查找、排序、二叉树的算法,统统记录于此。
文章目录
- 一、查找
- 1. 无序表的顺序查找
- 2. 折半查找
- 3. 分块查找
- 4. 二叉排序树BST
- 5. 哈希表查找
- 二、排序
- 1. 不带哨兵的直接插入排序
- 2. 带哨兵的直接插入排序
- 3. 带哨兵、折半查找的直接插入排序
- 4. 希尔排序
- 5. 冒泡排序
- 6. 快速排序
- 7. 选择排序
- 8. 堆排序
- 9. 归并排序
- 二叉树
- 1. 递归先序遍历
- 2. 非递归先序遍历
- 3. 递归中序遍历
- 4. 非递归中序遍历
- 5. 递归后序遍历
- 6. 非递归后序遍历
- 7. 广度遍历二叉树
- 8. 深度遍历
一、查找
1. 无序表的顺序查找
把待查关键字key存入表头(哨兵),从后向前逐个比较,可免去查找过程中每一步都要检测是否查找完毕,加快速度。
// 下标从1开始,头节点为空
public static int sentrySearch(int[] arr, int target){arr[0] = target;int index = arr.length-1;while(arr[index] != target){--index;}if(index == 0) return -1;return index;
}
- 空间复杂度:O(1)
- 时间复杂度:O(n)
- 平均查找长度:ASL =(n+1)/ 2
2. 折半查找
首先将给定值key与表中中间位置的元素比较,若相等则查找成功,返回该元素的存储位置;若不等则所需查找的元素只能在中间元素以外的前半部分或后半部分。
public static int Sort(int[] nums, int target){int low = 0;int high = nums.length;while(low < high){mid = (low + high) / 2;if(target == nums[mid]) return mid;if(target < nums[mid]) high = mid-1;if(target > nums[mid]) low = mid+1;}return -1
}
- 空间复杂度:O(1)
- 时间复杂度:O(log2log_2log2n)
- 平均查找长度:ASL = log2log_2log2(n+1)
3. 分块查找
分块查找又称索引顺序查找,它是顺序查找的一种改进方法:将n个数据元素“按块有序”划分为m块(m<=n)。每一块中的数据元素不必有序,但块与块之间必须“按块有序”,即第1快中的任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都小于第3块中的任一元素,……
查找分两部分:先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中;然后在已确定的快中用顺序法进行查找。
@AllArgsConstructor
class IndexItem {public int index; //值比较的索引public int start; //开始位置public int length;//块元素长度(非空)
}public int indexSearch(int key){int[] mainList = new int[]{22, 12, 13, 8, 9, 20, 33, 42, 44, 38, 24, 48,60, 58, 74, 49, 86, 53}IndexItem[] indexItemList = new IndexItem[]{new IndexItem(22,1,6),new IndexItem(48,7,6),new IndexItem(86,13,6);}// 第一步,查找在哪一块int index = 0;for(;index < indexItemList.length; index++){if(indexItemList[index].index >= key ) break;} int num = 0;for(int i=0; i<index; i++){num += indexlist[i].length;}for(int i=num; i<num+indexItemList.length; i++){if(MainList[i] == key) return i;}return -1;
}
- 时间复杂度:O(log(m)+n/m),n个数据分成m块
- 平均查找长度:ASL=ASL折半查找+ASL顺序查找=log2log_2log2(m+1) +(n/m+1)/2
4. 二叉排序树BST
private static class BinaryTreeNode {int data;BinaryTree lchild;BinaryTree rchild;}public class BinarySearchTree {public static BinaryTreeNode serachBinaryTree(BinaryTreeNode btn, int key) {if (btn == null) { // 树节点不存在,返回return new BinaryTreeNode();} else if (key == btn.data) { // 查找成功return btn;} else if (key < btn.data) { // 关键字小于根节点查找左子树return serachBinaryTree(btn.lchild, key);} else { // 关键字大于根节点查找右子树return serachBinaryTree(btn.rchild, key);}}
}
- 时间复杂度:O(logn)
- 空间复杂度:O(1)
- 平均查找长度ASL:查找成功的平均查找长度、查找失败的平均查找长度
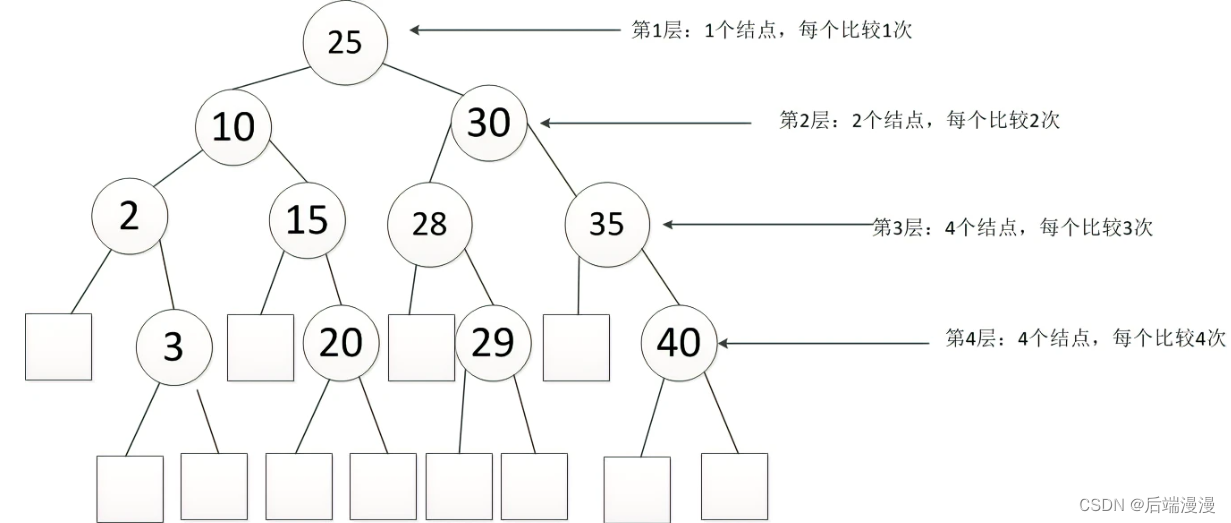
5. 哈希表查找
常用的哈希函数
- 直接地址法:H(key)=key或H(key)=a*key+b
- 除留余数法:H(key)= key mod p
- 数字分析法:可选取关键字的若干数位组成哈希地址,原则是使得到的哈希地址尽量避免冲突。
- 平方取中法:取关键字平方后的中间几位为哈希地址
常用的处理冲突方法- 开发地址法:有线性探查法和平方探查法
- 链式地址法:把所有的同义词用单链表链接起来的方法,种方哈希表中每个单元中存放的不再是记录本身,而是相应同义词单链表的头指针。
- 时间复杂度:O(1)
- 空间复杂度:O(n)
二、排序
注意:下标都是从1开始的
1. 不带哨兵的直接插入排序
