数据分析实战:从0到1完成数据获取分析到可视化
文章目录
- 1.数据分析基本流程
- 1.1 数据采集
- 1.2 数据提炼
- 1.3 数据探索分析
- 2.数据获取的方法和工具
- 2.1 数据解锁器
- 2.2 爬虫浏览器
- 2.3 数据洞察市场
- 3.完整案例分析:从数据采集到数据可视化
- 3.1 直接按需定制数据集获取数据
- 3.2 获取IP代理,利用python爬取数据
- 3.3 数据可视化
- 4.总结
1.数据分析基本流程
1.1 数据采集
数据采集顾名思义就是获取数据源的各类数据,它在数据分析和处理中扮演着至关重要的角色。
数据源的类型包括结构化数据、半结构化数据和非结构化数据,这些数据类型的多样性要求数据采集系统具备更高的灵活性和用户自定义能力。
由于很多数据应用都需要来自互联网的外部数据,因此,常常会用到网络爬虫,按照一定的规则,自动递抓取互联网信息的程序或者脚本。
再者,在大数据环境下,数据采集技术面临许多挑战,包括数据源种类多、数据类型复杂、数据量大且产生速度快等问题。因此,保证数据采集的可靠性和高效性,避免重复数据成为关键考量因素。
数据采集常常需要面临和克服以下问题:
- 数据多样性:源数据以各种格式存在,如文本、图片、视频等,需要掌握各种格式的处理方式。
- 大数据:数据海量且增长快,需要高效准确的定位到所需要的数据信息。
- 数据安全与隐私:在采集和存储数据的过程中,需要确保数据的安全性和保护用户隐私,避免数据泄露和滥用。
- 实时性要求:某些应用对数据的实时性有严格要求,如何在短时间内采集并处理大量实时数据是一个技术难题。
- 网络限制:对于在线数据采集,网络的稳定性和速度可能会影响数据的实时获取,因此需要一个稳定高效的网络。
- 频率限制:针对某公共网址,多次采集会遭到封禁,因此,需要切换不同的IP,或者仿真模拟真人操作采集数据。
- 技术机制:为了防止外部造成网址瘫痪,很多网站会设置各种机制,如验证码、IP 限制、动态页面等,因此需要拥有专业的技术处理才能获取数据。
针对这些问题,要么自己技术够用,要么能找到技术够硬的平台,通过技术平台解决难题或获取数据。
1.2 数据提炼
数据采集主要是将数据汇集在一起,为数据提炼做准备,而数据提炼是将采集的数据转化为有用信息的过程,常用到的技术有ETL。
ETL技术:主要用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)到目的端的过程。主要讲网页企业中的分散、凌乱、不统一的数据整合在一起,进行分析探索和决策。
数据提炼通常涉及以下几个关键步骤:
- 数据抽取:从无结构或半结构化的数据中提取关键信息,并将其组织成结构化格式,便于机器理解和处理。
- 数据加工:数据加工通常有字段映射、数据过滤、数据清洗、数据替换、数据计算、数据验证、数据合并和数据拆分,移除或修正错误、重复或不完整的数据,确保数据质量的完整性。
- 数据转换:将数据转换成适合分析的格式,例如通过归一化或标准化数值,常用到有数据挖掘技术。
常用的一些ETL工具有三种:
- DataStage:数据集成软件平台,专门针对多值数据源进行简化和自动化,提供图形框架用于转换、清洗和加载数据,能够处理大型数据库、关系数据和普通文件。
- Informatica PowerCenter:企业级需求而设计的企业数据集成平台,支持结构化、半结构化和非结构化数据,提供丰富的数据转换组件和工作流支持。
- Kettle:开源的ETL工具,数据抽取高效稳定,管理来自不同数据库的数据,提供图形化的操作界面,支持工作流。
1.3 数据探索分析
数据探索分析可以分为数据分析和数据解释。
- 数据分析旨在发现数据中的规律、趋势和关联性,以支持和指导决策制定。常用到的方法有描述性分析(对数据的基本特征进行概括和描述)、回归分析(用于研究变量之间的关系)、聚类分析(将数据进行分组)。
关联规则挖掘:发现不同数据项之间的关联。 - 数据解释的主要工作是对提炼的数据采用人机交互方式将结果展示给用户,为了更清晰有效地传递信息,通常会使用图形和图表,在视觉上更好地传递信息,有效的可视化可以帮助用户分析和探索数据,使复杂的数据更容易理解和使用。
2.数据获取的方法和工具
网络爬虫是数据获取的常用方法,和代理IP配合能保证数据采集的稳定运行。市面上有许多代理IP,选择通常有一套标准,不合格的代理可能导致爬虫频繁中断和失败等产生一系列问题,所以对于挑选可以参考以下几个方面:
- 试用服务:不同的代理IP,通常有一定的试用服务,可以通过测试对比代理的性能和适用性。
- 用户评价和反馈:代理IP服务于用户,可以多查看其他用户使用的评价和反馈,或者参考行业内相关人士的评测和推荐。
- 安全性和隐私保护:查看服务商的隐私政策,确保他们不会记录你的活动数据。
- IP池的规模和多样性:拥有大规模和多样化的IP池可以提供更好地覆盖和较低的封禁风险。
- 可靠性和稳定性:通过试用检查代理服务的运行时间和性能历史记录,确保它们能提供稳定可靠的服务。
- 专业的技术支持和服务:查看对应服务商的用户手册和资源,咨询对应客服,看是否提供良好的支持和服务。
刚好近期需要使用IP代理获取数据,通过不断地了解,发现亮数据有许多用户评价和反馈,好评众多,因此,博主立马进行了注册,通过测试使用后,发现IP质量特别好,工具也多,整体特别满意,有兴趣的可以试试 👉亮数据官网数据获取。
2.1 数据解锁器
数据解锁器是一种绕过网络限制或检测,模拟真人访问解锁网站网站并抓取数据。它能完全模仿真人挖掘网页数据,拥有管理IP发送请求率、设置请求间隔、校准参照标头、识别蜜罐陷阱、模仿真人和设备等功能。
解锁器的优点有:
- 自动解锁,自动重试。仿真浏览器指纹,解锁各大网站,设置请求间隔不断自动重试获取数据。
- 验证码解决方案。拥有多套方案,自动识别验证码中的字符或图形,运用成熟的技术来处理验证码。
- 应对目标网站的更改。及时发现网站的更改情况,调整采集策略,确保随时能正常获取数据。
- 选定域的结果解析和异步请求。在特定的领域范围内,对结果进行深入解析和分析,并发起不同步的请求操作,不阻塞当前的执行任务,提高系统的并发处理能力和效率。
2.2 爬虫浏览器
数据浏览器有很多,但大多都不够专业,对网络爬虫抓取数据并没有提供更多的帮助。但亮数据提供的爬虫浏览器内置网站解锁功能,集成了亮网络解锁器自动化解锁能力,并且自动管理所有网站深层解锁操作,包括:验证码解决、浏览器指纹识别、自动重试和选择标头等。
爬虫浏览器的亮点如下:
- 解锁最强大的网页屏蔽。大规模抓取总是需要复杂的解锁操作,亮数据浏览器后台自动管理所有网站解锁操作:CAPTCHA解决、浏览器指纹识别、自动重试、标头选择、cookie和Javascript渲染等,节省时间和资源。
- 轻易绕过任何机器人检测软件。使用 AI 技术,亮数据浏览器会不断调整,自动学习绕过机器人检测系统,以真实用户浏览器的形式出现在机器人检测系统中,以实现比代理更高的解锁成功率,告别屏蔽麻烦,节约成本。
- 根据需要批量使用网络抓取浏览器。亮数据浏览器托管在强大的可高度扩展的基础架构之上,这赋予你自由使用任何数量的浏览器来运行数据抓取项目的可能
- 兼容Puppeteer, Playwright和Selenium。轻松调用API以获取任意数量的浏览器会话,并使用Puppeteer (Python)、Playwright (Node.js)或Selenium与它们交互。非常适合需要网站交互来检索数据的抓取项目,例如将鼠标悬停在页面上、单击按钮、滚动、添加文本等。
2.3 数据洞察市场
数据洞察市场是一个利用数据分析为组织提供有价值见解的领域,它能快速地收集市场相关行业的数据,通过不断地对比和定位,发现潜在问题,指定合理更有效地方案,增强在市场上的竞争力。
最常见的一些指标和策略有:
- 市场份额:收集同行业市场份额的相关数据,分析自己的优劣势,并作出调整。
- 价格优化:收集对比各大平台的产品价格,跟踪同类产品不同季节时段的价格调整,优化自己的价格,获取利润同时,保有竞争力。
- 产品匹配:库存匹配,以确保你能在物流备货方面处于竞争优势。了解竞品的库存和已售数量,基于数据发现潜在热品,灵活更新库存减少成本压力。
- 高效运营:跟踪所有 SKU 并自动识别库存问题(缺货)、促销和低效活动、销售额或利润下降等来优化运营,优化生产。
只要清楚市场,才能知道需要什么数据,站在市场角度,收集集成各大公众平台数据,优先进行分析和训练,得出更好的市场洞察力。
3.完整案例分析:从数据采集到数据可视化
需求目标:以豆瓣网为例,获取豆瓣读书排行榜Top250(https://book.douban.com/top250)数据,整合梳理有效信息,制作数据可视化报告。
3.1 直接按需定制数据集获取数据
分析:在这里我们使用亮数据的“按需定制数据集”,根据自己的需要和使用场景定制自己的数据集。
- 进入到网络数据采集页面,选择数据产品为“按需定制数据集”。
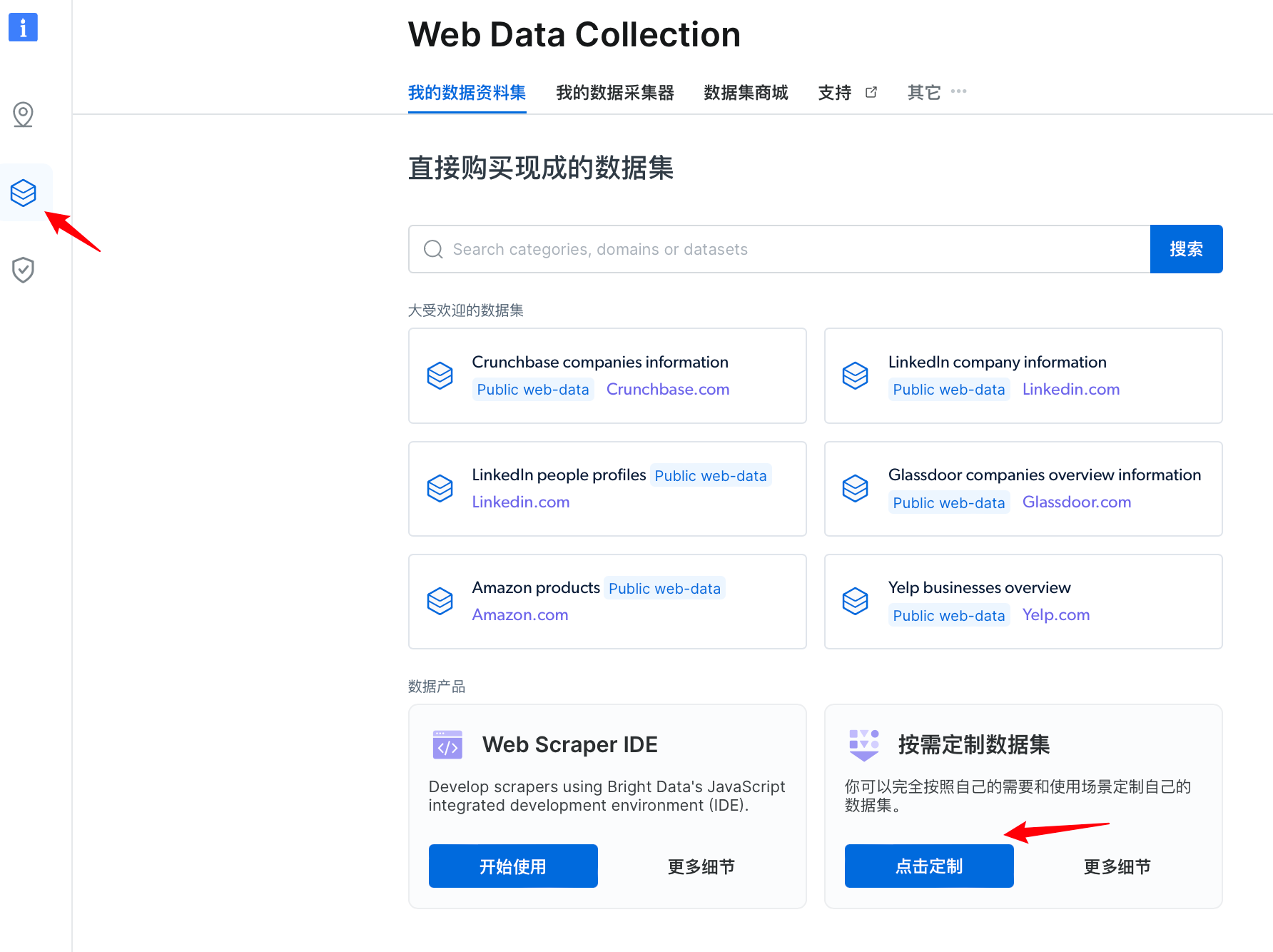
- 点击选择自定义默认数据集,开始创建代理端口。

