香橙派 AIpro 昇腾 Ascend C++ 分类模型适配
香橙派 AIpro 昇腾 Ascend C++ 分类模型适配
flyfish
文章目录
- 香橙派 AIpro 昇腾 Ascend C++ 分类模型适配
- 前言
- 一、PyTorch官网resnet模型处理方式
- 1、PyTorch模型 导出 onnx格式
- 2、完整测试 输出top1结果
- 3、完整测试 输出top5结果
- 二、YOLOv8官网resnet模型Python处理方式
- 三、昇腾resnet原始的C++预处理方式
- 四、香橙派 AIpro 分类模型 自带Python示例的预处理方式
- 五、对比不同
- 1、Normalize
- 2、CenterCrop
- 六、香橙派 AIpro 分类模型resnet C++ 适配
- 方式1 代码如下
- 方式2 代码如下
- 七、可以这样处理的原因
模型可以从多个地方获取,这里说明两个地方
从PyTorch官网获取到的resnet模型
从YOLOv8官网获取到的resnet模型
前言
模型的处理
查看香橙派 AIpro SoC版本

根据上面查看到SoC版本是 310B4,在转换模型时选择Ascend310B4

在硬件上可以加装一块固态盘,装上之后开机自动识别
一、PyTorch官网resnet模型处理方式
1、PyTorch模型 导出 onnx格式
从PyTorch官网获取到的resnet模型
# -*- coding: utf-8 -*-
import torch
import torchvision
import onnx
import onnxruntime
import torch.nn as nn
# 创建 PyTorch ResNet50 模型实例#在线下载
#model = torchvision.models.resnet50(pretrained=True)#本地加载
checkpoint_path ="/home/model/resnet50-19c8e357.pth"
model = torchvision.models.resnet50().to("cpu")
checkpoint = torch.load(checkpoint_path,map_location=torch.device('cpu'))model.load_state_dict(checkpoint)
model.eval()batch_size = 1
input_shape = (batch_size, 3, 224, 224)
input_data = torch.randn(input_shape)# 将模型转换为 ONNX 格式
output_path_static = "resnet_static.onnx"
output_path_dynamic = "resnet_dynamic.onnx"# dynamic
torch.onnx.export(model, input_data, output_path_dynamic,input_names=["input"], output_names=["output"],dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}})#static
torch.onnx.export(model, input_data, output_path_static,input_names=["input"], output_names=["output"])# 简单测试
session = onnxruntime.InferenceSession(output_path_dynamic)
new_batch_size = 2
new_input_shape = (new_batch_size, 3, 224, 224)
new_input_data = torch.randn(new_input_shape)
outputs = session.run(["output"], {"input": new_input_data.numpy()})
print(outputs)
2、完整测试 输出top1结果
# -*- coding: utf-8 -*-
import onnxruntime
import numpy as np
from torchvision import datasets, models, transforms
from PIL import Image
import torch.nn as nn
import torchdef postprocess(outputs):res = list()outputs_exp = np.exp(outputs)outputs = outputs_exp / np.sum(outputs_exp, axis=1)[:,None]predictions = np.argmax(outputs, axis = 1)for pred, output in zip(predictions, outputs):score = output[pred]res.append((pred.tolist(),float(score)))return resonnx_model_path = "/home/model/resnet50_static.onnx"ort_session = onnxruntime.InferenceSession(onnx_model_path)transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])image = Image.open("/home/dog1_1024_683.jpg")
image = transform(image).unsqueeze(0) # 增加批处理维度input_data = image.detach().numpy()outputs_np = ort_session.run(None, {'input': input_data})
outputs = outputs_np[0]res = postprocess(outputs)
print(res)
[(162, 0.9634788632392883)]
3、完整测试 输出top5结果
先把标签文件imagenet_classes.txt下载下来
curl -o imagenet_classes.txt https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt
# -*- coding: utf-8 -*-
import onnxruntime
import numpy as np
from torchvision import datasets, models, transforms
from PIL import Image
import torch.nn as nn
import torch
from onnx import numpy_helper
import timewith open("imagenet_classes.txt", "r") as f:categories = [s.strip() for s in f.readlines()]def softmax(x):e_x = np.exp(x - np.max(x))return e_x / e_x.sum()onnx_model_path = "/home/model/resnet50_static.onnx"ort_session = onnxruntime.InferenceSession(onnx_model_path)transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])image = Image.open("/home/dog1_1024_683.jpg")
image = transform(image).unsqueeze(0) # 增加批处理维度session = onnxruntime.InferenceSession(onnx_model_path, providers=['CPUExecutionProvider'])latency = []start = time.time()
input_arr = image.detach().numpy()output = session.run([], {'input':input_arr})[0]
latency.append(time.time() - start)
output = output.flatten()output = softmax(output)
top5_catid = np.argsort(-output)[:5]
for catid in top5_catid:print(catid, categories[catid], output[catid])print("ONNX Runtime CPU Inference time = {} ms".format(format(sum(latency) * 1000 / len(latency), '.2f')))
162 beagle 0.963479
167 English foxhound 0.020814817
166 Walker hound 0.011742038
161 basset 0.0024754668
164 bluetick 0.0004774033
ONNX Runtime CPU Inference time = 20.01 ms
预处理方式
在计算机视觉领域,很多预训练模型(例如ResNet、VGG等)都是基于ImageNet数据集训练的。因此,使用相同的均值和标准差对数据进行标准化处理,可以确保输入数据与预训练模型的输入分布一致,有助于充分利用预训练模型的优势。
transforms.Normalize函数通过减去均值并除以标准差,将输入图像的每个通道进行标准化处理。
ImageNet数据集的结构
训练集:包含超过120万张图像,用于训练模型。
验证集:包含50,000张图像,用于模型验证和调整超参数。
测试集:包含100,000张图像,用于评估模型的最终性能。
使用ImageNet数据集的注意事项
预处理:在使用ImageNet数据集进行训练时,通常需要对图像进行标准化处理,常用的均值和标准差为:
均值:0.485,0.456,0.406
标准差:0.229,0.224,0.225
