大模型中的Tokenizer
在使用GPT 、BERT模型输入词语常常会先进行tokenize 。
tokenize的目标是把输入的文本流,切分成一个个子串,每个子串相对有完整的语义,便于学习embedding表达和后续模型的使用。
一、粒度
三种粒度:word/subword/char
- word词,是最自然的语言单元。对于英文等自然语言来说,存在着天然的分隔符,比如说空格,或者是一些标点符号,对词的切分相对容易。但是对于一些东亚文字包括中文来说,就需要某种分词算法才行。顺便说一下,Tokenizers库中,基于规则切分部分,采用了spaCy和Moses两个库。如果基于词来做词汇表,由于长尾现象的存在,这个词汇表可能会超大。像Transformer XL库就用到了一个26.7万个单词的词汇表。这需要极大的embedding matrix才能存得下。embedding matrix是用于查找取用token的embedding vector的。这对于内存或者显存都是极大的挑战。常规的词汇表,一般大小不超过5万。
- char/字符, 也就是说,我们的词汇表里只有最基本的字符。而一般来讲,字符的数量是少量有限的。这样做的问题是,由于字符数量太小,我们在为每个字符学习嵌入向量的时候,每个向量就容纳了太多的语义在内,学习起来非常困难。
- subword子词级,它介于字符和单词之间。比如说Transformers可能会被分成Transform和ers两个部分。这个方案平衡了词汇量和语义独立性,是相对较优的方案。它的处理原则是,常用词应该保持原状,生僻词应该拆分成子词以共享token压缩空间
二、 不同tokenize的策略比较
1、word-level
这些分词的方法都是将句子拆分为词,即word-level,这么做的优缺点是:
优点:能够保存较为完整的语义信息
缺点:
1、词汇表会非常大,大的词汇表对应模型需要使用很大的embedding层,这既增加了内存,又增加了时间复杂度。
2、 word-level级别的分词略显粗糙,无法发现更加细节的语义信息,例如模型学到的“old”, “older”, and “oldest”之间的关系无法泛化到“smart”, “smarter”, and “smartest”。
3、word-level级别的分词对于拼写错误等情况的鲁棒性不好;
4、 oov问题不好解决
2、char-level
一个简单的方法就是将word-level的分词方法改成 char-level的分词方法,对于英文来说,就是字母界别的,比如 "China"拆分为"C","h","i","n","a",对于中文来说,"中国"拆分为"中","国",
优点:
1、这可以大大降低embedding部分计算的内存和时间复杂度,以英文为例,英文字母总共就26个,中文常用字也就几千个。
2、char-level的文本中蕴含了一些word-level的文本所难以描述的模式,因此一方面出现了可以学习到char-level特征的词向量FastText,另一方面在有监督任务中开始通过浅层CNN、HIghwayNet、RNN等网络引入char-level文本的表示;
缺点:
1、但是这样使得任务的难度大大增加了,毕竟使用字符大大扭曲了词的意义,一个字母或者一个单中文字实际上并没有任何语义意义,单纯使用char-level往往伴随着模型性能的下降;
2、增加了输入的计算压力,原本”I love you“是3个embedding进入后面的cnn、rnn之类的网络结构,而进行char-level拆分之后则变成 8个embedding进入后面的cnn或者rnn之类的网络结构,这样计算起来非常慢;
3、subword-level
subword-level的分词方式遵循的原则是:尽量不分解常用词,而是将不常用词分解为常用的子词,
例如,"annoyingly"可能被认为是一个罕见的单词,并且可以分解为"annoying"和"ly"。"annoying"并"ly"作为独立的子词会更频繁地出现,同时,"annoyingly"是由"annoying"和"ly"这两个子词的复合含义构成的复杂含义,这在诸如土耳其语之类的凝集性语言中特别有用,在该语言中,可以通过将子词串在一起来形成(几乎)任意长的复杂词。