public void InsertSort(int nums[]){int temp;for(int i=2; i<nums.length; i++){temp = nums[i];int j = i;while(nums[j]<nums[j-1] && j > 1){nums[j] = nums[j-1];}nums[j+1] = temp;}
}
- 时间复杂度:最差时间复杂度O(n2)、平均时间复杂度O(n2)
- 空间复杂度:O(1)
- 稳定性:稳定
2. 带哨兵的直接插入排序
public void InsertSort(int nums[]){for(int i=2; i<nums.length; i++){nums[0] = nums[i];int j = i;while(nums[j]<nums[j-1]){nums[j] = nums[j-1];}nums[j+1] = nums[0];}
}
- 时间复杂度:最差时间复杂度O(n2)、平均时间复杂度O(n2)
- 空间复杂度:O(1)
- 稳定性:稳定
3. 带哨兵、折半查找的直接插入排序
折半查找跟顺序查找的效率都是一样的,因为将元素向后退的次数是一样的。
public void InsertSort(int nums[]){int low,high,mid;for(int i=2;i<=n;i++){A[0]=A[i];low=1;high=i-1;while(low<=high){mid=(low+high)/2;if(A[mid]>A[0]) high=mid-1; //可用A[0],也可用A[i]else low=mid+1}for(int j=i-1;j>=high+1;--j) //注意这里只能用high,不能用low,midA[j+1]=A[j];A[high+1]=A[0];}
}
- 时间复杂度:最差时间复杂度O(n2)、平均时间复杂度O(n2)
- 空间复杂度:O(1)
- 稳定性:稳定
4. 希尔排序
先追求表中元素的部分有序,再逐渐逼近全局有序。
public void ShellSort(int arr[], int gap){while(gap>=1){for(int i=0; i<gap; i++){for(int j=i+gapl j<arr.length; j+=gap){int temp = arr[i];for(int k = j-gap; k>=i&&arr[k]>temp; k-=gap){arr[k+gap] = arr[k];}arr[k+gap] = temp;}}}
}
- 时间复杂度:O(n1.3~2)
- 空间复杂度:O(1)
- 稳定性:不稳定
5. 冒泡排序
public static void BubbleSort(int nums[]){for(int i = 1; i< nums.length; i++){boolean flag = true;for(int j = 0; j<nums.length-i; j++){if(arr[j] > arr[j+1]){int temp = arr[j];arr[j] = arr[j+1];arr[j+1] = temp;flag = false;}}if(flag) break;}
}
- 时间复杂度:最坏时间复杂度O(n2)、平均时间复杂度O(n2)
- 空间复杂度:O(1)
- 稳定性:稳定
6. 快速排序
public void quickSort(int[] nums, int left, int right){while(left >= right) return;int pivot = a[left];int i=left;int j=right;while(i < j){while(pivot <= a[j] && i<j) j--;while(pivot >= a[i] && i<j) i++;int temp = a[i];a[i] = a[j];a[j] = temp;}a[left] = a[i];a[i] = pivot;quickSort(a,left,i-1);//对左边的子数组进行快速排序quickSort(a,i+1,right);//对右边的子数组进行快速排序
}
- 时间复杂度:最差时间复杂度O(n2)、平均时间复杂度O(n2)
- 空间复杂度:O(log2n)~O(n)
- 稳定性:不稳定
7. 选择排序
public void SelectSort(int[] nums){for(int i=0; i<nums.length; i++){int temp = i;for(int j=i+1; j<nums.length; j++){if(nums[j] < nums[temp]) temp = j;}int swap = nums[i];nums[i] = nums[temp];nums[temp] = swap;}
}
- 时间复杂度:最差时间复杂度O(n2)、平均时间复杂度O(n2)
- 空间复杂度:O(1)
- 稳定性:稳定
8. 堆排序
堆排序分为两个过程:输出堆顶、调整新堆
void HeadAdjust(int A[],int k,int len){ //调整指定根节点A[k]A[0]=A[k];for(int i=k*2;i<=len;i*=2){if(i<len&&A[i]<A[i+1]) i++; //不管要不要交换,先选出最大的子结点if(A[0]>=A[i]) break; //不用交换,而且后面是一定调整好的了else{A[k]=A[i]k=i; //这里与A[K]=A[0]相呼应,其实也可以选择A[i]=A[0],每次都交换}}A[k]=A[0];
}void BuildMaxHeap(int A[],int len){ //从最后一个子树根节点开始调整,调整全部根节点for(int i=len/2;i>0;--i) HeadAdjust(A,i,len);
}void HeapSort(int A[],int len){BuildMaxHeap(A,len); //堆初始化for(i=len;i>1;i--){ Swap(A[i],A[1]); //将最大值放在最后,然后重新在指定位置调整HeapAdjuest(A,1,i-1) //截断最后一位,并且重新从第一位调整}
}
- 时间复杂度:最差时间复杂度O(nlog2n)、平均时间复杂度O(nlog2n)
- 空间复杂度:O(1)
- 稳定性:不稳定
9. 归并排序
把两个或多个已经有序的序列合并成一个
