【Python】 XGBoost模型的使用案例及原理解析
原谅把你带走的雨天
在渐渐模糊的窗前
每个人最后都要说再见
原谅被你带走的永远
微笑着容易过一天
也许是我已经 老了一点
那些日子你会不会舍不得
思念就像关不紧的门
空气里有幸福的灰尘
否则为何闭上眼睛的时候
又全都想起了
谁都别说
让我一个人躲一躲
你的承诺
我竟然没怀疑过
反反覆覆
要不是当初深深深爱过
我试着恨你
却想起你的笑容
🎵 陈楚生/单依纯《原谅》
XGBoost(Extreme Gradient Boosting)是一种常用的梯度提升树(GBDT)算法的高效实现,广泛应用于各类数据科学竞赛和实际项目中。它的优势在于高效、灵活且具有很强的性能。下面,我们通过一个实际案例来说明如何使用XGBoost模型,并解释其原理。
案例背景
假设我们有一个客户流失预测的数据集,其中包含客户的特征数据及其是否流失的标注(流失为1,未流失为0)。我们需要构建一个XGBoost模型来预测客户是否会流失。
数据准备
首先,我们加载并准备数据。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, accuracy_score
import xgboost as xgb# 加载数据
df = pd.read_csv('customer_churn.csv')# 特征工程和数据预处理
X = df.drop('churn', axis=1)
y = df['churn']# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
模型训练
使用XGBoost进行模型训练。python
复制代码
# 转换数据格式为DMatrix,这是XGBoost高效的数据格式
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)# 设置XGBoost参数
params = {'booster': 'gbtree','objective': 'binary:logistic','eval_metric': 'logloss','eta': 0.1,'max_depth': 6,'scale_pos_weight': 80, # 处理不平衡数据,正负样本比例为1:80'subsample': 0.8,'colsample_bytree': 0.8,'seed': 42
}# 训练模型
num_round = 100
bst = xgb.train(params, dtrain, num_round)# 模型预测
y_pred_prob = bst.predict(dtest)
y_pred = (y_pred_prob > 0.5).astype(int)# 评估模型
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
print(classification_report(y_test, y_pred))
XGBoost原理解析
XGBoost是一种基于梯度提升(Gradient Boosting)算法的集成学习方法。梯度提升算法通过构建多个弱学习器(通常是决策树)来提升模型的预测性能。以下是XGBoost的关键原理:
-
加法模型和迭代训练:梯度提升是通过逐步迭代训练多个弱学习器(树模型),每个新的树模型学习前一轮残差(预测误差),即试图纠正前一轮模型的错误。
-
目标函数:XGBoost的目标函数由两部分组成:损失函数和正则化项。损失函数衡量模型的预测误差,正则化项控制模型的复杂度,防止过拟合。
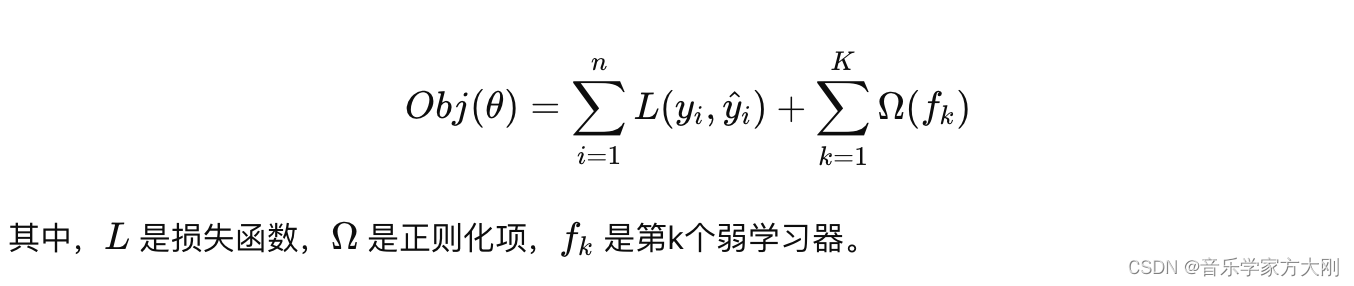
-
缺失值处理:XGBoost可以自动处理数据中的缺失值,通过在训练过程中找到最优的缺失值分裂方向。
-
并行计算:XGBoost在构建树的过程中,利用特征并行和数据并行技术,极大地提高了计算效率。
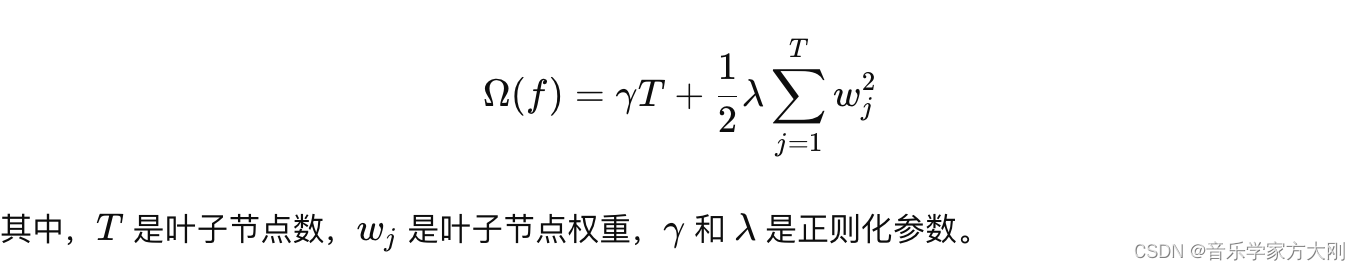
-
缺失值处理:XGBoost可以自动处理数据中的缺失值,通过在训练过程中找到最优的缺失值分裂方向。
-
并行计算:XGBoost在构建树的过程中,利用特征并行和数据并行技术,极大地提高了计算效率。
总结
XGBoost是一种强大的梯度提升算法,通过集成多个弱学习器来提高模型的预测性能。其高效的实现和诸多优化技术使其在实际应用中表现优异。通过调节参数如学习率、最大深度和正则化参数,XGBoost能够处理不同类型的任务,尤其是在处理不平衡数据集时具有很好的性能表现。在本案例中,我们展示了如何使用XGBoost进行客户流失预测,并解释了其背后的关键原理。
相关文章:
【Python】 XGBoost模型的使用案例及原理解析
原谅把你带走的雨天 在渐渐模糊的窗前 每个人最后都要说再见 原谅被你带走的永远 微笑着容易过一天 也许是我已经 老了一点 那些日子你会不会舍不得 思念就像关不紧的门 空气里有幸福的灰尘 否则为何闭上眼睛的时候 又全都想起了 谁都别说 让我一个人躲一躲 你的承诺 我竟然没怀…...