subword-level的分词方式使模型相对合理的词汇量(不会太多也不会太少),同时能够学习有意义的与上下文无关的表示形式(另外,subword-level的分词方式通过将模型分解成已知的子词,使模型能够处理以前从未见过的词(oov问题得到了很大程度上的缓解)。
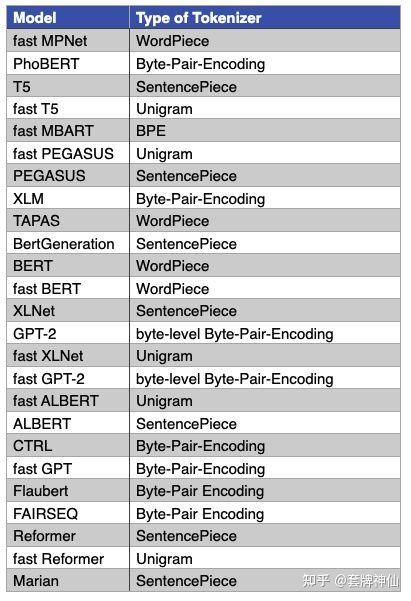
三. 常用tokenize算法
最常用的三种tokenize算法:BPE(Byte-Pair Encoding),WordPiece和SentencePiece
3.1 Byte-Pair Encoding (BPE) / Byte-level BPE
BPE
- 首先,它依赖于一种预分词器pretokenizer来完成初步的切分。pretokenizer可以是简单基于空格的,也可以是基于规则的;
- 分词之后,统计每个词出现的频次供后续计算使用。例如,我们统计到了5个词的词频
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
- 建立基础词汇表,包括所有的字符,即:
["b", "g", "h", "n", "p", "s", "u"]
- 根据规则,我们分别考察2-gram,3-gram的基本字符组合,把高频的ngram组合依次加入到词汇表当中,直到词汇表达到预定大小停止。比如,我们计算出ug/un/hug三种组合出现频次分别为20,16和15,加入到词汇表中。
- 最终词汇表的大小 = 基础字符词汇表大小 + 合并串的数量,比如像GPT,它的词汇表大小 40478 = 478(基础字符) + 40000(merges)。添加完后,我们词汇表变成:
["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
实际使用中,如果遇到未知字符用<unk>代表。
以语料:
{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}为例,假设我们对原始的文本进行分词之后只有上面4个词,则:
1、对每个词进行词频统计,并且对每个词末尾的字符转化为 末尾字符和</w>两个字符,停止符"</w>"的意义在于表示subword是词后缀。举例来说:"st"字词不加"</w>"可以出现在词首如"st ar",加了"</w>"表明改字词位于词尾,如"wide st</w>",二者意义截然不同。
{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}此时我们的词表为
{"l","o",'w',"e","r","</w>","n","s","t","i"}
2、统计每一个连续字节对的出现频率,选择最高频者合并成新的subword
{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w es t </w>': 6, 'w i d es t </w>': 3}最高频连续字节对"e"和"s"出现了6+3=9次,合并成"es"
需要注意的是,"es"生成后会消除"s",因为上述语料中 "s"总和"es"共同出现,但是s除了"es"外就没有其它的字符组合出现了,所以"s"被消除,但是"e"在"lower"中出现过有"er"或"we"这样的组合,所以"e"没有被消除,此时词表变化为:
{"l","o",'w',"e","r","</w>","n","es","t","i"}
(补充另外两种情况:
如果es中的e和s都是和es一起出现,除此之外没有单独再出现其它的字符组合,则es一起消除;如果es中的e和s都各自有和其它字符的组合,则e和s都不会被消除,但是多了个新词es)
3、继续上述过程:
{'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w est </w>': 6, 'w i d est </w>': 3}此时最高频连续字节对"es"和"t"出现了6+3=9次, 合并成"est"。输出:
同理,上一步的词表中"t"被消除,"est"加入此表
......
继续迭代直到达到人工预设的subword词表大小或下一个最高频的字节对出现频率为1。
上述就完成了编码过程,得到了词表,然后要把原始的word-level的分词结果进行相应转化:
1、将此表按照其中token的长度,从长到短排列;
例如排序好之后的词表为:
[“errrr</w>”, “tain</w>”, “moun”, “est</w>”, “high”, “the</w>”, “a</w>”]2、对原始的word-level的分词结果进行转化,例如原始的语料为:
[“the</w>”, “highest</w>”, “mountain</w>”]则转化为:
"the</w>" -> ["the</w>"]
"highest</w>" -> ["high", "est</w>"]
"mountain</w>" -> ["moun", "tain</w>"]这样就完成了BPE的分词了;
Byte-level BPE
BPE的一个问题是,如果遇到了unicode,基本字符集可能会很大。一种处理方法是我们以一个字节为一种“字符”,不管实际字符集用了几个字节来表示一个字符。这样的话,基础字符集的大小就锁定在了256。
例如,像GPT-2的词汇表大小为50257 = 256 + <EOS> + 50000 mergers,<EOS>是句子结尾的特殊标记。
3.2 WordPiece
WordPiece,从名字好理解,它是一种子词粒度的tokenize算法subword tokenization algorithm,很多著名的Transformers模型,比如BERT/DistilBERT/Electra都使用了它。
它的原理非常接近BPE,不同之处在于,它在做合并的时候,并不是每次找最高频的组合,而是找能够最大化训练集数据似然的merge,即它每次合并的两个字符串A和B,应该具有最大的 P(AB)P(A)P(B) 值。合并AB之后,所有原来切成A+B两个tokens的就只保留AB一个token,整个训练集上最大似然变化量与 P(AB)P(A)P(B) 成正比。
3.3 Unigram
与BPE或者WordPiece不同,Unigram的算法思想是从一个巨大的词汇表出发,再逐渐删除trim down其中的词汇,直到size满足预定义。
初始的词汇表可以采用所有预分词器分出来的词,再加上所有高频的子串。
每次从词汇表中删除词汇的原则是使预定义的损失最小。训练时,计算loss的公式为:
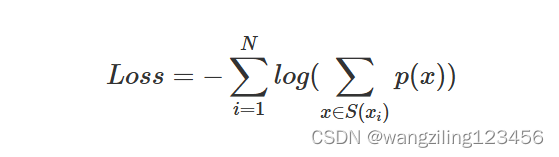
假设训练文档中的所有词分别为 x1;x2...xN ,而每个词tokenize的方法是一个集合 S(xi) 。当一个词汇表确定时,每个词tokenize的方法集合 S(xi) 就是确定的,而每种方法对应着一个概率p(x)。如果从词汇表中删除部分词,则某些词的tokenize的种类集合就会变少,log(*)中的求和项就会减少,从而增加整体loss。
Unigram算法每次会从词汇表中挑出使得loss增长最小的10%~20%的词汇来删除。
一般Unigram算法会与SentencePiece算法连用。
3.4 SentencePiece
SentencePiece,它是把一个句子看作一个整体,再拆成片段,而没有保留天然的词语的概念。一般地,它把空格space也当作一种特殊字符来处理,再用BPE或者Unigram算法来构造词汇表。
比如,XLNetTokenizer就采用了_来代替空格,解码的时候会再用空格替换回来。
目前,Tokenizers库中,所有使用了SentencePiece的都是与Unigram算法联合使用的,比如ALBERT、XLNet、Marian和T5.
四、切分实例
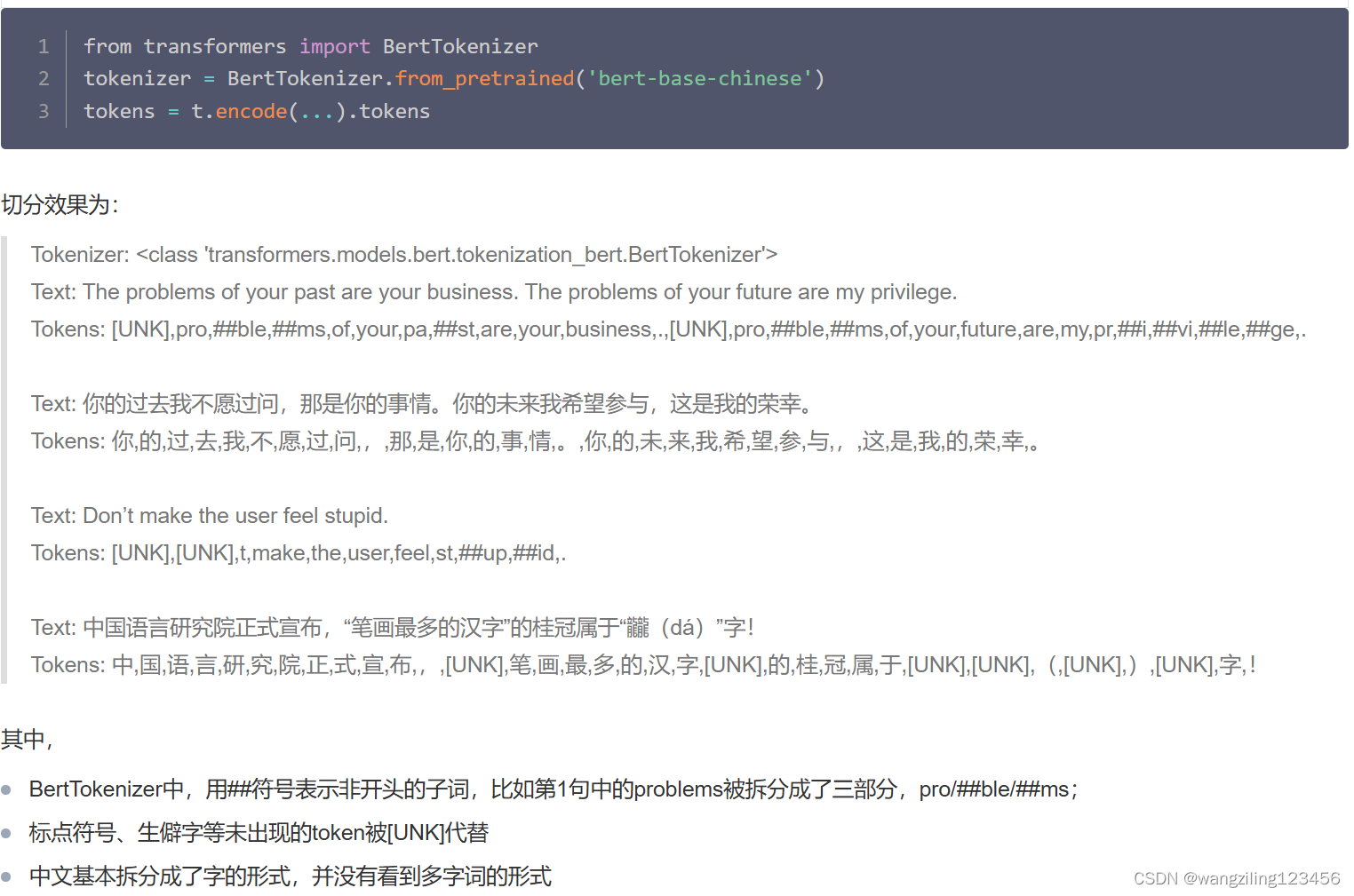
4.1 BertTokenizer / WordPiece
4.2 T5Tokenizer / SentencePiece

