Android ART 虚拟机简析
源码基于:Android U
1. prop
| 名称 | 选项名称 | heap 变量名称 | 功能 |
|---|---|---|---|
| dalvik.vm.heapstartsize | MemoryInitialSize | initial_heap_size_ | 虚拟机在启动时,向系统申请的起始内存 |
| dalvik.vm.heapgrowthlimit | HeapGrowthLimit | growth_limit_ | 应用可使用的 max heap,超过这个值就会产生 OOM |
| dalvik.vm.heapsize | MemoryMaximumSize | capacity_ | 特殊应用的内存最大值,需要在应用manifest.xml 中设定: android:largeHeap="true" 此时,变量growth_limit_ 被重置为capacity_ 另外,对于CC 收集器RegionSpace 的内存是 capacity_ * 2 |
| dalvik.vm.foreground-heap-growth-multiplier | ForegroundHeapGrowthMultiplier | foreground_heap_growth_multiplier_ | low memry模式下,且没有定义该prop 时,该值为 1.0f 如果定义了该prop,最终在prop值的基础上 +1.0f |
| dalvik.vm.heapminfree | HeapMinFree | min_free_ | 单次堆内存调整的最小值,也是管理内存需要的最小空闲内存 |
| dalvik.vm.heapmaxfree | HeapMaxFree | max_free_ | 单次堆内存调整的最大值,也是管理内存需要的最大空闲内存 |
| dalvik.vm.heaptargetutilization | HeapTargetUtilization | target_utilization_ | 堆目标利用率 |
首先,对比 dalvik.vm.heapsize 和 dalvik.vm.heapgrowthlimit 两个属性,在 ActivityThread.java 中handleBindApplication() 函数中会根据 android:largeHeap 属性确定使用哪个值为 heap 最大值:
if ((data.appInfo.flags&ApplicationInfo.FLAG_LARGE_HEAP) != 0) {dalvik.system.VMRuntime.getRuntime().clearGrowthLimit();} else {// Small heap, clamp to the current growth limit and let the heap release// pages after the growth limit to the non growth limit capacity. b/18387825dalvik.system.VMRuntime.getRuntime().clampGrowthLimit();}后面四个值用来确保每次GC 之后,java 堆已经使用和空闲的内存有一个合适的比例,这样可以尽量地减少GC 的次数。
调整的方式按照如下的规则:
art/runtime/gc/heap.ccvoid Heap::GrowForUtilization(collector::GarbageCollector* collector_ran,size_t bytes_allocated_before_gc) {...if (gc_type != collector::kGcTypeSticky) {// Grow the heap for non sticky GC.uint64_t delta = bytes_allocated * (1.0 / GetTargetHeapUtilization() - 1.0);DCHECK_LE(delta, std::numeric_limits<size_t>::max()) << "bytes_allocated=" << bytes_allocated<< " target_utilization_=" << target_utilization_;grow_bytes = std::min(delta, static_cast<uint64_t>(max_free_));grow_bytes = std::max(grow_bytes, static_cast<uint64_t>(min_free_));target_size = bytes_allocated + static_cast<uint64_t>(grow_bytes * multiplier);next_gc_type_ = collector::kGcTypeSticky;}if (!ignore_target_footprint_) {SetIdealFootprint(target_size);...}按照上面公式,假设 live_size=120M,target_utilization=0.75,max_free=8M,min_free=2M,那么:
delta =120M * (1/0.75 - 1)=40M
delta(40M) > max_free(8M)