public static int[] sort(int[] a,int low,int high){int mid = (low+high)/2;if(low<high){sort(a,low,mid);sort(a,mid+1,high);//左右归并merge(a,low,mid,high);}return a;}public static void merge(int[] a, int low, int mid, int high) {int[] temp = new int[high-low+1];int i= low;int j = mid+1;int k=0;// 把较小的数先移到新数组中while(i<=mid && j<=high){if(a[i]<a[j]){temp[k++] = a[i++];}else{temp[k++] = a[j++];}}// 把左边剩余的数移入数组 while(i<=mid){temp[k++] = a[i++];}// 把右边边剩余的数移入数组while(j<=high){temp[k++] = a[j++];}// 把新数组中的数覆盖nums数组for(int x=0;x<temp.length;x++){a[x+low] = temp[x];}}
- 时间复杂度:最差时间复杂度O(nlog2n)、平均时间复杂度O(nlog2n)
- 空间复杂度:O(n)
- 稳定性:稳定
二叉树
1. 递归先序遍历
public static void preOrder(TreeNode root){if(root == null) return;System.out.println(root.value);if(root.left != null) PreOrder(root.left);if(root.right != null) PreOrder(root.right);
}
2. 非递归先序遍历
public static void preOrder(TreeNode root){Stack<TreeNode> stack = new Stack<TreeNode>();while(root != null || !stack.isEmpty()){while(root!=null){ // 1. 下去的时候System.out.println(root.value); // 访问stack.push(root); // 入栈root = root.left // 左孩子}if(!stack.isEmpty()){ // 2. 回来的时候root = stack.pop(); // 出栈root = root.right; // 右孩子}}
}
3. 递归中序遍历
public static void midOrder(TreeNode root){if(root == null) return;if(root.left != null) PreOrder(root.left);System.out.println(root.value);if(root.right != null) PreOrder(root.right);
}
4. 非递归中序遍历
public static void minOrder(TreeNode root){Stack<TreeNode> stack = new Stack<TreeNode>();while(root != null || !stack.isEmpty()){while(root!=null){ // 1. 下去的时候stack.push(root); // 入栈root = root.left // 左孩子}if(!stack.isEmpty()){ // 2. 回来的时候root = stack.pop(); // 出栈System.out.println(root.value); // 访问root = root.right; // 右孩子}}
}
5. 递归后序遍历
public static void postOrder(TreeNode root){if(root == null) return;if(root.left != null) PreOrder(root.left);if(root.right != null) PreOrder(root.right);System.out.println(root.value);
}
6. 非递归后序遍历
public void postorderTraversal(TreeNode root) {Deque<TreeNode> stack = new LinkedList<TreeNode>();TreeNode prev = null; // prev是指上一个遍历到的结点if (root == null) return res;while (root != null || !stack.isEmpty()) {while (root != null) {stack.push(root);root = root.left;}root = stack.pop();// 要是没有右孩子,或者右孩子已经看过了,就打印根结点if (root.right == null || root.right == prev) {System.out.println(root.value);prev = root; // 保留最近遍历过的一次结点root = null; //这里设为null,就是好好的把结点输出} // 右孩子不是空的,并且上次prev没有走过的,就push进栈。else{ stack.push(root);root = root.right;}}
}
7. 广度遍历二叉树
public static void bfs(TreeNode root){Queue<TreeNode> queue = new LinkedList<TreeNode>();if(root == null) return;queue.add(root);while(!queue.isEmpty()){TreeNode t = queue.remove();System.out.println(root.value); if(t.left != null) queue.add(t.left);if(t.right != null) queue.add(t.right);}
}
8. 深度遍历
public void dfs(TreeNode root){Stack<TreeNode> stack=new Stack<TreeNode>();if(root==null)return list;//压入根节点stack.push(root);//然后就循环取出和压入节点,直到栈为空,结束循环while (!stack.isEmpty()){TreeNode t=stack.pop();if(t.right!=null)stack.push(t.right);if(t.left!=null)stack.push(t.left);System.out.println(t.value);}
}
相关文章:

查找、排序、二叉树的算法,统统记录于此。
文章目录一、查找1. 无序表的顺序查找2. 折半查找3. 分块查找4. 二叉排序树BST5. 哈希表查找二、排序1. 不带哨兵的直接插入排序2. 带哨兵的直接插入排序3. 带哨兵、折半查找的直接插入排序4. 希尔排序5. 冒泡排序6. 快速排序7. 选择排序8. 堆排序9. 归并排序二叉树1. 递归先序…...

如何用Python实现在网页中嵌入YouTube的视频?
要在网页中嵌入YouTube视频,可以使用HTML代码,在Python中使用字符串拼接的方式生成HTML代码。下面是一个示例代码,可以生成嵌入YouTube视频的HTML代码: def embed_youtube_video(video_id, width560, height315): """ 生成嵌…...
Easy Deep Learning——PyTorch中的自动微分
目录 什么是深度学习?它的实现原理是怎么样的呢? 什么是梯度下降?梯度下降是怎么计算出最优解的? 什么是导数?求导对于深度学习来说有何意义? PyTorch 自动微分(自动求导) 为什么…...

【生物信息】利用ChatGPT解释GO分析中的关于Biological Processes的问题
利用ChatGPT解释GO分析中的一些问题 如何理解GO中的evidence:ISS,这是什么?qualifier:involved_in是什么意思?evidence:TAS是什么?evidence: IBA是什么?evidence: IMP是什么?evidence:IDA是什么?evidence: IEA是什么?GO分析中,evidence: NAS是什么意思?GO分析中…...

