大模型时代的具身智能系列专题(五)
stanford宋舒然团队
宋舒然是斯坦福大学的助理教授。在此之前,他曾是哥伦比亚大学的助理教授,是Columbia Artificial Intelligence and Robotics Lab的负责人。他的研究聚焦于计算机视觉和机器人技术。本科毕业于香港科技大学。
主题相关作品
- diffusion policy
diffusion policy
扩散策略是一种生成机器人行为的新方法,它将机器人的视觉运动策略(visuomotor policy)表示为条件去噪扩散过程(conditional denoising diffusion process)。在 4 个不同的机器人操纵基准中的 15 个不同任务中对 Diffusion Policy 进行了基准测试,发现它平均提高了 46.9%。Diffusion Policy 可以学习动作分布得分函数的梯度(gradient of the action-distribution score),并在推理过程中通过一系列随机Langevin动力学步骤对该梯度场进行迭代优化。扩散公式在用于机器人策略时具有强大的优势,包括可以优雅地处理多模态动作分布、适用于高维动作空间,以及表现出令人印象深刻的训练稳定性。本文提出了一系列关键技术贡献,包括递减视界控制receding horizon control(MPC控制)、视觉调节(visual conditioning)和时间序列扩散transformer。
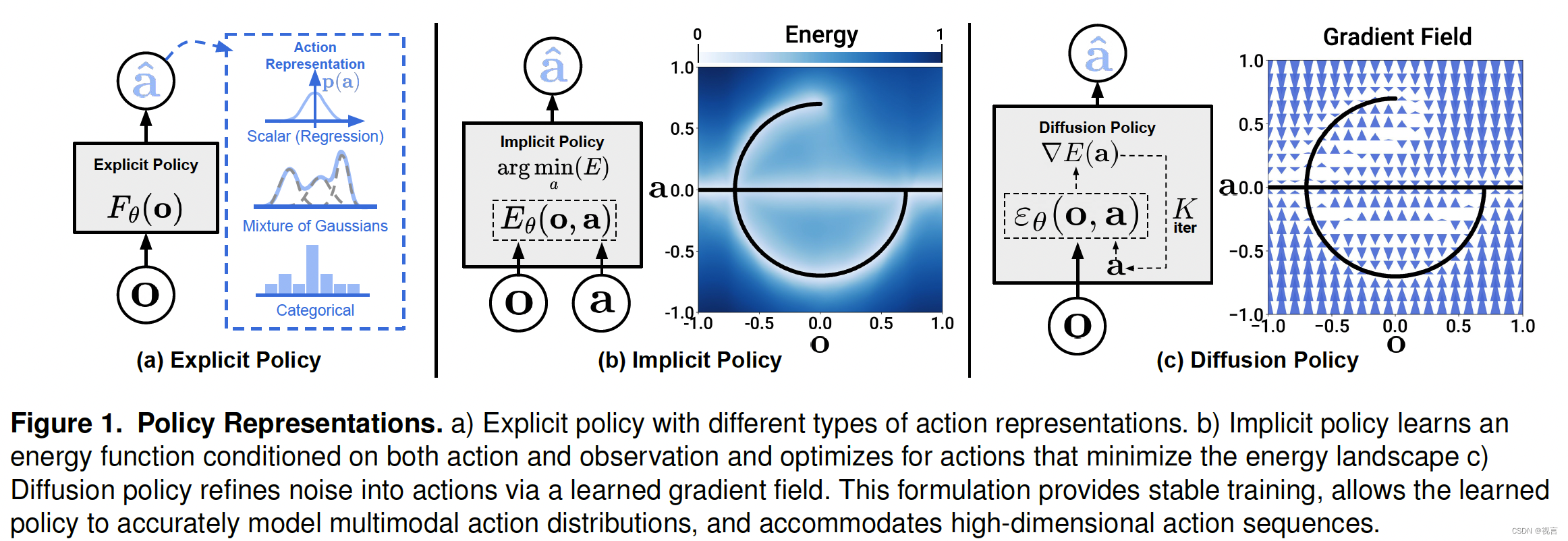
之前的研究试图通过图 1 a)显示策略(高斯混合、量化动作的分类表示法)或者图 1 b)从显式转换为隐式,以更好地捕捉多模态分布。本方法通过引入一种新形式的机器人视觉运动策略来应对这一挑战,即通过 “机器人动作空间上的条件去噪扩散过程”(Diffusion Policy)来生成行为。在这种方法中,策略不是直接输出动作,而是根据视觉观察结果,在 K 次去噪迭代中推导出动作分数梯度(图 1 c)。
扩散模型的几个关键特性:
-
Expressing multimodal action distributions。通过学习动作得分函数的梯度,并在此梯度场上执行随机Langevin动力学采样,扩散策略可以表达任意可归一化分布,其中包括多模态动作分布。
-
High-dimensional output space。扩散模型在高维输出空间中具有卓越的可扩展性。这一特性允许策略联合推断一系列未来行动,而不是单步行动,这对于鼓励时间行动一致性和避免短视的规划至关重要。
-
稳定的训练。训练基于能量的策略通常需要负采样来估计一个难以处理的归一化常数,而这会导致训练的不稳定性。扩散策略通过学习能量函数的梯度绕过了这一要求,从而在保持分布表达性的同时实现了稳定的训练。
Method
将视觉运动机器人策略制定为去噪扩散概率模型(DDPMs)。关键是,扩散策略能够表达复杂的多模态动作分布,并具有稳定的训练行为–几乎不需要针对特定任务进行超参数调整。