参考文章
NLP BERT GPT等模型中 tokenizer 类别说明详解-腾讯云开发者社区-腾讯云 (tencent.com)
tokenizers小结 - 知乎 (zhihu.com)
相关文章:
大模型中的Tokenizer
在使用GPT 、BERT模型输入词语常常会先进行tokenize 。 tokenize的目标是把输入的文本流,切分成一个个子串,每个子串相对有完整的语义,便于学习embedding表达和后续模型的使用。 一、粒度 三种粒度:word/subword/char word词&a…...

Filebeat进阶指南:核心架构与功能组件的深度剖析
🐇明明跟你说过:个人主页 🏅个人专栏:《洞察之眼:ELK监控与可视化》🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是ELK 2、FileBeat在ELK中的角色 二、Fil…...

深度神经网络
深度神经网络(Deep Neural Networks,DNNs)是机器学习领域中的一项关键技术,它基于人工神经网络的概念,通过构建多层结构来模拟人脑的学习过程。以下是关于深度神经网络的清晰回答: 一、定义与特点 深度神…...

c++【入门】你多大了
时间限制 : 1 秒 内存限制 : 128 MB 一天玩仔跑来问周周你多大了,周周告诉他自己 1010 岁了,玩仔又说自己也是,你听到了这个对话,想用程序显示出两个人的对话内容,现在就来试一试吧。 输入 无 输出 输出三行&…...

地质考察AR远程交互展示系统辅助老师日常授课
广东这片充满活力的土地,孕育了一家引领ARVR科技潮流的杰出企业——深圳华锐视点,作为一家专注于VR/AR技术研究与业务开发的先锋公司。多年来,我们不断突破技术壁垒,将AR增强现实技术与各行各业的实际需求完美结合,助力…...

容器是什么
什么是容器? 容器技术近年来在软件开发和部署中变得越来越重要,尤其是在云计算和微服务架构中。本文将详细介绍什么是容器、其工作原理、优势以及常见的容器技术。 容器的定义 容器是一种轻量级、可移植的虚拟化技术,它允许在一个主机操作…...

一分钟学习数据安全——数字身份的三种模式
微软首席身份架构师金卡梅隆曾说:互联网的构建缺少一个身份层。互联网的构建方式让你无法得知所连接的人和物是什么。这限制了我们对互联网的使用,并让我们面临越来越多的危险。如果我们坐视不管,将面临迅速激增的盗窃和欺诈事件,…...

