搭建YOLOv10环境 训练+推理+模型评估
文章目录
- 前言
- 一、环境搭建
- 必要环境
- 1. 创建yolov10虚拟环境
- 2. 下载pytorch (pytorch版本>=1.8)
- 3. 下载YOLOv10源码
- 4. 安装所需要的依赖包
- 二、推理测试
- 1. 将如下代码复制到ultralytics文件夹同级目录下并运行 即可得到推理结果
- 2. 关键参数
- 三、训练及评估
- 1. 数据结构介绍
- 2. 配置文件修改
- 3. 训练/评估模型
- 4. 关键参数
- 5. 单独对训练好的模型将进行评估
- 总结
前言
本文将详细介绍跑通YOLOv10的流程,并给各位提供用于训练、评估和模型推理的脚本一、环境搭建
必要环境
本文使用Windows10+Python3.8+CUDA10.2+CUDNN8.0.4作为基础环境,使用30系或40系显卡的小伙伴请安装11.0以上版本的CUDA
1. 创建yolov10虚拟环境
conda create -n yolov10 python=3.8
2. 下载pytorch (pytorch版本>=1.8)
pip install torch==1.9.1+cu102 torchvision==0.10.1+cu102 torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
若使用的是AMD显卡或不使用GPU的同学 可以通过以下命令可以安装CPU版本
pip install torch==1.9.1+cpu torchvision==0.10.1+cpu torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
3. 下载YOLOv10源码
地址:https://github.com/THU-MIG/yolov10
4. 安装所需要的依赖包
pip install -r requirements.txt
二、推理测试
1. 将如下代码复制到ultralytics文件夹同级目录下并运行 即可得到推理结果
import cv2
from ultralytics import YOLOv10
import os
import argparse
import time
import torchparser = argparse.ArgumentParser()
# 检测参数
parser.add_argument('--weights', default=r"yolov10n.pt", type=str, help='weights path')
parser.add_argument('--source', default=r"images", type=str, help='img or video(.mp4)path')
parser.add_argument('--save', default=r"./save", type=str, help='save img or video path')
parser.add_argument('--vis', default=True, action='store_true', help='visualize image')
parser.add_argument('--conf_thre', type=float, default=0.5, help='conf_thre')
parser.add_argument('--iou_thre', type=float, default=0.5, help='iou_thre')
opt = parser.parse_args()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')def get_color(idx):idx = idx * 3color = ((37 * idx) % 255, (17 * idx) % 255, (29 * idx) % 255)return colorclass Detector(object):def __init__(self, weight_path, conf_threshold=0.5, iou_threshold=0.5):self.device = deviceself.model = YOLOv10(weight_path)self.conf_threshold = conf_thresholdself.iou_threshold = iou_thresholdself.names = {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train',7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign',12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep',19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella',26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard',32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard',37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork',43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange',50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair',57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv',63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave',69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase',76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}def