CLIP源码详解:clip.py 文件
前言
这是关于 CLIP 源码中的 clip.py 文件中的代码带注释版本。
clip.py 文件的作用:封装了 clip 项目的相关 API,通过这些 API ,我们可以轻松使用 CLIP 项目预训练好的模型进行自己项目的应用。
另外不太容易懂的地方都使用了二级标题强调了,在该标题下面有对应的 GPT 的解释。
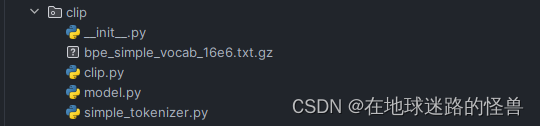
上图是 CLIP 的项目结构图。
正文
import hashlib
import os
import urllib
import warnings
from typing import Any, Union, List
from pkg_resources import packagingimport torch
from PIL import Image
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize
from tqdm import tqdmfrom .model import build_model
from .simple_tokenizer import SimpleTokenizer as _Tokenizer# 上面都是头文件
# 导入 torchvision.transforms 模块中的 InterpolationMode 枚举,并将其中的 BICUBIC 插值模式赋值给变量 BICUBIC。
# 如果导入失败(因为没有安装 torchvision 或者 InterpolationMode 不存在),则使用 PIL 库中的 BICUBIC 插值模式。
try:from torchvision.transforms import InterpolationModeBICUBIC = InterpolationMode.BICUBIC
except ImportError:BICUBIC = Image.BICUBIC
InterpolationMode 类的作用:

# 判断torch的版本,小于就报警告
if packaging.version.parse(torch.__version__) < packaging.version.parse("1.7.1"):warnings.warn("PyTorch version 1.7.1 or higher is recommended")
warnings.warn() 语法解释:

# 定义了本模块内可以被外部模块所引用的内容
__all__ = ["available_models", "load", "tokenize"]
# 创建 _Tokenizer类的对象实例
_tokenizer = _Tokenizer()

# 这段代码定义了一个名为 _MODELS 的字典,其中包含了各种预训练的 CLIP 模型及其对应的下载链接。
# 每个键值对表示了一个模型的名称和其对应的下载链接。
_MODELS = {"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt","RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt","RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt","RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt","RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt","ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt","ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt","ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt","ViT-L/14@336px": "https://openaipublic.azureedge.net/clip/models/3035c92b350959924f9f00213499208652fc7ea050643e8b385c2dac08641f02/ViT-L-14-336px.pt",
}
# 下载函数:用于从指定的 URL 下载文件到指定的目录中,并检查文件的 SHA256 校验和
def _download(url: str, root: str):# 创建存放下载文件的目录 root,如果目录已经存在则不会报错。os.makedirs(root, exist_ok=True)# 从 URL 中提取文件名filename = os.path.basename(url)# 从 URL 中提取预期的 SHA256 校验和值expected_sha256 = url.split("/")[-2]# 构建下载文件的完整路径。download_target = os.path.join(root, filename)# 文件存在性和完整性检查:# 首先检查下载目标文件是否存在,如果存在且不是普通文件,则抛出运行时错误if os.path.exists(download_target) and not os.path.isfile(download_target):raise RuntimeError(f"{download_target} exists and is not a regular file")# 如果文件已存在且其 SHA256 校验和与预期值匹配,则直接返回下载目标路径# 如果文件存在但 SHA256 校验和与预期值不匹配,则发出警告并重新下载文件if os.path.isfile(download_target):if hashlib.sha256(open(download_target, "rb").read()).hexdigest() == expected_sha256:return download_targetelse:warnings.warn(f"{download_target} exists, but the SHA256 checksum does not match; re-downloading the file")# 使用 urllib.request.urlopen() 打开 URL 连接,并通过 tqdm 实现下载进度条的显示。with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:with tqdm(total=int(source.info().get("Content-Length")), ncols=80, unit='iB', unit_scale=True, unit_divisor=1024) as loop:while True:buffer = source.read(8192)if not buffer:breakoutput.write(buffer)loop.update(len(buffer))# 下载完成后,再次检查下载文件的 SHA256 校验和是否与预期值匹配,如果不匹配则抛出运行时错误。if hashlib.sha256(open(download_target, "rb").read()).hexdigest() != expected_sha256:raise RuntimeError("Model has been downloaded but the SHA256 checksum does not not match")# 最后,返回下载完成的文件路径return download_target
上面代码所用到的 Python 语法的补充:
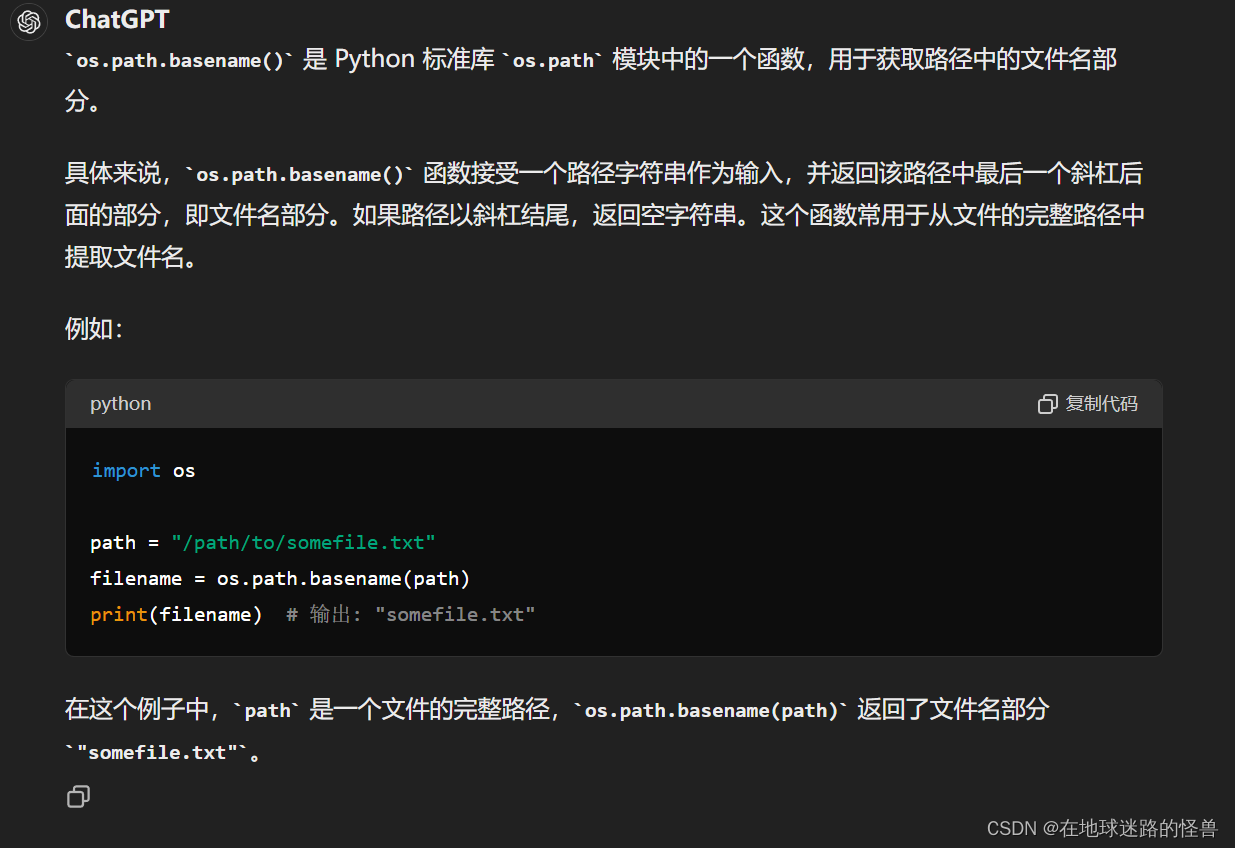
os.path.basename():
str.split(‘/’)[-2] 的含义:

hashlib.sha256():

with urllib.request.urlopen(url) as source, open(download_target, “wb”) as output:

# 这个函数 _convert_image_to_rgb(image) 接受一个图像对象作为输入,
# 然后将其转换为 RGB 模式的图像,并返回转换后的图像对象。
# 具体来说,函数调用了图像对象的 convert() 方法,并传递了字符串参数 "RGB"。
# 这个方法会将图像转换为 RGB(红绿蓝)模式,确保图像在处理过程中始终保持 RGB 格式。
# 这通常用于处理一些格式不一致的图像,例如从其他格式(如灰度图像)转换为 RGB 格式的图像
def _convert_image_to_rgb(image):return image.convert("RGB")# 这个函数 _transform(n_px) 接受一个参数 n_px,表示图像的大小(以像素为单位)。
# 函数的主要作用是定义了一系列图像转换操作,以便将输入的图像进行预处理,以便于后续的处理
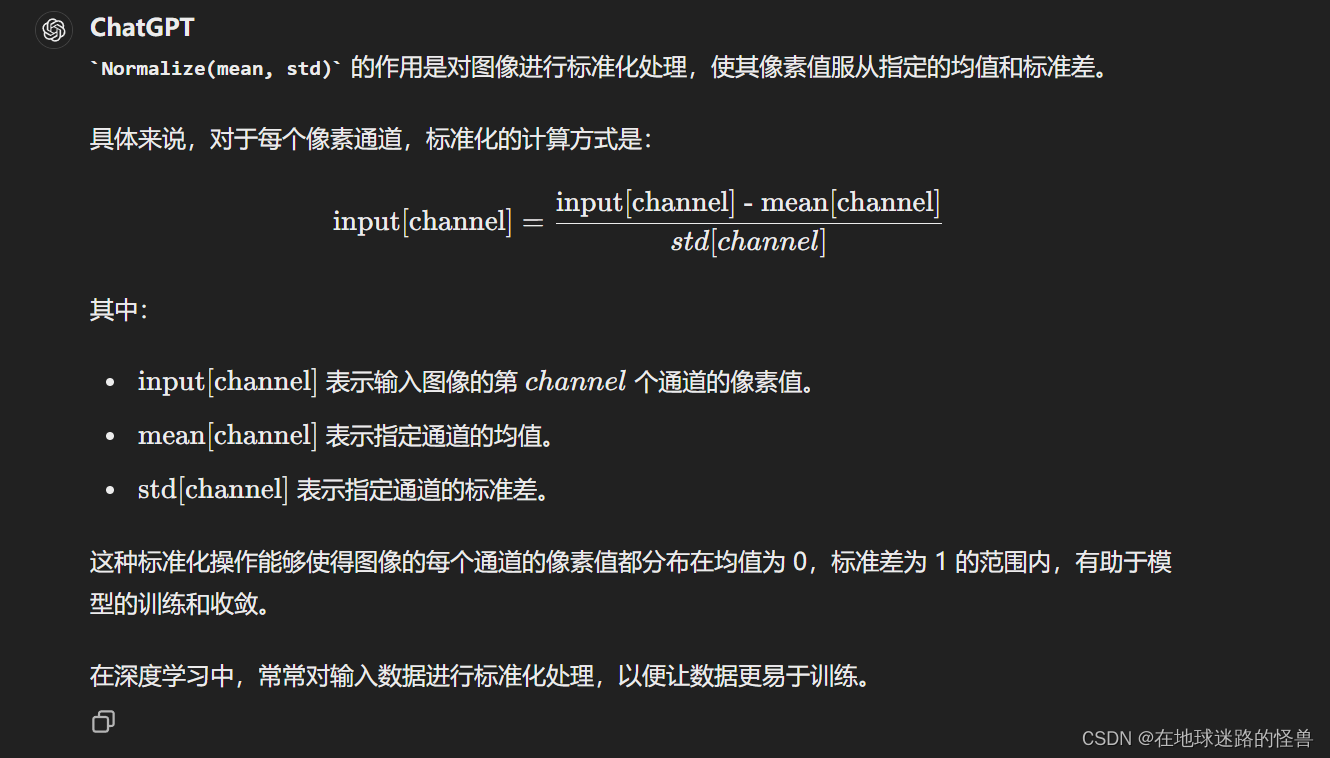
def _transform(n_px):return Compose([# 将图像调整为指定大小 n_px,采用双三次插值(BICUBIC)进行插值。Resize(n_px, interpolation=BICUBIC),# 对调整大小后的图像进行中心裁剪,裁剪尺寸为 n_px。CenterCrop(n_px),# 将图像转换为 RGB 模式, 也就是刚刚上面所定义的函数_convert_image_to_rgb,# 将图像转换为 PyTorch 的张量格式。ToTensor(),# 对张量进行标准化处理,减去均值 (0.48145466, 0.4578275, 0.40821073) # 并除以标准差 (0.26862954, 0.26130258, 0.27577711)。Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),])Normalize((mean), (std))
# 这个函数 available_models() 的作用是返回可用的 CLIP 模型的名称列表
def available_models() -> List[str]:"""Returns the names of available CLIP models"""# _MODELS就是我们刚刚上文所定义的字典,keys就是其字典中的键的集合,即模型名称return list(_MODELS.keys())
available_models() -> List[str]:

# 这段代码定义了一个 load 函数,用于加载 CLIP 模型
def load(# 模型名称,可以是由 clip.available_models() 返回的名称之一,# 也可以是包含状态字典的模型检查点的路径。name: str, # 模型加载到的设备,可以是字符串 "cpu" 或 "cuda",也可以是 torch.device 类型的对象。# 默认为 "cuda",如果 CUDA 可用的话,否则为 "cpu"。device: Union[str, torch.device] = "cuda" if torch.cuda.is_available() else "cpu", # 一个布尔值,表示是否加载 JIT 优化模型。默认为 False。jit: bool = False, # 下载模型文件的根目录路径。默认为 None,表示使用默认路径 "~/.cache/clip"。download_root: str = None):"""Load a CLIP modelParameters----------name : strA model name listed by `clip.available_models()`, or the path to a model checkpoint containing the state_dictdevice : Union[str, torch.device]The device to put the loaded modeljit : boolWhether to load the optimized JIT model or more hackable non-JIT model (default).download_root: strpath to download the model files; by default, it uses "~/.cache/clip"Returns-------model : torch.nn.ModuleThe CLIP modelpreprocess : Callable[[PIL.Image], torch.Tensor]A torchvision transform that converts a PIL image into a tensor that the returned model can take as its input"""# 根据 name 参数确定要加载的模型文件路径。如果 name 在 _MODELS 字典中,# 则根据模型名称从 _MODELS 中获取模型文件的下载链接,并下载到指定的目录。# 如果 name 是文件路径,则直接使用该路径。if name in _MODELS:model_path = _download(_MODELS[name], download_root or os.path.expanduser("~/.cache/clip"))elif os.path.isfile(name):model_path = name# 否则抛异常else:raise RuntimeError(f"Model {name} not found; available models = {available_models()}")# 接着,尝试加载模型文件。如果 jit 为 True,则尝试加载 JIT 优化模型;# 否则,尝试加载保存的状态字典。with open(model_path, 'rb') as opened_file:try:# loading JIT archive# torch.jit.load(opened_file, map_location=device if jit else "cpu").eval():# 尝试使用 torch.jit.load() 函数加载模型。如果 jit 参数为 True,则加载 JIT 优化的模型;# 否则,加载非 JIT 的模型。加载后,调用 .eval() 方法将模型设置为评估模式(evaluation mode),# 即不启用梯度计算。加载的模型赋值给变量 model。model = torch.jit.load(opened_file, map_location=device if jit else "cpu").eval()state_dict = Noneexcept RuntimeError:# 如果在加载模型时抛出了 RuntimeError 异常,则执行 except 代码块中的内容。# loading saved state dictif jit:# 如果 jit 参数为 True,则会发出警告,说明模型文件不是 JIT 归档(archive),而是保存的状态字典。# 然后将 jit 参数设为 False,以便后续加载状态字典。warnings.warn(f"File {model_path} is not a JIT archive. Loading as a state dict instead")jit = False# 然后,使用 torch.load() 函数加载模型的状态字典,并将加载的状态字典赋值给 state_dict 变量。# 加载的状态字典中包含了模型的参数state_dict = torch.load(opened_file, map_location="cpu")if not jit:# 如果加载的是状态字典,则调用 build_model() 函数构建模型,并根据设备将其移到指定设备上# build_model()函数是在另一个源文件 model.py 中的我们自己写的,后面会看到model = build_model(state_dict or model.state_dict()).to(device)# 这段代码的逻辑是,如果指定的设备是 CPU,则将模型的参数类型转换为浮点数类型# 这个操作通常用于将模型从 GPU 转移到 CPU 后,为了与 CPU 上的张量匹配,# 需要将模型的参数类型也转换为 CPU 上的浮点数类型。if str(device) == "cpu":model.float()# 最后返回加载的模型对象以及用于预处理图像的转换函数return model, _transform(model.visual.input_resolution)# 如果加载的是 JIT 模型,则对模型进行一些额外的处理,# 例如将模型中的设备名称修正为指定的设备名称,并在 CPU 设备上将数据类型转换为 float32。# patch the device names# 下面这两段代码的目的是修正模型中的设备名称,以确保模型在指定的设备上运行。# 使用 torch.jit.trace 函数跟踪一个 lambda 函数,该 lambda 函数创建一个形状为空的张量,# 并将其移动到指定的设备上。这样做是为了捕获模型中涉及设备的操作。device_holder = torch.jit.trace(lambda: torch.ones([]).to(torch.device(device)), example_inputs=[])# 使用 findAllNodes("prim::Constant") 方法找到计算图中所有的常量节点。# 在这些节点中,找到最后一个节点,该节点包含有关设备的信息。# 最后,修正找到的设备节点,以便它使用指定的设备。这样做是为了确保模型中的所有设备名称都与用户指定的设备名称一致。device_node = [n for n in device_holder.graph.findAllNodes("prim::Constant") if "Device" in repr(n)][-1]def _node_get(node: torch._C.Node, key: str):# node:表示 PyTorch 计算图中的一个节点,类型为 torch._C.Node。# key:表示要获取的属性的名称,类型为字符串。"""Gets attributes of a node which is polymorphic over return type.From https://github.com/pytorch/pytorch/pull/82628"""# 函数的文档字符串(docstring)描述了函数的作用来源,即从某个 GitHub PR(pull request)中获取。# 使用 node.kindOf(key) 方法获取节点的类型(kind),存储在变量 sel 中sel = node.kindOf(key)# 然后使用 getattr(node, sel) 方法,根据节点的类型来调用节点的特定方法,# 并将 key 作为参数传递给这个方法,以获取节点的属性值。return getattr(node, sel)(key)# 这段代码定义了一个名为 patch_device 的函数,它用于修正模型中的设备名称,# 以确保模型中所有节点的设备名称与指定的设备名称一致# 函数接受一个参数 module,表示模型的一个组成部分def patch_device(module):try:# 函数首先尝试获取模型中的计算图(graph),如果该模型具有 graph 属性,# 则将其添加到列表 graphs 中,否则将 graphs 设置为空列表graphs = [module.graph] if hasattr(module, "graph") else []except RuntimeError:graphs = []# 如果模型具有 forward1 属性,则也将其对应的计算图添加到 graphs 列表中if hasattr(module, "forward1"):graphs.append(module.forward1.graph)# 然后,对于 graphs 列表中的每个计算图,函数遍历其中的所有节点,查找节点类型为 "prim::Constant" 的节点。for graph in graphs:for node in graph.findAllNodes("prim::Constant"):if "value" in node.attributeNames() and str(_node_get(node, "value")).startswith("cuda"):node.copyAttributes(device_node)# 这段代码调用了 patch_device 函数来修正模型中与设备相关的节点,以确保模型在指定的设备上运行# 将 patch_device 函数应用于模型 model 的所有模块。这会递归地遍历模型的所有子模块,# 并对每个模块调用 patch_device 函数。这样可以确保模型中的所有模块都被修正,以适应指定的设备model.apply(patch_device)# 下面两行代码分别将 patch_device 函数应用于模型的 encode_image 和 encode_text 方法。# 这些方法通常是用于将图像和文本编码为特征向量的函数,# 因此对它们应用 patch_device 函数可以确保它们内部的设备相关节点也被修正。patch_device(model.encode_image)patch_device(model.encode_text)# patch dtype to float32 on CPU# 这段代码的目的是在 CPU 上将模型参数的数据类型转换为 float32。# 检查指定的设备是否为 CPU,如果是 CPU,则执行以下操作if str(device) == "cpu":# 使用 torch.jit.trace 函数创建一个用于创建 float32 类型张量的简单函数。# 这个函数是一个 lambda 函数,它创建一个形状为空的张量,并将其转换为 float32 类型。# 然后使用 torch.jit.trace 对这个函数进行跟踪,以获取与该函数关联的计算图。float_holder = torch.jit.trace(lambda: torch.ones([]).float(), example_inputs=[])# 在计算图中找到 aten::to 操作节点,并获取该节点的输入。这里假设 float32 类型转换的节点为第二个输入节点(索引为 1)。float_input = list(float_holder.graph.findNode("aten::to").inputs())[1]float_node = float_input.node()# 定义了一个名为 patch_float 的函数,用于将模型中的节点的数据类型转换为 float32。# 这个函数的逻辑与前面提到的 patch_device 函数类似,只是它将模型中的 aten::to 操作节点的数据类型转换为 float32def patch_float(module):try:graphs = [module.graph] if hasattr(module, "graph") else []except RuntimeError:graphs = []if hasattr(module, "forward1"):graphs.append(module.forward1.graph)for graph in graphs:for node in graph.findAllNodes("aten::to"):inputs = list(node.inputs())for i in [1, 2]: # dtype can be the second or third argument to aten::to()if _node_get(inputs[i].node(), "value") == 5:inputs[i].node().copyAttributes(float_node)# 最后这三行代码的作用是将 patch_float 函数应用于模型中的所有模块,# 并分别将其应用于模型的 encode_image 和 encode_text 方法。# 这样做的目的是确保模型中的所有部分,包括图像编码和文本编码的部分,# 都将其参数的数据类型转换为 float32,以适应 CPU 上的计算。model.apply(patch_float)patch_float(model.encode_image)patch_float(model.encode_text)# 这行代码 model.float() 是针对 PyTorch 模型对象 model 的方法调用。# 它的作用是将模型中的所有参数的数据类型转换为浮点数类型(float32)。# 这个方法通常用于将模型从 GPU 转移到 CPU 后,为了与 CPU 上的张量匹配,# 需要将模型的参数类型也转换为 CPU 上的浮点数类型。model.float()# 最后返回加载的模型对象以及用于预处理图像的转换函数return model, _transform(model.input_resolution.item())
Jit 模型优化的作用