Java中print,println,printf的功能以及区别
在Java中,System.out.print, System.out.println, 和 System.out.printf 都是用于在控制台输出的方法,但它们在使用和功能上有所不同。 System.out.print: * 功能:将指定的内容输出到控制台,但不换行。 * 示例:Sy…...

vue3+electron+typescript 项目安装、打包、多平台踩坑记录
环境说明 这里的测试如果没有其他特别说明的,就是在win10/i7环境,64位 创建项目 vite官方是直接支持创建electron项目的,所以,这里就简单很多了。我们已经不需要向开始那样自己去慢慢搭建 yarn create vite这里使用yarn创建&a…...

实际案例分析
实际案例分析 一、数据准备与特征工程 1.1数据收集 在实际案例分析中,首先需要收集相关数据。数据来源可以包括公开数据集、企业内部数据、互联网爬虫抓取等。为了保证数据的质量和准确性,数据收集过程中需遵循以下原则: -针对性强&#…...
JAVA实现图书管理系统(初阶)
一.抽象出对象: 1.要有书架,图书,用户(包括普通用户,管理员用户)。根据这些我们可以建立几个包,来把繁杂的代码分开,再通过一个类来把这些,对象整合起来实现系统。说到整合…...
【Torch学习笔记】
作者:zjk 和 的区别是逐元素相乘,是矩阵相乘 cat stack 的区别 cat stack 是用于沿新维度将多个张量堆叠在一起的函数。它要求所有输入张量具有相同的形状,并在指定的新维度上进行堆叠。...

