Flink-cdc更好的流式数据集成工具
What’s Flink-cdc?
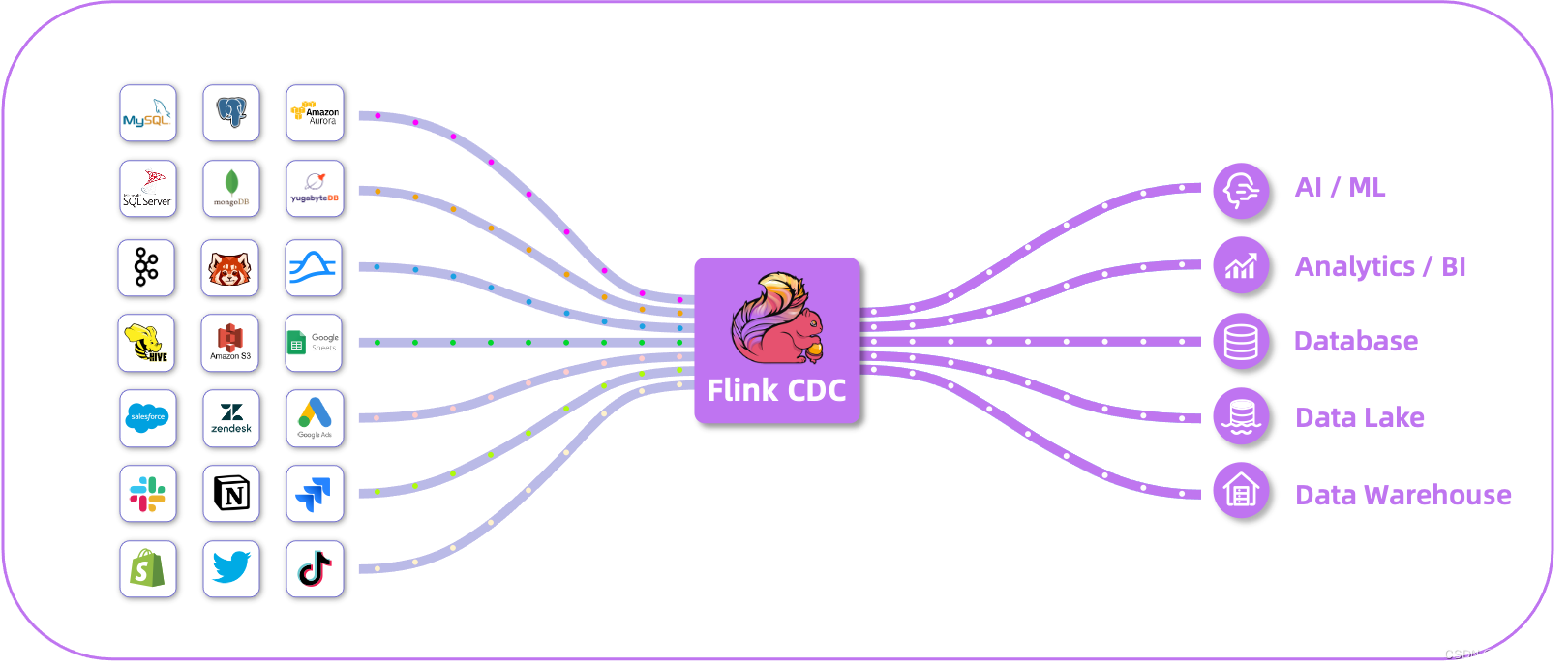
Flink CDC 是基于Apache Flink的一种数据变更捕获技术,用于从数据源(如数据库)中捕获和处理数据的变更事件。CDC技术允许实时地捕获数据库中的增、删、改操作,将这些变更事件转化为流式数据,并能够对这些事件进行实时处理和分析。
Flink CDC提供了与各种数据源集成的功能,包括常见的关系型数据库(如MySQL、PostgreSQL、Oracle等)以及NoSQL数据库(如MongoDB、HBase等)。它通过监控数据库的日志或轮询方式来捕获数据变更,并将变更事件作为数据流发送到Flink的任务中进行处理。
Flink CDC 深度集成并由 Apache Flink 驱动,提供以下核心功能:
✅ 端到端的数据集成框架
✅ 为数据集成的用户提供了易于构建作业的 API
✅ 支持在 Source 和 Sink 中处理多个表
✅ 整库同步
✅具备表结构变更自动同步的能力(Schema Evolution)
在使用者的角度,就是Flink-cdc可以简化流处理的流程:
-
引入Flink-cdc之前流处理流程

-
引入Flink-cdc之后后流处理流程

如上所示,在flink-cdc被引入后大大简化了流处理流程
