【pyspark速成专家】11_Spark性能调优方法2

目录
编辑
二,Spark任务UI监控
三,Spark调优案例
二,Spark任务UI监控
Spark任务启动后,可以在浏览器中输入 http://localhost:4040/ 进入到spark web UI 监控界面。
该界面中可以从多个维度以直观的方式非常细粒度地查看Spark任务的执行情况,包括任务进度,耗时分析,存储分析,shuffle数据量大小等。
最常查看的页面是 Stages页面和Excutors页面。
Jobs: 每一个Action操作对应一个Job,以Job粒度显示Application进度。有时间轴Timeline。
Stages: Job在遇到shuffle切开Stage,显示每个Stage进度,以及shuffle数据量。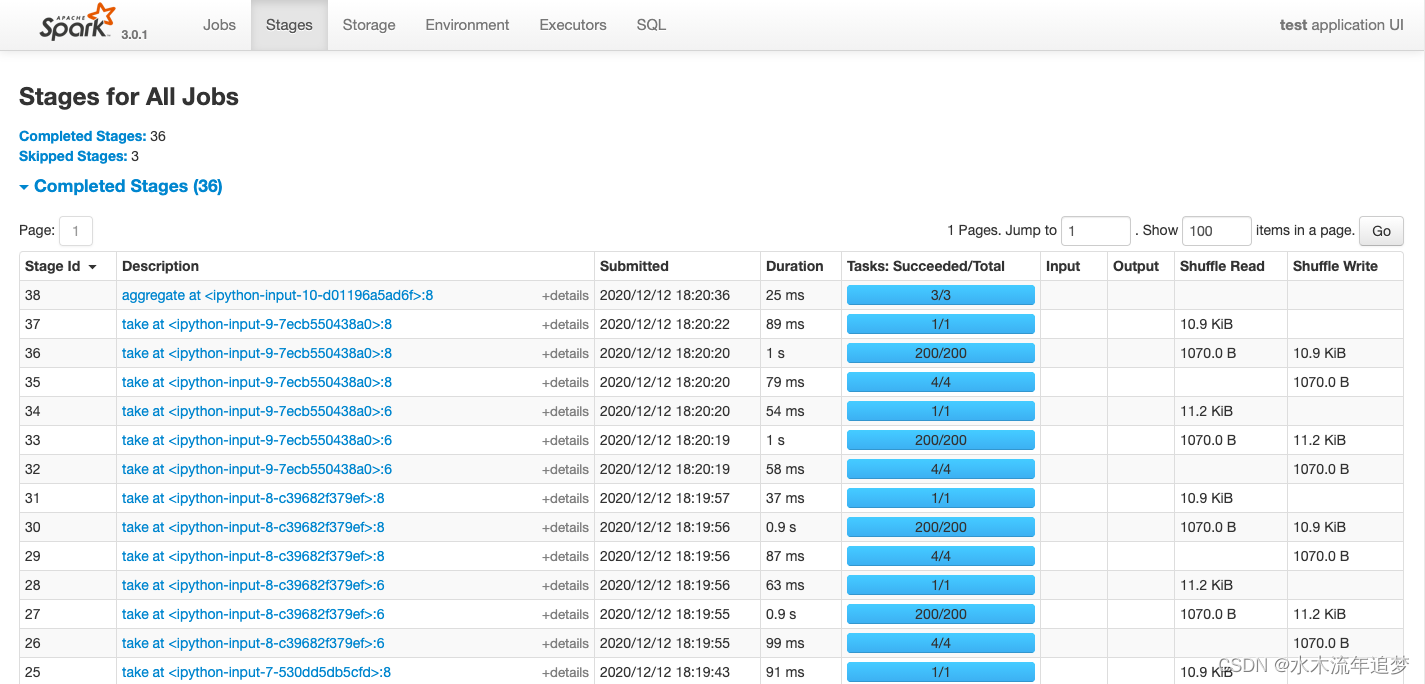 可以点击某个Stage进入详情页,查看其下面每个Task的执行情况以及各个partition执行的费时统计。
可以点击某个Stage进入详情页,查看其下面每个Task的执行情况以及各个partition执行的费时统计。