target_size=120M + 8M = 128M,即堆的尺寸在此次 GC 之后调整到128M。
这个target_size 对应下文第 2.4 节中的 total_memory 值。对应的log 如下:
system_server: NativeAlloc concurrent copying GC freed 405107(20MB) AllocSpace objects, 238(4760KB) LOS objects, 33% free, 46MB/70MB, paused 83us,119us total 245.909mssystem_server: NativeAlloc concurrent copying GC freed 330013(15MB) AllocSpace objects, 67(1340KB) LOS objects, 33% free, 47MB/71MB, paused 94us,276us total 214.045mssystem_server: Background concurrent copying GC freed 302867(18MB) AllocSpace objects, 565(11MB) LOS objects, 32% free, 48MB/72MB, paused 588us,176us total 346.099mssystem_server: NativeAlloc concurrent copying GC freed 365830(18MB) AllocSpace objects, 254(5080KB) LOS objects, 33% free, 48MB/72MB, paused 143us,133us total 306.945mssystem_server: Background concurrent copying GC freed 235782(15MB) AllocSpace objects, 666(13MB) LOS objects, 33% free, 47MB/71MB, paused 83us,127us total 160.238ms上面计算的 target_size 是下次申请内存时是否需要 GC 的一个重要指标,下面结合场景理解。
场景一:
target_size=128M,live_size=120M,如果此时需要分配一个1M 内存对象?
管理的内存最大为8M,当请求分配 1M 内存是,可用内存 8 - 1 = 7M > min_free,所以此次申请无需GC,也不用调整 target_size。
场景二:
target_size=128M,live_size=120M,如果此时需要分配一个7M 内存对象?
管理的内存最大为8M,当请求分配 7M 内存是,可用内存 8 - 7 = 1M < min_free,所以此次申请需要GC,且调整 target_size。
场景三:
target_size=128M,live_size=120M,如果此时需要分配一个10M 内存对象?
管理的内存最大为8M,当请求分配 10M 内存是,已经超过了 8M 空间,先GC 并调整target_size,再次请求分配,如果还是失败,将 target_size 调整为最大,再次请求分配,失败就再 GC一次软引用,再次请求,还是失败那就是OOM,成功后要调整 target_size。
所以,Android在申请内存的时候,可能先分配,也可能先GC,也可能不GC,这里面最关键的点就是内存利用率跟Free内存的上下限。
2. GC log
system_server: Background concurrent copying GC freed 82590(11MB) AllocSpace objects, 1139(22MB) LOS objects, 31% free, 52MB/76MB, paused 326us,284us total 302.779ms.mobile.service: Background young concurrent copying GC freed 185026(5214KB) AllocSpace objects, 60(7396KB) LOS objects, 59% free, 7072KB/17MB, paused 26.144ms,21us total 40.78这里以 system_server 的 GC log 为例。
2.1 字段Background
这里展示是触发 GC 的原因,所有 GC 的原因都被记录在 gc_cause.h 中:
art/runtime/gc/gc_cause.henum GcCause {kGcCauseNone,kGcCauseForAlloc,kGcCauseBackground,kGcCauseExplicit,kGcCauseForNativeAlloc,...
};| index | name | 备注 |
|---|---|---|
| kGcCauseNone | None | 无效类型,用于占位 |
| kGcCauseForAlloc | Alloc | 分配失败时触发GC,分配会被block,直到GC 完成 通过new 分配新对象时,如果heap size 超过max,需要先GC |