Flink-cdc支持的链接及对应的版本
Pipeline Connectors
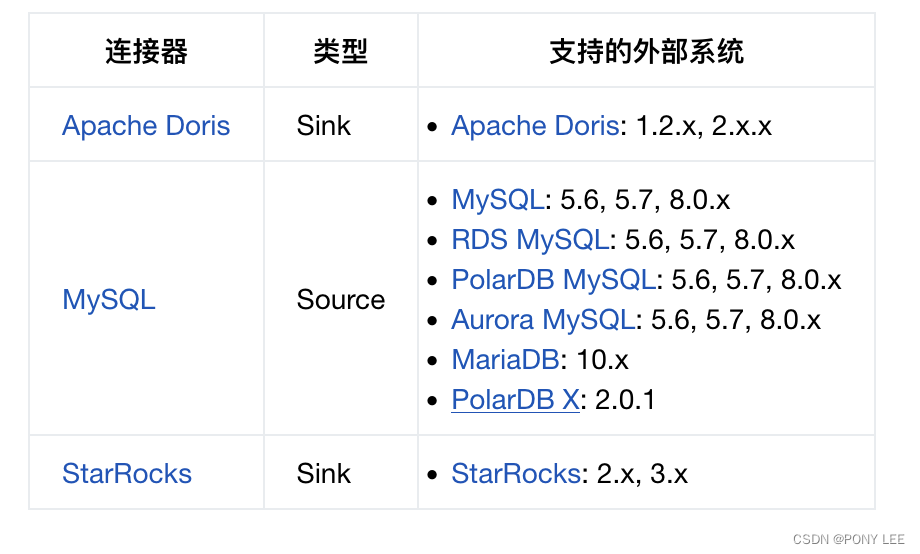
Source Connectors
 截止目前(2024-05-23)
截止目前(2024-05-23)
Flink-cdc与Flink对应对影版本的关系
 截止目前(2024-05-23)
截止目前(2024-05-23)
flink-connector-mysql-cdc 实例分析
示例代码
demo代码:
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class MySqlSourceDemo {public static void main(String[] args) throws Exception {MySqlSource<String> mySqlSource = MySqlSource.<String>builder().hostname("mysql-server-host").port(3306).databaseList("mydb") // 设置捕获的数据库.tableList("mydb.products") // 设置捕获的表,如果需要同步整个数据库,请将 tableList 设置为 ".*".
