SQOOP详细讲解
SQOOP安装及使用
SQOOP安装及使用SQOOP安装1、上传并解压2、修改文件夹名字3、修改配置文件4、修改环境变量5、添加MySQL连接驱动6、测试准备MySQL数据登录MySQL数据库创建student数据库切换数据库并导入数据另外一种导入数据的方式使用Navicat运行SQL文件导出MySQL数据库importMySQLToHDFS编写脚本,保存为MySQLToHDFS.conf执行脚本注意事项:MySQLToHive编写脚本,并保存为MySQLToHive.conf文件执行脚本--direct--e参数的使用MySQLToHBase编写脚本,并保存为MySQLToHBase.conf在HBase中创建student表执行脚本exportHDFSToMySQL编写脚本,并保存为HDFSToMySQL.conf先清空MySQL student表中的数据,不然会造成主键冲突执行脚本查看sqoop helpSqoop 在从HDFS中导出到关系型数据库时的一些问题问题一:问题二:问题三:**增量同步数据总结
SQOOP安装
1、上传并解压
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /usr/local/soft/
2、修改文件夹名字
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop-1.4.6
3、修改配置文件
# 切换到sqoop配置文件目录 cd /usr/local/soft/sqoop-1.4.6/conf # 复制配置文件并重命名 cp sqoop-env-template.sh sqoop-env.sh # vim sqoop-env.sh 编辑配置文件,并加入以下内容 export HADOOP_COMMON_HOME=/usr/local/soft/hadoop-2.7.6 export HADOOP_MAPRED_HOME=/usr/local/soft/hadoop-2.7.6/share/hadoop/mapreduce export HBASE_HOME=/usr/local/soft/hbase-1.4.6 export HIVE_HOME=/usr/local/soft/hive-1.2.1 export ZOOCFGDIR=/usr/local/soft/zookeeper-3.4.6/conf export ZOOKEEPER_HOME=/usr/local/soft/zookeeper-3.4.6 # 切换到bin目录 cd /usr/local/soft/sqoop-1.4.6/bin # vim configure-sqoop 修改配置文件,注释掉没用的内容(就是为了去掉警告信息)

4、修改环境变量
vim /etc/profile # 将sqoop的目录加入环境变量
5、添加MySQL连接驱动
# 从HIVE中复制MySQL连接驱动到$SQOOP_HOME/lib cp /usr/local/soft/hive-1.2.1/lib/mysql-connector-java-5.1.49.jar /usr/local/soft/sqoop-1.4.6/lib/
6、测试
# 打印sqoop版本 sqoop version