数据增强:为了提升模型的泛化能力,通常会对训练图像进行数据增强处理,例如随机裁剪、水平翻转等
transforms.Resize 处理方式不同,有的地方是256,有的地方用的是224,
二、YOLOv8官网resnet模型Python处理方式
从YOLOv8官网获取到的resnet模型
YOLOv8由Ultralytics 提供,YOLOv8 支持全方位的视觉 AI 任务,包括检测、分割、姿态估计、跟踪和分类。
yolov8-cls-resnet50配置
# Parameters
nc: 1000 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]s: [0.33, 0.50, 1024]m: [0.67, 0.75, 1024]l: [1.00, 1.00, 1024]x: [1.00, 1.25, 1024]# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, ResNetLayer, [3, 64, 1, True, 1]] # 0-P1/2- [-1, 1, ResNetLayer, [64, 64, 1, False, 3]] # 1-P2/4- [-1, 1, ResNetLayer, [256, 128, 2, False, 4]] # 2-P3/8- [-1, 1, ResNetLayer, [512, 256, 2, False, 6]] # 3-P4/16- [-1, 1, ResNetLayer, [1024, 512, 2, False, 3]] # 4-P5/32# YOLOv8.0n head
head:- [-1, 1, Classify, [nc]] # Classify
该分类模型的预处理方式如下
IMAGENET_MEAN = 0.485, 0.456, 0.406 # RGB mean
IMAGENET_STD = 0.229, 0.224, 0.225 # RGB standard deviation
def classify_transforms(size=224,mean=DEFAULT_MEAN,std=DEFAULT_STD,interpolation=Image.BILINEAR,crop_fraction: float = DEFAULT_CROP_FRACTION,
):"""Classification transforms for evaluation/inference. Inspired by timm/data/transforms_factory.py.Args:size (int): image sizemean (tuple): mean values of RGB channelsstd (tuple): std values of RGB channelsinterpolation (T.InterpolationMode): interpolation mode. default is T.InterpolationMode.BILINEAR.crop_fraction (float): fraction of image to crop. default is 1.0.Returns:(T.Compose): torchvision transforms"""import torchvision.transforms as T # scope for faster 'import ultralytics'if isinstance(size, (tuple, list)):assert len(size) == 2scale_size = tuple(math.floor(x / crop_fraction) for x in size)else:scale_size = math.floor(size / crop_fraction)scale_size = (scale_size, scale_size)# Aspect ratio is preserved, crops center within image, no borders are added, image is lostif scale_size[0] == scale_size[1]:# Simple case, use torchvision built-in Resize with the shortest edge mode (scalar size arg)tfl = [T.Resize(scale_size[0], interpolation=interpolation)]else:# Resize the shortest edge to matching target dim for non-square targettfl = [T.Resize(scale_size)]tfl += [T.CenterCrop(size)]tfl += [T.ToTensor(),T.Normalize(mean=torch.tensor(mean),std=torch.tensor(std),),]return T.Compose(tfl)标准化数据分布:深度学习模型通常在训练过程中受益于输入数据的标准化,即将输入数据的分布调整为零均值和单位方差。这样可以确保所有特征具有相似的尺度,从而提高学习效率。对于图像数据而言,这意味着将像素值从原始范围(通常是0-255)转换到一个更统一的范围。
加速收敛:通过减去平均值并除以标准差,可以使梯度下降等优化算法在训练初期更快地收敛。这是因为这样的预处理减少了输入数据的方差,使得学习过程更加稳定和高效。
网络权重初始化的匹配:很多预训练模型(尤其是基于ImageNet训练的模型)在设计和训练时就假设了输入数据经过了这样的标准化处理。因此,在微调这些模型或使用它们作为特征提取器时,继续使用相同的预处理步骤能保证数据分布与模型预期的一致性,有助于保持模型性能。
泛化能力:ImageNet是一个大规模、多样化的图像数据集,其统计特性(如颜色分布)在很大程度上代表了自然图像的普遍特征。因此,使用ImageNet的统计量进行归一化有助于模型学习到更广泛适用的特征,增强模型在新数据上的泛化能力。
如果任务或数据集与ImageNet有显著不同,直接使用ImageNet的均值和标准差可能不是最佳选择。在这种情况下,根据自己数据集的统计特性来计算并使用均值和标准差进行归一化可能会得到更好的效果。
原始代码
三、昇腾resnet原始的C++预处理方式
namespace {const float min_chn_0 = 123.675;const float min_chn_1 = 116.28;const float min_chn_2 = 103.53;const float var_reci_chn_0 = 0.0171247538316637;const float var_reci_chn_1 = 0.0175070028011204;const float var_reci_chn_2 = 0.0174291938997821;
}Result SampleResnetQuickStart::ProcessInput(const string testImgPath)
{// read image from file by cvimagePath = testImgPath;srcImage = imread(testImgPath);Mat resizedImage;// zoom image to modelWidth_ * modelHeight_resize(srcImage, resizedImage, Size(modelWidth_, modelHeight_));// get properties of imageint32_t channel = resizedImage.channels();int32_t resizeHeight = resizedImage.rows;int32_t resizeWeight = resizedImage.cols;// data standardizationfloat meanRgb[3] = {min_chn_2, min_chn_1, min_chn_0};float stdRgb[3] = {var_reci_chn_2, var_reci_chn_1, var_reci_chn_0};// create malloc of image, which is shape with NCHWimageBytes = (float*)malloc(channel * resizeHeight * resizeWeight * sizeof(float));memset(imageBytes, 0, channel * resizeHeight * resizeWeight * sizeof(float));uint8_t bgrToRgb=2;// image to bytes with shape HWC to CHW, and switch channel BGR to RGBfor (int c = 0; c < channel; ++c){for (int h = 0; h < resizeHeight; ++h){for (int w = 0; w < resizeWeight; ++w){int dstIdx = (bgrToRgb - c) * resizeHeight * resizeWeight + h * resizeWeight + w;imageBytes[dstIdx] = static_cast<float>((resizedImage.at<cv::Vec3b>(h, w)[c] -1.0f*meanRgb[c]) * 1.0f*stdRgb[c] );}}}return SUCCESS;
}
四、香橙派 AIpro 分类模型 自带Python示例的预处理方式
img_origin = Image.open(pic_path).convert('RGB')
from torchvision import transforms
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
trans_list = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),normalize])
