图解 Transformer
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学.
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
汇总合集:《大模型面试宝典》(2024版) 发布!
一、引言
随着大型语言模型如 ChatGPT 的横空出世,我们进入了自然语言处理(NLP)的一个新纪元。在这个纪元中,Transformer 架构扮演着至关重要的角色。其独特之处不仅在于其技术上的突破,更在于它如何彻底改变了我们对语言模型潜力的理解。
Transformer是一种深度学习架构,它使用注意力来显著提高深度学习 NLP 翻译模型的性能,其首次在论文《Attention is all you need》中出现。其问世标志着从序列建模的传统方法(如长短期记忆网络和门控循环单元)转变到一个更加高效、更能捕捉复杂语言模式的新框架,它允许模型同时处理输入序列的所有元素,并捕捉它们之间的复杂关系。这种全面的注意力机制使得Transformer在处理长序列时,相比于其前辈们更加高效与准确。
Transformer 的以上特点不仅提高了模型处理语言的能力,还极大增强了其学习复杂语言模式的能力。使得类 GPT 系列这样的模型,不仅能理解和生成自然语言,还能在多种任务上表现出色,如文本摘要、问答、翻译等。这种多功能性和灵活性的提升,为我们处理和理解自然语言提供了前所未有的可能性。
本文来自于 2023 年初翻译的 Ketan Doshi 博客中关于 Transformer 的系列文章。作者在系列文章中,介绍了 Transformer 的基本知识,架构,及其内部工作方式,并深入剖析了 Transformer 内部的细节。
系列文章共有四篇,本文为第一篇,主要从整体上介绍了 Transformer 的整体架构,工作过程。
二、何为 Transformer?
Transformer 架构擅长处理文本数据,这些数据本身是有顺序的。它们将一个文本序列作为输入,并产生另一个文本序列作为输出。例如,将一个输入的英语句子翻译成西班牙语。
