一、Elasticsearch介绍与部署
目录
一、什么是Elasticsearch
二、安装Elasticsearch
三、配置es
四、启动es
1、下载安装elasticsearch的插件head
2、在浏览器,加载扩展程序
3、运行扩展程序
4、输入es地址就可以了
五、Elasticsearch 创建、查看、删除索引、创建、查看、修改、删除文档、映射关系
1、索引操作
1.1、创建索引
1.2、查看指定索引
1.3、查看全部索引 _cat/indices?v
1.4、删除索引
2、文档操作
2.1、创建文档
2.2、查询单个文档:主键id查询
2.3、查看所有文档:全量查询
2.4、修改文档中的全部字段
2.5、修改文档某一个字段
2.6、条件查询文档内容
2.7、分页查询和排序文档内容
2.8、多条件查询 and
2.9、多条件查询 or
2.10、多条件查询 :大于 小于
2.11、聚合查询 根据价格分组、对价格求平均值
3、映射操作
六、创建分片索引
七、故障转移
八、水平扩容
一、什么是Elasticsearch
是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索搜索、支持分布式可实现高可用、提供API接口,可以处理大规模日志数据,比如:Nginx 、Tomcat、系统日志等功能 。
bin 可执行脚本目录
config 配置目录
jdk 内置 JDK 目录(ES是采用Java语言开发的)
lib 类库
logs 日志目录
modules 模块目录
plugins 插件目录
解后,进入 bin 文件目录,点击 elasticsearch.bat 文件启动 ES 服务。
二、安装Elasticsearch
1、下载es安装包
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
2、使用rz命令上传至服务器别解压
3、使用tcp命令传值另外两个服务器
4、创建es用户
useradd elasticsearch
5、创建数据目录
[root@rabbitmq_2 es]# mkdir es_data
6、创建日志目录
[root@rabbitmq_2 es]# mkdir es_log
7、配置elasticsearch文件权限
chown -R elasticsearch:elasticsearch /home/es/elasticsearch-7.8.0
chown -R elasticsearch:elasticsearch /home/es/es_data
chown -R elasticsearch:elasticsearch /home/es/es_log
6、出现这个错误 max virtual memory areas vm.max_map_count [65530] is too low,
vim /etc/sysctl.conf
添加这个,保存退出,刷新
vm.max_map_count=262144
[root@rabbitmq_2 es]# sysctl -p
vm.max_map_count = 262144
8、这个错误 max file descriptors [4096] for elasticsearch process is too low
vim /etc/security/limits.conf
# End of file
elasticsearch soft nofile 65535
elasticsearch hard nofile 65535
保存退出三、配置es
[elasticsearch@rabbitmq_1 config]$ vim elasticsearch.yml
cluster.name: my-application
node.name: node-1
node.master: true //当前节点可以是master节点、也可以是数据节点
node.data: true
path.data: /home/es/es_data
path.logs: /home/es/es_log
network.host: 0.0.0.0
http.port: 9200
//用来查找集群节点的模块
discovery.seed_hosts: ["192.168.134.132", "192.168.134.133"]
// 集群内可以被选为主节点的节点列表
cluster.initial_master_nodes: ["node-1"]
//跨域配置
http.cors.enabled: true
http.cros.allow-origin: "*"如果是ES集群的话,只需要把边配置文件scp到其他节点即可
[elasticsearch@rabbitmq_1 config]$ vim elasticsearch.yml
cluster.name: my-application
node.name: node-2
node.master: true //当前节点可以是master节点、也可以是数据节点
node.data: true
path.data: /home/es/es_data
path.logs: /home/es/es_log
network.host: 0.0.0.0
http.port: 9200
//用来查找集群节点的模块,节点发现,有几个机器就写几个
discovery.seed_hosts: ["192.168.134.132", "192.168.134.133"]
// 集群内可以被选为主节点的节点列表
cluster.initial_master_nodes: ["node-1"]
//跨域配置
http.cors.enabled: true
http.cros.allow-origin: "*"四、启动es
因为安全问题,es不允许使用root 启动,所以需要创建es用户
useradd elasticsearch //创建用户
passwd 123456 //设置密码
//授权
chown -R elasticsearch:elasticsearch /path/to/elasticsearch
//切换用户
su - elasticsearch[root@rabbitmq_2 bin]# sudo -u elasticsearch ./elasticsearch
[elasticsearch@rabbitmq_1 bin]$ ./elasticsearch
后台启动 街上 -d
有这一行表示启动成功
[node-1] Active license is now [BASIC]; Security is disabled
[elasticsearch@rabbitmq_1 bin]$ ./elasticsearch -d
然后去浏览器查看
http://192.168.134.132:9200/
{"name" : "node-1","cluster_name" : "my-application","cluster_uuid" : "VI1zyRs3TRu3MDBGxrPh5w","version" : {"number" : "7.8.0","build_flavor" : "default","build_type" : "tar","build_hash" : "757314695644ea9a1dc2fecd26d1a43856725e65","build_date" : "2020-06-14T19:35:50.234439Z","build_snapshot" : false,"lucene_version" : "8.5.1","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"
}
监控elasticsearch集群服务器的健康性
用curl命令对集群的健康性状态进行检查,如果返回值是green,说明正常,是yellow,说明是副本的分片丢失,如果是red,表示主片丢失。
[elasticsearch@rabbitmq_1 es_data]$ curl -sXGET http://192.168.134.132:9200/_cluster/health?pretty=true
{"cluster_name" : "my-application","status" : "green","timed_out" : false,"number_of_nodes" : 1,"number_of_data_nodes" : 1,"active_primary_shards" : 0,"active_shards" : 0,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}1、下载安装elasticsearch的插件head
地址:https://github.com/mobz/elasticsearch-head/raw/master/crx/es-head.crx
将下载好的es-head.crx 改为 es-head.rar,然后解压,解压后的目录
2、在浏览器,加载扩展程序

