随机森林算法教程(个人总结)
背景
随机森林(Random Forest)是一种集成学习方法,主要用于分类和回归任务。它通过构建多个决策树并将其结果进行集成,提升模型的准确性和鲁棒性。随机森林在处理高维数据和防止过拟合方面表现出色,是一种强大的机器学习算法。
随机森林的基本思想
随机森林由多个决策树组成,每棵树在训练时都从原始数据集进行有放回的随机抽样(即Bootstrap抽样),并在每个节点分裂时随机选择部分特征进行最佳分裂。最终结果通过对所有树的预测结果进行投票(分类)或平均(回归)来确定。
随机森林的优缺点
优点
- 高准确性:通过集成多棵树,减少了单棵树的过拟合风险,提高了模型的准确性。
- 鲁棒性强:对异常值和噪声不敏感,能够处理高维数据。
- 特征重要性评估:能够提供特征重要性评估,有助于理解模型和数据。
缺点
- 训练时间较长:由于需要训练多棵树,训练时间相对较长。
- 内存消耗大:存储多棵树需要较大的内存空间。
- 黑箱模型:尽管可以评估特征重要性,但具体决策过程难以解释。
随机森林的实现
算法步骤
- Bootstrap抽样:从原始数据集中随机抽取多个样本子集,每个子集用于训练一棵决策树。
- 特征选择:在每个节点分裂时,随机选择部分特征进行最佳分裂。
- 决策树构建:根据选定的样本子集和特征,构建多棵决策树。
- 结果集成:对于分类任务,通过对所有树的预测结果进行投票决定最终分类结果;对于回归任务,通过对所有树的预测结果进行平均决定最终回归结果。
算法实现
下面是一个使用Python和Scikit-learn库实现随机森林的示例。
1. 数据准备
我们使用一个示例数据集(如Iris数据集)进行演示。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
2. 构建随机森林模型
from sklearn.ensemble import RandomForestClassifier# 创建随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型
rf_classifier.fit(X_train, y_train)
3. 模型预测与评估
from sklearn.metrics import accuracy_score, classification_report# 预测测试集
y_pred = rf_classifier.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"准确率: {accuracy}")# 输出分类报告
print(classification_report(y_test, y_pred))
4. 特征重要性评估
import numpy as np
import matplotlib.pyplot as plt# 获取特征重要性
feature_importances = rf_classifier.feature_importances_# 绘制特征重要性条形图
features = iris.feature_names
indices = np.argsort(feature_importances)[::-1]plt.figure(figsize=(10, 6))
plt.title("Feature Importances")
plt.bar(range(X.shape[1]), feature_importances[indices], align="center")
plt.xticks(range(X.shape[1]), [features[i] for i in indices])
plt.show()
高级使用技巧
超参数调优
随机森林有多个超参数可以调节,如n_estimators(树的数量)、max_depth(树的最大深度)、min_samples_split(内部节点再划分所需最小样本数)等。可以通过网格搜索(Grid Search)或随机搜索(Random Search)进行超参数调优。
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [None, 10, 20, 30],'min_samples_split': [2, 5, 10]
}# 网格搜索
grid_search = GridSearchCV(estimator=rf_classifier, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2)
grid_search.fit(X_train, y_train)# 输出最佳参数
print(f"最佳参数: {grid_search.best_params_}")
处理不平衡数据
对于不平衡数据集,可以通过调整类权重或采用欠采样/过采样方法来改善模型性能。
# 调整类权重
rf_classifier_balanced = RandomForestClassifier(n_estimators=100, class_weight='balanced', random_state=42)
rf_classifier_balanced.fit(X_train, y_train)
并行化处理
随机森林的训练过程可以并行化处理,以提高训练速度。可以通过设置n_jobs参数实现。
# 并行训练
rf_classifier_parallel = RandomForestClassifier(n_estimators=100, n_jobs=-1, random_state=42)
rf_classifier_parallel.fit(X_train, y_train)
详细解释
1. Bootstrap抽样
Bootstrap抽样是一种有放回的随机抽样方法。在构建每棵决策树时,从原始数据集中随机抽取多个样本子集,每个样本子集的大小与原始数据集相同,但可能包含重复样本。这种方法可以增加模型的多样性,从而提高整体模型的泛化能力。
