变分自动编码器(VAE)深入理解与总结
本文导航
- 0 引言
- 1 起源
- 1.1 自编码器的任务定义
- 1.2 自编码器存在的问题
- 1.3 VAE的核心思路
- 2 VAE的建模过程
- 2.1 VAE的任务定义
- 2.2 真实分布 ϕ \phi ϕ是什么,为什么要逼近这个分布的参数,如何做?
- 2.3 “重参数化(Reparameterization)”技巧
- 3 一些常见的疑问
- 3.1 后验分布 p ( z ∣ x ) p(z|x) p(z∣x)必须假设为高斯分布么?
- 3.2 VAE的"变分"体现在哪里?
- 3.3 VAE的究竟在做什么?
- 参考资料
0 引言
VAE自2013年公开论文起诞生已有十多年,最近几年VAE类型的模型在图象生成领域应用较多,也是Diffusion扩散模型的基础,例如DALL-E3、Stable Diffusion及今年OpenAI发布的Sora都是建立在VAE的基础之上。此外,在音频、文本生成领域也有广泛应用,是深度学习中最为重要的技术之一。ICLR2024评选的首个时间检验奖在5月初公布,冠军颁给了《Auto-Encoding Variational Bayes》,这篇是经典VAE算法的原始论文,是关于一种变分推断和学习的算法,由Diederik P. Kingma和Max Welling撰写(DP Kingma不仅在生成模型和概率模型上有深入研究,还是大名鼎鼎的Adam Optimizer的作者,Max Welling除了研究概率模型之外,作为一个Graph Mining工作者,著名的GCN就是他和他的另一个学生TN Kipf提出的)。文章在2013年发表在arXiv上,主要解决在大型数据集上进行有效推断和学习的问题,特别是在存在不可处理的后验分布和连续潜在变量的情况下。
开始讲之前不得不吐槽一下,本博主后续打算对生成模型做一个全面的总结,看到网上各种解读的帖子已经非常多,但是大部分都是引用、复制别人的资料,里面大量的数学符号来源混乱也没做解释,给本博主造成了很大的困扰,我相信一定有很多读者跟我一样的感触。因此,本博主又仔细阅读了原始论文,本篇将直接基于原始论文和其中的数学变量对VAE的原理做深入的梳理。
1 起源
1.1 自编码器的任务定义
我们从自编码器(AutoEncoder,AE)出发,因为VAE是为了解决AE应用在内容生成任务时存在的缺陷而出现的。自编码器的初衷是做数据降维,从数据降维任务的角度来描述自编码器的建模过程就是:假设数据集 X X X的原始特征变量 x x x维度过高,那么我们希望通过编码器 E E E将其编码成低维特征向量 z = E ( x , w E ) z=E(x, w_{E}) z=E(x,wE),编码的原则是尽可能保留原始信息,因此我们再训练一个解码器 D D D,希望能通过 z z z重构原始信息,即 x ≈ D ( E ( x , w E ) , w D ) x≈D(E(x, w_{E}), w_{D}) x≈D(E(x,wE),wD),其优化目标一般是
w E , w D = arg min w E , w D E x ∼ D [ ∥ x − D ( E ( x , w E ) , w D ) ∥ ] \begin{equation} \begin{split} w_{E}, w_{D} = \argmin_{w_{E}, w_{D}} \Epsilon_{x\sim D}[\| x - D(E(x, w_{E}), w_{D})\|] \end{split} \end{equation} wE,wD=wE,wDargminEx∼D[∥x−D(E(x,wE),wD)∥]
其中, w E , w D w_{E}, w_{D} wE,wD分别为编码器 E E E和解码器 D D D的参数。
自编码器用图1表示可为:

图1 自编码器结构 \text{图1 自编码器结构} 图1 自编码器结构
1.2 自编码器存在的问题
理想情况下,假如每个样本都可以重构得很好,那么我们可以将 z z z当作是 x x x的等价表示。在内容生成任务上,我们不是想要由 z z z还原出训练样本 x x x,而是想要由新的编码向量实例 z z z生成与训练样本 x x x处于同一分布的新x值。但是实际中如果在自编码器上用一个新的编码向量实例 z z z由解码器 D D D生成出一个新的x时,通常并不我们想要的样子,比如在图片生成任务上,通常会生成类似于噪声的无意义图片。这表明编码向量 z z z在其向量空间内的分布不是均匀的,随意取的向量实例 z z z很大概率会超出其分布区域。
我们认为如果向量 z z z的分布形状是规整、无冗余、连续的,那么我们从中学习了一部分样本,就很容易泛化到未知的新样本上去,因为我们知道编码空间是规整连续的,所以我们知道训练样本的编码向量之间“缝隙”中的向量实例,实际上也对应着同一分布的、未知的真实样本,因此把已知的搞好了,很可能未知的也搞好了。
但是,因为常规的自编码器由于没有特别的约束, z z z的分布规律是完全不可控的(比如 z z z的各分量是否独立、是否要满足某种共现性?),所以随机抽取 z z z的新实例大概率不在 z z z的分布中,编码器生成结果就是没有意义的。
那么,VAE是如何解决自编码器存在的问题呢?
1.3 VAE的核心思路
为解决自编码器存在的问题,变分自编码器先从贝叶斯理论的角度引入了关于向量 z z z的后验分布 p ( z ∣ x ) p(z|x) p(z∣x),并且假设了 p ( z ∣ x ) p(z|x) p(z∣x)各个分变量服从独立高斯分布(为啥称为后验分布?因为我们认为 x x x是由变量 z z z生成的)。注意,这里并没有直接假设边缘概率 p ( z ) p(z) p(z)的各个分变量服从独立高斯分布,但很容易推导证明 p ( z ) p(z) p(z)的各个分变量是服从独立高斯分布的:
p ( z ) = ∫ p ( x ) p ( z ∣ x ) d x = ∫ p ( x ) N ( μ , σ 2 ) d x = N ( μ , σ 2 ) ∫ p ( x ) d x ∼ N ( μ , σ 2 ) \begin{equation} \begin{split} p(z) &= \int p(x)p(z|x)d_x \\ &= \int p(x)\mathcal{N}(\mu, \sigma^2)d_x \\ &= \mathcal{N}(\mu, \sigma^2)\int p(x)d_x \\ &\sim \mathcal{N}(\mu, \sigma^2) \\ \end{split} \end{equation} p(z)=∫p(x)p(z∣x)dx=∫p(x)N(μ,σ2)dx=N(μ,σ2)∫p(x)dx∼N(μ,σ2)
其中, N ( μ , σ 2 ) \mathcal{N}(\mu, \sigma^2) N(μ,σ2)是高斯分布, μ , σ 2 \mu, \sigma^2 μ,σ2分别为均值和方差, ∫ p ( x ) d x \int p(x)d_x ∫p(x)dx在数据集 X X X上是个常量,每一个 x x x是数据集上的一个样本。
那么思路就变得清晰了:如果我们从数据集 X X X上通过编码器 E E E学习到 p ( z ∣ x ) p(z|x) p(z∣x)的变量独立的高斯分布 N ( μ , σ ) \mathcal{N}(\mu, \sigma) N(μ,σ),那么在生成阶段,我们直接从这个学习到的高斯分布 N ( μ , σ ) \mathcal{N}(\mu, \sigma) N(μ,σ)中采样一个 z z z的向量实例,经过解码器 D D D就可以完美地生成满足数据集 X X X分布的数据 x x x值!
下面我们仔细建模这个思路的处理过程。
2 VAE的建模过程
2.1 VAE的任务定义
考虑数据集 X = { x ( i ) } i = 1 N X=\{x^{(i)}\}_{i=1}^N X={x(i)}i=1N由N个样本组成,每个样本都由一组 x x x变量组成,变量 x x x可能是连续分布或者离散分布。假设数据集由不可观测的连续型随机变量 z z z生成。VAE的概率图模型如下图2所示:

图2 概率图模型示意图 \text{图2 概率图模型示意图} 图2 概率图模型示意图
其中,
θ \theta θ为隐变量 z z z的后验分布 p θ ( z ∣ x ) p_{\theta}(z|x) pθ(z∣x)的分布参数,是需要学习出来的,比如对于高斯分布就是均值 μ \mu μ和标准差 σ \sigma σ;
ϕ \phi ϕ为隐变量 z z z的后验分布 p θ ( z ∣ x ) p_{\theta}(z|x) pθ(z∣x)的真实分布,可以认为是一个隐含的常量,如果 z z z高斯分布,那么该常量就对应均值和标准差的真实值;
VAE的生成过程包含两步:
(1)每个样本对应的 z ( i ) z^{(i)} z(i)真实值由一个先验分布 p θ ∗ ( z ) p_{\theta ^*}(z) pθ∗(z)生成;
(2)每个样本 x ( i ) x^{(i)} x(i)值由一个条件分布 p θ ∗ ( x ∣ z ) p_{\theta ^*}(x|z) pθ∗(x∣z)生成。
我们假设 p θ ∗ ( z ) p_{\theta ^*}(z) pθ∗(z)和 p θ ∗ ( x ∣ z ) p_{\theta ^*}(x|z) pθ∗(x∣z)分别来自 p θ ( z ) p_{\theta}(z) pθ(z)和 p θ ( x ∣ z ) p_{\theta}(x|z) pθ(x∣z)的参数化的分布族,他们的概率密度函数几乎处处不相同的。从我们的视角看,真实值 θ ∗ \theta ^* θ∗和隐变量 z ( i ) z^{(i)} z(i)的真实值都是不可知的。
我们没有对边际概率或后验概率做出一般的简化假设。相反,我们在这里感兴趣的是一种通用算法,它要解决以下问题:
(1) p θ ( x ) = ∫ p θ ( z ) p θ ( x ∣ z ) d z p_{\theta}(x) = \int p_{\theta}(z)p_{\theta}(x|z)d_z pθ(x)=∫pθ(z)pθ(x∣z)dz无法计算,同理, p θ ( z ∣ x ) = p θ ( x ∣ z ) p θ ( z ) / p θ ( x ) p_{\theta}(z|x) = p_{\theta}(x|z)p_{\theta}(z)/p_{\theta}(x) pθ(z∣x)=pθ(x∣z)pθ(z)/pθ(x)也无法求解,所以没法求EM(因为EM里面是要估计后验概率 p ( z ∣ x , θ ) p{}(z|x, \theta) p(z∣x,θ));
(2)数据集很大,批量优化成本太高;如果使用小批量甚至单个数据点进行参数更新或基于采样的解决方案,例如蒙特卡罗EM,通常又会太慢而非常耗时。
结合我们在上文1.3节介绍的VAE核心思路,要解决问题(1)中无法计算的概率,我们可以用神经网络来直接从训练样本中学习(对,万事不决,神经网络!呵呵),那么VAE的结构变成了这样(如下图3所示):
(1)设计一个编码器 E E E同时预测 p θ ( z ∣ x ) p_{\theta}(z|x) pθ(z∣x)的分布参数均值 μ \mu μ和标准差 σ \sigma σ,让这两个预测值要逼近真实分布 ϕ \phi ϕ的均值和标准差;注意, z z z是一个向量,所以均值 μ \mu μ和标准差 σ \sigma σ也都分别是一组向量;
(2)从均值 μ \mu μ和标准差 σ \sigma σ分布中采样一个向量实例作为 z z z的值,输入到解码器 D D D中解码出预测值 x ′ x' x′,让预测值 x ′ x' x′与真实值 x x x尽可能接近;这里的采样过程不可微,求不了梯度,会导致整个VAE的神经网络无法梯度更新;因此使用“重参数化(Reparameterization)”技巧引入了一个采样变量 ϵ \epsilon ϵ。

