【MySQL精通之路】查询优化器的使用(8)
MySQL通过影响查询计划评估方式的系统变量、可切换优化、优化器和索引提示以及优化器成本模型提供优化器控制。
服务器在column_statistics数据字典表中维护有关列值的直方图统计信息(请参阅第10.9.6节“Optimizer统计信息”)。与其他数据字典表一样,用户无法直接访问此表。相反,您可以通过查询information_SCHEMA来获取直方图信息。COLUMN_STATISTICS,它被实现为数据字典表上的视图。您还可以使用ANALYZE TABLE语句执行直方图管理。
1.控制查询计划评估
查询优化器的任务是找到执行SQL查询的最佳计划。由于“好”和“坏”计划之间的性能差异可能是几个数量级(即秒与小时甚至天),因此大多数查询优化器,包括MySQL的查询优化器,都会在所有可能的查询评估计划中或多或少地搜索最优计划。
对于联接查询,MySQL优化器调查的可能计划的数量随着查询中引用的表的数量呈指数级增长。对于少量的表(通常少于7到10个),这不是问题。然而,当提交更大的查询时,用于查询优化的时间很容易成为服务器性能的主要瓶颈。
一种更灵活的查询优化方法使用户能够控制优化器在搜索最佳查询评估计划时的详尽程度。一般的想法是,优化器调查的计划越少,编译查询所花费的时间就越少。另一方面,由于优化器跳过了一些计划,它可能无法找到最佳计划。
优化器相对于其评估的计划数量的行为可以使用两个系统变量进行控制:
optimizer_prune_level变量告诉优化器根据每个表访问的行数估计跳过某些计划。
我们的经验表明,这种“有根据的猜测”很少会错过最佳计划,并可能大大减少查询编译时间。这就是为什么默认情况下此选项处于启用状态(optimizer_prune_level=1)。
但是,如果您认为优化器错过了更好的查询计划,则可以关闭此选项(optimizer_prune_level=0),这样可能会导致查询编译耗时更长。
请注意,即使使用了这种启发式方法,优化器仍然会探索大致指数数量的计划。
optimizer_search_depth变量告诉优化器应该在每个不完整计划的“未来”中将查看的深度,以评估是否应该进一步扩展。
optimizer_search_depth的值越小,查询编译时间就越小。
例如,如果optimizer_search_depth接近查询中的表数,则具有12个、13个或更多表的查询
可能很容易需要数小时甚至数天才能编译。
同时,如果使用等于3或4的optimizer_search_depth进行编译,则优化器可以在不到一分钟的时间内对同一查询进行编译。
如果您不确定optimizer_search_depth的合理值是多少,可以将该变量设置为0,以告诉优化器自动确定该值。
2.可切换优化
优化器开关系统变量可以控制优化器的行为。
它的值是一组标志,每个标志的值为on或off,以指示相应的优化器行为是启用还是禁用。
此变量具有全局值和会话值,可以在运行时更改。
全局默认值可以在服务器启动时设置。
要查看当前的优化器标志集,请选择变量值:
mysql> SELECT @@optimizer_switch\G
*************************** 1. row ***************************
@@optimizer_switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=on,subquery_to_derived=off,prefer_ordering_index=on,hypergraph_optimizer=off,derived_condition_pushdown=on
1 row in set (0.00 sec)要更改optimizer_switch的值,请指定一个由一个或多个命令的逗号分隔列表组成的值:
SET [GLOBAL|SESSION] optimizer_switch='command[,command]...';每个命令值都应具有下表所示的其中一种形式。
| 命令 | 意义 |
|---|---|
default | 将每个优化重置为其默认值 |
| 将命名优化设置为其默认值 |
| 禁用命名优化 |
| 启用命名优化 |
值中命令的顺序无关紧要,尽管默认命令会首先执行(如果存在)。
将opt_name标志设置为default会将其设置为on或off中的默认值。
不允许在值中多次指定任何给定的opt_name,这会导致错误。
值中的任何错误都会导致赋值失败并出现错误,使优化器开关的值保持不变。
以下列表描述了按优化策略分组的允许的opt_name标志名称:
2.1 批处理密钥访问标志
batched_key_access(默认关闭)
控制BKA联接算法的使用。
batched_key_access在设置为on时要有任何效果,mrr标志也必须为on。
目前,mrr的成本估计过于悲观。因此,也有必要关闭mrr_cost_based以使用BKA。
有关更多信息,请参阅“块嵌套循环和批处理Key访问连接”。
【MySQL精通之路】SQL优化(1)-查询优化(12)-块嵌套循环和批处理Key访问联接-CSDN博客
2.2 块嵌套循环标志
block_nested_roop(默认启用)
控制BNL联接算法的使用。
在MySQL 8.0.18及更高版本中,这也控制了散列联接的使用,BNL和NO_BNL优化器提示也是如此。
在MySQL 8.0.20及更高版本中,从MySQL服务器中删除了块嵌套循环支持,该标志仅控制散列联接的使用,引用的优化器提示也是如此。
有关更多信息,请参阅“块嵌套循环和批处理Key访问连接”。
【MySQL精通之路】SQL优化(1)-查询优化(12)-块嵌套循环和批处理Key访问联接-CSDN博客
2.3 条件筛选标志
condition-fanout-filter(默认打开)
控制条件筛选的使用。
【MySQL精通之路】SQL优化(1)-查询优化(13)-条件过滤-CSDN博客
未完待续。。。
相关文章:
)
【MySQL精通之路】查询优化器的使用(8)
MySQL通过影响查询计划评估方式的系统变量、可切换优化、优化器和索引提示以及优化器成本模型提供优化器控制。 服务器在column_statistics数据字典表中维护有关列值的直方图统计信息(请参阅第10.9.6节“Optimizer统计信息”)。与其他数据字典表一样&am…...
原理与实践)
Docker in Docker(DinD)原理与实践
随着云计算和容器化技术的快速发展,Docker作为开源的应用容器引擎,已经成为企业部署和管理应用程序的首选工具。然而,在某些场景下,我们可能需要在Docker容器内部再运行一个Docker环境,即Docker in Docker(…...

