「代码厨房大揭秘:Python性能优化的烹饪秘籍!」
哈喽,我是阿佑,上篇咱们讲了 Socket 编程 —— 探索Python Socket编程,赋予你的网络应用隐形斗篷般的超能力!从基础到实战,构建安全的聊天室和HTTP服务器,成为网络世界的守护者。加入我们,一起揭开Socket编程的神秘面纱,让学习变得不再枯燥!
文章目录
- 1. 引言
- 为什么性能优化至关重要
- Python性能瓶颈的常见来源
- 2. 背景介绍
- 2.1 Python解释器与执行模型
- 2.2 性能测试基础
- 3. 代码层面的性能优化
- 3.1 数据结构与算法选择
- 3.2 减少全局变量与动态属性查找
- 3.3 避免不必要的计算与重复操作
- 4. 库与模块优化
- 4.1 使用高效库替换低效代码
- 4.2 并发与并行处理
- 5. 内存管理与垃圾回收
- 5.1 了解Python内存模型
- 5.2 手动管理与垃圾回收调整
- 6. 外部依赖与C扩展
- 6.1 使用Cython编写关键部分
- 6.2 利用C/C++扩展加速
- 7. 性能分析与调试工具
- 7.1 cProfile与profiling基础
- 7.2 使用vmprof与gprof进行更深入分析
- 8. 结论
- 综合策略在实际项目中的应用
- 持续性能优化的思考
- 9. 参考文献
1. 引言
为什么性能优化至关重要
想象一下,你是一个程序员,手里拿着一把锋利的Python之剑,准备在代码的海洋中航行。但是,如果你的剑不够快,不够锋利,那么在面对复杂的算法和庞大的数据时,你可能就会陷入困境。这就是性能优化的重要性所在——它能让你的剑更加锋利,让你在代码的海洋中乘风破浪。
Python性能瓶颈的常见来源
在Python的世界里,性能瓶颈就像是那些隐藏在暗处的小怪兽,它们悄悄地消耗着你的计算资源,让你的程序变得缓慢。常见的性能瓶颈来源包括:
- 全局解释器锁(GIL):这是Python中的一个守护神,它保护着Python的线程安全,但也限制了多线程程序的性能。
- 不合适的数据结构:如果你选择了错误的数据结构,就像选择了一个不适合的剑来战斗,效率自然低下。
- 低效的算法:算法就像是你的战斗技巧,如果技巧不佳,即使剑再锋利,也无法发挥出应有的力量。
- 内存管理不善:如果你的内存管理不善,就像是在战斗中不断丢失你的剑,这会严重影响你的战斗效率。
在接下来的旅程中,阿佑将和大家们一起探索如何优化Python的性能,就像是一个剑术大师,教你如何磨炼你的剑,让它在代码的海洋中更加闪耀。现在,让我们开始这段旅程,一步步揭开性能优化的神秘面纱。