图3 VAE模型结构 \text{图3 VAE模型结构} 图3 VAE模型结构
这图里面有两大问题:(1)真实分布 ϕ \phi ϕ是什么,为什么要逼近这个分布的参数?真实分布 ϕ \phi ϕ在图2中就已出现,但是我们并没有讲为什么会有这个,更没有说如何逼近这个真实分布;(2)“重参数化(Reparameterization)”技巧又是怎么运用的?
下面我们仔细讲讲。
2.2 真实分布 ϕ \phi ϕ是什么,为什么要逼近这个分布的参数,如何做?
在实际情况中,编码器 E E E输出的分布参数均值 μ \mu μ和标准差 σ \sigma σ并没有什么约束,对于模型来说,输出标准差 σ \sigma σ相当于对 z z z引入了一定的波动性,会导致解码器 D D D重建 x x x变得非常困难。训练中模型为了尽快收敛,极可能走捷径让标准差 σ \sigma σ一直为0,只调整均值 μ \mu μ,那么编码器预测输出标准差 σ \sigma σ就没啥用了,整个VAE模型退化成了标准的自编码器模型。如果要避免这种情况出现,那么我们就人为指定一个真实的分布 ϕ \phi ϕ让模型去拟合就好了,既然VAE模型假设了变量 z z z的后验条件概率 p θ ( z ∣ x ) p_{\theta}(z|x) pθ(z∣x)均服从高斯分布,那么让真实分布 ϕ \phi ϕ直接固定为标准正态分布 N ( 0 , I 2 ) \mathcal{N}(0, I^2) N(0,I2)就是最简单的。
要逼近这个真实分布 ϕ \phi ϕ,这里都是正态分布,最简单的方法就是分别比较均值和方差即可,可将其加入到模型的损失函数作为一个正则化项 L μ , σ L_{\mu, \sigma} Lμ,σ:
L μ , σ = E x ∼ D [ α ∥ ( μ − 0 ) ∥ 2 + β ∥ ( σ − 1 ) ∥ 2 ] , μ , σ = E ( x , w E ) \begin{align} L_{\mu, \sigma} &= \Epsilon_{x\sim D}[\alpha \| (\mu - 0)\|^2 +\beta \|(\sigma - 1)\|^2], \\ \mu, \sigma&= E(x, w_{E}) \end{align} Lμ,σμ,σ=Ex∼D[α∥(μ−0)∥2+β∥(σ−1)∥2],=E(x,wE)
其中, α , β \alpha,\beta α,β为均值损失和方差损失的权重项。
这样带来一个问题, α , β \alpha,\beta α,β项并不好设置,比例选取得不好,生成的图像会比较模糊。
标准的VAE模型中对这个正则化项做了一些改进,采用KL散度 KL ( N ( μ , σ 2 ) ∥ N ( 0 , I ) ) \text{KL}(N(μ,σ2)\|N(0,I)) KL(N(μ,σ2)∥N(0,I))度量这两个分布的距离,因此推导得到了一个更加复杂的正则化项 L μ , σ L_{\mu, \sigma} Lμ,σ:
L μ , σ = E x ∼ D [ ∑ i = 1 d 1 2 ( μ 2 + σ 2 − log σ 2 − 1 ) ] , μ , σ = E ( x , w E ) \begin{align} L_{\mu, \sigma} &= \Epsilon_{x\sim D}[\sum_{i=1}^{d}\frac{1}{2}(\mu^2 + \sigma^2 -\log \sigma^2 - 1)], \\ \mu, \sigma&= E(x, w_{E}) \end{align} Lμ,σμ,σ=Ex∼D[i=1∑d21(μ2+σ2−logσ2−1)],=E(x,wE)
这样就不用考虑均值损失和方差损失的相对比例问题了。
推导过程:
由于我们考虑的是 z z z各分量独立的多元正态分布,因此只需要推导一元正态分布的情形即可,根据定义我们可以写出
KL ( N ( μ , σ 2 ) ∥ N ( 0 , 1 ) ) = ∫ 1 2 π σ 2 e − ( x − μ ) 2 2 σ 2 ( l o g e − ( x − μ ) 2 2 σ 2 / 2 π σ 2 e − x 2 2 2 π ) d x = ∫ 1 2 π σ 2 e − ( x − μ ) 2 2 σ 2 l o g { 1 σ 2 exp 1 2 [ x 2 − ( x − μ ) 2 σ 2 ] } d x = 1 2 ∫ 1 2 π σ 2 e − ( x − μ ) 2 2 σ 2 [ − l o g σ 2 + x 2 − ( x − μ ) 2 σ 2 ] d x = 1 2 ( − log σ 2 + μ 2 + σ 2 − 1 ) \begin{align} \text{KL}(N(μ,σ2) \| N(0,1)) &= \int \frac{1}{\sqrt{2πσ^2}}e^{−\frac{(x−μ)2}{2σ^2}}(log \frac{e^{−\frac{(x−μ)^2}{2σ^2}/\sqrt{2πσ^2}}}{\frac{e^{−\frac {x^2}{2}}}{2π}})d_x \\ &= \int \frac{1}{\sqrt{2πσ^2}}e^{−\frac{(x−μ)2}{2σ^2}}log \{ \frac{1}{\sqrt{σ^2}} \exp{\frac{1}{2}[x^2 - \frac{(x-\mu)^2}{σ^2}]} \}d_x \\ &= \frac{1}{2}\int \frac{1}{\sqrt{2πσ^2}}e^{−\frac{(x−μ)2}{2σ^2}}[-log σ^2 + x^2 - \frac{(x-\mu)^2}{σ^2}] d_x \\ &= \frac{1}{2}(-\log σ^2 + \mu^2 + σ^2 - 1) \end{align} KL(N(μ,σ2)∥N(0,1))=∫2πσ21e−2σ2(x−μ)2(log2πe−2x2e−2σ2(x−μ)2/2πσ2)dx=∫2πσ21e−2σ2(x−μ)2log{σ21exp21[x2−σ2(x−μ)2]}dx=21∫2πσ21e−2σ2(x−μ)2[−logσ2+x2−σ2(x−μ)2]dx=21(−logσ2+μ2+σ2−1)
其中,