# 测试MySQL连通性 sqoop list-databases -connect jdbc:mysql://master:3306/ -username root -password 123456
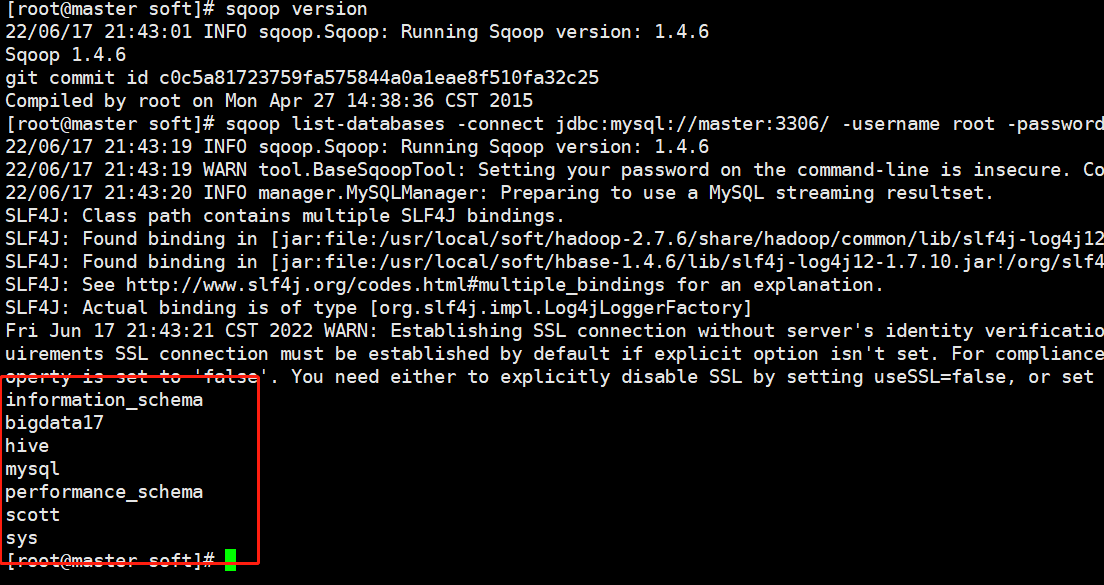
准备MySQL数据
登录MySQL数据库
mysql -u root -p123456;
创建student数据库
create database studentdb;
切换数据库并导入数据
# mysql shell中执行 use studentdb; source /usr/local/soft/bigdata29/student.sql; source /usr/local/soft/bigdata29/score.sql;
另外一种导入数据的方式
# linux shell中执行 mysql -uroot -p123456 studentdb < /usr/local/soft/shujia/student.sql mysql -uroot -p123456 studentdb < /usr/local/soft/shujia/score.sql
使用Navicat运行SQL文件
也可以通过Navicat导入
导出MySQL数据库
mysqldump -u root -p123456 数据库名>任意一个文件名.sql
import
从传统的关系型数据库导入HDFS、HIVE、HBASE......
MySQLToHDFS
编写脚本,保存为MySQLToHDFS.conf
sqoop执行脚本有两种方式:第一种方式:直接在命令行窗口中直接输入脚本;第二种方式是将命令封装成一个脚本文件,然后使用另一个命令执行 第一种方式: sqoop import \ --append \ --connect jdbc:mysql://master:3306/studentdb \ --username root \ --password 123456 \ --table student \ --m 1 \ --split-by id \ --target-dir /bigdata29/sqoopdata/student1/ \ --fields-terminated-by '\t' 第二种方式:使用脚本文件的形式 mysql2hdfs.conf import --append --connect jdbc:mysql://master:3306/studentdb --username root --password 123456 --table student --m 1 --split-by id --target-dir /bigdata29/sqoopdata/student2/ --fields-terminated-by ','
执行脚本
sqoop --options-file MySQLToHDFS.conf
注意事项:
1、--m 表示指定生成多少个Map任务,不是越多越好,因为MySQL Server的承载能力有限
2、当指定的Map任务数>1,那么需要结合--split-by参数,指定分割键,以确定每个map任务到底读取哪一部分数据,最好指定数值型的列,最好指定主键(或者分布均匀的列=>避免每个map任务处理的数据量差别过大)
3、如果指定的分割键数据分布不均,可能导致数据倾斜问题
4、分割的键最好指定数值型的,而且字段的类型为int、bigint这样的数值型
5、编写脚本的时候,注意:例如:--username参数,参数值不能和参数名同一行
--username root // 错误的 // 应该分成两行 --username root
6、运行的时候会报错InterruptedException,hadoop2.7.6自带的问题,忽略即可
21/01/25 14:32:32 WARN hdfs.DFSClient: Caught exception java.lang.InterruptedExceptionat java.lang.Object.wait(Native Method)at java.lang.Thread.join(Thread.java:1252)at java.lang.Thread.join(Thread.java:1326)at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:716)at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.endBlock(DFSOutputStream.java:476)at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:652)
7、实际上sqoop在读取mysql数据的时候,用的是JDBC的方式,所以当数据量大的时候,效率不是很高
8、sqoop底层通过MapReduce完成数据导入导出,只需要Map任务,不许需要Reduce任务 part-m-00000
9、每个Map任务会生成一个文件
MySQLToHive
先会将MySQL的数据导出来并在HDFS上找个目录临时存放,默认为:/user/用户名/表名
然后再将数据加载到Hive中,加载完成后,会将临时存放的目录删除
编写脚本,并保存为MySQLToHive.conf文件