2. 背景介绍
2.1 Python解释器与执行模型
在Python的世界里,我们有各种各样的解释器,它们就像是不同的魔法师,帮助我们执行代码。其中最著名的就是CPython,它是Python的官方和最常用的实现。CPython的工作原理就像是魔法师的咒语,它将你的Python代码转换成机器能够理解的语言。
但是,CPython有一个著名的“魔法限制”——全局解释器锁(GIL)。GIL就像是魔法师的法杖,它确保了在任何时刻只有一个线程能够执行Python字节码。这听起来很安全,但这也意味着即使你有一把强大的多核处理器之剑,你的程序也可能因为GIL而无法发挥出全部的力量。
2.2 性能测试基础
在性能优化的旅程中,你需要一个指南针来指引你——这就是性能测试。性能测试就像是你手中的地图,帮助你找到代码中的低效区域。基准测试是一种常见的性能测试方法,它通过测量程序在执行特定任务时的性能来评估其效率。
性能衡量工具就像是你的罗盘和望远镜,帮助你更准确地导航和观察。这些工具可以是简单的计时器,也可以是复杂的分析器,它们能够提供关于程序执行时间、内存使用情况等的详细信息。
现在,我们已经了解了Python的执行模型和性能测试的基础。接下来,我们将深入到代码层面,探索如何通过优化数据结构和算法来提升性能。就像是一个剑术大师,不仅要有一把锋利的剑,还要有精准的剑法。让我们一起继续这段旅程,揭开性能优化的更多秘密。
3. 代码层面的性能优化
3.1 数据结构与算法选择
想象一下,你是一个厨师,面前有一堆食材,你需要做出一顿美味的晚餐。如果你选择了正确的食材和烹饪方法,那么晚餐就会更加美味且制作效率更高。在Python编程中,选择正确的数据结构和算法也是同样的道理。
有效利用内置数据结构
Python为我们提供了丰富的内置数据结构,比如列表(list)、字典(dict)、集合(set)等。它们就像是厨房里的各种工具和食材,用得好,可以让你的代码更加高效。
比如,如果你需要频繁地检查一个元素是否存在,使用集合(set)而不是列表(list)会更快,因为集合是基于哈希表实现的,它的查找效率是O(1),而列表的查找效率是O(n)。
算法效率提升策略
算法就像是你的烹饪技巧,好的算法可以让程序运行得更快。一个简单的例子是排序算法,如果你的数据量不大,使用Python内置的sorted()函数就已经足够高效了。但如果数据量很大,你可能需要考虑使用更高效的算法,比如快速排序或归并排序。
3.2 减少全局变量与动态属性查找
全局变量和动态属性查找就像是你在做一道菜时,不停地在厨房里跑来跑去找调料。这不仅会降低你的烹饪效率,还可能让你的厨房变得一团糟。
作用域对性能的影响
局部变量的访问速度比全局变量快得多,因为局部变量存储在栈上,而全局变量存储在堆上。所以,尽量减少全局变量的使用,多使用局部变量。
使用局部变量与缓存查找结果
缓存查找结果就像是你把常用的调料放在手边,这样你就可以快速地拿到它们,而不需要每次都去柜子里翻找。在Python中,你可以使用functools.lru_cache装饰器来实现缓存功能,它可以自动存储函数的最近调用结果,避免重复计算。
3.3 避免不必要的计算与重复操作
想象一下,你在做一道菜时,不停地重复切洋葱,这不仅浪费时间和精力,还可能让你泪流满面。在编程中,避免不必要的计算和重复操作也是非常重要的。
延迟计算与缓存技术
延迟计算就像是你不需要立刻切洋葱,而是等到真正需要的时候再切。在Python中,你可以使用生成器(generator)来实现延迟计算,只在需要的时候才生成数据。
循环优化与列表推导式
循环优化就像是你在做一道菜时,尽量减少不必要的步骤。列表推导式(list comprehension)是一种优雅且高效的方式来创建列表,它通常比传统的循环更简洁、更快。
举个例子,使用列表推导式来创建一个包含平方数的列表:
squares = [x**2 for x in range(10)]
这比使用传统的for循环来创建同样的列表要简洁得多。
通过这些技巧,你可以让你的代码更加高效,就像是一个熟练的厨师,用最少的时间和精力做出最美味的晚餐。接下来,我们将探索如何通过使用高效的库和模块来进一步提升Python程序的性能。
4. 库与模块优化
4.1 使用高效库替换低效代码
在Python的世界里,我们有各种强大的库和模块,它们就像是你厨房里的各种高级料理机,能够帮你快速完成复杂的任务。
推荐的高性能库介绍
比如说,如果你需要处理大量的数据,numpy和pandas就是你的得力助手。numpy是一个用于科学计算的库,它提供了高度优化的多维数组对象和相应的操作。而pandas则是一个数据分析库,它提供了DataFrame对象,让你可以像操作Excel表格一样轻松处理数据。
举个例子,如果你需要对一组数据求和,使用numpy可以这样写:
import numpy as npdata = np.array([1, 2, 3, 4, 5])
total = np.sum(data)
print("总和是:", total)
这比使用Python原生的列表和循环要快得多。
numpy与pandas的高效数据处理
numpy和pandas之所以高效,是因为它们底层是用C语言编写的,这意味着它们的执行速度可以和C语言相媲美。使用这些库,你可以轻松处理大规模的数据集,而不必担心性能问题。
4.2 并发与并行处理
并发和并行处理就像是你在厨房里同时使用多个炉灶和烤箱,可以同时烹饪多道菜,大大提升效率。
threading与multiprocessing模块的正确使用
在Python中,threading模块可以让你创建线程,实现任务的并发执行。但是,由于GIL的存在,多线程在CPU密集型任务中可能不会带来太大的性能提升。这时,multiprocessing模块就显得尤为重要,它通过创建多个进程来绕过GIL的限制,实现真正的并行计算。
举个例子,如果你需要对一个大数组进行处理,使用multiprocessing可以这样写:
from multiprocessing import Pooldef process_data(data):# 这里是处理数据的函数return sum(data)if __name__ == "__main__":with Pool(4) as p: # 创建一个进程池,4个进程result = p.map(process_data, [list(range(10000)) for _ in range(10)])print("处理结果:", sum(result))
这段代码创建了一个进程池,并使用map方法并行处理数据。
asyncio与异步I/O编程
如果你的任务主要是I/O密集型的,比如网络请求或文件操作,那么asyncio模块将是你的好帮手。它可以让你的程序在等待I/O操作完成时,继续执行其他任务,从而提升效率。
举个例子,使用asyncio进行网络请求可以这样写:
import asyncio
import aiohttpasync def fetch_url(url):async with aiohttp.ClientSession() as session:async with session.get(url) as response:return await response.text()async def main():urls = ['http://example.com', 'http://example.org']tasks = [fetch_url(url) for url in urls]print(await asyncio.gather(*tasks))asyncio.run(main())
这段代码使用asyncio和aiohttp库并发地获取多个网页的内容。
通过合理使用这些库和模块,你的Python程序可以像一个高效的厨房,快速且优雅地完成任务。接下来,我们将探索如何通过内存管理和垃圾回收来进一步提升程序的性能。