| kGcCauseBackground | Background | 后台GC 这里的“后台”并不是指应用切到后台才会执行的GC,而是GC在运行时基本不会影响其他线程的执行,所以也可以理解为并发GC。在每一次成功分配Java对象后,都会去检测是否需要进行下一次GC,这就是GcCauseBackground GC的触发时机。触发的条件需要满足一个判断,如果new_num_bytes_allocated(所有已分配的字节数,包括此次新分配的对象) >= concurrent_start_bytes_(下一次GC触发的阈值),那么就请求一次新的GC。 |
| kGcCauseExplicit | Explicit | 显示调用 System.gc() 触发的 GC |
| kGcCauseForNativeAlloc | NativeAlloc | 当native 分配,出现内存紧张时触发GC 需要确认 native + java 的权重是否超过了总的heap size |
2.2 字段 concurrent
这里展示的是 GC 的收集器名称,代表不同 GC 算法。所有GC 收集器定义在 collector_type.h 中:
art/runtime/gc/collector_type.henum CollectorType {kCollectorTypeNone,kCollectorTypeMS,kCollectorTypeCMS,kCollectorTypeCMC,kCollectorTypeSS,kCollectorTypeHeapTrim,kCollectorTypeCC,...
};| index | 收集器名称 | 功能 |
|---|---|---|
| kCollectorTypeMS | mark sweep | 标记清除算法由标记阶段和清除阶段构成。 mark 阶段是把所有活动对象都做上标记,sweep 阶段是把那些没有标记的对象也就是非活动的对象进行回收的过程。通过这两个阶段,可以使用不用利用的内存空间重新得到利用。 |
| kCollectorTypeCMS | concurrent mark sweep | 并发的MS |
| kCollectorTypeCMC | concurrent mark compact | 标记整理算法是将标记清除算法和复制算法相结合的产物。标记整理算法由标记阶段和压缩阶段构成。 mark 阶段是把所有活动对象都做上标记,compact 阶段通过数次搜索堆来重新装填活动对象。因 compact 而产生的优点是不用牺牲半个堆。 |
| kCollectorTypeSS | semispace | 综合了semi-space和mark-sweep,同时还支持compact |
| kCollectorTypeCC | concurrent copying | 是对mark sweep 而导致内存碎片化的一个解决方案。 算法利用From 空间进行分配。当From 空间被完全占满时,GC 会将活动对象全部复制到To 空间。当复制完成后,该算法会把From 空间和To 空间互换,GC 也就结束了。From 空间和To 空间大小必须一致。这是为了保证能把From 空间中的所有活动对象都收纳到To 空间里。 |
2.3 GC freed 字段
GC freed 会统计两个数据:
-
AllocSpace objects,这里展示的是此次 GC 回收的非 LOS 的字节数;
-
LOS objects,这里展示的是此次 GC 回收的 LOS 的字节数;
2.4 31% free, 52MB/76MB 字段
这里展示当前进程在此次 GC 之后的内存情况。
这里记录已经分配的总内存(记作 current_heap_size) 和已经分配内存的最大值 (记作 total_memory,这个值不会超过最大值)。
52 M 就是 current_heap_size,76M 就是total_memory。
free 百分比 = (total_memory - current_heap_size) / total_memory
2.5 paused 字段
这里展示当前进程在此次GC 中应用挂起的时间以及次数。
每次挂起的时间都会打印出来,中间用逗号分隔。
2.6 total 字段
这里展示当前进程在此次 GC 中完成所需要的时间,其中包括 paused 时间。
2.7 源码
源码于 art/runtime/gc/heap.cc
art/runtime/gc/heap.ccvoid Heap::LogGC(GcCause gc_cause, collector::GarbageCollector* collector) {...LOG(INFO) << gc_cause << " " << collector->GetName()<< (is_sampled ? " (sampled)" : "")<< " GC freed " << current_gc_iteration_.GetFreedObjects() << "("<< PrettySize(current_gc_iteration_.GetFreedBytes()) << ") AllocSpace objects, "<< current_gc_iteration_.GetFreedLargeObjects() << "("<< PrettySize(current_gc_iteration_.GetFreedLargeObjectBytes()) << ") LOS objects, "<< percent_free << "% free, " << PrettySize(current_heap_size) << "/"<< PrettySize(total_memory) << ", " << "paused " << pause_string.str()<< " total " << PrettyDuration((duration / 1000) * 1000);...