科技前沿:IDEA插件Translation v3.6 带来革命性更新,翻译和发音更智能!
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …...

【并发小知识】
计算机五大组成部分 控制器 运算器 存储器 输入设备 输出设备 计算机的核心真正干活的是CPU(控制器运算器中央处理器) 程序要想计算机运行,它的代码必须要先由硬盘读到内存,之后cpu取指再执行 操作系统发展史 穿孔卡片处理…...

python将多个音频文件与一张图片合成视频
代码中m4a可以换成mp3,图片和音频放同一目录,图片名image.jpg,多线程max_workers可以根据CPU核心数量修改。 import os import subprocess import sys import concurrent.futures import ffmpeg def get_media_duration(media_path): probe ffmp…...

JavaEE:Servlet创建和使用及生命周期介绍
目录 ▐ Servlet概述 ▐ Servlet的创建和使用 ▐ Servlet中方法介绍 ▐ Servlet的生命周期 ▐ Servlet概述 • Servlet是Server Applet的简称,意思是 用Java编写的服务器端的程序,Servlet被部署在服务器中,而服务器负责管理并调用Servle…...

【Python设计模式15】适配器模式
适配器模式(Adapter Pattern)是一种结构型设计模式,它允许将一个类的接口转换成客户希望的另一个接口。适配器模式使得原本由于接口不兼容而无法一起工作的类能够一起工作。通过使用适配器模式,可以使得现有的类能够适应新的接口需…...

【Python设计模式05】装饰模式
装饰模式(Decorator Pattern)是一种结构型设计模式,它允许向一个现有对象添加新的功能,同时又不改变其结构。装饰模式通过创建一个装饰类来包裹原始类,从而在不修改原始类代码的情况下扩展对象的功能。 装饰模式的结构…...

kafka 消费模式基础架构
kafka 消费模式 &基础架构 目录概述需求: 设计思路实现思路分析1.kafka 消费模式基础架构基础架构2: 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your perfect code,full busy,skip hardness,…...

nginx安装部署问题
记一次nginx启动报错问题处理 问题1 内网部署nginx,开始执行make,执行不了,后面装了依赖的环境 yum install gcc-c 和 yum install -y pcre pcre-devel 问题2,启动nginx报错 解决nginx: [emerg] unknown directive “stream“ in…...
Serializable使用详解)
揭开Java序列化的神秘面纱(上)Serializable使用详解
Java序列化(Serialization)作为一项核心技术,在Java应用程序的多个领域都有着广泛的应用。无论是通过网络进行对象传输,还是实现对象的持久化存储,序列化都扮演着关键的角色。然而,这个看似简单的概念蕴含着丰富的原理和用法细节&…...