import --connect jdbc:mysql://master:3306/studentdb?useUnicode=true&characterEncoding=UTF-8&useSSL=false --username root --password 123456 --table student --m 1 --hive-import --hive-overwrite --hive-database bigdata29 --create-hive-table --hive-table sqoop_students1 --fields-terminated-by ','
执行脚本
sqoop --options-file MySQLToHive.conf
--direct
加上这个参数,可以在导出MySQL数据的时候,使用MySQL提供的导出工具mysqldump,加快导出速度,提高效率
需要将master上的/usr/bin/mysqldump分发至 node1、node2的/usr/bin目录下
scp /usr/bin/mysqldump node1:/usr/bin/ scp /usr/bin/mysqldump node2:/usr/bin/
--e参数的使用
sqoop在导入数据时,可以使用--e搭配sql来指定查询条件,并且还需在sql中添加$CONDITIONS,来实现并行运行mr的功能。
只要有--e+sql,就需要加$CONDITIONS,哪怕只有一个maptask。
sqoop通过继承hadoop的并行性来执行高效的数据传输。 为了帮助sqoop将查询拆分为多个可以并行传输的块,需要在查询的where子句中包含$conditions占位符。 sqoop将自动用生成的条件替换这个占位符,这些条件指定每个任务应该传输哪个数据片。
# 需求:将学号1500100007学生从mysql查出来导入到hive中 select * from student where id=1500100007 import --connect jdbc:mysql://master:3306/studentdb?useUnicode=true&characterEncoding=UTF-8&useSSL=false --username root --password 123456 --query "select * from score where id=1500100007 and $CONDITIONS" --target-dir /shujia/history/score1 --m 1 --hive-import --hive-overwrite --hive-database bigdata29 --create-hive-table --hive-table sqoop_score1 --fields-terminated-by ',' --direct
MySQLToHBase
编写脚本,并保存为MySQLToHBase.conf
sqoop1.4.6 只支持 HBase1.0.1 之前的版本的自动创建 HBase 表的功能
import --connect jdbc:mysql://master:3306/studentdb?useUnicode=true&characterEncoding=UTF-8&useSSL=false --username root --password 123456 --query "select * from student where id<1500100003 and $CONDITIONS" --target-dir /shujia/history/hbase_student --m 1 --hbase-create-table --hbase-table mysql2hbase1 --column-family info --hbase-row-key id --direct
在HBase中创建student表
create 'studentsq','cf1'
执行脚本
sqoop --options-file MySQLToHBase.conf
export
HDFSToMySQL
编写脚本,并保存为HDFSToMySQL.conf
在往关系型数据库中导出的时候我们要先在关系型数据库中创建好库以及表,这些sqoop不会帮我们完成。
export --export-dir /bigdata29/teachers/ --columns id,name,grade,clazz --fields-terminated-by ',' --connect jdbc:mysql://master:3306/studentdb?useUnicode=true&characterEncoding=UTF-8&useSSL=false --username root --password 123456 --table sqoop_teacher --num-mappers 1
先清空MySQL student表中的数据,不然会造成主键冲突
执行脚本
sqoop --options-file HDFSToMySQL.conf
查看sqoop help