2. 特征选择
在构建决策树的过程中,每个节点分裂时都会随机选择部分特征进行最佳分裂。这种随机选择特征的方法可以减少特征之间的相关性,进一步增加模型的多样性,减少过拟合风险。
3. 决策树构建
每棵决策树根据选定的样本子集和特征进行构建。决策树的构建过程包括以下步骤:
- 选择最佳分裂点:根据选定的特征,选择能够最大程度减少不纯度的分裂点。
- 递归分裂:对每个分裂后的子集,重复上述步骤,直到达到停止条件(如最大深度、最小样本数等)。
4. 结果集成
随机森林通过集成多棵决策树的预测结果来确定最终结果。对于分类任务,通过对所有树的预测结果进行投票决定最终分类结果;对于回归任务,通过对所有树的预测结果进行平均决定最终回归结果。
超参数调优
随机森林有多个超参数可以调节,以提高模型性能。常见的超参数包括:
n_estimators:森林中树的数量。树的数量越多,模型越稳定,但训练时间也越长。max_depth:每棵树的最大深度。深度越大,树越复杂,可能会过拟合。min_samples_split:内部节点再划分所需的最小样本数。样本数越大,树越简单,可能会欠拟合。min_samples_leaf:叶子节点所需的最小样本数。样本数越大,树越简单,可能会欠拟合。max_features:分裂时考虑的最大特征数。特征数越多,树越复杂,可能会过拟合。
处理不平衡数据
对于类别分布不平衡的数据集,可以通过调整类权重或采用欠采样/过采样方法来改善模型性能。调整类权重可以通过class_weight参数实现,设置为balanced时,模型会根据类别频率自动调整权重。欠采样和过采样可以通过手动调整数据集实现。
并行化处理
随机森林的训练过程可以并行化处理,以提高训练速度。可以通过设置n_jobs参数来控制并行线程数,n_jobs=-1表示使用所有可用的CPU核心进行并行计算。
随机森林应用实例
实例1:Iris数据集分类
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
import numpy as np# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型
rf_classifier.fit(X_train, y_train)# 预测测试集
y_pred = rf_classifier.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"准确率: {accuracy}")# 输出分类报告
print(classification_report(y_test, y_pred))# 获取特征重要性
feature_importances = rf_classifier.feature_importances_# 绘制特征重要性条形图
features = iris.feature_names
indices = np.argsort(feature_importances)[::-1]plt.figure(figsize=(10, 6))
plt.title("Feature Importances")
plt.bar(range(X.shape[1]), feature_importances[indices], align="center")
plt.xticks(range(X.shape[1]), [features[i] for i in indices])
plt.show()
实例2:乳腺癌数据集分类
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
import numpy as np# 加载数据集
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型
rf_classifier.fit(X_train, y_train)# 预测测试集
y_pred = rf_classifier.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"准确率: {accuracy}")# 输出分类报告
print(classification_report(y_test, y_pred))# 获取特征重要性
feature_importances = rf_classifier.feature_importances_# 绘制特征重要性条形图
features = cancer.feature_names
indices = np.argsort(feature_importances)[::-1]plt.figure(figsize=(10, 6))
plt.title("Feature Importances")
plt.bar(range(X.shape[1]), feature_importances[indices], align="center")
plt.xticks(range(X.shape[1]), [features[i] for i in indices])
plt.show()
结论
随机森林是一种强大且灵活的机器学习算法,适用于多种分类和回归任务。通过集成多个决策树,随机森林能够有效地减少过拟合,提高模型的准确性和稳定性。在实际应用中,可以通过超参数调优、处理不平衡数据和并行化处理等方法进一步提升模型性能。
通过本教程的详细介绍和代码示例,希望您对随机森林算法有了更深入的理解,并能够在实际项目中应用这些技术。如果有更多问题或需要进一步的帮助,请随时与我联系。
相关文章:
)
随机森林算法教程(个人总结)
背景 随机森林(Random Forest)是一种集成学习方法,主要用于分类和回归任务。它通过构建多个决策树并将其结果进行集成,提升模型的准确性和鲁棒性。随机森林在处理高维数据和防止过拟合方面表现出色,是一种强大的机器学…...