5. 内存管理与垃圾回收
5.1 了解Python内存模型
想象一下,你的电脑内存就像是一个大型超市,里面存放着各种各样的商品——也就是你的数据和对象。Python内存模型就像是超市的管理系统,它负责管理这些商品的存取和回收。
对象生命周期与引用计数
每个商品都有一个标签,上面写着它被多少人需要。在Python中,这就像是对象的引用计数。每当一个对象被引用,计数器就加一;每当引用被删除,计数器就减一。当计数器降到零时,就意味着没有人再需要这个对象,它就可以被回收了。
引用计数虽然简单有效,但也存在一些问题。比如,当两个对象相互引用时,即使它们不再被外界需要,它们的引用计数也不会降到零,这就是所谓的循环引用问题。
优化内存占用与避免内存泄漏
内存泄漏就像是超市里那些过期的商品,它们占用空间,但又不能被卖出去。在Python中,内存泄漏通常是由于不正确的资源管理造成的。为了避免内存泄漏,你需要确保不再需要的对象能够被及时回收。
5.2 手动管理与垃圾回收调整
使用del与弱引用
就像超市定期清理过期商品一样,你也可以使用del语句来手动删除不再需要的对象,释放它们占用的内存。此外,Python还提供了弱引用(weakref)模块,它允许你创建对对象的引用,但不会增加对象的引用计数。当对象被回收时,弱引用会自动失效。
举个例子,使用弱引用可以这样写:
import weakrefclass MyClass:passobj = MyClass()
weak_obj = weakref.ref(obj)del obj # 删除对象,引用计数降到0
print(weak_obj()) # 返回None,因为对象已经被回收
调整GC策略提升性能
Python的垃圾收集器(GC)就像是超市的清洁工,它会定期清理那些过期的商品。但是,如果你的超市(程序)非常大,那么清洁工的工作就会变得非常重要。Python的GC默认是开启的,但你可以通过调整GC的策略来优化性能。
比如,你可以设置垃圾收集器的阈值,控制它何时运行:
import gcgc.set_threshold(700, 10, 5) # 设置三个阈值参数
这就像是告诉清洁工,当过期商品达到700件时,就开始清理,每次清理10件,直到剩余5件为止。
通过合理管理内存和调整垃圾收集策略,你的Python程序可以运行得更加顺畅,就像是一个高效运转的超市,既不会浪费空间,也不会让顾客(用户)等待太久。接下来,我们将探索如何通过外部依赖和C扩展来进一步提升程序的性能。
6. 外部依赖与C扩展
6.1 使用Cython编写关键部分
在Python的世界里,我们经常会遇到一些性能瓶颈,就像是一个跑步运动员遇到了一块难以跨越的障碍。这时,Cython就像是一把神奇的钥匙,它能够帮你打开性能提升的大门。
Cython简介与性能提升案例
Cython是一种将Python代码编译成C语言代码的工具,从而让你的Python程序能够像C语言程序一样快速运行。使用Cython,你可以编写那些性能关键部分的代码,比如数值计算密集型的任务。
举个例子,假设你需要对一个大数组进行一些数值计算,使用Cython可以这样写:
# cython: language_level=3cpdef double sum_array(double[:] arr):cdef int i, n = arr.shape[0]cdef double s = 0for i in range(n):s += arr[i]return s
这段代码定义了一个Cython函数sum_array,它接受一个NumPy数组作为参数,并计算数组的总和。通过使用cpdef,这个函数既可以被Python调用,也可以被Cython调用。
6.2 利用C/C++扩展加速
如果你觉得Cython还不够快,或者你需要使用一些现有的C/C++库,那么编写Python的C/C++扩展可能是一个更好的选择。
Python FFI接口与ctypes使用
ctypes是Python的一个外部函数接口,它允许你调用C语言写的动态链接库。使用ctypes,你可以轻松地将C/C++代码集成到Python程序中。
举个例子,假设你有一个C语言写的动态链接库libexample.so,里面有一个函数add,你可以这样使用它:
from ctypes import cdlllib = cdll.LoadLibrary("./libexample.so")
result = lib.add(1, 2) # 调用C语言的add函数
print("结果是:", result)
编写C扩展模块
如果你需要更深入地集成C/C++代码,或者想要创建一个可以被其他Python程序重复使用的模块,那么编写C扩展可能是最佳选择。
编写C扩展涉及到一些C语言的编程知识,以及对Python/C API的理解。下面是一个简单的C扩展模块的例子:
// example_module.c#include <Python.h>static PyObject* add(PyObject* self, PyObject* args) {int a, b;if (!PyArg_ParseTuple(args, "ii", &a, &b)) {return NULL;}return Py_BuildValue("i", a + b);
}static PyMethodDef ExampleMethods[] = {{"add", add, METH_VARARGS, "Add two integers."},{NULL, NULL, 0, NULL}
};static struct PyModuleDef examplemodule = {PyModuleDef_HEAD_INIT,"example_module",NULL,-1,ExampleMethods
};PyMODINIT_FUNC PyInit_example_module(void) {return PyModule_Create(&examplemodule);
}
这段代码定义了一个简单的C扩展模块example_module,它提供了一个add函数,用于计算两个整数的和。
通过使用Cython、ctypes或编写C扩展,你可以显著提升Python程序的性能,就像是一个运动员穿上了一双超级跑鞋,让他能够更快地跨越障碍,达到终点。接下来,我们将探索如何使用性能分析与调试工具来进一步优化你的程序。
7. 性能分析与调试工具
7.1 cProfile与profiling基础
想象一下,你是一位侦探,正在寻找程序中的“性能犯罪现场”。在这种情况下,cProfile就是你的放大镜和笔记本,帮你记录和分析程序的一举一动。
性能剖析过程与报告解读
使用cProfile,你可以对Python程序进行性能剖析,它会告诉你哪些函数调用最频繁,哪些函数执行时间最长。这就像是侦探在现场收集证据,然后分析线索,找出“犯罪动机”。
举个例子,如果你想剖析一个简单的Python程序,可以这样做:
import cProfiledef some_function():# 这里是一些耗时的操作passdef another_function():for _ in range(1000000):some_function()cProfile.run('another_function()')
运行这段代码后,cProfile会生成一个性能报告,详细列出每个函数的调用次数、总执行时间等信息。
7.2 使用vmprof与gprof进行更深入分析
如果你觉得cProfile还不够深入,或者你需要更详细的内存使用情况,那么vmprof和gprof可能是你需要的工具。
多维度性能监控与优化建议
vmprof是一个Python性能分析工具,它提供了一个可视化的界面,帮助你监控内存使用情况和CPU使用情况。使用vmprof,你可以像看实时监控摄像头一样,观察程序的运行状态。
举个例子,使用vmprof可以这样:
# 在命令行中运行
vmprof --callgrind your_script.py
运行后,vmprof会生成一个火焰图(Flame Graph),它以一种非常直观的方式展示了程序的性能瓶颈。
gprof是一个更底层的性能分析工具,通常用于C/C++程序,但也可以通过C扩展用于Python程序。gprof可以提供非常详细的性能数据,包括函数调用的频率、时间等。
举个例子,如果你有一个C扩展模块,并且你想使用gprof进行性能分析,可以这样做:
// 在C扩展模块中添加
void init_your_module() {// 初始化代码// ...if (PyErr_Occurred()) {Py_FatalError("初期化失败");}
}
编译并运行你的程序后,使用gprof命令行工具来生成性能报告。
通过使用这些性能分析与调试工具,你可以像侦探一样,揭开程序性能问题的神秘面纱,找到优化的方向。这样,你的程序就可以像一辆经过精心调校的跑车,以最高效率在路上飞驰。接下来,我们将总结这些策略,并思考如何在实际项目中持续优化性能。
8. 结论
综合策略在实际项目中的应用
想象一下,你是一个武林高手,手握着我们之前提到的各种性能优化秘籍——从精妙的数据结构选择到高效的算法,从并发编程到内存管理,再到C扩展的神兵利器。现在,是时候将这些秘籍应用到江湖(实际项目)中去了。
案例分享
假设你正在开发一个数据分析平台,需要处理大量的数据。你首先使用numpy和pandas来高效地处理数据,然后通过cProfile找到了性能瓶颈——一个在循环中反复执行的数据处理函数。你决定使用Cython重写这个函数,让它运行得更快。
# 使用Cython重写的函数
cpdef compute_heavy_task(data):# 这里是一些复杂的计算cdef int ifor i in range(len(data)):# 执行一些计算return result
通过这种方式,你不仅提升了性能,还保持了代码的可读性和可维护性。
持续性能优化的思考
性能优化不是一蹴而就的,它更像是一场马拉松,需要持续的努力和思考。在这个过程中,你需要不断地回顾和评估你的策略:
- 性能测试:定期对你的程序进行性能测试,确保新的更改没有引入性能问题。
- 代码审查:通过代码审查来发现潜在的性能问题,并分享性能优化的最佳实践。
- 技术跟进:随着Python和相关库的不断更新,新的性能优化特性和工具也会不断出现,保持学习是非常重要的。
最后,记住性能优化的终极目标是提升用户体验。就像一位大厨,不仅要追求菜品的色香味俱全,更要让食客吃得开心、吃得满意。
通过这些策略,你的程序将不仅仅是运行得快,而是能够以优雅、高效的方式解决实际问题,就像一位武林高手,不仅武艺高强,更懂得如何在江湖中立足。

