基于高光谱数据集的创新点实现-高斯核函数卷积神经网络
一、高光谱数据集简介
1.1 数据集简介
数据集链接在这:高光谱数据集(.mat.csv)-科研学术
数据集包含下面三个文件:
文件中包含.mat与.csv,145x145x220,
其实主要使用avirissub.csv文件,在代码上只是将mat文件转成了csv文件。具体avirissub.csv如下:145x145x220,每行代表一个数据,每行前220列代表特征,最后一列代表标签值,共17类标签。

1.2.软件环境与配置:
安装TensorFlow2.12.0版本。指令如下:
pip install tensorflow==2.12.0
这个版本最关键,其他库,以此安装即可。
二、基线模型实现:
该代码旨在通过构建和训练卷积神经网络(CNN)模型来进行分类任务。下面是代码的详细解释和网络模型结构的说明:
2.1. 环境设置和数据加载
import pandas as pd
from tensorflow import keras
from tensorflow.keras.layers import Dense, Dropout, Conv1D, MaxPooling1D, Flatten
from tensorflow.keras.models import Sequential
from tensorflow.keras import optimizers
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
from keras.utils import np_utils
import scipy.io as sio
import osos.environ["CUDA_VISIBLE_DEVICES"] = "0"
np.random.seed(42)num_epoch = []
result_mean = []
result_std_y = []
result_std_w = []
- 引入所需库,包括Pandas、TensorFlow、Keras、Scipy等。
- 设置环境变量以使用指定的GPU设备。
- 设置随机种子以确保结果可重现。
2.2. 数据加载和预处理
data = sio.loadmat('D:/python_test/data/avirissub.mat')
data_L = sio.loadmat('D:/python_test/data/avirissub_gt.mat')print(sio.whosmat('D:/python_test/data/avirissub.mat'))
print(sio.whosmat('D:/python_test/data/avirissub_gt.mat'))data_D = data['x92AV3C']
data_L = data_L['x92AV3C_gt']data_D_flat = data_D.reshape(-1, data_D.shape[-1])
print(data_D_flat.shape)data_combined = pd.DataFrame(data_D_flat)
data_combined['label'] = data_L.flatten()
data_combined.to_csv('D:/python_test/data/avirissub.csv', index=False, header=False)data = pd.read_csv('D:/python_test/data/avirissub.csv', header=None)
data = data.values
data_D = data[:, :-1]
data_L = data[:, -1]
print(data_D.shape)data_D = data_D / np.max(np.max(data_D))
data_D_F = data_D / np.max(np.max(data_D))data_train, data_test, label_train, label_test = train_test_split(data_D_F, data_L, test_size=0.8, random_state=42, stratify=data_L)data_train = data_train.reshape(data_train.shape[0], data_train.shape[1], 1)
data_test = data_test.reshape(data_test.shape[0], data_test.shape[1], 1)print(np.unique(label_train))label_train = np_utils.to_categorical(label_train, None)
label_test = np_utils.to_categorical(label_test, None)
- 加载数据和标签,查看文件中的键和形状。
- 数据预处理:将多维数据展平成二维数组,合并数据和标签,保存为CSV文件,并从CSV文件中读取数据。
- 对特征数据进行归一化。
- 划分训练集和测试集,并调整数据形状以与Conv1D层兼容。
- 对标签数据进行独热编码。
2.3. 定义卷积神经网络模型
def CNN(num):result = []num_epoch.append(num)for i in range(3):time_S = time.time()model = Sequential()model.add(Conv1D(filters=6, kernel_size=8, input_shape=inputShape, activation='relu', name='spec_conv1'))model.add(MaxPooling1D(pool_size=2, name='spec_pool1'))model.add(Conv1D(filters=12, kernel_size=7, activation='relu', name='spec_conv2'))model.add(MaxPooling1D(pool_size=2, name='spec_pool2'))model.add(Conv1D(filters=24, kernel_size=8, activation='relu', name='spec_conv3'))model.add(MaxPooling1D(pool_size=2, name='spec_pool3'))model.add(Flatten(name='spe_fla'))model.add(Dense(256, activation='relu', name='spe_De'))model.add(Dense(17, activation='softmax'))adam = optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-8)model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])filepath = "../model/model_spe(5%).h5"checkpointer = ModelCheckpoint(filepath, monitor='val_acc', save_weights_only=False, mode='max', save_best_only=True, verbose=0)callback = [checkpointer]reduce_lr = ReduceLROnPlateau(monitor='val_acc', factor=0.9, patience=10, verbose=0, mode='auto', epsilon=0.000001, cooldown=0, min_lr=0)history = model.fit(data_train, label_train, epochs=num, batch_size=5, shuffle=True, validation_split=0.1, verbose=0)scores = model.evaluate(data_test, label_test, verbose=0)print("\n%s: %.2f%%" % (model.metrics_names[1], scores[1] * 100))result.append(scores[1] * 100)time_E = time.time()print("costTime:", time_E - time_S, 's')print(result)result_mean.append(np.mean(result))print("均值是:%.4f" % np.mean(result))result_std_y.append(np.std(result))print("标准差(有偏)是:%.4f" % np.std(result))result_std_w.append(np.std(result, ddof=1))print("标准差(无偏)是:%.4f" % np.std(result, ddof=1))
- 定义CNN函数,构建并训练卷积神经网络模型。
- 网络模型结构包括:
Conv1D层:一维卷积层,用于提取特征。共三个卷积层,每层有不同的过滤器数量和卷积核大小。MaxPooling1D层:最大池化层,用于下采样。每个卷积层后都有一个池化层。Flatten层:将多维特征图展平成一维。Dense层:全连接层,包含256个神经元,激活函数为ReLU。- 最后一层
Dense层:输出层,包含17个神经元,对应17个类别,激活函数为Softmax。
2.4. 模型训练和评估
if __name__ == '__main__':CNN(5)
- 调用CNN函数并设置迭代次数为5。
完整的基线模型版本代码如下
:
from __future__ import print_function
import pandas as pd
from tensorflow import keras
from tensorflow.keras.layers import Dense, Dropout, Conv1D, MaxPooling1D, Flatten
from tensorflow.keras.models import Sequential
from tensorflow.keras import optimizers
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
from keras.utils import np_utils
import scipy.io as sio
import os# 设置环境变量,指定使用的 GPU 设备
os.environ["CUDA_VISIBLE_DEVICES"] = "0"# 设置随机种子以便实验结果可重现
np.random.seed(42)# 初始化存储结果的列表
num_epoch = []
result_mean = []
result_std_y = []
result_std_w = []# 加载数据
data = sio.loadmat('D:/python_test/data/avirissub.mat') # 加载数据
data_L = sio.loadmat('D:/python_test/data/avirissub_gt.mat') # 加载标签# 查看.mat文件中包含的键和它们的形状
print(sio.whosmat('D:/python_test/data/avirissub.mat'))
print(sio.whosmat('D:/python_test/data/avirissub_gt.mat'))# 提取数据和标签
data_D = data['x92AV3C']
data_L = data_L['x92AV3C_gt']# 将多维数据展平成二维数组
data_D_flat = data_D.reshape(-1, data_D.shape[-1])
print(data_D_flat.shape)
# 将数据和标签合并
data_combined = pd.DataFrame(data_D_flat)
data_combined['label'] = data_L.flatten()# 保存为.csv文件
data_combined.to_csv('D:/python_test/data/avirissub.csv', index=False, header=False)# 从 CSV 文件中读取数据
data = pd.read_csv('D:/python_test/data/avirissub.csv', header=None) # 14 类可以用于分类
data = data.values
data_D = data[:, :-1] # 提取特征 提取了 data 矩阵的所有行和除了最后一列之外的所有列,这就是特征数据。
data_L = data[:, -1] # 提取标签 提取了 data 矩阵的所有行的最后一列,这就是标签数据
print(data_D.shape) # 打印特征数据的形状# 对特征数据进行归一化
data_D = data_D / np.max(np.max(data_D))
data_D_F = data_D / np.max(np.max(data_D))# 将数据划分为训练集和测试集
data_train, data_test, label_train, label_test = train_test_split(data_D_F, data_L, test_size=0.8, random_state=42,stratify=data_L)
# 将数据重新调整为与 Conv1D 层兼容的形状
data_train = data_train.reshape(data_train.shape[0], data_train.shape[1], 1)
data_test = data_test.reshape(data_test.shape[0], data_test.shape[1], 1)# 打印标签数据的唯一值,确保它们的范围是正确的
print(np.unique(label_train))# 根据类来自动定义独热编码