整个结果分为三项积分,第一项实际上就是 − l o g σ 2 −logσ^2 −logσ2乘以概率密度的积分(也就是1),所以结果是 − l o g σ 2 −logσ^2 −logσ2;第二项实际是正态分布的二阶矩,熟悉正态分布的朋友应该都清楚正态分布的二阶矩为 μ 2 + σ 2 μ^2+σ^2 μ2+σ2;而根据定义,第三项实际上就是“-方差除以方差=-1”。
所以VAE模型最终的训练目标就变成了:
w E , w D = arg min w E , w D E x ∼ D [ ∥ x − D ( ( μ + ϵ ⊗ σ ) , w D ) ∥ + ∑ i = 1 d 1 2 ( μ 2 + σ 2 − log σ 2 − 1 ) ] μ , σ = E ( x , w E ) ϵ ∼ N ( 0 , 1 ) \begin{align} w_{E}, w_{D} &= \argmin_{w_{E}, w_{D}} \Epsilon_{x\sim D}[\| x - D((\mu + \epsilon \otimes \sigma), w_{D})\| + \sum_{i=1}^{d}\frac{1}{2}(\mu^2 + \sigma^2 -\log \sigma^2 - 1)] \\ \mu, \sigma&= E(x, w_{E}) \\ \epsilon&\sim \mathcal{N}(0, 1) \end{align} wE,wDμ,σϵ=wE,wDargminEx∼D[∥x−D((μ+ϵ⊗σ),wD)∥+i=1∑d21(μ2+σ2−logσ2−1)]=E(x,wE)∼N(0,1)
其中,
w E , w D w_{E}, w_{D} wE,wD分别为编码器 E E E和解码器 D D D的参数;
ϵ \epsilon ϵ为从标准正态分布中采样的值。
2.3 “重参数化(Reparameterization)”技巧
这个重参数化技巧说白了就是将不可导的采样过程移出到神经网络结构之外。除了这个,我们在以前的博文《基于梯度的优化问题中不可导操作的处理方法总结》中有更多详细的总结。
简单来说,从 N ( μ , σ 2 ) N(μ,σ2) N(μ,σ2)中采样一个 z z z,相当于从 N ( 0 , I ) N(0,I) N(0,I)中采样一个 ε ε ε,然后让 z = μ + ε × σ z=μ+ε×σ z=μ+ε×σ。
推导过程:
∫ 1 2 π σ 2 e − ( z − μ ) 2 2 σ 2 d z = ∫ 1 2 π σ 2 e − 1 2 ( z − μ σ ) 2 d ( z − μ σ ) \begin{align} &\int \frac{1}{\sqrt{2πσ^2}}e^{−\frac{(z−μ)2}{2σ^2}}d_z \\ &= \int \frac{1}{\sqrt{2πσ^2}}e^{−\frac{1}{2}(\frac{z−μ}{σ})^2}d_{(\frac{z−μ}{σ})} \\ \end{align} ∫2πσ21e−2σ2(z−μ)2dz=∫2πσ21e−21(σz−μ)2d(σz−μ)
这说明 z − μ σ = ε \frac{z−μ}{σ}=ε σz−μ=ε是服从均值为0、方差为1的标准正态分布的,要同时把 d z d_z dz考虑进去,是因为乘上 d z d_z dz才算是概率,去掉 d z d_z dz是概率密度而不是概率。
于是,我们将从 N ( μ , σ 2 ) N(μ,σ^2) N(μ,σ2)采样变成了从 N ( 0 , I ) N(0,I) N(0,I)中采样,然后通过参数变换得到从 N ( μ , σ 2 ) N(μ,σ^2) N(μ,σ2)中采样的结果。
3 一些常见的疑问
3.1 后验分布 p ( z ∣ x ) p(z|x) p(z∣x)必须假设为高斯分布么?
用其他分布也不是不行,比如均匀分布,只是计算两个分布的KL散度不像高斯分布一样有良好的性质,可能需要考虑比如除零问题、量纲的问题等等。
3.2 VAE的"变分"体现在哪里?
要理解这个,得首先熟悉变分法。可以查阅对应的数学资料,不细讲,这里直接引用资料[2]作者苏剑林的话:
K L ( p ( x ) ∥ q ( x ) ) KL(p(x)\|q(x)) KL(p(x)∥q(x))实际上是一个泛函,要对泛函求极值(证明始终有 K L ( p ( x ) ∥ q ( x ) ) ≥ 0 KL(p(x)\|q(x))\ge 0 KL(p(x)∥q(x))≥0)就要用到变分法,当然,这里的变分法只是普通微积分的平行推广,还没涉及到真正复杂的变分法。而VAE的变分下界,是直接基于KL散度就得到的。所以直接承认了KL散度的话,就没有变分的什么事了。
一句话,VAE的名字中“变分”,是因为它的推导过程用到了KL散度及其性质。
3.3 VAE的究竟在做什么?
在VAE中,它的Encoder有两个,一个用来计算均值,一个用来计算方差;然后由计算的均值和方差合成隐空间变量 z z z的值,这相当于给 z z z的值施加了0均值标准化处理;它的Decoder部分与AE模型并无区别。
观察目标函数公式(11)的包括x重建误差+分布逼近误差,由于每个 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x)是不可能完全精确等于标准正态分布的,否则 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x)就相当于跟 x x x无关了, x x x重建效果将会极差,目标函数(11)的值将会变大。最终的结果就会是x重建误差+分布逼近误差处在某种平衡之中(确切说处在帕累托前端上), p ( z ∣ x ) p(z|x) p(z∣x)保留了一定的x信息使 x x x重建效果也还可以,同时保留着生成能力。
参考资料
[1]. Auto-Encoding Variational Bayes, 201312.
[2]. 变分自编码器(一):原来是这么一回事
相关文章:
变分自动编码器(VAE)深入理解与总结
本文导航 0 引言1 起源1.1 自编码器的任务定义1.2 自编码器存在的问题1.3 VAE的核心思路 2 VAE的建模过程2.1 VAE的任务定义2.2 真实分布 ϕ \phi ϕ是什么,为什么要逼近这个分布的参数,如何做?2.3 “重参数化(Reparameterization…...

