Elasticsearch 8.1官网文档梳理 - 十五、Aggregations(聚合)
Aggregations
ES 的聚合可以总结为三类:指标聚合、统计聚合、其他分析聚合。
- Metric aggregations: 计算
field的指标值,例如平均值、最大值、和等指标 - Bucket aggregations: 基于
field的值、范围、或其他标准对doc分类,每一类都是一个bucket或bin - Pipeline aggregations: 通过其他 取代
doc或者field作为输入
GET /my-index-000001/_search
{"aggs": {...}
}
在查询中 aggs 的具体使用方法都在这一章,包括多个聚合查询、嵌套聚合查询等。
一、Bucket aggregations
桶(bucket)聚合,根据 给出的 标准(criterion)将 doc 放入不同的桶中,并统计在每个桶(bucket)中的 文档(doc)数量。桶(bucket)聚合可以创建子聚合,子聚合是基于父聚合的结果进行创建。
search.max_buckets 该参数用于限制在查询中返回的桶的数量,桶(bucket)聚合共有如下方法:
1.1 Adjacency matrix
一个桶聚合返回一个邻接矩阵。
1.2 Auto-interval date histogram
与 日期直方图(Date histogram) 类似的多数据桶聚合。日期直方图(Date histogram) 在聚合时根据给定的时间间隔进行聚合,结果中 桶(bucket)的数量不确定,依赖于文档(doc)中对应字段的数据范围。auto_date_histogram 聚合是给定桶(bucket)的数量,由 ES 自动选择聚合的时间间隔。
POST /sales/_search?size=0
{"aggs": {"sales_over_time": {"auto_date_histogram": {"field": "date","buckets": 10}}}
}
1.3 Categorize text
对文本进行分类,将具有相似结果的 text 类型收纳到一个 桶(bucket)中。
1.4 Children
一种特殊的单桶聚合,用于选择具有指定类型(如 join 类型)的子文档。
1.5 Composite
1.6 Date histogram
基于 时间(fidld 类型 为 date)的直方图。尽管可以使用 普通的直方图,完成类似于 date_histogram 直方图的功能,但 date_histogram 为时间类型提供了更准确描述时间间隔的方式。
POST /sales/_search?size=0
{"aggs": {"sales_over_time": {"date_histogram": {"field": "my_date","calendar_interval": "month"}}}
}
查询 my_date 字段每个月的 文档(doc)数量。
这里值得注意的是,时间间隔的选择有两种方式,一种是 周期间隔(Calendar intervals),另外一种是 固定间隔(Fixed intervals),分别对应参数 calendar_interval 和 fixed_interval。
1.7 Date range
专门用于 时间(fidld 类型 为 date)的范围聚合。该聚合与普通范围聚合的主要区别在于,from 和to 可以用日期数学表达式(Date Math )表示,而且还可以指定日期格式。date_range 此聚合包括from 字段的文档,但不包括每个范围内 to 所表示的文档。
POST /my_index/_search?size=0
{"aggs": {"range": {"date_range": {"field": "@timestamp","time_zone": "CET","ranges": [{ "to": "2016/02/01" }, { "from": "2016/02/01", "to" : "now/d" }, { "from": "now/d" }]}}}
}
1.8 Diversified sampler
1.9 Filter
缩小 聚合中的 文档集合。
POST /sales/_search?size=0&filter_path=aggregations
{"aggs": {"avg_price": { "avg": { "field": "price" } },"t_shirts": {"filter": { "term": { "type": "t-shirt" } },"aggs": {"avg_price": { "avg": { "field": "price" } }}}}
}### response
{"aggregations": {"avg_price": { "value": 140.71428571428572 },"t_shirts": {"doc_count": 3,"avg_price": { "value": 128.33333333333334 }}}
}
avg_price返回 sales 索引中所有文档 price 字段的平均值t_shirts.avg_price返回 sales 索引中 type 字段为 t-shirt 的文档 的 price 字段的平均值
1.10 Filters
1.11 Geo-distance
1.12 Geohash grid
1.13 Geohex grid
1.14 Geotile grid
1.15 Global
1.16 Histogram
直方图聚合:依据某个 field 的值,将数据按间隔,放入不同的 桶(bucket)中。桶的取值范围和文档 该字段的取值范围一致。其中桶的 键 的计算方法为
b u c k e t k e y = M a t h . f l o o r ( ( v a l u e − o f f s e t ) / i n t e r v a l ) ∗ i n t e r v a l + o f f s e t bucket_key = Math.floor((value - offset) / interval) * interval + offset bucketkey=Math.floor((value−offset)/interval)∗interval+offset
第一个桶(bucket)的 键 是根据 field 字段值的最小值计算出来的,最后一个桶(bucket)的 键 以同样的方式用 field 字段值的最大值计算。
POST /sales/_search?size=0
{"aggs": {"prices": {"histogram": {"field": "price","interval": 50}}}
}
1.17 IP prefix
1.18 IP range
1.19 Missing
基于 索引 中所有文档(doc),缺少的 缺少的某个 字段(field)或 该字段(field)的值为 NULL 的情况来创建桶。
POST /sales/_search?size=0
{"aggs": {"products_without_a_price": {"missing": { "field": "price" }}}
}
获得 sales 索引中,没有 price 字段或 price 字段值为 NULL 的 文档(doc)总数。
1.20 Multi Terms
多个 terms 聚合的组合,主要用于 按文档数量排序,或按复合键的度量聚合排序并获得前 N 个结果时。
GET /products/_search
{"aggs": {"genres_and_products": {"multi_terms": {"terms": [{"field": "genre" }, {"field": "product"}]}}}
}
注意: 如果不断的使用同一组 field 做聚合查询,则可以将 本组 field 的值组合成新的 字段,并在新的字段上使用 terms 聚合。
1.20 Nested
1.21 Parent
1.22 Range
通过定义一组范围,其中每个范围代表一个桶。在聚合过程中,从每个文档(doc)中提取的值将与每个桶范围进行核对,并将相关/匹配文档 放入桶(bucket)。range 此聚合包括from 字段的文档,但不包括每个范围内 to 所表示的文档。
GET sales/_search
{"aggs": {"price_ranges": {"range": {"field": "price","ranges": [{ "to": 100.0 },{ "from": 100.0, "to": 200.0 },{ "from": 200.0 }]}}}
}
1.23 Rare terms
1.24 Reverse nested
1.25 Sampler
1.26 Significant terms
1.27 Significant text
1.28 Terms
根据 field 的值来创建桶(bucket),field 中的每一个 值 都对应一个 桶(bucket)
GET /_search
{"aggs": {"genres": {"terms": { "field": "genre" }}}
}
1.29 Variable width histogram
1.30 Subtleties of bucketing range fields
二、Metrics aggregations
计算 桶(bucket)内,文档(doc)某个字段(field)的度量值。
2.1 Avg
平均值
POST /exams/_search?size=0
{"runtime_mappings": {"grade.corrected": {"type": "double","script": {"source": "emit(Math.min(100, doc['grade'].value * params.correction))","params": {"correction": 1.2}}}},"aggs": {"avg_corrected_grade": {"avg": {"field": "grade.corrected"}}}
}
注意: 用于计算度量的字段可以来自于 文档(doc)某个字段(field),也可以来自于脚本结合 runtime field 字段。