阿佑给大家回顾下今天的知识点:
在当今这个信息爆炸、速度至上的时代,Python作为一门优雅而强大的编程语言,已经成为众多开发者的得力助手。然而,你是否曾在编写Python程序时,因为其运行速度而感到焦虑?别担心,本文将带你进入一个全新的性能优化世界,让你的Python程序从龟速飞跃至光速!
首先,我们深入探讨Python的性能瓶颈,从全局解释器锁(GIL)的束缚到内存管理的技巧,每一个环节都是提升性能的关键。我们像侦探一样,使用cProfile等工具,追踪程序的每一个细微动作,找出那些隐藏的性能杀手。
接下来,我们探索如何通过代码层面的优化,让Python程序焕发新生。从数据结构的选择到算法的优化,再到并发与并行处理的技巧,每一步都是提升效率的秘诀。想象一下,通过使用numpy和pandas这样的高性能库,你的数据处理速度将得到质的飞跃!
而当Python自身的能力已经无法满足你的需求时,Cython和C/C++扩展将是你突破性能极限的终极武器。通过将关键代码转化为C语言,你将能够释放Python的潜力,让程序运行速度得到前所未有的提升。
最后,我们学习了如何使用vmprof和gprof等高级工具,进行更深入的性能分析和调试。这不仅仅是对代码的优化,更是对编程思维的一次革命。通过这些工具,你将能够洞察程序的每一个角落,将性能优化做到极致。
在这场性能优化的旅程中,我们将不再是一个普通的程序员,而是一个精通性能优化的大师。我们的程序将不再是简单的代码堆砌,而是一个个精心打磨的艺术品。让我们一起打破Python的性能瓶颈,创造出令人震撼的高效程序,让代码的运行速度快到让人难以置信!
我是阿佑,一个专注于把晦涩的技术讲得有趣的中二青年,欢迎评论区留言~
9. 参考文献
-
Python官方文档: Performance Tips
- 官方文档总是我们最好的起点,Python的官方文档中包含了许多关于性能优化的宝贵建议和技巧。
-
《High Performance Python》书籍推荐
- 这本书由作者Michele Simionato撰写,深入探讨了Python性能优化的各个方面,是每一位希望提升Python程序性能的开发者的必读书籍。
-
Cython官方文档
- 如果你考虑使用Cython来提升性能,那么官方文档将是你的好帮手,它详细介绍了如何使用Cython以及相关的高级特性。
-
NumPy官方文档
- 对于任何需要进行数值计算的Python开发者来说,NumPy都是一个不可或缺的库,其官方文档提供了大量的使用示例和性能优化建议。
-
Pandas官方文档
- Pandas是数据分析的瑞士军刀,其官方文档详尽地介绍了如何高效地使用Pandas进行数据处理。
-
Asyncio官方文档
- 对于需要处理并发和异步I/O的开发者,Asyncio的官方文档提供了全面的指南和最佳实践。
-
ctypes和C扩展编程
- Python的扩展编程文档详细介绍了如何使用ctypes和编写C扩展来增强Python程序的性能。
-
性能分析工具文档
- 包括
cProfile、vmprof和gprof在内的性能分析工具都有自己的文档,这些文档是理解和使用这些工具的关键。
- 包括
-
在线教程和案例研究
- 网络上有大量的在线教程和案例研究,它们提供了实际的性能优化案例,是学习和启发的好资源。
-
Stack Overflow和社区论坛
- Stack Overflow和其他社区论坛是解决具体性能问题的宝库,你可以在这里找到许多经验丰富的开发者分享的解决方案和经验。
相关文章:
「代码厨房大揭秘:Python性能优化的烹饪秘籍!」
哈喽,我是阿佑,上篇咱们讲了 Socket 编程 —— 探索Python Socket编程,赋予你的网络应用隐形斗篷般的超能力!从基础到实战,构建安全的聊天室和HTTP服务器,成为网络世界的守护者。加入我们,一起揭…...