Denoising Diffusion Probabilistic Models
DDPM 是一类生成模型,其输出生成被模拟为一个去噪过程,通常称为随机Langevin动力学。
从高斯噪声采样的 x K x^K xK开始,DDPM 执行 K 次迭代去噪,产生一系列噪声水平递减的中间动作 x k , x k − 1 . . . x 0 x^k,x^{k-1}...x^0 xk,xk−1...x0,直到形成所需的无噪声输出 x 0 x^0 x0。该过程遵循公式:
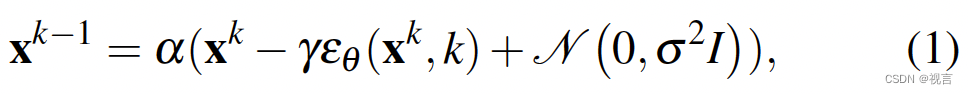
其中, ε θ ε_θ εθ 是噪声预测网络,将通过学习进行优化, N ( 0 , σ 2 ) N(0, σ^2) N(0,σ2)是每次迭代时添加的高斯噪声。上述公式 1 也可以解释为一个单一的噪声梯度下降步骤:
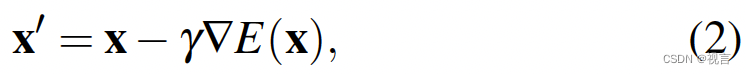
其中噪声预测网络 ε θ ( x , k ) ε_θ (x, k) εθ(x,k) 有效地预测了梯度场 ∇E(x),γ 是学习率。作为迭代步数 k 的函数,α、γ、σ 的选择也称为噪声调度(noise schedule),可以解释为梯度赋值过程中的学习率调度。事实证明,α 略小于 1 可以提高稳定性。
DDPM Training
训练过程的第一步是从数据集中随机抽取未经修改的样本 x 0 x^0 x0。对于每个样本,我们随机选择一个去噪迭代 k,然后为迭代 k 采样一个具有适当方差的随机噪声 ε k ε^k εk。噪声预测网络需要从添加了噪声的数据样本中预测噪声。
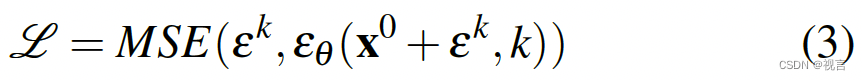
使用均方误差(MSE, Mean Squared Error)作为损失函数,来衡量网络的预测值 ε θ ( x 0 + ε k , k ) ε_θ(x^0+ε^k, k) εθ(x0+εk,k) 和实际噪声 ε k ε^k εk之间的差异。
Diffusion for Visuomotor Policy Learning
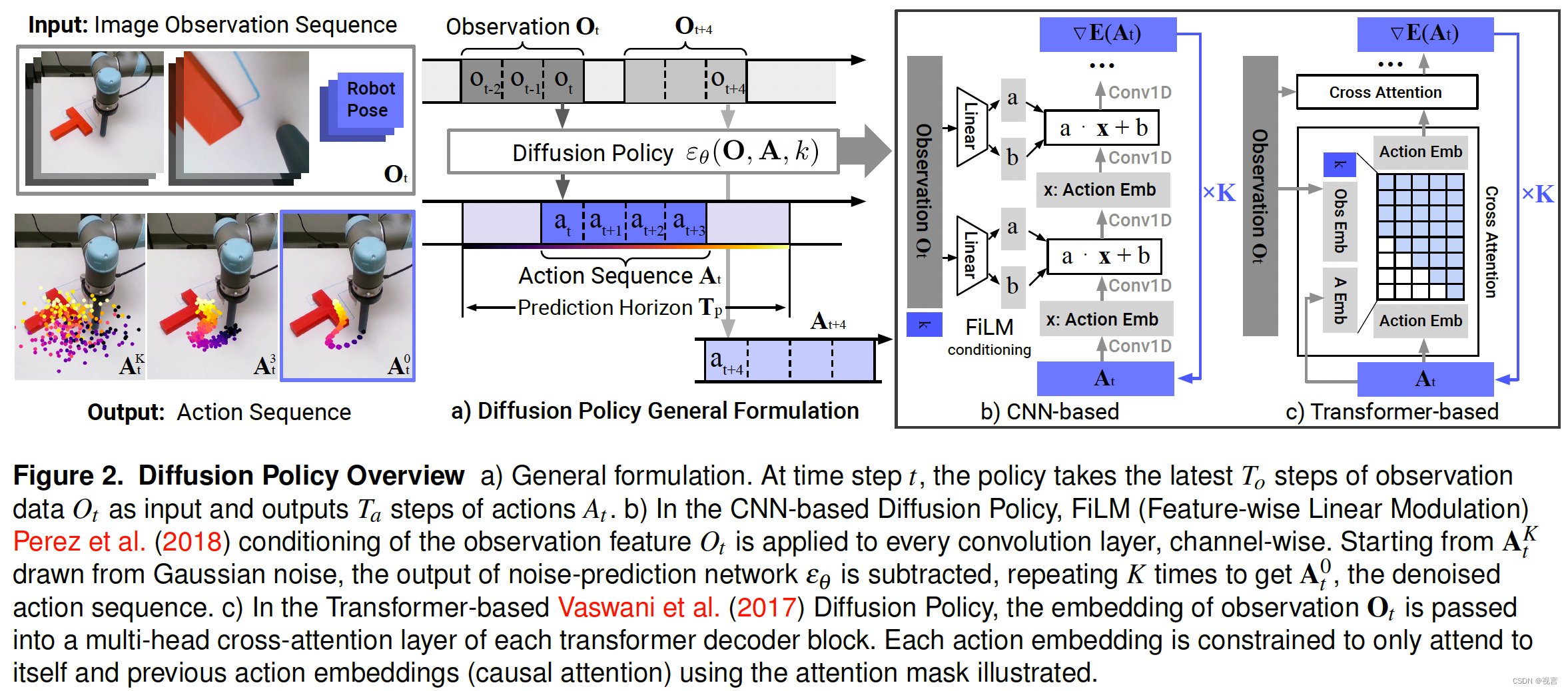
DDPM 通常用于生成图像(x 是一幅图像),使用 DDPM 来学习机器人视觉运动策略需要对公式进行两大修改: 1. 将输出 x 改为代表机器人动作。2. 使去噪过程以输入观测 O t O_t Ot 为条件。图 2 显示了相关概述。
闭环行动序列预测:有效的行动表述应鼓励长视距规划的时间一致性和平稳性,同时允许对意外观察做出迅速反应。为此,在重新规划之前,会在固定时间内使用扩散模型生成的行动序列预测。具体来说,在时间步长 t 处,策略将最新的 T o T_o To 步观测数据 O t O_t Ot 作为输入,并预测出 T p T_p Tp步行动,其中 T a T_a Ta 步行动将在机器人身上执行,无需重新规划。在这里,我们将 T o T_o To 定义为观察期, T p T_p Tp 定义为行动预测期, T a T_a Ta 定义为行动执行期。这样既能保证行动的时间一致性,又能保持反应灵敏。我们还使用receding horizon control通过使用之前的行动序列预测来warm-starting下一个推理设置,从而进一步提高行动的平滑性。