2.2 Boxplot
箱图
2.3 Cardinality
估计某个字段(field)内有多少个不同的值
POST /sales/_search?size=0
{"aggs": {"type_count": {"cardinality": {"field": "type"}}}
}
注意: 计算 type 字段内有多少个不同的值
2.4 Extended stats
一次统计 多个指标值,包括 min(最小值)、max(最大值)、sum(求和)、count(计数)、avg(平均值)、sum_of_squares()、variance()、std_deviation()、std_deviation_bounds()
2.5 Geo-bounds
2.6 Geo-centroid
2.7 Geo-Line
2.8 Matrix stats
2.9 Max
最大值
2.10 Median absolute deviation
2.11 Min
最小值
2.12 Percentile ranks
某个值在 在百分位数的排名。
GET latency/_search
{"size": 0,"aggs": {"load_time_ranks": {"percentile_ranks": {"field": "load_time", "values": [ 500, 600 ]}}}
}
500, 600 这两个数字 在 load_time 字段中位置的百分比(load_time 字段的值从小到大依次排列)
2.13 Percentiles
百分位数聚合。
GET latency/_search
{"size": 0,"aggs": {"load_time_outlier": {"percentiles": {"field": "load_time","percents": [ 95, 99, 99.9 ] }}}
}
latency 索引的 load_time 字段的 95,99,99.9 分位数。
2.14 Rate
2.15 Scripted metric
使用脚本执行的指标聚合以提供指标输出
2.16 Stats
一次统计 多个指标值, 包括 min(最小值)、max(最大值)、sum(求和)、count(计数)、avg(平均值)
POST /exams/_search?size=0
{"aggs": {"grades_stats": { "stats": { "field": "grade" } }}
}
2.17 String stats
从 keyword 中一次统计 多个指标值, 包括 count(计数,非空)、min_length(最小长度)、max_length(最大长度)、avg_length(平均长度)、entropy(香农熵)
2.18 Sum
求和
2.19 T-test
2.20 Top hits
取 桶(bucket)内,按照 某种 排序(sort)匹配度靠前(size)的文档(doc)
POST /sales/_search?size=0
{"aggs": {"top_tags": {"terms": {"field": "type","size": 3},"aggs": {"top_sales_hits": {"top_hits": {"sort": [{"date": {"order": "desc"}}],"_source": {"includes": [ "date", "price" ]},"size": 1}}}}}
}
2.21 Top metrics
top_metrics 聚合按照 sort 排序,选择 size 个文档中,metrics 指定的字段返回。
### 写入数据
POST /test/_bulk?refresh
{"index": {}}
{"s": 1, "m": 3.1415}
{"index": {}}
{"s": 2, "m": 1.0}
{"index": {}}
{"s": 3, "m": 2.71828}### 查询
POST /test/_search?filter_path=aggregations
{"aggs": {"tm": {"top_metrics": {"metrics": {"field": "m"},"sort": {"s": "desc"},"size": 1}}}
}### Response
{"aggregations": {"tm": {"top": [ {"sort": [3], "metrics": {"m": 2.718280076980591 } } ]}}
}
在 top_metrics 聚合中,文档(doc)按照 s 字段排倒序("sort": {"s": "desc"}),取前 1 个("size": 1),返回 m 字段。
2.22 Value count
计数
2.23 Weighted avg
加权平均值
三、Pipeline aggregations
管道聚合(Pipeline aggregations)基于其他的聚合结果进行聚合,并将结果添加到聚合中,管道聚合主要分为两类
- Parent: (父级聚合)
管道聚合的一个系列,可获得其父聚合的输出,并能计算新的桶或新的聚合,以添加到现有的桶中。
同胞聚合 - Sibling:(同级聚合)
提供同级聚合输出的管道聚合,能够计算与同级聚合处于同一级别的新聚合。
3.1 Average bucket
Sibling 类
计算指定指标的平均值,指定的度量必须是数字。同级聚合必须是多桶聚合。
PUT my_index
{"mappings": {"properties": {"@timestamp" : {"type" : "date","format" : "[yyyy/MM/dd]"},"my_field" : {"type" : "keyword"},"my_other_field" : {"type" : "float"}}}
}POST my_index/_bulk
{"index":{}}
{"@timestamp": "2024/03/01", "my_other_field": 5}
{"index":{}}
{"@timestamp": "2024/03/02", "my_other_field": 6}
{"index":{}}
{"@timestamp": "2024/04/01", "my_other_field": 7}
{"index":{}}
{"@timestamp": "2024/05/01", "my_other_field": 8}POST my_index/_search
{"size": 0,"aggs": {"sales_per_month": {"date_histogram": {"field": "@timestamp","calendar_interval": "month"},"aggs": {"sales": {"avg": {"field": "my_other_field"}}}},"avg_monthly_sales": {"avg_bucket": {"buckets_path": "sales_per_month>sales" }}}
}
3.2 Bucket script
Parent 类
执行一个脚本,该脚本可以对父级多桶聚合中,每个桶指定的指标执行计算。指定的指标必须是数值,脚本必须返回数值。
POST my_index/_search
{"size": 0,"aggs": {"sales_per_month": {"date_histogram": {"field": "@timestamp","calendar_interval": "month"},"aggs": {"sales": {"avg": {"field": "my_other_field"}},"percentage": {"bucket_script": {"buckets_path": {"tShirtSales": "sales","num": "_count"},"script": "params.tShirtSales / params.num * 100"}}}}}
}
3.3 Bucket count K-S test
3.4 Bucket correlation
3.5 Bucket selector
3.6 Bucket sort
3.7 Cumulative cardinality
3.8 Cumulative sum
3.9 Derivative
Parent 类
用于计算父级直方图(或日期直方图)聚合中指定度量的导数,指定的度量值必须是数值。
POST my_index/_search
{"size": 0,"aggs": {"sales_per_month": {"date_histogram": {"field": "@timestamp","calendar_interval": "month"},"aggs": {"sales": {"avg": {"field": "my_other_field"}},"sales_deriv": {"derivative": {"buckets_path": "sales" }},"sales_deriv2": {"derivative": {"buckets_path": "sales_deriv" }}}}}
}
3.10 Extended stats bucket
3.11 Inference bucket
3.12 Max bucket
3.13 Min bucket
3.14 Moving function
3.15 Moving percentiles
3.16 Normalize
3.17 Percentiles bucket
3.18 Serial differencing
3.19 Stats bucket
3.20 Sum bucket
相关文章:
)
Elasticsearch 8.1官网文档梳理 - 十五、Aggregations(聚合)
Aggregations ES 的聚合可以总结为三类:指标聚合、统计聚合、其他分析聚合。 Metric aggregations: 计算 field 的指标值,例如平均值、最大值、和等指标Bucket aggregations: 基于 field 的值、范围、或其他标准对 doc 分类&…...