Leetcode 剑指 Offer II 079.子集
题目难度: 中等 原题链接 今天继续更新 Leetcode 的剑指 Offer(专项突击版)系列, 大家在公众号 算法精选 里回复 剑指offer2 就能看到该系列当前连载的所有文章了, 记得关注哦~ 题目描述 给定一个整数数组 nums ,数组中的元素 互不相同 。返…...

Linux基础命令常见问题解决方案
Linux 基础命令常见问题解决方案 在Linux的日常使用中,用户经常会遇到各种各样的问题。本文旨在提供一个关于Linux基础命令的常见问题及其解决方案的全面指南。我们将覆盖30种不同的错误场景,并给出具体的解决步骤和示例,帮助初学者快速定位…...
 ——使用LINQ进行匿名对象初始化)
LINQ(五) ——使用LINQ进行匿名对象初始化
总目录 C# 语法总目录 上一篇:LINQ(四) ——使用LINQ进行对象类型初始化 LINQ 五 ——使用LINQ进行匿名对象初始化 6.2 匿名类型 6.2 匿名类型 可以不用声明定义一个对象,直接使用new,然后直接赋值即可 string[] names { "Tom",…...
1小时从0开始搭建自己的直播平台(详细步骤)
本文讲述了如何从0开始,利用腾讯云的平台,快速搭建一个直播平台的过程。 文章目录 效果图详细步骤准备工作第一步:添加域名并检验cname配置1.先填加一个推流域名2. 点击完下一步,得到一个cname地址3. 将cname地址,配置…...