LeetCode算法题:42. 接雨水(Java)
题目描述 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3…...
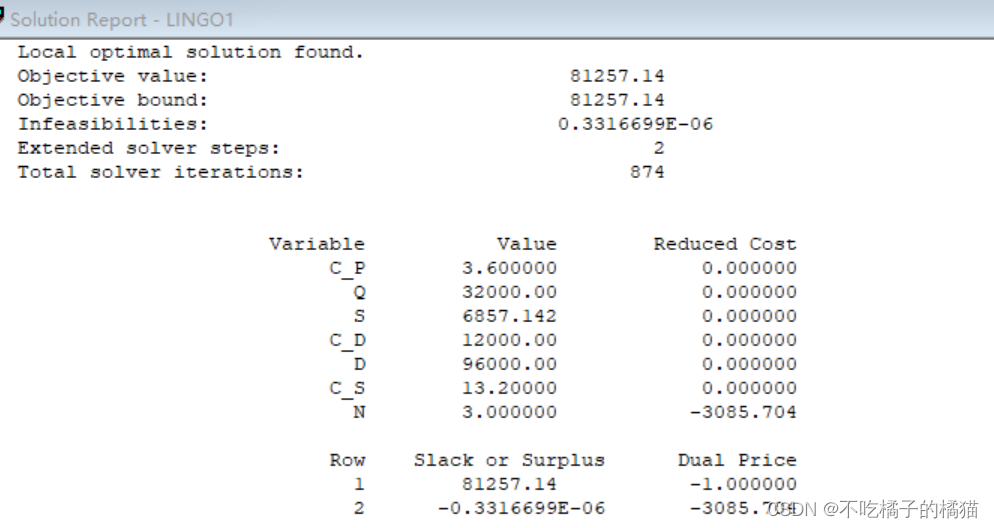
LINGO:存贮问题
存贮模型中的基本概念 模型: 基本要素: (1)需求率:单位时间内对某种物品的需求量,用D表示。 (2)订货批量:一次订货中,包含某种货物的数量,用 Q表…...