【重学C语言】十六、联合、枚举、面向对象编程
【重学C语言】十六、联合、枚举、面向对象编程 联合定义联合体使用联合体注意事项枚举枚举的定义为枚举常量指定整数值枚举的使用枚举的打印枚举的优势注意事项面向对象编程1. 结构体(Structs)2. 封装(Encapsulation)3. 继承(Inheritance)...

Github2024-05-21 Python开源项目日报 Top10
根据Github Trendings的统计,今日(2024-05-21统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Python项目10C项目1TypeScript项目1youtube-dl - 从YouTube和其他网站下载视频的命令行程序 创建周期:4951 天开发语言:Python协议类型:The …...
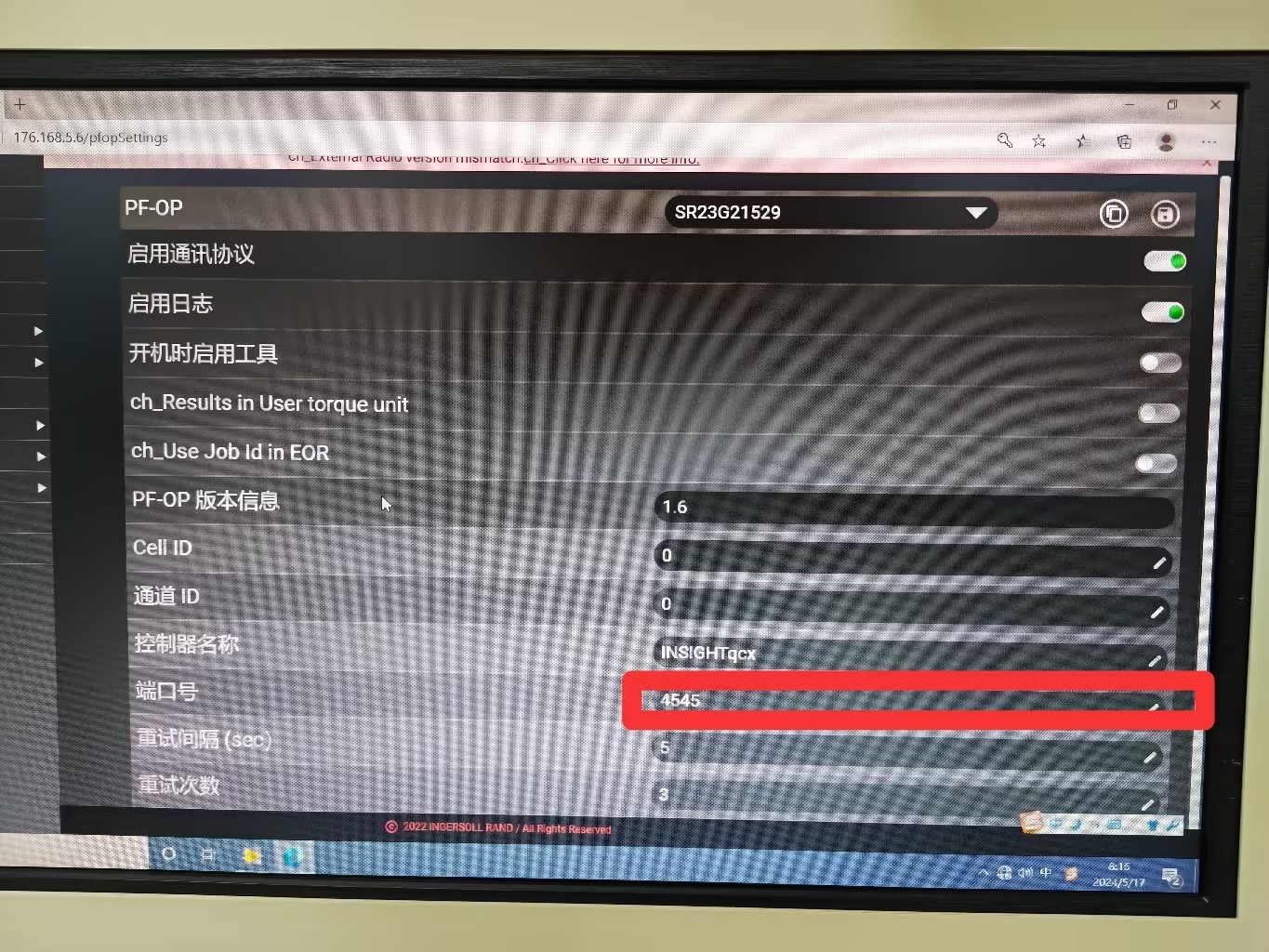
labview_开放协议
一、开放协议 二、硬件设置 英格索兰硬件设置: 三、配套测试软件 四、Labview代码...

