强化学习——学习笔记
一、什么是强化学习?
强化学习 (Reinforcement Learning, RL) 是一种通过与环境交互来学习决策策略的机器学习方法。它的核心思想是让智能体 (Agent) 在执行动作 (Action)、观察环境 (Environment) 反馈的状态 (State) 和奖励 (Reward) 的过程中,学习到一个最优策略 (Optimal Policy),从而实现长期累积奖励最大化。
强化学习的核心框架包括以下几个部分:
智能体 (Agent):在环境中执行动作,学习最优策略的实体;
环境 (Environment):提供状态信息和奖励反馈,受到智能体动作影响的外部系统;
状态 (State):描述环境当前状况的信息;
动作 (Action):智能体可以在环境中执行的操作;
奖励 (Reward):环境对智能体执行动作的评价,是一个标量值。
举一个小栗子,小明现在有一个问题,他要决定明天是学习还是去打球。现在就有两种可能性,打球和学习,如果现在的情况是,选择打球,那么小明将会受到批评,如果选择学习,他会受到奖励。显然,小明很大可能性会选择学习。这就是强化学习的内部机制。当对象在做一个决策的时候,算法会对每种可能性做一次函数计算,计算得到的结果叫做奖励值,奖励值会作为本次决策的重要参考标准。
具体的过程可以形象化为下图:

作为y一个高级的智能体,我们的大脑每时每刻都在进行决策,但是我们每个决策的过程就是这三个步骤:观察→行动→观测。我们通过观察周围的环境,然后做出相应的行动,然后在行动结束后,外界环境会给我们一个信号,这个信号是说我们的行动对外界造成了一定的影响,这些影响会得到一个结果(实际上就是上文说的奖励值),环境将影响通过这个信号让我们知道了。我们得到这个奖励值后,会根据新的环境和得到的奖励值,来进行下一个决策。
二、什么是马尔可夫过程?
强化学习问题通常可以建模为一个马尔可夫决策过程,包括以下几个要素:
1、状态集合 (State Set):S;
2、动作集合 (Action Set):A ;
3、状态转移函数 (State Transition Function): P ( s ′ ∣ s , a ) P ( s^′∣s,a ) P(s′∣s,a),描述在状态s下执行动作a后转移到状态 s ′ s^′ s′的概率;
4、奖励函数 (Reward Function): R ( s , a , s ′ ) R ( s,a,s^′ ) R(s,a,s′),描述在状态s 下执行动作a并转移到状态s′后获得的奖励。
5、策略 (Policy): π ( a ∣ s ) π (a∣s) π(a∣s),描述智能体在状态s下选择动作a 的概率。
q强化学习的目标是找到一个最优策略 π ∗ π^∗ π∗ ,使得长期累积奖励最大化。
说到这里还是没有说明什么是马尔可夫决策。我们可以看下图:

比如红绿灯系统,红灯之后一定是红黄、接着绿灯、黄灯,最后又红灯,每一个状态之间的变化是确定的。抑或是下图:
 比如今天是晴天,谁也没法百分百确定明天一定是晴天还是雨天、阴天(即便有天气预报)。
比如今天是晴天,谁也没法百分百确定明天一定是晴天还是雨天、阴天(即便有天气预报)。
对于以上的过程,我们假设有如下的状态转移矩阵(从一个状态到另外一个状态的概率):
 如果昨天是晴天,那么今天是晴天的概率为0.5,是多云的概率为0.375、是雨天的概率为0.125,且这三种天气状态的概率之和必为1。
如果昨天是晴天,那么今天是晴天的概率为0.5,是多云的概率为0.375、是雨天的概率为0.125,且这三种天气状态的概率之和必为1。
以上就是马尔可夫决策过程的细节。
具体来说:
1、当且仅当某时刻的状态只取决于上一时刻的状态时,一个随机过程被称为具有马尔可夫性,比如我们在上面两幅图中的情况。
2、具有马尔可夫性质的随机过程便是马尔可夫过程。
在马尔可夫决策过程的基础上,再加上奖励机制,就可以得到马尔可夫奖励过程。
三、什么是马尔可夫奖励过程?
上面所提到的奖励机制包括奖励函数R和折扣因子γ两部分组成。
1、奖励函数:某个状态s的奖励R(s),是指转移到该状态s时可以获得奖励的期望,有 R ( s ) = E [ R t + 1 ∣ S t = s ] R(s)=E[R_{t+1}|S_{t=s}] R(s)=E[Rt+1∣St=s]。也就是在状态s下奖励的期望。
奖励函数又包括如下两类:
状态价值函数 (Value Function): V π ( s ) V^\pi(s) Vπ(s),描述在状态s下,依据策略 π \pi π执行动作后能获得的未来累积奖励的期望。
动作价值函数 (Q-function): Q π ( s , a ) Q^\pi(s, a) Qπ(s,a),描述在状态s下执行动作a 并依据策略 π \pi π执行后续动作能获得的未来累积奖励的期望。
在目前多数的强化学习方法中,都是围绕动作价值函数展开研究的。
2、折扣因子 (Discount Factor)γ
γ取值范围为 [0, 1],表示未来奖励的折扣程度。在这里有一种解释是当一个很久发生的动作所获得奖励会随着时间的推移而慢慢变小的,比如货币贬值的现象。在强化学习中这是一个超参数的存在。
如下式所示:

在上式中,G表示当下即时奖励和所有持久奖励等一切奖励的加权和(考虑到一般越往后某个状态给的回报率越低,也即奖励因子或折扣因子越小,用γ表示)。
四、什么是马尔可夫决策过程?
在上文中已经对马尔可夫奖励过程进行了基本的介绍,如果在马尔可夫奖励过程的基础上增加一个来自外界的刺激比如智能体的动作,就得到了马尔可夫决策过程通俗讲,马尔可夫奖励过程与马尔可夫决策过程的区别就类似随波逐流与水手划船的区别。具体来说,在马尔可夫决策过程中, S t S_t St和 R t R_t Rt的每个可能的值出现的概率只取决于前一个状态 S t − 1 S_{t−1} St−1和前一个动作 A t − 1 A_{t−1} At−1,并且与更早之前的状态和动作完全无关。
当给定当前状态 S t S_t St(比如 S t = s S_t=s St=s),以及当前采取的动作 A t A_t At(比如 A t = a A_t=a At=a),那么下一个状态 S t + 1 S_{t+1} St+1出现的概率,可由状态转移概率矩阵表示。故有下式:

上式表达的意思为:在状态 s s s下采取动作 a a a后,转移到下一个状态 s ′ s^′ s′的概率。
假定在当前状态和当前动作确定后,其对应的奖励则设为 R t + 1 = r R_{t+1=r} Rt+1=r,状态转移概率矩阵类似为:

上式表达的意思为:在状态 s s s下采取动作 a a a后,转移到下一个状态 s ′ s^′ s′并获得奖励r的概率。
最终可以得到奖励函数即为:

上式表达的意思为:在状态s以及动作a的发生下,对所有接下来可能的奖励r求和,这里的r有不确定性,受环境所限制。
整个过程相当于将不同状态转移概率与对应的奖励r相乘并相加,以得到条件期望。
假设奖励是确定性的,则可以简化公式,去掉对r的求和,即:

因此上式就变为了只需要计算在状态s下采取动作a后,转移到下一个状态s′的概率乘确定的奖励r,然后对所有可能的下一个状态s′求和以得到条件期望。
这时我们还有一个疑问,如果环境反馈给我们一个现在智能体所处的状态,智能体要通过什么方式决定接下来的动作呢?这时就涉及到策略policy,策略函数可以表述为π
函数。
可得 a = π ( s ) a=π(s) a=π(s),意味着输入状态s,策略函数π输出动作a。
策略函数还有如下两种表达方式:
1、 a = π θ ( s ) a=πθ(s) a=πθ(s)
上式所要表达的意思为:当于在输入状态s确定的情况下,输出的动作a只和参数θ
有关,这个θ就是策略函数π的参数。举个例子就是y=wx+b中的w和b。
2、 π ( a ∣ s ) = P ( A t = a ∣ S t = s ) π(a|s)=P(A_{t=a}|S_{t=s}) π(a∣s)=P(At=a∣St=s),
上式所要表达的意思为:相当于输入一个状态s下,智能体采取某个动作a的概率。
以上文中的天气状态为例:不同状态出现的概率不一样(比如今天是晴天,那明天是晴天,还是雨天、阴天不一定),同一状态下执行不同动作的概率也不一样(比如即便在天气预报预测明天大概率是天晴的情况下,你大概率不会带伞,但依然不排除你可能会防止突然下雨而带伞)。
经过上文的基本介绍之后让我们再重新定义一下最初提到的两个价值函数。
状态价值函数:
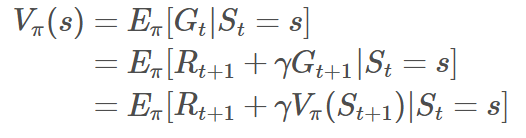
上式所要表达的意思就是从状态s出发遵循策略π能获得的期望回报。
动作价值函数:

上式所要表达的意思就是当前状态s依据策略执行动作a得到的期望回报,记住这个函数,在接下来的算法中会常常涉及到,得到Q函数后,进入某个状态要采取的最优动作便可以通过Q函数得到。
以上两个函数对应的流程如下图:

有了上述推导,我们可以知道Q函数怎么转换到状态价值函数的,如下式:

具体可以解释为下式,状态s的价值等于在该状态下基于策略π采取所有动作的概率与相应的价值相乘再求和的结果。
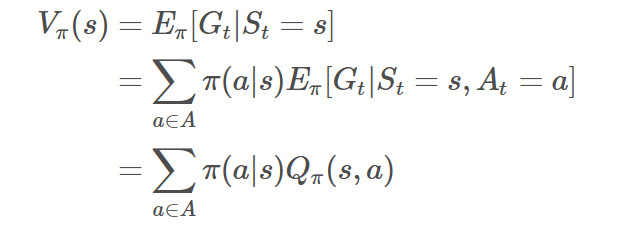
而从状态价值函数转换到Q函数如下式:

推导过程如下:
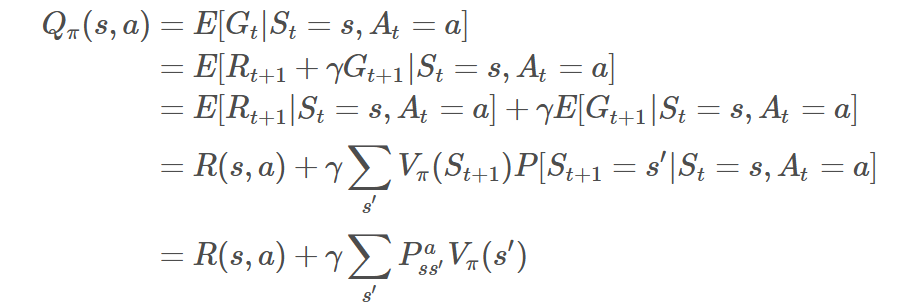
在状态s下采取动作a的价值等于当前奖励R(s,a),加上经过衰减的所有可能的下一个状态的状态转移概率与相应的价值的乘积。
经过上式互相带入我们就可以得到马尔可夫决策的贝尔曼方程:

下图即为马尔可夫决策过程。

上图展示了在什么样的状态s下,有多少概率会做出动作a,这就是一个决策过程。如上图。当做出动作a,环境会给智能体反馈一个环境以及奖励。
整理自:https://blog.csdn.net/v_JULY_v/article/details/128965854
相关文章:
强化学习——学习笔记
一、什么是强化学习? 强化学习 (Reinforcement Learning, RL) 是一种通过与环境交互来学习决策策略的机器学习方法。它的核心思想是让智能体 (Agent) 在执行动作 (Action)、观察环境 (Environment) 反馈的状态 (State) 和奖励 (Reward) 的过程中,学习到…...

NAT简介
一、NAT 概念定义 NAT(Network Address Translation,网络地址转换)是一种将私有 IP 地址转换为公有 IP 地址的技术。 允许一个组织内部使用私有 IP 地址的网络通过少量的公有 IP 地址连接到互联网。实现了私有网络与外部网络的通信…...

联想凌拓 NetApp AFF C250 全闪存存储助力丰田合成打造数据新“引擎”
联想凌拓 NetApp AFF C250全闪存存储助力丰田合成打造数据新“引擎” 丰田合成(张家港)科技有限公司(以下简称“丰田合成”)于2003年12月成立,坐落在中国江苏省张家港市保税区中华路113号,是日本丰田合成株…...

红队技巧:仿冒Windows登录
Metasploit框架:phish_windows_credentials Metasploit带有内置的后期漏洞利用功能,可帮助我们完成任务。由于它是后渗透的模块,因此只需要输入会话即可: use post/windows/gather/phish_windows_credentials set session 1 …...