label_train = np_utils.to_categorical(label_train, None)
label_test = np_utils.to_categorical(label_test, None)inputShape = data_train[0].shape # 输入形状import timedef CNN(num):result = []num_epoch.append(num)# for i in range(50):for i in range(3):time_S = time.time()model = Sequential()# 定义模型结构model.add(Conv1D(filters=6, kernel_size=8, input_shape=inputShape, activation='relu', name='spec_conv1'))model.add(MaxPooling1D(pool_size=2, name='spec_pool1'))#model.add(Conv1D(filters=12, kernel_size=7, activation='relu', name='spec_conv2'))model.add(MaxPooling1D(pool_size=2, name='spec_pool2'))#model.add(Conv1D(filters=24, kernel_size=8, activation='relu', name='spec_conv3'))model.add(MaxPooling1D(pool_size=2, name='spec_pool3'))# model.add(Conv1D(filters=48, kernel_size=10, activation='relu', name='spec_conv4'))# model.add(MaxPooling1D(pool_size=2, name='spec_pool4'))model.add(Flatten(name='spe_fla'))model.add(Dense(256, activation='relu', name='spe_De'))# model.add(Dropout(0.5,name = 'drop'))model.add(Dense(17, activation='softmax'))# 设置优化器和损失函数,并编译模型adam = optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-8)model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])filepath = "../model/model_spe(5%).h5"checkpointer = ModelCheckpoint(filepath, monitor='val_acc', save_weights_only=False, mode='max',save_best_only=True, verbose=0)callback = [checkpointer]reduce_lr = ReduceLROnPlateau(monitor='val_acc', factor=0.9, patience=10, verbose=0, mode='auto',epsilon=0.000001,cooldown=0, min_lr=0)# 训练模型并计算评分history = model.fit(data_train, label_train, epochs=num, batch_size=5, shuffle=True, validation_split=0.1,verbose=0)scores = model.evaluate(data_test, label_test, verbose=0)print("\n%s: %.2f%%" % (model.metrics_names[1], scores[1] * 100))# 保存模型result.append(scores[1] * 100)time_E = time.time()print("costTime:", time_E - time_S, 's')print(result)result_mean.append(np.mean(result))print("均值是:%.4f" % np.mean(result))result_std_y.append(np.std(result))print("标准差(有偏)是:%.4f" % np.std(result))result_std_w.append(np.std(result, ddof=1))print("标准差(无偏)是:%.4f" % np.std(result, ddof=1))if __name__ == '__main__':# 调用 CNN 函数并设置迭代次数为 50# CNN(50)CNN(5)三、创新点实现:
这段代码在原有基础上引入了一些创新点,主要包括自定义卷积层和自定义回调函数。下面是具体创新点的详细解释:
3.1. 高斯核函数和自定义卷积层
高斯核函数
def gaussian_kernel(x, y, sigma=1.0):return tf.exp(-tf.reduce_sum(tf.square(x - y), axis=-1) / (2 * sigma ** 2))
- 定义高斯核函数,用于计算输入片段与卷积核之间的相似性。
自定义卷积层
class GaussianKernelConv1D(Layer):def __init__(self, filters, kernel_size, sigma=1.0, **kwargs):super(GaussianKernelConv1D, self).__init__(**kwargs)self.filters = filtersself.kernel_size = kernel_sizeself.sigma = sigmadef build(self, input_shape):self.kernel = self.add_weight(name='kernel',shape=(self.kernel_size, int(input_shape[-1]), self.filters),initializer='uniform',trainable=True)super(GaussianKernelConv1D, self).build(input_shape)def call(self, inputs):output = []for i in range(inputs.shape[1] - self.kernel_size + 1):slice = inputs[:, i:i+self.kernel_size, :]slice = tf.expand_dims(slice, -1)kernel = tf.expand_dims(self.kernel, 0)similarity = gaussian_kernel(slice, kernel, self.sigma)output.append(tf.reduce_sum(similarity, axis=2))return tf.stack(output, axis=1)