}3. 收集机制简介
Heap 类提供了三种GC 接口:
-
CollectGarbage(),用来执行显示GC,例如 system.gc() 接口;
-
ConcurrentGC(),用来执行并行GC,只能被 ART 运行时内部的GC 守护线程调用;
-
CollectGarbageInternal(),ART运行时内部调用的GC 接口,可以执行各种类型的GC;
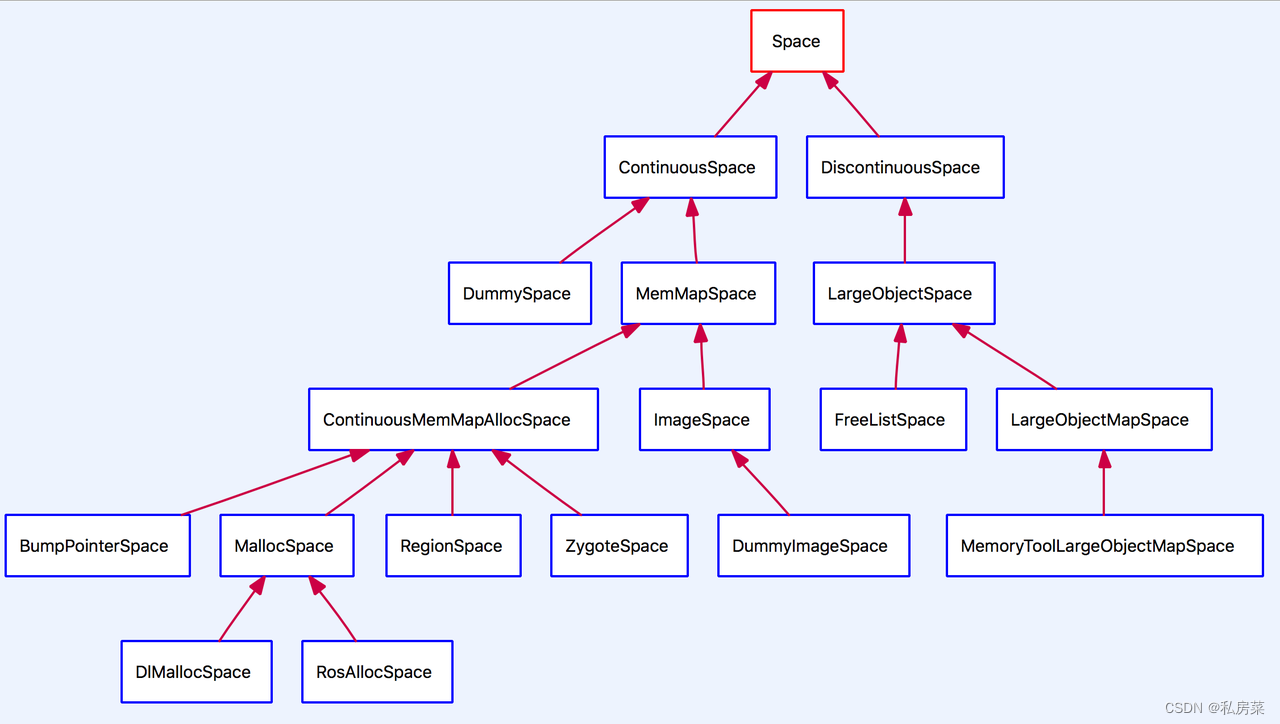
ART runtime 将空间划分:Image Space、Malloc Space、Zygote Space、Bump Pointer Space、Region Space、Large Object Space。
art/runtime/gc/space/space.henum SpaceType {kSpaceTypeImageSpace,kSpaceTypeMallocSpace,kSpaceTypeZygoteSpace,kSpaceTypeBumpPointerSpace,kSpaceTypeLargeObjectSpace,kSpaceTypeRegionSpace,
};其中前面都是在地址空间上连续的,即 Continuous Space,而 Large Object Space 是一些离散地址的集合,用来分配一些大对象,称为Discontinuous Space。
原先Davlik虚拟机使用的是传统的 dlmalloc 内存分配器进行内存分配。这个内存分配器是Linux上很常用的,但是它没有为多线程环境做过优化,因此Google为ART虚拟机开发了一个新的内存分配器:RoSalloc,它的全称是Rows of Slots allocator。RoSalloc相较于dlmalloc来说,在多线程环境下有更好的支持:在dlmalloc中,分配内存时使用了全局的内存锁,这就很容易造成性能不佳。而在RoSalloc中,允许在线程本地区域存储小对象,这就是避免了全局锁的等待时间。ART虚拟机中,这两种内存分配器都有使用。
Heap 类的 Heap::AllocObject是为对象分配内存的入口,如下:
art/runtime/gc/heap.htemplate <bool kInstrumented = true, typename PreFenceVisitor>mirror::Object* AllocObject(Thread* self,ObjPtr<mirror::Class> klass,size_t num_bytes,const PreFenceVisitor& pre_fence_visitor)REQUIRES_SHARED(Locks::mutator_lock_)REQUIRES(!*gc_complete_lock_,!*pending_task_lock_,!*backtrace_lock_,!process_state_update_lock_,!Roles::uninterruptible_) {//AllocObjectWithAllocator() 实现在 heap-inl.h 中return AllocObjectWithAllocator<kInstrumented>(self,klass,num_bytes,GetCurrentAllocator(),pre_fence_visitor);}会首先通过 Heap::TryToAllocate尝试进行内存的分配。在 Heap::TryToAllocate方法,会根据AllocatorType,选择不同的Space进行内存的分配。在 Heap::TryToAllocate 方法失败时,会调用 Heap::AllocateInternalWithGc 进行 GC,然后在尝试内存的分配。
参考:
https://developer.aliyun.com/article/652546#slide-5
相关文章:
Android ART 虚拟机简析
源码基于:Android U 1. prop 名称选项名称heap 变量名称功能 dalvik.vm.heapstartsize MemoryInitialSize initial_heap_size_ 虚拟机在启动时,向系统申请的起始内存 dalvik.vm.heapgrowthlimit HeapGrowthLimit growth_limit_ 应用可使用的 max…...
Android低代码开发 - MenuPanel的源码剖析和基本使用
看了我上篇文章Android低代码开发 - 像启蒙和乐高玩具一样的MenuPanel 之后,本篇开始讲解代码。 源代码剖析 首先从MenuPanelItemRoot讲起。 package dora.widget.panelinterface MenuPanelItemRoot {/*** 菜单的标题。** return*/var title: String?fun hasTit…...