深度学习——自己的训练集——图像分类(CNN)
图像分类 1.导入必要的库2.指定图像和标签文件夹路径3.获取文件夹内的所有图像文件名4.获取classes.txt文件中的所有标签5.初始化一个字典来存储图片名和对应的标签6.遍历每个图片名的.txt文件7.随机选择一张图片进行展示8.构建图像的完整路径9.加载图像10.检查图像是否为空 随…...

goimghdr,一个有趣的 Python 库!
更多Python学习内容:ipengtao.com 大家好,今天为大家分享一个有趣的 Python 库 - goimghdr。 Github地址:https://github.com/corona10/goimghdr 在图像处理和分析过程中,识别图像文件的类型是一个常见的需求。Python自带的imghdr…...

每小时电量的计算sql
计算思路,把每小时的电表最大记录取出来,然后用当前小时的最大值减去上个小时的最大值即可。 使用了MYSQL8窗口函数进行计算。 SELECT b.*,b.epimp - b.lastEmimp ecValue FROM ( SELECT a.deviceId,a.ctime,a.epimp, lag(epimp) over (ORDER BY a.dev…...
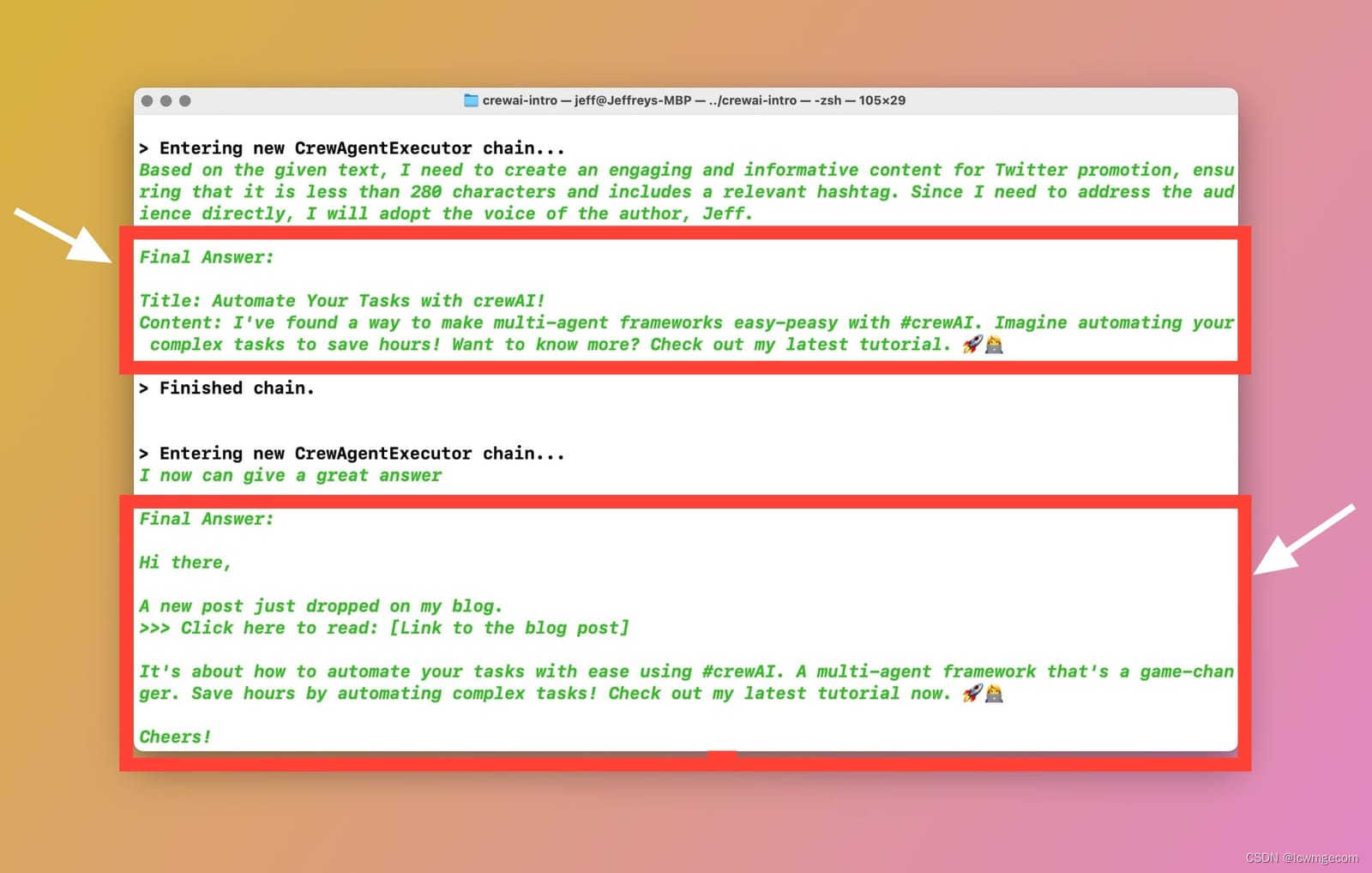
自动化您的任务——crewAI 初学者教程
今天,我写这篇文章是为了分享您开始使用一个非常流行的多智能体框架所需了解的所有信息:crewAI。 我将在这里或那里跳过一些内容,使本教程成为一个精炼的教程,概述帮助您入门的关键概念和要点 今天,我写这篇文章是为了…...
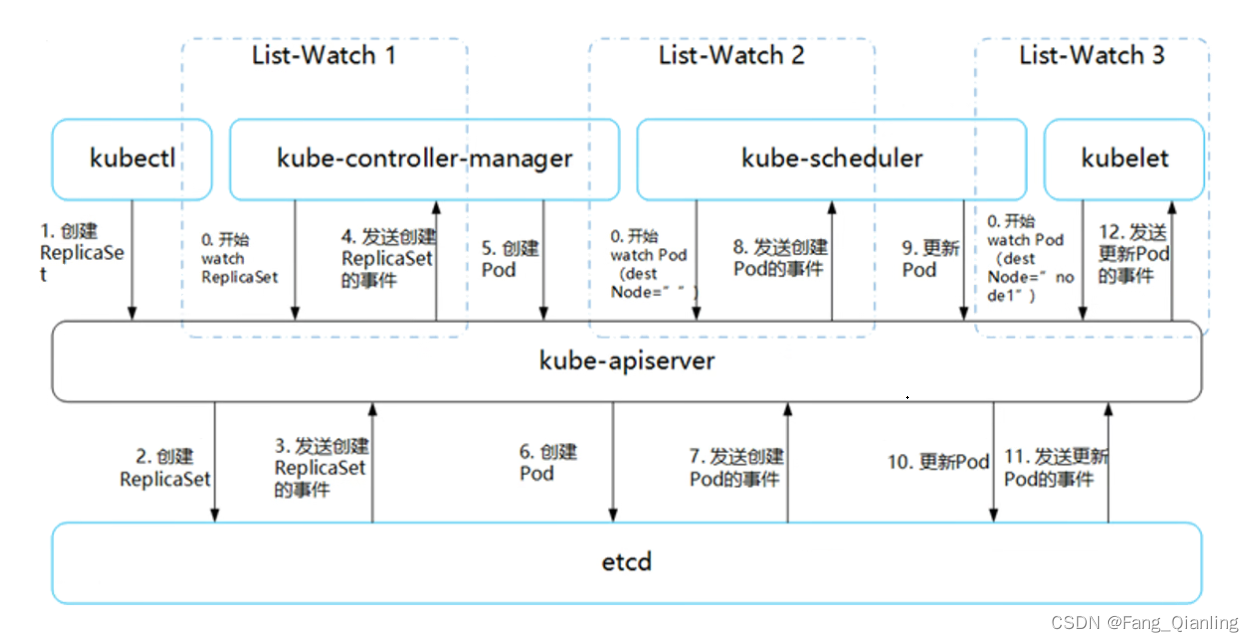
K8s集群中的Pod调度约束亲和性与反亲和性
前言 在 K8s 集群管理中,Pod 的调度约束——亲和性(Affinity)与反亲和性(Anti-Affinity)这两种机制允许管理员精细控制 Pod 在集群内的分布方式,以适应多样化的业务需求和运维策略。本篇将介绍 K8s 集群中…...