img = trans_list(img_origin)
运行
(base) HwHiAiUser@orangepiaipro:~/samples/model-adapter-models/cls/edge_infer$ ./run.sh
set env successfully!!
start exec atc
[Sample] init resource stage:
Init resource success
load model mobilenetv3_100_bs1.om
Init model resource
[Model] create model output dataset:
[Model] create model output dataset success
[Model] class Model init resource stage success
acl.mdl.execute exhaust 0:00:00.004750
class result : cat
pic name: cat
pre cost:7050.8ms
forward cost:6.8ms
post cost:0.0ms
total cost:7057.6ms
FPS:0.1
image name :./data/cat/cat.23.jpg, infer result: cat
acl.mdl.execute exhaust 0:00:00.004660
class result : cat
pic name: cat
pre cost:14.0ms
forward cost:5.2ms
post cost:0.0ms
total cost:19.2ms
FPS:52.2
image name :./data/cat/cat.76.jpg, infer result: cat
五、对比不同
经过比对有以下不同处
1、Normalize
Normalize 数值的不同,YOLOv8和PyTorch 是IMAGENET_MEAN 和 IMAGENET_STD
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
昇腾的是
namespace {const float min_chn_0 = 123.675;const float min_chn_1 = 116.28;const float min_chn_2 = 103.53;const float var_reci_chn_0 = 0.0171247538316637;const float var_reci_chn_1 = 0.0175070028011204;const float var_reci_chn_2 = 0.0174291938997821;
}
2、CenterCrop
YOLOv8和PyTorch都有 CenterCrop 中心剪裁处理
六、香橙派 AIpro 分类模型resnet C++ 适配
根据对比的结果所以我们只要处理IMAGENET_MEAN 和 IMAGENET_STD ,在加上CenterCrop 中心剪裁处理
所以我们可以增加centercrop_and_resize函数,然后在ProcessInput调用即可。
方式1 代码如下
static const float IMAGENET_MEAN[3] = { 0.485, 0.456, 0.406 };
static const float IMAGENET_STD[3] = { 0.229, 0.224, 0.225 };void centercrop_and_resize(const cv::Mat& src_img, cv::Mat& dst_img,int target_size)
{int height = src_img.rows;int width = src_img.cols;if(height >= width)// hw{cv::resize(src_img, dst_img, cv::Size(target_size,target_size * height / width), 0, 0, cv::INTER_AREA);}else{cv::resize(src_img, dst_img, cv::Size(target_size * width / height,target_size), 0, 0, cv::INTER_AREA);}height = dst_img.rows;width = dst_img.cols;cv::Point center(width/2, height/2);cv::Size size(target_size, target_size);cv::getRectSubPix(dst_img, size, center, dst_img);
}
Result SampleResnetQuickStart::ProcessInput(const string testImgPath)
{// read image from file by cvimagePath = testImgPath;srcImage = imread(testImgPath);cv::cvtColor(srcImage, srcImage, cv::COLOR_BGR2RGB);Mat resizedImage;centercrop_and_resize(srcImage,resizedImage,224);// get properties of imageint32_t channel = resizedImage.channels();int32_t resizeHeight = resizedImage.rows;int32_t resizeWeight = resizedImage.cols;std::vector<cv::Mat> rgbChannels(3);cv::split(resizedImage, rgbChannels);for (size_t i = 0; i < rgbChannels.size(); i++) // resizedImage = resizedImage / 255.0;{rgbChannels[i].convertTo(rgbChannels[i], CV_32FC1, 1.0 / ( 255.0* IMAGENET_STD[i]), (0.0 - IMAGENET_MEAN[i]) / IMAGENET_STD[i]);}int len = channel * resizeHeight * resizeWeight * sizeof(float);imageBytes = (float *)malloc(len);memset(imageBytes, 0, len);int index = 0;for (int c = 0; c <3; c++){ // R,G,Bfor (int h = 0; h < modelHeight_; ++h){for (int w = 0; w < modelWidth_; ++w){imageBytes[index] = rgbChannels[c].at<float>(h, w); // R->G->Bindex++;}}}return SUCCESS;
}
方式2 代码如下
CenterCrop类似如下的写法
char* centercrop_and_resize(cv::Mat& iImg, std::vector<int> iImgSize, cv::Mat& oImg)
{if (iImg.channels() == 3){oImg = iImg.clone();cv::cvtColor(oImg, oImg, cv::COLOR_BGR2RGB);}else{cv::cvtColor(iImg, oImg, cv::COLOR_GRAY2RGB);}int h = iImg.rows;int w = iImg.cols;int m = min(h, w);int top = (h - m) / 2;int left = (w - m) / 2;cv::resize(oImg(cv::Rect(left, top, m, m)), oImg, cv::Size(iImgSize.at(0), iImgSize.at(1)));return RET_OK;
}
使用方式
cv::Mat img = cv::imread(img_path);
std::vector<int> imgSize = { 640, 640 };
cv::Mat processedImg;
centercrop_and_resize(iImg, imgSize, processedImg);
processedImg就是我们要得到的cv::Mat 。图像经过centercrop,最后大小是640, 640,通道顺序是RGB
七、可以这样处理的原因
不同的Normalize数值之间的转换关系
# namespace {
# const float min_chn_0 = 123.675;
# const float min_chn_1 = 116.28;
# const float min_chn_2 = 103.53;
# const float var_reci_chn_0 = 0.0171247538316637;
# const float var_reci_chn_1 = 0.0175070028011204;
# const float var_reci_chn_2 = 0.0174291938997821;
# }import numpy as np
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])print(mean * 255)# [123.675 116.28 103.53 ]
print(1/(std*255))#[0.01712475 0.017507 0.01742919]
两者是可以相互转换的
# 0.485 × 255 = 123.675
# 0.456 × 255 = 116.28
# 0.406 × 255 = 103.53# 0.229 × 255 = 58.395
# 0.224 × 255 = 57.12
# 0.225 × 255 = 57.375# 1 ÷ 58.395 = 0.017124754
# 1 ÷ 57.12 = 0.017507003
# 1 ÷ 57.375 = 0.017429194
原始整个流程如下