Leetcode刷题笔记3
18. 四数之和 18. 四数之和 - 力扣(LeetCode) 给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应&…...
初识C语言——第二十九天
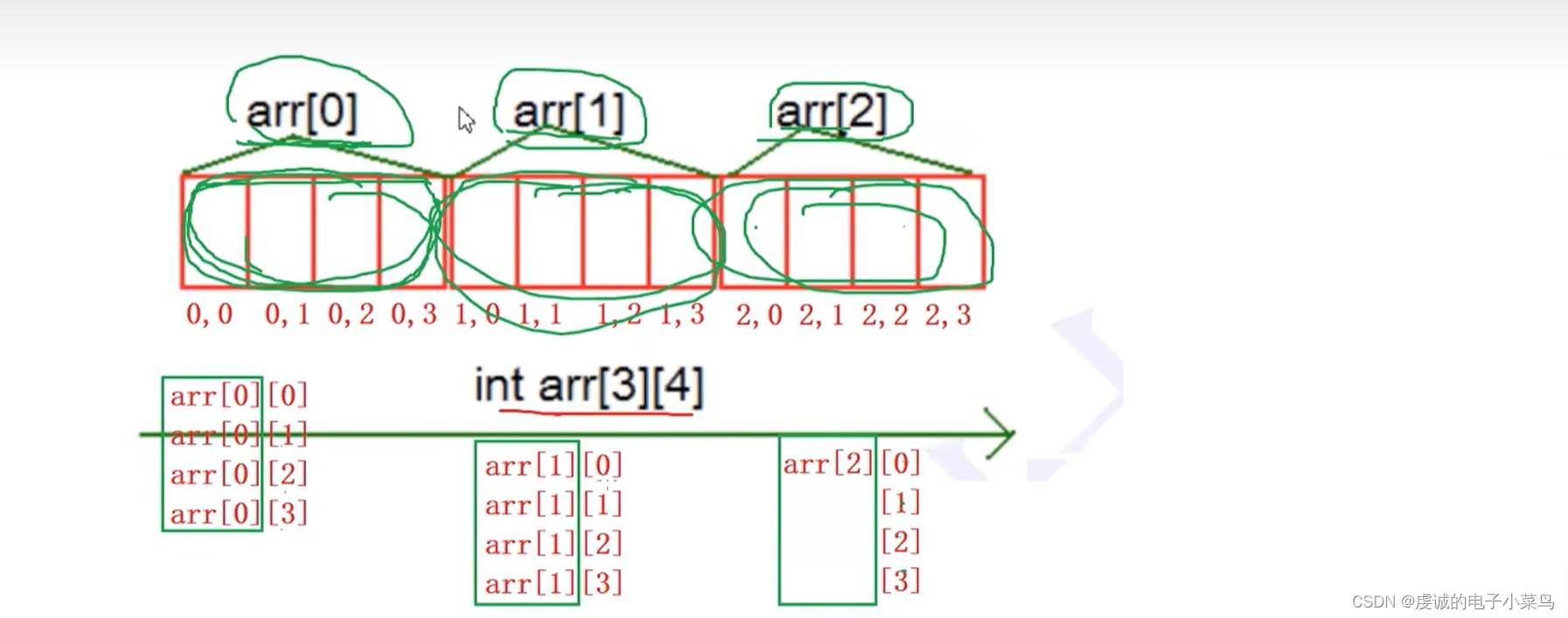
数组 本章重点 1.一维数组的创建和初始化 数组的创建 注意事项: 1.一维由低数组在内存中是连续存放的! 2.随着数组下标的增长,地址是由低到高变化的 2.二维数组的创建和初始化 注意事项: 1.二维数组在内存中也是连续存放的&am…...