kafka之consumer参数auto.offset.reset
Kafka的auto.offset.reset 参数是用于指定消费者在启动时如何处理偏移量(offset)的。这个参数有三个主要的取值:earliest、latest和none。 earliest: 当各分区下有已提交的offset时,从提交的offset开始消费;…...
回答篇二:测试开发高频面试题目
引用之前文章:测试开发高频面试题目 本篇文章是回答篇(持续更新中) 1. 在测试开发中使用哪些自动化测试工具和框架?介绍一下你对其中一个工具或框架的经验。 a. 测试中经常是用的自动化测试工具和框架有Selenium、Pytest、Postman…...
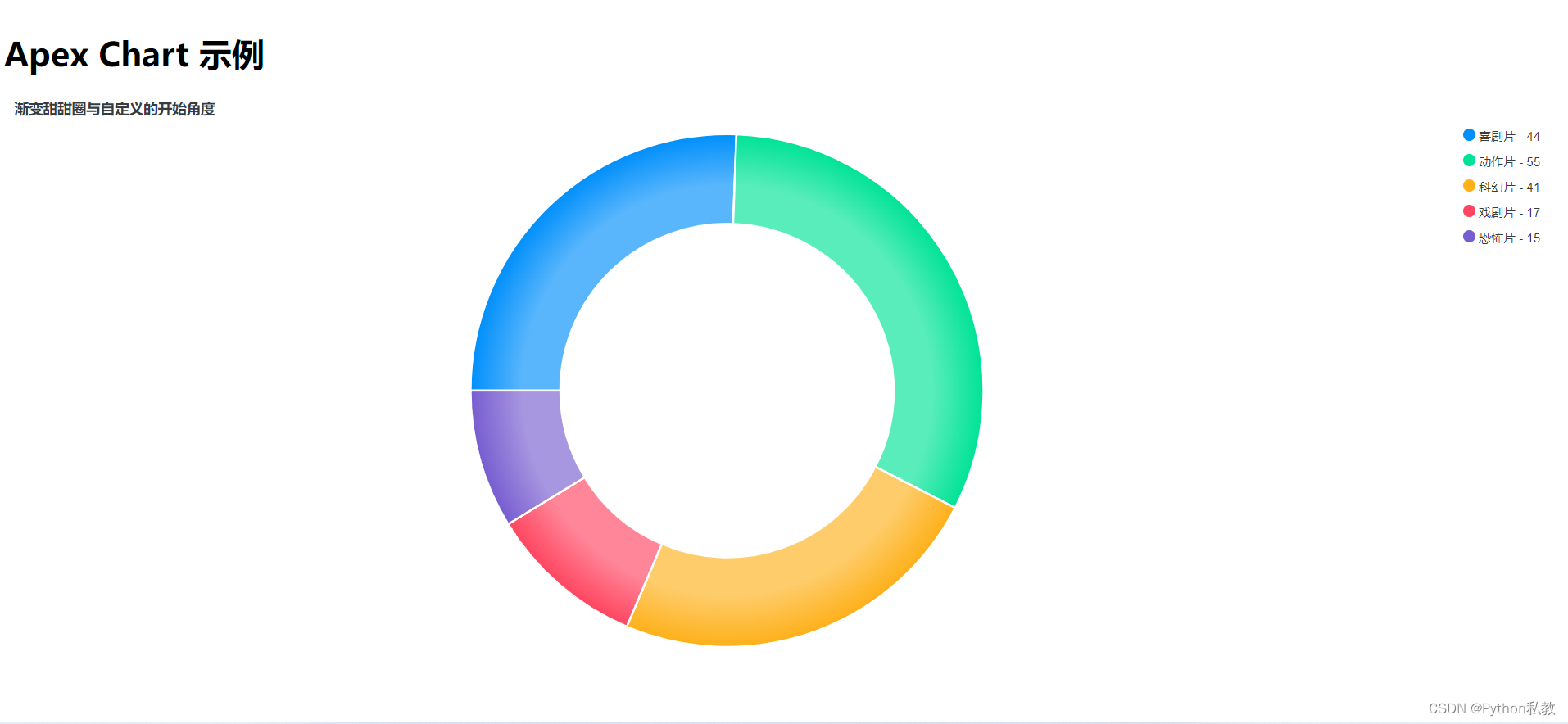
React18 apexcharts数据可视化之甜甜圈图
03 甜甜圈图 apexcharts数据可视化之甜甜圈图。 有完整配套的Python后端代码。 本教程主要会介绍如下图形绘制方式: 基本甜甜圈图个性图案的甜甜圈图渐变色的甜甜圈图 面包圈 import ApexChart from react-apexcharts;export function DonutUpdate() {// 数据…...