AWS安全性身份和合规性之Amazon Macie
Amazon Macie是一项数据安全和数据隐私服务,它利用机器学习(ML)和模式匹配来发现和保护敏感数据。可帮助客户发现、分类和保护其敏感数据,以及监控其数据存储库的安全性。 应用场景: 敏感数据发现 一家金融服务公司…...

redis数据类型set,zset
华子目录 Set结构图相关命令sdiff key1 [key2]sdiffstore destination key1 [key2...]sinter key1 [key2...]sinterstore destination key1 [key2...]sunion key1 [key2...]sunionstore destination key1 [key2...]smove source destination memberspop key [count]sscan key c…...
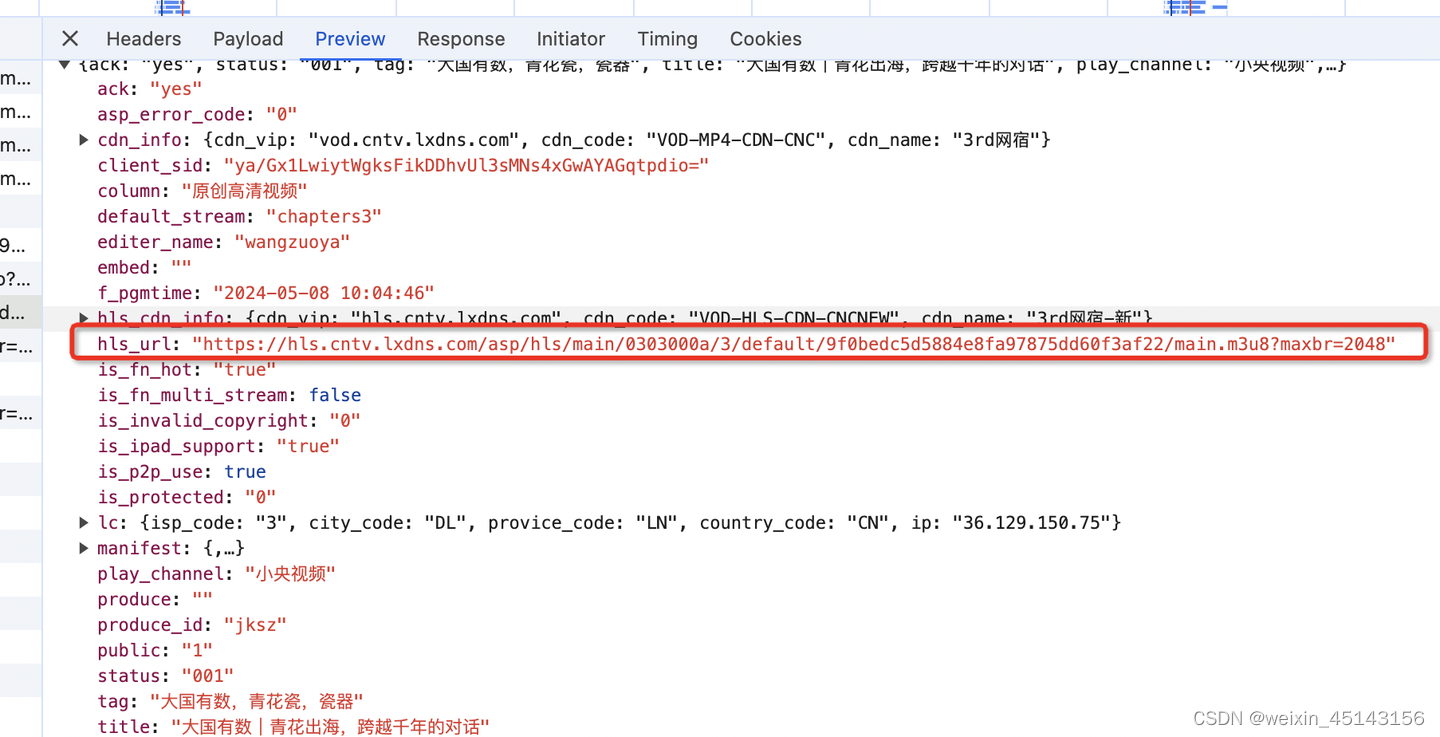
央视网视频下载和花屏问题处理
央视网(www.cctv.com)视频下载往往是花屏的,如何处理呢? 如果您是IT技术开发者,那么您可以通过下面步骤自己实现。 用chrome浏览器,F2打开开发者工具,找到当前页面的network 然后找一个接口:https://vdn.a…...
)
四、通信和网络安全—局域网|广域网|远程连接和攻击技术(CISSP)
目录 1.局域网和广域网 1.1 WAN技术总结 2.远程连接—无线技术 2.1 VPN 2.2 隧道协议总结...