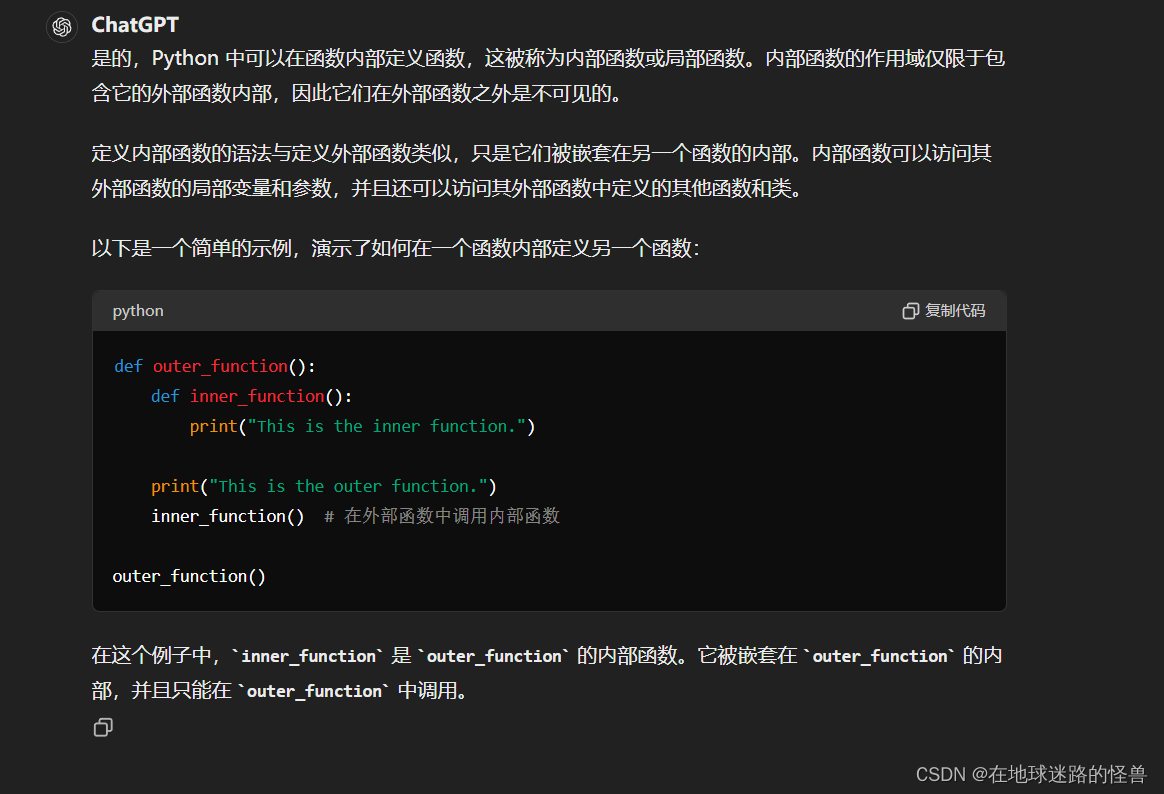
Python 代码中可以在函数中定义函数
# 这段代码定义了一个名为 tokenize 的函数,用于将输入文本字符串或文本字符串列表进行标记化处理,生成对应的标记化表示
def tokenize(# 输入的文本字符串或文本字符串列表texts: Union[str, List[str]], # 上下文长度,即生成的标记化表示的长度。CLIP 模型通常使用 77 作为上下文长度context_length: int = 77, # 是否截断文本,如果文本的编码长度超过上下文长度,则截断文本。# 如果为 True,则截断文本;如果为 False,则在文本编码长度超过上下文长度时引发错误truncate: bool = False) -> Union[torch.IntTensor, torch.LongTensor]:"""Returns the tokenized representation of given input string(s)Parameters----------texts : Union[str, List[str]]An input string or a list of input strings to tokenizecontext_length : intThe context length to use; all CLIP models use 77 as the context lengthtruncate: boolWhether to truncate the text in case its encoding is longer than the context lengthReturns-------A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length].We return LongTensor when torch version is <1.8.0, since older index_select requires indices to be long."""# 函数首先检查 texts 是否为单个字符串,如果是则将其转换为单个字符串列表。if isinstance(texts, str):texts = [texts]# 然后,函数使用 CLIP tokenizer(这个函数是在另一个simple_tokenizer文件中定义的) 将每个文本字符串编码为标记化表示,# 并将其添加到 all_tokens 列表中。sot_token = _tokenizer.encoder["<|startoftext|>"]eot_token = _tokenizer.encoder["<|endoftext|>"]all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]# 接下来,函数创建一个大小为 [number of input strings, context_length] 的零张量 result,# 其中 number of input strings 表示输入字符串的数量。