《异常检测——从经典算法到深度学习》28 UNRAVEL ANOMALIES:基于周期与趋势分解的时间序列异常检测端到端方法
《异常检测——从经典算法到深度学习》
- 0 概论
- 1 基于隔离森林的异常检测算法
- 2 基于LOF的异常检测算法
- 3 基于One-Class SVM的异常检测算法
- 4 基于高斯概率密度异常检测算法
- 5 Opprentice——异常检测经典算法最终篇
- 6 基于重构概率的 VAE 异常检测
- 7 基于条件VAE异常检测
- 8 Donut: 基于 VAE 的 Web 应用周期性 KPI 无监督异常检测
- 9 异常检测资料汇总(持续更新&抛砖引玉)
- 10 Bagel: 基于条件 VAE 的鲁棒无监督KPI异常检测
- 11 ADS: 针对大量出现的KPI流快速部署异常检测模型
- 12 Buzz: 对复杂 KPI 基于VAE对抗训练的非监督异常检测
- 13 MAD: 基于GANs的时间序列数据多元异常检测
- 14 对于流数据基于 RRCF 的异常检测
- 15 通过无监督和主动学习进行实用的白盒异常检测
- 16 基于VAE和LOF的无监督KPI异常检测算法
- 17 基于 VAE-LSTM 混合模型的时间异常检测
- 18 USAD:多元时间序列的无监督异常检测
- 19 OmniAnomaly:基于随机循环网络的多元时间序列鲁棒异常检测
- 20 HotSpot:多维特征 Additive KPI 的异常定位
- 21 Anomaly Transformer: 基于关联差异的时间序列异常检测
- 22 Kontrast: 通过自监督对比学习识别软件变更中的错误
- 23 TimesNet: 用于常规时间序列分析的时间二维变化模型
- 24 TSB-UAD:用于单变量时间序列异常检测的端到端基准套件
- 25 DIF:基于深度隔离林的异常检测算法
- 26 Time-LLM:基于大语言模型的时间序列预测
- 27 Dejavu: Actionable and Interpretable Fault Localization for Recurring Failures in Online Service Systems
- 28 UNRAVEL ANOMALIES:基于周期与趋势分解的时间序列异常检测端到端方法
相关:
- VAE 模型基本原理简单介绍
- GAN 数学原理简单介绍以及代码实践
- 单指标时间序列异常检测——基于重构概率的变分自编码(VAE)代码实现(详细解释)
28. Unravel Anomalies: An End-to-end Seasonal-Trend Decomposition Approach for Time Series Anomaly Detection
论文名称:UNRAVEL ANOMALIES: AN END-TO-END SEASONAL-TREND DECOMPOSITION APPROACH FOR TIME SERIES ANOMALY DETECTION
会议名称:ICASSP 2024
论文地址:ieee | 阿里云盘 |
PPT 下载:https://sigport.org/sites/default/files/docs/TADNet%20Oral.pdf
源码地址:https://github.com/zhangzw16/TADNet

28.1 论文概述
论文很短(除去引用只有4页),我们可以很快地过一遍论文大体内容:


28.2 相关技术
见原文第1节 New insights.
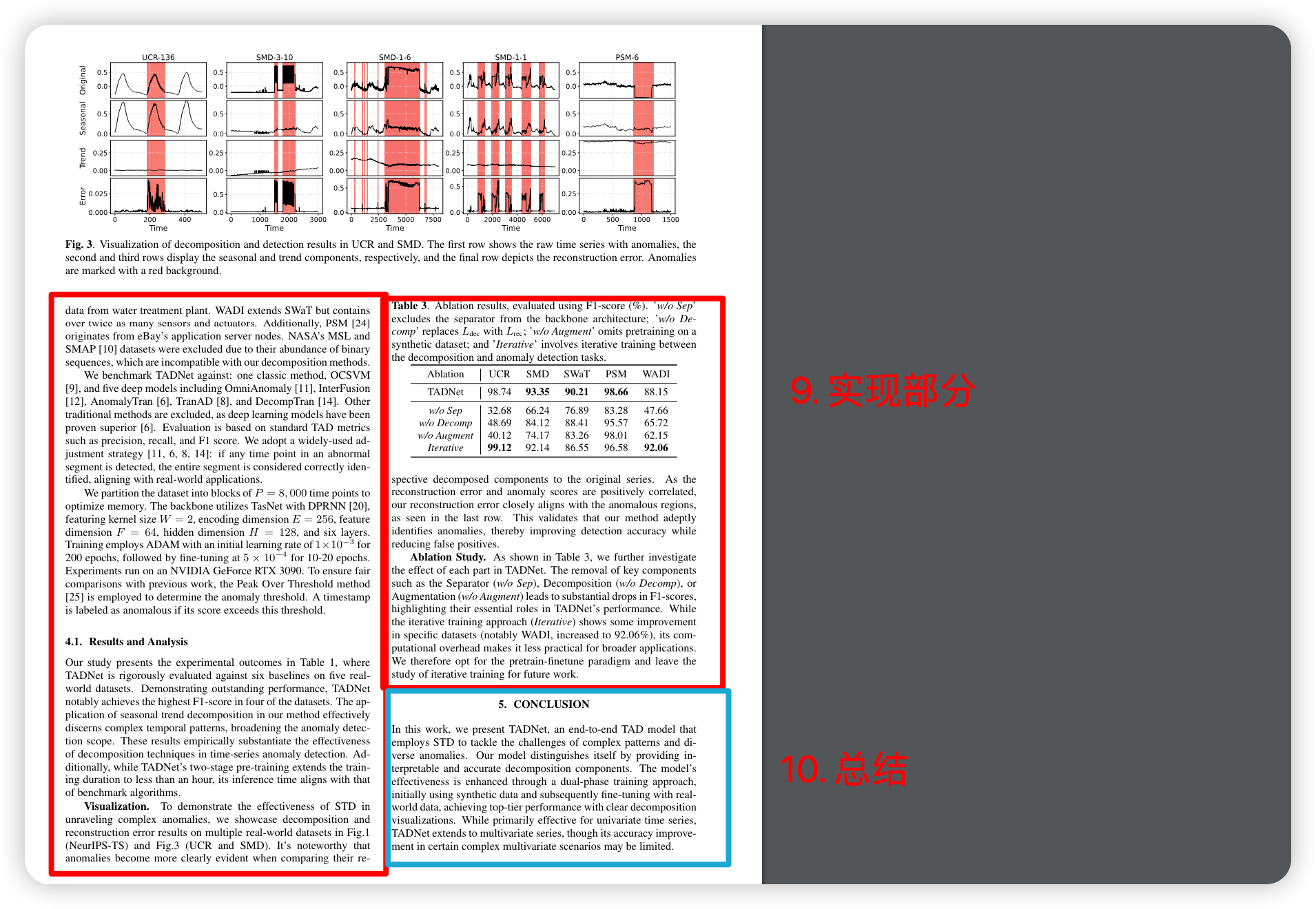
New insights:时间序列本质上由多个重叠模式组成:季节性、趋势和残差。这种重叠性质可能会掩盖不同类型的异常值。使用季节性-趋势分解(STD)的优势在图 1 中有生动的展示,它显示了如何通过将其分离为各自的成分来有效地分离异常值。通过利用 STD 的能力,我们的方法可以独特地分解这些复杂的复合模式。此外,根据文献[4] 提出的分类法,我们发现不同类型的数据异常都可以与相应的组件相关联:季节性异常与季节性成分、趋势异常与趋势成分以及点异常与剩余成分。
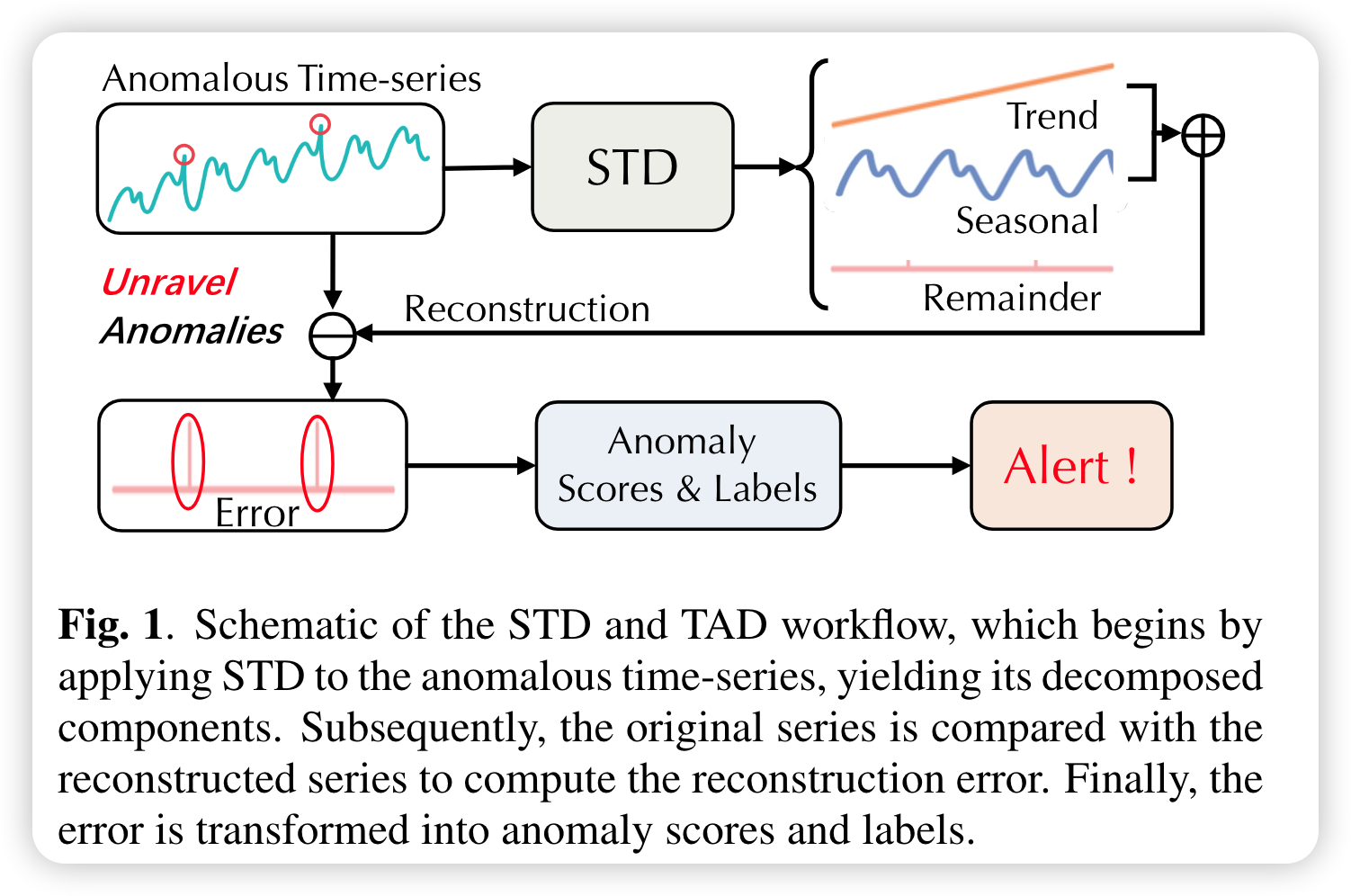
尽管现有研究已将时间序列分解纳入 TAD 任务,但这些方法并不遵循端到端的训练方式。具体而言,它们要么依赖于预定义的分解算法,需要精细的参数调整,要么仅将分解用于数据预处理。为了克服端到端训练缺乏监督信号的问题,我们引入了一种新的两步训练方法。最初,我们生成一个模拟真实世界数据分解成分的合成数据集。首先,我们在这个合成数据集上为分解任务预训练我们的模型。该模型随后根据真实世界的异常数据进行微调,从而增强时间序列分解和异常检测。