sqoop help 21/04/26 15:50:36 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 usage: sqoop COMMAND [ARGS] Available commands:codegen Generate code to interact with database recordscreate-hive-table Import a table definition into Hiveeval Evaluate a SQL statement and display the resultsexport Export an HDFS directory to a database tablehelp List available commandsimport Import a table from a database to HDFSimport-all-tables Import tables from a database to HDFSimport-mainframe Import datasets from a mainframe server to HDFSjob Work with saved jobslist-databases List available databases on a serverlist-tables List available tables in a databasemerge Merge results of incremental importsmetastore Run a standalone Sqoop metastoreversion Display version information See 'sqoop help COMMAND' for information on a specific command.
# 查看import的详细帮助 sqoop import --help
1、并行度不能太高,就是 -m 2、如果没有主键的时候,-m 不是1的时候就要指定分割字段,不然会报错,如果有主键的时候,-m 不是1 可以不去指定分割字段,默认是主键,不指定 -m 的时候,Sqoop会默认是分4个map任务。
export --export-dir /user/hive/warehouse/bigdata29.db/t_movie1/ --columns id,name,types --fields-terminated-by ',' --connect jdbc:mysql://master:3306/bigdata29?useUnicode=true&characterEncoding=UTF-8&useSSL=false --username root --password 123456 --table sqoop_movie --num-mappers 1 --direct
Sqoop 在从HDFS中导出到关系型数据库时的一些问题
问题一:
在上传过程中遇到这种问题:
ERROR tool.ExportTool: Encountered IOException running export job: java.io.IOException: No columns to generate for ClassWriter
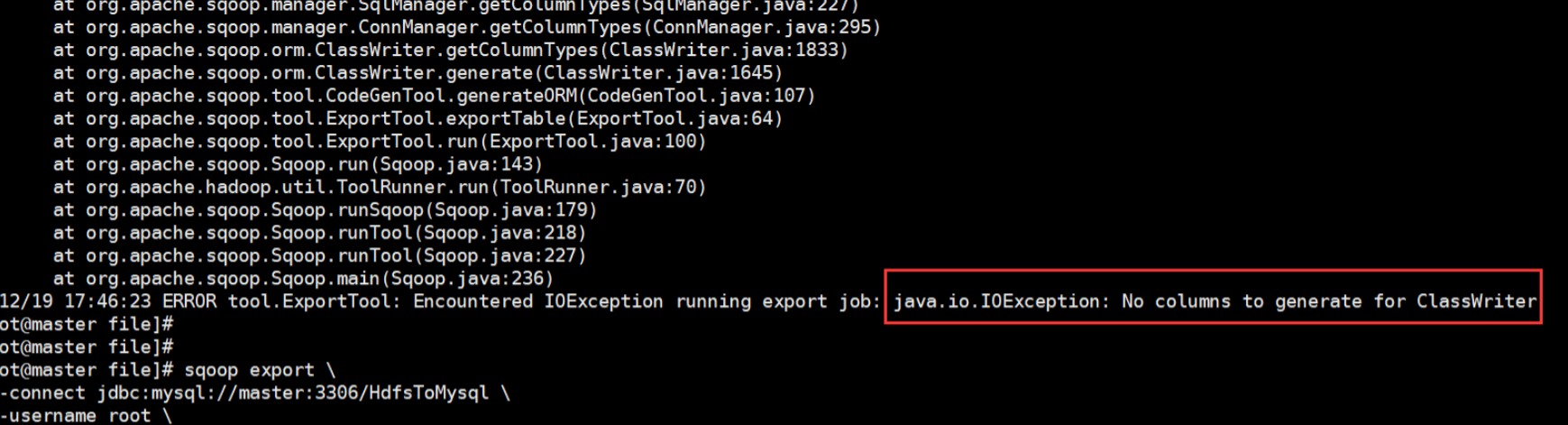
驱动版本的过低导致的,其实在尝试这个方法的时候我们可以先进行这样:加一行命令,--driver com.mysql.jdbc.Driver \ 然后问题解决!!! 如果添加命令之后还没有解决就把jar包换成高点版本的。
问题二:
依旧是导出的时候,会报错,但是我们很神奇的发现,也有部分数据导入了。这也就是下一个问题。
Caused by: java.lang.NumberFormatException: For input string: "null"
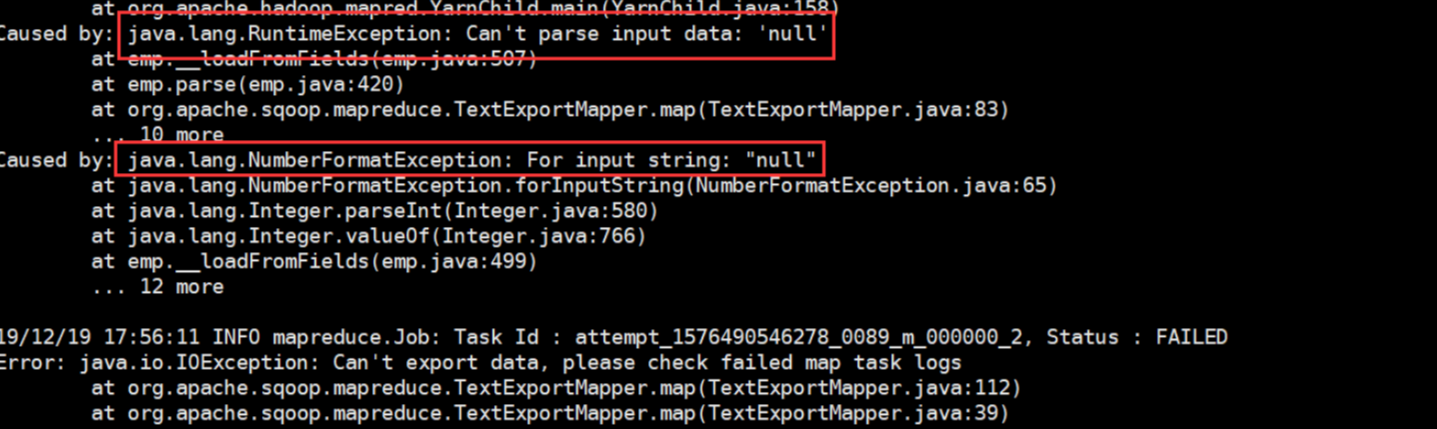
解决方式:因为数据有存在null值得导致的 在命令中加入一行(方式一中的修改方式,方式二也就是转换一下格式):--input-null-string '\\N' \ --input-null-string '\\N'
问题三:**
java.lang.RuntimeException: Can't parse input data: '1998/5/11'
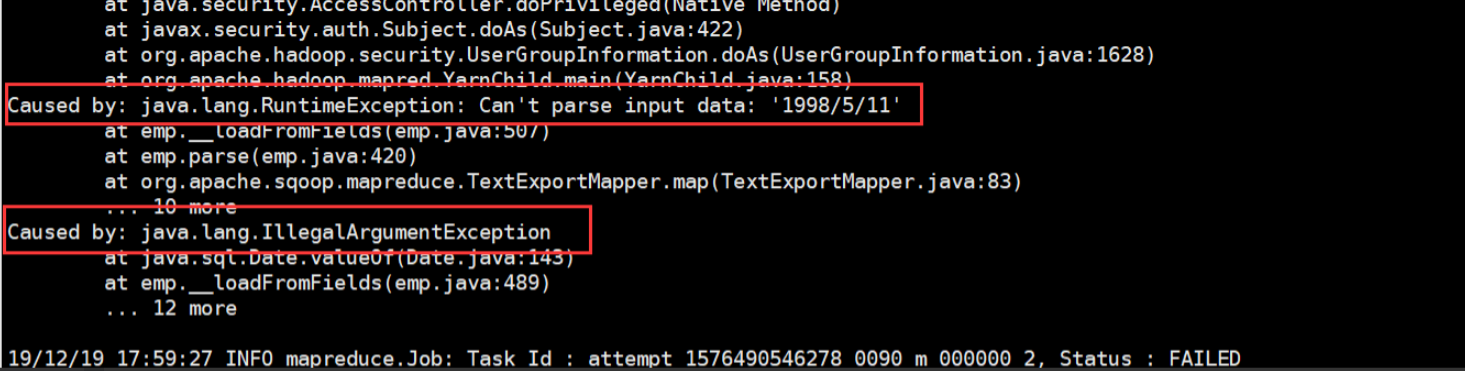
出现像这样的问题,大多是因为HDFS上的数据与关系型数据库创建表的字段类型不匹配导致的。仔细对比修改后,就不会有这个报错啦!!
增量同步数据
我们之前导入的都是全量导入,一次性全部导入,但是实际开发并不是这样,例如web端进行用户注册,mysql就增加了一条数据,但是HDFS中的数据并没有进行更新,但是又再全部导入一次又完全没有必要。
所以,sqoop提供了增量导入的方法。
1、数据准备:
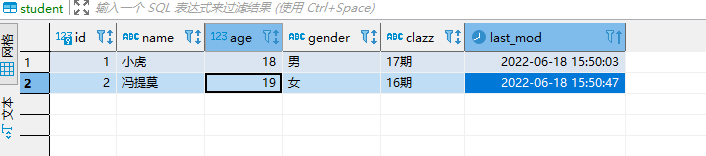
CREATE TABLE sqoop_stu2( id int, name STRING, age int, gender STRING, clazz STRING, last_mod TIMESTAMP )row format delimited fields terminated by ','
2、将其先用全量导入到HDFS(hive)中去
3、先在mysql中添加一条数据,在使用命令进行追加
4、根据时间进行大量追加(不去重)
#前面的案例中,hive本身的数据也是存储在HDFS上的,所以我今后要做增量操作的时候,需要指定HDFS上的路径 import --connect jdbc:mysql://master:3306/student --username root --password 123456 --table student --target-dir /user/hive/warehouse/testsqoop.db/from_mysql_student --fields-terminated-by '\t' --incremental append --check-column id --last-value 3
结果:但是我们发现有两个重复的字段