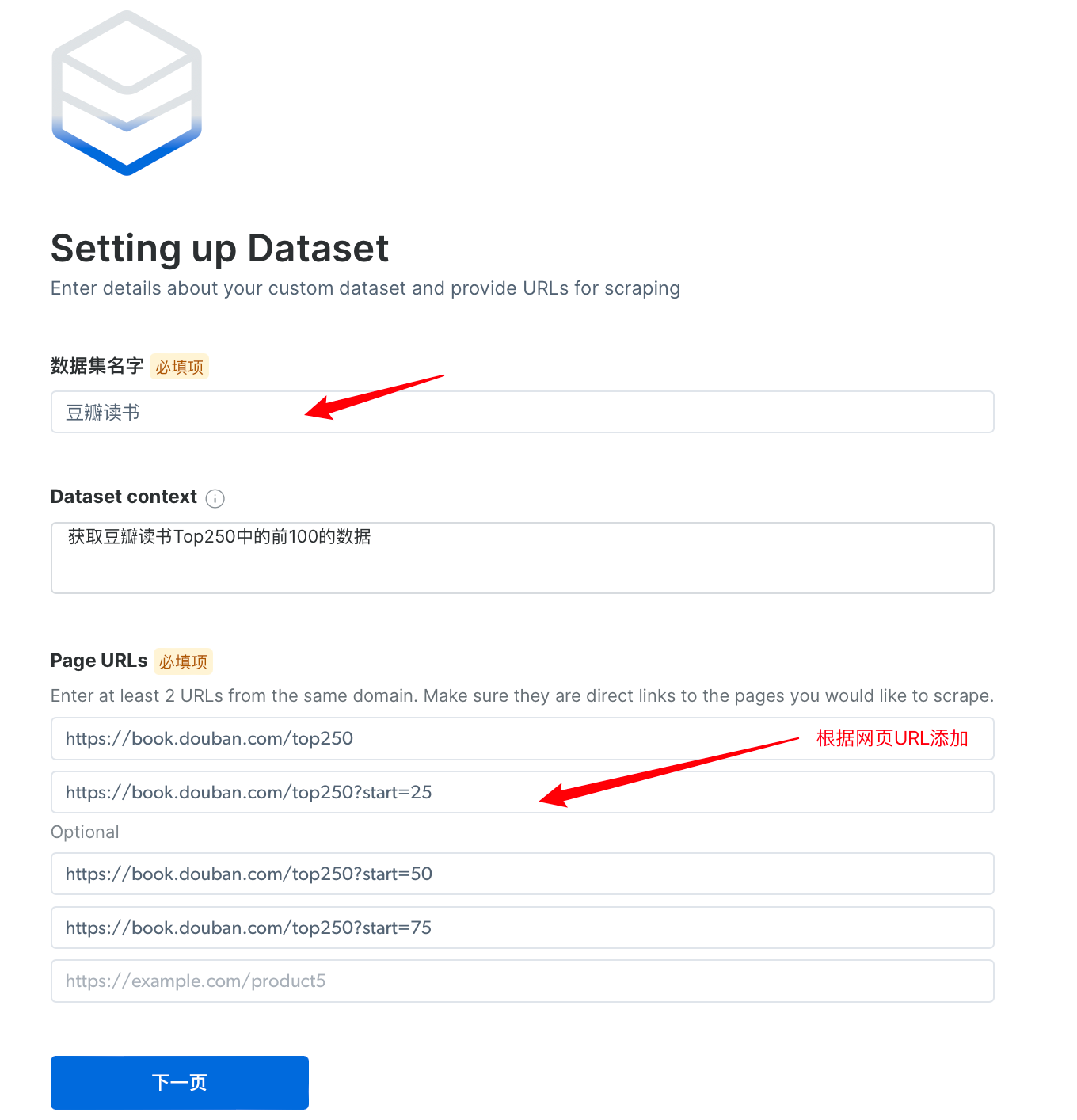
- 填写需要获取的数据集名字、包含的内容,查看豆瓣读书排行榜Top250每页分布,可得出每页对应的URL,依次填入,点击下一页。
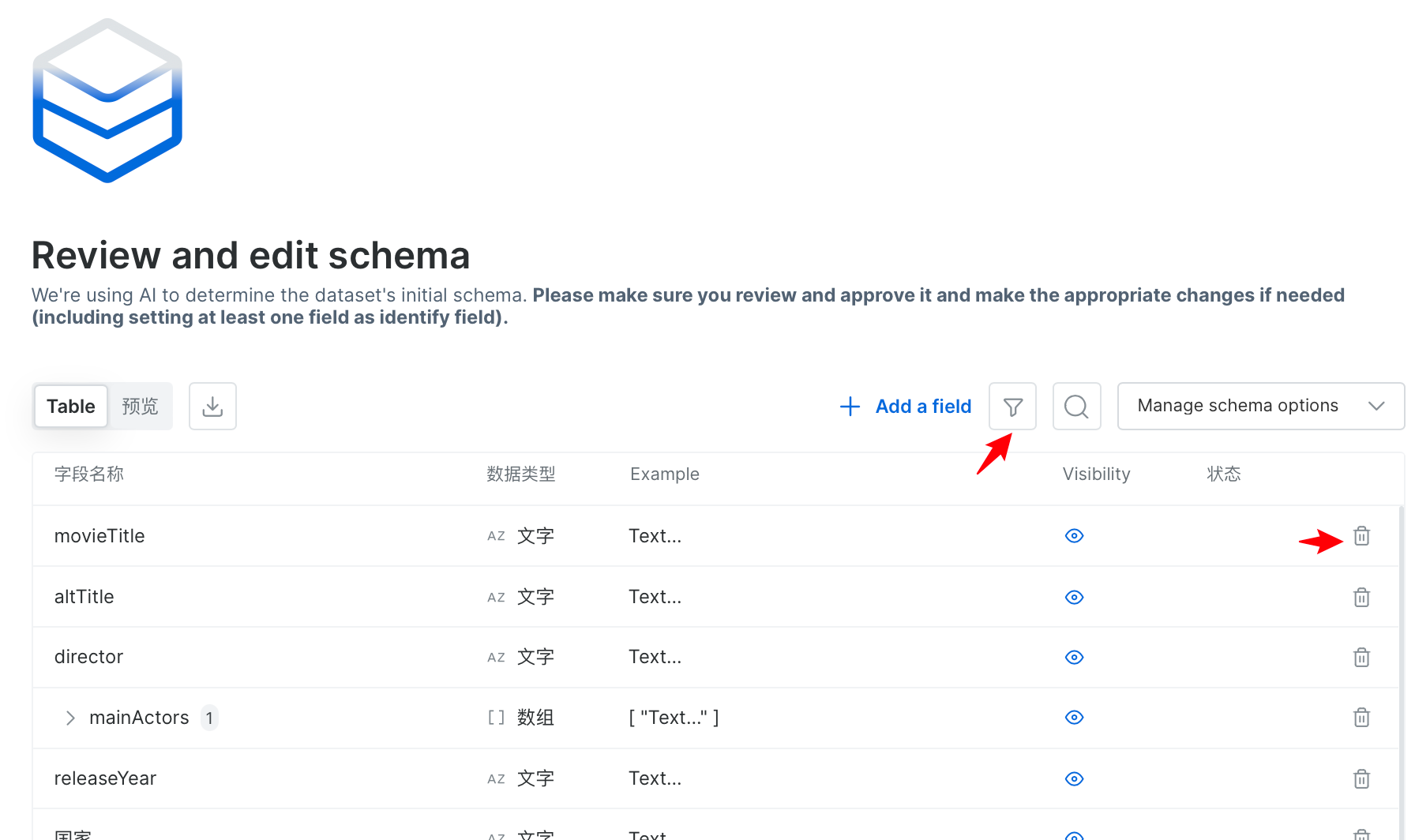
- 等待一定时间,我们可以查看获取数据集的数据字典,其中,可以根据自己的需要可以添加、修改和删除字段或者字段类型。
- 确定表结构没有问题后,我们可以查看数据样例,并且能导出CSV数据。
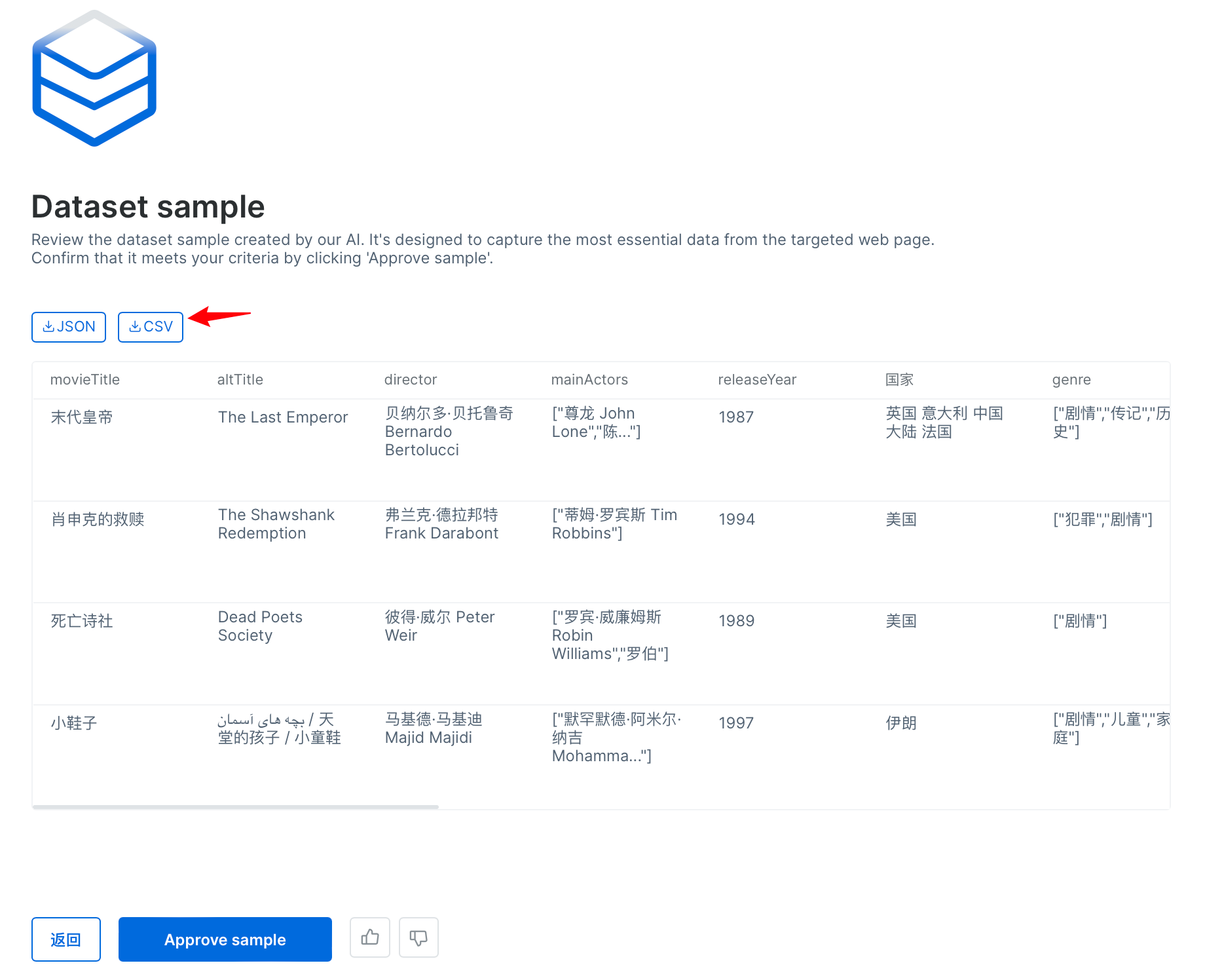
可见,直接根据网址的提示进行操作,非常快速就能获取到自己想要的数据。
3.2 获取IP代理,利用python爬取数据
众所周知,爬虫速度过快,频繁访问都会被封IP,怎么解决这个问题呢?再去换一台设备?先不说数据是否同步,仅仅换个设备的成本就不低,这个时候就需要代理IP了,根据获得的代理IP,直接在python的使用。
1)准备工作
导入本次需要用到的基本模块,以下所有的执行都在这基础上运行。
from bs4 import BeautifulSoup # 用于解析HTML和XML文档
import requests # 爬虫库
import re # 正则库
import pandas as pd # 数据处理库
import times # 防止爬取过快
进入到豆瓣网址,点击不同的页面,可以发现网址URL有如下:
# 第一页
https://book.douban.com/top250?start=0
# 第二页
https://book.douban.com/top250?start=25
# 第三页
https://book.douban.com/top250?start=50
通过观察可以发现,URL后面参数是25的倍数变化,因此可以使用如下代码替代:
# 设置翻页for i in range(10):# 根据每一页的URL规律定义url = 'https://book.douban.com/top250?start=' + str(i*25) + '&filter='print(url)
2)获取网页源码数据
a. 在不使用任何代理情况下,直接模拟浏览器,添加请求头,发起请求。
# 定义获取源码函数
def get_html_info1(url):# 请求头headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}# 发起请求,返回响应对象response = requests.get(url, headers=headers)# 解析网页内容soup = BeautifulSoup(response.text, 'html.parser')# 打印查看信息print(soup)return soup
# 使用该函数
get_html_info1("https://book.douban.com/top250?start=0")
多次请求后出现404!!!
b. 进一步优化,在这里我从 亮数据官方网站中注册获取到的IP,我们使用它进行发起请求,获取数据。
# 定义获取源码函数
def get_html_info2(url):# 请求头headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}# 根据获取到的IP,添加代理proxies = {'http': 'http://brd-customer-hl_93341477-zone-web_unlocker2:ke6rcbba1z0z@brd.superproxy.io:22225','https': 'http://brd-customer-hl_93341477-zone-web_unlocker2:ke6rcbba1z0z@brd.superproxy.io:22225'}# 发起请求,返回响应对象response = requests.get(url, headers=headers,proxies=proxies)# 解析网页内容soup = BeautifulSoup(response.text, 'html.parser')# 打印查看信息print(soup)return soup
# 使用该函数
get_html_info2("https://book.douban.com/top250?start=0")
c. 继续在亮数据中探索发现,平台的亮网络解锁器和亮数据解锁器,只需要将所需要的URL放入,调整通道和地区,爬虫代码无需修改直接可复用。

