揭秘Tensor Core黑科技:如何让AI计算速度飞跃

揭秘 Tensor Core 底层:如何让AI计算速度飞跃
Tensor Core,加速深度学习计算的利器,专用于高效执行深度神经网络中的矩阵乘法和卷积运算,提升计算效率。
Tensor Core凭借混合精度计算与张量核心操作,大幅加速深度学习模型的训练和推理。它采用半精度(FP16)作为输入输出,全精度(FP32)存储中间结果,确保精度同时最大化效率。这种高效计算方式,使Tensor Core能在短时间内完成大量矩阵运算,为深度学习带来质的飞跃。
Tensor Core 显著超越传统CUDA Core,每个时钟周期可执行高达4x4x4的GEMM运算,即同步完成64次浮点乘法累加(FMA),实现前所未有的计算效率。
Tensor Core的并行计算大幅加速深度学习模型的训练与推理,显著提升计算效率,引领人工智能领域迈向革命性新篇章。
TensorCore 计算原理
下面我们首先来回顾一下 Tensor Core 的计算原理。
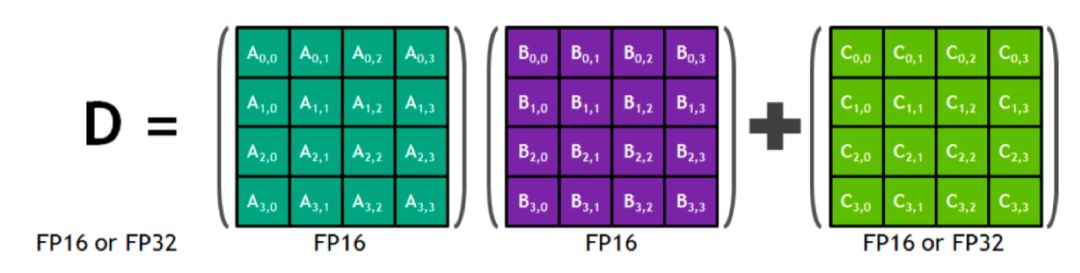
Tensor Core 计算
深绿色4x4矩阵A与紫色4x4矩阵B相乘,再与绿色矩阵C相加。混合精度技术在此应用中大放异彩,计算时采用FP16提高速度,而存储时则灵活选择FP32或FP16以保持数据精度,实现高效与准确性的完美融合。
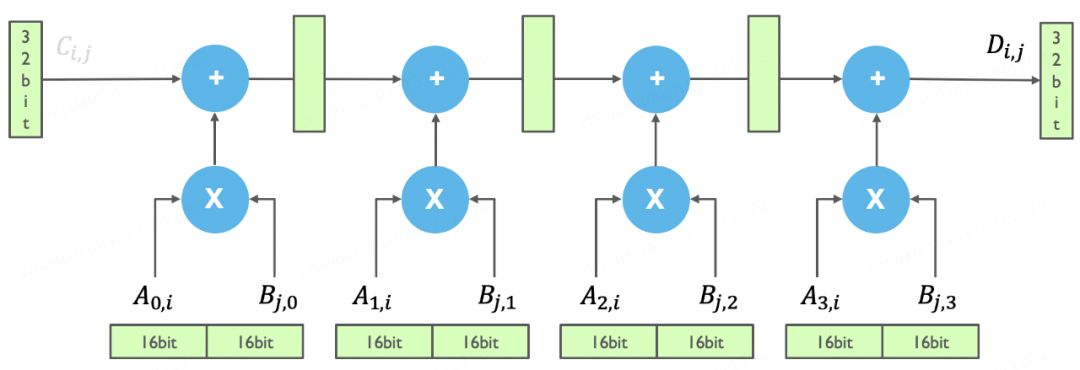
数学计算中,D矩阵的元素由矩阵A的一行与矩阵B的一列相乘,再与矩阵C的对应元素相加得出,公式精准呈现这一计算过程。
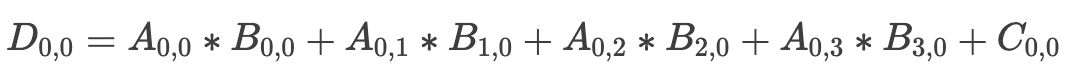
NVIDIA的GPU Tensor Core通过矩阵计算而非逐行处理,大幅提升计算效率。其计算模拟图展示了其高效能力,展现了其专业性和创新力。
Tensor Core FMA
Pascal架构(无Tensor Core)如图左,每时钟周期以元素乘行的方式,4次相乘得一列数据。而Volta架构(含Tensor Core)如图右,其Tensor Core直接计算矩阵A与B的乘积,一次性输出完整矩阵。Volta的高效性在矩阵运算中尤为显著,展现了显著的性能优势。