时间序列异常检测(Time-Series Anomaly Detection) 考虑一个长度为 T \mathcal{T} T 的时间序列数据集 T ∈ R T × D T \in \mathbb{R}^{\mathcal{T}\times D} T∈RT×D,当 D = 1 D=1 D=1 时称为单变量时间序列,当 D > 1 D>1 D>1 时称为多变量时间序列。TAD 任务的主要目标是在 T \mathcal{T} T 中识别异常,并生成输出序列 Y \mathcal{Y} Y。 Y \mathcal{Y} Y 中的每个元素对应于 T \mathcal{T} T 中相应数据点的异常状态,其中 1 表示异常。为此,使用基于点的方法(Point-wise score method)产生异常分数系列 S = { s 1 , s 2 , . . . , s m } S=\{s_1,s_2,...,s_m\} S={s1,s2,...,sm} ,其中 s i ∈ R s_i \in \mathbb{R} si∈R。然后通过独立阈值处理将这些分数转换为二进制异常标签 Y \mathcal{Y} Y 。
季节性趋势分解 (Seasonal-Trend Decomposition) 对于一个单变量时间序列 x ∈ R T x \in \mathbb{R}^\mathcal{T} x∈RT,它的结构成分包括趋势性和季节性,表示为 x t = τ t + s t + r t x_t=\mathcal{\tau}_t+s_t+r_t xt=τt+st+rt,其中 τ t \tau_t τt、 s t s_t st 和 r t r_t rt 分别表示在第 t t t 个时间戳的趋势、季节性和剩余部分。
TAD 任务的方法的主要重点在于对单变量时间序列进行季节性-趋势分解。当前文献强调了评估每个变量以提高预测准确性的优点。因此,多元时间序列中的每个变量都会经历独立分解,而整体异常检测策略会考虑其多元本征特性。
时域音频分解(Time-domain Audio Separation):此任务可以描述为:给定混合的离散波形 x t ∈ R T x_t\in\mathbb{R}^{T} xt∈RT,对源数据 C \mathcal{C} C( s t ( 1 ) , … , s t ( C ) ∈ R T s_t^{(1)},\ldots,s_t^{(C)}\in \mathbb{R}^{T} st(1),…,st(C)∈RT) 进行评估时 。从数学上讲,这表示为 x t = ∑ i = 1 C s t ( i ) x_t=\sum_{i=1}^C s_t^{(i)} xt=∑i=1Cst(i)。
单声道音频源分离领域已经通过各种深度学习模型取得了进展。TasNet 在此领域引入了端到端学习的概念。Conv-TasNet 通过集成卷积层进一步发展了这种方法。DPRNN 专注于通过循环神经网络改善长期建模。最近,像 SepFormer 这样的架构整合了注意力机制。
时域音频分离的理论框架与季节性趋势分解任务表现出惊人的相似性,从而使我们思考在这些领域之间可能的方法转换,以改进时间序列分解和异常检测。
28.3 核心方法
28.3.1 总体架构 Overall Framework
TADNet 的总体流程图如图 2 所示。预处理包括数据标准化 normalization 和分段(segmentation)。首先将输入数据被归一化到 [0,1) 范围内。分段采用长度为 P P P 的滑动窗口方法,将归一化的 T \mathcal{T} T 转换为长度为 P P P 的非重叠块(non-overlap blocks),表示为 D = X 1 , X 2 , … , X N \mathcal{D}={\mathcal{X}_1,\mathcal{X}_2,\ldots,\mathcal{X}_N} D=X1,X2,…,XN。值得注意的是,虽然分段提供了更灵活的方法来管理较长的序列,但它不会影响结果。
在 TADNet 主干网中,我们利用TasNet架构及其语音(speech separation)分离的变体。将季节和趋势分量视为不同的音频信号,如图 2 所示,TasNet 有助于有效的 STD。
由于训练只使用正常样本,异常情况通常会破坏重构过程。为了检测这些异常值,我们计算重构误差,表示为 S c o r e ( t ) = ∥ T t , : − T t , : ∥ 2 Score(t) = \parallel \mathcal{T}_{t,:}-\mathcal{T}_{t,:} \parallel_2 Score(t)=∥Tt,:−Tt,:∥2,其中 ∥ ⋅ ∥ 2 \parallel \cdot \parallel_2 ∥⋅∥2 表示 L2 范数。