视觉观测条件:我们使用 DDPM 来近似条件分布 p ( A t ∣ O t ) p(A_t |O_t ) p(At∣Ot) 而不是 联合分布 p ( A t , O t ) p(A_t , O_t ) p(At,Ot) 。这种表述方式使模型能够根据观察结果预测行动,而无需付出推断未来状态的代价,从而加快了扩散过程,提高了生成行动的准确性。为了捕捉条件分布 p ( A t ∣ O t ) p(A_t |O_t ) p(At∣Ot),我们将公式 1 修改为:
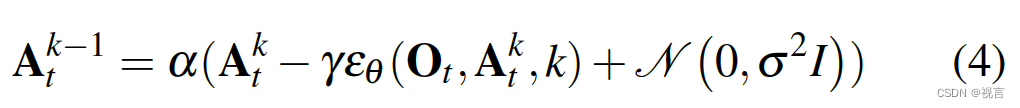
将公式 3 中的训练损失修改为:
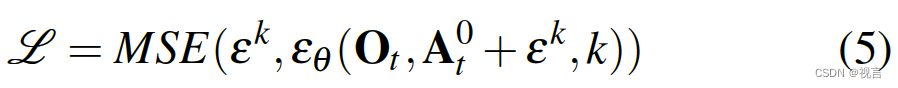
从去噪过程的输出中排除观测特征 Ot 能显著提高推理速度,更好地适应实时控制。这也有助于使视觉编码器的端到端训练。
Key Design Decisions
Network Architecture Options
第一个设计决策是 ε θ ε_θ εθ 的神经网络架构选择。研究了两种常见的网络架构类型:CNNs和Transformers,并比较它们的性能和训练特性。
CNN-based Diffusion Policy。采用Janner et al. 的1D temporal CNN,并做了一些修改:首先,我们只对条件分布 p ( A t ∣ O t ) p(A_t |O_t) p(At∣Ot)进行建模,通过FiLM(Feature-wise Linear Modulation) 和去噪迭代k来调节观察特征 O t O_t Ot上的动作生成过程,如图2 (b)所示。其次,我们只预测动作轨迹,而不预测concat的观察动作轨迹。第三,我们删除了基于绘画的目标状态条件作用,因为它与我们利用超前预测视界的框架不兼容。然而,目标条件作用仍然可能与用于观察的相同的FiLM条件作用方法共用。实际上,基于 CNN 的骨干网络在大多数任务中都能很好地运行,无需进行过多的超参数调整。然而,当所需的动作序列随时间发生快速而剧烈的变化时(如速度指令动作空间),它的表现就会很差,这可能是由于时间卷积偏好低频信号的归纳偏差 。
Time-series diffusion transformer。为了减少CNN模型Tancik et al.中的过平滑效应,我们引入了一种新的基于transformer的DDPM,该模型采用minGPT Shafiullah et al.的变压器架构进行动作预测。带有噪声 A t k A^k_t Atk的动作作为transformer解码器块的输入tokens传入,扩散迭代k的正弦嵌入作为第一个token。通过共享MLP将观测值 O t O_t Ot转化为观测值嵌入序列,作为输入特征传递到transformer解码器堆栈中。