detect_image(self, img_bgr):results = self.model(img_bgr, verbose=True, conf=self.conf_threshold,iou=self.iou_threshold, device=self.device)bboxes_cls = results[0].boxes.clsbboxes_conf = results[0].boxes.confbboxes_xyxy = results[0].boxes.xyxy.cpu().numpy().astype('uint32')for idx in range(len(bboxes_cls)):box_cls = int(bboxes_cls[idx])bbox_xyxy = bboxes_xyxy[idx]bbox_label = self.names[box_cls]box_conf = f"{bboxes_conf[idx]:.2f}"xmax, ymax, xmin, ymin = bbox_xyxy[2], bbox_xyxy[3], bbox_xyxy[0], bbox_xyxy[1]img_bgr = cv2.rectangle(img_bgr, (xmin, ymin), (xmax, ymax), get_color(box_cls + 3), 2)cv2.putText(img_bgr, f'{str(bbox_label)}/{str(box_conf)}', (xmin, ymin - 10),cv2.FONT_HERSHEY_SIMPLEX, 0.5, get_color(box_cls + 3), 2)return img_bgr# Example usage
if __name__ == '__main__':model = Detector(weight_path=opt.weights, conf_threshold=opt.conf_thre, iou_threshold=opt.iou_thre)images_format = ['.png', '.jpg', '.jpeg', '.JPG', '.PNG', '.JPEG']video_format = ['mov', 'MOV', 'mp4', 'MP4']if os.path.join(opt.source).split(".")[-1] not in video_format:image_names = [name for name in os.listdir(opt.source) for item in images_format ifos.path.splitext(name)[1] == item]for img_name in image_names:img_path = os.path.join(opt.source, img_name)img_ori = cv2.imread(img_path)img_vis = model.detect_image(img_ori)img_vis = cv2.resize(img_vis, None, fx=1.0, fy=1.0, interpolation=cv2.INTER_NEAREST)cv2.imwrite(os.path.join(opt.save, img_name), img_vis)if opt.vis:cv2.imshow(img_name, img_vis)cv2.waitKey(0)cv2.destroyAllWindows()else:capture = cv2.VideoCapture(opt.source)fps = capture.get(cv2.CAP_PROP_FPS)size = (int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)),int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)))fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')outVideo = cv2.VideoWriter(os.path.join(opt.save, os.path.basename(opt.source).split('.')[-2] + "_out.mp4"),fourcc,fps, size)while True:ret, frame = capture.read()if not ret:breakstart_frame_time = time.perf_counter()img_vis = model.detect_image(frame)# 结束计时end_frame_time = time.perf_counter() # 使用perf_counter进行时间记录# 计算每帧处理的FPSelapsed_time = end_frame_time - start_frame_timeif elapsed_time == 0:fps_estimation = 0.0else:fps_estimation = 1 / elapsed_timeh, w, c = img_vis.shapecv2.putText(img_vis, f"FPS: {fps_estimation:.2f}", (10, 35), cv2.FONT_HERSHEY_SIMPLEX, 1.3, (0, 0, 255), 2)outVideo.write(img_vis)cv2.imshow('detect', img_vis)cv2.waitKey(1)capture.release()outVideo.release()2. 关键参数
1. 测试图片:–source 变量后填写图像文件夹路径 如:default=r"images"
2. 测试视频:–source 变量后填写视频路径 如:default=r"video.mp4"
推理图像效果:

推理视频效果:
三、训练及评估
1. 数据结构介绍
这里使用的数据集是VOC2007,用留出法将数据按9:1的比例划分成了训练集和验证集
下载地址如下:
链接:https://pan.baidu.com/s/1FmbShVF1SQOZfjncj3OKJA?pwd=i7od
提取码:i7od
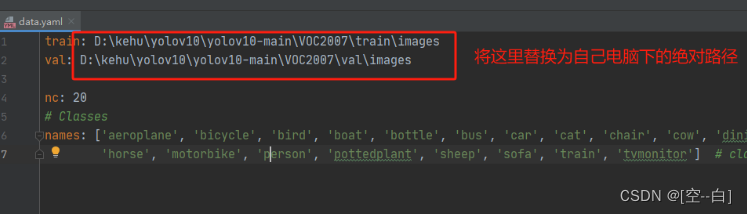
2. 配置文件修改
3. 训练/评估模型
将如下代码复制到ultralytics文件夹同级目录下并运行 即可开始训练
# -*- coding:utf-8 -*-
from ultralytics import YOLOv10
import argparse# 解析命令行参数
parser = argparse.ArgumentParser(description='Train or validate YOLO model.')
# train用于训练原始模型 val 用于得到精度指标
parser.add_argument('--mode', type=str, default='train', help='Mode of operation.')
# 预训练模型
parser.add_argument('--weights', type=str, default='yolov10n.pt', help='Path to model file.')
# 数据集存放路径
parser.add_argument('--data', type=str, default='VOC2007/data.yaml', help='Path to data file.')
parser.add_argument('--epoch', type=int, default=200, help='Number of epochs.')
parser.add_argument('--batch', type=int, default=8, help='Batch size.')
parser.add_argument('--workers', type=int, default=0, help='Number of workers.')
parser.add_argument('--device', type=str, default='0', help='Device to use.')
parser.add_argument('--name', type=str, default='', help='Name data file.')
args = parser.parse_args()def train(model, data, epoch, batch, workers, device, name):model.train(data=data, epochs=epoch, batch=batch, workers=workers, device=device, name=name)def validate(model, data, batch, workers, device, name):model.val(data=data, batch=batch, workers=workers, device=device, name=name)def main():model = YOLOv10(args.weights)if args.mode == 'train':train(model, args.data, args.epoch, args.batch, args.workers, args.device, args.name)else:validate(model, args.data, args.batch, args.workers, args.device, args.name)if __name__ == '__main__':main()4. 关键参数
1. 模式选择:
–mode train: 开始训练模型
–mode val: 进行模型验证
2. 训练轮数: 通过 --epoch 参数设置训练轮数,默认为200轮。该参数控制模型在训练集上迭代的次数,增加轮数有助于提升模型性能,但同时也会增加训练时间。
3. 训练批次: 通过 --batch 参数设置训练批次大小,一般设置为2的倍数,如8或16。批次大小决定了每次参数更新时使用的样本数量,较大的批次有助于加速收敛,但会增加显存占用,需根据实际显存大小进行调整
4. 训练数据加载进程数: 通过 --workers 参数设置数据加载进程数,默认为8。该参数控制了在训练期间用于加载和预处理数据的进程数量。增加进程数可以加快数据的加载速度,linux系统下一般设置为8或16,windows系统设置为0。
训练过程:
训练结束后模型已经训练过程默认会保存到runs/detect/exp路径下
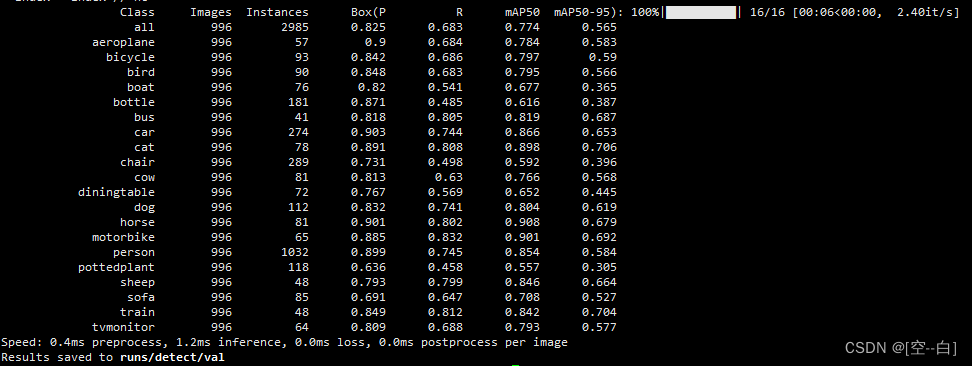
5. 单独对训练好的模型将进行评估
1. 将 --mode变量后改为val 如:default=“val”
2. 将 --weights变量后改为要单独评估的模型路径 如:default=r"runs/detect/exp/weights/best.pt"
评估过程:
总结
yolo是真卷呐,版本号一会儿一变的,v9还没看呢v10已经出来了…
最近经常在b站上更新一些有关目标检测的视频,大家感兴趣可以来看看 https://b23.tv/1upjbcG
学习交流群:995760755
相关文章:
搭建YOLOv10环境 训练+推理+模型评估
文章目录 前言一、环境搭建必要环境1. 创建yolov10虚拟环境2. 下载pytorch (pytorch版本>1.8)3. 下载YOLOv10源码4. 安装所需要的依赖包 二、推理测试1. 将如下代码复制到ultralytics文件夹同级目录下并运行 即可得到推理结果2. 关键参数 三、训练及评估1. 数据结构介绍2. 配…...