解决Android studio 一直提示下载gradle-xxx-all.zip问题
今天用AndroidStdiod打开一个新工程的时候,发现项目一直卡在正在下载gradle-xxx-all.zip的任务上,网络出奇的慢,即使配了VPN也无济于事,于是按照以往经验:将gradle-xxx-all.zip下载到.gradle\gradle\wrapper\dists目录…...

3DEXPERIENCE DELMIA Role: RVN - Robotics Virtual Commissioning Analyst
Discipline: Robotics Role: RVN - Robotics Virtual Commissioning Analyst 通过准确地模拟连接到PLC程序的机器人、设备和传感器,在制造虚拟孪生上执行虚拟调试情景 为任何机器人角色的多周期情景创建传感器,生成和变换零件启用 PLC 程序的虚拟验证和…...
js知识点之闭包
闭包 什么是闭包 闭包,是 JavaScript 中一个非常重要的知识点,也是我们前端面试中较高几率被问到的知识点之一。 打开《JavaScript 高级程序设计》和《 JavaScript 权威指南》,会发现里面针对闭包的解释各执一词,在网络上搜索关…...

LORA微调,让大模型更平易近人
技术背景 最近和大模型一起爆火的,还有大模型的微调方法。 这类方法只用很少的数据,就能让大模型在原本表现没那么好的下游任务中“脱颖而出”,成为这个任务的专家。 而其中最火的大模型微调方法,又要属LoRA。 增加数据量和模…...

LabVIEW全自动样品处理系统有哪些优势?
基于LabVIEW的全自动样品处理系统在现代科研和工业应用中展现出显著的优势,其在数据采集、分析和控制方面的性能使其成为提高效率和精度的理想选择。以下是该系统的详细优势: 高效自动化 LabVIEW的图形化编程语言极大地简化了自动化流程的开发。用户可…...

shell脚本操作http请求的返回值——shell处理json格式数据
日常工作中,我们经常会遇到http请求会返回大量格式固定的数据,而我们只需要其中的一部分,那么怎么提取我们想要的字段呢。 这里会介绍一种用shell脚本处理http请求返回,或者处理json格式数据的方式。 这里我们用到了 jq这个强大的…...

leetcode力扣 300. 最长递增子序列 II
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。 示例 1&#…...

C++_vector简单源码剖析:vector模拟实现
文章目录 🚀1.迭代器🚀2.构造函数与析构函数⚡️2.1 默认构造函数vector()⚡️2.2 vector(int n, const T& value T())⚡️内置类型也有构造函数 ⚡️2.3 赋值重载operator⚡️2.4 通用迭代器拷贝⚡️2.5 vector(initializer_list<T> il)⚡️…...

第3章 数据链路层
王道学习 考纲内容 (一)数据链路层的功能 (二)组帧 (三)差错控制 检错编码;纠错编码 (四)流量控制与可靠传输机制 流量控制、可靠传输与滑动窗口…...

使用OrangePi KunPeng Pro部署AI模型
目录 一、OrangePi Kunpeng Pro简介二、环境搭建三、模型运行环境搭建(1)下载Ollama用于启动并运行大型语言模型(2)配置ollama系统服务(3)启动ollama服务(4)启动ollama(5)查看ollama运行状态四、模型部署(1)部署1.8b的qwen(2)部署2b的gemma(3)部署3.8的phi3(4)部署4b的qwen(5)部…...

SpringMVC 数据映射VC
从 view 层发送请求到Controller,在Controller中获取参数: 在不输入值时会报400,参数错误 在不输入值时num默认为null 没有找到对应标签名称叫nums的,输入任何值时都报400 设置required默认值为false,即使表单没有nums…...
Clickhouse Bitmap 类型操作总结—— Clickhouse 基础篇(四)
文章目录 创建 Bitmap 对象Bitmap 转换为整数数组计算总数(去重)值指定start, end 索引生成子 Bitmap指定 start 索引和数量限制生成子 Bitmap指定偏移量生成子 Bitmap是否包含指定元素两个 Bitmap 是否存在相同元素一个是否为另一个 Bitmap 的子集求最小…...