// .tableList(".*") // 捕获整个数据库的表
// .tableList("^(?!mysql|information_schema|performance_schema).*") // 设置捕获的表,排除系统库
// .tableList("mydb.(?!products|orders).*") // 同步排除products和orders表之外的整个my_db库.username("flink-cdc").password("xxx").serverId("5400-5405").deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串.serverTimeZone("Asia/Shanghai") // 设置时区.startupOptions(StartupOptions.initial()).scanNewlyAddedTableEnabled(true) // 启用扫描新添加的表功能
// .includeSchemaChanges(true) // 包括 schema 变更.build();org.apache.flink.configuration.Configuration config = new org.apache.flink.configuration.Configuration();config.setString("rest.port", "8081");
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(config); //本地环境,调试用StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置 3s 的 checkpoint 间隔env.enableCheckpointing(3000);env.setStateBackend(new HashMapStateBackend());env.getCheckpointConfig().setCheckpointStorage("file:///tmp/ck");//本地文件系统
// env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); 1.14.0 版本开始支持env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")// 设置 source 节点的并行度为 4.setParallelism(5).print().setParallelism(1); // 设置 sink 节点并行度为 1env.execute("Print MySQL Snapshot + Binlog");}
}maven依赖:
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.14.5</flink.version><scala.binary.version>2.12</scala.binary.version></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><scope>test</scope></dependency><!-- 将 Apache Flink 的 Web 运行时模块添加到项目中 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version><scope>provided</scope> <!--provided生命周期在test模式才可以运行,在main模式会找不到包--></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>2.3.0</version><scope>compile</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version><scope>compile</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version><scope>provided</scope></dependency></dependencies>
日志配置文件:
log4j.properties