Volta V100 GPU相较于Pascal P100,在AI吞吐量上实现了飞跃,每个SM的AI吞吐量激增8倍。更值得一提的是,Volta架构在SM数量和核心设计上的精妙优化,使得整体性能飙升,总提升高达12倍。
TensorCore 指令流水
指令流水技术显著提升处理器效率,它将指令分解为多个精细步骤,各由专用电路并行处理。这种流水线式的连续执行方式,实现了指令的高效并行处理,极大提升了执行效率。
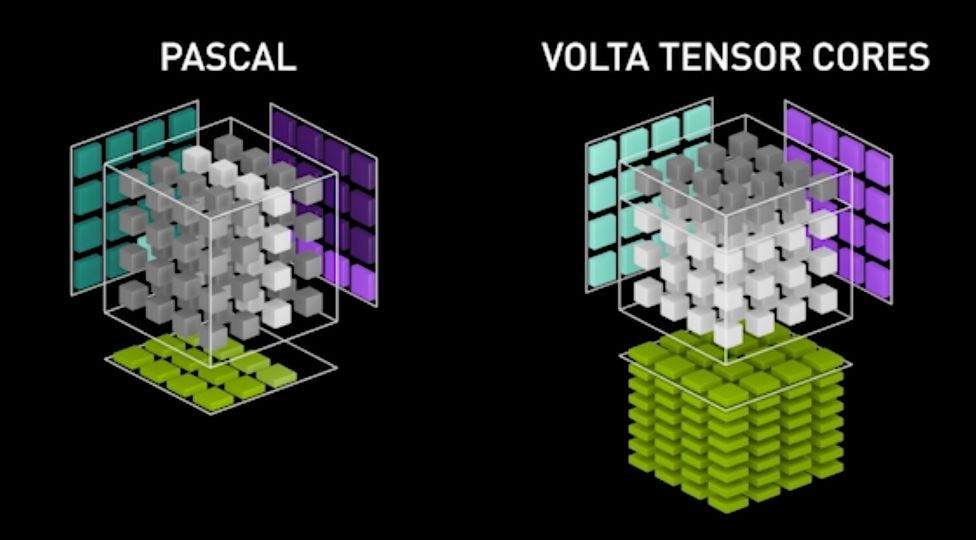
Tensor Core 模拟电路
Tensor Core模拟电路图展示了矩阵计算的核心操作。加号代表矩阵加,乘号则代表矩阵乘,这两者是矩阵计算的基础。图中绿色长方块为寄存器,其中16位横置寄存器用于存储输入与中间数据,而32位竖向寄存器则用于累积结果或高精度数据存储,确保计算高效精确。
在Tensor Core中实现矩阵相乘,即A行乘B列(假设长度均为4),其电路示意图详细展示了计算过程。无需考虑矩阵切分,我们聚焦于这一核心运算的精准实现。
Tensor Core 计算中,输入为16bit数据,乘加后需32位寄存器存储中间数据。高精度存储寄存器紧邻实际计算单元,实现A矩阵行与B矩阵列的乘法操作,简洁高效,确保计算精确性。这一设计优化了矩阵运算的效率和准确性。
GPU V100中,计算核心为矩阵间直接相乘生成新矩阵。模拟电路演示仅展示其中行列间FMA运算,生成单一元素的过程,凸显GPU强大计算能力。
那么一个矩阵中更多元素的是如何进行计算的呢?
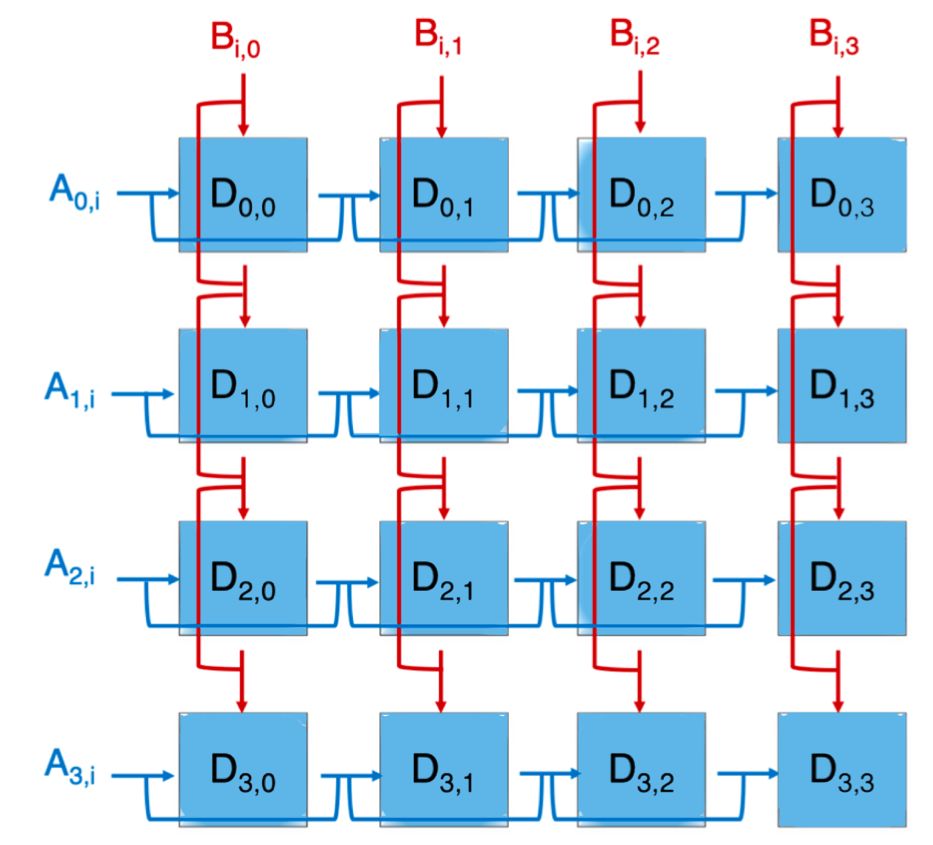
Tensor Core 矩阵模拟电路
矩阵A的行与矩阵B的列通过FMA运算生成一个元素,如首个蓝色方块所示。整体计算过程犹如电路拼接,简单地将A矩阵的每一行与B矩阵的每一列相乘,从而构建出整个矩阵的每个元素。
在此时,A、B矩阵的寄存器应各自构成一组阵列,实现并行读取与计算。这种阵列布局使矩阵的每个元素都能执行FMA计算,显著提升计算效率。
下面我们再来了解下指令流水的 Pipline 是如何组织起来的。
当我们进行一个 Fp32 标量元素乘加操作的指令时,就像下面图所示。
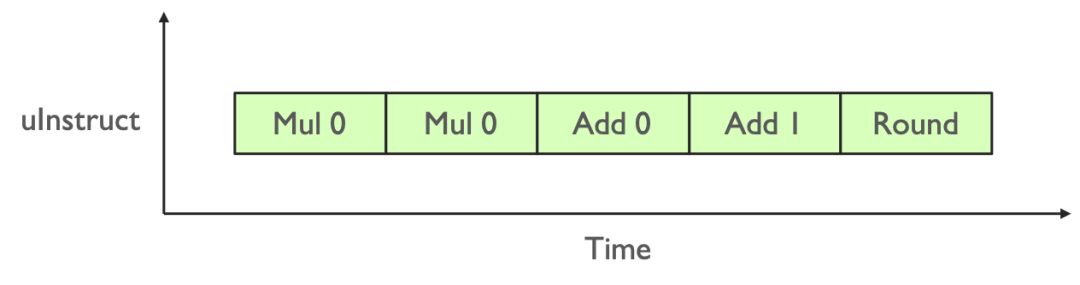
Tensor Core 标量流水线
Tensor Core内乘法运算仅支持Fp16,而存储与加法运算则采用Fp32,巧妙地实现了乘法运算的精简,显著提升计算效率。