#!/usr/bin/env python
print('If you get error "ImportError: No module named \'six\'" install six:\n'+\'$ sudo pip install six');
print('To enable your free eval account and get CUSTOMER, YOURZONE and ' + \'YOURPASS, please contact sales@brightdata.com')
import sys
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
if sys.version_info[0]==2:import sixfrom six.moves.urllib import requestopener = request.build_opener(request.ProxyHandler({'http': 'http://brd-customer-hl_93341477-zone-web_unlocker2:ke6rcbba1z0z@brd.superproxy.io:22225','https': 'http://brd-customer-hl_93341477-zone-web_unlocker2:ke6rcbba1z0z@brd.superproxy.io:22225'}))print(opener.open('https://book.douban.com/top250?start=0').read())
if sys.version_info[0]==3:import urllib.requestopener = urllib.request.build_opener(urllib.request.ProxyHandler({'http': 'http://brd-customer-hl_93341477-zone-web_unlocker2:ke6rcbba1z0z@brd.superproxy.io:22225','https': 'http://brd-customer-hl_93341477-zone-web_unlocker2:ke6rcbba1z0z@brd.superproxy.io:22225'}))print(opener.open('https://book.douban.com/top250?start=0').read())
在Pycharm中可以使用示例代码直接爬取源码,不用自己调整任何东西。爬取的源码通常还不能直接使用,需要进一步进行提炼。