821. 字符的最短距离 - 力扣
1. 题目 给你一个字符串 s 和一个字符 c ,且 c 是 s 中出现过的字符。 返回一个整数数组 answer ,其中 answer.length s.length 且 answer[i] 是 s 中从下标 i 到离它 最近 的字符 c 的 距离 。 两个下标 i 和 j 之间的 距离 为 abs(i - j) ,…...

BI工具如何为金融行业带来变革?金融行业营销管理策略大揭秘
当今数字化时代,金融行业正经历着前所未有的变革。随着大数据、人工智能、区块链等新兴技术的兴起,金融机构正面临着重新定义服务模式、风险管理和客户体验的挑战。商业智能(BI)作为这一变革的关键驱动力,已经成为金融…...

操作系统 - 计算机系统概述
事前提一嘴 室友考完研了,下一年就是我了,真不想和他们一起考,压力太大了,这里分享一点笔记吧 采用王道考研的书以及视频,去掉了一些书上的废话,加上了视频中的重点,最后总结出来的 如有侵权&a…...

[论文笔记]REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
引言 今天带来一篇经典论文REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS的阅读笔记,论文中文意思是 在语言模型中协同推理和行动。 虽然大型语言模型(LLMs)在语言理解和互动决策任务中展现出强大的能力,但它们在推理(例如思维链提示)和…...

[]下标的意义
数组: int array[10]; array[0]获取的是值,还是引用? std::map<int,string> m_map; m_map[0]返回的是引用还是值,还是指针。 #include <iostream> #include <map> #include <vector> #include <al…...
去重复记录和排序——kettle开发09
一、去除重复记录 去除重复记录,就是将数据流中的数据进行字段比较,从而去掉重复值的过程。去除重复记录的前提是需要将数据流中的数据进行排序,然后再进行去重操作。 去除重复记录的逻辑是,如下图,我们将需要比较的…...

中创算力与中国移动初步达成战略合作意向,共同构建智能生态圈!
2024年5月14日,为进一步深化合作,促进业务共同发展,实现双方优势互补。中国移动云能力中心高级专家、郑州移动总经理助理邵根波、管城分公司政企部经理张文孟、航海东路分局张旭红莅临中创算力。中创董事长许伟威、副总经理杨光、技术总监刘朝…...
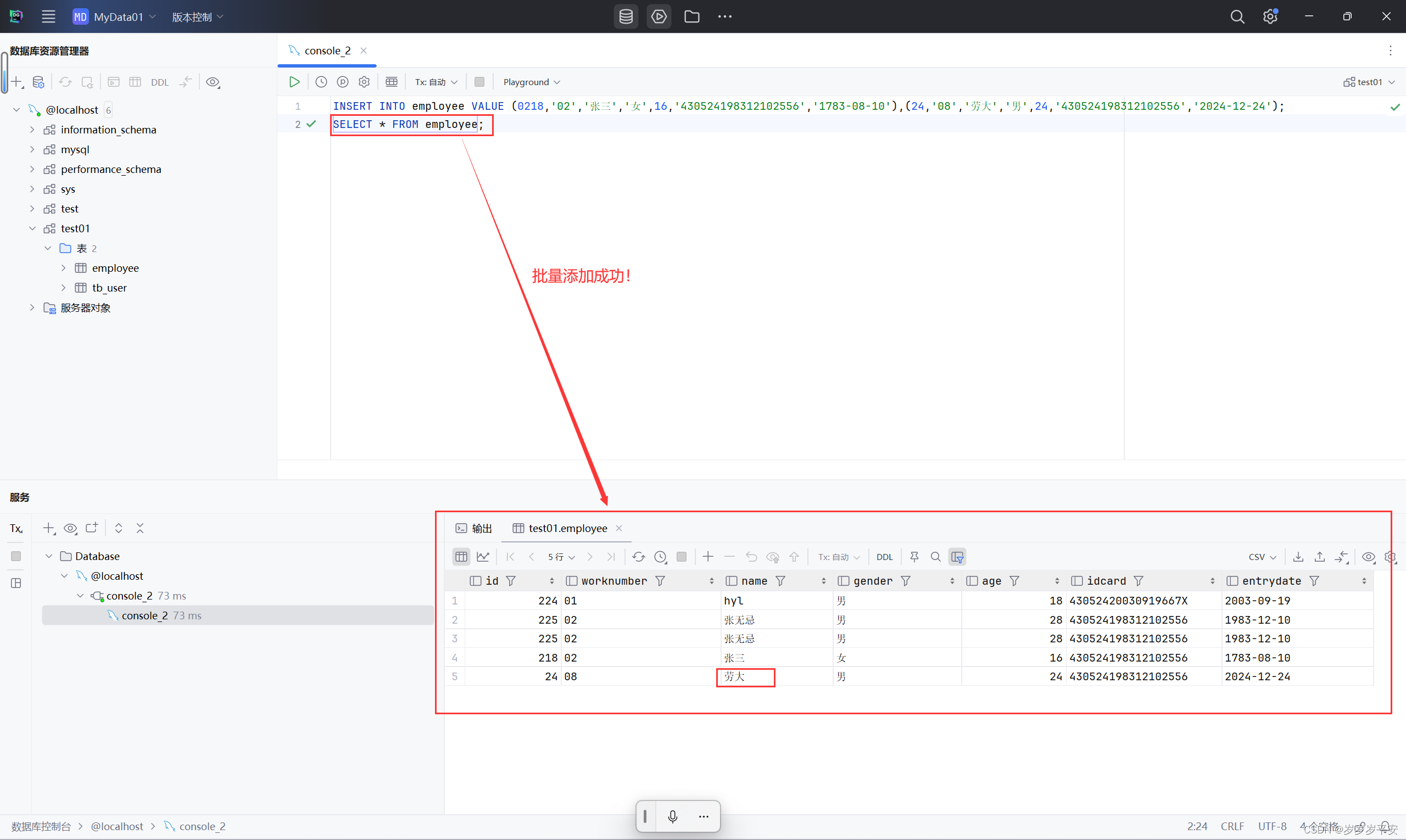
基础—SQL—DML(数据操作语言)插入数据
一、介绍 分类全称说明DMLData Manipulation Language数据操作语言。用来对数据库表中的数据进行增删改(插入、删除、修改) 则增、删、改是三个操作也就对应着三个关键字,分别是: 添加数据:( INSERT )修改数据&#…...