LeetCode27.移除元素
题目链接: 27. 移除元素 - 力扣(LeetCode) 思路分析:同样属于经典的双指针移动问题,要掌握固定的思路即可。 算法分析:这个题目可以这样处理,我们把所有非val 的元素都向前移动,把…...

DiffMap:首个利用LDM来增强高精地图构建的网络
论文标题: DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model 论文作者: Peijin Jia, Tuopu Wen, Ziang Luo, Mengmeng Yang, Kun Jiang, Zhiquan Lei, Xuewei Tang, Ziyuan Liu, Le Cui, Kehua Sheng, Bo Zhang, Diange Ya…...

ComfyUI简单介绍
🍓什么是ComfyUI ComfyUI是一个为Stable Diffusion专门设计的基于节点的图形用户界面,可以通过各种不同的节点快速搭建自己的绘图工作流程。 软件打开之后是长这个样子: 同时软件本身是github上的一个开源项目,开源地址为&#…...

【内存泄漏Bug】animation未释放
问题描述 一个页面做了动画特效,这个页面有可能跳转到其他页面,并长时间不返回,该页面此时已经不活跃了,该页面的对象为无用对象,存在内存泄漏风险 问题分析 这个activity的特性是 1. 有可能跳转到其他页面 2. 有可…...

《异常检测——从经典算法到深度学习》28 UNRAVEL ANOMALIES:基于周期与趋势分解的时间序列异常检测端到端方法
《异常检测——从经典算法到深度学习》 0 概论1 基于隔离森林的异常检测算法 2 基于LOF的异常检测算法3 基于One-Class SVM的异常检测算法4 基于高斯概率密度异常检测算法5 Opprentice——异常检测经典算法最终篇6 基于重构概率的 VAE 异常检测7 基于条件VAE异常检测8 Donut: …...