适配后的处理就在上面第3步ProcessInput加上了 CenterCrop
链接地址
https://www.hiascend.com/zh/
https://gitee.com/ascend
华为原版的resnet图片分类,有C++版本和Python版本
https://gitee.com/ascend/samples/tree/master/inference/modelInference/sampleResnetQuickStart/
相关文章:
香橙派 AIpro 昇腾 Ascend C++ 分类模型适配
香橙派 AIpro 昇腾 Ascend C 分类模型适配 flyfish 文章目录 香橙派 AIpro 昇腾 Ascend C 分类模型适配前言一、PyTorch官网resnet模型处理方式1、PyTorch模型 导出 onnx格式2、完整测试 输出top1结果3、完整测试 输出top5结果 二、YOLOv8官网resnet模型Python处理方式三、昇腾…...
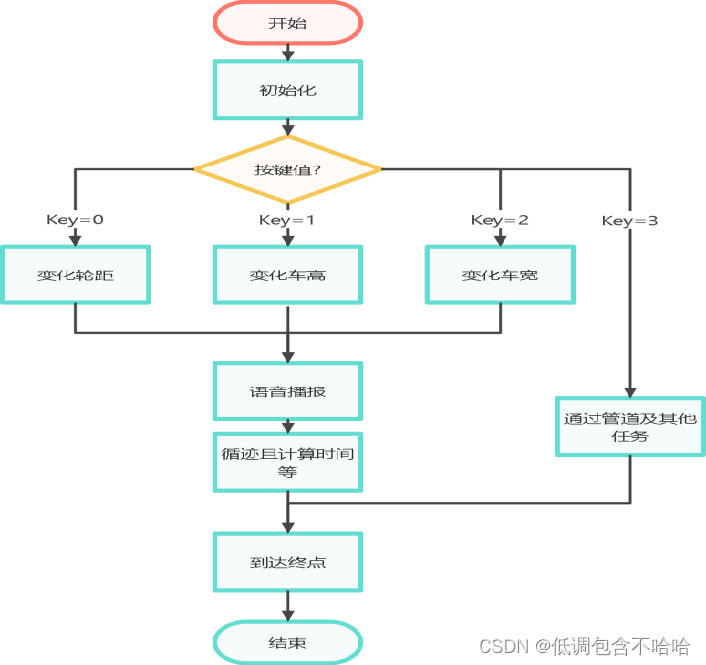
2024吉林省电赛(达盛杯)
1. 电赛F4系统板3D图 提起自制STM32F407VET6系统板 2. 电赛原理图 3. 电赛PCB图 4. 智能车实物图 下图是电赛的实物图,结构采用3D打印 5. 软件设计 下图是程序设计图 6. 仿真视频 (1) 变化高度 2024吉林省电赛仿真1 (2) 变化轮距 2024电赛仿真2 7. APP控制小车 …...