5、往往开发中需要进行去重操作:sqoop提供了一个方法进行去重,内部是先开一个map任务将数据导入进来,然后再开一个map任务根据指定的字段进行合并去重
结果:

之前有重复的也进行合并去重操作,最后生成一个结果。
总结:
–check-column 用来指定一些列,这些列在增量导入时用来检查这些数据是否作为增量数据进行导入,和关系型数据库中的自增字段及时间戳类似. 注意:这些被指定的列的类型不能使任意字符类型,如char、varchar等类型都是不可以的,同时–check-column可以去指定多个列 –incremental 用来指定增量导入的模式,两种模式分别为Append和Lastmodified –last-value 指定上一次导入中检查列指定字段最大值
总结
RDBMS-->HDFS import HDFS--->RDBMS export Mysql--->HDFS(hive) 要知道你要数据的来源和数据的目的地 mysql: --connect jdbc:mysql://master:3306/student --username root --password 123456 --table student hdfs: --target-dir /user/hive/warehouse/sqooptest.db/from_mysql_student --fields-terminated-by '\t' hive: 1) --hive-import --hive-overwrite --create-hive-table (如果表不存在,自动创建,如果存在,报错,就不需要这个参数) --hive-database testsqoop --hive-table from_mysql_student --fields-terminated-by '\t' 2) --target-dir /user/hive/warehouse/bigdata29.db/sqoop_stu2 --fields-terminated-by ',' # 增量需要添加的参数================================================= --incremental append --check-column id --last-value 3 (或者是)------------------------------------------------------------ --fields-terminated-by '\t' --check-column (hive的列名) last_mod --incremental lastmodified --last-value "2022-06-18 16:40:09" --m 1 ======================================================================== # 如果需要去重,请先搞清楚根据什么去重,否则结果可能不是你想要的 --merge-key name (这里是根据姓名去重,你可以改成自己的去重列名) # 经过实践得出,如果要追加导入到hive中并且要进行去重的话,建议最好使用lastmodified以时间戳的方式追加,以写入hdfs的路径方式追加,这样可以实现追加的同时并且去重。 hbase:(如果hbase导入要创建表的话,需要将--hbase-create-table参数放到hbase参数的第一个才会生效) --hbase-create-table --hbase-table studentsq --column-family cf1 --hbase-row-key id (mysql中的列名) --m 1 HDFS--->mysql hdfs: --columns id,name,age,gender,clazz --export-dir /shujia/bigdata17/sqoopinput/ --fields-terminated-by ',' # 如果数据分割出来的字段值有空值,需要添加以下参数(面试可能会面到) --null-string '\\N' --null-non-string '\\N'
相关文章:
SQOOP详细讲解
SQOOP安装及使用 SQOOP安装及使用SQOOP安装1、上传并解压2、修改文件夹名字3、修改配置文件4、修改环境变量5、添加MySQL连接驱动6、测试准备MySQL数据登录MySQL数据库创建student数据库切换数据库并导入数据另外一种导入数据的方式使用Navicat运行SQL文件导出MySQL数据库impo…...

