,j=u ∗ - mo2m,j m∗ o2m ≤ u ∗(对于 j∈ Ω)和 to2o,i=u ∗ - mo2o,i m∗ o2o =u ∗(对于任务对齐损失),如 [20,59,27,64,14] 所示。因此,两个分支之间的监督差距可以通过不同分类目标的 1-Wasserstein 距离得出:

我们可以观察到,差距随着 to2m,i 的增大而减小,即 i 在 Ω 中的排名靠前。如图 2.(a) 所示,当 to2m,i=u∗ 时,差距达到最小,即 i 是 Ω 中最好的正样本。为此,我们提出了一致匹配度量,即 αo2o=r - αo2m 和 βo2o=r - βo2m,这意味着 mo2o=mr o2m。因此,一对多磁头的最佳正样本也是一对一磁头的最佳正样本。因此,这两个磁头可以得到一致、和谐的优化。为简单起见,我们默认 r=1,即 αo2o=αo2m 和 βo2o=βo2m。为了验证改进后的监督配准,我们统计了训练后一对多结果的前 1 / 5 / 10 中一对一匹配对的数量。如图 2(b)所示,在一致匹配度量下,配准得到了改善。如需更全面地了解数学证明,请参阅附录。
Holistic Efficiency-Accuracy Driven Model Design (效率-精度驱动的整体模型设计)
效率驱动的模型设计。YOLO 的组件包括stem, downsampling layers, stages with basic building blocks, and the head.。stem的计算成本较低,因此我们对其他三个部分进行了效率驱动模型设计。
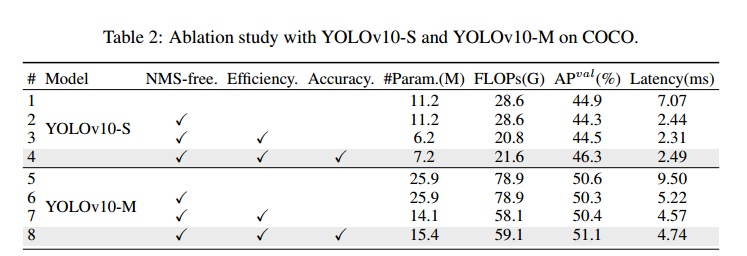
(1) 轻量级分类头。在 YOLOs 中,分类头和回归头通常采用相同的架构。但是,它们在计算开销方面表现出明显的差异。例如,在 YOLOv8-S 中,分类头的 FLOPs 和参数数(5.95G/1.51M)分别是回归头(2.34G/0.64M)的 2.5 倍和 2.4 倍。不过,在分析了分类误差和回归误差的影响后(见表 6),我们发现回归头对 YOLO 性能的影响更大。因此,我们可以减少分类头的开销,而不必担心性能会受到很大影响。因此,我们简单地采用了一种轻量级的分类头架构,它由两个深度可分离卷积[24, 8]组成,内核大小为 3×3,然后是 1×1 卷积。
(2) 空间-通道解耦降采样。YOLO 通常利用步长为 2 的常规 3×3 标准卷积,同时实现空间降采样(从 H × W 到 H 2 × W 2)和通道转换(从 C 到 2C)。这将带来不可忽略的计算成本 O( 9 2HW C2 ) 和参数数量 O(18C 2 ) 。取而代之的是,我们建议将空间缩小和通道增加操作解耦,从而实现更高效的下采样。具体来说,我们首先利用点卷积来调节通道维度,然后利用深度卷积来执行空间下采样。这将计算成本降低到 O(2HW C2 + 9 2HW C),参数数量降低到 O(2C 2 + 18C)。同时,它最大限度地保留了下采样过程中的信息,从而在降低延迟的同时实现了极具竞争力的性能。
(3) 等级引导的模块设计。YOLO 通常在所有阶段采用相同的基本构件 [27, 59],例如 YOLOv8 [20] 中的瓶颈构件。为了彻底检查 YOLO 的这种同构设计,我们利用本征等级 [31, 15] 来分析每个阶段的冗余度。具体来说,我们计算每个阶段中最后一个基本块中最后一次卷积的数值秩,其中计算大于阈值的奇异值的数量。图 3.(a) 显示了 YOLOv8 的结果,表明深度阶段和大型模型容易出现更多冗余。这一观察结果表明,简单地对所有阶段应用相同的块设计并不能实现最佳的容量-效率权衡。为了解决这个问题,我们提出了一种等级引导的区块设计方案,旨在通过紧凑的架构设计来降低冗余阶段的复杂性。