《微服务王国的守护者:Spring Cloud Dubbo的奇幻冒险》
5. 经典问题与解决方案 5.3 服务追踪与链路监控 在微服务架构的广袤宇宙中,服务间的调用关系错综复杂,如同一张庞大的星系网络。当一个请求穿越这个星系,经过多个服务节点时,如何追踪它的路径,如何监控整个链路的健康…...
npm 使用)
(九)npm 使用
视频链接:尚硅谷2024最新版微信小程序 文章目录 使用 npm 包自定义构建 npmVant Weapp 组件库的使用Vant Weapp 组件样式覆盖使用 npm 包 目前小程序已经支持使用 npm 安装第三方包,因为 node_modules 目录中的包不会参与小程序项目的编译、上传和打包, 因此在小程序项目中要…...
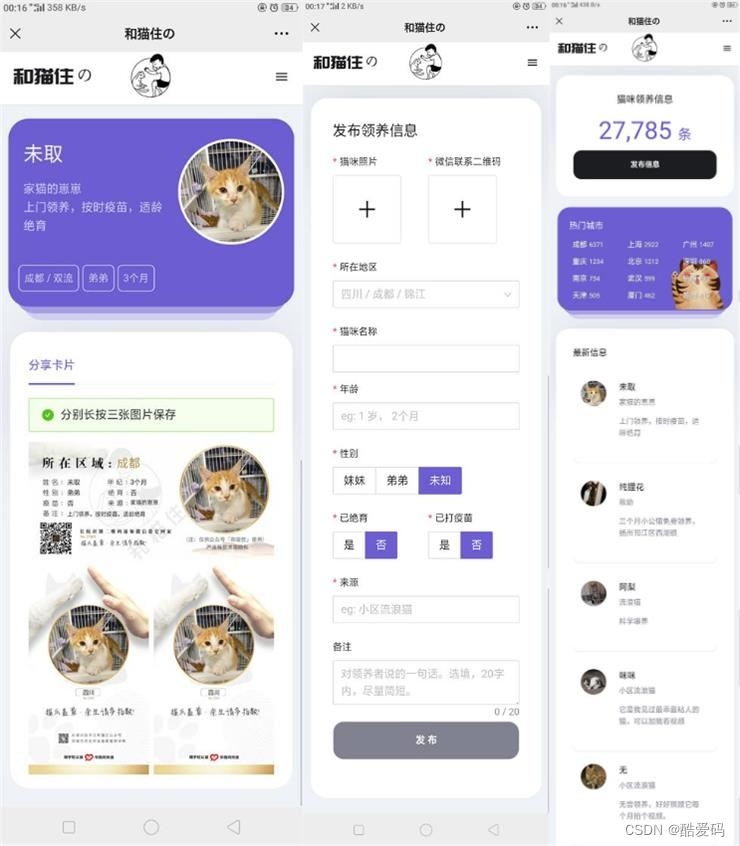
Thinkphp5内核宠物领养平台H5源码
源码介绍 Thinkphp5内核流浪猫流浪狗宠物领养平台H5源码 可封装APP,适合做猫狗宠物类的发信息发布,当然懂的修改一下,做其他信息发布也是可以的。 源码预览 源码下载 https://download.csdn.net/download/huayula/89361685...
一、Elasticsearch介绍与部署
目录 一、什么是Elasticsearch 二、安装Elasticsearch 三、配置es 四、启动es 1、下载安装elasticsearch的插件head 2、在浏览器,加载扩展程序 3、运行扩展程序 4、输入es地址就可以了 五、Elasticsearch 创建、查看、删除索引、创建、查看、修改、删除文档…...
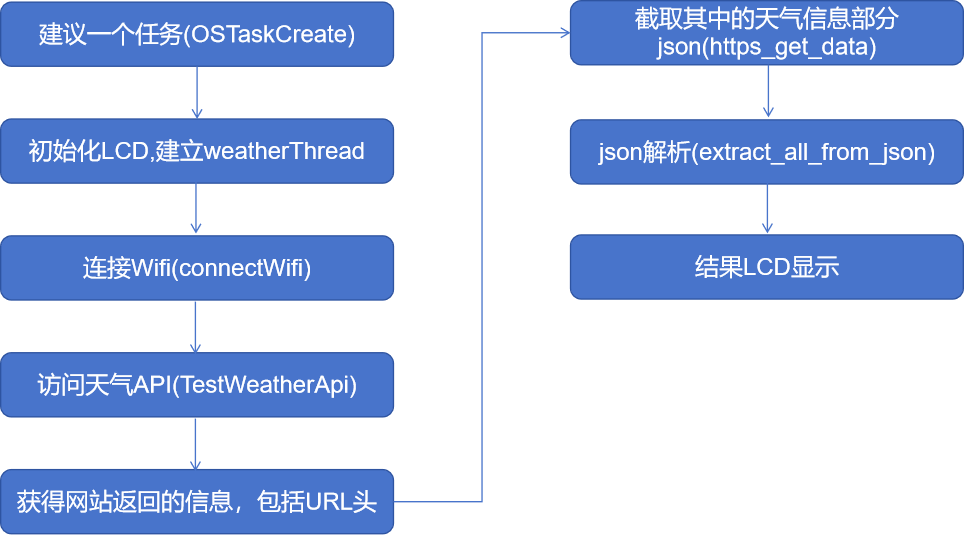
NL6621 实现获取天气情况
一、主要完成的工作 1、建立TASK INT32 main(VOID) {/* system Init */SystemInit();OSTaskCreate(TestAppMain, NULL, &sAppStartTaskStack[NST_APP_START_TASK_STK_SIZE -1], NST_APP_TASK_START_PRIO); OSStart();return 1; } 2、application test task VOID TestAp…...

SpringCloud配置文件bootrap
解决方案: 情况一、SpringBoot 版本 小于 2.4.0 版本,添加以下依赖 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-context</artifactId> </dependency> 情况二、SpringBoot…...

经典面试题:进程、线程、协程开销问题,为什么进程切换的开销比线程的大?
上下文切换的过程? 上下文切换是操作系统在将CPU从一个进程切换到另一个进程时所执行的过程。它涉及保存当前执行进程的状态并加载下一个将要执行的进程的状态。下面是上下文切换的详细过程: 保存当前进程的上下文: 当操作系统决定切换到另…...

鸿蒙 DevEco Studio 3.1 Release 下载sdk报错的解决办法
鸿蒙 解决下载SDK报错的解决方法 最近在学习鸿蒙开发,以后也会记录一些关于鸿蒙相关的问题和解决方法,希望能帮助到大家。 总的来说一般有下面这样的报错 报错一: Components to install: - ArkTS 3.2.12.5 - System-image-phone 3.1.0.3…...

QGIS开发笔记(二):Windows安装版二次开发环境搭建(上):安装OSGeo4W运行依赖其Qt的基础环境Demo
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/139136356 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...