2018年MathorCup数学建模C题陆基导弹打击航母的数学建模与算法设计解题全过程文档及程序
2018年第八届MathorCup高校数学建模挑战赛 C题 陆基导弹打击航母的数学建模与算法设计 原题再现: 火箭军是保卫海疆主权的战略力量,导弹是国之利器。保家卫国,匹夫有责。为此,请参赛者认真阅读"陆基反舰导弹打击航母的建模示意图"。(附图 1 )参考图中的…...
打怪升级之CFile类
CFile类 信息源自官方文档:https://learn.microsoft.com/zh-cn/cpp/mfc/reference/cfile-class?viewmsvc-170。 CFile是Microsoft 基础类文件类的基类。它直接提供非缓冲的二进制磁盘输入/输出设备,并直接地通过派生类支持文本文件和内存文件。CFile与…...

[css]通过网站实例学习以最简单的方式构造三元素布局
文章目录二元素布局纵向布局横向布局三元素布局b站直播布局实例左右-下 布局左-上下 布局上下-右 布局方案一方案二后言二元素布局 在学习三元素布局之前,让我们先简单了解一下只有两个元素的布局吧 两个元素的相对关系非常简单,不是上下就是左右 纵向布…...
【冲刺蓝桥杯的最后30天】day6
大家好😃,我是想要慢慢变得优秀的向阳🌞同学👨💻,断更了整整一年,又开始恢复CSDN更新,从今天开始更新备战蓝桥30天系列,一共30天,如果对你有帮助或者正在备…...
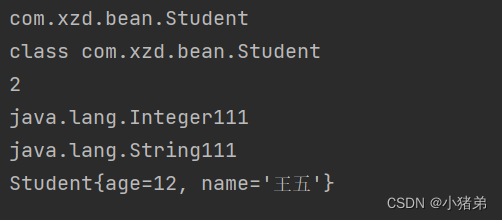
ssm框架之spring:浅聊IOC
IOC 前面体验了spring,不过其运用了IOC,至于IOC( Inverse Of Controll—控制反转 ) 看一下百度百科解释: 控制反转(Inversion of Control,缩写为IoC),是面向对象编程中的一种设计原则&#x…...
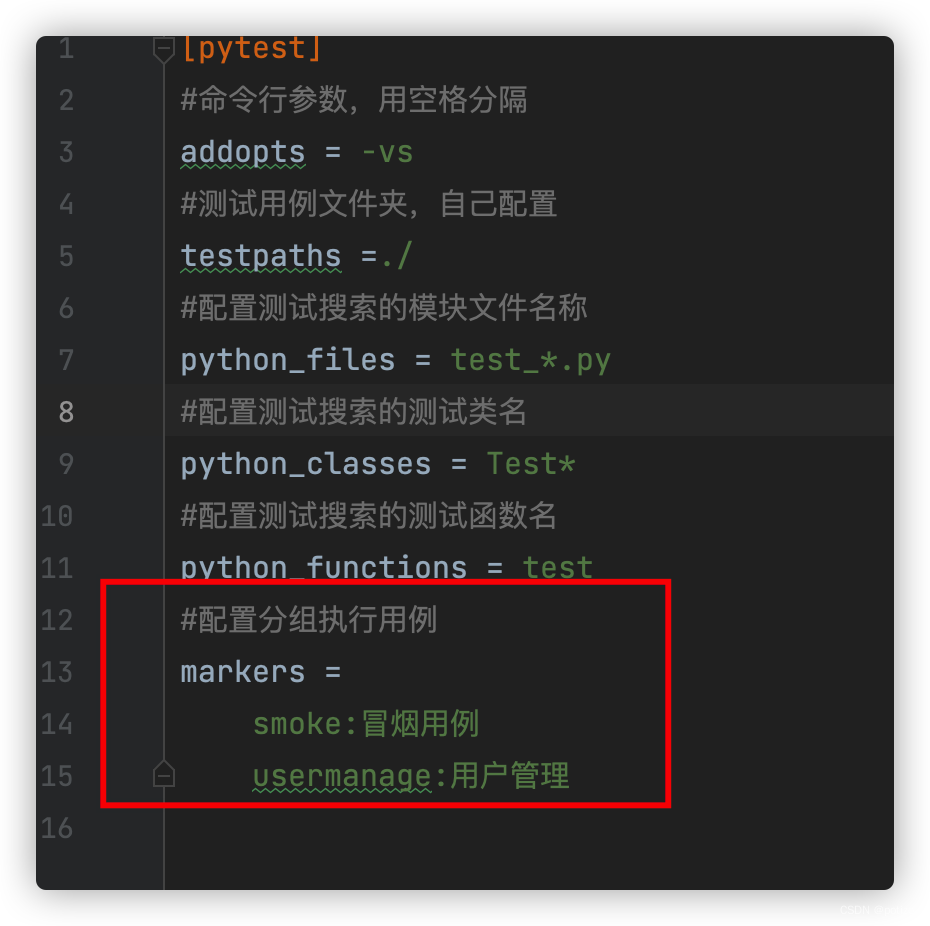
pytest初识
一、单元测试框架 (1)什么是单元测试框架? 单元测试是指在软件开发中,针对软件的最小单元(函数、方法)进行正确性的检查测试 (2)单元测试框架 java:junit和testng pytho…...
-12)
设计模式~责任链模式(Chain of Responsibility)-12
目录 (1)优点 (2)缺点 (3)使用场景 (4)注意事项: (5)应用实例: (6)经典案例 代码 责任链, …...