202474读书笔记|《我自我的田渠归来》——愿你拥有向上的力量,一切的好事都应该有权利发生
202474读书笔记|《我自我的田渠归来》——愿你拥有向上的力量 《我自我的田渠归来》作者张晓风,被称为华语散文温柔的一支笔,她的短文很有味道,角度奇特,温柔慈悲而敏锐。 很幸运遇到了这本书,以她的感受重新认识一些事…...
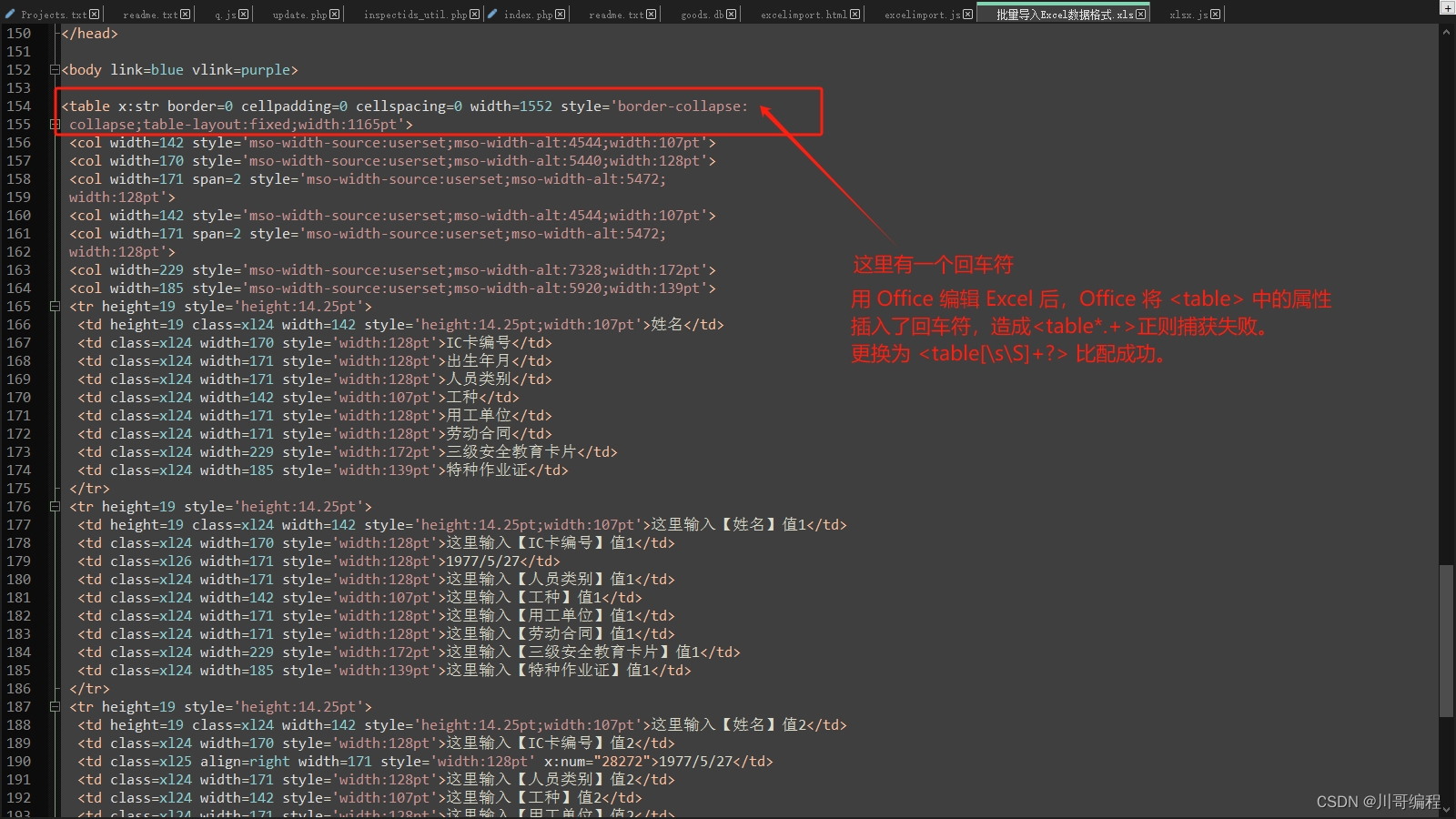
SheetJS V0.17.5 导入 Excel 异常修复 Invalid HTML:could not find<table>
导入 Excel 提示错误:Invalid HTML:could not find<table> 检查源代码 发现 table 属性有回车符 Overview: https://docs.sheetjs.com/docs/ Source: https://git.sheetjs.com/sheetjs/sheetjs/issues The public-facing websites of SheetJS: sheetjs.com…...