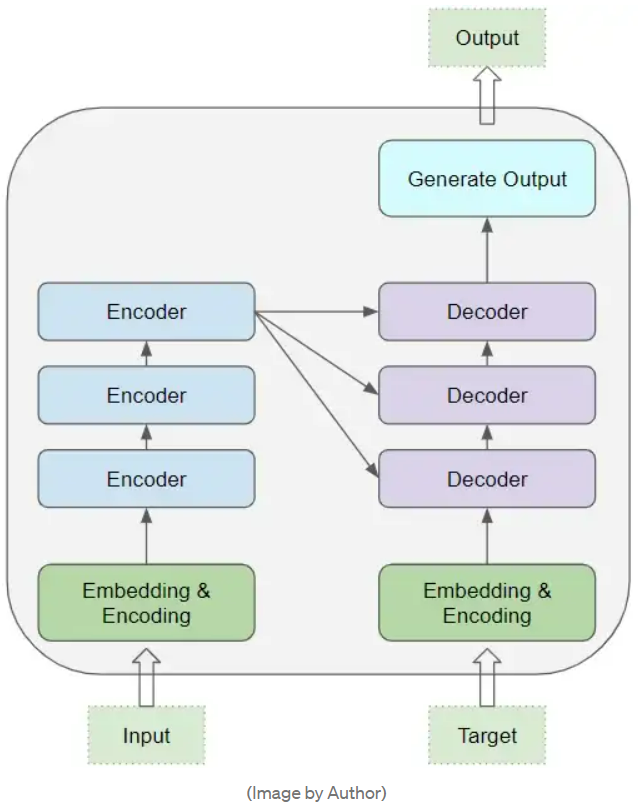
Transformer 的核心部分,包含一个编码器层和解码器层的堆栈。为了避免混淆,我们把单个层称为编码器或解码器,并使用 编码器堆栈 或 解码器堆栈 分别表示一组编码器与一组解码器。(原文为 Encoder stack 和_Decoder stack_)。
在 编码器堆栈 和 解码器堆栈 之前,都有对应的嵌入层。而在 解码器堆栈 后,有一个输出层来生成最终的输出。
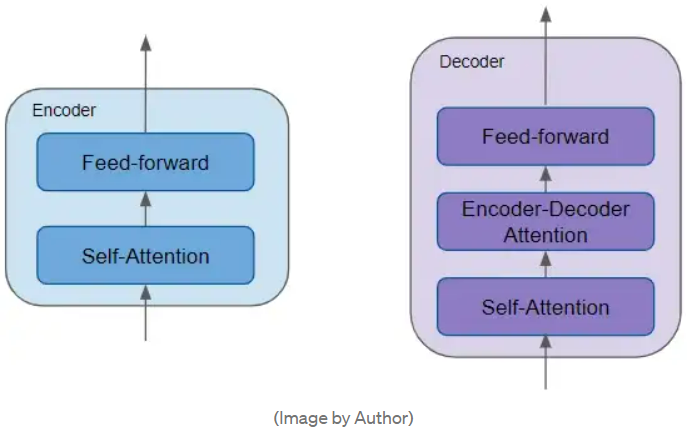
编码器堆栈中的每个编码器的结构相同。解码器堆栈亦然。其各自结构如下:
-
编码器:一般有两个子层:包含自注意力层 self-attention,用于计算序列中不同词之间的关系;同时包含一个前馈层 feed-forward。
-
解码器:一般有三个子层:包含自注意力层_self-attention_,前馈层 feed-forward,编码器-解码器注意力层 Decoder-Encoder self attention。
-
每个编码器和解码器都有独属于本层的一组权重。
注意,编码器与解码器的自注意力层 self-attention、前馈层 feed-forward,以及解码器中的 编码器-解码器注意力 层 Decoder-Encoder self attention 均有残差连接以及正则化层。
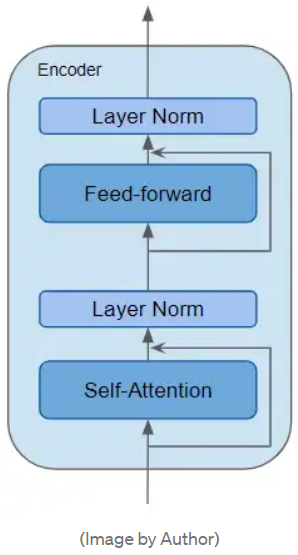
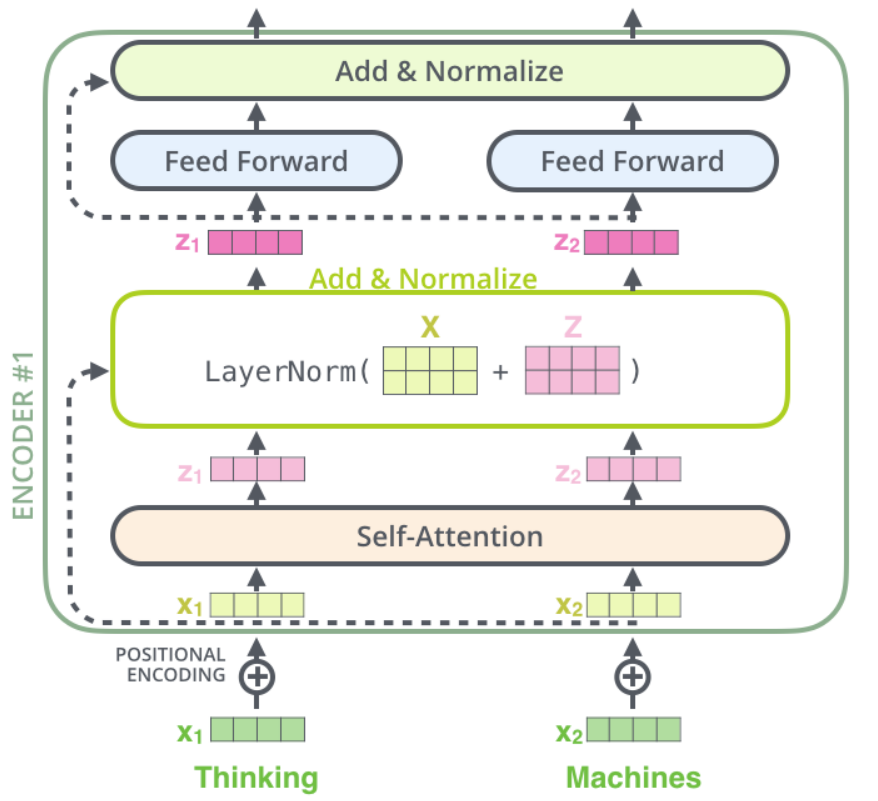
基于 Transformer 的变体有许多。一些 Transformer 架构甚至没有 Decoder 结构,而仅仅依赖 Encoder。
三、Attention 在做什么?
Transformer 的突破性表现关键在于其对注意力的使用。
在处理一个单词时,注意力使模型能够关注输入中与该单词密切相关的其他单词。
例如,在以下的英文句子中,ball 与 blue 、hold 密切相关。另一方面,boy 与 blue 没有关系。