Storage:
监控cache或者persist导致的数据存储大小。
Environment:
显示spark和scala版本,依赖的各种jar包及其版本。
Excutors : 监控各个Excutors的存储和shuffle情况。
SQL: 显示各种SQL命令在那些Jobs中被执行。
三,Spark调优案例
下面介绍几个调优的典型案例:
1,资源配置优化
2,利用缓存减少重复计算
3,数据倾斜调优
4,broadcast+map代替join
5,reduceByKey/aggregateByKey代替groupByKey
1,资源配置优化
下面是一个资源配置的例子:
优化前:
#提交python写的任务
spark-submit --master yarn \
--deploy-mode cluster \
--executor-memory 12G \
--driver-memory 12G \
--num-executors 100 \
--executor-cores 8 \
--conf spark.yarn.maxAppAttempts=2 \
--conf spark.task.maxFailures=10 \
--conf spark.stage.maxConsecutiveAttempts=10 \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./anaconda3.zip/anaconda3/bin/python #指定excutors的Python环境
--conf spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON = ./anaconda3.zip/anaconda3/bin/python #cluster模式时候设置
--archives viewfs:///user/hadoop-xxx/yyy/anaconda3.zip #上传到hdfs的Python环境
--files data.csv,profile.txt
--py-files pkg.py,tqdm.py
pyspark_demo.py 优化后:这里主要减小了 executor-cores数量,一般设置为1~4,过大的数量可能会造成每个core计算和存储资源不足产生OOM,也会增加GC时间。 此外也将默认分区数调到了1600,并设置了2G的堆外内存。
#提交python写的任务
spark-submit --master yarn \
--deploy-mode cluster \
--executor-memory 12G \
--driver-memory 12G \
--num-executors 100 \
--executor-cores 2 \
--conf spark.yarn.maxAppAttempts=2 \
--conf spark.default.parallelism=1600 \
--conf spark.sql.shuffle.partitions=1600 \
--conf spark.memory.offHeap.enabled=true \
--conf spark.memory.offHeap.size=2g\
--conf spark.task.maxFailures=10 \
--conf spark.stage.maxConsecutiveAttempts=10 \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./anaconda3.zip/anaconda3/bin/python #指定excutors的Python环境
--conf spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON = ./anaconda3.zip/anaconda3/bin/python #cluster模式时候设置
--archives viewfs:///user/hadoop-xxx/yyy/anaconda3.zip #上传到hdfs的Python环境
--files data.csv,profile.txt
--py-files pkg.py,tqdm.py
pyspark_demo.py 2, 利用缓存减少重复计算
%%time
# 优化前:
import math
rdd_x = sc.parallelize(range(0,2000000,3),3)
rdd_y = sc.parallelize(range(2000000,4000000,2),3)
rdd_z = sc.parallelize(range(4000000,6000000,2),3)
rdd_data = rdd_x.union(rdd_y).union(rdd_z).map(lambda x:math.tan(x))
s = rdd_data.reduce(lambda a,b:a+b+0.0)
n = rdd_data.count()
mean = s/n
print(mean)%%time
# 优化后:
import math
from pyspark.storagelevel import StorageLevel
rdd_x = sc.parallelize(range(0,2000000,3),3)
rdd_y = sc.parallelize(range(2000000,4000000,2),3)
rdd_z = sc.parallelize(range(4000000,6000000,2),3)
rdd_data = rdd_x.union(rdd_y).union(rdd_z).map(lambda x:math.tan(x)).persist(StorageLevel.MEMORY_AND_DISK)s = rdd_data.reduce(lambda a,b:a+b+0.0)
n = rdd_data.count()
mean = s/n
rdd_data.unpersist()
print(mean)3, 数据倾斜调优
%%time
# 优化前:
rdd_data = sc.parallelize(["hello world"]*1000000+["good morning"]*10000+["I love spark"]*10000)
rdd_word = rdd_data.flatMap(lambda x:x.split(" "))
rdd_one = rdd_word.map(lambda x:(x,1))
rdd_count = rdd_one.reduceByKey(lambda a,b:a+b+0.0)
print(rdd_count.collect()) %%time
# 优化后:
import random
rdd_data = sc.parallelize(["hello world"]*1000000+["good morning"]*10000+["I love spark"]*10000)
rdd_word = rdd_data.flatMap(lambda x:x.split(" "))
rdd_one = rdd_word.map(lambda x:(x,1))
rdd_mid_key = rdd_one.map(lambda x:(x[0]+"_"+str(random.randint(0,999)),x[1]))
rdd_mid_count = rdd_mid_key.reduceByKey(lambda a,b:a+b+0.0)
rdd_count = rdd_mid_count.map(lambda x:(x[0].split("_")[0],x[1])).reduceByKey(lambda a,b:a+b+0.0)
print(rdd_count.collect()) #作者按:此处仅示范原理,单机上该优化方案难以获得性能优势4, broadcast+map代替join
该优化策略一般限于有一个参与join的rdd的数据量不大的情况。
%%time
# 优化前:rdd_age = sc.parallelize([("LiLei",18),("HanMeimei",19),("Jim",17),("LiLy",20)])
rdd_gender = sc.parallelize([("LiLei","male"),("HanMeimei","female"),("Jim","male"),("LiLy","female")])
rdd_students = rdd_age.join(rdd_gender).map(lambda x:(x[0],x[1][0],x[1][1]))print(rdd_students.collect())%%time # 优化后:
rdd_age = sc.parallelize([("LiLei",18),("HanMeimei",19),("Jim",17),("LiLy",20)])
rdd_gender = sc.parallelize([("LiLei","male"),("HanMeimei","female"),("Jim","male"),("LiLy","female")],2)
ages = rdd_age.collect()
broads = sc.broadcast(ages)def get_age(it):result = []ages = dict(broads.value)for x in it:name = x[0]age = ages.get(name,0)result.append((x[0],age,x[1]))return iter(result)rdd_students = rdd_gender.mapPartitions(get_age)print(rdd_students.collect())5,reduceByKey/aggregateByKey代替groupByKey
groupByKey算子是一个低效的算子,其会产生大量的shuffle。其功能可以用reduceByKey和aggreagateByKey代替,通过在每个partition内部先做一次数据的合并操作,大大减少了shuffle的数据量。
%%time
# 优化前:
rdd_students = sc.parallelize([("class1","LiLei"),("class2","HanMeimei"),("class1","Lucy"),("class1","Ann"),("class1","Jim"),("class2","Lily")])
rdd_names = rdd_students.groupByKey().map(lambda t:(t[0],list(t[1])))
names = rdd_names.collect()
print(names)%%time
# 优化后:
rdd_students = sc.parallelize([("class1","LiLei"),("class2","HanMeimei"),("class1","Lucy"),("class1","Ann"),("class1","Jim"),("class2","Lily")])
rdd_names = rdd_students.aggregateByKey([],lambda arr,name:arr+[name],lambda arr1,arr2:arr1+arr2)names = rdd_names.collect()
print(names)相关文章:
【pyspark速成专家】11_Spark性能调优方法2
目录 编辑 二,Spark任务UI监控 三,Spark调优案例 二,Spark任务UI监控 Spark任务启动后,可以在浏览器中输入 http://localhost:4040/ 进入到spark web UI 监控界面。 该界面中可以从多个维度以直观的方式非常细粒度地查看Spa…...