WPF实现搜索文本高亮
WPF实现搜索文本高亮 1、使用自定义的TextBlock public class HighlightTextblock : TextBlock{public string DefaultText { get; set; }public string HiText{get { return (string)GetValue(HiTextProperty); }set { SetValue(HiTextProperty, value); }}// Using a Depend…...
)
Vue小程序项目知识积累(三)
1.CSS中的var( ) var() 函数用于插入自定义属性(也称为CSS变量)的值。 var(--main-bg-color,20rpx) 设置一个CSS变量的值,但是如果 --main-bg-color 变量不存在,它将默认返回 20rpx。 CSS变量必须在一个有效的CSS规则…...
)
React Native 之 像素比例(十七)
在 React Native 中,PixelRatio 是一个用于获取设备像素比(Pixel Ratio)的实用工具。像素比(或称为设备像素密度、DPI 密度等)是物理像素和设备独立像素(DIPs 或 DPs)之间的比率。设备独立像素是…...

Leetcode 112:路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。 说明: 叶子节点是指没有子节点的节点。 思路:遍历存储每条路径。当前节点为叶子节点时,求和。并判断是否等于目标…...

电源模块测试系统怎么测试输入电压范围?
在现代电子设备中,电源模块的性能直接影响着整个系统的稳定性和效率。其中,电源输入电压范围是指电源能够接受的输入电压的最小值和最大值,它是确保电源正常工作的重要参数。为了提高测试效率和精度,自动化的测试方法逐渐取代了传…...
实战指南:Vue 2基座 + Vue 3 + Vite + TypeScript微前端架构实现动态菜单与登录共享
实战指南:Vue 2基座 Vue 3 Vite TypeScript子应用vue2微前端架构实现动态菜单与登录共享 导读: 在当今的前端开发中,微前端架构已经成为了一种流行的架构模式。本文将介绍如何结合Vue 2基座、Vue 3子应用、Vite构建工具和TypeScript语言…...
)
Java面试进阶指南:高级知识点问答精粹(一)
Java 面试问题及答案 1. 什么是Java中的集合框架?它包含哪些主要接口? 答案: Java集合框架是一个设计用来存储和操作大量数据的统一的架构。它提供了一套标准的接口和类,使得我们可以以一种统一的方式来处理数据集合。集合框架主…...

儿童礼物笔记
文章目录 女孩礼物毛绒玩具音乐水晶系列水彩笔 男孩礼物益智类玩具积木类泡沫类机动玩具类 小孩过生日或儿童节,选礼物想破脑袋,做个笔记吧。 如果自家的小孩,还好说些,送亲友就需要动动脑筋。 女孩礼物 毛绒玩具 不错的选择&a…...

LeetCode215数组中第K个最大元素
题目描述 给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。 解析 快速排序的思想ÿ…...

LeetCode //C - 143. Reorder List
143. Reorder List You are given the head of a singly linked-list. The list can be represented as: L0 → L1 → … → Ln - 1 → Ln Reorder the list to be on the following form: L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → … You may not modify the values i…...

速盾:cdn如何解析?
CDN是内容分发网络(Content Delivery Network)的缩写,它是一种通过在全球范围内分布节点服务器来提供高性能、高可用性的网络服务的技术。CDN的主要功能是通过将内容分发到离用户更近的服务器节点,从而加速用户对网站、应用程序、…...
K8s集群调度续章
目录 一、污点(Taint) 1、污点(Taint) 2、污点组成格式 3、当前taint effect支持如下三个选项: 4、查看node节点上的污点 5、设置污点 6、清除污点 7、示例一 查看pod状态,模拟驱逐node02上的pod …...
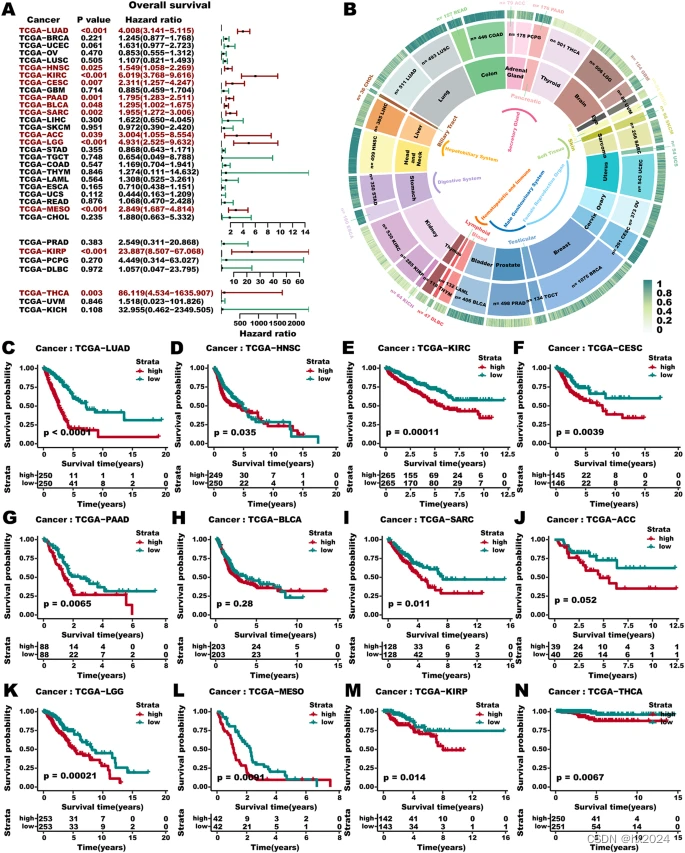
大工作量LUAD代谢重编程模型多组学(J Transl Med)
目录 1,单细胞早期、晚期和转移性 LUAD 的细胞动力学变化 2,细胞代谢重编程介导的LUAD驱动恶性转移的异质性 3,模型构建 S-MMR评分管线构建 4,S-MMR 模型的预后评估 5, 还开发了S-MMR 评分网络工具 6,…...