重学java51.Collections集合工具类、泛型
"我已不在地坛,地坛在我" —— 《想念地坛》 24.5.28 一、Collections集合工具类 1.概述:集合工具类 2.特点: a.构造私有 b.方法都是静态的 3.使用:类名直接调用 4.方法: static <T> boolean addAll(collection<? super T>c,T... el…...
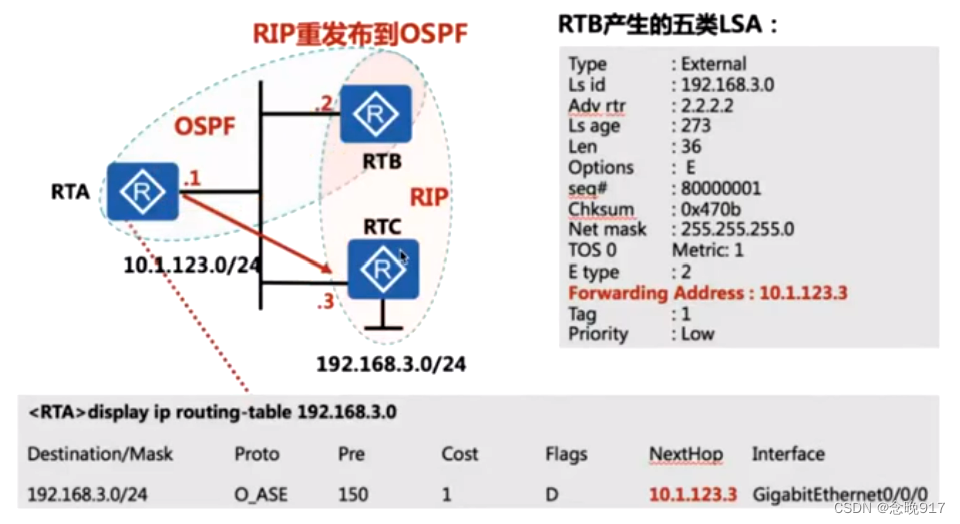
OSPF扩展知识2
FA-转发地址 正常 OSPF 区域收到的 5 类 LSA 不存在 FA 值; 产生 FA 的条件: 1、5类LSA ----假设 R2为 ASBR,90/0 口工作的 OSPF 中,g0/1 口工作在非 ospf 协议或不同 ospf 进程中;若 g0/1 也同时宣告在和 g0/0 相同的 OSPF 进程…...