“梯度” ε θ ( O t , A t k , k ) ε_θ (O_t,A_t^k,k) εθ(Ot,Atk,k)由解码器堆栈的每个相应输出tokens预测。在基于状态的实验中,大多数表现最佳的策略都是通过transformer主干实现的,尤其是在任务复杂度和行动变化率较高的情况下。然而,我们发现transformer对超参数更为敏感。未来有可能通过改进transformer训练技术或扩大数据规模来解决。
Recommendations。一般建议从基于 CNN 的扩散策略实施开始,作为新任务的首次尝试。如果由于任务复杂或动作变化率高而导致性能低下,则可以使用Time-series diffusion transformer来提高性能,但需要付出额外的tuning代价。
Visual Encoder
视觉编码器将原始图像序列映射为潜在嵌入 O t O_t Ot,并使用扩散策略进行端到端训练。不同的摄像机视角使用不同的编码器,每个时间步中的图像独立编码,然后串联形成 O t O_t Ot。我们使用标准 ResNet-18(无预训练)作为编码器,并做了以下修改: 1) 用spatial softmax pooling取代全局平均池化(global average pooling),以保持空间信息。2) 用 GroupNorm 取代 BatchNorm ,以获得稳定的训练。当归一化层与指数移动平均(Exponential Moving Average)结合使用时,这一点非常重要 (常用于 DDPMs)。
Noise Schedule
噪声表由 σ、α、γ 和加性高斯噪声 ε k ε^k εk 定义,是 k 的函数,Ho 等人(2020 年)、Nichol 和 Dhariwal(2021 年)对噪声表进行了积极研究。基本噪声表控制着扩散策略捕捉动作信号高频和低频特征的程度。在我们的控制任务中,我们根据经验发现,iDDPM中提出的平方余弦时间表(Square Cosine Schedule)最适合我们的任务。
Accelerating Inference for Real-time Control
我们使用扩散过程作为机器人的策略;因此,对于闭环实时控制来说,拥有快速的推理速度至关重要。Song 等人(2021 年)提出的去噪扩散隐含模型(DDIM)方法将训练和推理中的去噪迭代次数分离开来,从而允许算法使用较少的推理迭代次数来加快推理过程。在我们的实际实验中,使用 100 次训练迭代和 10 次推理迭代的 DDIM,可以在 Nvidia 3080 GPU 上实现 0.1 秒的推理延迟。
Intriguing Properties of Diffusion Policy
Model Multi-Modal Action Distributions
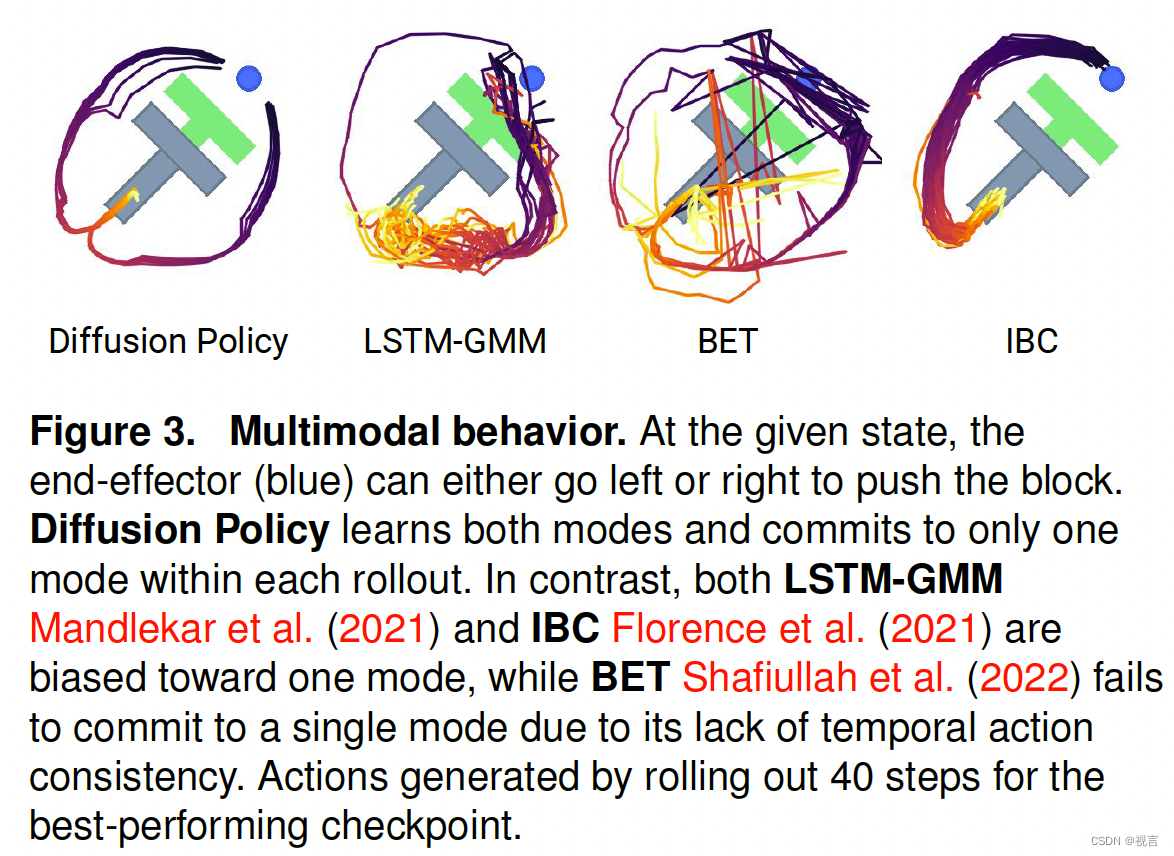