Python打包篇-exe
文章目录 pyinstallerauto-py-to-exe pyinstaller 命令行工具,语法自行查看官方help pip install pyinstallerauto-py-to-exe 基于pyinstaller的一款GUI工具,会自行打包py文件中依赖的库 pip install auto-py-to-exe auto-py-to-exe.exe //运行即可...

游戏找不到d3dcompiler_43.dll怎么办,教你5种可靠的修复方法
在电脑使用过程中,我们经常会遇到一些错误提示,其中之一就是“找不到d3dcompiler43.dll”。这个问题通常出现在游戏或者图形处理软件中,它会导致程序无法正常运行。为了解决这个问题,我经过多次尝试和总结,找到了以下五…...

如何使用多种算法解决LeetCode第135题——分发糖果问题
❤️❤️❤️ 欢迎来到我的博客。希望您能在这里找到既有价值又有趣的内容,和我一起探索、学习和成长。欢迎评论区畅所欲言、享受知识的乐趣! 推荐:数据分析螺丝钉的首页 格物致知 终身学习 期待您的关注 导航: LeetCode解锁100…...
泰拉瑞亚从零开始的开服教程
前言 本教程将讲诉使用Linux系统搭建泰拉瑞亚服务器(因为网上已经有很完善的windows开服教程了),使用的Linux发行版是Debian11,服务端使用的程序是TShock,游戏版本是1.4.4.9 所需要准备的 一台服务器(本教程使用的是…...
【云原生】K8s管理工具--Kubectl详解(一)
一、陈述式管理 1.1、陈述式资源管理方法 kubernetes 集群管理集群资源的唯一入口是通过相应的方法调用 apiserver 的接口kubectl 是官方的 CLI 命令行工具,用于与 apiserver 进行通信,将用户在命令行输入的命令,组织并转化为apiserver 能识…...

2024.5.26.python.exercise
# # 导入包 # from pyecharts.charts import Bar, Timeline # from pyecharts.options import LabelOpts, TitleOpts # from pyecharts.globals import ThemeType # # # 从文件中读取信息 # GDP_file open("1960-2019全球GDP数据.csv", "r", encoding&quo…...
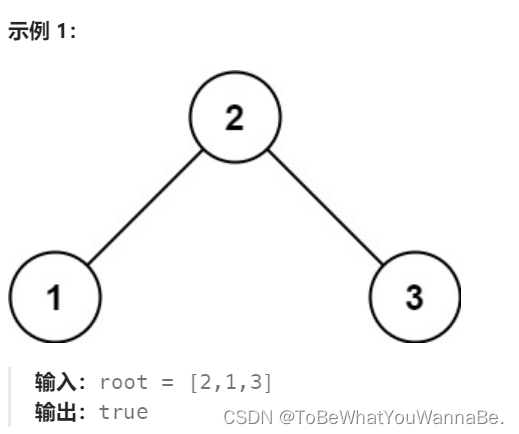
代码随想录-Day20
654. 最大二叉树 给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建: 创建一个根节点,其值为 nums 中的最大值。 递归地在最大值 左边 的 子数组前缀上 构建左子树。 递归地在最大值 右边 的 子数组后缀上 构建右子树。 返回 nums…...

揭秘C++ String容器:字符串操作的艺术
目录 编辑 引言 一、初识std::string:构造与初始化 二、字符串的操纵艺术:拼接、查找与替换 三、访问与遍历:字符的细腻触感 四、大小与容量:动态调整的智慧 五、进阶功能:探索更多可能 结语 引言 在C标准库…...

【C++】牛客 ——DP36 abb
✨题目链接: DP36 abb ✨题目描述 leafee 最近爱上了 abb 型语句,比如“叠词词”、“恶心心” leafee 拿到了一个只含有小写字母的字符串,她想知道有多少个 "abb" 型的子序列? 定义: abb 型字符串满足以下…...

SpringBoot如何实现跨域?
定义一个配置类,实现WebMvcConfigurer接口,重写addCorsMappings方法 Configuration public class CorsConfig implements WebMvcConfigurer {Overridepublic void addCorsMappings(CorsRegistry registry) {registry.addMapping("/**").allow…...

SW 草图偏移 先预选
因为有些不能用链全部选,可以先框选要偏移的,再点偏移命令...