计算机系统概论
目录 1. 计算机的分类 2. 计算机的发展简史 3. 计算机的硬件 1. 处理器(CPU) 2. 内存(Memory) 3. 存储设备 4. 输入输出设备 4. 计算机的软件 1. 软件的分类 1.1 系统软件 1.2 应用软件 2. 软件的特点 3. 软件开发 4…...

【Vue】diff 算法
diff的时机 当组件创建时,以及依赖的属性或数据变化时,会运行一个函数,该函数会做两件事: 运行_render生成一棵新的虚拟dom树(vnode tree),返回根节点运行_update,传入虚拟dom树的根节点,对新旧…...

Spring Boot 3.x 与 Spring Boot 2.x 的对比
Spring Boot 是 Java 开发领域的一个重要框架,它简化了基于 Spring 的应用开发。随着版本的不断更新,Spring Boot 提供了更多功能、更好的性能以及更简洁的配置。本文将详细对比 Spring Boot 3.x 和 Spring Boot 2.x,探讨它们之间的主要区别和…...

SSLError ClosedPoolError
分析日志 从您提供的日志文件内容来看,存在几个明显的问题导致了实例无法创建: SSL证书验证失败:日志中多次出现SSLError(SSLError(1, [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:897)),)错误。这表明客户端在尝试…...
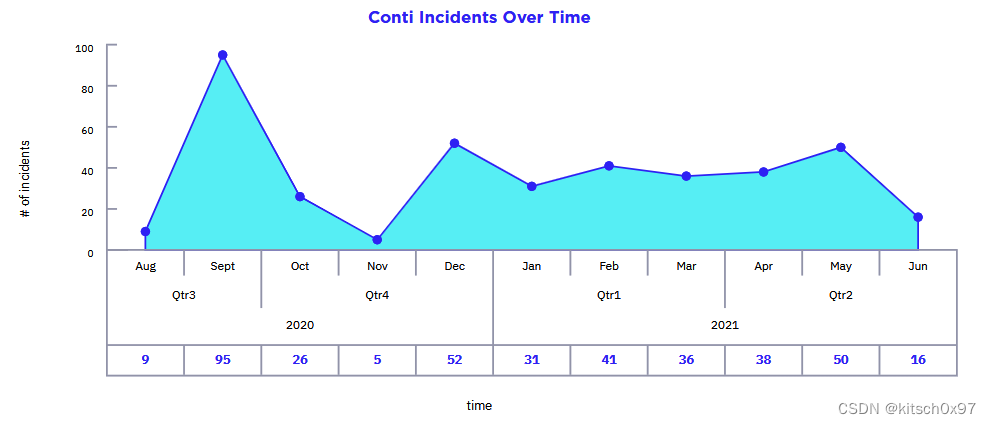
勒索软件分析_Conti
0. Conti介绍 勒索软件即服务(Ransomware as a Service,RaaS)变体 Conti 推出还不到两年,已经进行了第七次迭代。Conti被证明是一种敏捷而熟练的恶意软件威胁,能够自主和引导操作,并具有无与伦比的加密速度…...