扩散策略的多模态行为产生有两个来源——潜在的随机抽样过程和随机初始化。在随机朗之万动力学中,在每个采样过程开始时从标准高斯中提取初始样本 A t K A^K_t AtK,这有助于为最终动作预测 A t 0 A^0_t At0指定不同可能的收敛盆地。然后,该动作进一步随机优化,在大量迭代中添加高斯扰动,这使得单个动作样本能够收敛并在不同的多模态动作盆地之间移动。图3显示了平面推送任务(Push T)中扩散策略的多模态行为示例,没有对测试场景进行明确演示。
Synergy with Position Control
我们发现具有位置控制动作空间的扩散策略始终优于具有速度控制的扩散策略,如图4所示。这一令人惊讶的结果与最近大多数依赖于速度控制的行为克隆工作形成了鲜明对比。
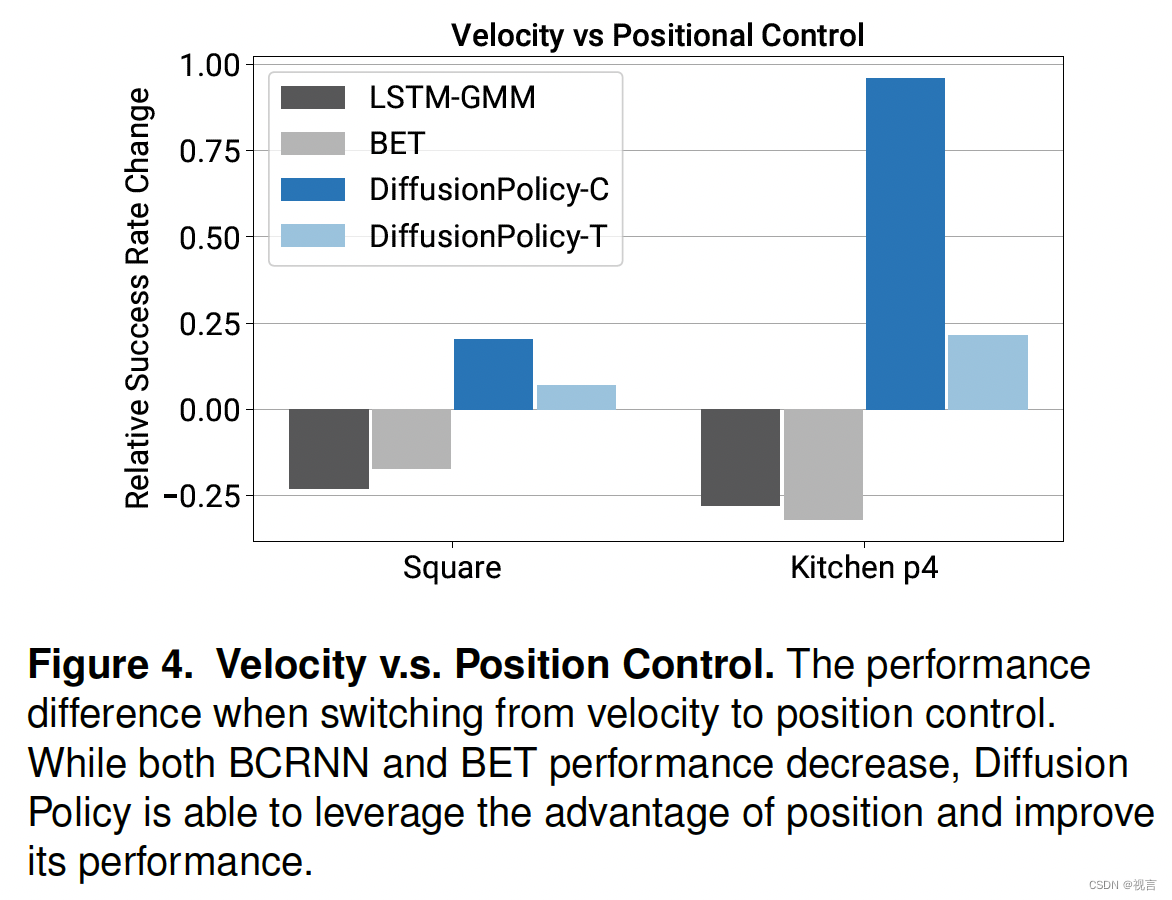
我们推测这种差异有两个主要原因:首先,动作多模态在位置控制模式下比在使用速度控制模式下更为明显。由于扩散策略比现有方法更好地表达了行动多模态,我们推测它本质上比现有方法受这一缺陷的影响更小。此外,位置控制比速度控制受复合误差效应的影响更小,因此更适合于动作序列预测(如下节所述)。因此,扩散策略既不受位置控制的主要缺点的影响,又能更好地利用位置控制的优点。
Benefits of Action-Sequence Prediction
由于难以从高维输出空间中有效采样,大多数策略学习方法往往避免了序列预测。例如,IBC在对具有非平滑能量landscape的高维动作空间进行有效采样时会遇到困难。类似地,BCRNNand和BET也难以指定动作分布中存在的模式数(需要gmm或k-means步长)。相反,DDPM可以很好地扩展输出维度,而不会牺牲模型的表达性,这在许多图像生成应用程序中得到了证明。利用这种能力,扩散策略以高维动作序列的形式表示动作,它自然地解决了以下问题:
- 时间动作一致性:以图3为例。为了将T块从底部推入目标,策略可以从左侧或右侧绕过T块。然而,假设序列中的每个动作都被预测为独立的多模态分布(如在BCRNNand BET中所做的那样)。在这种情况下,连续的动作可以从不同的模式中绘制出来,导致在两个有效轨迹之间交替的抖动动作。
- 对空闲动作的鲁棒性:当演示暂停时,会发生空闲动作,并导致一系列相同的位置动作或接近零速度的动作。它在远程操作中很常见,像液体倾倒这样的任务有时就需要。然而,单步策略很容易过度适应这种暂停行为。例如,BC-RNN和IBC经常在现实世界的实验中陷入困境,因为没有明确地从训练中移除空闲动作。
相关文章:
大模型时代的具身智能系列专题(五)
stanford宋舒然团队 宋舒然是斯坦福大学的助理教授。在此之前,他曾是哥伦比亚大学的助理教授,是Columbia Artificial Intelligence and Robotics Lab的负责人。他的研究聚焦于计算机视觉和机器人技术。本科毕业于香港科技大学。 主题相关作品 diffusio…...
基于springboot+vue的社区医院管理服务系统
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:…...