GaussianKernelConv1D是一个自定义的一维卷积层,使用高斯核函数来计算相似性。build方法中定义了卷积核,并设置为可训练参数。call方法中实现了卷积操作,通过滑动窗口方式计算输入片段和卷积核之间的相似性,并累加这些相似性值。
3.2. 自定义回调函数
自定义回调函数用于在每个 epoch 结束时输出训练信息
class TrainingProgressCallback(Callback):def on_epoch_end(self, epoch, logs=None):logs = logs or {}print(f"Epoch {epoch + 1}/{self.params['epochs']}, Loss: {logs.get('loss')}, Accuracy: {logs.get('accuracy')}, "f"Val Loss: {logs.get('val_loss')}, Val Accuracy: {logs.get('val_accuracy')}")
TrainingProgressCallback是一个自定义回调函数,用于在每个 epoch 结束时输出训练进度,包括损失和准确率。
3.3. 模型构建、训练和评估
CNN 函数
def CNN(num):result = []num_epoch.append(num)for i in range(3):time_S = time.time()model = Sequential()# 定义模型结构model.add(GaussianKernelConv1D(filters=6, kernel_size=8, input_shape=inputShape, name='spec_conv1'))model.add(MaxPooling1D(pool_size=2, name='spec_pool1'))model.add(GaussianKernelConv1D(filters=12, kernel_size=7, name='spec_conv2'))model.add(MaxPooling1D(pool_size=2, name='spec_pool2'))model.add(GaussianKernelConv1D(filters=24, kernel_size=8, name='spec_conv3'))model.add(MaxPooling1D(pool_size=2, name='spec_pool3'))model.add(Flatten(name='spe_fla'))model.add(Dense(256, activation='relu', name='spe_De'))model.add(Dense(17, activation='softmax'))# 设置优化器和损失函数,并编译模型adam = optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-8)model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])filepath = "../model/model_spe(5%).h5"checkpointer = ModelCheckpoint(filepath, monitor='val_accuracy', save_weights_only=False, mode='max',save_best_only=True, verbose=0)callback = [checkpointer, TrainingProgressCallback()]reduce_lr = ReduceLROnPlateau(monitor='val_accuracy', factor=0.9, patience=10, verbose=0, mode='auto',min_delta=0.000001,cooldown=0, min_lr=0)callback.append(reduce_lr)# 训练模型并计算评分history = model.fit(data_train, label_train, epochs=num, batch_size=5, shuffle=True, validation_split=0.1,verbose=1, callbacks=callback)scores = model.evaluate(data_test, label_test, verbose=0)print("\n%s: %.2f%%" % (model.metrics_names[1], scores[1] * 100))result.append(scores[1] * 100)time_E = time.time()print("costTime:", time_E - time_S, 's')print(result)result_mean.append(np.mean(result))print("均值是:%.4f" % np.mean(result))result_std_y.append(np.std(result))print("标准差(有偏)是:%.4f" % np.std(result))result_std_w.append(np.std(result, ddof=1))print("标准差(无偏)是:%.4f" % np.std(result, ddof=1))
- 在
CNN函数中,模型结构与之前类似,但卷积层替换为自定义的GaussianKernelConv1D层。 - 使用
TrainingProgressCallback在每个 epoch 结束时输出训练进度。 - 训练模型并评估其性能。
四、总结
相对于原代码,新的代码主要创新点包括:
- 引入高斯核函数和自定义卷积层:使用高斯核函数来计算输入片段与卷积核之间的相似性,增加了模型的灵活性和非线性特征提取能力。
- 自定义回调函数:用于在每个 epoch 结束时输出训练进度,提供更详细的训练信息,便于实时监控和调整模型。
相关文章:
基于高光谱数据集的创新点实现-高斯核函数卷积神经网络
一、高光谱数据集简介 1.1 数据集简介 数据集链接在这:高光谱数据集(.mat.csv)-科研学术 数据集包含下面三个文件: 文件中包含.mat与.csv,145x145x220, 其实主要使用avirissub.csv文件,在代码上只是将mat文件转成了csv文件。具体avirissub.csv如下&am…...
【python 进阶】 绘图
1. 将多个柱状绘制在一个图中 import seaborn as sns import matplotlib.pyplot as plt import numpy as np import pandas as pd# 创建示例数据 categories [A, B, C, D, E] values1 np.random.randint(1, 10, sizelen(categories)) values2 np.random.randint(1, 10, siz…...