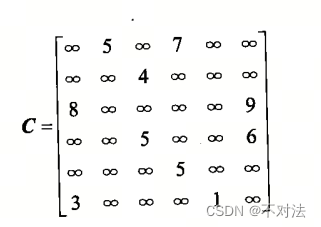
【算法题】520 钻石争霸赛 2024 全解析
都是自己写的代码,发现自己的问题是做题速度还是不够快 520-1 爱之恒久远 在 520 这个特殊的日子里,请你直接在屏幕上输出:Forever and always。 输入格式: 本题没有输入。 输出格式: 在一行中输出 Forever and always…...

Yii 结合MPDF 给PDF文件添加多行水印
首先确保安装了mpdf扩展 composer require mpdf/mpdf public function createWaterPdf($file_path,$water_text){date_default_timezone_set(PRC);ini_set(memory_limit, 6400M);ini_set(max_execution_time, 0);try{$mpdf new Mpdf();$pageCount $mpdf->SetSourceFile…...
你什么时候感觉学明白Java了?
学是学不明白Java的,要学明白Java,一定只能在工作以后。 1 在学习阶段,哪怕是借鉴别人的学习路线,其实依然会学很多不必要的技能,比如jsp,swing,或者多线程,或者设计模式。 2 或者…...

马斯克xAI融资60亿美元,宣布打造世界第一超算中心,10万张H100GPU
昨天,埃隆马斯克的xAI初创公司宣布获得60亿美元的巨额融资,主要用于打造一台巨大的超级计算机,马斯克称之为“超级计算工厂”。 从创立OpenAI到如今的xAI,技术和算力的发展历经了几个时代,但似乎马斯克的吸金能力一直…...

贪心算法[1]
首先用最最最经典的部分背包问题来引入贪心的思想。 由题意可知我们需要挑选出价值最大的物品放入背包,价值即单位价值。 我们需要计算出每一堆金币中单位价值。金币的属性涉及两个特征,重量和价值。 所以我们使用结构体。 上代码。 #include <i…...

卢文岩博士受邀参与中国科学院大学校友论坛 解码DPU核心价值
近日,第五届中国科学院大学校友创新论坛正式举行,本次论坛聚焦科技前沿领域,旨在搭建高端对话平台,促进产学研深度融合。在大算力时代——AI技术前沿沙龙上,中科驭数高级副总裁、CTO卢文岩博士受邀分享《DPU——连接算…...
2024年上半年软件设计师试题及答案(回忆版)
目录 基础知识选择题案例题1.缺陷识别的数据流图2.球队、球员、比赛记录的数据库题3.用户、老师、学生、课程用例图4.算法题5.程序设计题基础知识选择题 树的节点,度为4的有4个,度为3的有8个,度为2个有6个,度为1的有10个,问有几个叶子结点 二位数组,一个元素2个字节,A0…...