如何通过OpenHarmony的音频模块实现录音变速功能?
简介 OpenAtom OpenHarmony(以下简称“OpenHarmony”)是由开放原子开源基金会孵化及运营的开源项目,是面向全场景、全连接、全智能时代的智能物联网操作系统。 多媒体子系统是OpenHarmony系统中的核心子系统,为系统提供了相机、…...

Pure Live:你的纯净直播聚合解决方案,告别平台切换烦恼
Pure Live:你的纯净直播聚合解决方案,告别平台切换烦恼 【免费下载链接】pure_live A Flutter project can make you watch live with ease. 项目地址: https://gitcode.com/gh_mirrors/pu/pure_live 你是否曾为同时关注多个直播平台的主播而感到…...

ReTerraForged终极指南:5步掌握Minecraft高级地形生成技术
ReTerraForged终极指南:5步掌握Minecraft高级地形生成技术 【免费下载链接】ReTerraForged TerraForged for modern MC versions 项目地址: https://gitcode.com/gh_mirrors/re/ReTerraForged ReTerraForged是一款专为现代Minecraft版本设计的革命性地形生成…...

3分钟快速上手:AutoCAD字体管理终极方案FontCenter完整教程
3分钟快速上手:AutoCAD字体管理终极方案FontCenter完整教程 【免费下载链接】FontCenter AutoCAD自动管理字体插件 项目地址: https://gitcode.com/gh_mirrors/fo/FontCenter 还在为AutoCAD字体缺失问题烦恼吗?每次打开同事的图纸都遇到文字乱码、…...

论文被吐槽逻辑乱?,有哪些真正值得入手的的AI智能降重工具推荐?
毕业论文降AIGC率,优先选语义重构 学术优化 去AI痕迹的工具,免费与付费结合更高效。下面按中文、英文、免费/付费分类推荐,附实测效果与适用场景。 一、中文论文降重工具(最常用) 1. 千笔AI(综合全能首选…...

ODS怎么转PDF?5种转换方法对比与2026实测工具推荐
当你拿到OpenDocument电子表格(ODS格式)文件,却需要分享成PDF格式时,转换往往成为一个必要步骤。ODS是LibreOffice等开源办公套件的标准格式,具有高度兼容性和数据完整性,但在跨平台分享和打印时࿰…...

Suno.cn从工具到生态,AI音乐平台的崛起、挑战与本土化之路
2026年,Suno已从一款“文字生成音乐”的玩具,成长为估值25亿美元、年营收超3亿美元的全球AI音乐巨头。然而,在版权风暴与本土化浪潮中,它的故事远未结束。 🚀 一、市场地位与商业成功:Suno的狂飙突进 Suno在2026年的增长堪称现象级。其首席执行官Mikey Shulman宣布,平…...

bezier-easing性能优化秘籍:牛顿迭代与二分搜索算法详解
bezier-easing性能优化秘籍:牛顿迭代与二分搜索算法详解 【免费下载链接】bezier-easing cubic-bezier implementation for your JavaScript animation easings – MIT License 项目地址: https://gitcode.com/gh_mirrors/be/bezier-easing 在现代Web动画开发…...
)
STM32CubeIDE新手避坑:如何正确添加自定义文件夹(以OLED驱动为例)
STM32CubeIDE工程管理实战:从零构建模块化OLED驱动框架 第一次在STM32CubeIDE中引入第三方驱动时,90%的开发者都会在头文件引用环节卡壳。那些看似简单的"../BSP/oled.h"路径背后,隐藏着嵌入式工程管理的核心逻辑。本文将用真实的O…...
细分学习)
Linux Capabilities(能力机制)细分学习
文章目录一. 网络相关 (Network)二. 系统与内核管理 (System & Kernel)三. 进程与信号管理 (Process & Signal)四. 文件系统与存储 (Filesystem & Storage)五. 审计与安全 (Audit & Security)六. IPC (进程间通信)七 在 Docker/K8s 中使用7.1. 只赋予网络管理能…...

XXMI启动器:6款热门二次元游戏模组一站式管理终极指南
XXMI启动器:6款热门二次元游戏模组一站式管理终极指南 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI启动器是一款专为二次元游戏爱好者设计的开源模组管理平台…...