28.3.2 TADNet 主要部分
编码器接受单变量时间序列 x d ∈ R P x_d\in\mathbb{R}^P xd∈RP,其中 d = 1 , 2 , … , D d=1,2,\ldots,D d=1,2,…,D 来源于多元变量 X i \mathcal{X}_i Xi。它将该序列划分为多个重叠窗口(frames)。每个窗口具有长度 L L L,并且与相邻窗口重叠 S S S 个步长。然后按顺序将这些窗口合并为 X d ∈ R L × K \mathbf{X}_d\in\mathbb{R}^{L\times K} Xd∈RL×K。通过随后的线性变换,编码器将 X d \mathbf{X}_d Xd映射到潜在空间 E = U X d \mathbf{E}=\mathbf{U}\mathbf{X}_d E=UXd。矩阵 U ∈ R N × L \mathbf{U} \in \mathbb{R}^{N\times L} U∈RN×L 的行(rows) 包含可训练的转换基(transformation),而 E ∈ R N × K \mathbf{E} \in \mathbb{R}^{N\times K} E∈RN×K 表示输入时间序列在潜在空间中的特征表示。
分离器接收编码表示,并负责为分解的每个组件生成掩码(masks)。形式上表示为, { M T , M s , M r } = F sep ( E ; θ ) \{\mathbf{M_\mathcal{T}},\mathbf{M_\mathcal{s},\mathbf{M_\mathcal{r}}}\} = \mathcal{F}_{\text{sep}}(\mathbf{E;\theta}) {MT,Ms,Mr}=Fsep(E;θ) ,其中 M T \mathbf{M_\mathcal{T}} MT, M s \mathbf{M_\mathcal{s}} Ms 和 M r \mathbf{M_\mathcal{r}} Mr分别表示趋势、季节性和剩余成分的掩码。在这里, F sep \mathcal{F}_\text{sep} Fsep 表示分离子网络,可以使用各种架构如CNN,RNN或者Transformer 来实现。利用这些掩码,全局特征 E \mathbf{E} E 中每个目标的嵌入是:
E τ = M τ ⊙ E , E s = M s ⊙ E , E r = M r ⊙ E (1) \mathbf{E}_\tau=\mathbf{M}_\tau \odot \mathbf{E}, \quad \mathbf{E}_s=\mathbf{M}_s \odot \mathbf{E}, \quad \mathbf{E}_r=\mathbf{M}_r \odot \mathbf{E} \tag{1} Eτ=Mτ⊙E,Es=Ms⊙E,Er=Mr⊙E(1)
通过相应掩模的逐点乘积来实现。
解码器架构镜像编码器,采用分离器生成的屏蔽嵌入。这些嵌入通过线性变换 V V V 被映射回时域。
S ^ τ = E τ T V , S ^ s = E s T V , S ^ r = E r T V (2) \hat{\mathbf{S}}_\tau=\mathbf{E}_\tau^T \mathbf{V}, \quad \hat{\mathbf{S}}_s=\mathbf{E}_s^T \mathbf{V}, \quad \hat{\mathbf{S}}_r=\mathbf{E}_r^T \mathbf{V} \tag{2} S^τ=EτTV,S^s=EsTV,S^r=ErTV(2)
这里, V ∈ R N × L V\in \mathbb{R}^{N \times L} V∈RN×L 有 N N N 个解码器基 (decoder bases)。重构的趋势、季节性和余数,表示为 S ^ T \hat{\mathbf{S}}_\mathcal{T} S^T、 S ^ S \hat{\mathbf{S}}_\mathcal{S} S^S 和 S ^ r \hat{\mathbf{S}}_\mathcal{r} S^r,是从它们各自的嵌入中导出的。输出时域信号通过重叠和相加运算(overlap-and-add operation)获得 T d ^ \hat{\mathcal{T}_d} Td^, s d ^ \hat{\mathcal{s}_d} sd^, r d ^ \hat{\mathcal{r}_d} rd^ 。
28.3.3 合成数据集
在异常检测中,现实世界的数据通常缺乏 STD 所必需的微妙趋势和季节性模式。为了使 TADnet 具有鲁棒的 STD 能力,我们构建了一个合成数据集。该数据集经过精心设计,具有复杂的季节性和趋势变化、异常值和噪声,以模拟真实环境,如图 1 所示。确定性和随机趋势都被用来构造趋势和季节成分,然后对其进行归一化,以保持零均值和单位方差。
趋势(Trend) 确定性趋势使用具有固定系数的线性趋势函数生成: τ t ( d ) = β 0 + β 1 ⋅ t \tau^{(d)}_t=\beta_0 +\beta_1 \cdot t τt(d)=β0+β1⋅t,其中 β 0 \beta_0 β0 和 β 1 \beta _{1} β1 是可调参数。 随机趋势成分通过 ARIMA (0,2,0) 过程进行建模,并按如下方式整合到趋势模型中:
τ t ( s ) = ∑ n = 1 t n X n \tau^{(s)}_{t} = \sum_{n = 1}^{t} n X _{n} τt(s)=∑n=1tnXn ,其中 X t X_t Xt 是服从正态分布的白噪声项,满足 Δ 2 τ t ( s ) = X t \Delta ^ {2} \tau^{(s)}_{t} = X_t Δ2τt(s)=Xt。
周期性(Seasonal) 确定性的季节性成分结合了各种类型的周期信号。它包括振幅、频率和相位随时间变化的正弦波,以及振幅、周期和相位各不相同的方波。
对于缓慢变化的随机序列,季节性成分由重复的周期组成一个缓慢变化的趋势系列 τ t ( s ) \tau_t^{(s)} τt(s)。 这个系列是由趋势生成算法生成的,以确保在周期之间平滑过渡。 每个周期都由周期 T 0 T_0 T0 和相位 ϕ \phi ϕ 唯一地刻画出来。 随机季节性分量因此被定义为 s t = τ mod ( t + ϕ , T 0 ) ( s ) s_t = \tau^{(s)}_{\text{mod}(t+\phi,T_0)} st=τmod(t+ϕ,T0)(s) 。
为了丰富数据集,我们对周期长度和振幅进行了一些微调,包括重新采样单个周期并对周期内的值进行缩放,以实现更多样化和泛化的信号分解。
余项(Remainder) 通过使用具有可调方差的白噪声过程来定义余项部分。
为了增强分解模型对异常值的鲁棒性并确保稳定的分解性能,我们按照文献 [4] 中概述的方法向合成数据集中注入了部分异常值。
28.3.4 两阶段训练策略(Two-Phase Training Strategy)
我们为TADnet提出了一个两阶段训练策略,以确保其在时间序列分解和异常检测中的有效性。
在第一阶段,TADnet 在合成数据集上进行预训练,重点是时间序列分解。相应的损失函数由下列公式给出:
L d e c = ∑ d = 1 D ( ∥ τ d − τ ^ d ∥ 2 2 + ∥ s d − s ^ d ∥ 2 2 + ∥ r d − r ^ d ∥ 2 2 ) (3) L_{\mathrm{dec}}=\sum_{d=1}^D\left(\left\|\tau_d-\hat{\tau}_d\right\|_2^2+\left\|s_d-\hat{s}_d\right\|_2^2+\left\|r_d-\hat{r}_d\right\|_2^2\right) \tag{3} Ldec=d=1∑D(∥τd−τ^d∥22+∥sd−s^d∥22+∥rd−r^d∥22)(3)
这里, τ d \tau_d τd、 s d s_d sd 和 r d r_d rd 分别表示第 d d d 维度的实际季节性、趋势性和残差分量,而 τ d \tau_d τd、 s d s_d sd 和 r d r_d rd 则分别表示其预测值。
在第二阶段,使用一个真实的TAD数据集来微调TADnet。 这个阶段强调了在分解后准确重建原始时间序列,这是有效检测异常的关键要求。 该阶段的重点是整体重构精度的损失函数如下:
L r e c = ∑ d = 1 D ∥ x d − ( τ ^ d + s ^ d ) ∥ 2 2 (4) L_{\mathrm{rec}}=\sum_{d=1}^D\left\|x_d-\left(\hat{\tau}_d+\hat{s}_d\right)\right\|_2^2 \tag{4} Lrec=d=1∑D∥xd−(τ^d+s^d)∥22(4)
这里, x d x_d xd 表示在第 d d d 维上的原始时间序列, τ ^ d + s ^ d \hat{\tau}_d + \hat{s}_d τ^d+s^d 是其预测重构。
28.4 源码分析
源码地址为:https://github.com/zhangzw16/TADNet/tree/main
这里只对项目各个 .py 文件的功能概述:
- pot:
constants.py主要用于配置和初始化一个时间序列异常检测任务的参数;pot.py用于评估时间序列异常检测模型的性能,包括采用Point-Onset (POT) 方法进行异常检测,并计算相关的评估指标。spot.py实现了 SPOT 、 biSPOT、dSPOT、bidSPOT 四个算法,在 pot.py 文件中使用。
- src:
data.py数据读取与格式转换等,用于处理音频数据的PyTorch自定义数据集和数据加载器。loss.py损失函数、损失的计算相关函数;mask.py该函数用于在给定数组arr中随机选择一个长度为len0的子数组,并将该子数组用零填充,然后返回填充后的数组和选择的子数组的起始和结束位置。models.py模型核心相关内容,应用循环神经网络(RNN)和Sepformer进行音频信号处理。preprocess.py主要实现了对指定目录下的.npy文件进行预处理的功能separate.py一个使用FaSNet_base模型进行时间序列分离的程序。solver.py类用于训练和验证深度学习模型。它接收数据加载器、模型、优化器和参数,然后在多个epoch上执行训练和交叉验证。训练过程中,每过一定epoch会调整学习率,并保存最佳验证性能的模型。_run_one_epoch方法处理单个epoch的训练或验证,包括前向传播、计算损失和(在训练时)反向传播。test.py测试类train.py一个命令行接口,用于使用FaSNet_base模型进行时间序列异常检测网络的训练。utils.py相关工具类
- synthetic:合成数据