【Unity入门】认识Unity编辑器
Unity 是一个广泛应用于游戏开发的强大引擎,从 1.0 版本开始到现在,其编辑器的基本框架一直保持稳定。其基于组件架构的设计,使得界面使用起来直观且高效。为了更好地理解 Unity 的界面,我们可以将其比喻为搭建一个舞台。以下是对…...

Spring控制重复请求
通过AOP拦截所有请求,控制在规定时间内请求次数。 1:添加maven <dependency><groupId>net.jodah</groupId><artifactId>expiringmap</artifactId><version>0.5.10</version> </dependency> 2&#x…...
)
AWS安全性身份和合规性之Key Management Service(KMS)
AWS Key Management Service(KMS)是一项用于创建和管理加密密钥的托管服务,可帮助客户保护其数据的安全性和机密性。 比如一家医疗保健公司需要在AWS上存储敏感的病人健康数据,需要对数据进行加密以确保数据的机密性。他们使用AW…...

esp32 固件备份 固件恢复
首先是固件备份,这个在产品的工程管理中还是相当重要的。由于工具链的更新(工具版本),以及板子或其上物料的变更(硬件版本),或者新的库的导入或原有库的删除,PCBA是分分钟有可能死给…...
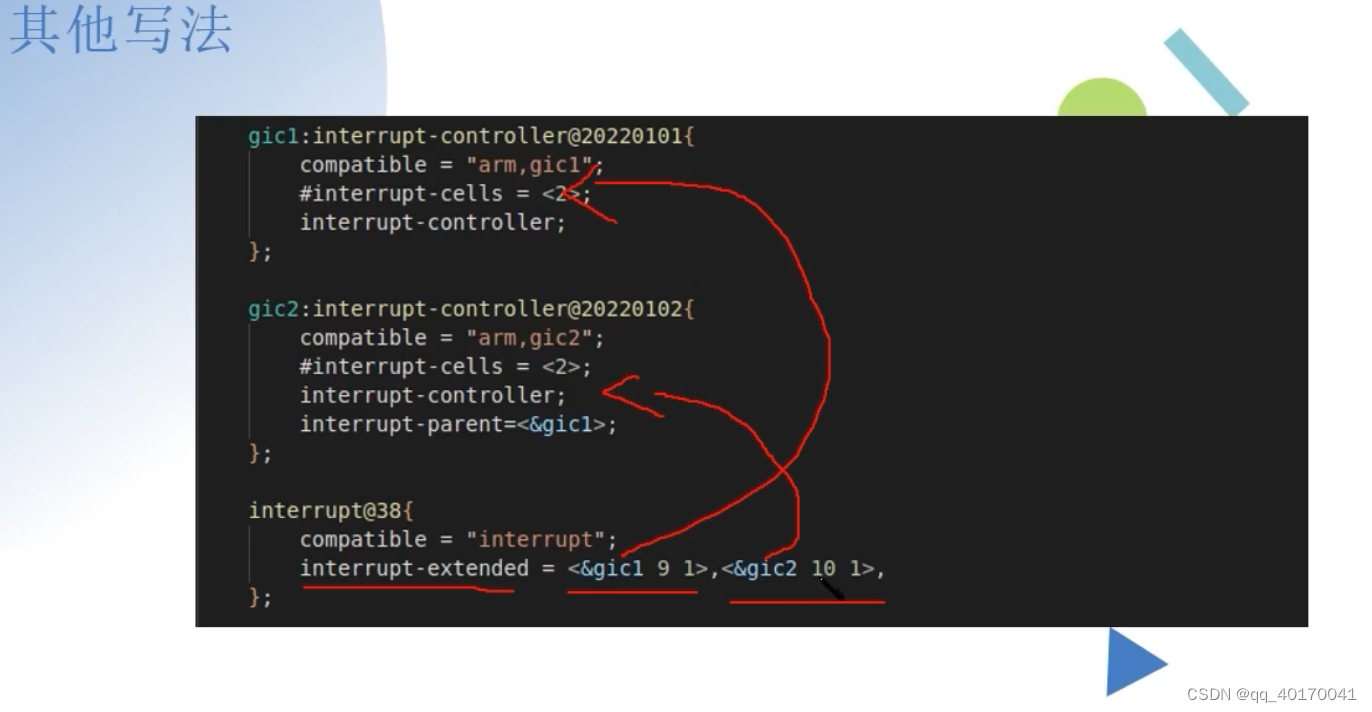
linux开发之设备树四、设备树中断节点
中断节点 这里是由原厂的BSP工程师写的一部分 在CPU的外部有一个GIC控制器,外设会连接在GIC控制器上 设备树是对硬件进行描述的,所以设备树会对CPU进行描述,也要对GIC 控制器进行描述,这部分的代码由原厂的BSP工程师进行编写&…...
基于STM32实现智能楼宇对讲系统
目录 引言环境准备智能楼宇对讲系统基础代码示例:实现智能楼宇对讲系统 音频输入和输出按键控制显示屏和用户界面网络通信应用场景:楼宇安防与智能家居问题解决方案与优化收尾与总结 1. 引言 本教程将详细介绍如何在STM32嵌入式系统中使用C语言实现智能…...
】)
面试专区|【DevOps-46道DevOps高频题整理(附答案背诵版)】
简述什么是 DevOps工作流程 ? DevOps工作流程是一种将开发和运维团队紧密结合起来的方法,旨在实现软件开发和交付的高效性和可靠性。它强调自动化和持续集成,以便频繁地进行软件交付和部署。 DevOps工作流程通常包括以下阶段: …...

算法基础之台阶-Nim游戏
台阶-Nim游戏 核心思想:博弈论 可以看作第i阶台阶上有i个含有i个石子的堆这样所有台阶上一共n!个堆就变成了经典Nim优化:发现偶数阶台阶上2n堆异或 0 , 奇数阶台阶异或 原本石子数量 因此 当遍历到奇数阶时异或一下就行 #include <iostream>…...

VUE3注册指令的方法
指令注册只能全局指令和选项式页面指令,composition api没有页面指令 选项式页面指令 <template><div class"home"><h3>自定义指令</h3><div class"from"><el-input type"text" v-focus v-model"name&q…...