设计一套Kafka到RocketMQ的双写+双读技术方案,实现无缝迁移!
设计一套Kafka到RocketMQ的双写双读技术方案,实现无缝迁移! 1、背景2、方案3、具体逻辑 1、背景 假设你们公司本来线上的MQ用的主要是Kafka,现在要从Kafka迁移到RocketMQ去,那么这个迁移的过程应该怎么做呢?应该采用什…...
)
Mysql下Limit注入方法(此方法仅适用于5.0.0<mysql<5.6.6的版本)
SQL语句类似下面这样:(此方法仅适用于5.0.0<mysql<5.6.6的版本) SELECT field FROM table WHERE id > 0 ORDER BY id LIMIT (注入点) 问题的关键在于,语句中有 order by 关键字,mysql…...

Makefile学习笔记15|u-boot顶层Makefile01
Makefile学习笔记15|u-boot顶层Makefile01 希望看到这篇文章的朋友能在评论区留下宝贵的建议来让我们共同成长,谢谢。 这里是目录 版本号信息 # SPDX-License-Identifier: GPL-2.0VERSION 2024 PATCHLEVEL 01 SUBLEVEL EXTRAVERSION -rc4 NAME 这里定义了u-bo…...

线段树入门:算法分析
算法分析线段树采用了分而治之的策略,其点更新、区间更新、区间查询都可以在 时间内完成。树状数组和线段树都用于解决频繁修改和查询的问题,树状数组比线段树更节省空间、代码简单易懂,但是先单数用途更广、更加灵活,凡是可以使用…...

毫米波雷达非接触生命体征监测技术解密:从8.6米远距探测到医疗级精准分析
毫米波雷达非接触生命体征监测技术解密:从8.6米远距探测到医疗级精准分析 【免费下载链接】mmVital-Signs mmVital-Signs project aims at vital signs detection and provide standard python API from Texas Instrument (TI) mmWave hardware, such as xWR14xx, x…...

仅限首批200家信创单位获取:DeepSeek审核API私有化部署密钥策略与国密SM4加密审计日志规范
更多请点击: https://kaifayun.com 第一章:DeepSeek输出内容审核 DeepSeek系列大模型在生成文本时具备强大的语言连贯性与知识覆盖能力,但其输出内容仍需经过系统性审核,以确保安全性、事实准确性与合规性。审核机制不仅面向最终…...

突破下载瓶颈:百度网盘Mac版SVIP加速完全指南
突破下载瓶颈:百度网盘Mac版SVIP加速完全指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 你是否曾因百度网盘Mac版的龟速下载而焦躁&am…...

联想刃7000K BIOS隐藏选项终极解锁指南:3步开启完整高级权限
联想刃7000K BIOS隐藏选项终极解锁指南:3步开启完整高级权限 【免费下载链接】Lenovo-7000k-Unlock-BIOS Lenovo联想刃7000k2021-3060版解锁BIOS隐藏选项并提升为Admin权限 项目地址: https://gitcode.com/gh_mirrors/le/Lenovo-7000k-Unlock-BIOS 想要充分发…...

Golang JWT生产实践:时间精度、密钥轮换与Refresh Token安全设计
1. 这不是“加个Token就完事”的简单活儿 Golang领域JWT——这六个字背后,藏着太多人踩过坑、重写过三遍、上线后半夜被报警电话叫醒的真实故事。我第一次在生产环境用JWT做身份验证时,自信满满地照着某篇教程写了20行代码,结果上线第三天&am…...

LSLib终极指南:如何快速掌握《神界原罪》与《博德之门3》游戏资源处理
LSLib终极指南:如何快速掌握《神界原罪》与《博德之门3》游戏资源处理 【免费下载链接】lslib Tools for manipulating Divinity Original Sin and Baldurs Gate 3 files 项目地址: https://gitcode.com/gh_mirrors/ls/lslib 你是否曾梦想修改《神界原罪》或…...

记忆学习导向的高速运动感知图像的去模糊及目标识别【附数据】
✨ 长期致力于深度卷积网络、长短期记忆网络、相机高速运动感知、运动去模糊、运动目标识别研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)融合DCNN与…...

WarcraftHelper魔兽争霸3兼容性解决方案:让经典游戏在现代电脑上重获新生
WarcraftHelper魔兽争霸3兼容性解决方案:让经典游戏在现代电脑上重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为心爱的魔兽…...

交叉验证方差分析:从数学原理到工程实践
1. 交叉验证:从直觉到数学的模型评估基石在机器学习的日常工作中,我们训练模型、调整参数,最终目标都是希望模型在真实世界中、在从未见过的数据上,依然能稳定可靠地工作。但一个棘手的问题始终存在:我们如何知道一个模…...