anomaly.py用于生成包含异常子信号的序列。类初始化时接受两个参数:amplitude表示序列的振幅,默认为1;type表示异常类型,可选值为’point’、‘interval’、‘contextual’、‘collective’、‘shapelet’、‘noise’。类中的generate方法接受一个时间序列作为输入,并根据设定的异常类型,在时间序列中添加相应的异常子信号,最后返回生成的异常序列。const.py相关参数常量。generate.py生成具有给定信息的完整序列。main.py这段代码主要实现了从给定的pk_info信息中生成时间序列数据,并将其分为趋势、噪声、季节性和完整序列四类,然后将这些序列保存到指定的文件夹中。noise.py用于生成具有给定振幅的噪声序列season.py周期性相关代码trend.py趋势性相关代码
run.py: 执行入口
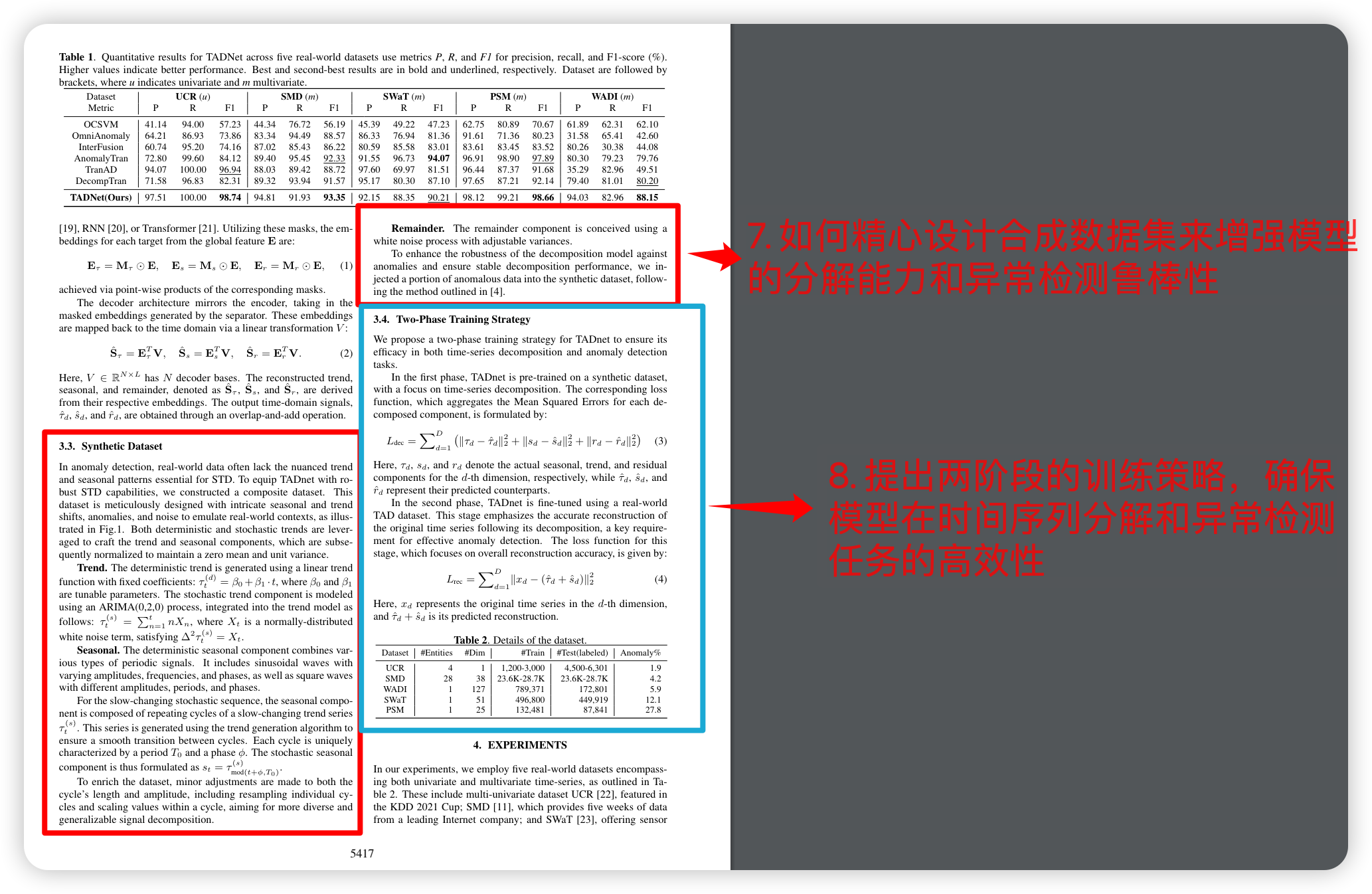
28.5 Ablation Study (消融学习)
论文中提出的Ablation Study是一种系统性的实验方法,用于评估模型或算法中各个组成部分对整体性能的贡献。通过有选择地移除或替换模型的部分组件(例如,在TADNet模型中的Separator、Decomposition模块或数据增强预训练步骤),并观察模型性能的变化,特别是使用F1分数作为评价指标,研究者能够量化每个部分的重要性。
在TADNet的Ablation Study中,进行了以下实验:
-
w/o Sep:移除了模型中的Separator(分隔器),导致所有数据集上的F1分数显著下降,显示了Separator在区分和处理时间序列复杂模式中的关键作用。
-
w/o Decomp:将分解模块(Ldec)替换为一个简单的重建模块(Lrec),导致性能降低,强调了季节趋势分解在异常检测任务中的有效性。
-
w/o Augment:省略了在合成数据集上的预训练步骤,降低了模型在所有数据集上的表现,证明了预训练对于提升模型在真实世界数据上的表现至关重要。
-
Iterative:采用迭代训练方法,在分解和异常检测任务之间交替进行训练,虽然在特定数据集(如WADI)上提高了F1分数至92.06%,但考虑到增加的计算成本,作者选择了预训练-微调范式作为主要方法,并认为迭代训练的进一步探索可以留作未来工作。
通过这些Ablation Study,研究者不仅验证了TADNet各组成部分的有效性,而且为模型的优化和调整提供了指导,同时也为读者展示了如何在自己的研究中实施类似的实验来深入理解模型内部机制和组件的功能。
28.5 本章总结
论文提出了一种名为TADNet的模型,用于有效识别时间序列中的异常。该模型通过将复杂的时间序列数据分解为季节性、趋势和残差三个组成部分来简化分析,并与各类异常关联,从而提升检测性能。
TADNet采用两阶段训练策略。首先,在合成数据集上进行预训练,该数据集包含了模拟的季节性、趋势和残差组件,以及故意注入的异常数据以增强模型鲁棒性。预训练阶段的损失函数旨在最小化每个分解组件(季节性、趋势和残差)的均方误差。其次,模型在真实世界的时间序列异常检测(TAD)数据集上进行微调,重点是精确重构原始时间序列,这对于有效异常检测至关重要。此阶段的损失函数关注于整体重构精度。
论文还介绍了合成数据集中各组成部分的生成方法,如确定性季节性成分结合了不同幅度、频率和相位的正弦波及方波,慢变随机序列的周期性趋势则通过特定算法生成以确保周期间平滑过渡。此外,为了丰富数据集并提高信号分解的多样性和泛化能力,对周期长度和振幅进行了微调。
论文可以参考的地方:
-
端到端季节趋势分解(STD):TADNet利用季节趋势分解将时间序列拆解成季节性、趋势和残余三个部分,这有助于单独分析和理解每个部分的异常,简化了复杂时间序列的分析过程。
-
两阶段训练策略:首先在合成数据集上预训练模型以学习如何有效地分解时间序列,然后在真实世界的异常检测数据集上微调,平衡了有效分解与精确异常检测的需求。这种策略可以作为新算法设计中数据处理和模型优化的重要参考。
-
合成数据集生成:论文中详细介绍了一种合成数据集的生成方法,包括慢变随机序列、包含各种周期信号的季节性组件以及残差组件的白噪声过程,甚至在其中注入异常数据以增强模型的鲁棒性。这种方法可以用来为新算法设计提供高质量的训练数据,尤其是在缺乏足够标注的真实数据情况下。
-
Ablation Study:(详情请参考原论文 4.1节 Ablation Study )通过对模型不同组件(如分离器、分解模块、数据增强步骤和迭代训练策略)的消融实验,论文揭示了每个部分对模型性能的重要性。在设计新算法时,可以借鉴这些发现来决定哪些组件是必不可少的,以及它们如何影响最终性能。
-
Reconstruction-based Anomaly Detection:(前面提到的 Donut / Bagel / LOF-VAE 等都是这类算法)通过计算重构误差来检测异常,该方法简单直观且有效。模型预测的重构误差与实际异常区域高度相关,表明这种方法能准确识别异常同时减少误报。
-
可解释性:TADNet不仅提高了检测准确性,还提供了清晰的分解可视化,使得结果具有更强的可解释性。新算法设计时考虑增强模型的解释能力,有助于用户理解和信任检测结果。
-
适应多变量时间序列:尽管主要针对单变量时间序列设计,TADNet也扩展到了多变量场景。虽然在某些复杂多变量情况下可能面临限制,但其框架为处理更广泛的数据类型提供了基础。
希望能帮到各位小伙伴 ~ 万分感谢各位的点赞、评论与关注支持 ~