我们首先提出了一种紧凑型反转块(CIB)结构,它采用廉价的深度卷积进行空间混合,并采用经济高效的点卷积进行信通道混合。它可以作为高效的基本构件,例如嵌入 ELAN 结构[58, 20](图 3.(b))。然后,我们主张采用等级引导的模块分配策略,在保持有竞争力的容量的同时实现最佳效率。具体来说,给定一个模型后,我们根据其内在等级以升序对其所有阶段进行排序。我们将进一步检验用 CIB 替换领先阶段基本区块的性能变化。如果与给定模型相比性能没有下降,我们就继续替换下一阶段,反之则停止这一过程。因此,我们可以实现跨阶段和跨模型规模的自适应紧凑块设计,在不影响性能的情况下实现更高的效率。由于篇幅限制,我们在附录中提供了算法的详细信息
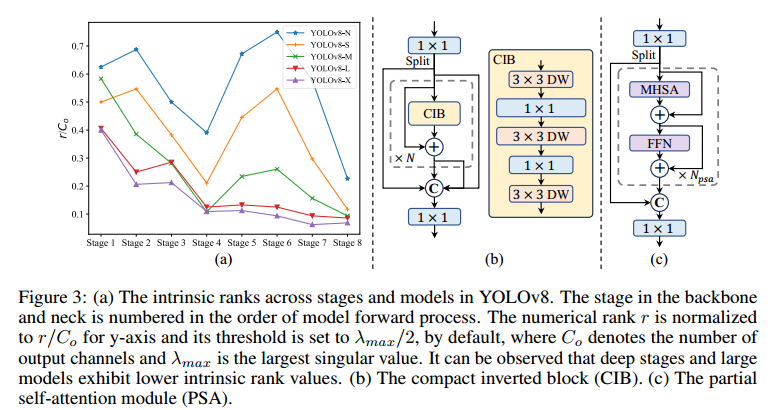
精度驱动模型设计。我们进一步探索了大核卷积和自注意力的精度驱动设计,旨在以最小的成本提高性能。
(1) 大核卷积。采用大核深度卷积是扩大感受野和增强模型能力的有效方法 [9, 38, 37]。但是,如果在所有阶段都简单地利用它们,可能会对用于检测小物体的浅层特征造成污染,同时也会在高分辨率阶段带来巨大的 I/O 开销和延迟[7]。因此,我们建议在深度阶段利用 CIB 中的大核深度卷积。具体来说,我们仿照文献[37],将 CIB 中第二个 3×3 深度卷积的核大小增加到 7×7。此外,我们还采用了结构重参数化技术 [10, 9, 53],引入了另一个 3×3 深度卷积分支,在不增加推理开销的情况下缓解了优化问题。此外,随着模型大小的增加,其感受野自然也会扩大,使用大核卷积的好处也会随之减少。因此,我们只在模型规模较小的情况下采用大核卷积。
(2) 部分自注意力(PSA)。自注意力[52]因其卓越的全局建模能力而被广泛应用于各种视觉任务中[36, 13, 70]。然而,它的计算复杂度和内存占用都很高。为了解决这个问题,考虑到普遍存在的注意头冗余问题 [63],我们提出了一种高效的部分自注意(PSA)模块设计,如图 3©所示。具体来说,我们在 1×1 卷积后将各通道的特征平均分成两部分。我们只将其中一部分输入由多头自注意模块(MHSA)和前馈网络(FFN)组成的 NPSA 模块。然后,两部分通过 1×1 卷积进行连接和融合。此外,我们遵循文献[21],将查询和关键字的维度分配为 MHSA 中值的一半,并用 BatchNorm [26] 代替 LayerNorm [1],以实现快速推理。此外,PSA 只放在分辨率最低的第 4 阶段之后,避免了自注意力的二次计算复杂度带来的过高开销。这样,全局表示学习能力就能以较低的计算成本融入 YOLOs,从而很好地增强了模型的能力,提高了性能。
Experiment
Conclusion
在本文中,我们将后处理和模型架构作为整个 YOLOs 检测流程的目标。在后处理方面,我们提出了无 NMS 训练的一致双重分配,实现了高效的端到端检测。在模型架构方面,我们引入了效率-精度驱动的整体模型设计策略,改善了性能-效率的权衡。这些都为我们带来了全新的实时端到端对象检测器 YOLOv10。广泛的实验表明,与其他先进的检测器相比,YOLOv10 的性能和延迟都达到了最先进的水平,充分证明了它的优越性。
相关文章:
【论文阅读】 YOLOv10: Real-Time End-to-End Object Detection
文章目录 AbstractIntroductionRelated WorkMethodologyConsistent Dual Assignments for NMS-free Training (无NMS训练的一致性双重任务分配)Holistic Efficiency-Accuracy Driven Model Design (效率-精度驱动的整体模型设计) …...