3、运行扩展程序
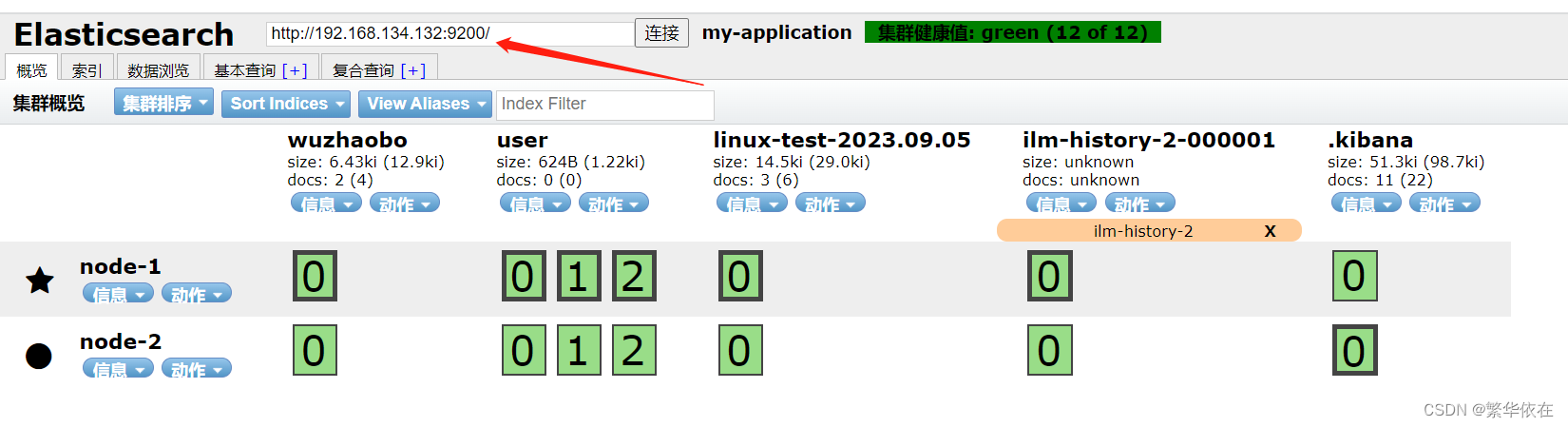
4、输入es地址就可以了
五、Elasticsearch 创建、查看、删除索引、创建、查看、修改、删除文档、映射关系
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比。
ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个 type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
索引的精髓:一切设计为了提高搜索性能
1、索引操作
1.1、创建索引
在ES中创建一个索引,就相当于在mysql中创建了一个数据库,而mysql中的数据库肯定是不能重复的,也即ES中的索引也不能重复,所以这是一个幂等性操作,需要发送PUT请求(如果重复发送PUT请求、重复添加索引,会返回错误信息),这里不能发送POST请求。