Tensor Core 两个元素流水线
Tensor Core计算时,输出单个元素需A的一行与B的一列相乘,高效实现依赖四条并行Pipeline流水线,确保高效能处理。
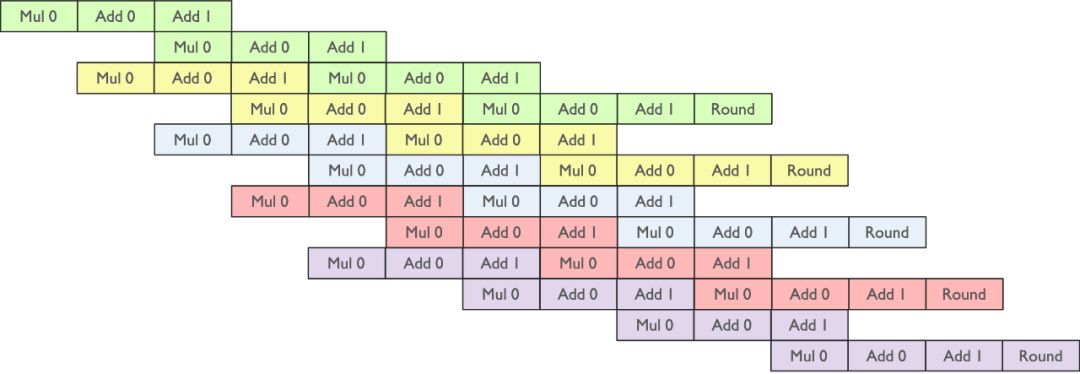
Tensor Core 一行 x 一列流水线
图示中,绿色指令流水与黄色流水线共同完成了部分计算。为全面计算所有元素,需高效拼接大量指令流水,确保计算流畅无阻。
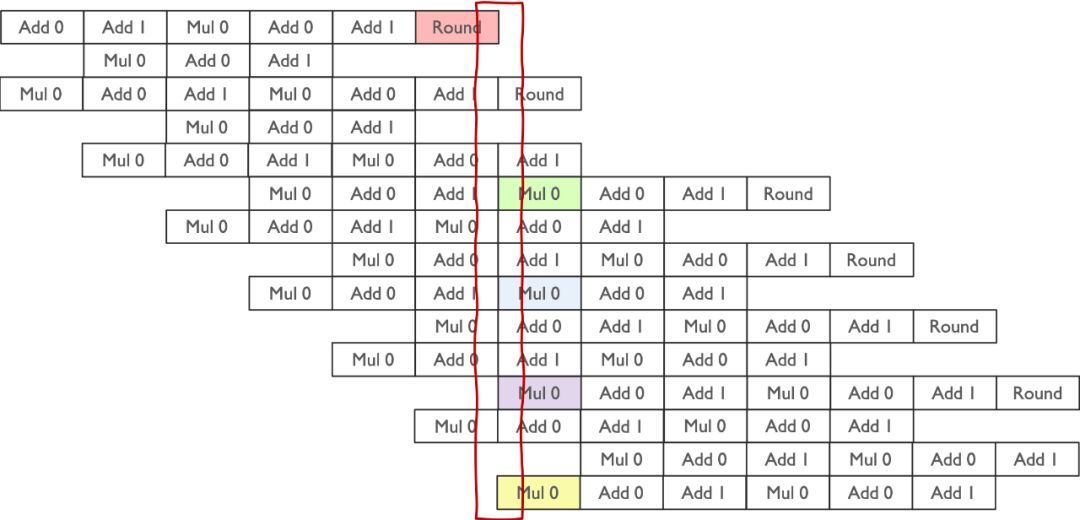
Tensor Core 矩阵流水线
数据在流水线中的读写遵循明确规律:乘法计算时,从存储单元读取两数据;计算完成后,Round阶段将结果写回单元。在特定时刻,流水线涉及四个数据:两个用于计算,两个存储回寄存器。这一流程确保了数据的高效处理与准确存储。
Tensor Core的高效运算得益于精心设计的指令流水线处理。这种设计使数据读取、计算和写入无缝交替,最大化硬件资源利用率,显著提升计算效率。流水线技术不仅加速Tensor Core运算,更为深度学习应用提供强大动力,实现快速、高效的计算体验。
TensorCore 线程执行
在整体 CUDA 软件设计方面,其目的是与 GPU 计算和存储分层结构相匹配。
NVIDIA CUDA定义Tensor Core为通用编程(General Programming)范式,旨在通过CUDA平台最大化Tensor Core的硬件效能。CUDA让开发者能够运用通用编程模型,精准调用Tensor Core功能,实现并行计算的高效运行,从而显著提升计算效率。
Tensor Core 的计算简化为 C = A * B,但面对大矩阵时,由于 Tensor Core 仅支持4x4的运算,需将矩阵切片并分配到 Thread Block 中。这种分片处理策略确保了大规模矩阵运算的高效执行,充分发挥了 Tensor Core 的计算能力。
在软件层面,我们定义Warp以分配切片矩阵至不同线程束。通过线程并行执行,实现矩阵乘法的高效计算,充分利用Tensor Core的计算潜能。此分块、分配与并行化策略有效释放硬件资源,极大提升计算效率,为深度学习及科学计算等应用带来显著加速效果。
下面我们将详细展开 Tensor Core 是如何完成大的矩阵计算的。
Block-level 矩阵乘
Tensor Core中,GEMM(矩阵乘)每次仅处理小矩阵块。实际操作时,需将矩阵A、B分别切分为小块,以计算出小矩阵C。此过程高效且精准,如图所示。
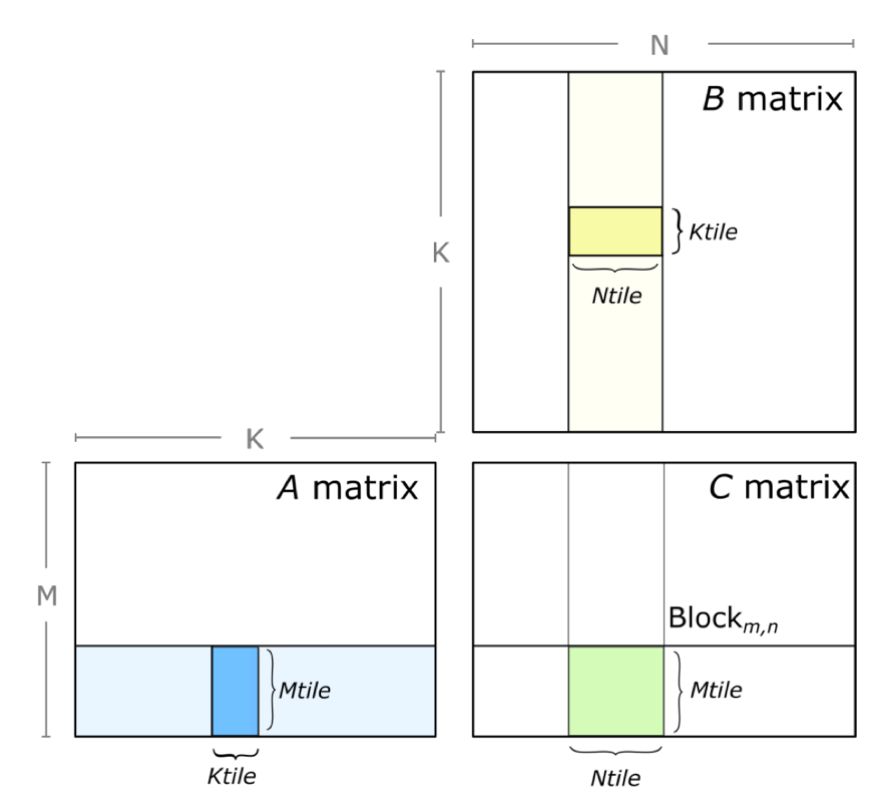
Block-level 的矩阵乘
for (int mb = O; mb < M; mb += Mtile)