【Python】 Python 字典查询:‘has_key()‘ 方法与 ‘in‘ 关键字的比较
基本原理 在 Python 中,字典(dict)是一种非常常用的数据结构,用于存储键值对。字典的查询操作是编程中常见的任务之一。在 Python 2.x 版本中,has_key() 方法被用来检查字典中是否存在某个键。然而,在 Pyt…...
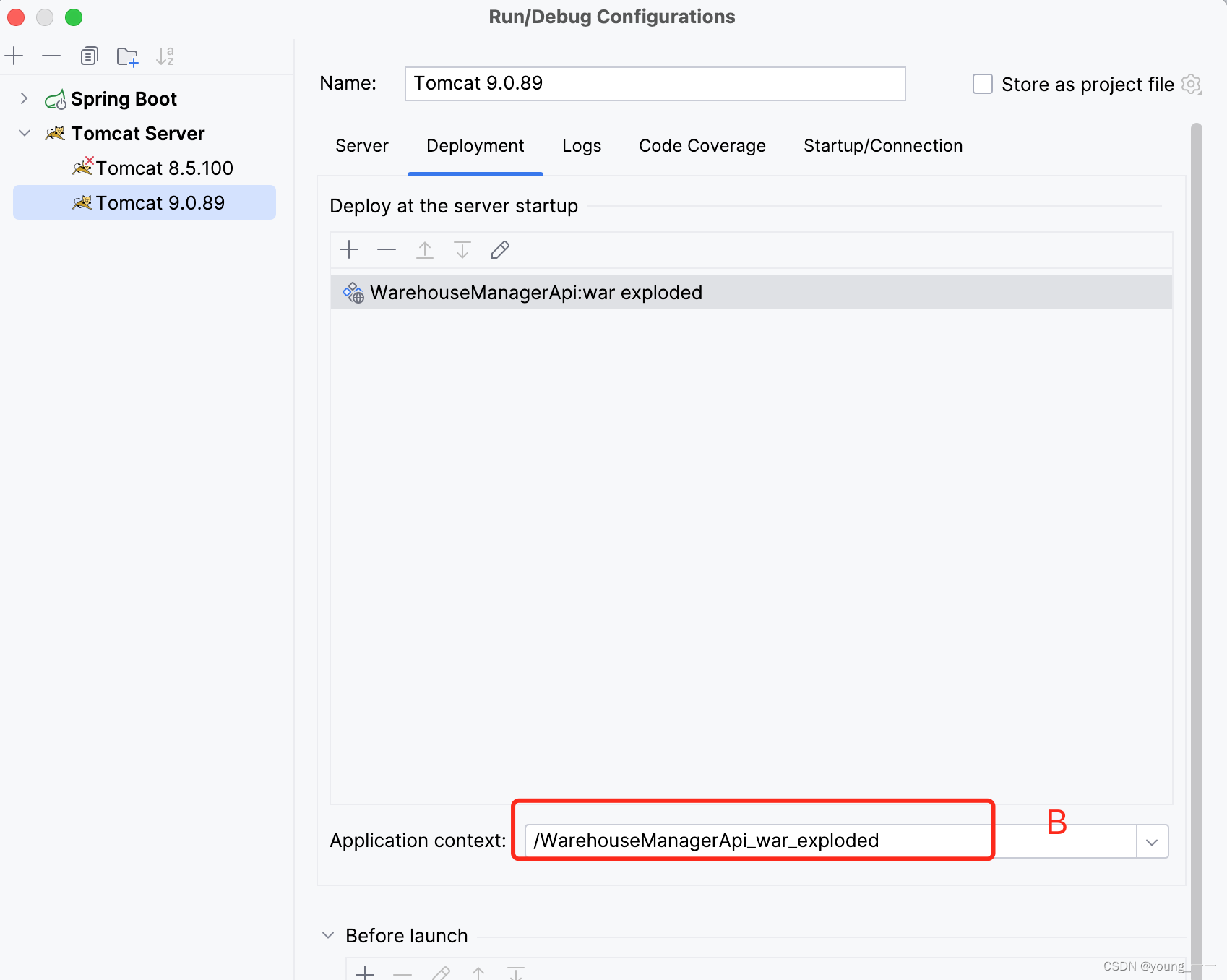
IDEA通过tomcat运行注意事项
配置run--》edit configurations 以下的A B部分要保持一致 A和B的路径要保持一致...

Unity Hub 添加模块报错 Validation Failed 的解决办法
提供两种方法,请自行选择其中一种。 在C:\Windows\System32\drivers\etc\hosts中添加下面的内容并保存后,完全关闭Unity Hub并重新打开,再次尝试下载刚刚失败的模块。 127.0.0.1 public-cdn.cloud.unity3d.com 127.0.0.1 public-cdn.cloud.…...

软件功能测试的类型和流程分享
在现代社会,软件已经成为人们生活中不可或缺的一部分,而在软件的开发过程中,功能测试是不可或缺的环节。软件功能测试指的是对软件系统的功能进行检查和验证,以确保软件在各种情况下能够正常运行,并且能够按照用户需求…...

【C语言】atoi函数的使用及模拟实现
atoi (ascii to integer),是把参数 str 所指向的字符串转换为一个整数(int类型)的库函数。 使用场景 引子: 有兴趣的朋友可以听我逐句翻译一下cpluscplus.com里的这段解释(要考六级了练一下): …...

Golang:使用bndr/gotabulate实现美观的打印表格数据
bndr/gotabulate 可以使用 Go 语言简单、美观的打印表格数据 文档 https://pkg.go.dev/github.com/bndr/gotabulatehttps://github.com/bndr/gotabulate 安装 go get github.com/bndr/gotabulate代码示例 package mainimport ("fmt""github.com/bndr/gotab…...