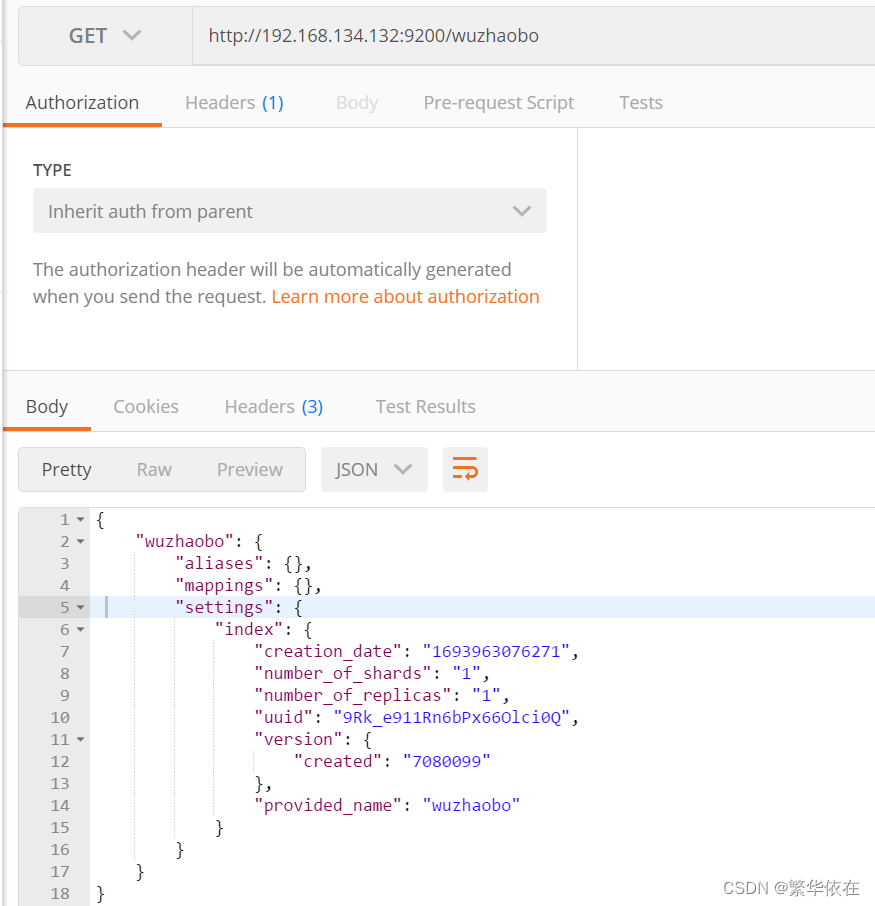
1.2、查看指定索引
在postman中,向ES服务器发送GET请求。这里的路径和上边的创建索引是一样的,只是请求方式不一样
1.3、查看全部索引 _cat/indices?v
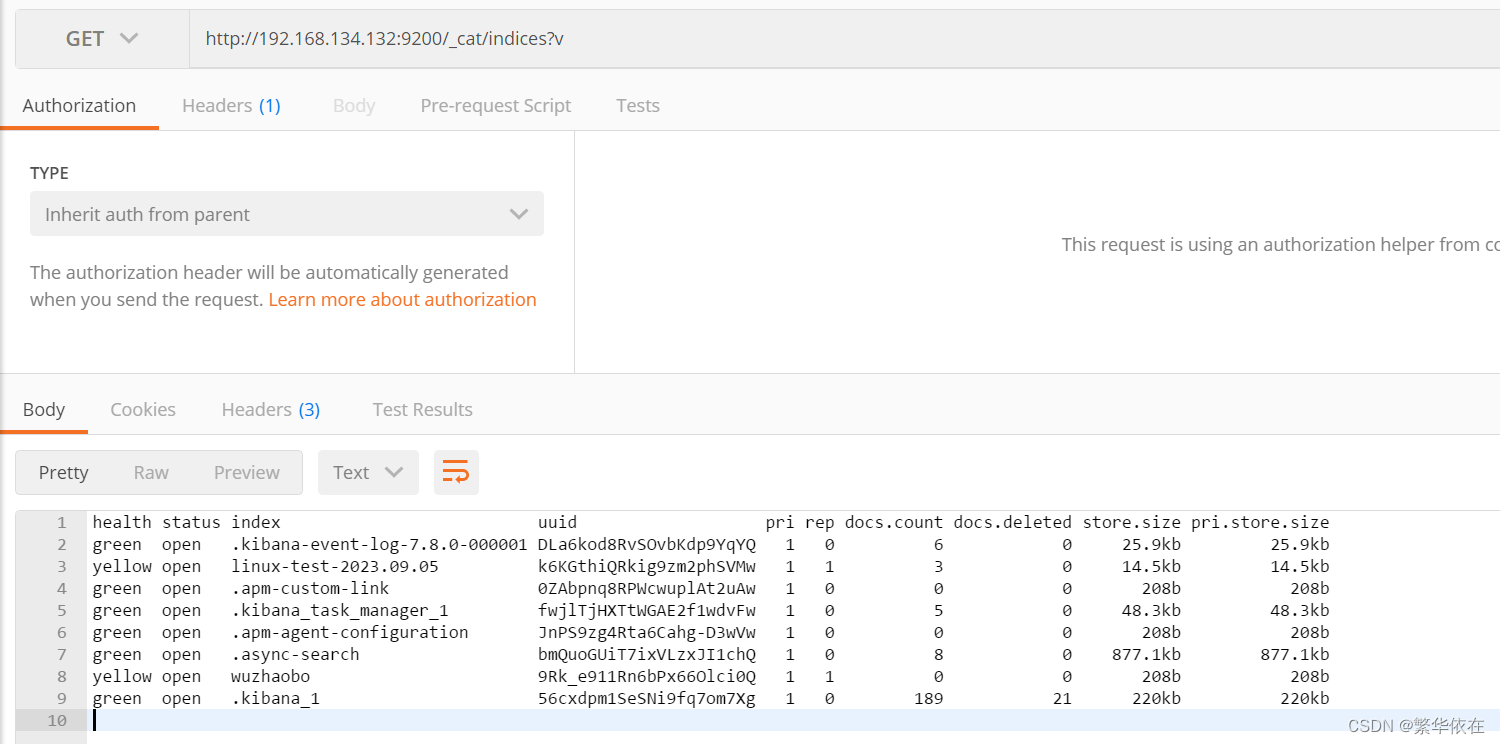
在 Postman 中,向 ES 服务器发 GET 请求。
http://192.168.134.132:9200/_cat/indices?v
health 当前服务器健康状态:green(集群完整) yellow(单点正常、集群不完整) red(单点不正常)
status 索引打开、关闭状态
index 索引名
uuid 索引统一编号
pri 主分片数量
rep 副本数量
docs.count 可用文档数量
docs.deleted 文档删除状态(逻辑删除)
store.size 主分片和副分片整体占空间大小
pri.store.size 主分片占空间大小
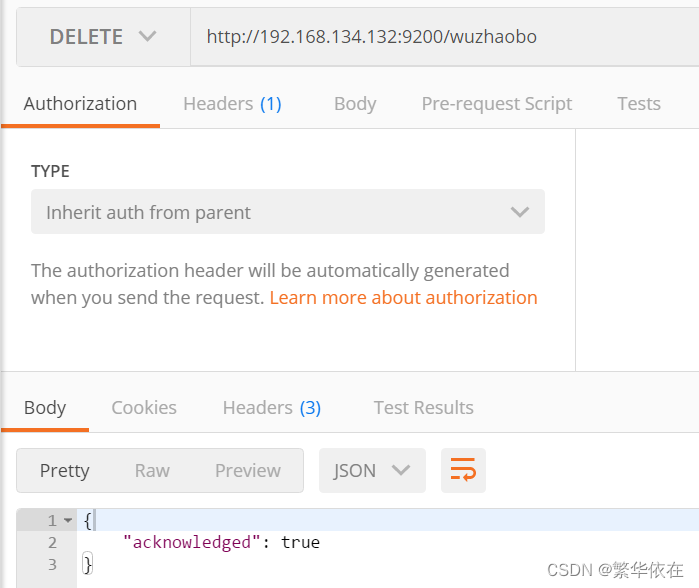
1.4、删除索引
在 Postman 中,向 ES 服务器发 DELETE 请求。
2、文档操作
2.1、创建文档
索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式 。在 Postman 中,向 ES 服务器发 POST 请求。
http://192.168.134.132:9200/wuzhaobo/_doc
请求体
{"title":"小米手机","category":"小米","image":"http://www.szh.com/szh.jpg","price":3999.00
}
返回
{"_index": "wuzhaobo","_type": "_doc","_id": "7E4haIoB8mJ8_ZzJqBEe","_version": 1,"result": "created","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1
}
上面的数据创建后,由于没有指定数据唯一性标识(ID),默认情况下,ES 服务器会随机生成一个。
如果想要自定义唯一性标识,需要在创建时指定。推荐使用下面这种方式创建文档。
http://192.168.134.132:9200/wuzhaobo/_doc/1002
请求体和不变2.2、查询单个文档:主键id查询
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询。在 Postman 中,向 ES 服务器发 GET 请求。
请求地址:http://192.168.134.132:9200/wuzhaobo/_doc/1002
返回:
{"_index": "wuzhaobo","_type": "_doc","_id": "1002","_version": 1,"_seq_no": 1,"_primary_term": 1,"found": true,"_source": {"title": "小米手机","category": "小米","image": "http://www.szh.com/szh.jpg","price": 3999}
}2.3、查看所有文档:全量查询
"query":这里的query代表一个查询对象,里边有不通的查询属性
"match_all":查询类型,例如:match_all(代表查询所有),match、term、range等等
1、查询所有文档