Transformer 通过将输入序列中的_每个词与其他词_关联起来(同一序列中),形成 self-attention 机制。
考虑以下两个句子:
-
The cat drank the milk because it was hungry.
-
The cat drank the milk because it was sweet.
第一个句子中,单词 ‘it’ 指‘cat’;第二个句子中,‘it’ 指 ‘milk’。当模型处理 'it’这个词时,self-attention 给了模型更多关于 ‘it’ 意义的信息,这样就能把 'it '与正确的词联系起来。

为了使模型能够处理有关于句子意图和语义的更多细微差别,Transformer 对每个单词都进行注意力打分**。**
在处理 "it "这个词时,第一个分数突出 “cat”,而第二个分数突出 “hungry”。因此,当模型解码’it’这个词时,即把它翻译成另一种语言的单词时,将会把 ‘cat’ 和 ‘hungry’ 某些语义方面的性质纳入到目标语言中。

四、Transformer 训练过程
Transformer 的训练和推理有一些细微差别。
首先来看训练。每一条训练数据都包括两部分内容:
-
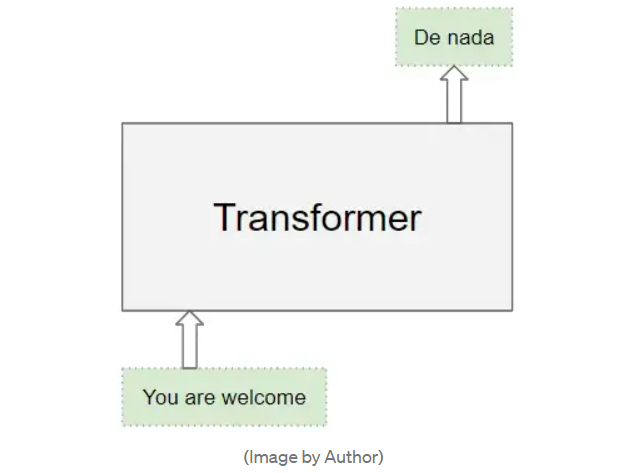
输入序列,或称为“源序列”(例如对于一个翻译问题,“You are welcome” 是一个输入序列)
-
输出序列,或称为“目标序列(上述的翻译问题 “De nada” 即为“You are welcome” 的西班牙语翻译,为输出序列)
而 Transformer 训练的目标就是,通过对训练数据中源序列与目标序列之间规律的学习,在测试或实际的任务中,给定源序列,生成目标序列。
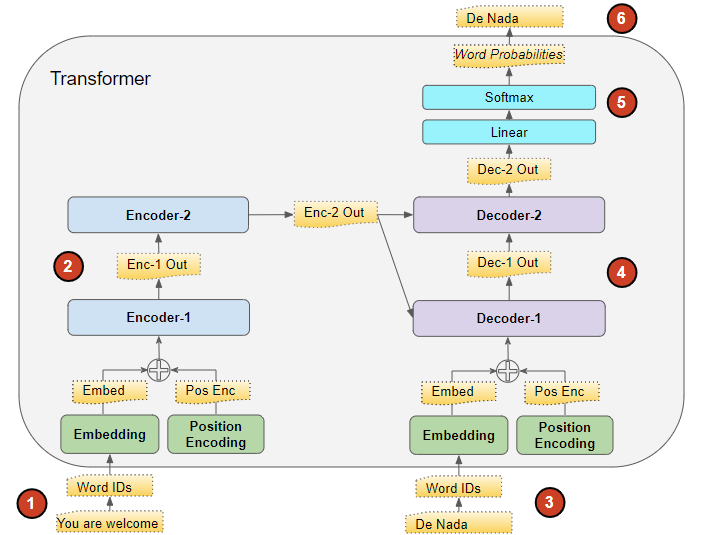
如上图所示,Transformer在训练过程中,模型对数据的处理过程如下,大体可分为 6 个步骤:
-
在送入第一个编码器之前,输入序列 (src_seq) 首先被转换为嵌入(同时带有位置编码),产生词嵌入表示(src_position_embed),之后送入第一个编码器。
-
由各编码器组成的编码器堆栈按照顺序对第一步中的输出进行处理,产生输入序列的编码表示(enc_outputs)。
-
在右侧的解码器堆栈中,目标序列首先加一个句首标记,被转换成嵌入(带位置编码),产生词嵌入表示(tgt_position_embed),之后送入第一个解码器。
-
由各解码器组成的解码器堆栈,将第三步的词嵌入表示(tgt_position_embed),与编码器堆栈的编码表示(enc_outputs)一起处理,产生目标序列的解码表示(dec_outputs)。
-
输出层将其转换为词概率和最终的输出序列(out_seq)。
-
损失函数将这个输出序列(out_seq)与训练数据中的目标序列(tgt_seq)进行比较。这个损失被用来产生梯度,在反向传播过程中训练模型。
五、Transformer 推理过程
在推理过程中,我们只有输入序列,而没有目标序列作为输入传递给解码器。Transformer 推理的目标是仅通过输入序列产生目标序列。
因此,与 Seq2Seq 模型类似,我们在一个时间步的完整循环中生成当前时间步的输出,并在下一个时间段将前一个时间段的输出序列传给解码器作为其输入,直到我们遇到句末标记。
但与 Seq2Seq 模型的不同之处在于,在每个时间步,我们输入直到当前时间步所产生的整个输出序列,而不是只输入上一个时间步产生的词(类似输入序列长度可变的自回归模型)。
非常重要,把原文粘过来:The difference from the Seq2Seq model is that, at each timestep, we re-feed the entire output sequence generated thus far, rather than just the last word.