c++(一)
c(一) C与C有什么区别命名空间使用 输入输出流引用指针和引用的区别定义拓展 函数重载例子测试函数重载原理 参数默认值什么是参数默认值注意 在c中如何引入c的库动态内存分配new、delete与malloc、free的区别? C与C有什么区别 <1>都是…...

java面试中高频问题----1
一、乐观锁和悲观锁定义、场景怎么判断用什么? 1.乐观锁: 定义:乐观锁假设大多数情况下,资源不会发生冲突。因此,允许多个线程同时访问资源。 场景:读操作多,写操作少,数据冲突概率…...

ABB 控制柜
1,主计算机:相当于电脑的主机,用于存放系统和数据,需要24V直流电才能工作。执行用户编写的程序,控制机器人进行响应的动作。主计算机有很多接口,比如与编程PC连接的服务网口、用于连接示教器的网口、连接轴…...
【错误记录】HarmonyOS 运行报错 ( Failure INSTALL_PARSE_FAILED_USESDK_ERROR )
文章目录 一、报错信息二、问题分析三、解决方案 一、报错信息 在 DevEco Studio 中 , 使用 远程设备 , 向 P40 Failure[INSTALL_PARSE_FAILED_USESDK_ERROR] compileSdkVersion and releaseType of the app do not match the apiVersion and releaseType on the device. 二、…...

使用C语言openssl库实现 RSA加密 和 消息验证
Q:什么是RSA? A:RSA(Rivest-Shamir-Adleman)是一种非对称加密算法,是最早的一种用于公开密钥加密和数字签名的算法。它使用一对公钥(public key)和私钥(private key&…...

海外投放面试手册
海外投放面试手册 岗位职责: 负责Google 、Facebook、TikTok、Twitter等海外主流广告平台的自主投放操作及合作渠道沟通;负责海外合作渠道媒体的广告投放管理、媒体数据监测、效果分析、优化调整等工作; 3.了解海外各渠道&…...
第十三章 进程与线程
第十三章 进程与线程 程序与进程的概念 程序: 英文单词为Program,是指一系列有序指令的集合,使用编程语言所编写,用于实现一定的功能。 进程: 进程则是指启动后的程序,系统会为进程分配内存空间。 函数式…...
、状态后端选择和调优等有所了解)
Flink面试整理-对Flink的高级特性如CEP(复杂事件处理)、状态后端选择和调优等有所了解
Apache Flink 提供了一系列高级特性,使其成为一个强大的实时数据处理框架,特别适用于复杂的数据处理场景。其中,复杂事件处理(CEP)、状态后端的选择和调优是其中重要的几个方面。 复杂事件处理(CEP) CEP 概念:CEP 是用于在数据流中识别复杂模式的技术。它允许用户指定事…...

算法:树状数组
文章目录 面试题 10.10. 数字流的秩327. 区间和的个数315. 计算右侧小于当前元素的个数 树状数组可以理解一种数的存储格式。 面试题 10.10. 数字流的秩 假设你正在读取一串整数。每隔一段时间,你希望能找出数字 x 的秩(小于或等于 x 的值的个数)。 请实现数据结构…...

Kafka SASL_SSL集群认证
背景 公司需要对kafka环境进行安全验证,目前考虑到的方案有Kerberos和SSL和SASL_SSL,最终考虑到安全和功能的丰富度,我们最终选择了SASL_SSL方案。处于知识积累的角度,记录一下kafka SASL_SSL安装部署的步骤。 机器规划 目前测试环境公搭建了三台kafka主机服务,现在将详…...
同城交友论坛静态页面app Hbuild
关注...

spring session+redis存储session,实现用户登录功能,并在拦截器里面判断用户session是否过期,过期就跳转到登录页面
在Spring应用中,使用Redis存储Session是一种常见的方式,可以实现分布式环境下的Session管理。以下是实现用户登录功能,并在拦截器中判断Session是否过期并跳转到登录页面的基本步骤: 添加依赖:首先,确保你的…...

Debug-013-el-loading中显示倒计时时间
前言: 今天实现一个小小的优化,业务上是后端需要从设备上拿数据,所以前端需要不断调用一个查询接口,直到后端数据获取完毕,前后端根据一个ending字段为true判断停止调用查询接口。由于这个查询时间比较久&…...