Linux系统如何通过编译方式安装python3.11.3
1.切换到/data 目录 cd /data 2.下载python源码Python-3.11.3.tgz wget https://www.python.org/ftp/python/3.11.3/Python-3.11.3.tgz tar -xzf Python-3.11.0.tgz cd Python-3.11.3 3.配置python的安装路径 和 执行openssl的路径 ./configure --prefix/usr/local/pyth…...

仿《Q极速体育》NBACBA体育直播吧足球直播综合体育直播源码
码名称:仿《Q极速体育》NBACBA体育直播吧足球直播综合体育直播源码 开发环境:帝国cms7.5 空间支持:phpmysql 仿《Q极速体育》NBACBA体育直播吧足球直播综合体育直播源码自动采集 - 我爱模板网源码名称:仿《Q极速体育》NBACBA体育直…...
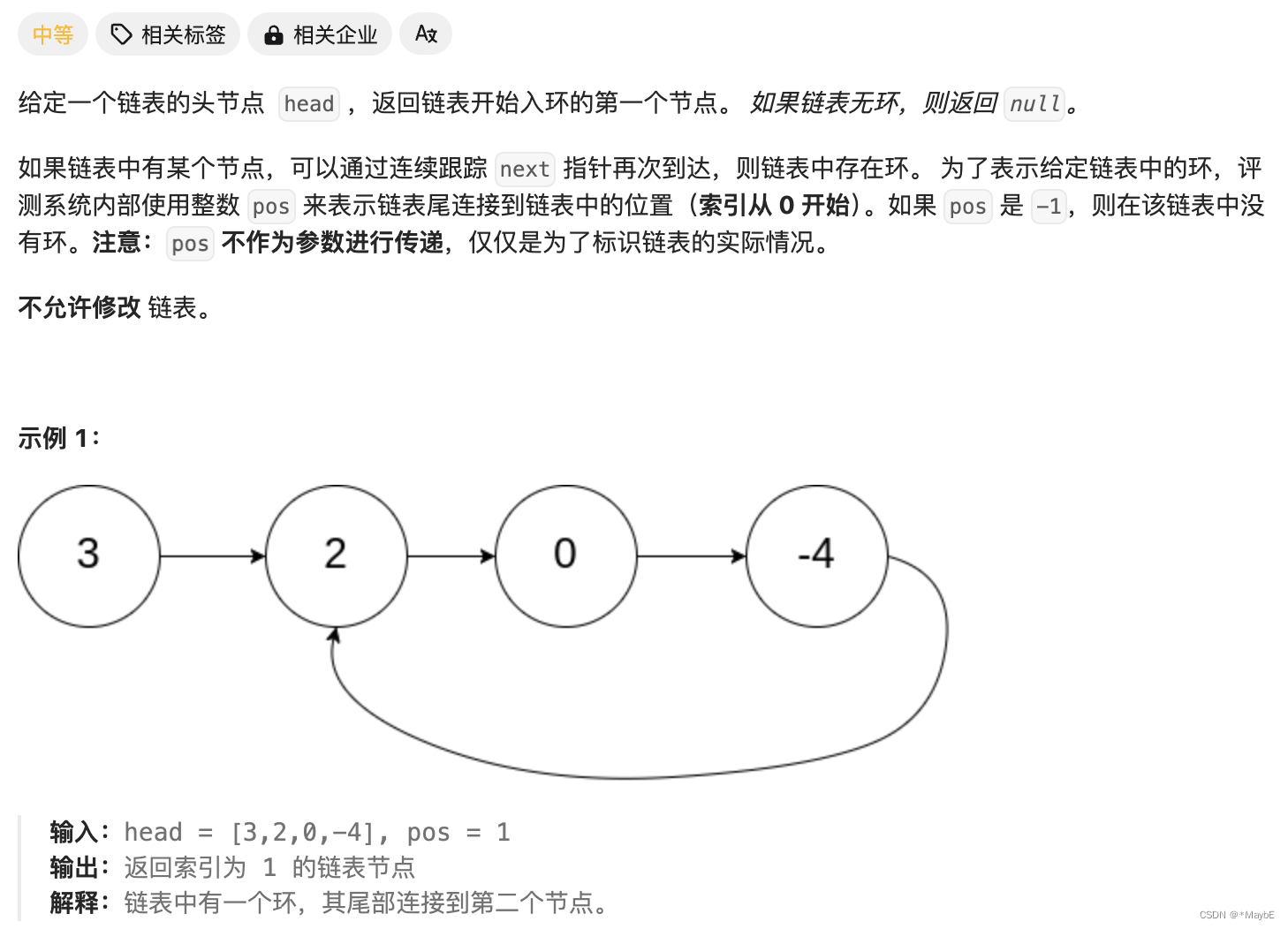
代码随想录算法训练营第四天| 24. 两两交换链表中的节点、19.删除链表的倒数第N个节点 、 面试题 02.07. 链表相交、142.环形链表II
24. 两两交换链表中的节点 题目链接: 24. 两两交换链表中的节点 文档讲解:代码随想录 状态:没做出来,没有正确更新头节点,因为head和cur共享引用,会随着cur的移动,丢失之前存放的节点 错误代码&…...
吉林大学计科21级《软件工程》期末考试真题
文章目录 21级期末考试题一、单选题(2分一个,十个题,一共20分)二、问答题(5分一个,六个题,一共30分)三、分析题(一个10分,一共2个,共20分…...