【ElasticSearch】(一)—— 初识ES
文章目录1. 了解ES1.1 elasticsearch的作用1.2 ELK技术栈1.3 elasticsearch和lucene1.4 为什么不是其他搜索技术?1.5 总结2. 倒排索引2.1 正向索引2.2 倒排索引2.3 正向和倒排3. ES的一些概念3.1 文档和字段3.2 索引和映射3.3 mysql与elasticsearch1. 了解ES Elasti…...
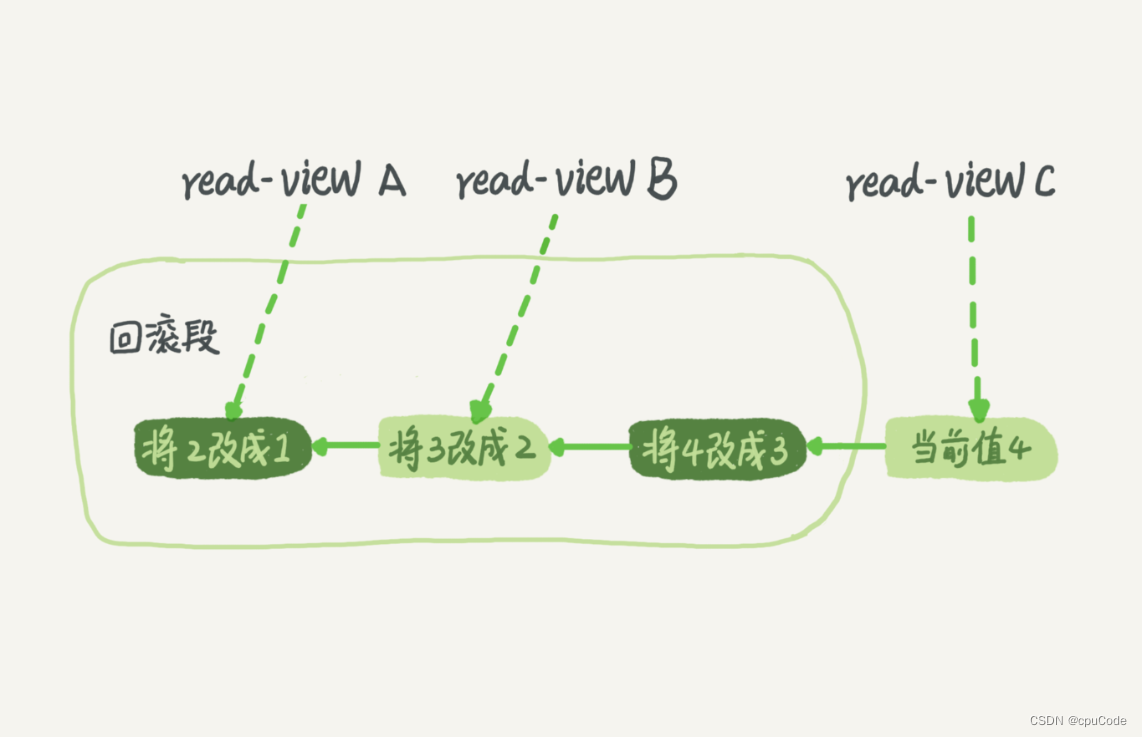
MySQL 事务隔离
MySQL 事务隔离事务隔离实现事务的启动ACID : 原子(Atomicity)、一致(Consistency)、隔离(Isolation)、永久(Durability) 多个事务可能出现问题 : 脏读 (dirty read) , 不可重复读 (non-repeatable read) , 幻读 (phantom read) 事务隔离级别 : 读未提交 (read uncommitted)…...