车载电子电器架构 —— 智能座舱标准化意义
车载电子电器架构 —— 智能座舱标准化意义 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消…...

Compose在xml中使用滑动冲突处理
一、背景 在现有Android项目中使用Compose可能存在滑动冲突问题,例如 SmartRefreshLayoutCoordinatorLayoutComposeView(ComposeView这里又是一个LazyColumn) 二、解决方案 官方介绍:https://developer.android.google.cn/develop/ui/compose/touch-inp…...
微信网页版登录插件v1.1.1
说到如今的微信客户端,大家肯定会有很多提不完的意见或者建议。比如这几年体积越来越大,如果使用频率比较高,那占用空间就更离谱了。系统迷见过很多人电脑C盘空间爆满,都是由于微信PC版造成的。 而且,它还加了很多乱七…...

华为实训课笔记 2024
华为实训 5/205/215/225/235/275/28 5/20 5/21 5/22 5/23 5/27 5/28...

HTML静态网页成品作业(HTML+CSS)——宠物狗介绍网页(3个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有3个页面。 二、作品演示 三、代…...
网络模型-路由策略
一、路由策略 路由策略(Routing Policy)作用于路由,主要实现了路由过滤和路由属性设置等功能,它通过改变路由属性(包括可达性)来改变网络流量所经过的路径。目的:设备在发布、接收和引入路由信息时,根据实际组网需要实施一些策略,…...
-锁和事务模型)
【MySQL精通之路】InnoDB(7)-锁和事务模型
1.InnoDB锁 【MySQL精通之路】InnoDB(7)-锁和事务模型(1)-锁-CSDN博客 2.InnoDB事务模型 【MySQL精通之路】InnoDB(7)-锁和事务模型(2)-事务模型-CSDN博客 3.InnoDB中不同SQL语句设置的锁 4.幻影行 5.InnoDB中的死锁 5.1InnoDB死锁示例 5.2死锁检测 …...
深度学习创新点不大但有效果,可以发论文吗?
深度学习中创新点比较小,但有效果,可以发论文吗?当然可以发,但如果想让编辑和审稿人眼前一亮,投中更高区位的论文,写作永远都是重要的。 那么怎样“讲故事”才能让论文更有吸引力?我总结了三点…...