5月29日,每日信息差
第一、据悉,微信视频号直播电商团队将并入到微信开放平台(小程序、公众号等)团队,原微信视频号直播电商团队转由微信开放平台负责人负责。知情人士表示,此次调整,将有助于微信视频号直播电商业务更好地融入…...

2024年弘连网络FIC大会竞赛题线下决赛题
总结: FIC决赛的时候,很多小问题没发现,在pve平台做题确实很方便。 这套题目复盘完,服务器这块的知识确实收获了很多,对pve集群平台和网络拓扑也有了一定的认识,感谢各位大佬悉心指导。 接下来࿰…...

Element-UI 入门指南:从安装到自定义主题的详细教程
Element-UI 是一个基于 Vue.js 的前端组件库,它提供了丰富的 UI 组件,可以帮助开发者快速构建高质量的用户界面。以下是使用 Element-UI 的快速入门指南: 安装 Element-UI Element-UI 是一个基于 Vue.js 的组件库,它提供了丰富的…...
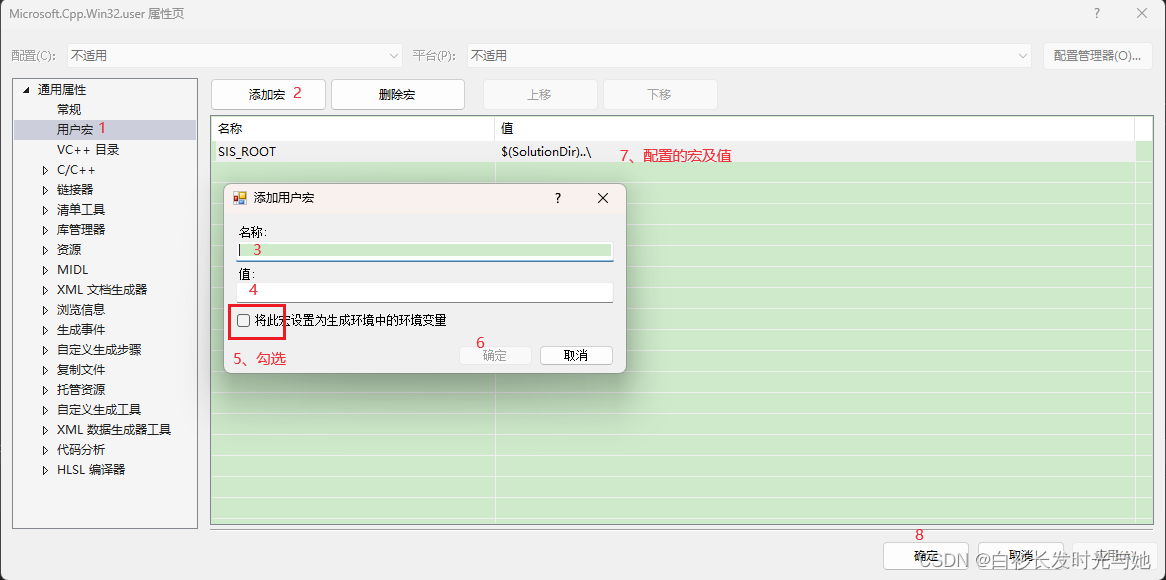
vs工程添加自定义宏
一、简介 用户可以添加自定义宏变量方便工程路径名称的修改和配置 例:$(SolutionDir) 为解决方案路径,$(PojectDir) 为工程所在路径 测试环境:vs2017,qt5.14.0 二、配置 1、打开属性窗口:视图-》其他窗口-》属性管…...

shell脚本:将一维数组以二维数组显示
shell脚本:将一维数组改成二维数组显示 1.编辑脚本文件 vi output_array.sh2.编写脚本 #!/bin/bash# 假设一维数组one_array已经包含9个元素 one_array(1 2 3 4 5 6 7 8 9) # 获取数组长度 length${#one_array[]} # 数组长度除以3获得新数组行数n n$((length / …...