GET 请求地址:http://192.168.134.132:9200/wuzhaobo/_search"hits": [{"_index": "wuzhaobo","_type": "_doc","_id": "7E4haIoB8mJ8_ZzJqBEe","_score": 1,"_source": {"title": "小米手机","category": "小米","image": "http://www.szh.com/szh.jpg","price": 3999}},{"_index": "wuzhaobo","_type": "_doc","_id": "1002","_score": 1,"_source": {"title": "小米手机","category": "小米","image": "http://www.szh.com/szh.jpg","price": 3999}}]2.4、修改文档中的全部字段
修改数据时,也可以只修改某一给条数据的局部信息,也可以修改所有字段信息。
修完完之后,再次发送GET请求,查看修改后的文档内容。
PUT 请求地址:http://192.168.134.132:9200/wuzhaobo/_doc/1002
请求体
{"title":"华为手机","category":"华为","images":"http://www.szh.com/szh.jpg","price":2400.00
}
返回
{"_index": "wuzhaobo","_type": "_doc","_id": "1002","_version": 2,"result": "updated","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 2,"_primary_term": 1
}2.5、修改文档某一个字段
使用post请求:http://192.168.134.132:9200/wuzhaobo/_doc/1002
请求体
{"title":"苹果手机","category":"苹果",
}2.6、条件查询文档内容
http://192.168.134.132:9200/wuzhaobo/_search?q=category:苹果
上边这个容易乱码,建议使用请求体查询
GET请求地址:http://192.168.134.132:9200/wuzhaobo/_search
请求体:
{"query" :{"match" : {"category" : "苹果"}}
}
2.7、分页查询和排序文档内容
默认情况下,Elasticsearch 在搜索的结果中,会把文档中保存在_source 的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source 的过滤
sort 可以让我们按照不同的字段进行排序,并且通过 order 指定排序的方式。desc 降序,asc 升序。
from:当前页的起始索引,默认从 0 开始。 // (页码-1)*每页条数, 第一页:(1-1)*2=0, 第二页:(2-1)*2=2
size:每页显示多少条。
GET 请求地址:http://192.168.134.132:9200/wuzhaobo/_search
请求体
{"query" :{"match_all" : {}},"from" : 0, //分页,"size" : 2,"_source" : ["title","price"], //过滤 只显示这两个参数"sort" : { //排序"price" : {"order" : "desc"}}
}
2.8、多条件查询 and
bool把各种其它查询通过must(必须 and )、must_not(必须不)、should(应该 or)的方式进行组合 。
GET请求地址:http://192.168.134.132:9200/wuzhaobo/_search
请求体:
{"query" :{"bool" : {"must" : [{"match" : {"category" : "小米"}},{"match" : {"price": 3999}}]}}
}2.9、多条件查询 or
bool把各种其它查询通过 must(必须 and )、must_not(必须不)、should(应该 or)的方式进行组合 。
GET请求地址:http://192.168.134.132:9200/wuzhaobo/_search
请求体:
{"query" :{"bool" : {"should" : [{"match" : {"category" : "小米"}},{"match" : {"price": 3999}}]}}
}2.10、多条件查询 :大于 小于
range 查询找出那些落在指定区间内的数字或者时间。range 查询允许以下字符:
gt 大于> gte 大于等于 >= lt 小于 < lte 小于等于 <=
请求地址:http://192.168.134.132:9200/wuzhaobo/_search
请求体:
{"query" :{"bool" : {"must" : [{"match" : {"category" : "小米"}}],"filter" : { //过滤"range" : {"price" : {"gt" : 3000,"lt" : 4000}}}}}
}2.11、聚合查询 根据价格分组、对价格求平均值
对某个字段取最大值 max
对某个字段取最小值 min
对某个字段求和 sum
对某个字段取平均值 avg
对某个字段的值进行去重之后再取总数 distinct
分组
{"aggs" : { //聚合操作"price_group" : { //名称,自定义"terms" : { //分组、关键字"field" : "price" //分组字段}}},"size" : 0
}
价格平均值
{"aggs" : {"fenzu" : {"avg" : {"field" : "price"}}},"size" : 0
}
价格最大值
{"aggs" : {"fenzu" : {"max" : {"field" : "price"}}},"size" : 0
} 3、映射操作
有了索引库,等于有了数据库中的 database。
接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
type:类型,Elasticsearch 中支持的数据类型非常丰富,说几个关键的:
String 类型,又分两种: text:可分词 keyword:不可分词,数据会作为完整字段进行匹配
Numerical:数值类型,分两类 基本数据类型:long、integer、short、byte、double、float、half_float 浮点数的高精度类型:scaled_float
Date:日期类型
Array:数组类型
Object:对象
index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。
true:字段会被索引,则可以用来进行搜索
false:字段不会被索引,不能用来搜索
store:是否将数据进行独立存储,默认为 false
原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置"store": true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置
analyzer:分词器,这里的 ik_max_word 即使用 ik 分词器
首先是 http://127.0.0.1:9200/user ,发送PUT请求,创建一个user索引,然后在这个索引下创建一个映射。
就类似于在mysql中创建一个名为 user 的数据库,在这个数据库中定义一张表的结构如下:👇👇👇
text 类型为true表示 name 字段可以支持 分词、拆解 操作的查询;而 keyword 类型为true表示 sex 字段仅支持完全匹配的模式;最后 keyword 类型为false表示 tel 字段不支持查询。
1、先创建一个索引
PUT请求地址:http://192.168.134.132:9200/user
然后在索引下创建映射
POST地址:http://192.168.134.132:9200/user/_mapping
{"properties" : {"name" : {"type" : "text","index" : true},"sex" : {"type" : "keyword","index" : true},"tel" : {"type" : "keyword","index" : false}}