【ARM Cache 系列文章 7.1 – ARMv8/v9 MMU 页表配置详细介绍 02 】
文章目录 Translation table descriptorTable descriptor format页面粒度和地址长度粒度(Granules)48位和52位地址TCR_ELx.DSVTCR_EL2.DSFEAT_LPA块描述符|页描述符紧接上篇文章【ARM Cache 系列文章 7 – ARMv8/v9 MMU 页表配置 01 】 Translation table descriptor</...

Mysql搭建主从同步,docker方式(一主一从)
服务器:两台Centos9 用Docker搭建主从 使用Docker拉取MySQL镜像 确保两台服务器都安装好了docker 安装docker请查看:Centos安装docker 1.两台服务器都先拉取mysql镜像 docker pull mysql 2.我这里是在 /opt/docker/mysql 下创建mysql的文件夹用来存…...
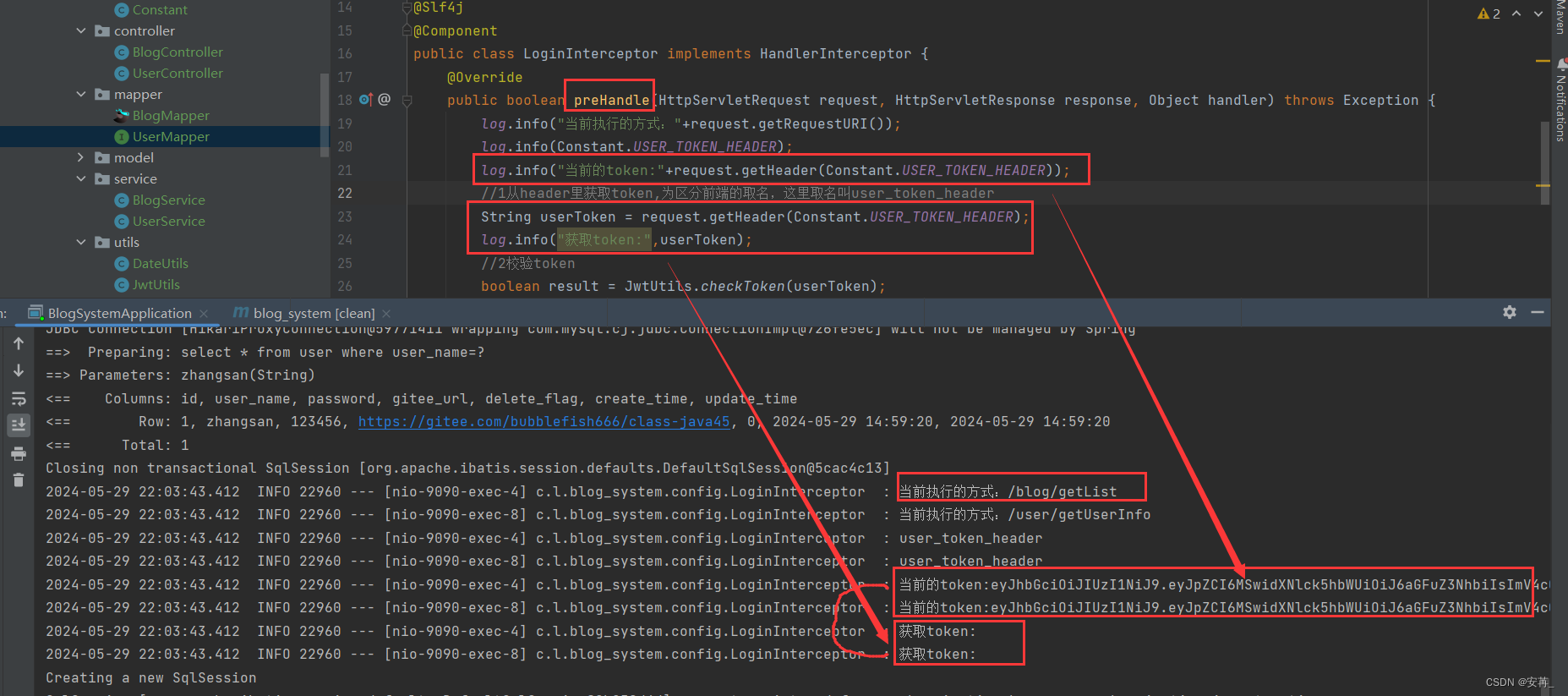
【已解决】使用token登录机制,token获取不到,blog_list.html界面加载不出来
Bug产生 今天使用token完成用户登录信息的存储的时候被卡了大半天。 因为登录的功能写的已经很多了,所以今天就没有写一点验一点,而是在写完获取博客列表功功能,验证完它的后端后,了解完令牌的基本使用以及Jwt的基本使用方式——…...

【Linux 网络编程】网络的基础知识详解!
文章目录 1. 计算机网络背景2. 认识 "协议" 1. 计算机网络背景 网络互联: 多台计算机连接在一起, 完成数据共享; 🍎局域网(LAN----Local Area Network): 计算机数量更多了, 通过交换机和路由器连接。 🍎 广域网WAN: 将…...
Nacos 2.x 系列【12】配置加密插件
文章目录 1. 前言2. 安装插件2.1 编译2.2 客户端2.3 服务端 3. 测试 1. 前言 为保证用户敏感配置数据的安全,Nacos提供了配置加密的新特性。降低了用户使用的风险,也不需要再对配置进行单独的加密处理。 前提条件: 版本:老版本暂时不兼容&…...
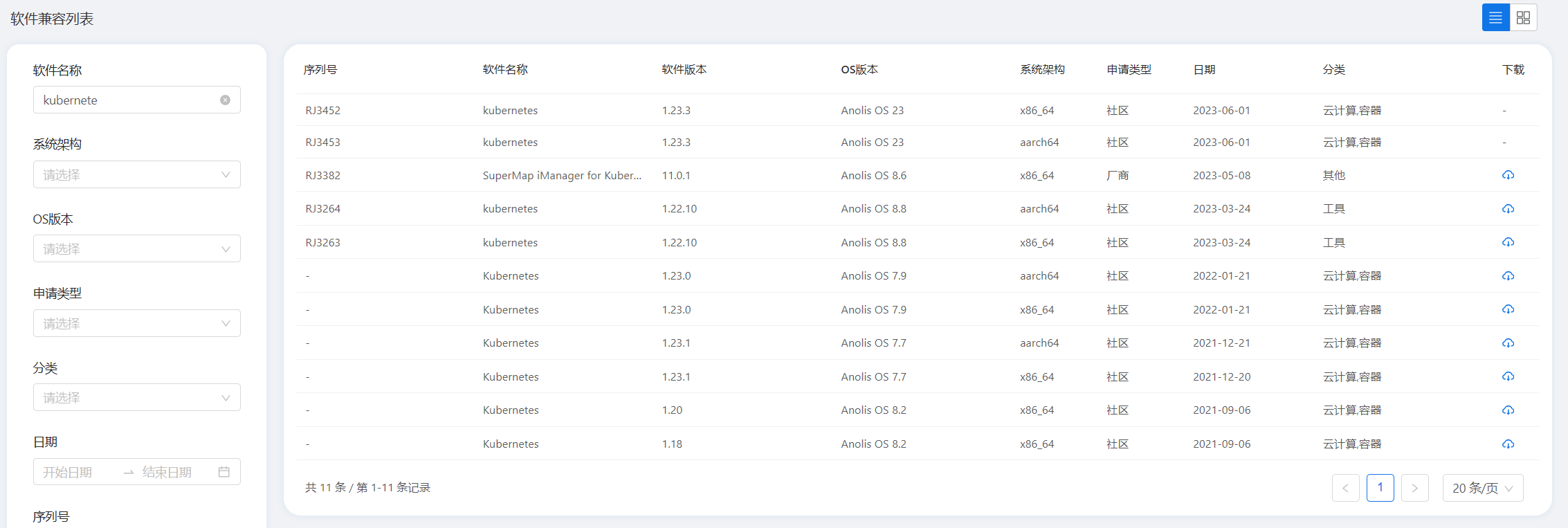
Kubernetes和Docker对不同OS和CPU架构的适配关系
Docker Docker官网对操作系统和CPU架构的适配关系图 对于其他发行版本,Docker官方表示没有测试或验证在相应衍生发行版本上的安装,并建议针对例如Debian、Ubuntu等衍生发行版本上使用官方的对应版本。 Kubernetes X86-64 ARM64 Debian系 √ √ Re…...
LabVIEW机器设备的振动监测
振动监测是工业和机械维护中重要的一部分,通过检测和分析机械振动,提前发现潜在故障,确保设备的可靠运行。LabVIEW是一种强大的图形化编程环境,非常适合用于振动监测系统的开发和实施。以下从多个角度详细介绍LabVIEW在振动监测中…...