for (int nb = O; nb < N; nb += NtiLe)
for(int kb = O; kb < K; kb += Ktile)
{
//compute Mtile-by-Ntile-by-Ktile matrix product
for (int k = O; k < Ktile; ++k)
for(int i= O; i< Mtile; ++i)
for (int j= O; j< Ntile;++j)
{
int row = mb + i;
int col = nb + j;
C[row][col] +=,A[row][kb + k] * B[kb + k][col];
}
}
如代码所示,我们沿维度将循环嵌套划分为块,进而分解为Mtile-by-Ntile的独立矩阵乘。最终,通过累加Mtile-by-Ntile-by-Ktile的矩阵乘积,高效计算每个乘积,确保性能与效率的双赢。
在GPU计算中,CUDA kernel grid将线程块精准映射至输出矩阵D的各分区,实现高效的并行计算。线程块并行执行Mtile-by-Ntile-by-Ktile矩阵乘法,并在K维上迭代,累积计算结果。这种基于Thread Block的并行策略,确保了计算资源的高效利用,显著提升了矩阵乘法的性能。
Warp-level 矩阵乘
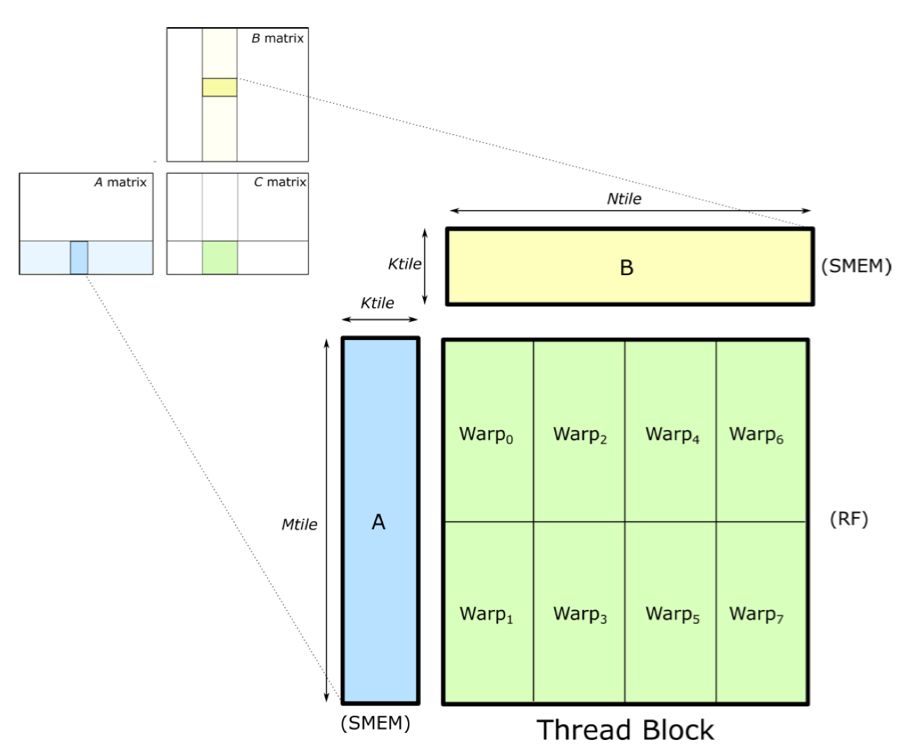
Warp-level 的矩阵乘
CUDA编程模型中,矩阵乘法操作在线程块内执行,实则由Warp单元分配执行。Warp作为GPU的执行单元,由32个线程协同工作,共同执行指令,显著提升矩阵乘法的执行效率。
矩阵乘法中,为提升计算速度和降低内存访问延迟,我们常将矩阵A、B的部分数据载入共享内存(SMEM)。SMEM是线程块内共享的快速内存,支持线程间数据交换和协作,减少了对全局内存的频繁读取,显著提升了计算效率。
在矩阵乘法中,Warp负责高效计算结果矩阵C的部分或全部。通过将C的不同块分配给不同的Warp,实现并行处理。Warp内的线程同步执行,协同工作,共享内存数据以完成计算任务,确保计算效率与准确性并存。
矩阵乘法中,Warp内线程协同操作,通过共享内存(SMEM)加载数据至寄存器(RF)进行乘加运算,结果再存入寄存器或全局内存,高效完成一系列计算任务。
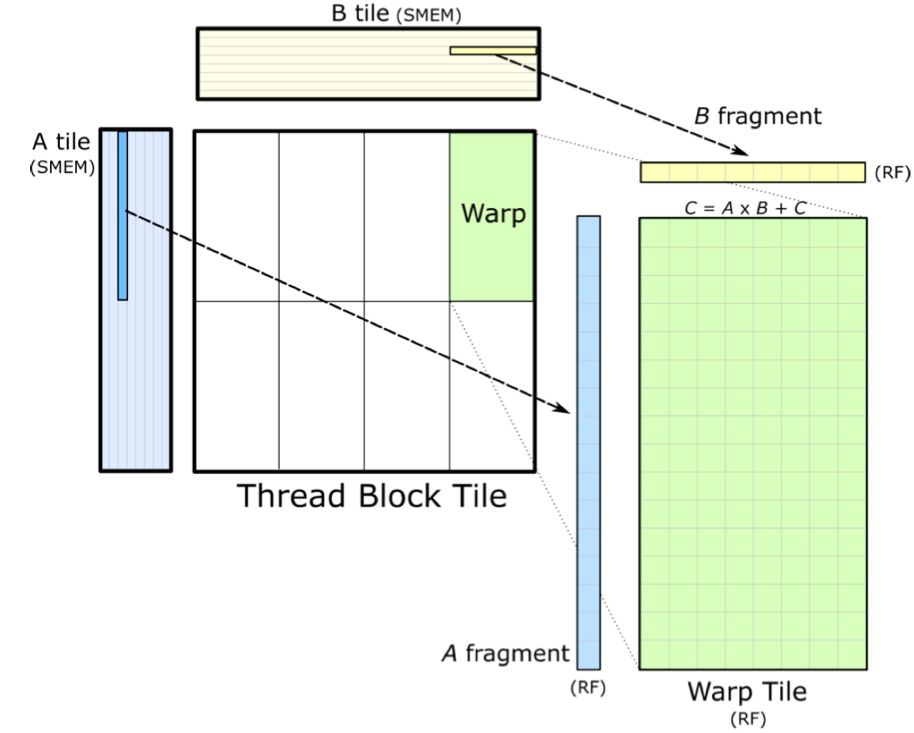
Warp-level 的矩阵乘展开
下面我们详细解释一下这个过程:
Warp由多线程组成,协同工作以高效处理矩阵乘法。线程间紧密合作,通过精准乘加运算,迅速得出准确结果,大幅提升计算效率。