数据库技术基础
数据库技术基础 导航 文章目录 数据库技术基础导航一、基础概念数据库系统数据库管理系统DBMS分类数据库技术的发展数据库体系结构 二、数据模型数据模型基本概念 三、数据库的控制功能事务概述SOL中事务定义语句日志文件故障种类两个操作Undo/Redo事务故障的恢复系统故障的恢…...

这些项目,我当初但凡参与一个,现在也不至于还是个程序员
10年前,我刚开始干开发不久,我觉得这真是一个有前景的职业,我觉得我的未来会无限广阔,我觉得再过几年,我一定工资不菲。于是我开始像很多大佬说的那样,开始制定职业规划,并且坚决执行。但过去这…...

ch2应用层--计算机网络期末复习
2.1应用层协议原理 网络应用程序位于应用层 开发网络应用程序: 写出能够在不同的端系统上通过网络彼此通信的程序 2.1.1网络应用程序体系结构分类: 客户机/服务器结构 服务器: 总是打开(always-on)具有固定的、众所周知的IP地址 主机群集常被用于创建强大的虚拟服务器 客…...

弧形导轨精度等级适配策略
弧形导轨是用于实现曲线运动的线性导向装置,广泛应用于自动化设备、机器人、医疗机械等领域。弧形导轨作为机械传动中的核心部件,其精度等级直接影响设备性能与稳定性。从精密加工到重型机械,不同场景对导轨的制造精度、运行精度及耐磨性要求…...

通过 Langchain 框架实现 ChatGPT 的使用
一. 简介Langchain 框架:LangChain 是一个开源框架,是一个让大语言模型(如ChatGPT)能连接外部工具、记忆对话、执行复杂任务的“智能助手”开发框架,解决了LLM应用开发中的各种工程化问题。# LangChain 的核心定位&…...

手把手教你用Python计算斯皮尔曼相关系数:从手动推导到scipy一键调用
深入掌握Python中的斯皮尔曼相关系数:从数学原理到实战应用 在数据分析领域,理解变量之间的关系是至关重要的。斯皮尔曼相关系数作为一种非参数统计量,能够揭示数据间的单调关联,而不仅仅是线性关系。本文将带你从基础概念出发&am…...
Pixel Epic动态卷轴技术揭秘:TextIteratorStreamer流式输出实现原理与调优
Pixel Epic动态卷轴技术揭秘:TextIteratorStreamer流式输出实现原理与调优 1. 引言:像素史诗的独特体验 Pixel Epic(像素史诗)作为一款研究报告辅助终端,最引人注目的特点莫过于其独特的"动态卷轴"输出效果…...

Python高效实现:质因数分解的三种算法对比
1. 质因数分解:从数学概念到Python实现 质因数分解是数学中一个基础但重要的概念。简单来说,就是把一个正整数分解成若干个质数相乘的形式。比如数字28可以分解为227,这里的2和7都是质数,也就是28的质因数。这个概念在密码学、数据…...

如何用快马平台为网站开发公司快速生成企业官网原型,提升方案演示效率
作为一名经常需要快速响应客户需求的网站开发者,我最近发现了一个能大幅提升工作效率的好方法 - 使用InsCode(快马)平台来生成企业官网原型。这个方法特别适合像我们华网三百每年.cn这样需要快速为客户提供方案演示的网站开发公司。 需求分析阶段 当接到一个新客户…...

图深度学习文献宝库LiteratureDL4Graph:一站式掌握图神经网络研究进展
图深度学习文献宝库LiteratureDL4Graph:一站式掌握图神经网络研究进展 【免费下载链接】LiteratureDL4Graph 项目地址: https://gitcode.com/gh_mirrors/li/LiteratureDL4Graph 想要快速掌握图神经网络(GNN)和图深度学习的最新研究进展吗?Litera…...
)
避坑指南:用docker-compose部署Python项目时最容易忽略的5个配置细节(内网特别版)
避坑指南:用docker-compose部署Python项目时最容易忽略的5个配置细节(内网特别版) 在企业级开发中,内网环境下的Docker部署往往比公网场景复杂数倍。我曾亲眼见过一个团队因为时区配置错误导致日志时间全部错乱,排查了…...

单片机:从核心原理到智能应用实战
1. 单片机:智能时代的微型大脑 想象一下清晨醒来,窗帘自动拉开,咖啡机开始工作,室内温度始终保持在最舒适的状态——这些看似简单的智能场景背后,都藏着一个不起眼却至关重要的核心部件:单片机。这块比硬币…...

springboot+vue基于web的电脑配件商城的设计系统
目录 同行可拿货,招校园代理 ,本人源头供货商系统功能模块划分技术架构设计要点特色功能实现路径安全防护措施扩展性考虑 项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作 同行可拿货,招校园代理 ,本人源头供货商 系统功能模块…...