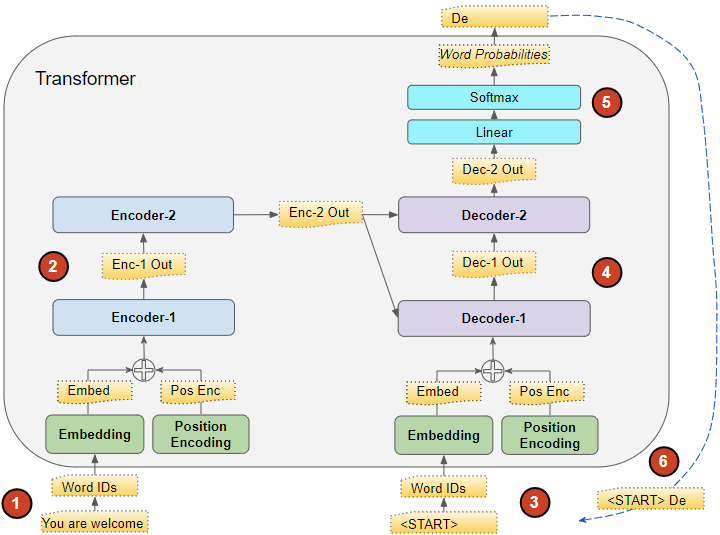
推理过程中的数据流转如下:
-
第一步与训练过程相同:输入序列 (src_seq) 首先被转换为嵌入(带有位置编码),产生词嵌入表示(src_position_embed),之后送入第一个编码器。
-
第二步也与训练过程相同:由各编码器组成的编码器堆栈按照顺序对第一步中的输出进行处理,产生输入序列的编码表示(enc_outputs)。
-
从第三步开始一切变得不一样了:在第一个时间步,使用一个只有句首符号的空序列来代替训练过程中使用的目标序列。空序列转换为嵌入带有位置编码的嵌入(start_position_embed),并被送入解码器堆栈中的第一个解码器。
-
解码器堆栈将第三步的空序列嵌入表示(start_position_embed),与编码器堆栈的编码表示(enc_outputs)一起处理,产生目标序列第一个词的编码表示(step1_dec_outputs)。
-
输出层将其(step1_dec_outputs)转换为词概率和第一个目标单词(step1_tgt_seq)。
-
将这一步产生的目标单词填入解码器输入的序列中的第二个时间步位置。在第二个时间步,解码器输入序列包含句首符号产生的 token 和第一个时间步产生的目标单词。
-
回到第3个步骤,与之前一样,将新的解码器序列输入模型。然后取输出的第二个词并将其附加到解码器序列中。重复这个步骤,直到它预测出一个句末标记。需要明确的是,由于编码器序列在每次迭代中都不会改变,我们不必每次都重复第1和第2步。
六、Teacher Forcing
训练时向解码器输入整个目标序列的方法被称为 Teacher Forcing。
训练时,我们本可以使用与推理时相同的方法。即在一个时间步运行 Transformer,从输出序列中取出最后一个词,将其附加到解码器的输入中,并将其送入解码器进行下一次迭代。最后,当预测到句末标记时,Loss 函数将比较生成的输出序列和目标序列,以训练网络。
但这种训练机制不仅会导致训练时间更长,而且还会增加模型训练难度:若模型预测的第一个词错误,则会根据第一个错误的预测词来预测第二个词,以此类推。
相反,通过向解码器提供目标序列,实际上是给了一个提示。即使第一个词预测错误,在下一时间步,它也可以用正确的第一个词来预测第二个词,避免了错误的持续累加。
此外,这种机制保证了 Transformer 在训练阶段并行地输出所有的词,而不需要循环,这大大加快了训练速度。
七、 Transformer 应用场景
Transformer 的用途非常广泛,可用于大多数NLP任务,如语言模型和文本分类。它们经常被用于 Seq2Seq 的模型,如机器翻译、文本总结、问题回答、命名实体识别和语音识别等应用。
对于不同的问题,有不同的 Transformer 架构。基本的编码器层被用作这些架构的通用构件,根据所解决的问题,有不同的特定应用 “头”。
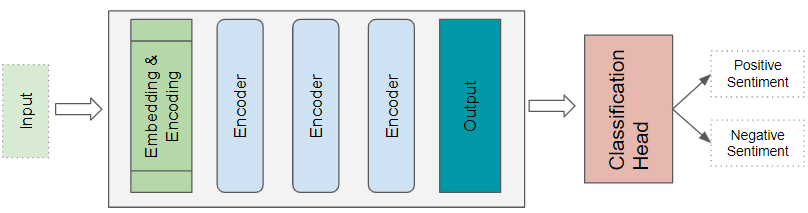
1. Transformer 分类器架构
如下所示,一个情感分析程序,把一个文本文件作为输入。一个分类头接收Transformer 的输出,并生成预测的类别标签,如正面或负面情绪。
2. Transformer Language Model architecture
Language Model architecture 架构将把输入序列的初始部分,如一个文本句子作为输入,并通过预测后面的句子来生成新的文本。一个 Language Model architecture 头接受 Transformer 的输出作为 head 的输入,产生关于词表中每个词的概率输出。概率最高的词成为句子中下一个词的预测输出。