实用指南:3分钟在Windows中解锁iPhone HEIC照片缩略图预览
实用指南:3分钟在Windows中解锁iPhone HEIC照片缩略图预览 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 还在为iPh…...

OpenPLC Editor:零成本开启工业自动化编程的完整解决方案
OpenPLC Editor:零成本开启工业自动化编程的完整解决方案 【免费下载链接】OpenPLC_Editor 项目地址: https://gitcode.com/gh_mirrors/ope/OpenPLC_Editor 在工业自动化领域,PLC编程一直被视为专业工程师的专属技能,高昂的商业软件许…...

如何快速掌握League-Toolkit:英雄联盟玩家的终极辅助工具指南
如何快速掌握League-Toolkit:英雄联盟玩家的终极辅助工具指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League-Toolkit是一款…...

别再乱用sudo了!麒麟KYLINOS下用ACL实现安全的精细化权限控制
麒麟KYLINOS权限管理革命:用ACL替代sudo的精细化控制实战 在麒麟KYLINOS操作系统中,许多管理员习惯性地使用sudo或简单粗暴的chmod 777来解决权限问题,这种"一刀切"的做法实际上为系统安全埋下了重大隐患。想象一下这样的场景&…...

终极指南:HS2-HF_Patch汉化补丁完全免费使用手册
终极指南:HS2-HF_Patch汉化补丁完全免费使用手册 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的日文界面而烦恼吗ÿ…...
)
为什么你的Perplexity总搜不到知网核心期刊?97.6%用户忽略的3个元数据过滤阈值(附知网后台原始字段对照表)
更多请点击: https://intelliparadigm.com 第一章:Perplexity知网文献搜索失效的底层归因 Perplexity.ai 作为一款基于大模型的实时网络问答工具,其核心能力依赖于对公开网页内容的动态抓取与语义解析。然而当用户尝试通过 Perplexity 查询中…...

GoogleTest 使用指南 | 测试模板函数
GoogleTest 使用指南 | 测试模板函数GoogleTest 使用指南 | 测试模板函数GoogleTest 使用指南 | 测试模板函数 模板类和函数由于其泛型特性,需要在不同类型下进行测试,以确保其通用性和正确性。 下面是一个示例。 m…...
)
告别环境配置烦恼:用PHPStudy+VSCode搭建PHP调试环境(含XDebug配置避坑指南)
告别环境配置烦恼:用PHPStudyVSCode搭建PHP调试环境(含XDebug配置避坑指南) 刚接触PHP开发时,最令人头疼的莫过于环境配置。明明跟着教程一步步操作,却总是卡在某个环节无法继续。特别是XDebug调试器的配置,…...

Windows Cleaner终极指南:开源免费解决C盘爆满问题的高效方案
Windows Cleaner终极指南:开源免费解决C盘爆满问题的高效方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款基于Python和PyQt…...

Seraphine:你的英雄联盟智能助手,3步实现高效战绩查询与游戏辅助
Seraphine:你的英雄联盟智能助手,3步实现高效战绩查询与游戏辅助 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 还在为英雄联盟对局中信息不足而困扰吗?想要在BP阶段就占据…...