【改變,是面對的開始】
改變,不是為了逃避無法解決的困境,而是為了面對心靈深處最懼怕的聲音。 她離開宛如人間天堂的義大利,轉往物質相對匱乏的印度,想藉由清修的方式,理清混亂的內在,重新與自己對話。 赫然發現,認…...

AI大模型实现德语口语练习
利用AI大模型实现德语口语练习的应用需要整合多种技术和资源,以确保学生能够获得全面、互动和有效的学习体验。以下是实现德语口语练习应用的详细流程和技术要点。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 实现流程 …...

一文读懂npm i的命令以及作用
目录 1. 基本知识2. 常见用法 1. 基本知识 npm i 是 Node Package Manager (npm) 的一个命令,用于安装 Node.js 项目依赖的包 是 npm install 的简写形式,功能完全相同 详细解析 npm: npm 是 Node.js 的包管理工具,用于安装、共…...

You don‘t have enough free space或者no space left on device异常
1.磁盘空间不足 Linux安装软件显示 You dont have enough free space 或者docker拉镜像时,出现磁盘空间不足的情况 no space left on device 如果你是ubuntu系统。查看磁盘空间 df -h 多半是这个目录满了/dev/mapper/ubuntu--vg-ubuntu--lv 大多情况我们只希望扩…...

饮料添加剂新型褪色光照试验仪器太阳光模拟器
太阳光模拟器的定义和功能 太阳光模拟器是一种高科技设备,它可以模拟太阳光的光谱、光强和光照条件,用于实验室环境中对太阳能电池、光电器件以及其他需要太阳光条件的设备和材料进行评估。太阳光模拟器的主要功能包括模拟太阳光的光谱分布、辐照度、光…...

ElasticSearch - 删除已经设置的认证密码(7.x)
文章目录 Pre版本号 7.x操作步骤检查当前Elasticsearch安全配置停止Elasticsearch服务修改Elasticsearch配置文件删除密码重启Elasticsearch服务验证配置 小结 Pre Elasticsearch - Configuring security in Elasticsearch 开启用户名和密码访问 版本号 7.x ES7.x 操作步骤 …...