15、设计模式之责任链模式
责任链模式 顾名思义,责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。 在这种模式中,通…...

神奇动物在哪里,但导演是微软
大数据产业创新服务媒体 ——聚焦数据 改变商业 一说到计算机视觉,大多数人第一时间联想到的便是“人脸识别”、“自动驾驶“、道路检测”等跟我们日常生活息息相关的关键词。而在2024年的5月末,微软在GitHub上面上传了这样一个计算机视觉的项目&#x…...

Flutter 中的 Flow 小部件:全面指南
Flutter 中的 Flow 小部件:全面指南 Flutter 的 Flow 是一个功能强大的布局小部件,它允许开发者在父组件的任意位置放置子组件。Flow 可以通过使用 FlowDelegate 完全自定义子组件的布局,这为创建复杂的自定义布局提供了极大的灵活性。本文将…...

【pyspark速成专家】11_Spark性能调优方法2
目录 编辑 二,Spark任务UI监控 三,Spark调优案例 二,Spark任务UI监控 Spark任务启动后,可以在浏览器中输入 http://localhost:4040/ 进入到spark web UI 监控界面。 该界面中可以从多个维度以直观的方式非常细粒度地查看Spa…...

吊顶的做法防踩坑,吊顶怎么省钱还好看
怎么做个好看的吊顶?你天天抬头看不? 现在楼房到手本身层高两米75左右,等铺完地暖和瓷砖还得增加几公分 如果再整个吊顶,就属于花钱买压抑了,吊顶就是遮丑, 某些比较显层高还亮堂,今天把做法分享出来 开发商给的毛坯两米8 做完地暖铺完瓷砖,层高是两米七八, 让木工在走廊两边…...
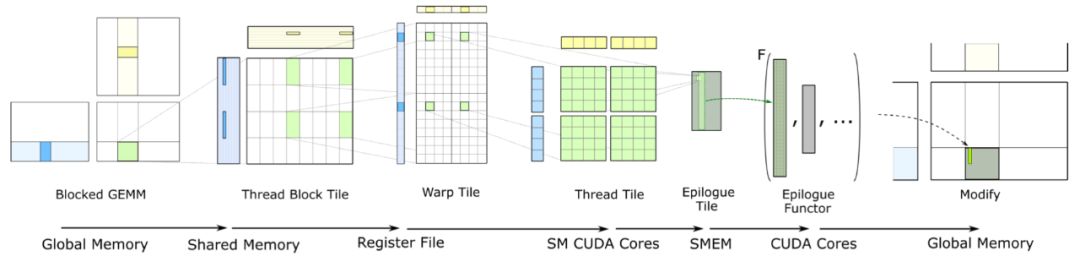
揭秘Tensor Core黑科技:如何让AI计算速度飞跃
揭秘 Tensor Core 底层:如何让AI计算速度飞跃 Tensor Core,加速深度学习计算的利器,专用于高效执行深度神经网络中的矩阵乘法和卷积运算,提升计算效率。 Tensor Core凭借混合精度计算与张量核心操作,大幅加速深度学习…...
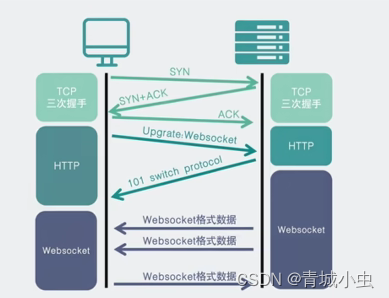
为什么会有websocket(由来)
一、HTTP 协议的缺点和解决方案 1、HTTP 协议的缺点和解决方案 用户在使用淘宝、京东这样的网站的时候,每当点击一个按钮其实就是发送一个http请求。那我们先来回顾一下http请求的请求方式。 一个完整的http请求是被分为request请求节点和response响应阶段的&…...