memblock_free_all释放page到buddy,前后nr_free的情况
https://www.cnblogs.com/tolimit/p/5287801.html 在zone_sizes_init 之后,各个node,zone的page总数已知。但是此时的每个order的空闲链表是空的,也就是无法通过alloc_page这种接口来分配。此时page还在memblock管控,需要memblock…...

Django实现websocket
Django实现websocket WebSocket功能使用介绍安装配置WebSocket接口--消息接收者的实现scope通道层 channel layer部署Web客户端连接Mac客户端 WebSocket功能 WebSocket长连接一般用于实现实时功能,例如web端的消息通知、会话等场景。 使用 WebSocket 向 Django 项…...

先进制造aps专题九 中国aps行业分析
国外aps的问题是不给国内客户定制算法 国外aps的算法都很强大,考虑几百个约束条件,各种复杂的工序关系,还有副资源约束特殊规格约束,排程还优化,光c写的算法代码就几十万行甚至上百万行 国内aps的问题是实现不了复杂的…...

力扣hot100:23. 合并 K 个升序链表
23. 合并 K 个升序链表 这题非常容易想到归并排序的思路,俩升序序列合并,可以使用归并的方法。 不过这里显然是一个多路归并排序;包含多个子数组的归并算法,这可以让我们拓展归并算法的思路。 假设n是序列个数,ni是…...
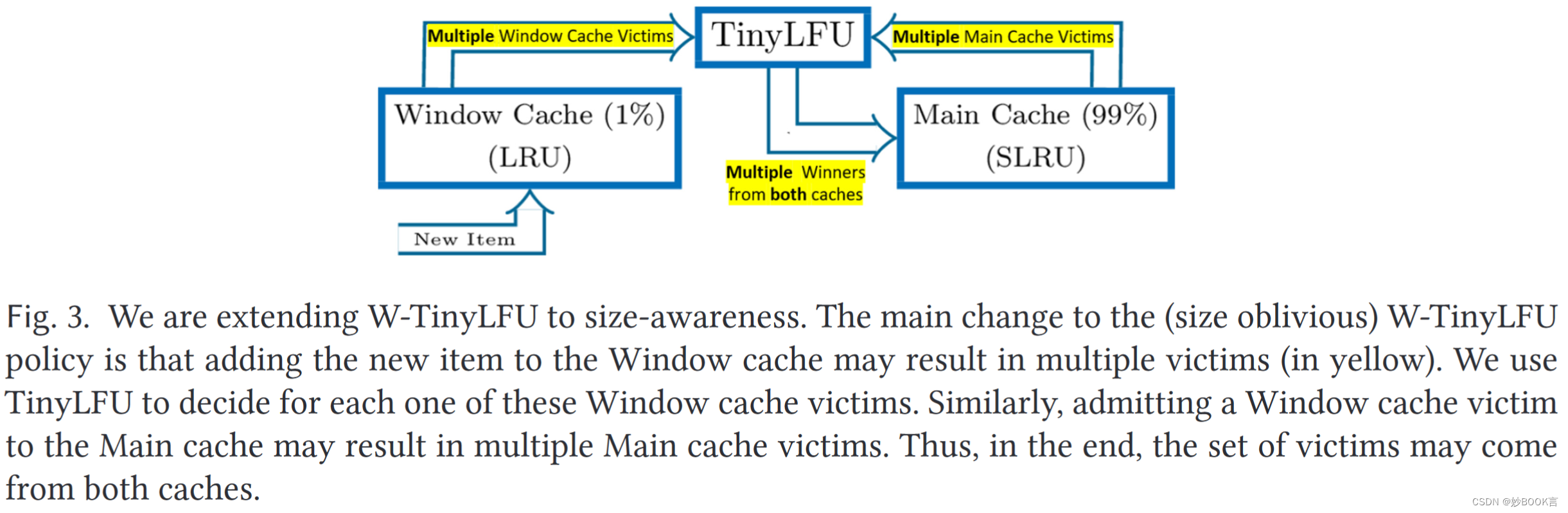
Lightweight Robust Size Aware Cache Management——论文泛读
TOC 2022 Paper 论文阅读笔记整理 问题 现代键值存储、对象存储、互联网代理缓存和内容交付网络(CDN)通常管理不同大小的对象,例如,Blob、不同长度的视频文件、不同分辨率的图像和小文件。在这种工作负载中,大小感知…...
搜索自动补全-elasticsearch实现
1. elasticsearch准备 1.1 拼音分词器 github地址:https://github.com/infinilabs/analysis-pinyin/releases?page6 必须与elasticsearch的版本相同 第四步,重启es docker restart es1.2 定义索引库 PUT /app_info_article {"settings": …...