}
返回 :
{"acknowledged": true
}
索引有了,映射也有了(数据库有了,表结构有了,就差向表中添加数据了),也就是需要添加文档内容。
post请求地址:http://192.168.134.132:9200/user/_doc/1001
请求体:
{"name" : "吴兆波","sex" : "man","tel" : "11111111"
}
查询:get 请求地址:http://192.168.134.132:9200/user/_doc/1001
{"_index": "user","_type": "_doc","_id": "1001","_version": 1,"_seq_no": 0,"_primary_term": 1,"found": true,"_source": {"name": "吴兆波","sex": "man","tel": "11111111"}
}
因为name字段是支持text模式查询,即支持分词、拆解操作,做倒排索引,所以虽然文档中的name字段为张起灵,但是经过分词拆解,name为徐、凤、年、凤年 这几种都可以查询出数据。查询:get 请求地址:http://192.168.134.132:9200/user/_doc/1001
{"query" : {"match" : {"name" : "兆"}}
}
由于 sex 字段不支持text分词拆解,仅支持keyword完全匹配的模式,所以源文档数据中 sex 为 man,这里只写个 m 是查询不到的。
最后的tel字段是最苛刻的,压根不支持text、keyword两种查询,所以这里就算是写成和文档中的 tel 一样,也查询不到,因为 tel 字段不支持查询。六、创建分片索引
PUT请求地址:http://192.168.134.132:9200/user
请求体
{"settings" : {"number_of_shards" : "3", //3个分片"number_of_replicas" : "1" // 1个副本}
}
返回:
{"acknowledged": true,"shards_acknowledged": true,"index": "user"
}
去kibana 浏览器,就能看到创建的这个索引七、故障转移
因为在master上创建分片索引和副本之后,没有分配到其他节点,如果master宕机,存在数据丢失风险,所以需要启动节点2,副本会自动转移到节点2上,实现了故障转移
八、水平扩容
如果在使用过程中,容量不够了,就需要扩容,来启动节点3,
原则就是:1、主和副本是不能放在一起的 2、一定要保证均匀、让每个节点都能均匀的得到请求和访问
node1和node2上各有1个分片被迁移到node3上,现在每个节点都有2个分片,这样性能也得到了提升
相关文章:
一、Elasticsearch介绍与部署
目录 一、什么是Elasticsearch 二、安装Elasticsearch 三、配置es 四、启动es 1、下载安装elasticsearch的插件head 2、在浏览器,加载扩展程序 3、运行扩展程序 4、输入es地址就可以了 五、Elasticsearch 创建、查看、删除索引、创建、查看、修改、删除文档…...
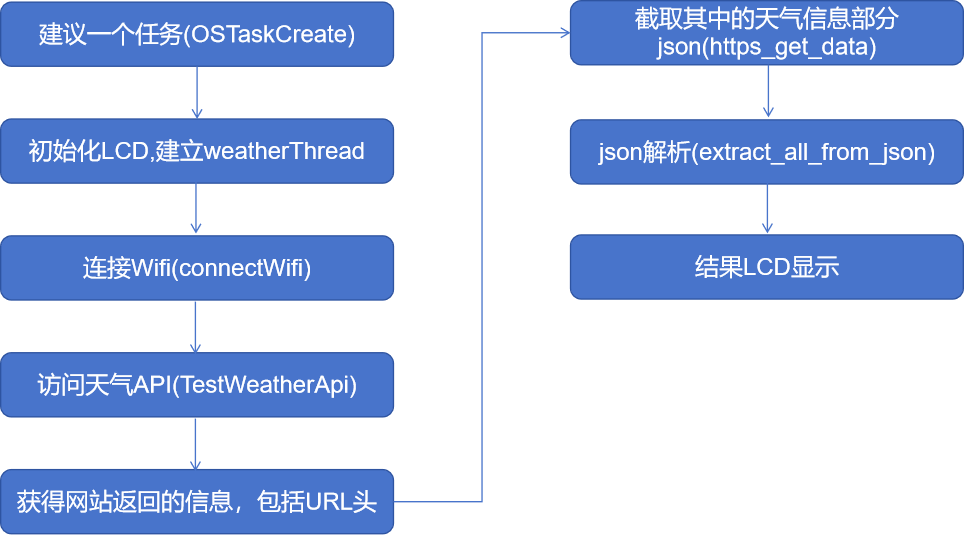
NL6621 实现获取天气情况
一、主要完成的工作 1、建立TASK INT32 main(VOID) {/* system Init */SystemInit();OSTaskCreate(TestAppMain, NULL, &sAppStartTaskStack[NST_APP_START_TASK_STK_SIZE -1], NST_APP_TASK_START_PRIO); OSStart();return 1; } 2、application test task VOID TestAp…...