FreeRTOS学习笔记-基于stm32(7)任务状态查询与任务时间统计API函数
1、FreeRTOS任务相关API函数 函数描述uxTaskPriorityGet()查询某个任务的优先级vTaskPrioritySet()改变某个任务的任务优先级uxTaskGetSystemState()获取系统中任务状态vTaskGetInfo()获取某个任务信息xTaskGetApplicationTaskTag()获取某个任务的标签(Tag)值xTaskGetCurrentT…...

Flutter 中的 ElevatedButton 小部件:全面指南
Flutter 中的 ElevatedButton 小部件:全面指南 Flutter 提供了多种按钮小部件,每种都有其独特的用途和样式。ElevatedButton 是其中一种,它代表了具有凸起效果的按钮,通常用于 Material Design 风格的应用中。本文将为您提供一个…...
huggingface的self.state与self.control来源(TrainerState与TrainerControl)
文章目录 前言一、huggingface的trainer的self.state与self.control初始化调用二、TrainerState源码解读(self.state)1、huggingface中self.state初始化参数2、TrainerState类的Demo 三、TrainerControl源码解读(self.control)总结 前言 在 Hugging Face 中,self.s…...

开源TeslaMate:重新定义特斯拉数据监控与分析体验
开源TeslaMate:重新定义特斯拉数据监控与分析体验 【免费下载链接】teslamate teslamate-org/teslamate: TeslaMate 是一个开源项目,用于收集特斯拉电动汽车的实时数据,并存储在数据库中以便进一步分析和可视化。该项目支持监控车辆状态、行驶…...

如何彻底解决Cursor API限制问题:从免费到Pro的完整指南
如何彻底解决Cursor API限制问题:从免费到Pro的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...

CIC-IDS-2018数据集 代码预处理
CIC-IDS-2018数据集 预处理 数据集的获取地址在 https://aistudio.baidu.com/datasetdetail/60692 第一次登陆,注册就行,内容随便填就能注册 create_sample_data() 在代码中被注释,没有添加数据之前,可以跑一下这个函数&…...

南北阁Nanbeige 4.1-3B Git版本控制实战:从入门到团队协作
南北阁Nanbeige 4.1-3B Git版本控制实战:从入门到团队协作 本文面向刚接触版本控制的开发者,手把手教你用南北阁Nanbeige 4.1-3B掌握Git核心技能,从基础命令到团队协作全流程。 1. 为什么你需要Git版本控制? 刚开始写代码时&…...

drprov.dll文件丢失找不到 免费下载修复方法分享
在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC运行库或者安装…...

HAL库定时器双杀技:STM32F401CCU6同时实现PWM输出+输入捕获的避坑指南
HAL库定时器双杀技:STM32F401CCU6同时实现PWM输出输入捕获的避坑指南 在嵌入式开发中,定时器是最基础也最强大的外设之一。对于STM32F4系列微控制器,HAL库提供了丰富的定时器功能,但如何在同一芯片上同时实现PWM输出和输入捕获&am…...

XCOM 2模组管理终极解决方案:AML启动器效率革命指南
XCOM 2模组管理终极解决方案:AML启动器效率革命指南 【免费下载链接】xcom2-launcher The Alternative Mod Launcher (AML) is a replacement for the default game launchers from XCOM 2 and XCOM Chimera Squad. 项目地址: https://gitcode.com/gh_mirrors/xc/…...

手把手教你优化SiC MOSFET模块:从铜带键合到双面散热的5个关键技术
SiC MOSFET功率模块封装优化实战:五大关键技术深度解析 在电力电子领域,碳化硅(SiC)MOSFET功率模块正逐步取代传统硅基IGBT,成为高效率、高功率密度应用的首选。然而,要充分发挥SiC材料的性能优势,封装技术面临前所未…...

别再只会复制代码了!用CubeMX配置STM32F407的PWM驱动TB6612,从原理到实战一次搞懂
从零构建PWM电机控制系统:STM32F407与TB6612的深度实践指南 引言:为什么你需要摆脱复制粘贴的陷阱 在实验室里,我见过太多学生面对电机控制项目时的第一反应——打开搜索引擎,寻找"STM32 PWM驱动电机代码",然…...
的实战技巧)
告别BibTeX混乱:在LaTeX中精准控制单条参考文献格式(颜色、字体)的实战技巧
告别BibTeX混乱:在LaTeX中精准控制单条参考文献格式(颜色、字体)的实战技巧 学术写作中,参考文献的视觉呈现往往被忽视。当审稿人要求"突出显示新增文献"时,当需要区分自己的前期工作与奠基性研究时&#x…...