Smileyan
2024.05.20 00:17
相关文章:
《异常检测——从经典算法到深度学习》28 UNRAVEL ANOMALIES:基于周期与趋势分解的时间序列异常检测端到端方法
《异常检测——从经典算法到深度学习》 0 概论1 基于隔离森林的异常检测算法 2 基于LOF的异常检测算法3 基于One-Class SVM的异常检测算法4 基于高斯概率密度异常检测算法5 Opprentice——异常检测经典算法最终篇6 基于重构概率的 VAE 异常检测7 基于条件VAE异常检测8 Donut: …...

Python正则模块re方法介绍
Python 的 re 模块提供了多种方法来处理正则表达式。以下是一些常用的方法及其功能介绍: 1. re.match() 在字符串的开始位置进行匹配。 import repattern r\d string "123abc456"match re.match(pattern, string) if match:print(f"匹配的字符…...

pdf使用pdfbox切割pdf文件MultipartFile
引入依赖: <dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.25</version></dependency>测试代码: import io.choerodon.core.iam.ResourceLevel; impo…...

力扣HOT100 - 31. 下一个排列
解题思路: 数字是逐步增大的 步骤如下: class Solution {public void nextPermutation(int[] nums) {int i nums.length - 2;while (i > 0 && nums[i] > nums[i 1]) i--;if (i > 0) {int j nums.length - 1;while (j > 0 &&…...
设计模式 20 中介者模式 Mediator Pattern
设计模式 20 中介者模式 Mediator Pattern 1.定义 中介者模式(Mediator Pattern)是一种行为型设计模式,它通过封装对象之间的交互,促进对象之间的解耦合。中介者模式的核心思想是引入一个中介者对象,将系统中对象之间…...

在 C++ 中,p->name 和 p.name 的效果并不相同。它们用于不同的情况,取决于你是否通过指针访问结构体成员。
p->name:这是指针访问运算符(箭头运算符)。当 p 是一个指向结构体的指针时,用 p->name 来访问结构体的成员。 student* p &stu; // p 是一个指向 student 类型的指针 cout << p->name << endl; // 通过…...

C++基础:多态
多态相关 多态继承重写父类的虚函数多态的体现,父类的引用指向子类对象的空间虚函数可以实现,也可以不实现,不实现必须要有初始值存在未定义的虚函数的类为抽象类.抽象类不能实例化对象;(animal父类不能实例化对象)如果父类中的函数非虚函数,则会调用父类中的函数//多态的体现…...
)
移除元素(算法题)
文章目录 移除元素解题思路 移除元素 给你一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并原地修改输入数组。 元素的顺序可以改变。…...
电商场景的视频动效
AtomoVideo:AIGC赋能下的电商视频动效生成本文分享阿里妈妈视频 AIGC(AtomoVideo等) 赋能视频广告创意的探索和实践。通过基于扩散模型的视频生成技术,结合可控生成技术,使静态电商图片能够栩栩如生地“动”起来,实现了在电商领域的视频 AIGC 应用落地。https://mp.weixi…...

Windows操作系统基本知识整理
目录 引言 一、Windows操作系统的发展历史 1.1 Windows 1.0到Windows 3.0 1.2 Windows 95到Windows Me 1.3 Windows NT到Windows 2000 1.4 Windows XP到Windows 7 1.5 Windows 8到Windows 10 二、Windows操作系统的核心组件 2.1 内核 2.2 文件系统 2.3 图形用户界面&…...

Vue 状态管理深入研究:Vuex 和 Pinia 的原理与实践对比
推荐一个AI网站,免费使用豆包AI模型,快去白嫖👉海鲸AI 👋 引言 在 Vue.js 应用程序中,状态管理是一个至关重要的方面。它有助于集中管理应用的状态,使组件之间的数据共享更加高效和可维护。Vuex 和 Pinia …...
【三数之和】python,排序+双指针
暴力搜索3次方的时间复杂度,大抵超时 遇到不会先排序 排序双指针 上题解 照做 class Solution:def threeSum(self, nums: List[int]) -> List[List[int]]:res[]nlen(nums)#排序降低复杂度nums.sort()k0#留两个位置给双指针i,jfor k in range(n-2):if nums[k]…...
)
TCP通信实现(服务端与客户端)
TCP通信实现(服务器端) 案例 // TCP 通信的服务器端#include <stdio.h> #include <arpa/inet.h> #include <unistd.h> #include <string.h> #include <stdlib.h>int main() {// 1.创建socket(用于监听的套接字)int lfd socket(AF_…...

安装appium自动化测试环境,我自己的版本信息
教程来自:Appium原理与安装 - 白月黑羽 我的软件的版本: 安装是选择为自己安装而不是选all user pip install appium-python-client命令在项目根目录下安装appium-python-client sdk的话最简单的安装方式就是去Android官网下一个android studio然后在…...