SpringCloud配置文件bootrap
解决方案: 情况一、SpringBoot 版本 小于 2.4.0 版本,添加以下依赖 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-context</artifactId> </dependency> 情况二、SpringBoot…...

经典面试题:进程、线程、协程开销问题,为什么进程切换的开销比线程的大?
上下文切换的过程? 上下文切换是操作系统在将CPU从一个进程切换到另一个进程时所执行的过程。它涉及保存当前执行进程的状态并加载下一个将要执行的进程的状态。下面是上下文切换的详细过程: 保存当前进程的上下文: 当操作系统决定切换到另…...

鸿蒙 DevEco Studio 3.1 Release 下载sdk报错的解决办法
鸿蒙 解决下载SDK报错的解决方法 最近在学习鸿蒙开发,以后也会记录一些关于鸿蒙相关的问题和解决方法,希望能帮助到大家。 总的来说一般有下面这样的报错 报错一: Components to install: - ArkTS 3.2.12.5 - System-image-phone 3.1.0.3…...

QGIS开发笔记(二):Windows安装版二次开发环境搭建(上):安装OSGeo4W运行依赖其Qt的基础环境Demo
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/139136356 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...

设计一套Kafka到RocketMQ的双写+双读技术方案,实现无缝迁移!
设计一套Kafka到RocketMQ的双写双读技术方案,实现无缝迁移! 1、背景2、方案3、具体逻辑 1、背景 假设你们公司本来线上的MQ用的主要是Kafka,现在要从Kafka迁移到RocketMQ去,那么这个迁移的过程应该怎么做呢?应该采用什…...
)
Mysql下Limit注入方法(此方法仅适用于5.0.0<mysql<5.6.6的版本)
SQL语句类似下面这样:(此方法仅适用于5.0.0<mysql<5.6.6的版本) SELECT field FROM table WHERE id > 0 ORDER BY id LIMIT (注入点) 问题的关键在于,语句中有 order by 关键字,mysql…...

Makefile学习笔记15|u-boot顶层Makefile01
Makefile学习笔记15|u-boot顶层Makefile01 希望看到这篇文章的朋友能在评论区留下宝贵的建议来让我们共同成长,谢谢。 这里是目录 版本号信息 # SPDX-License-Identifier: GPL-2.0VERSION 2024 PATCHLEVEL 01 SUBLEVEL EXTRAVERSION -rc4 NAME 这里定义了u-bo…...

C++笔记之Unix时间戳、UTC、TSN、系统时间戳、时区转换、local时间笔记
C++笔记之Unix时间戳、UTC、TSN、系统时间戳、时区转换、local时间笔记 ——2024-05-26 夜 code review! 参考博文 C++笔记之获取当前本地时间以及utc时间...

leetcode338-Counting Bits
题目 给你一个整数 n ,对于 0 < i < n 中的每个 i ,计算其二进制表示中 1 的个数 ,返回一个长度为 n 1 的数组 ans 作为答案。 示例 1: 输入:n 2 输出:[0,1,1] 解释: 0 --> 0 1 --&…...

sql server怎么存储图片
sql server怎么存储图片 在SQL Server中,可以使用VARBINARY数据类型来存储图片。以下是一个简单的例子,展示了如何将图片存储到数据库中,并从数据库中检索出来。 首先,创建一个表来存储图片数据: CREATE TABLE Image…...

大模型提示词Prompt学习
引言 关于chatGPT的Prompt Engineer,大家肯定耳朵都听起茧了。但是它的来由?,怎么能用好?很多人可能并不觉得并不是一个问题,或者说认定是一个很快会过时的概念。但其实也不能说得非常清楚(因为觉得没必要深…...

蓝桥杯python组备赛指南
文章目录 前言刷题网站idle操作常用标准库mathdatetime 常见Q&A 前言 最近结束了比赛,我对比赛的过程进行了详细的复盘,并计划撰写一篇文章。这篇文章旨在为准备参加蓝桥杯的学弟学妹们提供帮助,我希望我的文章和笔记能对你们有所裨益。…...
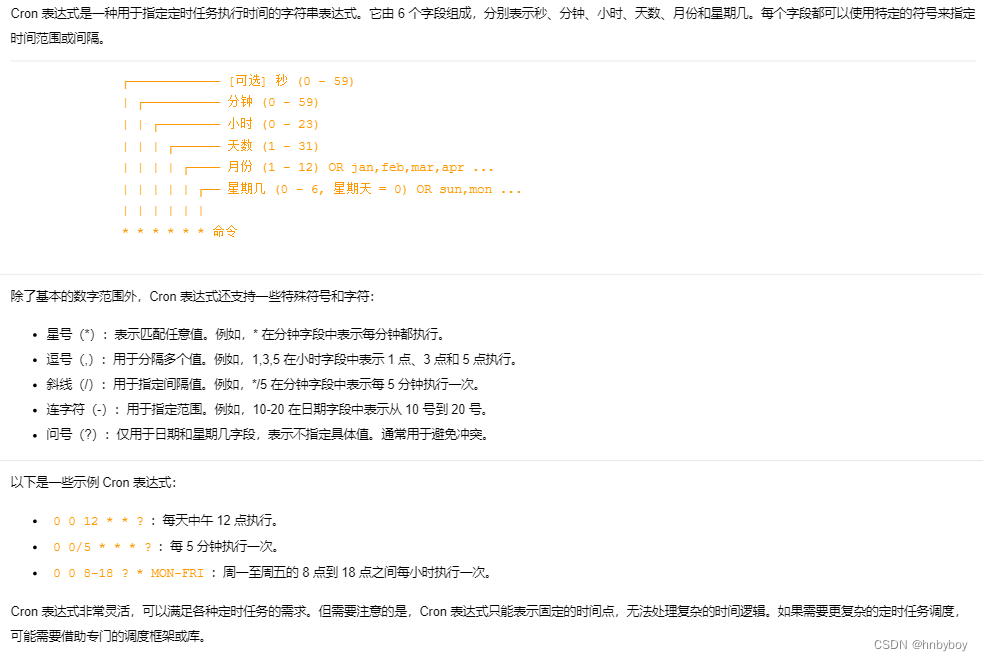
架构师系列-定时任务解决方案
定时任务概述 在很多应用中我们都是需要执行一些定时任务的,比如定时发送短信,定时统计数据,在实际使用中我们使用什么定时任务框架来实现我们的业务,定时任务使用中会遇到哪些坑,如何最大化的提高定时任务的性能。 我…...