Warp线程在计算时,需从共享内存迅速加载矩阵A、B的片段至寄存器,确保数据快速访问与计算。加载速度需足够快,避免线程等待,维持计算高效性。这一优化确保计算流程的高效流畅,为数据处理提供强大支持。
随后,各线程在寄存器上并行执行矩阵乘法,计算矩阵C的元素,暂存于寄存器中直至所有乘加操作完成。计算中,我们对共享内存数据实施K维排序,旨在优化线程的数据访问效率,显著减少内存访问延迟,确保线程高效获取所需数据,从而最大化计算效率。
Thread-level 矩阵乘
Tensor Core 高效并行执行核心操作:矩阵A乘以矩阵B,直接得出C矩阵,展现计算的高效与简洁。
Tensor Core作为NVIDIA GPU的核心硬件,通过CUDA编程模型的WMMA(Warp级矩阵乘加)API得到完美支持。该API专为Tensor Core设计,让开发者在CUDA程序中直接解锁硬件加速潜力。利用WMMA API,开发者不仅能高效执行矩阵乘法累积操作,还能轻松管理数据加载、存储及同步,实现性能与效率的双重飞跃。
在GEMM软硬件分层中,数据复用至关重要。面对庞大矩阵数据,高效复用能显著提升计算效率。通过全局内存、共享内存和寄存器等不同内存层次结构,我们精心管理和复用数据,确保每一层都能充分发挥数据价值,实现高效计算。
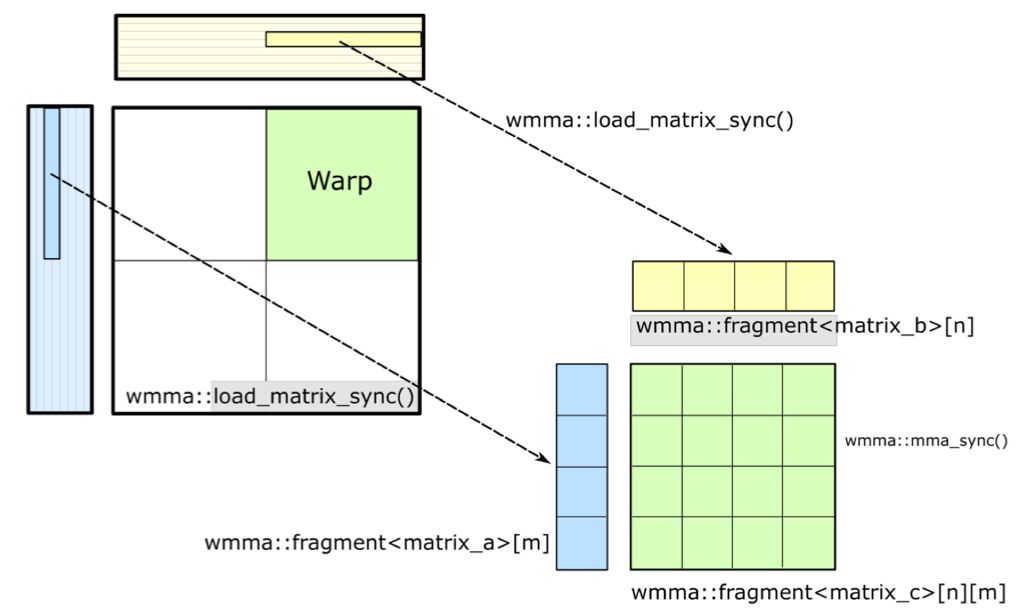
Thread-level 的矩阵乘
大矩阵高效计算的核心在于将其分割并存储于全局内存。计算时,小块数据被迅速加载至共享内存或寄存器,大幅减少内存访问延迟,提升计算效率。完成每块矩阵乘法后,结果即刻累积,涉及中间结果从寄存器或共享内存回流至全局内存,并适时同步与累加,确保最终矩阵乘法结果的完整性。这一流程,确保计算速度与精度的双重优化。
通过精心设计的计算和数据管理操作,我们高效完成了GEMM计算任务,并将结果精准地写回输出矩阵C。此过程充分利用了Tensor Core的硬件加速和CUDA编程模型的灵活性,显著提升了矩阵乘法的计算效率。
累积矩阵结果
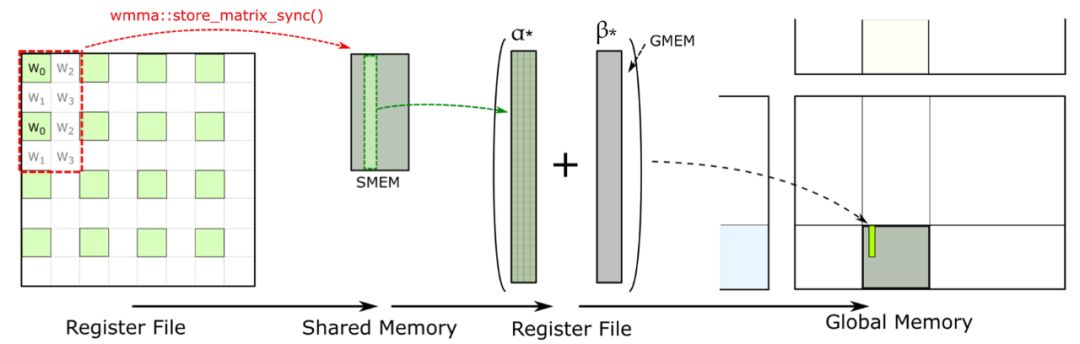
Tensor Core 累积矩阵并写出最终结果
Tensor Core中的WMMA API支持register file中临时结果的快速回传。特别地,store matrix sync API能将数据高效搬移至共享内存(SMEM),确保数据处理的流畅与高效。这一机制显著提升了计算效率,为深度学习等应用提供了强大支持。
SMEM内高效累积数据,存储至全局内存。通过全局内存,实现数据块的无缝拼接,快速回传并输出结果,确保高效处理。
整体计算过程
下面我们来总结一下整个的计算过程:
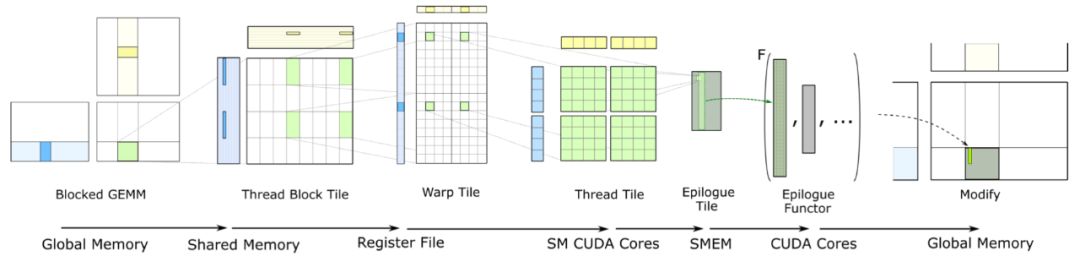
Tensor Core 计算全流程