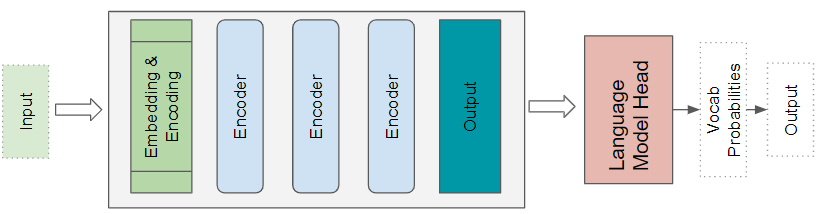
八、与 RNN 类型的架构相比,为什么 Transformer 的效果要好?
RNNs 和 LSTMs、GRU也是之前 NLP 常用的架构,直到 Transformer 的出现。
然而,这有两个限制:
-
对于长句中相距较远的单词,其间的长距离依赖关系是一个挑战。
-
RNNs 每个时间步值处理输入序列的一个词。这意味着在完成时间步 T-1 计算之前,它无法进行时间步骤 T 的计算。(即无法进行并行计算)这降低了训练和推理速度。
对于CNN来说,所有的输出都可以并行计算,这使得卷积速度大大加快。然而,它们在处理长距离的依赖关系方面也有限制:
卷积层中,只有图像(或文字,如果应用于文本数据)中足够接近于核大小的部分可以相互作用。对于相距较远的项目,你需要一个有许多层的更深的网络。
Transformer 架构解决了这两个限制。它摆脱了RNNs,完全依靠 Attention的优势:
- 并行地处理序列中的所有单词,从而大大加快了计算速度。
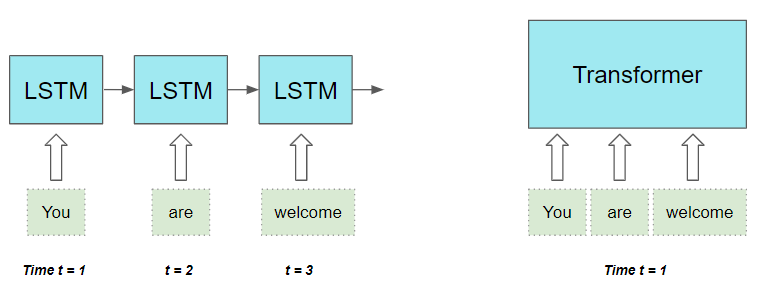
- 输入序列中单词之间的距离并不重要。Transformer 同样擅长计算相邻词和相距较远的词之间的依赖关系。
总结
作为系列文章的第一篇,本文介绍了 Transformer 的整体架构,以及训练、推理的过程。下一篇文章将深入到 Transformer 的各层,从数据流转的过程,介绍 Transformer 各层的原理及作用。
用通俗易懂方式讲解系列
-
《大模型面试宝典》(2024版) 正式发布!
-
《大模型实战宝典》(2024版)正式发布!
-
用通俗易懂的方式讲解:自然语言处理初学者指南(附1000页的PPT讲解)
-
用通俗易懂的方式讲解:1.6万字全面掌握 BERT
-
用通俗易懂的方式讲解:NLP 这样学习才是正确路线
-
用通俗易懂的方式讲解:28张图全解深度学习知识!
-
用通俗易懂的方式讲解:不用再找了,这就是 NLP 方向最全面试题库
-
用通俗易懂的方式讲解:实体关系抽取入门教程
-
用通俗易懂的方式讲解:灵魂 20 问帮你彻底搞定Transformer
-
用通俗易懂的方式讲解:图解 Transformer 架构
-
用通俗易懂的方式讲解:大模型算法面经指南(附答案)
-
用通俗易懂的方式讲解:十分钟部署清华 ChatGLM-6B,实测效果超预期
-
用通俗易懂的方式讲解:内容讲解+代码案例,轻松掌握大模型应用框架 LangChain
-
用通俗易懂的方式讲解:如何用大语言模型构建一个知识问答系统
-
用通俗易懂的方式讲解:最全的大模型 RAG 技术概览
-
用通俗易懂的方式讲解:利用 LangChain 和 Neo4j 向量索引,构建一个RAG应用程序
-
用通俗易懂的方式讲解:使用 Neo4j 和 LangChain 集成非结构化知识图增强 QA
-
用通俗易懂的方式讲解:面了 5 家知名企业的NLP算法岗(大模型方向),被考倒了。。。。。
-
用通俗易懂的方式讲解:NLP 算法实习岗,对我后续找工作太重要了!。
-
用通俗易懂的方式讲解:理想汽车大模型算法工程师面试,被问的瑟瑟发抖。。。。
-
用通俗易懂的方式讲解:基于 Langchain-Chatchat,我搭建了一个本地知识库问答系统
-
用通俗易懂的方式讲解:面试字节大模型算法岗(实习)
-
用通俗易懂的方式讲解:大模型算法岗(含实习)最走心的总结
-
用通俗易懂的方式讲解:大模型微调方法汇总
相关文章:
图解 Transformer
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学. 针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 汇总合集&…...