如果 PyTorch 版本低于 1.8.0,# 则使用 dtype=torch.long 创建长整型张量,否则使用 dtype=torch.int 创建整型张量。if packaging.version.parse(torch.__version__) < packaging.version.parse("1.8.0"):result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)else:result = torch.zeros(len(all_tokens), context_length, dtype=torch.int)# 然后,函数遍历 all_tokens 列表中的每个标记化表示,并将其填充到 result 张量中。# 如果标记化表示的长度超过了上下文长度,则根据 truncate 参数的值进行截断或引发错误。最终返回填充后的张量 result。for i, tokens in enumerate(all_tokens):if len(tokens) > context_length:if truncate:tokens = tokens[:context_length]tokens[-1] = eot_tokenelse:raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")result[i, :len(tokens)] = torch.tensor(tokens)return resultall_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]
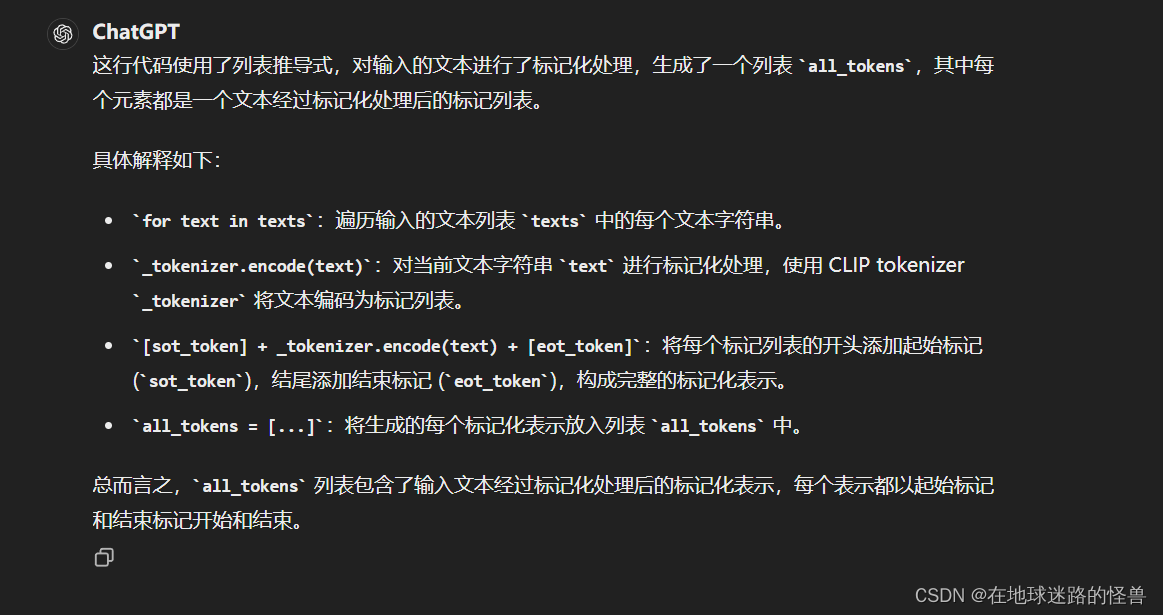
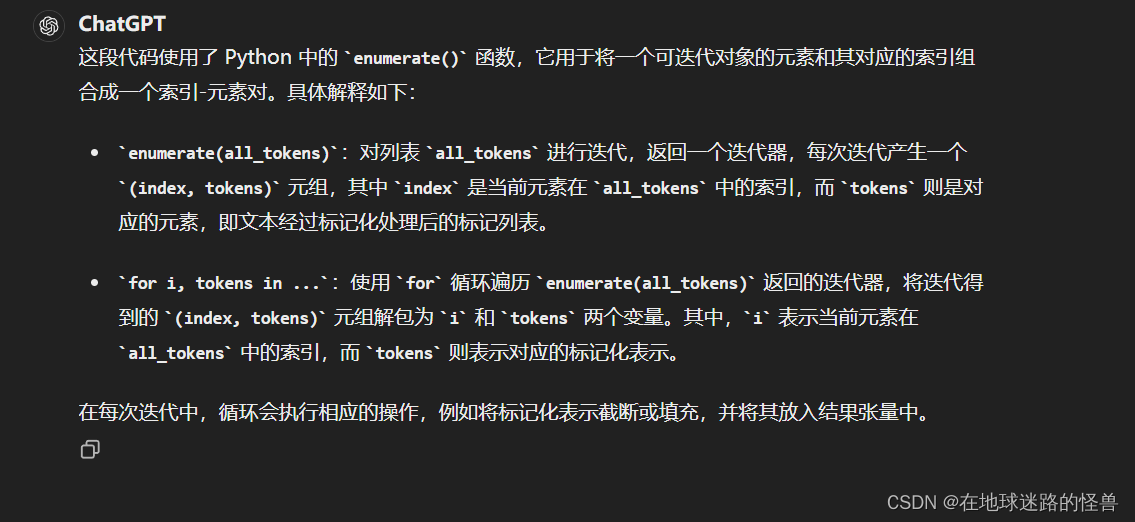
for i, tokens in enumerate(all_tokens):
总结
通过这个文件提供的相关 API,我们就可以进行简单的测试了,测试代码如下:
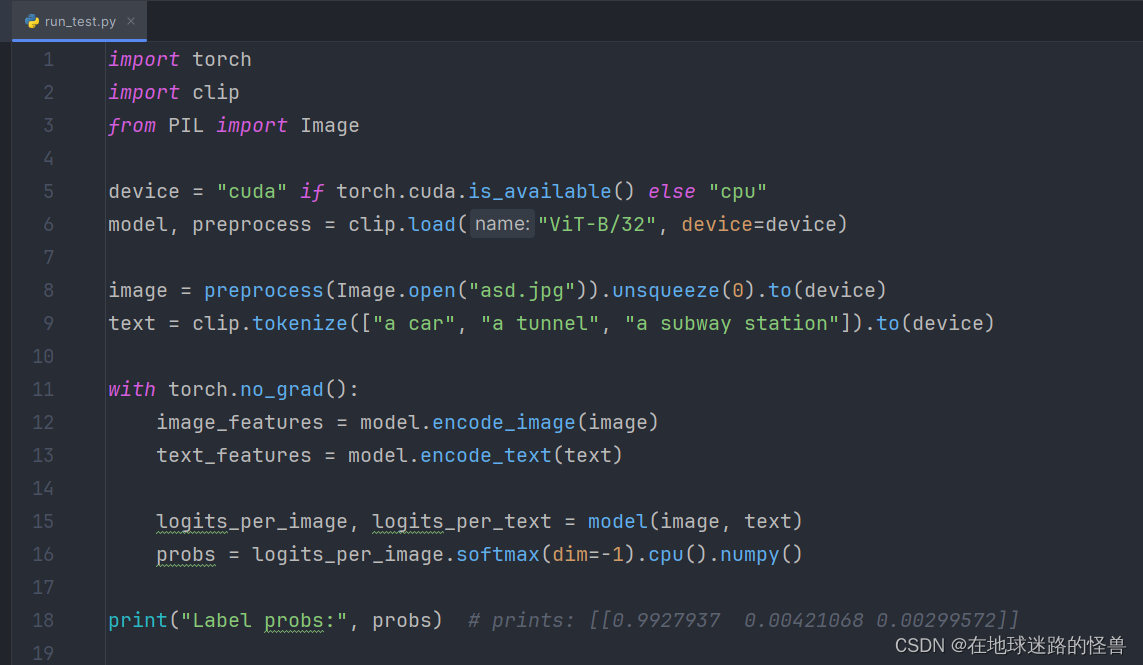
可以看见引入了 clip 这个模块之后,我们就可以进行简单的使用了。
相关文章:
CLIP源码详解:clip.py 文件
前言 这是关于 CLIP 源码中的 clip.py 文件中的代码带注释版本。 clip.py 文件的作用:封装了 clip 项目的相关 API,通过这些 API ,我们可以轻松使用 CLIP 项目预训练好的模型进行自己项目的应用。 另外不太容易懂的地方都使用了二级标题强…...