矩阵进行GEMM计算前会先分块,并存储在GPU的全局内存中,这是GPU上最大的内存区域,专为处理计算中需频繁访问的海量数据而设计,确保高效的数据处理速度。
计算前,程序将矩阵分块加载至共享内存,确保低延迟访问。共享内存是线程块内所有线程可访问的数据池,实现数据的高效共享与重用,优化计算性能。
在矩阵乘法运算中,线程高效地将共享内存数据加载至其私有寄存器,这是GPU上速度最快的内存空间。每个线程拥有独立寄存器文件,确保运算的独立性。在Tensor Core中,数据直接存储于其寄存器文件,并进行高速计算,极大提升了矩阵乘法的执行效率。
计算完成后,结果直接写回共享内存,而非滞留于Tensor Core寄存器。此举旨在优化中间结果存储与线程间数据交互。CUDA的WMMA API提供了如store matrix sync等函数,确保数据同步累积准确无误,从而高效利用共享内存资源,提升数据处理效率。
在共享内存中累积结果后,将自动写回全局内存。此过程需多线程块协同,因矩阵乘法需多线程块合力完成。全局内存确保各线程块结果无缝拼接,形成完整的矩阵乘法结果,高效且精准。
总结
深度学习中的GEMM计算涵盖矩阵分块、数据加载至共享内存与寄存器、Tensor Core内计算、结果存回共享内存并写入全局内存,实现高效数据处理。
Tensor Core,精通数学的计算专家,擅长深度学习的矩阵乘法和卷积运算。其采用FP16计算,FP32存储中间结果,确保高效且精确。Tensor Core能一次性处理4x4矩阵乘法,相较于CUDA Core,计算速度显著提升,为深度学习领域带来革命性变革。
借助WMMA API与CUDA编程技术,我们高效利用GPU资源,实现矩阵乘法运算性能飞跃,轻松应对高性能计算需求。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
相关文章:
揭秘Tensor Core黑科技:如何让AI计算速度飞跃
揭秘 Tensor Core 底层:如何让AI计算速度飞跃 Tensor Core,加速深度学习计算的利器,专用于高效执行深度神经网络中的矩阵乘法和卷积运算,提升计算效率。 Tensor Core凭借混合精度计算与张量核心操作,大幅加速深度学习…...
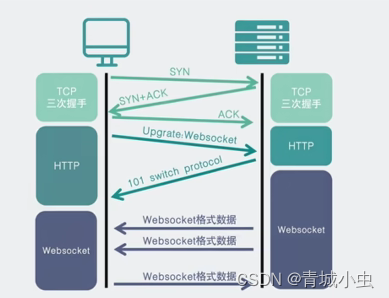
为什么会有websocket(由来)
一、HTTP 协议的缺点和解决方案 1、HTTP 协议的缺点和解决方案 用户在使用淘宝、京东这样的网站的时候,每当点击一个按钮其实就是发送一个http请求。那我们先来回顾一下http请求的请求方式。 一个完整的http请求是被分为request请求节点和response响应阶段的&…...