QT C++ 读写mySQL数据库 图片 例子
在上篇文章中描述了怎样搭建读写数据库的环境。 本文更进一步,描述了读写mySQL数据库,字符、整型数字、图片。读写图片相对难点。 数据库的图片字段用BLOB,如果图片较大要用longblob,否则会报错。 另外,读写数据库都使用了短连…...

终极指南:如何使用RPGMakerDecrypter轻松解密游戏资源
终极指南:如何使用RPGMakerDecrypter轻松解密游戏资源 【免费下载链接】RPGMakerDecrypter Tool for extracting RPG Maker XP, VX and VX Ace encrypted archives. 项目地址: https://gitcode.com/gh_mirrors/rp/RPGMakerDecrypter RPGMakerDecrypter是一款…...

5分钟解锁网盘直链下载:告别限速,拥抱满速自由
5分钟解锁网盘直链下载:告别限速,拥抱满速自由 【免费下载链接】baiduyun 油猴脚本 - 一个免费开源的网盘下载助手 项目地址: https://gitcode.com/gh_mirrors/ba/baiduyun 还在为网盘下载速度而烦恼吗?你是否经历过下载一个几GB的文件…...

为什么conda装不上opencv-python?深入解析conda与pip的包管理差异
为什么conda装不上opencv-python?深入解析conda与pip的包管理差异 在Python生态系统中,conda和pip是最常用的两种包管理工具。许多开发者习惯使用conda创建和管理虚拟环境,但在安装某些特定包如opencv-python时,却常常遇到"P…...

金蝶k3软件常用基础SQL数据表
金蝶软件常用基础SQL数据表SQL数据库 1、系统表 t_tabledescription2、字段表 t_fielddescription3、基础资料表(版本:10.3) t_item 其中fitemclassid值表示1-客户;2-部门;3-职员;4-商品;5-仓位…...

暗黑破坏神2终极单机插件:PlugY生存工具包完全指南
暗黑破坏神2终极单机插件:PlugY生存工具包完全指南 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 如果你是一名暗黑破坏神2的单机玩家,是否曾…...

STM32+FreeRTOS双分区开发避坑指南:Bootloader跳转前别忘了这行关键代码
STM32FreeRTOS双分区开发避坑指南:Bootloader跳转前别忘了这行关键代码 当你在STM32上实现BootloaderApp双分区架构时,是否遇到过这样的场景:Bootloader明明成功跳转到了应用程序,却在启动FreeRTOS调度器时突然崩溃?寄…...
)
别再只用DoDragDrop了!手把手教你用WPF实现一个能拖拽合并数据的自定义控件(附完整源码)
WPF高级拖拽交互实战:从原生API局限到自定义控件设计 在构建现代桌面应用时,流畅自然的拖拽交互往往能极大提升用户体验。WPF虽然提供了基础的DoDragDrop API,但当我们需要实现复杂场景如卡片合并、动态数据交换时,原生方案就显得…...

如何快速上手TegraRcmGUI:Switch破解注入完整指南
如何快速上手TegraRcmGUI:Switch破解注入完整指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI 你是否曾为Nintendo Switch的定制化需求而烦恼…...

Swin2SR权限控制系统搭建:从小白到部署的完整实战教程
Swin2SR权限控制系统搭建:从小白到部署的完整实战教程 1. 引言:从个人工具到团队服务的转变 你刚刚体验了Swin2SR的强大,一张模糊的老照片,几秒钟就变得清晰锐利,那种感觉就像给图片做了一次“数字近视手术”。但很快…...

从一道蓝桥杯EDA赛题,聊聊平衡车硬件设计中那些‘不起眼’却关键的安全电路
平衡车硬件设计中的安全电路:从蓝桥杯赛题到工程实战 去年调试一款平衡车原型机时,我曾遇到一个诡异现象:每次电池快耗尽时,电机就会突然失控。经过三天排查,最终发现问题出在电源检测电路的分压电阻取值上——这个看似…...