9.4 Go语言入门(运算符)
Go语言入门(运算符) 目录三、运算符1. 算术运算符2. 关系运算符3. 逻辑运算符4. 位运算符5. 赋值运算符6. 其他运算符7. 运算符优先级 目录 Go 语言(Golang)是一种静态类型、编译型语言,由 Google 开发,专注…...

CLIP 源码分析:simple_tokenizer.py
tokenizer的含义 from .clip import *引入头文件时为什么有个. 正文 import gzip import html import os from functools import lru_cacheimport ftfy import regex as re# 上面的都是头文件# 这段代码定义了一个函数 default_bpe(),它使用了装饰器 lru_cache()。…...
)
别再手动刷权重了!用Maya的ADV插件,30分钟搞定角色身体绑定(附减模包裹技巧)
别再手动刷权重了!用Maya的ADV插件30分钟完成角色身体绑定 角色绑定一直是三维动画制作中的痛点环节。记得刚入行时,我曾为一个穿着皮夹克的游戏角色手动刷权重整整两天,结果肘部变形依然不自然。直到接触ADV插件的减模包裹功能,…...

在数据分析和报告自动化场景中集成Taotoken调用大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在数据分析和报告自动化场景中集成Taotoken调用大模型 数据分析与报告生成是许多团队日常工作中的高频任务。传统流程中࿰…...

8. Python 模块与包 深度解析
Python 模块与包 深度解析 目录 模块与包的概念模块基础 2.1 模块即 .py 文件2.2 import 语句与 from ... import2.3 模块搜索路径 sys.path 模块的编译与缓存包 4.1 常规包与 __init__.py4.2 命名空间包4.3 相对导入与绝对导入 __name__ 与 "__main__"模块与包的组…...

在Windows通知栏悄悄学习:ToastFish让你的碎片时间变成单词记忆神器
在Windows通知栏悄悄学习:ToastFish让你的碎片时间变成单词记忆神器 【免费下载链接】ToastFish 一个利用摸鱼时间背单词的软件。 项目地址: https://gitcode.com/GitHub_Trending/to/ToastFish 想象一下这样的场景:你正在办公室里忙碌地处理文件…...

3分钟实现GitHub界面汉化:浏览器插件让GitHub说中文
3分钟实现GitHub界面汉化:浏览器插件让GitHub说中文 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 你是否曾因GitHub的英…...

2026三相温升交直流升流器:现场检修的“移动电源”
干抢修最怕遇到怀疑母线或开关接触不良导致过热的情况。大半夜的,不可能把设备拆下来送回厂里试验。有一次处理一个110kV隔离开关发热缺陷,换完触头,必须马上验证温升合格才能送电。那时候用的老式升流器又笨又重,从车上抬下来接线…...

群晖SSH远程访问全链路打通指南
1. 为什么群晖的SSH不是“开个开关”就完事的很多人第一次在群晖DSM界面里点开“控制面板 > 终端机和SNMP > 启用SSH服务”,看到端口22打钩、状态显示“已启用”,就以为大功告成,兴冲冲拿Mac或Windows的终端连一下——结果ssh admin192…...

《从 0 实现 SGLang》第 1 篇 · LLM 推理引擎到底在做什么
千行代码,一步步搭出一个现代 LLM 推理引擎,吃透大模型推理的每一项关键技术。 本阶段目标 — 最简推理实现 用最朴素的方式把端到端推理跑通:先搭起整体框架,再逐个模块替换为完整实现。整个阶段共 5 篇短文: 序号…...

Rust技术周刊 2026年第16周
阅读原文: https://mp.weixin.qq.com/s/9en-gxsNB544aG6hgkwJVQ 本周 Rust 生态亮点:GPU 计算突破(KAIO 达 cuBLAS 92.5%、flodl 多 GPU 训练),Tokio 异步优化实战频出,扩展标准库路线图发布,Rust 进入 Pix…...

随机森林在精准农业中的落地实践:地理空间建模与田间部署
1. 项目概述:当随机森林遇上农田里的厘米级变量在华北平原某农场的冬小麦田里,我第一次用随机森林模型预测氮肥施用量时,手里的无人机刚飞完第三圈,地面传感器网络正把土壤电导率、含水量、温度的实时数据推送到边缘计算节点。这不…...