【MySQL精通之路】优化
1 优化概述 数据库性能取决于数据库级别的几个因素,如表、查询和配置设置。这些软件结构导致了硬件级别的CPU和I/O操作,您必须将其最小化并使其尽可能高效。 在研究数据库性能时,首先要学习软件方面的高级规则和指导原则,并使用挂…...

解读大模型应用的可观测性
一、引言 随着人工智能技术的飞速发展,大模型作为AI领域的重要分支,正日益成为科技竞争的新高地。大模型通过输入大量语料进行训练,赋予计算机拥有像人类一样的“思考”能力,使其能够理解文本、图片、语音等内容,并进…...

嵌入式学习记录5.18(多点通信)
一、套接字属性设置相关函数 #include <sys/types.h> /* See NOTES */#include <sys/socket.h>int getsockopt(int sockfd, int level, int optname,void *optval, socklen_t *optlen);int setsockopt(int sockfd, int level, int optname,const void *op…...

shell脚本的基础应用
规范脚本的构成 #!/bin/bash # 注释信息 可执行的语句 执行脚本的方法 有1.添加x权限 ,绝对路经,或者相对路径2. 使用解释器 不需加x,root...bash...bash..echo 3,用source, 开机root ...bash ...echo bash -x /opt/test01.sh ÿ…...

【golang】内存对齐
什么是内存对齐 在访问特定类型变量的时候通常在特定的内存地址访问,这就需要对这些数据在内存中存放的位置有限制,各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。 内存对齐是编译器的管辖…...

Java 17的新特性有哪些?
Java 17是Java编程语言的最新版本,于2021年9月14日发布。以下是Java 17的一些新特性: Sealed类和接口:Sealed类和接口限制了继承和实现的范围,在编译时提供更强的封装性。 Pattern匹配:Pattern匹配简化了对实例进行类…...

攻击同学网络,让同学断网
技术介绍:ARP欺骗 ARP欺骗(ARP spoofing)是一种网络攻击技术,它通过伪造ARP(地址解析协议)响应包来欺骗目标设备,使其将网络流量发送到攻击者指定的位置。具体操作步骤如下: 攻击者…...
Springboot启动时报错Property ‘mapperLocations‘ was not specified.
这几天没整boot 晚上直接运行不了了 本想是在表现层写点代码测测接口的 localhost8080找半天 结果404 先考虑好久 是不是url输入错了 然后 就发现 结果boot都不能启动了 JUnit也测不出来 找了半天 结果是开关机导致数据库没开 手动打开服务 找到MySQL启动 IDEA连接数据…...

MyBatis系统学习篇 - 动态SQL
MyBatis提供了动态SQL帮助我们解决在业务过程中,我们根据不同的条件动态生成SQL语句,用来满足各种复杂的查询需求,包括MyBatis中常用的动态SQL标签和用法,这种方式在一定程度上帮助我们重复写许多SQL堆积在一起,下面我…...

[LLM-Agent]万字长文深度解析规划框架:HuggingGPT
HuggingGPT是一个结合了ChatGPT和Hugging Face平台上的各种专家模型,以解决复杂的AI任务,可以认为他是一种结合任务规划和工具调用两种Agent工作流的框架。它的工作流程主要分为以下几个步骤: 任务规划:使用ChatGPT分析用户的请求…...

二十三篇:未来数据库革新:AI与云原生的融合之旅
未来数据库革新:AI与云原生的融合之旅 1. 智能数据库管理:AI的魔法 在数字化时代,数据库技术作为信息管理的核心,正经历着前所未有的变革。AI(人工智能)和云原生技术的融合,正在重新定义数据库…...

彩光赋能中国智造 极简光3.X助力“数智”转型
蒸汽时代、电气时代、信息时代三大工业革命后 互联网和智能制造主导的工业4.0时代来临 大数据、云计算、人工智能等新兴技术 对企业园区的网络架构、负载能力等 提出了新要求,也使得光纤较于传统铜缆 在距离、性能、延时上的优势日益凸显 基于此 围绕未来园区网建设的企…...
985上交应届生转正12天,被某东辞退了!
👇我的小册 45章教程:(小白零基础用Python量化股票分析小册) ,原价299,限时特价2杯咖啡,满100人涨10元。 01.事情起源 最近粉丝群都在转发一个截图,某应届毕业生在某东实习一年,才转正才12天,就因为自己调侃…...
——快速排序算法)
Unity算法(一)——快速排序算法
文章目录 前言快速排序算法1、概念与实现2、优化 前言 算法是程序员的基础能力之一,资质越老的程序员在这方面理解会越深,很多时候项目在某个需要优化、提升的节点时,往往一些算法的使用就可以大大提升程序性能。当然,对于不同项…...