基础06-JS中for-in和for-of有什么区别
for…in 和 for…of 的区别 题目 for…in 和 for…of 的区别 key 和 value for…in 遍历 key , for…of 遍历 value const arr [10, 20, 30] for (let n of arr) {console.log(n) }const str abc for (let s of str) {console.log(s) }function fn() {for (let argument…...

AI视频智能分析EasyCVR视频融合平台录像计划模块搜索框细节优化
EasyCVR支持海量视频汇聚管理,可提供视频监控直播、云端录像、云存储、录像检索与回看、智能告警、平台级联、智能分析等视频服务。在录像功能上,平台可支持: 根据业务场景自定义录像计划,可支持7*24H不间断录像,支持…...
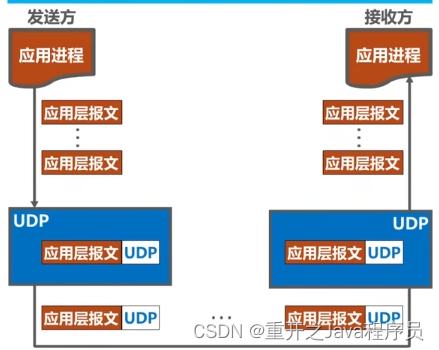
TCP和UDP对比
TCP和UDP对比 UDP(用户数据报协议) 无连接(指的是逻辑连接关系,不是物理上的连接) 支持单播、多播以及广播,也就是UDP支持一对一、一对多、一对全 面向应用报文的,对应用层交付的报文直接打包 无连接不可靠的传输服务(适用于IP电话、视频会议等实时应用),不使用流量控制和…...

CVS Health 西维斯健康EDI需求
CVS Health西维斯健康在特拉华州成立,通过旗下的 CVS Pharmacy 和 Longs Drugs 零售店以及 CVS.com 电商提供处方药、美容产品、化妆品、电影和照片加工服务、季节性商品、贺卡和方便食品。CVS Health通过使高质量的护理变得更经济、更易获得、更简单、更无缝&#…...
Anaconda配置Python科学计算库SciPy的方法
本文介绍在Anaconda环境中,安装Python语言SciPy模块的方法。 SciPy是基于Python的科学计算库,用于解决科学、工程和技术计算中的各种问题。它建立在NumPy库的基础之上,提供了大量高效、易于使用的功能,包括统计分析、信号处理、优…...
数据库基本功之复杂查询的子查询
子查询返回的值可以被外部查询使用,这样的复合查询等效与执行两个连续的查询. 1. 单行单列子查询 (>,<,,<>,>,<)内部SELECT子句只返回一行结果 2.多行单列子查询 (all, any, in,not in) all (>大于最大的,<小于最小的) SQL> select ename, sal from…...