QGIS使用python代码导出给定坐标图片
代码基于https://blog.csdn.net/x572722344/article/details/108121230进行修改,代码在QGIS内部编译器运行 # -*- coding: utf-8 -*- from osgeo import ogr# 像素[高, 宽] px_geosize [2.645859085290482, 2.6458015267176016]# 待裁剪影像的坐标范围[min_x, min…...

看花眼,眼花缭乱的主食冻干到底应该怎么选?靠谱的主食冻干分享
随着科学养猫知识的普及,主食冻干喂养越来越受到养猫人的青睐。主食冻干不仅符合猫咪的饮食天性,还能提供均衡的营养,有助于维护猫咪的口腔和消化系统健康。许多猫主人认识到了主食冻干喂养的诸多益处,计划尝试这种喂养方式&#…...

开源VS闭源:谁更能推动AI技术的普及与发展?
一、引言 在人工智能(AI)技术的浪潮中,开源与闭源两种模式一直并存,并各自在推动AI技术普及与发展上发挥着重要作用。然而,关于哪种模式更能有效地推动AI技术的普及与发展,一直存在着激烈的讨论。本文将深…...

前端面试题日常练-day28 【面试题】
题目 希望这些选择题能够帮助您进行前端面试的准备,答案在文末。 1. 在Vue中,以下哪个选项用于监听组件生命周期钩子函数? a) watch b) computed c) lifecycle d) created 2. 在Vue中,以下哪个选项用于在列表渲染时为每个元素…...
好消息!DolphinScheduler官网集成LLM模型问答AI kapa.ai