Leetcode 2028
思路:1-6之间的的n个数组合起来要变成sum_t mean*(rolls.size()n) - sum(rolls) ; 那么可以先假设每个数都是sum_t / n 其中这个数必须要在1 - 6 之间否者无法分配。 然后可以得出n * (sum_t / n ) < sum ; 需要对余数mod进行调整,为了减少调整的次…...
Angular(1):使用Angular CLI创建空项目
要创建一个空的 Angular 项目,可以使用 Angular CLI(命令行界面)。以下是使用 Angular CLI 创建一个新项目的步骤: 1、安装 Angular CLI: 打开你的命令行界面(在 Windows 上是 CMD、PowerShell 或 Git Bas…...
算法原题)
字节跳动(校招)算法原题
大模型"价格战"越演越烈 昨天的 文章 提到,自从 5 月 15 号,字节跳动发布了击穿行业底价的豆包大模型后,各大厂家纷纷跟进降价,而且都不是普通降价,要么降价 90% 以上,要么直接免费。 今天是豆包…...

前端面试题日常练-day39 【面试题】
题目 希望这些选择题能够帮助您进行前端面试的准备,答案在文末。 1. 哪个jQuery方法用于设置元素的HTML内容? a) .html() b) .text() c) .val() d) .append() 2. 在jQuery中,以下哪个方法用于隐藏或显示一个元素? a) .toggle…...

别再死记硬背了!用Python+仿真软件复现莱顿瓶实验,轻松理解电容器原理
用Python仿真软件复现莱顿瓶实验:从历史装置到现代电容教学 在工程教育中,电容原理常常是学生遇到的第一个抽象概念。传统的板书推导和公式记忆往往让学习者陷入"知其然而不知其所以然"的困境。18世纪的莱顿瓶作为人类最早的电容器,…...

Mac/Win双平台保姆级教程:从零配置ADB环境到连接真机/模拟器
Mac/Win双平台保姆级教程:从零配置ADB环境到连接真机/模拟器 第一次接触Android开发或测试时,配置ADB环境往往是让人头疼的第一步。不同操作系统、不同设备品牌、不同模拟器之间的差异,让很多新手在"adb devices"命令前败下阵来。…...

字节面试官:你知道Claude Code的多Agent实现机制吗?
上周四晚上,我的微信弹出一条消息。一个准备跳槽字节AI Agent岗的朋友发来语音,语气像刚被泼了一盆冷水:“他们没让我手撕Transformer,也没问RLHF。上来就是一句——你知道Claude Code的多Agent实现机制吗?能不能讲一下…...

你的RAR5密码有多安全?我用hashcat掩码攻击实测了一下
RAR5密码安全实测:从暴力破解到防御策略 当你在深夜赶工,把重要文件打包成加密压缩包发送给同事时,是否想过这个密码能撑多久?上周我给自己设置了一个看似安全的8位数字密码,结果在咖啡还没凉透前就被破解了。这不是危…...

车规级LGA封装RK3588开发板:硬件设计与车规应用实战解析
1. 项目概述:当“车规级”遇上“LGA封装”的RK3588 最近在嵌入式圈子里,一个消息引起了不小的讨论:深圳市九鼎创展科技推出了一款搭载LGA封装核心板的RK3588开发板,并且主打车规级应用。对于长期在工业控制和边缘计算领域摸爬滚打…...

私有化视频会议平台/企业级融媒体平台EasyDSS赋能企业远程培训高质量落地
在数字化转型深化的今天,企业远程培训已从“应急手段”升级为“常态化赋能模式”,尤其是对于跨区域布局、员工基数庞大的企业而言,远程培训的安全性、规范性与体验感,直接决定了人才培养的效率与质量。私有化视频会议系统EasyDSS凭…...

避坑指南:在ArcGIS中提取DEM高程点,为什么导入Global Mapper后看不到高度?
避坑指南:ArcGIS与Global Mapper高程数据互操作的核心陷阱与解决方案 当你第一次将精心处理的DEM高程点从ArcGIS导入Global Mapper,期待看到起伏有致的三维地形时,却发现所有点都"躺平"在二维平面上——这种挫败感我深有体会。这不…...
)
告别手动配置!用Matlab+LUA脚本自动化DCA1000雷达数据采集(附1843配置实例)
雷达数据采集自动化:Matlab与LUA脚本的高效协作方案 在毫米波雷达研发领域,数据采集是每个工程师日常工作中不可或缺的环节。传统的手动配置方式不仅耗时耗力,还容易因人为操作失误导致数据质量不稳定。本文将介绍如何通过Matlab与LUA脚本的协…...

谷歌关键词优化具体要做什么?独立站新手必看的5条铁规
建站满60天,后台数据面板显示0笔订单。 访问谷歌站长控制台,过去28天曝光次数仅为12。一家售卖宠物玩具的独立站上线45天,上传200个商品页面。每页装填3句机器翻译英文。页面缺失买家真实评价,网页找不到1处猫咪啃咬耐用度测试图。…...

TI IWR6843ISK-ODS雷达固件开发环境搭建:从MATLAB Runtime到CCS的保姆级避坑指南
TI IWR6843ISK-ODS雷达固件开发环境搭建实战手册 毫米波雷达技术正在智能感知领域掀起革命浪潮,而德州仪器(TI)的IWR6843ISK-ODS评估板因其出色的集成度和性价比,成为众多开发者进入这一领域的首选平台。然而,从硬件拆封到第一个雷达点云成功…...