SpringCloud配置文件bootstrap不生效问题解决
解决方案: 情况一、SpringBoot 版本 小于 2.4.0 版本,添加以下依赖 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-context</artifactId> </dependency> 情况二、SpringBoot…...

Java面试八股之自旋是什么意思
Java中的自旋是什么意思 自旋是多线程编程中的一种同步机制,尤其在Java中与锁的实现密切相关。当一个线程尝试获取某个锁(如内置锁或显式锁)时,如果锁已被其他线程持有,通常的做法是将该线程置于阻塞状态,…...

做好随时离开的准备:前一天还在为618加班到凌晨,第二天就被裁了
今日感悟 最近,一则令人唏嘘的新闻在网络上引起了广泛关注:一名员工前一天还在为618大促活动加班到凌晨,身心疲惫,然而第二天却收到了裁员通知,顿时陷入了失业的困境。 这则新闻不仅揭示了职场竞争的残酷现实ÿ…...

利用ESP32(Arduino IDE)向匿名上位机发送欧拉角
文章目录 一. 匿名上位机介绍二. 匿名协议说明1. 匿名协议官方说明文档2. 协议说明 三. 向匿名上位机发送数据(基于Arduino IDE的esp32)四. 运行效果 一. 匿名上位机介绍 匿名上位机官方介绍视频 匿名上位机官方下载 二. 匿名协议说明 1. 匿名协议官方说明文档 官方对于协…...
Java开发工具类(JDK、Hutool、Guava)
目录 Java开发常用的工具类1、JDK自带程序读取控制台输入内容(调试程序或者学习的时候比较有用)Arrays工具类 数组转集合Collections 集合工具类 排序Collections 集合工具类 查找Lambda表达式 操作集合 收集、转map、分组 2、Apache 的 commons-lang3 和…...

TCP协议的相关特性
目录 正文: 1.可靠性 2.连接管理 3.滑动窗口 4.流量控制 5.拥塞控制 6.延迟应答 7.捎带应答 总结: 正文: 1.可靠性 TCP协议是一个有连接,可靠传输,面向字节流,全双工的协议。其中可靠传输的实现…...

Lombok,一款超级强大的Java工具库
在软件开发过程中,繁琐的模板代码经常让开发者感到烦恼。 Lombok 是一款 Java 库,能够帮助开发者减少这些冗余代码,提高开发效率。本文将介绍 Lombok 的基本概念、安装和配置方法,以及如何在实际项目中使用它。 Lombok 是什么 L…...

FreeBSD下使用原生虚拟机管理器bhyve
hbyve简介 自 FreeBSD 10.0-RELEASE 起,BSD 许可的 bhyve 虚拟机管理器已成为底层系统不可或缺的一部分。bhyve 强大而灵活,支持多种客户机操作系统,涵盖 FreeBSD、OpenBSD 以及多个 Linux 发行版。在默认配置下,bhyve 提供对串行…...

CTFshow之文件上传web入门151关-161关解密。包教包会!!!!
这段时间一直在搞文件上传相关的知识,正好把ctf的题目写了写,也算是给自字做个总结! 不过ctf有一个缺点就是所有的测试全部是黑盒测试,无法从代码层面和大家解释,我找个时间把upload-labs靶场做一做给大家讲讲白盒的代…...