充电宝哪款好用?什么牌子充电宝耐用?充电宝选购要点总结
随着科技的飞速发展,充电宝已成为现代生活的必备之物。无论是日常通勤、旅行出差,还是在紧急情况下,充电宝都能为我们的电子设备提供可靠的电力支持。然而,面对市场上众多品牌和型号的充电宝,如何选择一款性价比高的充…...

【启程Golang之旅】基本变量与类型讲解
欢迎来到Golang的世界!在当今快节奏的软件开发领域,选择一种高效、简洁的编程语言至关重要。而在这方面,Golang(又称Go)无疑是一个备受瞩目的选择。在本文中,带领您探索Golang的世界,一步步地了…...
使用docker部署项目
一、docker私有镜像仓库 1、docker私有镜像仓库 库(Repository)是集中存放镜像的地方,又分为公共镜像和私有仓库。 当我们执行docker pull xxx的时候,它实际上是从registry.docker.com这个地址去查找,这就是Docker公…...
智慧林业云巡平台 客户端和移动端(支持语音和视频)自动定位巡护,后端离线路线监测
目前现状 无法客观、方便地掌握护林员的到位情况,因而无法有效地保证巡护人员按计划要求,按时按周期对所负责的林区开展巡护,使巡护工作的质量得不到保证。遇到火情、乱砍滥伐等灾情时无法及时上报处理,现场状况、位置等信息描述…...

别再只用Hydra了!这5个SSH安全加固技巧,让你的服务器告别暴力破解
5个进阶SSH安全加固策略:从基础防护到企业级防御 当服务器管理员清晨打开日志,发现数百次失败的SSH登录尝试时,那种被窥视的不安感会瞬间袭来。暴力破解不再是理论威胁——互联网扫描机器人每时每刻都在寻找暴露的22端口,而Hydra等…...

C-Eval:中文大模型能力评估的“高考”与诊断工具
1. 项目概述:为什么我们需要一个“中文大模型高考”?最近两年,大模型的热度居高不下,各种评测榜单也层出不穷。但不知道你有没有发现一个现象:很多号称在某某英文评测集上“刷”到SOTA(State-of-the-Art&am…...

Obsidian个性化首页终极指南:3种配置方案提升知识管理效率70%
Obsidian个性化首页终极指南:3种配置方案提升知识管理效率70% 【免费下载链接】obsidian-homepage Obsidian homepage - Minimal and aesthetic template (with my unique features) 项目地址: https://gitcode.com/gh_mirrors/obs/obsidian-homepage 在信息…...

基于ESP32的嵌入式AI语音交互系统:从硬件设计到软件实现全解析
1. 项目概述:从零打造一个会聊天的嵌入式AI伙伴几年前,当我第一次把“小爱同学”拆开,看到里面密密麻麻的芯片和电路时,一个念头就冒了出来:能不能自己动手,用一块开发板,从头搭建一个能听会说、…...

还在为Linux文件搜索太慢而烦恼?FSearch让文件秒级定位成为现实
还在为Linux文件搜索太慢而烦恼?FSearch让文件秒级定位成为现实 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 你是否曾在Linux系统中花费大量时间寻找一…...

手把手教你用SWM34SRET6驱动4.3寸TFT屏:从LVGL图片加载到SDRAM缓存的完整流程
手把手教你用SWM34SRET6驱动4.3寸TFT屏:从LVGL图片加载到SDRAM缓存的完整流程 在嵌入式开发中,实现高性能的图形界面显示往往需要处理复杂的硬件资源分配和软件架构设计。SWM34SRET6作为一款内置8MB SDRAM的Cortex-M33微控制器,为TFT-LCD驱动…...

新手入门指南使用 Python 快速调用 TaoToken 多模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手入门指南:使用 Python 快速调用 TaoToken 多模型服务 对于刚接触大模型 API 的开发者而言,面对众多模型…...
)
告别点灯:用STM32+FPGA+FSMC做个数据吞吐测试仪(附Quartus与标准库工程)
STM32与FPGA联袂打造:高性能数据吞吐测试仪实战指南 在嵌入式系统开发中,总线通信性能往往是决定整体系统响应速度的关键瓶颈。对于硬件爱好者、电子工程师和学生群体而言,如何直观测量和优化总线传输效率,是一个既具挑战性又充满…...
)
数据结构第8章查找:单元测试15题全解析(顺序查找+折半查找+分块查找+哈希查找)
第8章 查找 单元测试1. 线性表只有以( A )方式存储,才能进行折半查找。A. 顺序B. 链接C. 二叉树D. 关键字有序的2. 有序表为{2,4,10,13,33,42,46,64&#x…...

dropin-minimal-css项目架构深度解析:目录结构与核心组件
dropin-minimal-css项目架构深度解析:目录结构与核心组件 【免费下载链接】dropin-minimal-css Drop-in switcher for previewing minimal CSS frameworks 项目地址: https://gitcode.com/gh_mirrors/dr/dropin-minimal-css dropin-minimal-css是一个用于预览…...