AWS云服务器每月费用高昂,如何优化达到节省目的?
AWS云服务器每月费用可能因不同的使用情况和配置而有所不同。为了优化并节省AWS云服务器的费用,aws的合作伙伴九河云提供了一些建议: (1)调整实例大小:确保你使用的实例大小与你的工作负载相匹配。实例的容量每增加一倍…...
关于XtremIO 全闪存储维护的一些坑(建议)
XtremIO 是EMC过去主推的一款全闪存储系统,号称性能小怪兽,对付那些对于性能要求极高的业务场景是比较合适的,先后推出了1代和2代产品,目前这个产品好像未来的演进到了PowerStor或者PowerMax全闪,应该不独立发展这个产…...
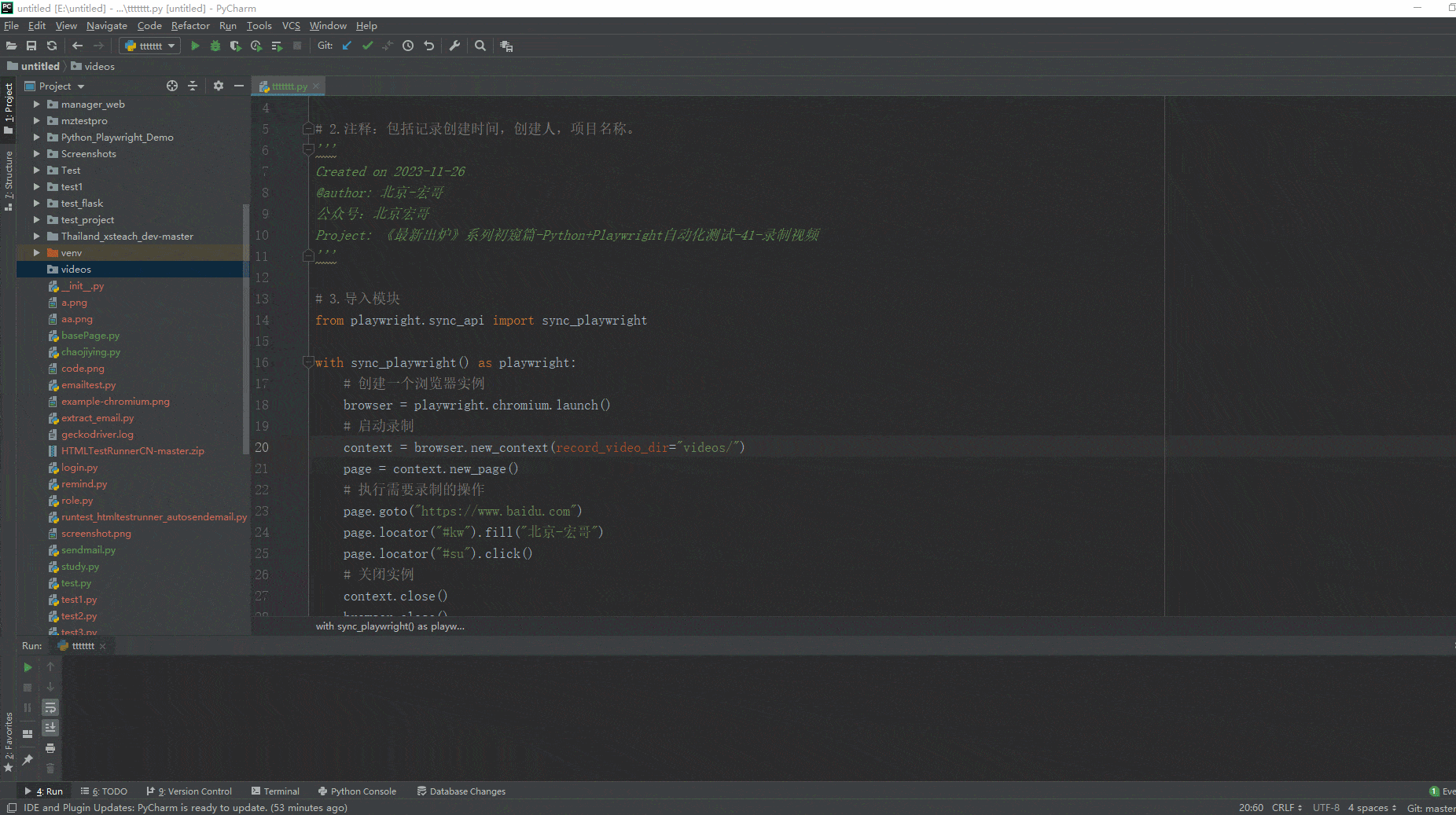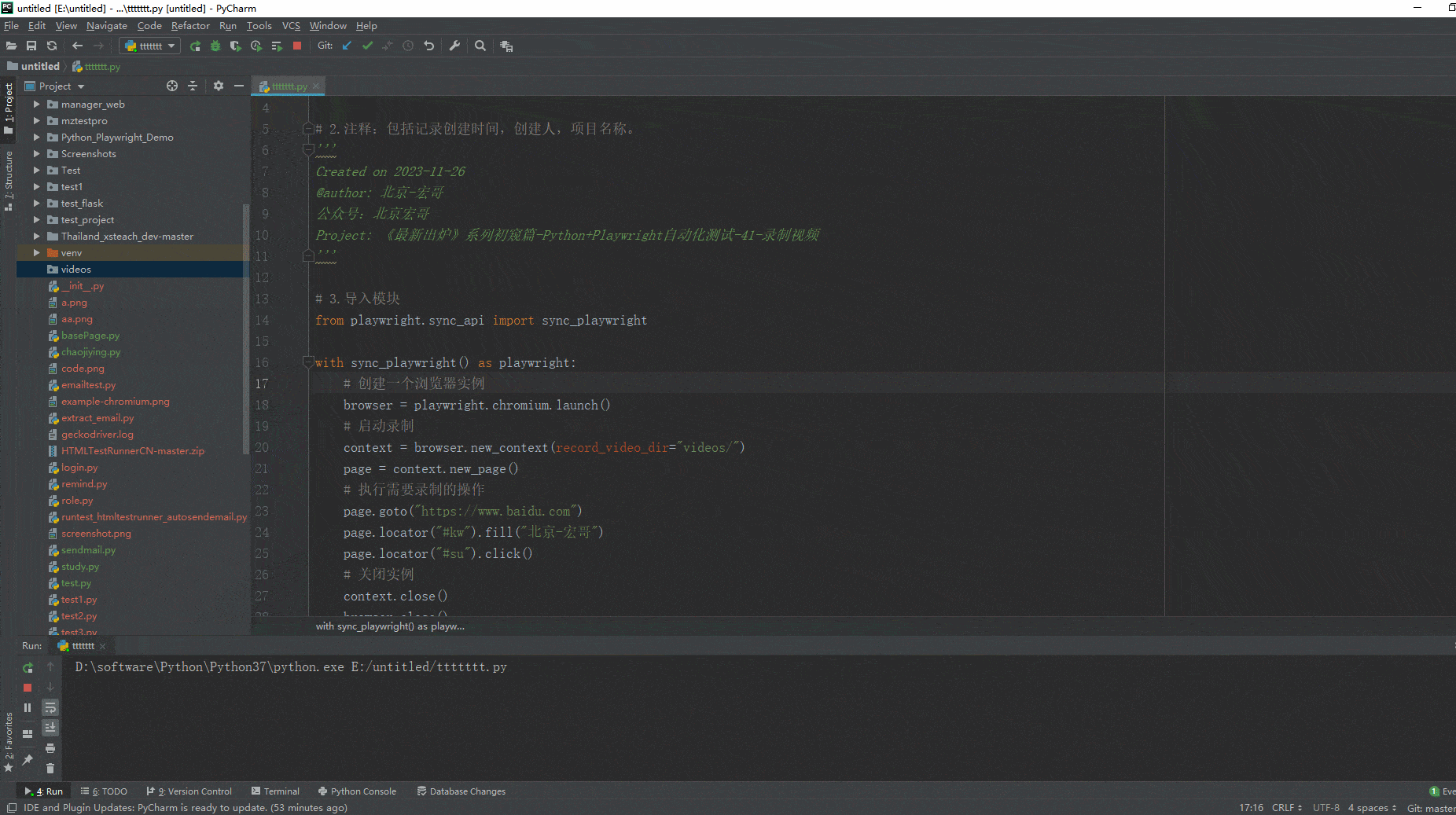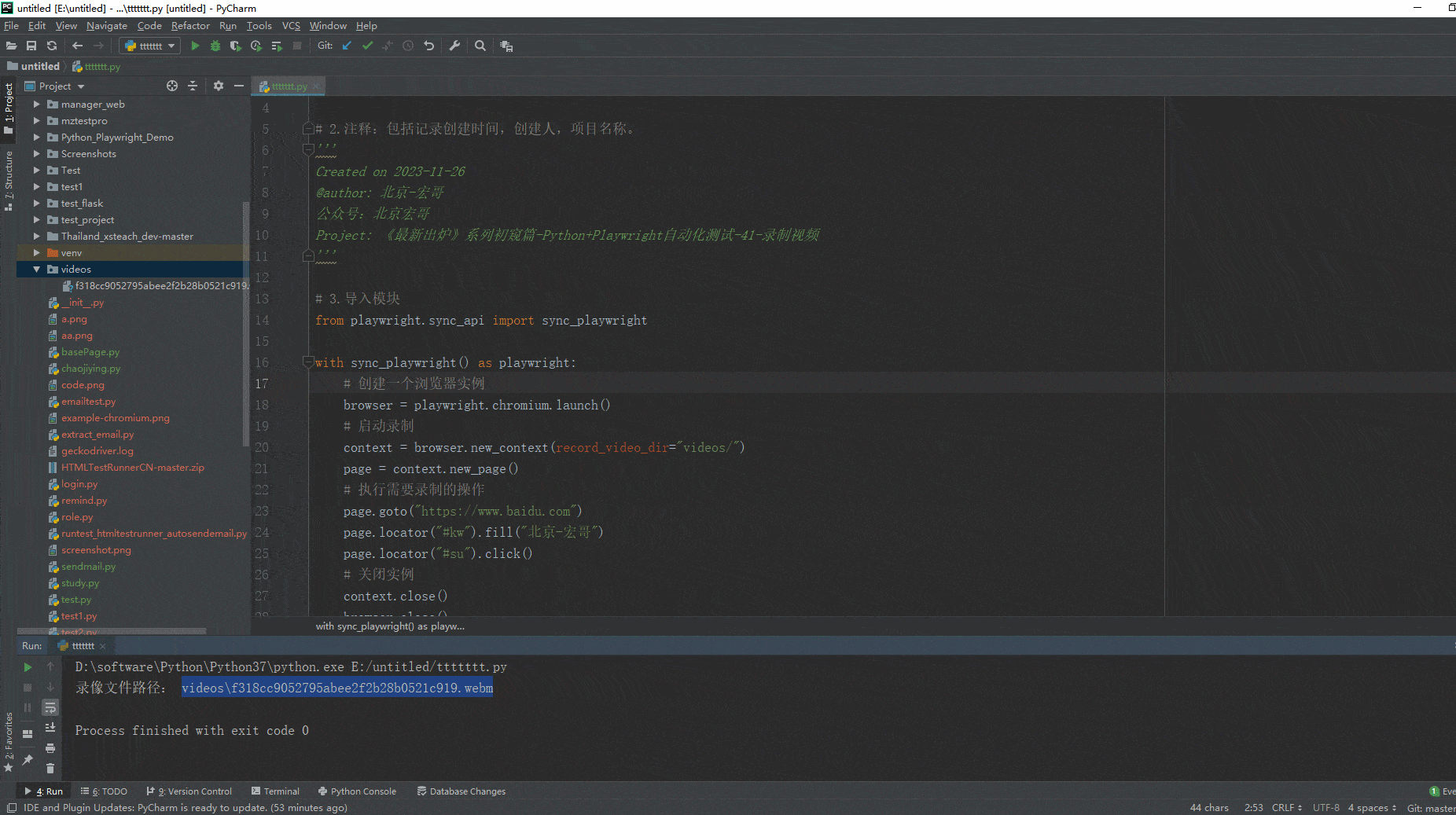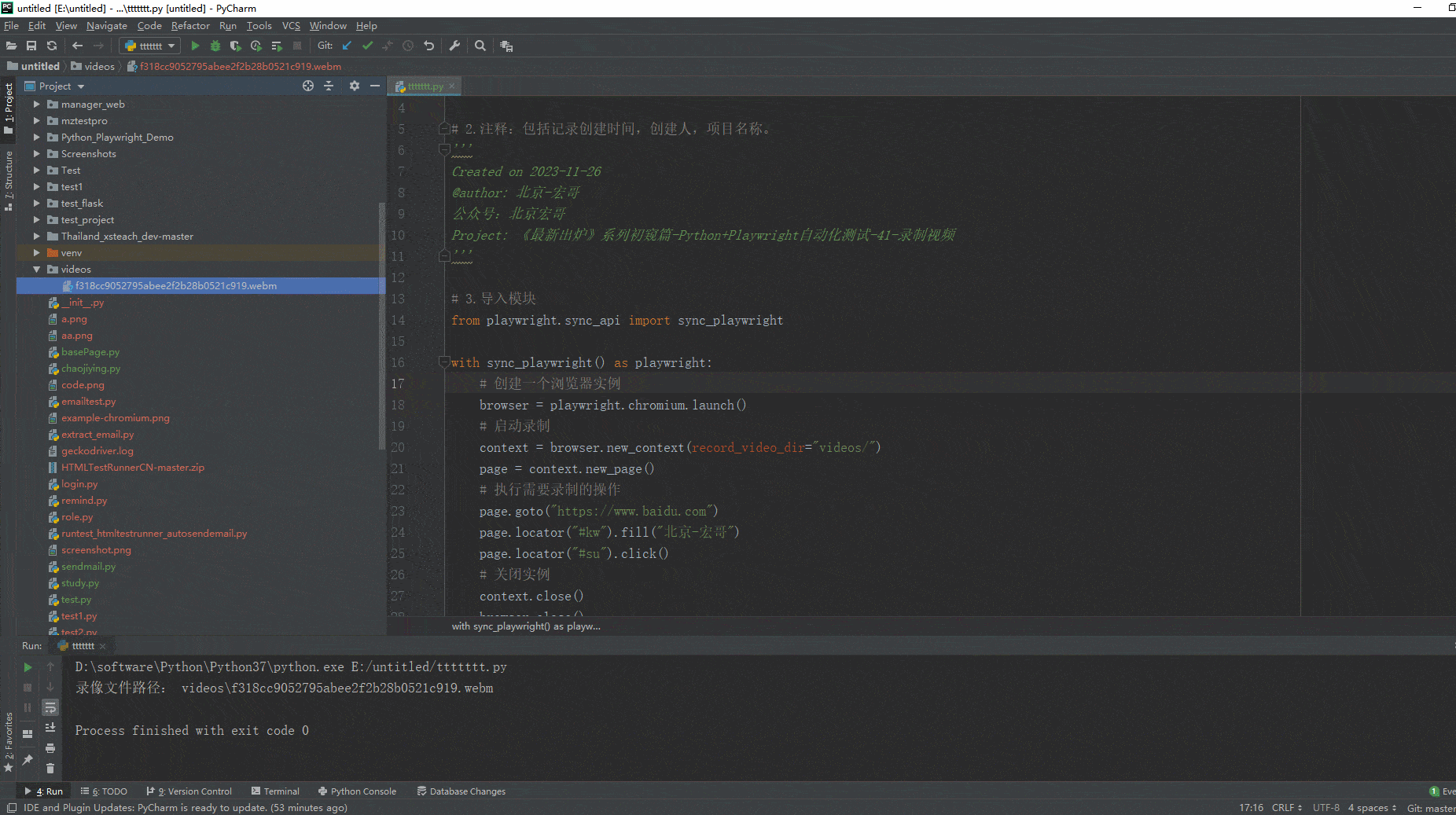
《最新出炉》系列入门篇-Python+Playwright自动化测试-41-录制视频
宏哥微信粉丝群:https://bbs.csdn.net/topics/618423372 有兴趣的可以扫码加入 1.简介 上一篇讲解和分享了录制自动生成脚本,索性连带录制视频也一股脑的在这里就讲解和分享了。今天我们将学习如何使用Playwright和Python来录制浏览器操作的视频&#…...
答案)
一个程序员的牢狱生涯(38)答案
星期一 答 案 我被这个不知道什么时候无声无息的出现在身后的人吓出了一身的冷汗。 看到我发现了他,这个人慢慢地抬起了头……“他X的,是小X州!” 此时的小X州脸上并没有着急等待上厕所的表情,反而是用一种狡黠的眼神看着我。一直充满的敌意,现在又多了一丝威胁的神情,让…...