不少小伙伴可能发现了,Apache DolphinScheduler官网最近默默上线了kapa.ai作为LLM的问答AI。 集成kapa.ai之后,社区用户可以点击Apache DolphinScheduler官网首页右下角的「Ask AI」模块,在接下来弹出的问答框输入自己的问题,即可…...
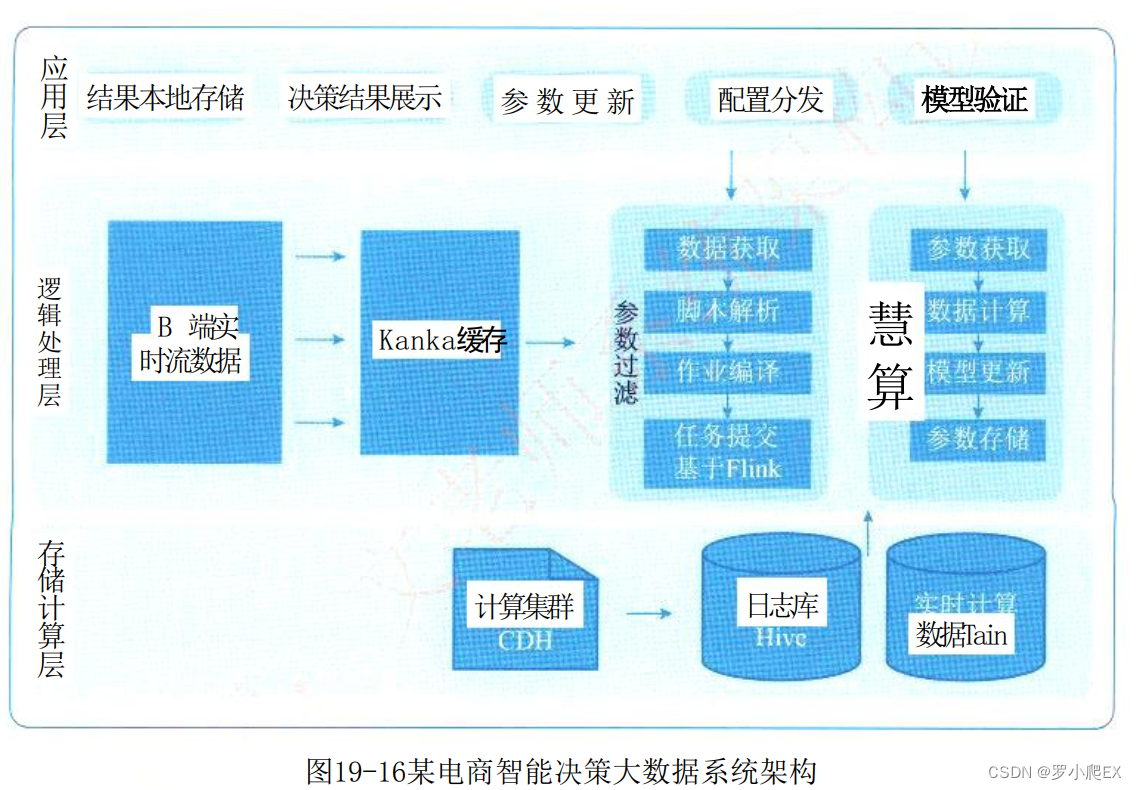
【软考】下篇 第19章 大数据架构设计理论与实践
目录 大数据处理系统架构特征Lambda架构Lambda架构介绍Lambda架构实现Lambda架构优缺点Lambda架构与其他架构模式对比 Kappa架构Kappa架构介绍Kappa架构实现Kappa架构优缺点 常见Kappa架构变形(Kappa、混合分析系统)Kappa架构混合分析系统的Kappa架构 La…...
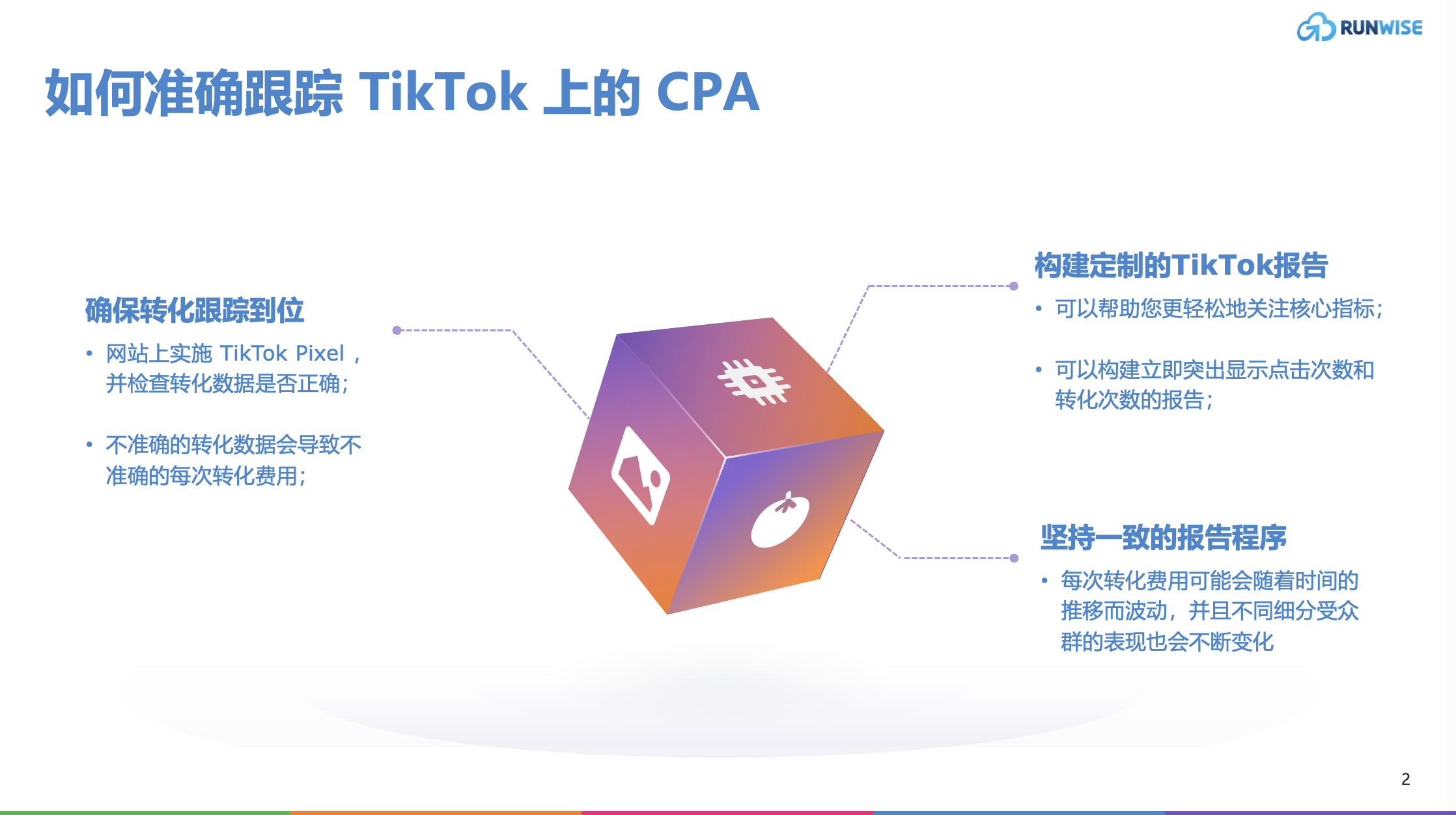
创新指南|降低 TikTok CPA 的 9 项专家策略
企业在 TikTok 上投放广告,往往最想确保获得最佳的投资回报。然而,这往往说起来容易做起来难。您需要了解如何利用不同的营销工具、定位策略和创意执行来实现您的业务目标并提高成本效率。本文将分享 9 个行之有效的策略,助您有效降低 TikTok…...
jmeter服务器性能监控分析工具ServerAgent教程
ServerAgent介绍:支持监控CPU,memory,磁盘,网络等,和JMeter集成,在JMeter的图形界面中,可以实时看到监控的数据,但是,它只能监控硬件资源使用情况。 不能监控应用服务 S…...
工作纪实50-Idea下载项目乱码
下载了公司的一份项目代码,发现是gbk格式的,但是我的日常习惯又是utf-8,下载项目以后全是乱码,一脸懵 借用网友的一张图,如果是一个一个文件这么搞,真的是费劲,好几百个文件! 步骤…...