连接远程的kafka【linux】
# 连接远程的kafka【linux】 前言版权推荐连接远程的kafka【linux】一、开放防火墙端口二、本地测试是否能访问端口三、远程kafka配置四、开启远程kakfa五、本地测试能否连接远程六、SpringBoot测试连接 遇到的问题最后 前言 2024-5-14 18:45:48 以下内容源自《【linux】》 仅…...
简单的 Cython 示例
1, pyx文件 fibonacci.pyx def fibonacci_old(n):if n < 0:return 0elif n 1:return 1else:return fibonacci_old(n-1) fibonacci_old(n-2) 2,setup.py setup.py from setuptools import setup from Cython.Build import cythonizesetup(ext_mod…...

Laravel时间处理类Carbon
时间和日期处理是非常常见的任务。Carbon 是一个功能强大的 PHP 扩展包,它为我们提供了许多方便的方法来处理日期和时间。在 Laravel 中,你无需单独安装 Carbon,因为 Laravel 默认已经包含了它。如果你正在使用 Laravel,那么你已经…...

2024年5月软考架构题目回忆分享
十年架构两茫茫 ,Redis , UML 夜来幽梦忽还乡 , 大数据, Lambda 选择题 1.需求分析和架构设计面临这两个不同对象,一个是问题空间,一个是解空间 这是英文题,总共五个题目,只记得这么多 2. …...

香橙派 AIpro开发板初上手
一、香橙派 AIpro开箱 最近拿到了香橙派 AIpro(OrangePi AIpro),下面就是里面的板子和相关的配件。包含主板、散热组件、电源适配器、双C口电源线、32GB SD卡。我手上的这个是8G LPDDR4X运存的版本。 OrangePi AIpro开发板是一款由香橙派与华…...

如何使用DotNet-MetaData识别.NET恶意软件源码文件元数据
关于DotNet-MetaData DotNet-MetaData是一款针对.NET恶意软件的安全分析工具,该工具专为蓝队研究人员设计,可以帮助广大研究人员轻松识别.NET恶意软件二进制源代码文件中的元数据。 工具架构 当前版本的DotNet-MetaData主要由以下两个部分组成…...