【MySQL精通之路】优化
1 优化概述 数据库性能取决于数据库级别的几个因素,如表、查询和配置设置。这些软件结构导致了硬件级别的CPU和I/O操作,您必须将其最小化并使其尽可能高效。 在研究数据库性能时,首先要学习软件方面的高级规则和指导原则,并使用挂…...

解读大模型应用的可观测性
一、引言 随着人工智能技术的飞速发展,大模型作为AI领域的重要分支,正日益成为科技竞争的新高地。大模型通过输入大量语料进行训练,赋予计算机拥有像人类一样的“思考”能力,使其能够理解文本、图片、语音等内容,并进…...

嵌入式学习记录5.18(多点通信)
一、套接字属性设置相关函数 #include <sys/types.h> /* See NOTES */#include <sys/socket.h>int getsockopt(int sockfd, int level, int optname,void *optval, socklen_t *optlen);int setsockopt(int sockfd, int level, int optname,const void *op…...

shell脚本的基础应用
规范脚本的构成 #!/bin/bash # 注释信息 可执行的语句 执行脚本的方法 有1.添加x权限 ,绝对路经,或者相对路径2. 使用解释器 不需加x,root...bash...bash..echo 3,用source, 开机root ...bash ...echo bash -x /opt/test01.sh ÿ…...

【golang】内存对齐
什么是内存对齐 在访问特定类型变量的时候通常在特定的内存地址访问,这就需要对这些数据在内存中存放的位置有限制,各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。 内存对齐是编译器的管辖…...
)
LangChain学习之提示词模板 Prompts(2/8)
模块 2: 提示词模板 (Prompts) 2.1 提示词 (Prompts) 概述 在与大型语言模型(LLM)交互时,提示词 (Prompt) 是向模型发出的指令或问题。一个好的提示词能够引导模型生成高质量、符合预期的输出。LangChain 提供了强大的提示词管理功能&#…...

Hertz.dev未来展望:音频AI技术的演进路线与发展趋势
Hertz.dev未来展望:音频AI技术的演进路线与发展趋势 【免费下载链接】hertz-dev first base model for full-duplex conversational audio 项目地址: https://gitcode.com/gh_mirrors/he/hertz-dev Hertz-dev作为开源的全双工对话音频基础模型,正…...

CANN Triton排序选择算子优化
Sort/Select 算子优化 【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills 适用于需要迭代选择元素的算子:NMS、…...

ZYNQ平台SGMII光口实战:从Vivado连线、设备树到静态IP设置的完整避坑指南
ZYNQ平台SGMII光口实战:从Vivado连线到静态IP部署的全流程解析 在嵌入式系统开发中,以太网通信的稳定实现往往是项目成功的关键。对于采用Xilinx ZYNQ系列FPGA的开发者而言,SGMII(Serial Gigabit Media Independent Interface&…...

别再死磕标注数据了!用扩散模型从海量无标签遥感图像中‘白嫖’语义信息,提升变化检测精度
扩散模型在遥感变化检测中的无监督语义挖掘实战 遥感图像变化检测一直是地理信息科学和计算机视觉交叉领域的重要课题。传统方法高度依赖大量精确标注的训练数据,而标注成本高昂、周期漫长,成为制约算法性能提升的瓶颈。2022年涌现的多项突破性研究证明&…...

FPGA数学库设计:从定点数、CORDIC到AXI-Stream的硬件算法实现
1. 项目概述:为什么我们需要一个FPGA数学库?如果你在FPGA开发中做过信号处理、图像算法或者任何需要复杂数学运算的设计,大概率会面临一个共同的困境:如何高效、可靠地实现那些看似基础的数学函数?比如,计算…...

【限时解密】Perplexity写作辅助底层架构图首次公开:基于逆向分析的7大能力边界与替代方案评估
更多请点击: https://codechina.net 第一章:Perplexity写作辅助功能的定位与核心价值 Perplexity并非传统意义上的语法校对工具或模板生成器,而是一个以“问题驱动、证据锚定”为核心范式的智能写作协作者。它将用户输入的写作任务自动解构为…...

实在Agent架构实战:彻底化解工厂员工入转调离流程繁琐与HR行政超负荷困局
摘要: 站在2026年这个数字化深水区的节点,制造企业正面临前所未有的管理韧性挑战。工厂员工入转调离流程繁琐已不再仅仅是行政效率问题,而是演变为制约企业规模化扩张与人力成本控制的战略瓶颈。传统数字化手段往往受困于系统烟囱、老旧OA/ER…...

告别VirtualBox的‘不是Host-Only适配器’错误:一个网络配置的深度修复指南
VirtualBox Host-Only网络故障全解析:从原理到实战修复 当你正准备启动VirtualBox中的开发环境虚拟机时,突然弹出的红色错误提示框让所有工作戛然而止——"Interface is not a Host-Only Adapter"。这个看似简单的网络适配器错误背后…...
)
用C语言链表实现一个简易图书管理系统(附完整源码)
从零构建C语言链表图书管理系统:工程化实践指南 当你第一次在数据结构课本上看到链表时,是否觉得这些抽象的概念离实际开发很遥远?作为C语言初学者,我完全理解这种困惑——直到亲手用链表实现了一个真正的图书管理系统。本文将带你…...