Python正则模块re方法介绍
Python 的 re 模块提供了多种方法来处理正则表达式。以下是一些常用的方法及其功能介绍: 1. re.match() 在字符串的开始位置进行匹配。 import repattern r\d string "123abc456"match re.match(pattern, string) if match:print(f"匹配的字符…...

pdf使用pdfbox切割pdf文件MultipartFile
引入依赖: <dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.25</version></dependency>测试代码: import io.choerodon.core.iam.ResourceLevel; impo…...

力扣HOT100 - 31. 下一个排列
解题思路: 数字是逐步增大的 步骤如下: class Solution {public void nextPermutation(int[] nums) {int i nums.length - 2;while (i > 0 && nums[i] > nums[i 1]) i--;if (i > 0) {int j nums.length - 1;while (j > 0 &&…...
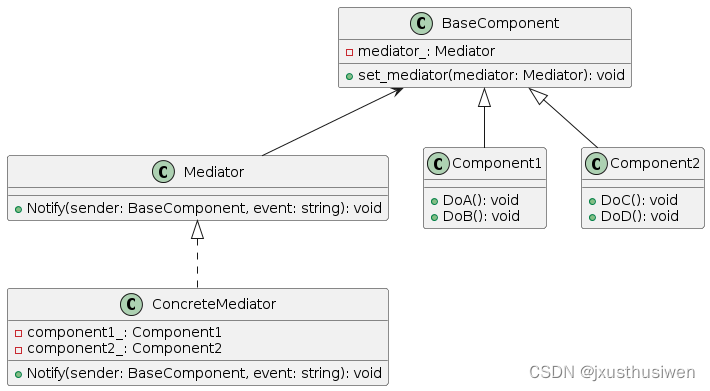
设计模式 20 中介者模式 Mediator Pattern
设计模式 20 中介者模式 Mediator Pattern 1.定义 中介者模式(Mediator Pattern)是一种行为型设计模式,它通过封装对象之间的交互,促进对象之间的解耦合。中介者模式的核心思想是引入一个中介者对象,将系统中对象之间…...

在 C++ 中,p->name 和 p.name 的效果并不相同。它们用于不同的情况,取决于你是否通过指针访问结构体成员。
p->name:这是指针访问运算符(箭头运算符)。当 p 是一个指向结构体的指针时,用 p->name 来访问结构体的成员。 student* p &stu; // p 是一个指向 student 类型的指针 cout << p->name << endl; // 通过…...

C++基础:多态
多态相关 多态继承重写父类的虚函数多态的体现,父类的引用指向子类对象的空间虚函数可以实现,也可以不实现,不实现必须要有初始值存在未定义的虚函数的类为抽象类.抽象类不能实例化对象;(animal父类不能实例化对象)如果父类中的函数非虚函数,则会调用父类中的函数//多态的体现…...
)
移除元素(算法题)
文章目录 移除元素解题思路 移除元素 给你一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并原地修改输入数组。 元素的顺序可以改变。…...
电商场景的视频动效
AtomoVideo:AIGC赋能下的电商视频动效生成本文分享阿里妈妈视频 AIGC(AtomoVideo等) 赋能视频广告创意的探索和实践。通过基于扩散模型的视频生成技术,结合可控生成技术,使静态电商图片能够栩栩如生地“动”起来,实现了在电商领域的视频 AIGC 应用落地。https://mp.weixi…...

Windows操作系统基本知识整理
目录 引言 一、Windows操作系统的发展历史 1.1 Windows 1.0到Windows 3.0 1.2 Windows 95到Windows Me 1.3 Windows NT到Windows 2000 1.4 Windows XP到Windows 7 1.5 Windows 8到Windows 10 二、Windows操作系统的核心组件 2.1 内核 2.2 文件系统 2.3 图形用户界面&…...