LeetCode---栈与队列
232. 用栈实现队列 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty): 实现 MyQueue 类: void push(int x) 将元素 x 推到队列的末尾int pop() 从队列的开头移除并返回元素int pee…...

【教程】利用API接口添加本站同款【每日新闻早早报】-每天自动更新,不占用文章数量
本次分享的是给网站添加一个每日早报的文章,可以看到本站置顶上面还有一个日更的日报,这是利用ALAPI的接口完成的!利用接口有利也有弊,因为每次用户访问网站的时候就会增加一次API接口请求,导致文章的请求会因为请求量…...

僵尸进程,孤儿进程,守护进程
【一】僵尸进程 1.僵尸进程是指完成自己的任务之后,没有被父进程回收资源,占用系统资源,对计算机有害,应该避免 """ 所有的子进程在运行结束之后都会变成僵尸进程(死了没死透)还保留着pid和一些运行过程的中的记录便于主进程查看(短时间…...
Nuxt3 中使用 ESLint
# 快速安装 使用该命令安装的同时会给依赖、内置模块同时更新 npx nuxi module add eslint安装完毕后,nuxt.config.ts 文件 和 package.json 文件 会新增代码段: # nuxt.config.ts modules: ["nuxt/eslint" ] # package.json "devDep…...
【Jmeter】性能测试之压测脚本生成,也可以录制接口自动化测试场景
准备工作-10分中药录制HTTPS脚本,需配置证书 准备工作-10分中药 以https://www.baidu.com/这个地址为录制脚本的示例。 录制脚本前的准备工作当然是得先把Jmeter下载安装好、JDK环境配置好、打开Jmeter.bat,打开cmd,输入ipconfig,…...
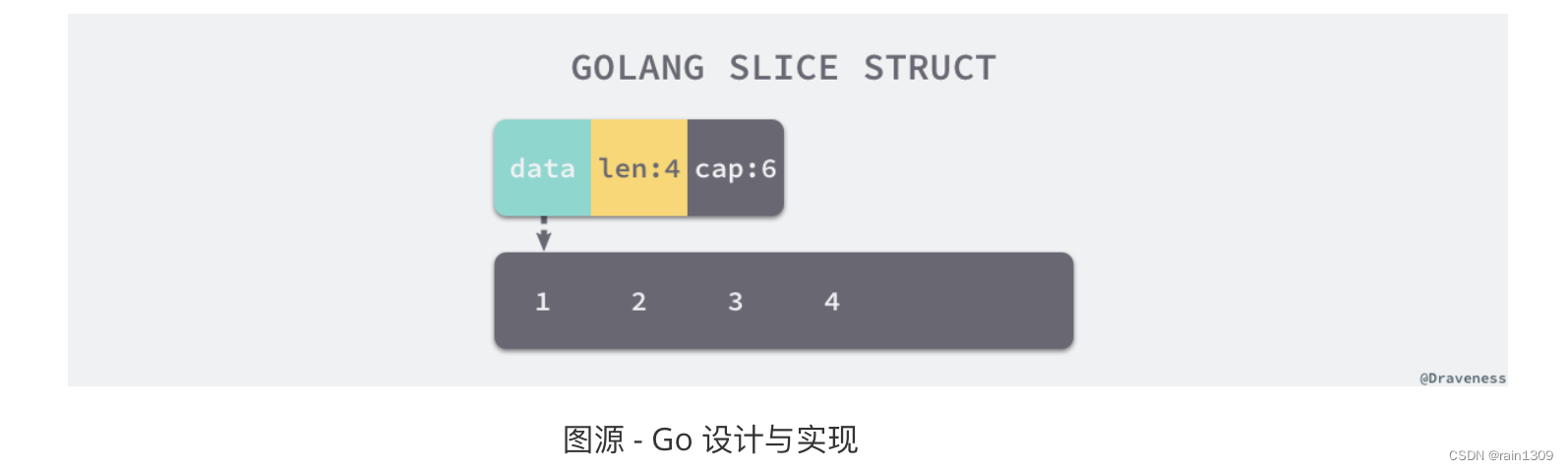
Go 编程技巧:零拷贝字符串与切片转换的高效秘籍
前言 在深入探讨Go语言中字符串与切片类型转换的高效方法之前,让我们先思考一个关键问题:如何在不进行内存拷贝的情况下,实现这两种数据类型之间的无缝转换?本文将详细解析Go语言中字符串(字符类型)和切…...