linux下重启oracle数据库步骤
Linux下重启oracle数据库步骤: 1.使用oracle用户登录数据库服务器(root登录的话进入数据库时会找不到sqlplus命令) su – oracle 2.通过数据库管理员sysdba进入oracle数据库 sqlplus / as sysdba 3.关闭数据库 shutdown immediate ࿰…...

[自动驾驶技术]-1 概述技术和法规
自动驾驶(Autonomous Driving),也称为无人驾驶或自驾,是指通过计算机系统和传感器设备,自动驾驶汽车在没有人类干预的情况下能够感知环境并做出驾驶决策,从而实现车辆的自主行驶。 自动驾驶技术层级 自动…...
Qt自定义标题栏
效果如下: 代码如下: // widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget>QT_BEGIN_NAMESPACE namespace Ui { class Widget; } QT_END_NAMESPACEclass Widget : public QWidget {Q_OBJECTpublic:Widget(QWidget *parent nullptr…...

java如何向数组中插入元素
java的数组是不可改变的,因此如果要向数组中插入新的元素,需要新建一个数组,新的数组元素个数减去老数组元素个数的差大于等于要插入新的元素数量。 假如说要插入一个数组元素,需要把新元素插入到中间,把新的数组分为…...

4、PHP的xml注入漏洞(xxe)
青少年ctf:PHP的XXE 1、打开网页是一个PHP版本页面 2、CTRLf搜索xml,发现2.8.0版本,含有xml漏洞 3、bp抓包 4、使用代码出发bug GET /simplexml_load_string.php HTTP/1.1 补充: <?xml version"1.0" encoding&quo…...
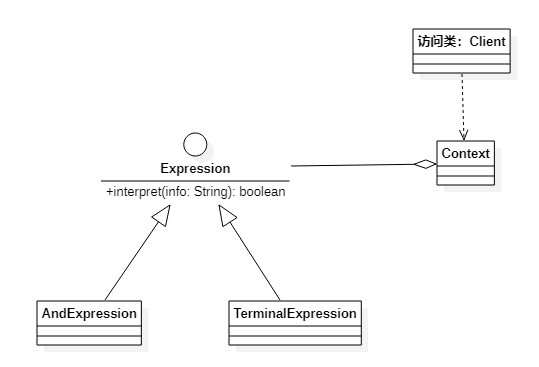
设计模式-解释器模式
作者持续关注 WPS二次开发专题系列,持续为大家带来更多有价值的WPS开发技术细节,如果能够帮助到您,请帮忙来个一键三连,更多问题请联系我(QQ:250325397) 定义 解释器模式(Interpreter Pattern&…...
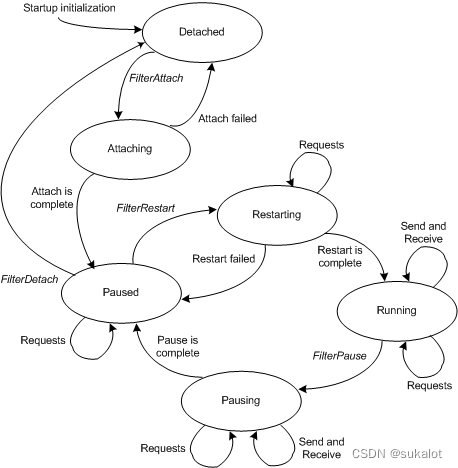
NDIS驱动程序堆栈
NDIS 6.0 引入了暂停和重启驱动程序堆栈的功能。 若要支持 NDIS 6.0 提供的堆栈管理功能,必须重写旧版驱动程序。 NDIS 6.0 还引入了 NDIS Filter驱动程序。 Filter驱动程序可以监视和修改协议驱动程序与微型端口驱动程序之间的交互。 与 NDIS 5 相比,F…...

大数据开发面试题【数仓篇】
197、数据仓库和传统数据库区别 由于历史数据使用频率过低,导致数据堆积,查询性能下降;用于查询分析,涉及大量的历史数据,数据仓库中的数据一般来日志文件和事务 数据库是跟业务挂钩的,数据库不可能装下一…...

Leetcode刷题笔记5
76. 最小覆盖子串 76. 最小覆盖子串 - 力扣(LeetCode) 解法一: 暴力枚举 哈希表 先定义left和right,可以在随机位置 枚举一个位置向后找,找到一个位置之后,发现这段区间是一个最小的区间之后,…...

【Qt】Qt中的信号槽
一、信号和槽概述 信号槽是Qt矿建引以为豪的机制之一。 所谓信号槽,实际上就是观察者模式(发布——订阅模式)。当某个事件发生之后,比如,按钮检测到自己被点击了一下,它就会发出一个信号。这种发出的信号是…...