吊顶的做法防踩坑,吊顶怎么省钱还好看
怎么做个好看的吊顶?你天天抬头看不? 现在楼房到手本身层高两米75左右,等铺完地暖和瓷砖还得增加几公分 如果再整个吊顶,就属于花钱买压抑了,吊顶就是遮丑, 某些比较显层高还亮堂,今天把做法分享出来 开发商给的毛坯两米8 做完地暖铺完瓷砖,层高是两米七八, 让木工在走廊两边…...
揭秘Tensor Core黑科技:如何让AI计算速度飞跃
揭秘 Tensor Core 底层:如何让AI计算速度飞跃 Tensor Core,加速深度学习计算的利器,专用于高效执行深度神经网络中的矩阵乘法和卷积运算,提升计算效率。 Tensor Core凭借混合精度计算与张量核心操作,大幅加速深度学习…...
为什么会有websocket(由来)
一、HTTP 协议的缺点和解决方案 1、HTTP 协议的缺点和解决方案 用户在使用淘宝、京东这样的网站的时候,每当点击一个按钮其实就是发送一个http请求。那我们先来回顾一下http请求的请求方式。 一个完整的http请求是被分为request请求节点和response响应阶段的&…...

【MySQL精通之路】优化
1 优化概述 数据库性能取决于数据库级别的几个因素,如表、查询和配置设置。这些软件结构导致了硬件级别的CPU和I/O操作,您必须将其最小化并使其尽可能高效。 在研究数据库性能时,首先要学习软件方面的高级规则和指导原则,并使用挂…...