【讲解下Web前端三大主流的框架】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...
视频监控平台AS-V1000产品介绍:账户或用户数据的导入和导出功能介绍
目录 一、功能描述 (一)导入功能定义 (二)导出功能定义 二、用户数据的导入导出的作用 三、AS-V1000新版本的导出和导入功能介绍 (一)功能主界面 (二)导出功能 1、导出操作 …...
markdown画时序图的时候,如何自动显示每一条时序的序号
1: 现象描述 今天画时序图的时候,发现时序上面没有显示序号,看起来不够清晰,只有单纯的说明; 如下图所示 刚测试CSDN的时序图,默认是带序号的,看起来和实际使用的markdown工具有关系; 2:解决办…...

朴素贝叶斯
经典三门问题 问题 一种说法(直觉派) 另一种说法(贝叶斯派) 注意P(B)1, 已经知道路人抽中的就是绿豆 三门问题在网上争端比较大,分为直觉派和贝叶斯派,最后一个程序员出来写程序跑了一遍,发现就是贝叶斯派 朴素贝叶斯的直观理解 在X的条件下分别等于0~9的概率 注意之前我们讲的…...

【软件设计师】——10.面向对象技术
目录 10.1 基本概念 10.2设计原则 10.3 设计模式的概念与分类 10.4 创建型模式 10.4.1 Singleton 单例模式 10.4.2 Builder 构建器模式 10.4.3 Abstract Factory 抽象工厂模式 10.4.4 Prototype原型模式 10.4.5 Factory Method工厂方法模式 10.5 结构型模式 10.5.1 A…...

唐山无人机航拍,唐山无人机建模,唐山数据孪生
随着数字经济发展,各地逐渐兴起了无人机低空经济;尤其是无人机航拍,无人机建模;目前技术很成熟;比如水利部提出的数字孪生,四预的实现,都要通过无人机采集底层数据; 目前无人机建模…...
)
手把手教你用AD9834 DDS模块DIY一个可调信号源(附AD原理图/PCB/程序)
从零构建AD9834 DDS可调信号源:硬件搭建与软件调优全指南 在电子设计与射频实验中,一个稳定可靠的可调信号源是不可或缺的工具。商用信号发生器往往价格昂贵,而基于AD9834 DDS模块的DIY方案,能以极低成本实现0-10MHz频率范围内的高…...

VN设备通道乱序问题解析与Vector硬件固定配置实战
1. 问题根源:为什么VN设备的通道会“乱跑”?在汽车电子测试领域,Vector的VN系列设备(如VN1640A、VN1610等)是进行CAN、LIN、FlexRay等总线通信测试与仿真的核心工具。当我们在一个复杂的台架上部署了多台同型号的VN设备…...

tcpdump 核心选项与过滤表达式实战指南:从基础到高效网络排查
1. 从命令行到洞察力:为什么你需要精通 tcpdump如果你在运维、开发或者网络安全领域工作,网络问题排查几乎是你绕不开的日常。当服务调用超时、接口响应异常,或者流量出现诡异波动时,你需要的不是猜测,而是证据。tcpdu…...
)
手把手教你修复‘MsBuild.exe不是内部或外部命令’(附Win10/Win11环境变量配置详解)
手把手教你解决‘MsBuild.exe不是内部或外部命令’问题 第一次在命令行里敲下msbuild却看到系统报错"不是内部或外部命令"时,那种挫败感我至今记忆犹新。作为.NET开发者必备的核心工具,MSBuild的配置问题困扰过无数新手。本文将用最直观的方式…...

Open Generative AI与Stable Diffusion对比:开源AI生成平台的5大优势
Open Generative AI与Stable Diffusion对比:开源AI生成平台的5大优势 【免费下载链接】Open-Generative-AI Open-source alternative to AI video platforms — Free AI image & video generation studio with 200 models (Flux, Midjourney, Kling, Sora, Veo)…...

WordPress与PageAdmin CMS深度技术对比:从架构到国产化合规的全维度分析
摘要在内容管理系统选型中,WordPress作为全球市场占有率最高的开源CMS,与国内企业级平台PageAdmin CMS代表了两种不同的技术路线。本文从底层架构(PHP vs .NET Core)、数据库设计、缓存策略、安全机制、二次开发能力、国产化适配及…...
:含12个领域专属风格锚点模板与冲突检测CLI工具)
NotebookLM风格一致性密钥库(仅限首批200位AI架构师开放获取):含12个领域专属风格锚点模板与冲突检测CLI工具
更多请点击: https://kaifayun.com 第一章:NotebookLM风格一致性密钥库的演进逻辑与核心价值 NotebookLM 风格的一致性密钥库并非传统密码学密钥管理系统的简单复刻,而是面向语义化知识协作场景深度重构的基础设施。其演进逻辑根植于三个关键…...

腾讯云服务器跑通 Cube Sandbox:从 PVM 内核到 65 ms 冷启动的全程实战
腾讯云服务器跑通 Cube Sandbox:从 PVM 内核到 65 ms 冷启动的全程实战 适合第一次想把 Cube Sandbox 真正跑起来的开发者。本文用一台普通腾讯云 CVM(OpenCloudOS 9.4 / 8C16G / 无嵌套虚拟化),从空白系统一路推到 Sandbox.creat…...

FastAdmin任意文件读取漏洞CVE-2024-7928深度解析与三阶段修复
1. 这个漏洞不是“能读任意文件”那么简单,而是整个FastAdmin旧版本的信任基石崩塌了你可能在安全通报里看到过CVE-2024-7928的简短描述:“FastAdmin框架存在任意文件读取漏洞”,甚至有些文章直接写成“可读取服务器任意配置文件”。但我在给…...

3分钟完成Windows和Office永久激活:KMS_VL_ALL_AIO智能激活方案完全指南
3分钟完成Windows和Office永久激活:KMS_VL_ALL_AIO智能激活方案完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为系统激活烦恼吗?每次重装系统或安装Office…...