【学习记录】服务器转发使用tensorboard
场景 代码在服务器上运行,想使用tensorboard查看训练的过程。 但是服务器上不能直接访问地址,所以要转发端口到本地,从而在本地网页中能够打开tensorboard。 参考:https://zhuanlan.zhihu.com/p/680596384 这时我们需要建立本地…...

类型转换之显式转换
显式转换——>手动处理,强制转换 括号强转 作用:一般情况下,将高精度的类型转换为低精度。 语法:变量类型 变量名 (变量类型)变量; 注意:精度问题,范围问题。 括号强转&#x…...

Mybatis多表查询,报错:Column ‘id‘ in field list is ambiguous
错误原因: Mybatis 多表查询时,多个表有相同名字的字段,比如 id,名字重复,没有指定对应的表名。 有两个地方需要注意:(1)将其中一个重复字段的 Mybatis的 column 修改为其他的名字。(2)字段加上对应的表名…...
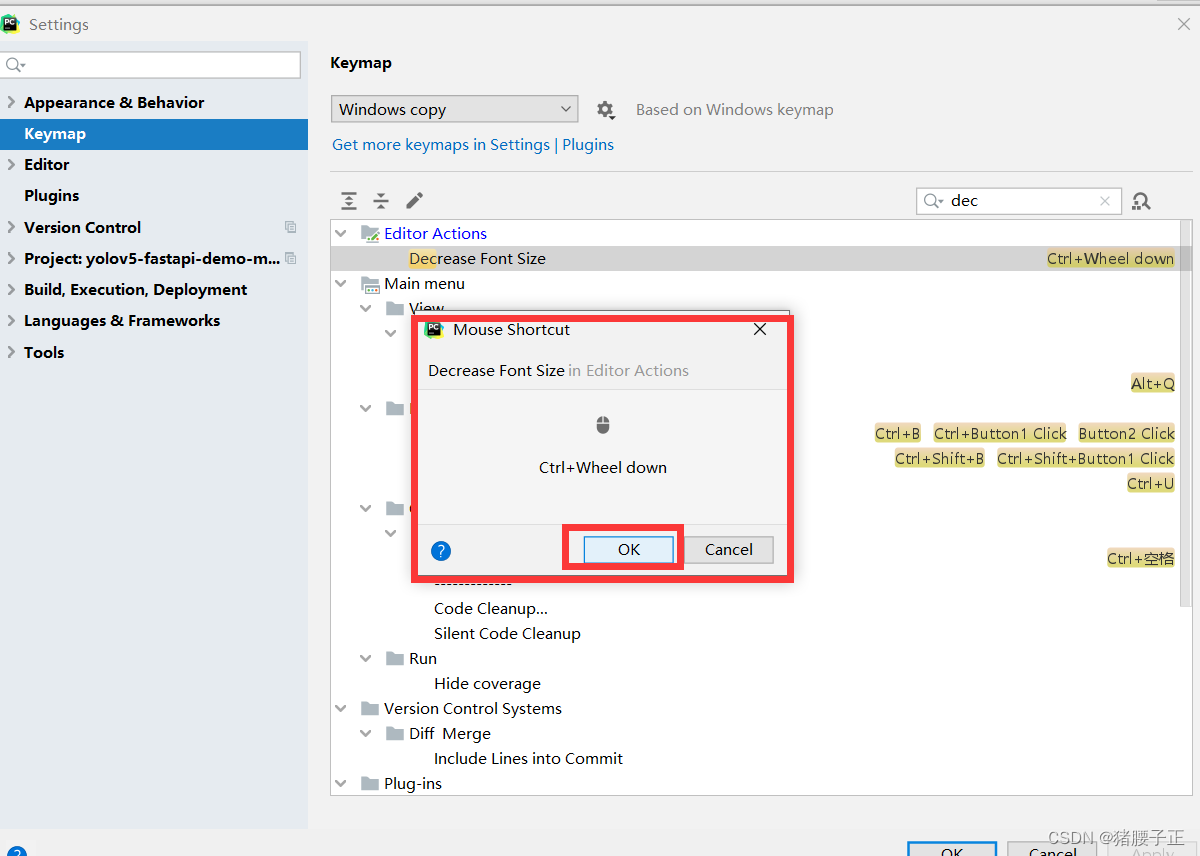
PyCharm面板ctrl+鼠标滚轮放大缩小代码
1.【File】➡【Settings】 2.点击【Keymap】,在右边搜索框中搜incre,双击出现的【Increase Font Size】 3.在弹出的提示框中选择【Add Mouse Shortcut】 4.弹出下面的提示框后,键盘按住【ctrl】,并且上滑鼠标滚轮。然后点击【O…...