可以发现b和c两部分获取数据非常稳定,未出现异常情况,代理IP
2)数据提炼
首先,打开开发者工具查看HTML源码,聚焦选中要定位的元素,可以发现书本信息集中在<div,class="indent"><table></table></div>标签中;
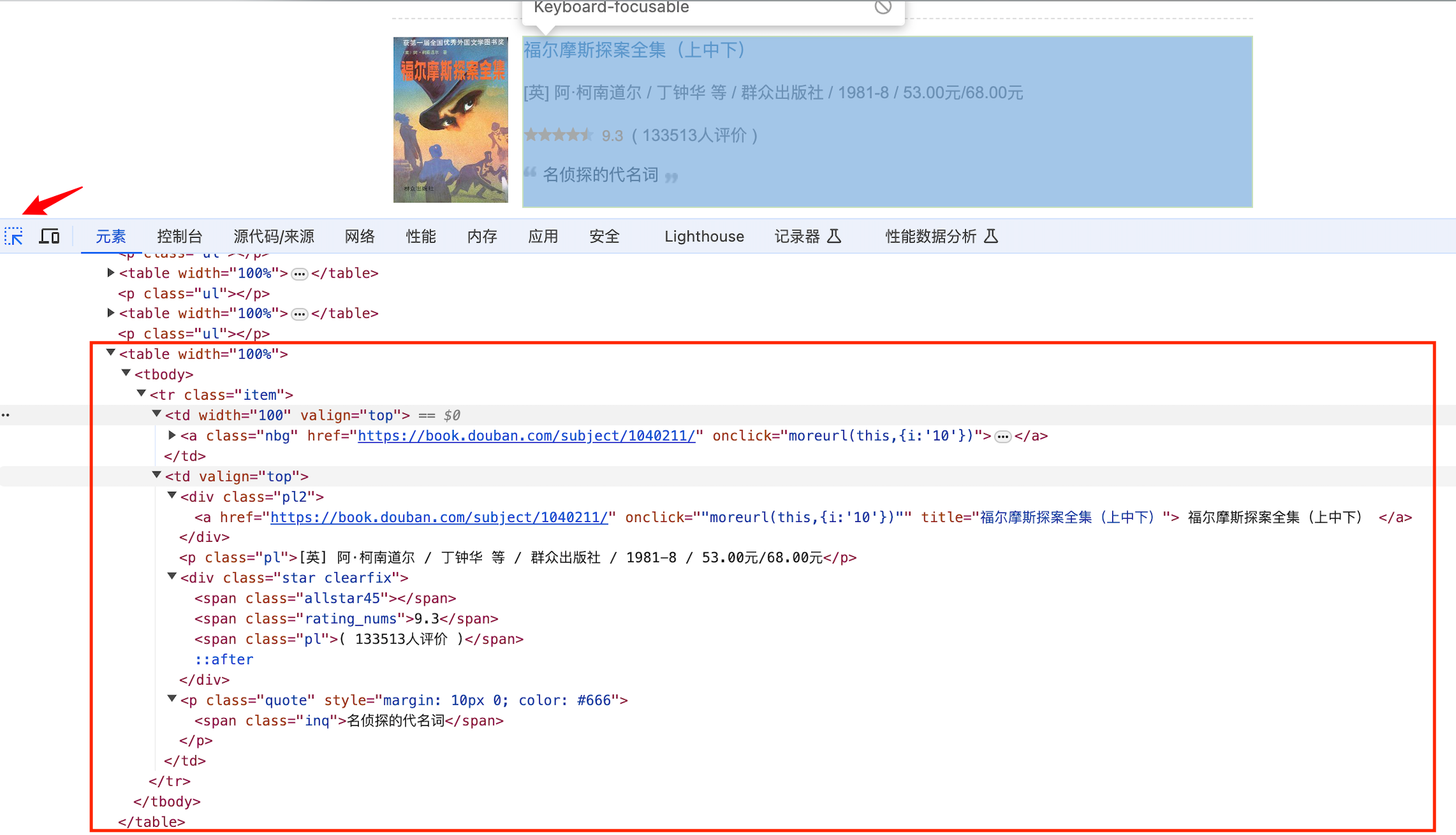

其次,较为复杂的是出版相关的信息,数据有"余华 / 作家出版社 / 2012-8 / 20.00元"、“[英] 阿·柯南道尔 / 丁钟华 等 / 群众出版社 / 1981-8 / 53.00元/68.00元”、“少年儿童出版社 / 1962 / 30.00元”,存在着作者和译者两者其一或都无情况,因此,对数据进行分割时需要分情况处理。创建一个get_data函数用于提炼数据,如下:
def get_data(soup,data_list):# 获取<div,class="indent"><table></table></div>标签中所有的图书信息book_list = soup.find('div', class_='indent').find_all('table')# 遍历图书列表for book in book_list:# 书名:根据<div,class='pl2'><a></a></div>标签提取信息title = book.find('div', class_='pl2').find('a')['title']# 评分:根据<span,class='rating_nums'></span>标签提取信息rating = book.find('span', class_='rating_nums').text# 评价人数:根据<span,class='pl'></span>标签提取信息,正则出需要的数量comment_count = re.search(r'\d+', book.find('span', class_='pl').text).group()# 推荐语:根据<span,class='inq'></span>标签提取信息,如果没有则赋空quote = book.find('span', class_='inq').text if book.find('span', class_='inq') else None# 书本出版相关信息:根据<p,class='pl'></span>标签提取信息publisher_info = book.find('p', class_='pl').text# 作者和译者:并不是所有的图书都有,因此需要根据实际信息分情况处理if publisher_info.count(' / ') == 4:author = publisher_info.split(' / ')[-5].strip()translator = publisher_info.split(' / ')[-4].strip()elif publisher_info.count(' / ') == 2:author = Nonetranslator = Noneelse:author = publisher_info.split(' / ')[-4].strip()translator = None# 出版社:根据提取的出版信息分隔符提取publisher = publisher_info.split(' / ')[-3].strip()# 定价:由于定价存在多种情况,根据提取的出版信息分隔符和正则匹配信息price = re.sub(r'(元)|(CNY\s)|(NT\$)', '', publisher_info.split(' / ')[-1].strip())# 出版年year = publisher_info.split(' / ')[-2].strip().split('-')[0]# 书本链接book_link = book.find('a')['href']# 封面图片链接img_link = book.find('a').find('img')['src']# 打印查看每次获取提炼的信息print({'书名': title, '评分': rating, '评价人数': comment_count, '推荐语': quote, '作者': author, '译者': translator, '出版社': publisher, '出版年': year, '定价': price, '书本链接': book_link, '封面图片链接': img_link})# 将获取的信息合并追加data_list.append({'书名': title, '评分': rating, '评价人数': comment_count, '推荐语': quote, '作者': author, '译者': translator, '出版社': publisher, '出版年': year, '定价': price, '书本链接': book_link, '封面图片链接': img_link})return data_list
# 使用get_html_info1函数获取HTML源码
get_html_info1("https://book.douban.com/top250?start=0")
# 使用get_data函数提炼数据
get_data(soup,data_list)
执行查看打印结果如下:

3)数据导出
数据提炼完成,我们常常需要保存数据或者数据入库,方便查看和其他工具调用,因此,定义数据导出函数如下:
# 定义数据导出CSV函数
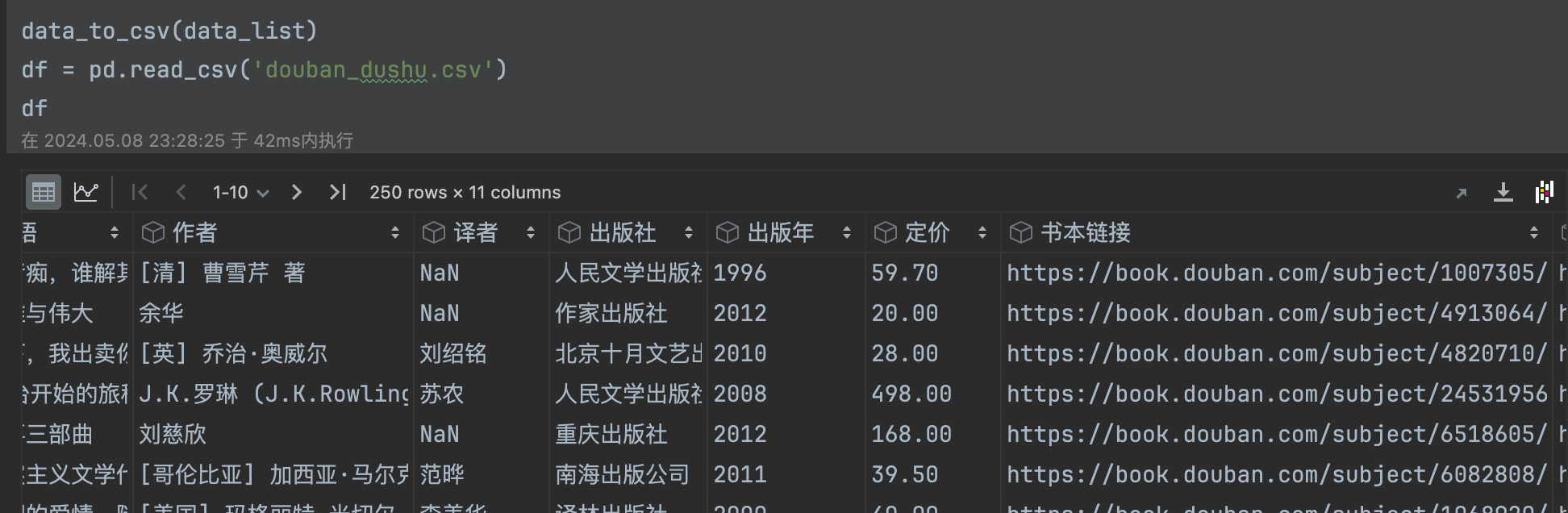
def data_to_csv(data_list):# 创建DataFrame对象df = pd.DataFrame(data_list)# 保存为CSV文件df.to_csv('douban_dushu.csv',index=False)
使用数据导出函数,并且查看数据,可以发现总共获取了11列250行数据。
3.3 数据可视化
数据可视化又可以称为数据解释,主要工作是对数据进行处理,将结果更直观地展现,使复杂的数据更容易理解和使用,在本节中做基本的演示。
1)准备工作
导入数据可视化用到的基本库,读取提取到的数据。
import pandas as pd
from pyecharts import options as opts
from pyecharts.options import ComponentTitleOpts
from pyecharts.charts import Bar, Line # 绘制条形图和线图
from pyecharts.charts import TreeMap # 绘制树形图
from pyecharts.components import Table # 绘制表格
df = pd.read_csv('douban_dushu.csv') # 读取提炼的数据
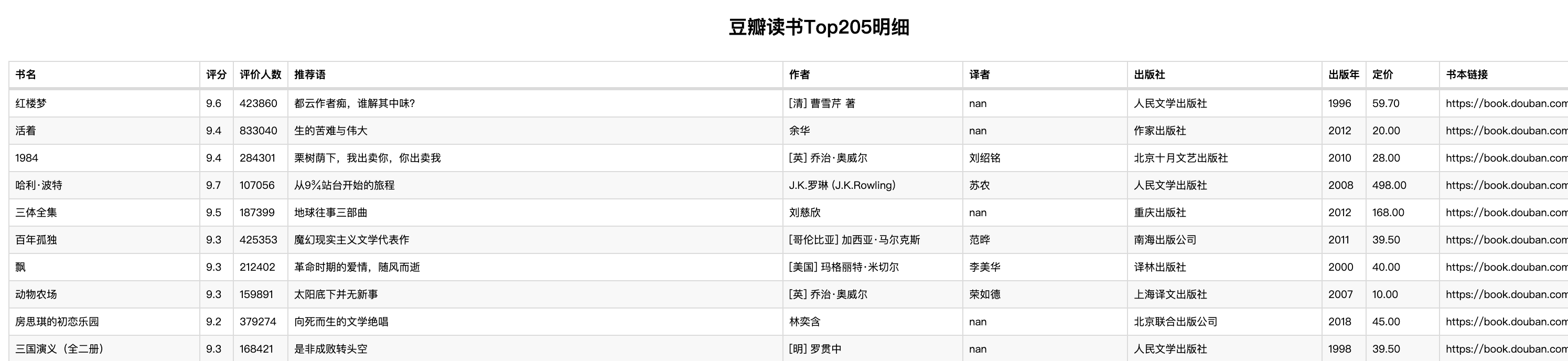
2)做明细表
根据提炼的数据,明细表可以帮助用户高效地查看、编辑和分析详细的数据信息,便于查看和发现问题,图书详情尽在掌握。
table = Table()
headers = df.columns.tolist() # 表列表
rows = [list(row) for row in df.values] # 数据列表
table.add(headers, rows) # 表单中添加表头和数据
table.set_global_opts(title_opts=ComponentTitleOpts(title="豆瓣读书Top205明细") # 添加标题
)
table.render("豆瓣读书Top205明细.html") # 导出HTML查看
3)绘制柱形图
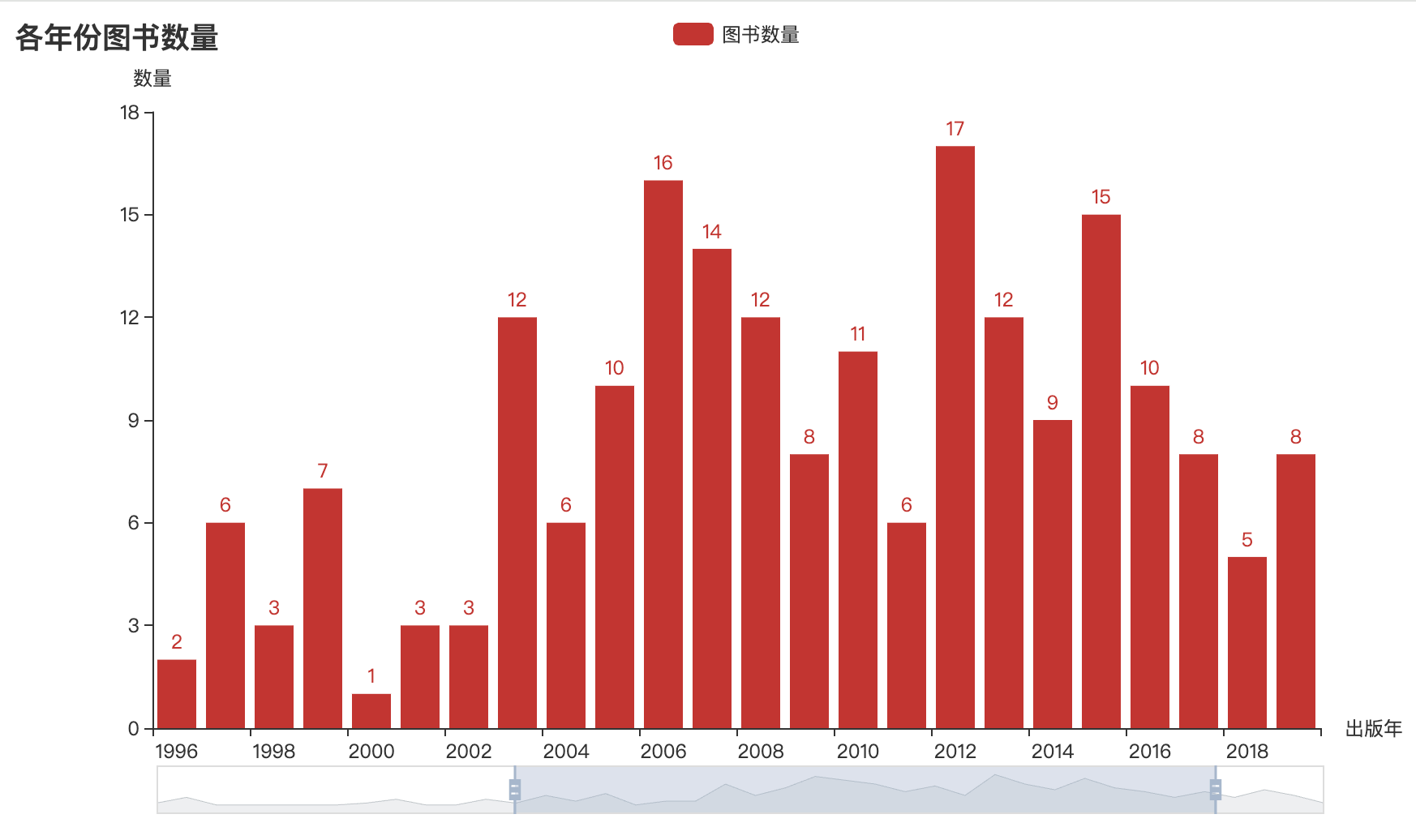
柱形图能更直观地查看和对比不同年份出版的图书情况,因此,我们进一步绘制查看读书Top250中出版年的图书数量变化。
year_counts = df['出版年'].value_counts() # 根据出版年份统计图书数量
year_counts.columns = ['出版年', '数量'] # 汇总的数据定义列名
year_counts = year_counts.sort_index() # 根据数量排序
c = (Bar().add_xaxis(list(year_counts.index)).add_yaxis('图书数量', year_counts.values.tolist()).set_global_opts(title_opts=opts.TitleOpts(title='各年份图书数量'), # 标题yaxis_opts=opts.AxisOpts(name='数量'), # y轴xaxis_opts=opts.AxisOpts(name='出版年'), # x轴datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_='inside')],) # 数据显示位置.render('各年份图书数量.html'))
4)绘制矩形树形图
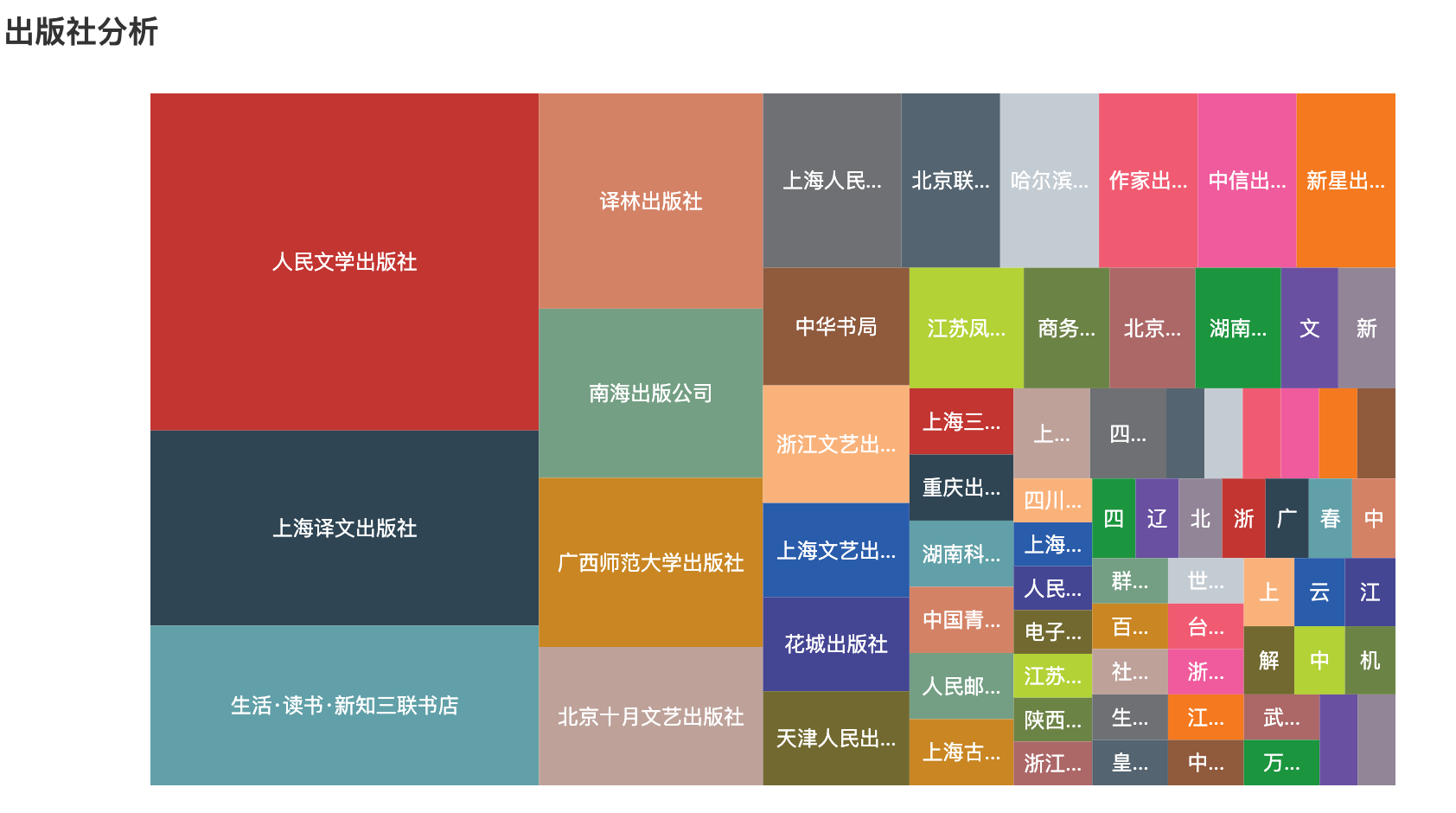
我们可以使用矩形树形图查看不同的出版社出版图书的分布情况。
publisher = df['出版社'].value_counts() # 根据出版社统计图书数量
output_list = [{"value": value, "name": name} for name, value in publisher.items()] # 转化为列表嵌套字段形式
c = (TreeMap().add("", output_list).set_global_opts(title_opts=opts.TitleOpts(title="出版社分析")).render("出版社分析.html")
)
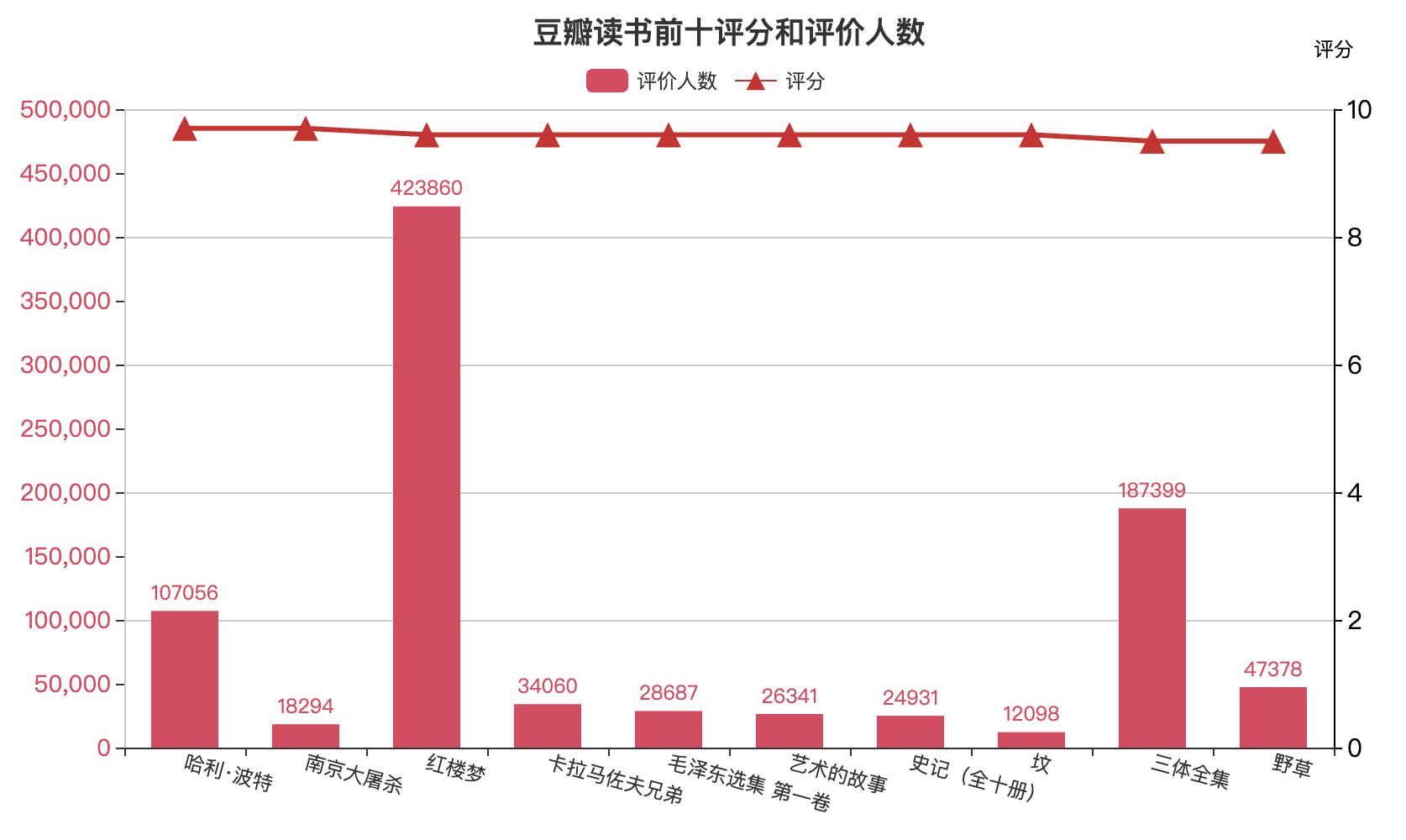
4)绘制组合图
通过明细数据可以看到,图书有评分和评价人数,进一步分析三种的数据情况,在这里我们绘制组合图统一展示:
# 创建bar对象,并制定画布大小
bar = Bar(init_opts=opts.InitOpts(width='1200px',height='300px'))
# 将数据根据评分、评价人数、书名进行升序排列
df3 = df.sort_values(by=['评分','评价人数','书名'],ascending=False)
# 依次将排名前十的三列数据拿出
x_data = df3['书名'].tolist()[:10]
rating = df3['评分'].tolist()[:10]
comment_count = df3['评价人数'].tolist()[:10]
# 柱形图设置
bar = (Bar().add_xaxis(x_data) # x轴.add_yaxis( # y轴系列数据series_name="评价人数",y_axis=comment_count,yaxis_index=0,z=0,color="#d14a61",bar_width=40, ).extend_axis( # 扩展的y轴系列参数配置yaxis=opts.AxisOpts(type_="value", name="评分", name_gap=30, min_=0, max_=10,axislabel_opts=opts.LabelOpts(font_size=15), axisline_opts=opts.AxisLineOpts(linestyle_opts=opts.LineStyleOpts(color="black") ),splitline_opts=opts.SplitLineOpts( is_show=True, linestyle_opts=opts.LineStyleOpts(opacity=1) ),)).set_global_opts( # y轴系列参数配置 yaxis_opts=opts.AxisOpts( name="评价人数", name_gap=60, min_=0, max_=500000, interval=50000, axislabel_opts=opts.LabelOpts(font_size=14), axisline_opts=opts.AxisLineOpts( linestyle_opts=opts.LineStyleOpts(color="blank")),),xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),title_opts=opts.TitleOpts(title="豆瓣读书前十评分和评价人数",pos_left="center",pos_top="top"),legend_opts=opts.LegendOpts(pos_left='40%',pos_bottom='89%'),tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),)
)
# 折线图设置
line = (Line().add_xaxis(x_data).add_yaxis(series_name="评分", y_axis=rating,symbol='triangle',symbol_size=15,yaxis_index=1, color="#aa00ff",label_opts=opts.LabelOpts(is_show=False, font_size=10,font_weight='bold'),linestyle_opts=opts.LineStyleOpts(width=3) )
)
bar.overlap(line).render("豆瓣读书前十评分和评价人数.html")
常见的数据可视化工具主要分为三类:底层程序框架;第三方库;软件工具。在这里使用的是第三方库,主要是使用Python的pyecharts进行了制作,如果想了解更多,可以前往pyecharts官网,当然也可以通过其他软件工具实现,如Tableau、PowerBI等。
4.总结
本文通过基本的案例,介绍了数据分析的基本流程,了解的各部分的职责。数据分析和可视化其实不难,主要是开头难,大多数人常常止步于数据采集,常因采集不到自己所需要的数据而懊恼或者放弃,
因此本文给大家介绍了数据获取的基本方法和可用的工具(亮 数 据 官 网),希望对大家有所帮助,能有更多的时间用于分析,得出有价值的信息,利用数据更好的驱动决策。
相关文章:
数据分析实战:从0到1完成数据获取分析到可视化
文章目录 1.数据分析基本流程1.1 数据采集1.2 数据提炼1.3 数据探索分析 2.数据获取的方法和工具2.1 数据解锁器2.2 爬虫浏览器2.3 数据洞察市场 3.完整案例分析:从数据采集到数据可视化3.1 直接按需定制数据集获取数据3.2 获取IP代理,利用python爬取数据…...