Python读写文件
最近得以空闲,然后继续学习py。 学习一下py中最频繁用到的文件读写的方法。 在py中,操作是通过文件对象【File obj】实现的,通过文件对象可以读写文本文件和一些二进制文件。 1.打开文件 使用Python中的open函数。有8个参数,但…...
docker-如何将容器外的脚本放入容器内,将容器内的脚本放入容器外
文章目录 前言docker-如何将容器外的脚本放入容器内,将容器内的脚本放入容器外、1. docker 如何将容器外的脚本放入容器内1.1. 验证 2. 将容器内的脚本放入容器外 前言 如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊&…...

算法训练营第三十九天 | LeetCode 738 单调递增的数字、LeetCode 968 监控二叉树
LeetCode 738 单调递增的数字 这题类似模拟,可以找出如下规律: 先将数字按位数从高位到低位存到一个整型数组中。在这个数组中,从左往右遍历,如果遇到一个两数相等,并且记录的这个变量之前没有赋过值,那么…...

Hive语法学习总结
Hive SQL语法学习总结 hive参数库操作1.创建库2.具体案例3.库的其他操作 表和库的路径演示表的操作创建表插入数据 hive参数 一 hive常用交互命令hive -e sql语句hive -f sql文件 //文件中是sql语句二 参数的设置方式一:在客户端中设置参数(当次有效)set 参数名参…...

【Linux】TCP协议【中】{确认应答机制/超时重传机制/连接管理机制}
文章目录 1.确认应答机制2.超时重传机制:超时不一定是真超时了3.连接管理机制 1.确认应答机制 TCP协议中的确认应答机制是确保数据可靠传输的关键部分。以下是该机制的主要步骤和特点的详细解释: 数据分段与发送: 发送方将要发送的数据分成一…...

solidworks画螺母学习笔记
螺母 单位mm 六边形 直径16mm,水平约束,内圆直径10mm 拉伸 选择两侧对称,厚度7mm 拉伸切除 画相切圆 切除深度7mm,反向切除 拔模角度45 镜像切除 倒角 直径1mm 异形孔向导 螺纹线 偏移打勾,距离为2mm…...
WebGL的医学培训软件开发
开发基于WebGL的医学培训软件是一项复杂且技术性强的任务,需要结合医学专业知识和计算机图形学技术。以下是详细的开发流程和关键步骤。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 1.需求分析与定义 目标用户…...