VsCode个人插件
Auto Rename Tag > 同时修改标签 Rainbow Brackets > 不同层级不同括号颜色 Dracula Official > 个人比较喜欢的一款主题 Error Lens > 错误信息显示 ES7REACT/Redux/React-Native>react开发插件 ESLINT Indenticator>方便看结构 Prettier Formatter …...
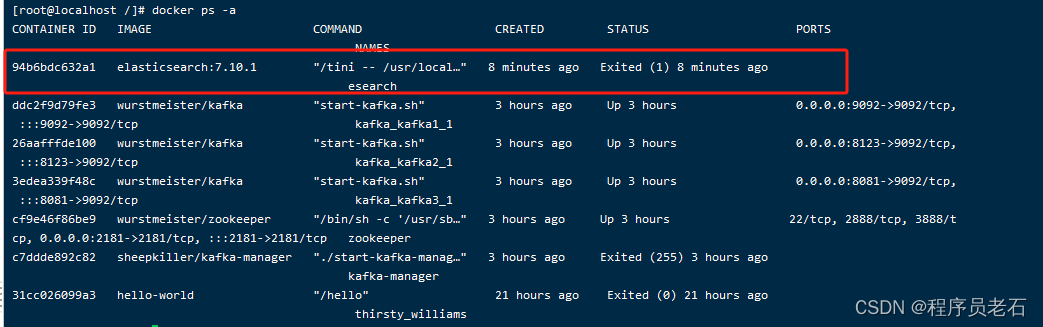
Docker环境安装并使用Elasticsearch
1、拉取es docker pull elasticsearch:7.10.12、查看镜像 docker images3、启动es docker run -d --name esearch -p 9200:9200 -p 9300:9300 elasticsearch:7.10.14、如果启动ES时出现一下问题 Unable to find image docker.elastic.co/elasticsearch/elasticsearch:7.10.…...
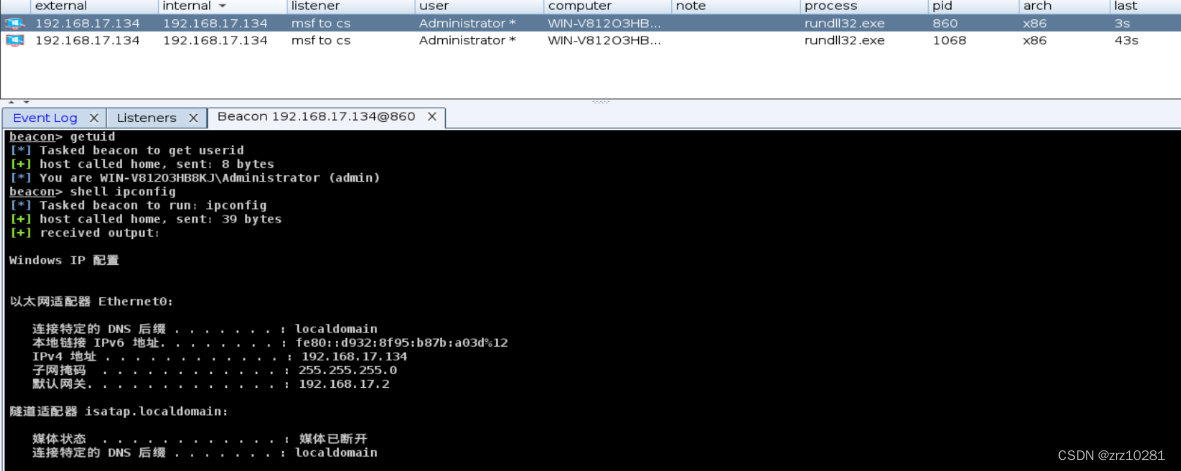
中心渗透Ⅱ
cs与msf权限传递以及mimikatz抓取win2012明文密码 使用Cobalt Strike抓取win2012明文密码,将会话传递到Metasploit Framework上 1.cs生成木马并使目标服务器中马 建立监听生成木马 2.抓取目标主机的明文密码 通过修改注册表来让Wdigest Auth保存明文口令 shell …...
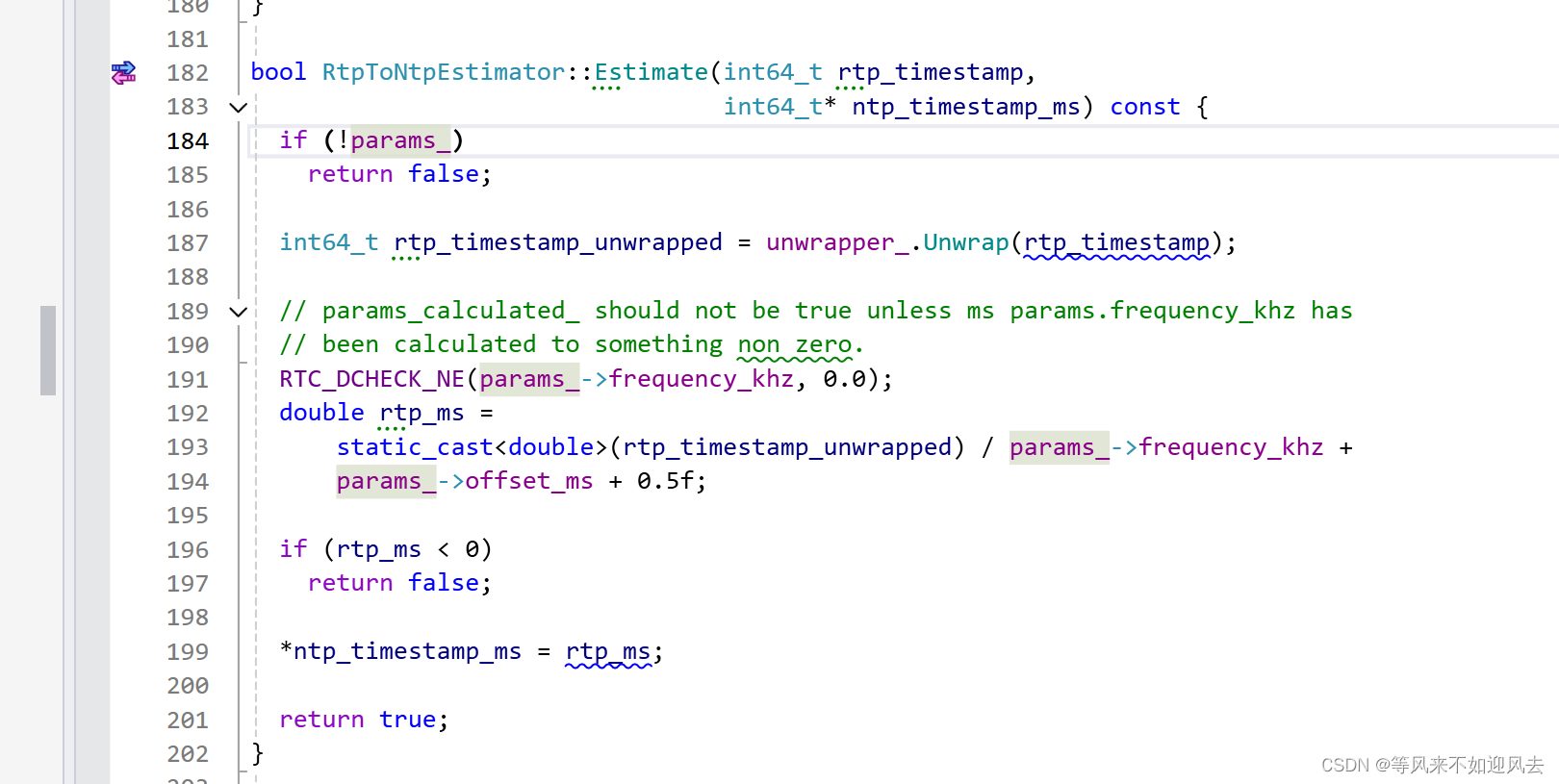
【webrtc】RtpToNtpEstimator:最小二乘法、ntp估计及c++实例
上一篇: 【webrtc】RtpToNtpEstimator:将 RTP 时间戳映射到 NTP 时间 分析了最小二乘法的实现及对rtp到ntp的映射计算的调用流程 基于最小二乘法进行估计 RtpToNtpEstimator::Estimate G:\CDN\rtcCli\m98\src\system_wrappers\source\rtp_to_ntp_estimator.cc RtpToNtpEstima…...
【DevOps】Elasticsearch在Ubuntu 20.04上的安装与配置:详细指南
目录 一、ES 简介 1、核心概念 2、工作原理 3、 优势 二、ES 在 Ubuntu 20.04 上的安装 1、安装 Java 2、下载 ES 安装包 3、创建 ES 用户 4 、解压安装包 5、 配置 ES 6、 启动 ES 7、验证安装 三、ES 常用命令 1、创建索引 2、 插入文档 3、查询文档 四、ES…...
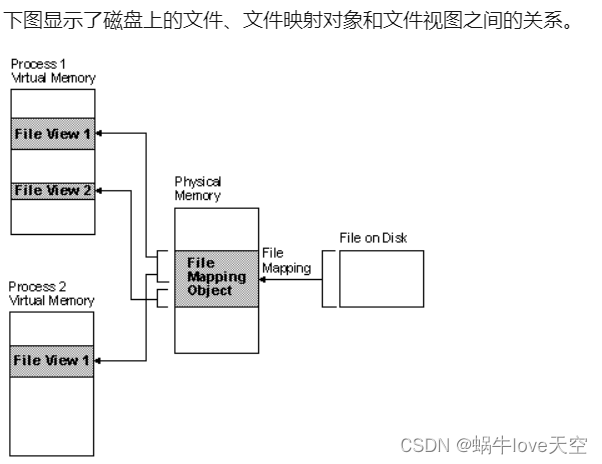
windows内存管理
一 windows系统的内存管理涉及哪些 1.1 虚拟内存管理机制 windows操作系统使用虚拟内存技术,将磁盘文件,通过映射对象(存储在物理内存)关联,映射到虚拟内存作为文件试图。即用户操作"虚拟内存中File View Objec…...
c++ 将指针转换为 void* 后,转换为怎么判断原指针类型?
当将指针转换为void后,擦除了指针所指向对象的类型信息,因此无法通过void指针来判断原始指针的类型。我这里有一套编程入门教程,不仅包含了详细的视频讲解,项目实战。如果你渴望学习编程,不妨点个关注,给个…...