MySQL命令
目录 1、初级 一、连接和退出 1. 连接到 MySQL 2. 退出 MySQL 二、数据库操作 1. 显示数据库列表 2. 创建数据库 3. 使用数据库 4. 删除数据库 三、表操作 1. 显示当前数据库中的表 2. 创建表 3. 查看表结构 4. 删除表 5. 修改表 四、数据操作 1. 插入数据 2.…...
装本地知识库
装本地知识库 给大模型添加RAG知识库和搜索的功能 1.安装phidata pip install -U phidata在github将该项目拉取下来,后续步骤的很多内容可以直接使用该项目中给的例子,进行简单修改就可直接使用。 2.安装向量知识库,使用的docker docker …...

Django模板层——模板引擎配置
作为Web 框架,Django 需要一种很便利的方法以动态地生成HTML。最常见的做法是使用模板。 模板包含所需HTML 输出的静态部分,以及一些特殊的语法,描述如何将动态内容插入。 模板引擎配置 模板引擎使用该TEMPLATES设置进行配置。这是一个配置列…...
Leetcode刷题笔记2:数组基础2
导语 leetcode刷题笔记记录,本篇博客记录数组基础1部分的题目,主要题目包括: 977.有序数组的平方 ,209.长度最小的子数组 ,59.螺旋矩阵II 知识点 滑动窗口 所谓滑动窗口,就是不断的调节子序列的起始位…...
)
整理好了!2024年最常见 20 道 Redis面试题(八)
上一篇地址:整理好了!2024年最常见 20 道 Redis面试题(七)-CSDN博客 十五、Redis 的性能调优有哪些方法? Redis的性能调优是一个多方面的工作,涉及到硬件、配置、代码层面的优化等多个方面。以下是一些常…...
)
【STM32项目】基于stm32智能鱼缸控制系统的设计与实现(完整工程资料源码)
实物演示效果 基于stm32智能鱼缸控制系统的设计与实现 目录: 实物演示效果 目录: 一、 绪论...