新时代AI浪潮下,程序员和产品经理如何入局AIGC领域?
当下,AI浪潮席卷全球,AIGC大模型技术已经成为当今技术领域的一个重要趋势,对于产品经理来说,掌握这项技术不仅能够增强他们的职业技能,还能在竞争激烈的职场中脱颖而出。 为什么呢? 把握AI时代的机遇 AI技…...
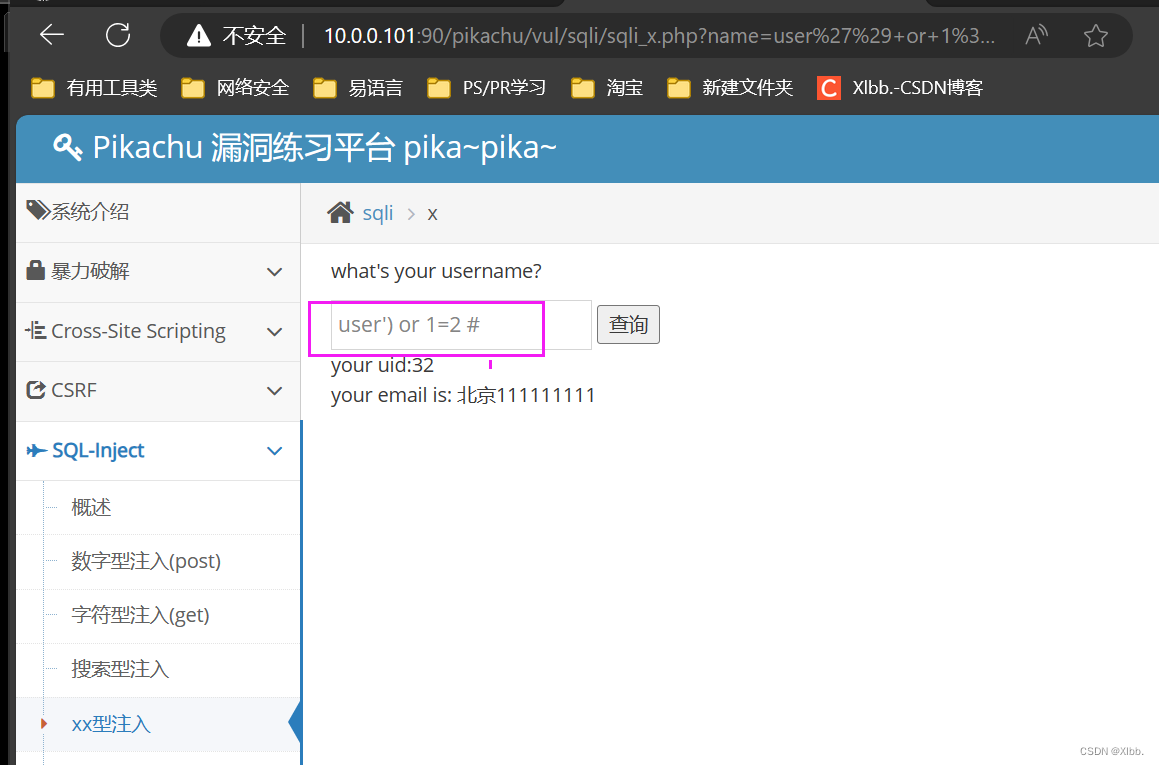
OWASP top10--SQL注入(一)
SQL注入式攻击技术,一般针对基于Web平台的应用程序.造成SQL注入攻击漏洞的原因,是由于程序员在编写Web程序时,没有对浏览器端提交的参数进行严格的过滤和判断。用户可以修改构造参数,提交SQL查询语句,并传递至服务器端…...

java —— 类与方法
一、访问修饰符 在类和方法中,均可使用访问修饰符以锁定该类或方法的被访问权限。访问修饰符有四种: (一)public 同一个项目中,对所有的类可见。 (二)protected 同一个项目中,对…...

【MySQL精通之路】InnoDB-启动选项和系统变量
系统变量可以在服务器启动时设置TRUE或FALSE启用禁用,也可以通过使用--skip前缀来禁用 例如: 要启用或禁用InnoDB自适应哈希索引,可以在命令行中使用--skip-innodb-adaptive-hash-index或--innodb-adaptive-hash-index,或者在配置…...

嵌入式linux系统中文件系统制作方法详解
第一:制作目的 1、掌握嵌入式Ubuntu系统的构建方法 2、熟悉嵌入式Ubuntu文件系统映射压缩打包方法 3、掌握RK3399linux系统单文件系统更新方法 Ubuntu根文件系统制作完成之后,把制作好的ubuntu文件系统映射文件在出厂系统的基础上替换原有的ubuntu根文件系统,即对 Linux 系统…...