【Spring】深入理解 Spring 中的 ImportSelector、Aware 和 Processor 接口
前言 Spring 框架提供了一系列接口和机制,为开发者提供了灵活、可扩展的编程模型。其中,ImportSelector、Aware 接口以及 Processor 系列接口是非常重要的扩展点,本文将深入探讨它们的设计目的、使用方法以及示例应用。 一、ImportSelector…...
【C语言】strstr函数的使用和模拟
前言 今天给大家带来一个字符串函数,strstr()的使用介绍和模拟实现。 模拟实现这个函数,可以帮助我们更深刻地理解这个函数的功能和提高解决字符串相关问题的能力,有兴趣的话就请往下看吧。 strstr函数介绍 函数功能: strstr函…...
五分钟”手撕“异常
目录 一、什么是异常 二、异常的体系和分类 三、异常的处理 1.抛出异常 2.异常的捕获 异常声明throws: try-catch处理 四、finally finally一定会被执行吗? 五、throw和throws区别 六、异常处理的流程 七、自定义异常 一、什么是异常 顾名…...

【vue3+elementuiplus】el-select下拉框会自动触发校验规则
场景:编辑弹框省份字段下拉框必填,触发方式change,有值第一次打开不会触发校验提示,关闭弹框再次打开触发必填校验提示,但是该字段有值 问题的原因是:在关闭弹层事件中,我做了resetfileds&…...
【论文复现】LSTM长短记忆网络
LSTM 前言网络架构总线遗忘门记忆门记忆细胞输出门 模型定义单个LSTM神经元的定义LSTM层内结构的定义 模型训练模型评估代码细节LSTM层单元的首尾的处理配置Tensorflow的GPU版本 前言 LSTM作为经典模型,可以用来做语言模型,实现类似于语言模型的功能&am…...

目标检测YOLO实战应用案例100讲-【自动驾驶】激光雷达
目录 前言 算法原理 测距方法 发射单元 接收单元 扫描单元...

用C语言设计轨道电机的驱动库
一、设计目的 设计能驱动立体轨道电机的抽象驱动程序库。 二、设计要求 命名规范。设计简单,方便使用。体积小。满足电机的移动、停止、初始化、恢复等控制,甚至通过网络控制。 三、设计内容 (一)属性封装 1、定义配置结构体 // 用于配置参数 typed…...