【Qt】数据库(一)SQLITE创建、增删查改
填坑1:如何连续插入 汇总SQlite语句 创建表格:create table <table_name> (f1 type1, f2 type2,…); 增:insert into <table_name> values (value1, value2,…); 改:update <table_name> set <f1value1>,…...
)
【模拟面试问答】力扣165题:比较版本号(逐个比较与双指针法详解及模拟面试问答)
在本篇文章中,我们将详细解读力扣第165题“比较版本号”。通过学习本篇文章,读者将掌握如何使用多种方法来解决这一问题,并了解相关的复杂度分析和模拟面试问答。每种方法都将配以详细的解释和ASCII图解,以便于理解。 问题描述 …...
用PhpStudy在本地电脑搭建WordPress网站教程(2024版)
对新手来说,明白了建站3要素后,如果直接购买域名、空间去建站,因为不熟练,反复测试主题、框架、插件等费时费力,等网站建成可能要两三个月,白白损失这段时间的建站费用。那么新手怎么建测试网站来练手呢&am…...

高中数学:平面向量-题型总结及解题思路梳理
一、知识点及解题思路梳理 高中,2/3的向量题目是坐标向量题,1/3是几何向量题。但是,这1/3的几何向量题可以转换成坐标向量题。 二、练习 例题1 几何型向量题 例题2...
 (WAF)详解)
【玩转google云】Google Cloud Platform (GCP) (WAF)详解
目录 引言 一、什么是Web Application Firewall? 二、GCP WAF简介 三、GCP WAF的主要功能...
前端开发工程师——数据可视化
canvas canvas绘制线段 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content"widthd…...

BP-4500-PoER工控机:宽温无风扇设计,6网口4PoE+,赋能机器视觉与边缘计算
1. 项目概述:一台为严苛环境而生的工业视觉“大脑”在机器视觉、边缘计算或者工业自动化现场,我们常常需要一台足够“皮实”的计算机。它不能是办公室里娇贵的台式机,也不能是性能孱弱的单板机。它需要扛得住产线上的粉尘、振动,耐…...

2026论文写作工具红黑榜:一键生成论文工具怎么选?一篇讲透:
2026年论文写作工具红黑榜出炉,红榜优先选千笔AI、ThouPen、豆包,适配国内学术规范;黑榜避开低质免费工具、无真实引用平台、过度依赖全文生成的工具。选择时建议按需求匹配三维模型:需求匹配度 - 数据可信度 - 成本承受力。一、红…...

5分钟搞定!RK3588开发板Ubuntu系统终极配置指南 [特殊字符]
5分钟搞定!RK3588开发板Ubuntu系统终极配置指南 🚀 【免费下载链接】ubuntu-rockchip Ubuntu for Rockchip RK35XX Devices 项目地址: https://gitcode.com/gh_mirrors/ub/ubuntu-rockchip 还在为RK3588开发板的系统配置发愁吗?别担心…...

3分钟搞定!GetQzonehistory教你永久保存QQ空间青春回忆
3分钟搞定!GetQzonehistory教你永久保存QQ空间青春回忆 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 还在担心那些承载着青春记忆的QQ空间说说会消失吗?GetQzo…...

3步轻松解锁Cursor Pro:告别试用限制,永久免费享受AI编程助手
3步轻松解锁Cursor Pro:告别试用限制,永久免费享受AI编程助手 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...
)
无人超市|基于Java+vue的无人超市管理系统(源码+数据库+文档)
无人超市管理系统 基于SprinBootvue的无人超市管理系统 一、前言 二、系统设计 三、系统功能设计 系统功能实现 后台管理员模块实现 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂…...

深度解析 StoreClaw:面向电商全域的 “懂销售” 智能体技术架构与核心实现原理
摘要随着大语言模型、多智能体协同、实时数据分析与自动化决策技术的快速迭代,AI 正从辅助工具向业务执行主体演进。传统电商平台数字化工具多停留在数据统计、报表展示、基础客服层面,缺乏具备自主感知、自主分析、自主决策、自主执行的闭环能力&#x…...

在OpenClaw Agent工作流中无缝接入Taotoken调用多模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw Agent工作流中无缝接入Taotoken调用多模型能力 对于使用OpenClaw构建智能体工作流的开发者而言,能够灵活调…...

观察Taotoken在不同网络环境下API调用的延迟表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在不同网络环境下API调用的延迟表现 在将大模型API集成到实际应用时,网络环境是影响开发者体验的关键因素…...

vue3+vite+springboot路径配置:维护统一的baseUrl
提交表单:try…catch 捕获异常,如果校验失败,前台页面会有错误提示。 const submitForm async () > {try {await formRef.value.validate(); // 校验失败会抛出异常const submitData { ...formData };submitData.allowedSubmitTypes su…...