Swift 属性
属性 一、存储属性1、常量结构体实例的存储属性2、延时加载存储属性3、存储属性和实例变量 二、计算属性1、简化 Setter 声明2、简化 Getter 声明3、只读计算属性 三、属性观察器四、属性包装器1、设置被包装属性的初始值2、从属性包装器中呈现一个值 五、全局变量和局部变量六…...

基于maxkey接入jeecgboot并实现账户同步
1. 注册应用 1.1 在统一认证中心注册第三方应用 1.1.1 填写应用名和登录地址 1.1.2 填写认证地址授权方式和作用域 1.1.3 选择权限范围并提交 1.2 配置访问权限 1.2.1 指定用户组 1.1.2 选择注册的应用 1.1.3 在单点登录认证页面查看添加的应用 1.3 同步一个第三方应用的账号…...

3分钟完成Windows和Office永久激活:KMS_VL_ALL_AIO智能激活方案完全指南
3分钟完成Windows和Office永久激活:KMS_VL_ALL_AIO智能激活方案完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为系统激活烦恼吗?每次重装系统或安装Office…...

ChatGPT写代码总出错?揭秘92%开发者忽略的3层提示工程校验机制
更多请点击: https://intelliparadigm.com 第一章:ChatGPT写代码总出错?揭秘92%开发者忽略的3层提示工程校验机制 当ChatGPT生成的代码在本地运行失败、逻辑错位或依赖缺失时,问题往往不在模型本身,而在于提示&#x…...
)
ISTA 3H-2011 全解析|机械搬运散装运输容器综合模拟测试标准(CSDN 完整版)
前言ISTA 3H-2011 是 ISTA 3 系列高级综合模拟性能测试,专门针对机械搬运的散装运输容器,容器可装载同种或不同产品,多用于汽车配件周转箱、工业散装料架、可循环运输容器等场景。标准完整模拟散装容器在物流中的水平冲击、旋转面 / 棱跌落、…...

2026实测:租用RTX 4090 CUDA适配与PyTorch精准安装教程
RTX 4090搭载Ada Lovelace架构、4nm制程工艺,配备16384个CUDA核心、24GB GDDR6X显存、1TB/s显存带宽,FP32算力82.6 TFLOPS,是7B-13B大模型训练、图像识别、深度学习推理的核心主流算力。个人开发者、中小团队自建RTX 4090硬件,存在…...

如何用My-TODOs打造高效跨平台待办清单:免费开源桌面应用终极指南
如何用My-TODOs打造高效跨平台待办清单:免费开源桌面应用终极指南 【免费下载链接】My-TODOs A cross-platform desktop To-Do list. 跨平台桌面待办小工具 项目地址: https://gitcode.com/gh_mirrors/my/My-TODOs 在现代快节奏的工作生活中,高效…...

【AI Agent部署】Claude Code + Ollama/CC Switch 部署指南
Windows11 Claude Code 简单的配置指南方式一和方式二中也是两种Claude Code的安装方式 方式一:NPM 全局安装 依赖Node环境适合原本就用Node开发的用户容易出现全局包路径冲突 方式二:Winget 原生安装(推荐新方案) 无任何依赖&am…...

5大核心功能深度解析:Akebi-GC游戏辅助工具完整使用指南
5大核心功能深度解析:Akebi-GC游戏辅助工具完整使用指南 【免费下载链接】Akebi-GC (Fork) The great software for some game that exploiting anime girls (and boys). 项目地址: https://gitcode.com/gh_mirrors/ak/Akebi-GC Akebi-GC是一款功能强大的游戏…...

如何用Python自动化脚本高效抢购热门演出门票?智能抢票解决方案揭秘
如何用Python自动化脚本高效抢购热门演出门票?智能抢票解决方案揭秘 【免费下载链接】Automatic_ticket_purchase 大麦网抢票脚本 项目地址: https://gitcode.com/GitHub_Trending/au/Automatic_ticket_purchase 还在为热门演唱会门票秒光而烦恼吗࿱…...
)
别再手动调图了!用LaTeX的subcaption包搞定论文子图排版(附完整代码)
LaTeX子图排版终极指南:告别手动调整的5个高效技巧 写论文时最让人抓狂的莫过于图片排版——尤其是当需要排列多个子图时。每次编译后总有几个图片位置不对齐,标题错位,或者直接跑到了下一页。这种反复调试的过程不仅浪费时间,还…...

终极指南:如何在OBS Studio中免费使用VST插件实现专业级音频处理
终极指南:如何在OBS Studio中免费使用VST插件实现专业级音频处理 【免费下载链接】obs-vst Use VST plugins in OBS 项目地址: https://gitcode.com/gh_mirrors/ob/obs-vst 想要让直播声音瞬间达到专业水准?OBS-VST插件就是你的答案!这…...