解读大模型应用的可观测性
一、引言 随着人工智能技术的飞速发展,大模型作为AI领域的重要分支,正日益成为科技竞争的新高地。大模型通过输入大量语料进行训练,赋予计算机拥有像人类一样的“思考”能力,使其能够理解文本、图片、语音等内容,并进…...

嵌入式学习记录5.18(多点通信)
一、套接字属性设置相关函数 #include <sys/types.h> /* See NOTES */#include <sys/socket.h>int getsockopt(int sockfd, int level, int optname,void *optval, socklen_t *optlen);int setsockopt(int sockfd, int level, int optname,const void *op…...

shell脚本的基础应用
规范脚本的构成 #!/bin/bash # 注释信息 可执行的语句 执行脚本的方法 有1.添加x权限 ,绝对路经,或者相对路径2. 使用解释器 不需加x,root...bash...bash..echo 3,用source, 开机root ...bash ...echo bash -x /opt/test01.sh ÿ…...

【golang】内存对齐
什么是内存对齐 在访问特定类型变量的时候通常在特定的内存地址访问,这就需要对这些数据在内存中存放的位置有限制,各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。 内存对齐是编译器的管辖…...

Java 17的新特性有哪些?
Java 17是Java编程语言的最新版本,于2021年9月14日发布。以下是Java 17的一些新特性: Sealed类和接口:Sealed类和接口限制了继承和实现的范围,在编译时提供更强的封装性。 Pattern匹配:Pattern匹配简化了对实例进行类…...

攻击同学网络,让同学断网
技术介绍:ARP欺骗 ARP欺骗(ARP spoofing)是一种网络攻击技术,它通过伪造ARP(地址解析协议)响应包来欺骗目标设备,使其将网络流量发送到攻击者指定的位置。具体操作步骤如下: 攻击者…...
Springboot启动时报错Property ‘mapperLocations‘ was not specified.
这几天没整boot 晚上直接运行不了了 本想是在表现层写点代码测测接口的 localhost8080找半天 结果404 先考虑好久 是不是url输入错了 然后 就发现 结果boot都不能启动了 JUnit也测不出来 找了半天 结果是开关机导致数据库没开 手动打开服务 找到MySQL启动 IDEA连接数据…...

MyBatis系统学习篇 - 动态SQL
MyBatis提供了动态SQL帮助我们解决在业务过程中,我们根据不同的条件动态生成SQL语句,用来满足各种复杂的查询需求,包括MyBatis中常用的动态SQL标签和用法,这种方式在一定程度上帮助我们重复写许多SQL堆积在一起,下面我…...

[LLM-Agent]万字长文深度解析规划框架:HuggingGPT
HuggingGPT是一个结合了ChatGPT和Hugging Face平台上的各种专家模型,以解决复杂的AI任务,可以认为他是一种结合任务规划和工具调用两种Agent工作流的框架。它的工作流程主要分为以下几个步骤: 任务规划:使用ChatGPT分析用户的请求…...

二十三篇:未来数据库革新:AI与云原生的融合之旅
未来数据库革新:AI与云原生的融合之旅 1. 智能数据库管理:AI的魔法 在数字化时代,数据库技术作为信息管理的核心,正经历着前所未有的变革。AI(人工智能)和云原生技术的融合,正在重新定义数据库…...

彩光赋能中国智造 极简光3.X助力“数智”转型
蒸汽时代、电气时代、信息时代三大工业革命后 互联网和智能制造主导的工业4.0时代来临 大数据、云计算、人工智能等新兴技术 对企业园区的网络架构、负载能力等 提出了新要求,也使得光纤较于传统铜缆 在距离、性能、延时上的优势日益凸显 基于此 围绕未来园区网建设的企…...
985上交应届生转正12天,被某东辞退了!
👇我的小册 45章教程:(小白零基础用Python量化股票分析小册) ,原价299,限时特价2杯咖啡,满100人涨10元。 01.事情起源 最近粉丝群都在转发一个截图,某应届毕业生在某东实习一年,才转正才12天,就因为自己调侃…...
——快速排序算法)
Unity算法(一)——快速排序算法
文章目录 前言快速排序算法1、概念与实现2、优化 前言 算法是程序员的基础能力之一,资质越老的程序员在这方面理解会越深,很多时候项目在某个需要优化、提升的节点时,往往一些算法的使用就可以大大提升程序性能。当然,对于不同项…...