37. 解数独 - 力扣(LeetCode)
基础知识要求: Java: 方法、for循环、if else语句、数组 Python: 方法、for循环、if else语句、列表 题目: 编写一个程序,通过填充空格来解决数独问题。 数独的解法需 遵循如下规则: 数字 1-9 在每一行…...

使用uniapp编写的微信小程序进行分包
简介: 由于小程序发布的时候每个包最多只能放置2MB的东西,所以把所有的代码资源都放置在一个主包当中不显示,所以就需要进行合理分包,,但是分包后整个小程序最终不能超过20MB。 一般情况下,我习惯将tabba…...

dialoqbase入门指南:如何在5分钟内创建你的第一个AI聊天机器人
dialoqbase入门指南:如何在5分钟内创建你的第一个AI聊天机器人 【免费下载链接】dialoqbase Create chatbots with ease 项目地址: https://gitcode.com/gh_mirrors/di/dialoqbase dialoqbase是一款强大的开源工具,让你能够轻松创建AI聊天机器人。…...

5分钟快速上手Vue3思维导图:打造专业级数据可视化应用
5分钟快速上手Vue3思维导图:打造专业级数据可视化应用 【免费下载链接】vue3-mindmap Mindmap component for Vue3 项目地址: https://gitcode.com/gh_mirrors/vu/vue3-mindmap Vue3-Mindmap是一个基于Vue 3和TypeScript构建的现代化思维导图组件,…...

AI行业的“人才缺口”:哪些AI岗位最紧缺
一、AI行业人才缺口的整体态势在AI技术飞速发展的当下,其对各行业的渗透速度远超预期,人才供需矛盾愈发凸显。据《人工智能产业人才发展报告(2025~2026)》测算,中国AI人才总缺口超过580万人,其中核心技术岗位缺口超过80万人。人力…...

从 API 调用到工具链:梳理 AI 介入测试流程的 5 个成熟度等级
2026年,AI正在以前所未有的速度重构软件测试行业。但“AI测试”并非一个开关——从简单调用ChatGPT生成几条用例,到构建完整的Agent自愈测试体系,中间存在一条清晰的能力进化路径。本文将这条路径梳理为5个成熟度等级,结合2026年最新工具、开源项目与行业数据,帮你准确评估…...

Sunshine终极指南:8步搭建你的个人游戏串流服务器
Sunshine终极指南:8步搭建你的个人游戏串流服务器 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上流畅玩PC游戏吗?Sunshine是一款免费开源…...

DLSS Swapper:免费开源的游戏性能优化终极解决方案
DLSS Swapper:免费开源的游戏性能优化终极解决方案 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为PC游戏玩家设计的免费开源工具,它能够智能管理、下载和替换游戏中的DL…...

ViGEmBus虚拟游戏控制器驱动:从零开始掌握Windows手柄模拟技术
ViGEmBus虚拟游戏控制器驱动:从零开始掌握Windows手柄模拟技术 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想在Windows电脑上使用任意手柄玩…...

空洞骑士模组管理革命:Scarab如何让复杂变简单?
空洞骑士模组管理革命:Scarab如何让复杂变简单? 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为空洞骑士模组安装而头疼吗?每次手动…...

大语言模型推理引擎优化:架构挑战与关键技术解析
1. 大语言模型推理引擎的架构挑战与优化方向1.1 Transformer架构的固有瓶颈Transformer架构的自注意力机制存在两大核心瓶颈:计算复杂度和内存占用。对于序列长度N,自注意力层的计算复杂度为O(N),这使得长文本处理成为性能黑洞。以2048 token…...

Keil MDK-ARM许可证错误-25的解决方案
1. 问题现象与背景解析最近在升级Keil MDK-ARM到新版本后,不少开发者遇到了一个棘手的许可证错误。当尝试编译项目时,系统会弹出如下错误提示:Error: A9555E: License checkout for feature mdk_xxx_compiler5 with version 5.0201411 has be…...