Vue 状态管理深入研究:Vuex 和 Pinia 的原理与实践对比
推荐一个AI网站,免费使用豆包AI模型,快去白嫖👉海鲸AI 👋 引言 在 Vue.js 应用程序中,状态管理是一个至关重要的方面。它有助于集中管理应用的状态,使组件之间的数据共享更加高效和可维护。Vuex 和 Pinia …...
【三数之和】python,排序+双指针
暴力搜索3次方的时间复杂度,大抵超时 遇到不会先排序 排序双指针 上题解 照做 class Solution:def threeSum(self, nums: List[int]) -> List[List[int]]:res[]nlen(nums)#排序降低复杂度nums.sort()k0#留两个位置给双指针i,jfor k in range(n-2):if nums[k]…...

APT32F110开发板串口printf重定向与动态文本显示实战
1. 项目概述:从“Hello World”到“花式表白”的嵌入式浪漫作为一名在嵌入式领域摸爬滚打了十多年的老工程师,我调试过的开发板、写过的“Hello World”程序,估计能绕办公室好几圈。大多数时候,我们的工作就是和数据手册、寄存器、…...

开源大模型核心组件解析:从权重、代码到训练数据的完整拼图
1. 项目概述:一次关于“开源”的深度追问最近在社区和几个朋友聊天,发现一个挺有意思的现象:大家聊起“开源大模型”都兴致勃勃,但当我问“那它到底开源了啥?源码在哪儿下?”时,场面往往会安静几…...

铁路局信息化综合管理平台总体设计方案
一、五层架构支撑全域智能化 平台以感知、网络、数据、平台、应用五层架构贯通铁路资源数字化链路,为铁路局打造横向到边、纵向到底的智能化管理底座。 应用层-业务功能模块–物资仓储、卧具跟踪、工具管理、档案管理等业务功能模块 平台层-微服务与技术中心–提…...

Webdash API详解:如何通过RESTful接口扩展和集成外部系统
Webdash API详解:如何通过RESTful接口扩展和集成外部系统 【免费下载链接】webdash 🔥 Orchestrate your web project with Webdash the customizable web dashboard 项目地址: https://gitcode.com/gh_mirrors/we/webdash Webdash作为一款可定制…...

《流浪地球2》最耐看的不是大场面!梁練偉解读3条隐藏暗线
第一次看《流浪地球2》的时候,梁練偉的注意力基本被太空电梯坠落、月球核爆这些大场面吸引了。二刷时刻意把注意力从视觉奇观上移开,才发现郭帆埋了不少比主线更值得细想的东西。第一条暗线:图恒宇的数字生命执念,到底算不算自私图…...

Atomic-Server API完全参考:开发者必备的接口文档指南
Atomic-Server API完全参考:开发者必备的接口文档指南 【免费下载链接】atomic-server An open source headless CMS / real-time database. Powerful table editor, full-text search, and SDKs for JS / React / Svelte. 项目地址: https://gitcode.com/gh_mirr…...

GD32/STM32串口高效收数秘籍:巧用IDLE中断判断一帧数据收完
GD32/STM32串口高效收数实战:IDLE中断DMA的黄金组合 在嵌入式开发中,串口通信就像设备间的"普通话",但如何高效接收不定长数据帧却让不少工程师头疼。想象一下无人机飞控与地面站的通信场景:数据包可能短至几个字节的指…...

AI技术的未来发展方向
AI技术的未来发展方向AI技术的未来发展将围绕以下几个关键领域展开,这些方向不仅推动技术进步,也深刻影响社会和经济结构。通用人工智能(AGI)的探索AGI旨在实现与人类智能相当的通用性,能够跨领域学习和推理。当前研究…...

Windows 11终极优化指南:Win11Debloat一键提升51%系统性能
Windows 11终极优化指南:Win11Debloat一键提升51%系统性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...
)
Python(循环中断)
目录 1.break---终止整个循环 1.1 基本概念 1.2 基本用法示例 1.3 典型应用场景 1.4 break 与 else 的经典搭配 2. continue —— 跳过本次迭代 2.1 基本概念 2.2 基本用法示例 2.3 典型应用场景 2.4 continue与 else 3. break vs continue —— 对比总结 4. pass …...