Leetcode 2028
思路:1-6之间的的n个数组合起来要变成sum_t mean*(rolls.size()n) - sum(rolls) ; 那么可以先假设每个数都是sum_t / n 其中这个数必须要在1 - 6 之间否者无法分配。 然后可以得出n * (sum_t / n ) < sum ; 需要对余数mod进行调整,为了减少调整的次…...
Angular(1):使用Angular CLI创建空项目
要创建一个空的 Angular 项目,可以使用 Angular CLI(命令行界面)。以下是使用 Angular CLI 创建一个新项目的步骤: 1、安装 Angular CLI: 打开你的命令行界面(在 Windows 上是 CMD、PowerShell 或 Git Bas…...

AI Agent将如何重构制造业的安全生产隐患识别模式?深度理解与实在Agent闭环实战
一、从“被动监控”到“主动进化”:2026年制造业安全隐患识别的范式迁移 站在2026年的时间节点回看,制造业的安全生产模式正经历着自工业4.0以来最深刻的变革。 传统的安全识别逻辑长期停留在“信号触发-人工干预”的被动阶段, 无论是基于阈值…...

精密运放ADA4091-2驱动能力不够?试试‘复合放大器’这招,带宽和带载能力都翻倍
精密运放驱动能力不足的终极解决方案:复合放大器架构深度解析 在精密信号链设计中,工程师们常常面临一个两难选择:要么选择ADA4091-2这类具有超低噪声和卓越直流性能的精密运放,但牺牲驱动能力;要么选用大电流运放&…...

嵌入式核心板选型指南:从单核到四核的精准配置与实战优化
1. 项目概述:从“固定套餐”到“自助餐”的嵌入式核心板选型变革最近在规划一个工业HMI项目,主控选型时又翻开了飞凌嵌入式的产品手册。看到AM62x系列核心板配置新增了单核、双核、四核的选项,第一反应是:这路子对了。在嵌入式开发…...

复旦微FM33FR0xx开发板实战:从零构建低功耗电容触摸应用
1. 项目概述:从一块开发板说起最近在捣鼓智能家居的小玩意儿,想找个带触摸功能又够省电的MCU,正好看到了复旦微电子新出的FM33FR0xx系列开发套件。这板子到手玩了一阵,感觉挺有意思,它不单单是块核心板,还配…...

HsMod终极指南:55项功能打造你的个性化炉石传说体验
HsMod终极指南:55项功能打造你的个性化炉石传说体验 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx框架开发的炉石传说多功能插件,为玩家提…...

从MSP430到MSPM0L1306:嵌入式工程迁移实战与SDK应用指南
1. 项目概述:从零理解MSPM0L1306的工程迁移最近在帮一个朋友处理一个老项目升级,核心需求是把一个基于TI老款MSP430系列MCU的温控器,迁移到TI新推出的MSPM0L1306这颗芯片上。朋友的原话是:“老芯片快买不到了,新出的MS…...

实验7全流程
## 实验七:微服务综合项目实战(零基础全流程)本实验基于 **Spring Boot 3.5.x** **Spring Cloud 2025.0.1** **RabbitMQ 4.2.3** **Redis 7.x**,带你从零搭建一个完整的电商下单系统: **用户请求 → Gateway网关 …...
)
JMeter 实战:JSON 响应中文节点 + 数值精准断言(附真实接口案例)
前言在接口自动化测试、性能测试过程中,JSON 断言是 JMeter 最常用的校验方式。日常开发中经常遇到JSON 键为中文、数组嵌套、浮点数金额校验等场景,很多同学会出现路径写错、数值匹配失败、中文节点解析异常等问题。本文以真实业务接口返回数据为例&…...

别让中文路径坑了你!FaceFusion在Windows和Mac上的完整环境配置与文件规范指南
别让中文路径坑了你!FaceFusion在Windows和Mac上的完整环境配置与文件规范指南 在数字创意领域,FaceFusion作为一款强大的AI换脸工具,正受到越来越多内容创作者的青睐。然而,许多用户在初次接触时往往会被一系列看似莫名其妙的错误…...

ARM嵌入式项目存储选型指南:从eMMC到SD卡,如何平衡性能、可靠性与成本
1. 项目概述:为什么存储选型是ARM嵌入式项目的“命门”?干了十几年嵌入式开发,从早期的ARM7、ARM9到现在的Cortex-A系列,经手的项目少说也有上百个。我发现一个很有意思的现象:很多工程师在选型时,CPU主频、…...