脑机接口科普0019——大脑的分区及功能
本文禁止转载!!!! 在前文脑机接口科普0018——前额叶切除手术_sgmcy的博客-CSDN博客科普中,有个这样的一张图: 这个图呢,把大脑划分为不同的区域,然后不同的区域代表不同的功能。 …...

手把手教你修复conda的HTTP 404错误:从错误日志分析到快速解决
深度解析Conda的HTTP 404错误:从日志分析到高效修复 当你满怀期待地输入conda create -n myenv python3.9准备创建新环境时,终端却无情地抛出一堆红色错误信息,最扎眼的就是那个requests.exceptions.HTTPError: 404 Client Error。这种突如其…...
背后的三大工程难题)
从‘飞到红色建筑左边’说起:拆解无人机视觉语言导航(VLN)背后的三大工程难题
从"飞到红色建筑左边"说起:拆解无人机视觉语言导航的工程化困局 当你在测试场地对无人机说出"飞到红色建筑左边"时,这个看似简单的指令背后,是一场跨越模态鸿沟的复杂解码过程。不同于实验室里的完美演示,真实…...
)
Minikube国内环境配置全攻略:从安装到Dashboard镜像加速(含阿里云镜像源)
Minikube国内环境高效配置指南:从零搭建到Dashboard可视化 对于国内开发者而言,在本地环境中快速搭建Kubernetes学习平台往往面临镜像拉取缓慢甚至失败的困扰。本文将系统性地介绍如何利用Minikube在国内网络环境下构建稳定的单机Kubernetes环境…...

达梦数据库-归档日志文件-记录总结
达梦数据库-归档日志文件-记录总结DM数据库可以运行在归档模式或非归档模式下。如果是归档模式,联机日志文件中的内容保存到硬盘中,形成归档日志文件;如果是非归档模式,则不会形成归档日志。归档日志文件以归档时间命名࿰…...

BoltDB vs Redis 读性能对比:实测表现与原理差异
一、前言 BoltDB(bbolt)与 Redis 都是高并发场景下常见的键值存储,但存储架构、存储介质、并发模型完全不同,导致两者在读性能、延迟、并发扩展性上呈现巨大差异。 本文从原理、延迟、并发读能力、资源开销四个维度对比两者的读性…...

如何在编程中免费使用LxgwWenKai字体:终极指南
如何在编程中免费使用LxgwWenKai字体:终极指南 【免费下载链接】LxgwWenKai LxgwWenKai: 这是一个开源的中文字体项目,提供了多种版本的字体文件,适用于不同的使用场景,包括屏幕阅读、轻便版、GB规范字形和TC旧字形版。 项目地址…...
)
为什么你的Python 3.14 JIT始终未触发?揭开__pycache__/jit_profile.bin隐藏机制与企业级profile引导策略(仅3家头部云厂商公开的冷启动预热方案)
第一章:Python 3.14 JIT 编译器的演进逻辑与企业级定位Python 3.14 引入的原生 JIT(Just-In-Time)编译器并非对 CPython 的简单性能补丁,而是基于多年运行时分析与生产环境反馈重构的执行引擎。其核心演进逻辑聚焦于“渐进式优化”…...

突破安卓视频解析壁垒:LAMDA框架实现流媒体捕获与自动化提取全指南
突破安卓视频解析壁垒:LAMDA框架实现流媒体捕获与自动化提取全指南 【免费下载链接】lamda ⚡️ Android reverse engineering & automation framework | 史上最强安卓抓包/逆向/HOOK & 云手机/远程桌面/自动化辅助框架,你的工作从未如此简单快捷…...

Yuzu模拟器版本高效管理实战指南:从新手到专家的避坑技巧
Yuzu模拟器版本高效管理实战指南:从新手到专家的避坑技巧 【免费下载链接】yuzu-downloads 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu-downloads 你是否曾遇到这样的困境:刚更新的Yuzu模拟器让原本流畅的游戏变得卡顿,…...

LVDS信号完整性救星:Xilinx OSERDESE2+IDELAY2配置避坑指南
LVDS信号完整性救星:Xilinx OSERDESE2IDELAY2配置避坑指南 当你在Gbps级LVDS接口设计中遇到信号抖动问题时,是否曾盯着眼图上的毛刺束手无策?作为Xilinx FPGA开发者,我们常陷入这样的困境:明明按照手册配置了OSERDESE2…...