HTML跳动的爱心
目录 写在前面 HTML简介 跳动的爱心 代码分析 运行结果 推荐文章 写在后面 写在前面 哎呀,这是谁的小心心?跳得好快吖! HTML简介 老生常谈啦,咱们还是从HTML开始吧! HTML是超文本标记语言(Hyper…...
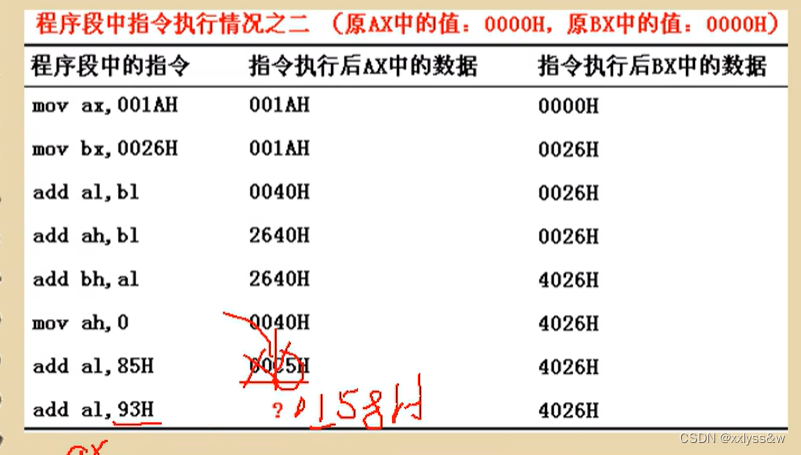
汇编原理(二)
寄存器:所有寄存器都是16位(0-15),可以存放两个字节 AX,BX,CX,DX存放一般性数据,称为通用寄存器 AX的逻辑结构。最大存放的数据为2的16次方减1。可分为AH和AL,兼容8位寄存器。 字:1word 2Byte…...

Android Studio开发之路(十三)主题影响Button颜色问题解决及button自定义样式
一、问题描述 在开发过程中发现安卓的默认主题色是紫色,并且会导致button也是紫色,有时直接在xml布局文件中直接设置button的背景色或者设置背景图片不起效果 方案一、如果是app,可以直接设置主题颜色 比如,将主题设置为白色&a…...

eNSP学习——OSPF单区域配置
目录 相关命令 实验背景 实验目的 实验步骤 实验拓扑 实验编址 实验步骤 1、基础配置 2、部署单区域OSPF网络 3、检查OSPF单区域的配置结果 OSPF——开放式最短路径优先 基于链路状态的协议,具有收敛快、路由无环、扩展性好等优点; 相关命令 […...

深度学习中的优化算法二(Pytorch 19)
一 梯度下降 尽管梯度下降(gradient descent)很少直接用于深度学习,但了解它是理解下一节 随机梯度下降算法 的关键。例如,由于学习率过大,优化问题可能会发散,这种现象早已在梯度下降中出现。同样地&…...

R实验 方差分析
实验目的: 掌握单因素方差分析的思想和方法; 掌握多重均值检验方法; 掌握多个总体的方差齐性检验; 掌握Kruskal-Wallis秩和检验的思想和方法; 掌握多重Wilcoxon秩和检验的思想和方法。 实验内容: &…...

AI智能体|手把手教你使用扣子Coze图像流的文生图功能
大家好,我是无界生长。 AI智能体|手把手教你使用扣子Coze图像流的文生图功能本文详细介绍了Coze平台的\x26quot;图像流\x26quot;功能中的\x26quot;文生图\x26quot;节点,包括创建图像流、编排文生图节点、节点参数配置,并通过案例…...

应用程序图标提取
文章目录 [toc]提取过程提取案例——提取7-zip应用程序的图标 提取过程 找到需要提取图标的应用程序的.exe文件 复制.exe文件到桌面,并将复制的.exe文件后缀改为.zip 使用解压工具7-zip解压.zip文件 在解压后的文件夹中,在.rsrc/ICON路径下的.ico文件…...

Excel表格在线解密:轻松解密密码,快速恢复数据
忘记了excel表格密码?教你简单两步走:具体步骤如下。首先,在百度搜索中键入“密码帝官网”。其次,点击“立即开始”,在用户中心上传表格文件即可找回密码。这种方法不用下载软件,操作简单易行,适…...
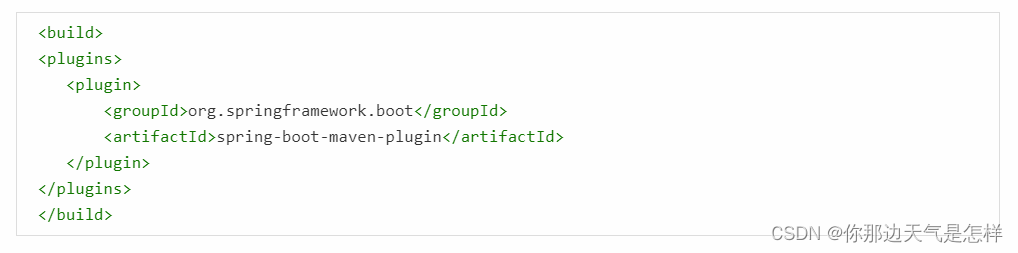
springboot小结1
什么是springboot Spring Boot是为了简化Spring应用的创建、运行、调试、部署等而出现的,使用它可以做到专注于Spring应用的开发,而无需过多关注XML的配置。 简单来说,它提供了一堆依赖打包Starter,并已经按照使用习惯解决…...

【Qt 学习笔记】Qt窗口 | 菜单栏 | QMenuBar的使用及说明
博客主页:Duck Bro 博客主页系列专栏:Qt 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ Qt窗口 | 菜单栏 | QMenuBar的使用及说明 文章编号:Qt 学习…...

Spark运行模式详解
Spark概述 Spark 可以在多种不同的运行模式下执行,每种模式都有其自身的特点和适用场景。 部署Spark集群大体上分为两种模式:单机模式与集群模式。大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。但是在生产环境中ÿ…...
)
DeepSeek模型越狱攻击实录与反制(2024最新0day漏洞封堵手册)
更多请点击: https://kaifayun.com 第一章:DeepSeek模型安全加固概述 DeepSeek系列大语言模型在开源生态中广泛应用,但其默认部署配置存在若干潜在安全风险,包括未授权API访问、提示注入攻击面暴露、敏感信息泄露通道及权重文件未…...

【ChatGPT移动端实战指南】:20年AI工程师亲测的5大隐藏技巧,90%用户从未用过
更多请点击: https://intelliparadigm.com 第一章:ChatGPT移动端使用体验 在 iOS 和 Android 平台上,官方 ChatGPT 应用已全面支持语音输入、多轮上下文保持与离线提示缓存,显著优化了通勤、会议间隙等碎片化场景下的交互效率。…...

智能体系统设计简明教程
曾经有一段时间,软件系统大多在等待。 它们等待请求,等待输入,等待工程师已经知道系统应该执行的操作序列而编写的明确指令。 即使是大规模分布式系统,在很大程度上也是在同一个假设下运行的。复杂性来自于规模、并发和协调——…...

集成学习驱动的智能黑盒测试:基于模型分歧的用例生成方法
1. 项目概述与核心价值在软件开发的漫长周期里,测试环节始终是保障质量、控制风险的关键闸口。然而,无论是手动编写测试用例,还是依赖传统的自动化脚本,都面临着效率瓶颈和覆盖度不足的挑战。尤其是在面对复杂的黑盒系统时&#x…...

【AI视频生成工具学习曲线深度报告】:20年AI工程经验总结的5大认知断层与30天速通路径
更多请点击: https://codechina.net 第一章:AI视频生成工具学习曲线的本质解构 AI视频生成工具的学习曲线并非线性陡峭的“技术门槛”,而是一组相互耦合的认知域跃迁过程——涵盖提示工程直觉、时序一致性理解、跨模态对齐敏感度以及算力-质…...

YOLOv11农田烟草叶片病害目标检测数据集-470张-tobacco-plant-1
YOLOv11农田烟草叶片病害目标检测数据集 📊 数据集基本信息 目标类别: [‘Black shank’, ‘Healthy Leaf’, ‘Tobacco leaf curl disease -TLCD-’, ‘Tobacco mosaic virus -TMV-’, ‘brown sport’, ‘frogeye leaf spot’]中文类别:[‘…...

GetQzonehistory:如何通过开源工具实现QQ空间数据主权迁移?
GetQzonehistory:如何通过开源工具实现QQ空间数据主权迁移? 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字资产管理领域,数据主权已成为个人用…...

长期使用 Taotoken Token Plan 套餐对于项目运营成本的实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用 Taotoken Token Plan 套餐对于项目运营成本的实际感受 1. 从按次计费到订阅套餐的转变 在项目初期,我们通常…...

随机森林与Bagging回归器在农业产量时序预测中的集成学习应用
1. 项目概述与核心价值在农业领域,精准预测作物产量从来都不是一个简单的数学问题,它直接关系到从田间地头到国家粮仓的资源配置效率。过去,我们更多地依赖农艺师的经验和简单的历史平均数据,但面对日益复杂的气候变化和市场波动&…...

解锁音乐自由:3分钟掌握QQ音乐加密音频无损解密技巧 [特殊字符]
解锁音乐自由:3分钟掌握QQ音乐加密音频无损解密技巧 🎵 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾为QQ音乐下载的歌曲只能在特定播放器…...