AI爆文写作:要写文章爆,这47个爆文前缀少不了!
47个爆文前缀:很震惊很好用 这些前缀,虽然被用了无数次,但每个人看到还是会忍不住点进去。 可以借鉴这样强情绪的句式。 序号前缀1就在刚刚…2真相曝光…3震惊国人…4惊天秘密…5疯狂转发…6删前速看…7千万别吃…8还敢喝吗…9癌症前兆…10赶快扔了…11太可怕了…12大事不…...
javas-core VS java-object-diff
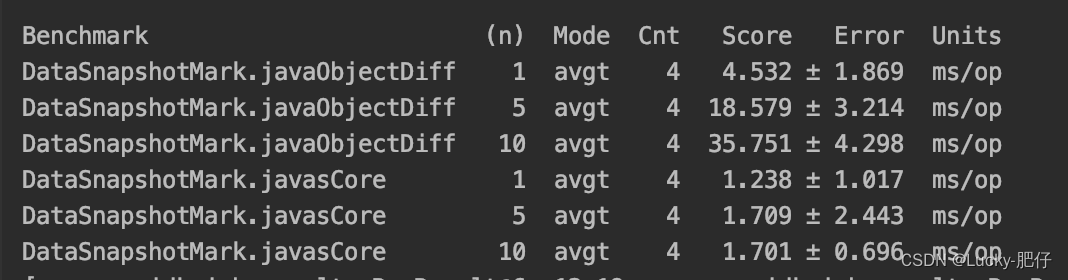
对照工具选择 javas-core 和 java-object-diff ,对比demo https://github.com/kofgame/objectdiff-vs-javers,都为同源对比,都支持嵌套对象。 使用JMH测试方法进行性能测试,使用题库的QuestionResponseVO对象来进行对照对比,进行…...

dirsearch指令大全
文章目录 基本用法主要参数和选项目标和URL设置--url URL--url-list FILE 扩展名--extensions EXTENSIONS 字典文件--wordlists WORDLIST 线程和性能--threads THREADS--timeout SECONDS--delay MILLISECONDS 忽略状态码代理和请求设置--proxy PROXY--headers HEADERS 保存结果…...

C++基础:构建者设计模式
#include <iostream> #include <string> using namespace std; //构建者设计模式-一种工厂只生产一种复杂的产品 class robot {public:string head;string upbody;string downbody; };class robotBuilder {private:robot *myRobot;public:robotBuilder() //构造函…...

Swift 请求用户授权以跟踪其跨应用或网站的活动
步骤1:导入框架 首先,需要在Swift文件中导入AppTrackingTransparency框架。 import AppTrackingTransparency import AdSupport步骤2:请求跟踪许可 在适当的地方请求用户的跟踪许可。通常,这个请求会在应用启动时或者在用户执行…...

最新版npm详解
如:npm中搜索 jQuery image.png image.png 接地气的描述:npm 类似于如下各大手机应用市场 image.png image.png 查看本地 node 和 npm 是否安装成功 image.png image.png 或 npm install -g npm image.png image.png image.png image.png image.…...

超值分享50个DFM模型格式的素人直播资源,适用于DeepFaceLive的DFM合集
50直播模型:点击下载 作为直播达人,我在网上购买了大量直播用的模型资源,包含男模女模、明星脸、大众脸、网红脸及各种稀缺的路人素人模型。现在,我将这些宝贵的资源整理成合集分享给大家,需要的朋友们可以直接点击下…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

OpenClaw用户如何快速接入Taotoken并开始Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户如何快速接入Taotoken并开始Agent工作流 对于使用OpenClaw框架构建AI智能体的开发者而言,快速接入稳定、多…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...

告别DLL缺失烦恼!Visual C++运行库合集一键搞定Windows应用依赖问题
告别DLL缺失烦恼!Visual C运行库合集一键搞定Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软件或游戏时…...

大厂校招变了:AI 能力正在进入笔试和面试
最近不少同学投递校招时,应该已经发现一个变化: 以前 JD 里写的是“熟悉 Python / Java / SQL / Office 优先”。 现在越来越多岗位开始出现新的描述: “熟练使用 AI 工具者优先” “了解大模型应用者优先” “具备 AI 辅助编程经验优先” “…...

5分钟免费搞定HS2汉化:Honey Select 2完整中文补丁终极教程
5分钟免费搞定HS2汉化:Honey Select 2完整中文补丁终极教程 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的日文界面而烦恼吗…...