linux下的spi子系统
概念通信模式可以分为单工、半双工和全双工,单工通信指信号只在一个方向上传输,仅 能发送或接收,而半双工通信指信号可以在俩个方向上传输,但某一个时刻只允许发送或接收,而全双工通信指数据同时在俩个方向上传输&…...

ESP8266上玩转MicroPython:四角按钮控制LED的3种接线方案对比
ESP8266上玩转MicroPython:四角按钮控制LED的3种接线方案对比 在物联网和智能硬件开发中,ESP8266凭借其出色的性价比和丰富的功能接口,成为了创客和开发者的首选。而MicroPython的出现,更是让Python开发者能够轻松上手硬件编程。本…...

深度解析开源项目:NVIDIA Profile Inspector 完全指南与实战配置方案
深度解析开源项目:NVIDIA Profile Inspector 完全指南与实战配置方案 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector(NPI)是一款功能强大的…...

通过WireShark与WinHex从pcap数据流中提取并修复损坏的JPG图片
1. 从pcap文件中筛选JPG数据流 当你拿到一个网络抓包文件(pcap格式),里面可能混杂着各种网络流量数据。要从中提取出图片文件,首先得学会用WireShark这个神器来筛选目标数据。我处理过不少类似的案例,发现很多新手容易…...

键盘连击终结者:开源工具KeyboardChatterBlocker让老化键盘重获新生
键盘连击终结者:开源工具KeyboardChatterBlocker让老化键盘重获新生 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 机械键盘…...

干农活总腰疼?农民朋友别再硬扛腰突
经常弯腰种地、扛重物、干农活,很多农民朋友常年腰疼,总觉得累点正常,咬牙硬扛。 殊不知慢慢发展成腰间盘突出,坐骨神经疼、腿麻无力,后期连农活都干不了。乱贴偏方、盲目正骨,还容易加重病情。我院 30 多年…...

Ostrakon-VL终端惊艳效果:终端界面响应速度实测对比
Ostrakon-VL终端惊艳效果:终端界面响应速度实测对比 1. 像素特工终端效果展示 1.1 视觉设计亮点 Ostrakon-VL终端采用了独特的8-bit像素艺术风格,将传统零售场景中的图像识别任务转化为充满游戏感的"数据扫描任务"。这种设计不仅提升了用户…...

AI视频修复与字幕去除工具:突破硬字幕处理瓶颈的全流程解决方案
AI视频修复与字幕去除工具:突破硬字幕处理瓶颈的全流程解决方案 【免费下载链接】video-subtitle-remover 基于AI的图片/视频硬字幕去除、文本水印去除,无损分辨率生成去字幕、去水印后的图片/视频文件。无需申请第三方API,本地实现。AI-base…...

怎么样辨别生活中遇到的那些理财平台的真假?
怎么样辨别生活中遇到的那些理财平台的真假?凡是声称高息保本的投资理财平台极有可能是黑平台。尝试用手机官方应用商城搜索理财软件,如果是别人通过聊天软件发链接给你安装的,不是正规手机应用商城下载的,且在应用商城无法搜索到…...

MT管理器安卓版,APK逆向修改神器,APP提取APK教程。
今天算是比较郁闷的一天,作为互联网上算是最老的一批写用户,如果你是带人学习互联网的大佬,估计你都会放弃我这种年龄段的人,不过我还是活下来了,像我们这样的80、90后还有一大批活下来了。 AI出来了给人的引影响很大…...