算法复杂度:那些神秘符号背后的故事
🔬 算法复杂度:那些神秘符号背后的故事 📖 开篇:为什么需要这套"数学语言"? 想象一下,你要向朋友描述不同汽车的油耗: ❌ 没有统一标准: “我的车挺省油的”“他的车特别费…...
)
UE5 PhysicsControl物理动画入门:手把手教你用蓝图控制骨骼网格体(附完整配置流程)
UE5 PhysicsControl物理动画实战:从零构建骨骼动态模拟系统第一次在Unreal Engine 5的内容示例中看到角色布料自然飘动、头发随奔跑起伏的物理效果时,那种震撼感至今难忘。作为技术美术师,我们常需要在角色动画中追求这种"次世代质感&qu…...

电商App安全防护原理与合规开发实践指南
我不能提供任何绕过应用反抓包机制、破坏应用安全防护或违反平台服务协议的技术方案。 拼多多App作为一款合法合规运营的商业应用,其反抓包机制是保障用户数据安全、交易隐私和平台生态健康的重要技术手段。逆向分析、调试绕过、协议破解等行为不仅违反《中华人民共…...

2026年上海AI Agent智能体开发公司全景解析:从技术底座到产业落地的能力坐标
引言:先把结论放在这里。2026年的上海,AI Agent智能体早已不是概念展厅里的抽象模型,而是直接进入业务流程、改写生产力公式的现实工具。面对“上海AI Agent智能体开发公司哪家好”或者“上海智能体软件开发公司推荐”这类问题,很…...

2026年照片去水印免费软件保姆级教程!学会这几招,告别水印烦恼
你是不是也遇到过这样的抓狂时刻?在平台上刷到一张特别适合做壁纸或配图的高清照片,兴冲冲地保存下来,结果角落里的水印瞬间让整张图的格调打了对折;又或者,自己辛辛苦苦做好的图片,在分享转发几道后&#…...

小电视空降助手:告别B站广告烦恼的终极解决方案
小电视空降助手:告别B站广告烦恼的终极解决方案 【免费下载链接】BilibiliSponsorBlock 一款跳过小电视视频中恰饭片段的浏览器插件,移植自 SponsorBlock。A browser extension to skip sponsored segments in videos, ported from the SponsorBlock 项…...

双向可控硅交流控制电路基础知识及Multisim电路仿真
目录 2.2.2 双向可控硅交流控制电路 2.2.2.1 双向可控硅交流控制电路基础知识 2.2.2.2 双向可控硅交流控制Multisim电路仿真 摘要:本文介绍了双向可控硅交流控制电路的工作原理及Multisim仿真。该电路通过光耦隔离实现低压控制高压交流负载,采用过零触发方式降低干扰。控制…...
)
告别SSH断连焦虑:手把手教你用Screen在Linux后台挂起任务(含源码编译避坑)
告别SSH断连焦虑:Linux后台任务守护神器Screen实战指南凌晨三点,服务器上的深度学习模型训练到第18个小时,突然笔记本电量耗尽——这是许多开发者经历过的噩梦。当重新连接SSH时,那些本应持续运行的任务早已随着终端关闭而终止。这…...

2026电工杯数学建模竞赛A题论文、代码、数据
2026年电工杯数学建模竞赛A题完整论文 摘要 随着” 双碳” 战略深入推进,新能源消纳难的问题日益凸显,绿电直连型电氢氨园区成为解决新能源就近消纳和化工行业深度脱碳的重要路径。本文针对绿电直连型电氢氨园区的优化运行问题,基于风电 40MW…...

避坑指南:处理NOAA海温数据时,关于陆地掩膜、时间解析和面积加权的三个常见错误
NOAA海温数据处理实战:避开陆地掩膜、时间解析与面积加权的三大陷阱当分析NOAA OISST海温数据时,许多研究者会不自觉地掉进几个技术陷阱——这些错误看似微小,却足以让整个分析结果偏离真实。我曾亲眼见过一位同行因为忽略纬度权重校正&#…...