5.23 Linux中超时检测方式+模拟面试
1.IO多路复用的原理? IO多路复用使得一个或少量线程资源处理多个连接的IO事件的技术。对于要处理的多个阻塞的IO操作,建立集合并存储它们的文件描述符,利用单个阻塞函数去监控集合中文件描述符事件到达的情况,(如果到…...

MySQL数据表索引命名规范
在数据库设计和开发过程中,索引是提高查询性能的重要工具。合理的索引命名规范不仅能提高代码的可读性,还能便于维护和管理。本文将详细介绍MySQL数据表索引的命名规范,包括不同类型索引的命名方法,并提供多个代码示例以说明如何命…...

python内置函数map/filter/reduce详解
在Python中,map(), filter(), 和 reduce() 是内置的高级函数(实际是class),用于处理可迭代对象(如列表、元组等)的元素。这些函数通常与lambda函数一起使用,以简洁地表达常见的操作。下面我将分别解释这三个函数。 1. …...

PICO VR眼镜定制播放器使用说明文档videoplayerlib-ToB.apk
安装高级定制播放器 高级定制播放器下载地址:https://download.csdn.net/download/ahphong/89360454 仅限用于PICO G2、G3、G4、NEO系列VR眼镜上使用, 用途:用于第三方APP(开发者)调用定制播放器播放2D、3D、180、360全景视频。 VR眼镜系统请升级到最新版,可在官网下载,…...

如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南
如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重新焕发活力&a…...

国产大模型新王登基?Qwen3.7-Max全球第五、编程Agent登顶,千问APP免费体验全攻略
AI前线观察 | 2026.05.25 就在刚刚过去的阿里云峰会上,通义千问甩出了一张“王炸”。万亿参数MoE架构的旗舰模型Qwen3.7-Max正式接入千问APP、PC端及网页端。这不仅仅是一次版本更新,更是国产大模型在权威第三方榜单中首次稳居全球前五、国产第一的里程碑…...

Mysql?基础语法!!!
作为程序员、数据分析从业者,甚至是产品运营,SQL都是必须掌握的核心技能。不管是后端开发对数据库增删改查,还是数据分析提取业务数据,本质都是在写SQL语句。很多新手觉得SQL难,其实是没有理清逻辑。SQL的核心逻辑非常…...
)
【独家首发】Sora 2 AVI支持并非“开箱即用”:3层封装校验机制详解(RIFF→AVI→OpenCV Mat内存映射链路图解)
更多请点击: https://codechina.net 第一章:Sora 2 AVI支持并非“开箱即用”:核心矛盾与技术定位 Sora 2 的官方文档与发布说明中明确将 AVI 视为“实验性容器支持”,而非默认启用的输入格式。其底层解码栈基于 FFmpeg 5.1 构建&…...

SafeExamBrowser安全绕过实战:虚拟机检测绕过与日志伪装技术架构深度解析
SafeExamBrowser安全绕过实战:虚拟机检测绕过与日志伪装技术架构深度解析 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass SafeExamBrowser&…...

具身智能的发展对人类社会的影响有哪些?
具身智能对人类社会影响一、经济产业层面产业重构:催生机器人、智能制造、自动驾驶新产业,重塑生产链条效率跃升:替代重复繁重劳作,工厂、农业、物流产能大幅提升就业结构变化:低端体力岗位缩减,运维、研发…...

终极指南:5分钟搞定淘宝淘金币全任务自动化脚本
终极指南:5分钟搞定淘宝淘金币全任务自动化脚本 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 你是否厌倦…...

Qri入门教程:如何在5分钟内开始使用分布式数据集版本控制
Qri入门教程:如何在5分钟内开始使用分布式数据集版本控制 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一款强大的分布式数据集版本控制工具,它比电子表格更强大,比数…...

告别手动分类!用Python+ArcPy批量处理DEM,一键生成坡度坡向等高线报告
用PythonArcPy实现DEM地形分析全自动化:从数据到报告的智能工作流 第一次接手山区风电项目的地形分析任务时,我花了整整三天时间在ArcGIS界面里反复点击同样的按钮——加载DEM、计算坡度坡向、生成等高线、调整分类阈值、导出图片。当第五个区域的报告终…...

深度解析:ctfileGet如何实现城通网盘直链解析的3大技术突破
深度解析:ctfileGet如何实现城通网盘直链解析的3大技术突破 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet ctfileGet是一款专为城通网盘设计的开源直链解析工具,通过创新的技术…...