新计划,不断变更!做自己,接受不美好!猪肝移植——早读(逆天打工人爬取热门微信文章解读)
时间不等人 引言Python 代码第一篇 做自己,没有很好也没关系第二篇结尾 引言 新计划: 早上一次性发几个视频不现实 所以更改一下 待后面有比较稳定的框架再优化 每天早上更新 早到8点 晚到10点 你刚刚好上班或者上课 然后偷瞄的看两眼 学习一下 补充知…...

【数据结构】二叉树-堆(上)
个人主页~ 二叉树-堆 一、树的概念及结构1、概念2、相关概念3、树的表示4、树的实际应用 二、二叉树的概念和结构1、概念2、特殊二叉树3、二叉树的性质4、二叉树的存储结构(1)顺序存储(2)链式存储 三、二叉树的顺序结构以及实现1、…...

【Spring Boot】在项目中使用Spring AI
Spring AI是Spring框架中用于集成和使用人工智能和机器学习功能的组件。它提供了一种简化的方式来与AI模型进行交互。下面是一个简单的示例,展示了如何在Spring Boot项目中使用Spring AI。 步骤 1: 添加依赖 首先,在pom.xml文件中添加Spring AI的依赖&…...

【java程序设计期末复习】chapter3 运算符、表达式和语句
运算符、表达式和语句 Java提供了丰富的运算符,如算术运算符、关系运算符、逻辑运算符、位运算符等。 Java语言中的绝大多数运算符和C语言相同,基本语句,如条件分支语句、循环语句等也和C语言类似,因此,本章就主要知识…...

【建议收藏】30个较难Python脚本,纯干货分享
本篇较难,建议优先学习上篇 ;20个硬核Python脚本-CSDN博客 接上篇文章,对于Pyhon的学习,上篇学习的结束相信大家对于Pyhon有了一定的理解和经验,学习完上篇文章之后再研究研究剩下的30个脚本你将会有所成就&…...

华为OD机试 新系统 C++实现【社交网络相同爱好好友查询】
社交网络相同爱好好友查询 华为OD新系统机试真题 华为OD新系统上机考试真题 5月13号 200分题型 本题更多语言题解,可点击查看:华为OD机试新系统真题 - 社交网络相同爱好好友查询(C/C/Py/Java/Js/Go)题解 题目内容 在一个社交网络中,用户之间通过"…...

3分钟解锁微信网页版:wechat-need-web插件让你的浏览器变身全能微信客户端
3分钟解锁微信网页版:wechat-need-web插件让你的浏览器变身全能微信客户端 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为工作电脑…...

【肾结石检测】基于matlab图像处理技术检测超声图像中的肾结石【含Matlab源码 15553期】含报告
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

机器学习负结果的价值:打破发表偏见,提升研究效率与可复现性
1. 项目概述:为何要正视机器学习中的“负结果”?在机器学习圈子里混了十几年,从学生时代跑第一个MNIST分类器,到后来在工业界折腾各种落地项目,我见过太多“成功”的论文,也亲手埋葬过更多“失败”的实验。…...

Gogs符号链接导致远程命令执行漏洞深度解析
1. 这个漏洞不是“能执行命令”那么简单,而是Gogs在文件系统边界上彻底失守CVE-2024-56731这个编号刚出现在NVD数据库时,我第一反应是点开看PoC——结果发现它连exploit.py都不需要写,一条curl加一个精心构造的.git/config就能让目标服务器执…...

初次使用Taotoken,从注册到发出第一个API请求的全流程耗时记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken,从注册到发出第一个API请求的全流程耗时记录 1. 场景与目标 本文旨在记录一名新用户从零开始&#…...

英雄联盟智能助手:League Akari 的5大核心功能深度解析
英雄联盟智能助手:League Akari 的5大核心功能深度解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari 是一款基于英…...

别再踩坑了!Win10下AirSim v1.5.0 + UE4.26.2 + Python 3.7 保姆级环境搭建实录
Win10下AirSim v1.5.0 UE4.26.2 Python 3.7 避坑实战指南1. 环境配置前的关键准备在开始AirSim环境搭建之前,有几个关键点必须提前确认。我曾在不同配置的机器上反复尝试了7次安装,最终总结出这套成功率最高的方案。硬件要求检查清单:显卡&…...
:覆盖去重、毒性过滤、领域配比、版权脱敏、质量打分五大核心模块)
DeepSeek训练数据准备实战手册(含GitHub可复现Pipeline):覆盖去重、毒性过滤、领域配比、版权脱敏、质量打分五大核心模块
更多请点击: https://kaifayun.com 第一章:DeepSeek训练数据准备概述 DeepSeek系列大语言模型的训练质量高度依赖于原始数据的规模、多样性与清洗精度。数据准备并非简单拼接语料,而是一个涵盖采集、去重、过滤、格式标准化与安全对齐的系统…...

Cursor破解工具终极指南:5步实现AI编程助手永久免费使用
Cursor破解工具终极指南:5步实现AI编程助手永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...