log4j.rootCategory=error,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %p %c{1}:%L - %m%n启动standalone Flink级群
# jobmanager
docker run -d \
--name flink-jm \
--hostname flink-jm \
-p 8082:8081 \
--env FLINK_PROPERTIES="jobmanager.rpc.address: flink-jm" \
--network flink-network-standalone \
ponylee/flink:1.15.0-java8 \
jobmanager# taskmanager
docker run -d \
--name flink-tm \
--hostname flink-tm \
--env FLINK_PROPERTIES="jobmanager.rpc.address: flink-jm" \
--network flink-network-standalone \
ponylee/flink:1.15.0-java8 \
taskmanager \
-Dtaskmanager.memory.process.size=1024m \
-Dtaskmanager.numberOfTaskSlots=5 \
-Drest.flamegraph.enabled=true分析说明
为每个 Reader 设置不同的 Server id
每个用于读取 binlog 的 MySQL 数据库客户端都应该有一个唯一的 id,称为 Server id。 MySQL 服务器将使用此 id 来维护网络连接和 binlog 位置。 因此,如果不同的作业共享相同的 Server id, 则可能导致从错误的 binlog 位置读取数据。 因此,建议通过为每个 Reader 设置不同的 Server id , 假设 Source 并行度为 4,server id 配置必须:serverId(“5400-5405”),5405-5400=5 >= 4。来为 4 个 Source readers 中的每一个分配唯一的 Server id。
查看mysql链接发现
select * from information_schema.processlist where user = ‘flink-cdc’;
 Flink-cdc对mysql的影响
Flink-cdc对mysql的影响
正常情况下,Flink-cdc是No-lock Read,主库可以继续处理事务和查询,而不会导致主库进程阻塞,不会对主库产生直接影响。但是,在某些情况下数据同步的过程中可能会对主库产生一些间接影响,比如:网络、IO、CPU负载以及mysql的并发连接数等资源消耗。但这些对主库的开销影响相对较小(全量同步阶段可能比较耗能,但时间相对比较短)。
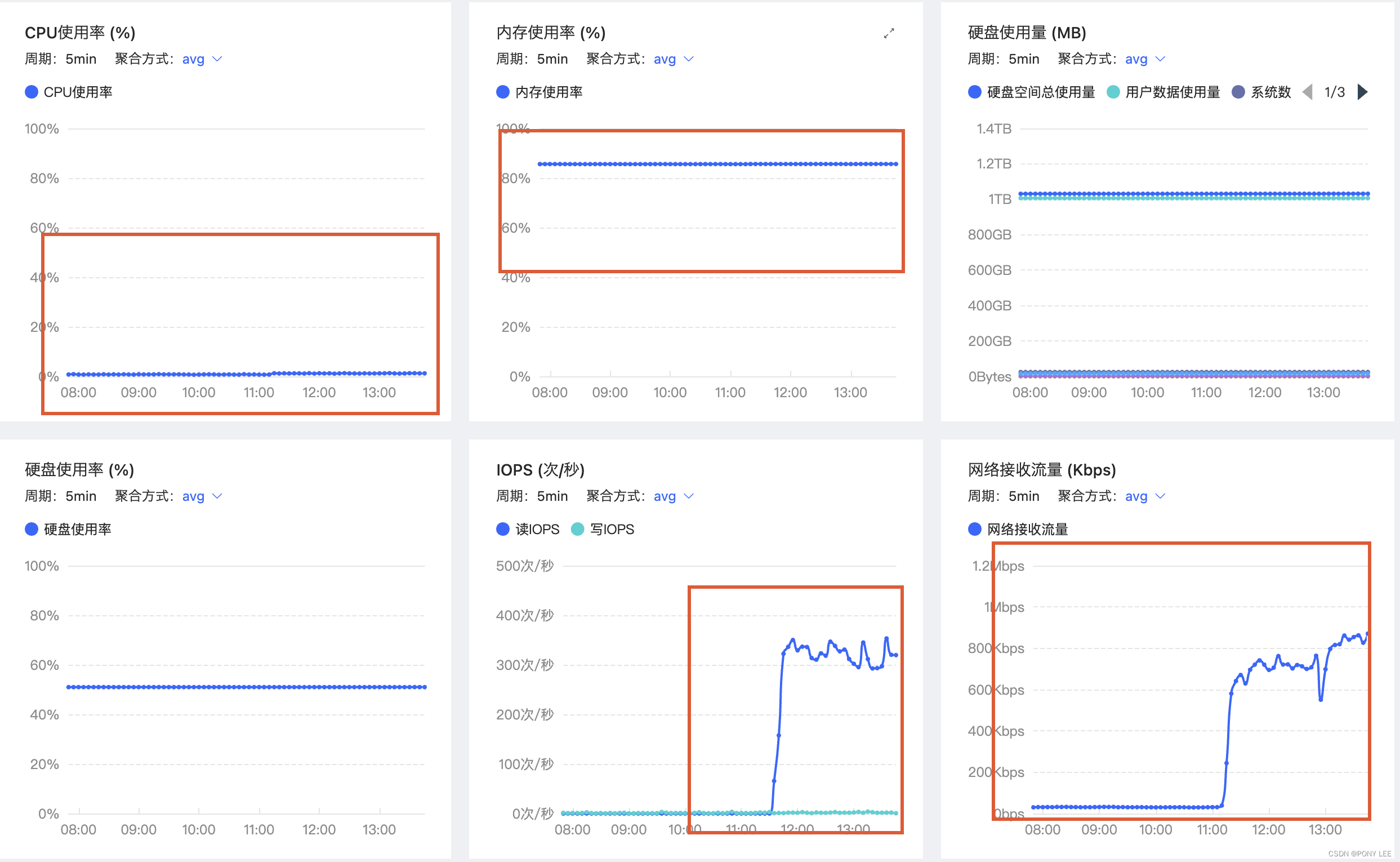

从上图mysql资源使用情况来看,flink-cdc对内存和CPU负载影响微乎极微,是No-lock Read,主要表现对网络和IO的资源消耗。
断点续传
通过从checkpoint/savepoint 恢复,flink-cdc可以保证断点续传。
-
从checkpoint/savepoint恢复,缩小同步范围,例如:从tableList(“mydb.products,mydb.orders”)或tableList(“.*”) 缩小到 tableList(“mydb.products”),应用更新生效。
-
应用从checkpoint/savepoint恢复,扩大同步范围的部分不会生效,例如:从tableList(“mydb.products”) 到 tableList(“mydb.products,mydb.orders”)或tableList(“.*”),应用更新不生效生效。若想使动态加表生效,可以显示制定scanNewlyAddedTableEnabled(true) ,来启用扫描新添加的表功能。如没有特殊情况,建议在开发环境开启此配置。
flink-cdc包名变更
Flink CDC 项目 从 2.0.0 版本将 group id 从com.alibaba.ververica 改成 com.ververica, 自 3.1 版本从将 group id 从 com.ververica 改成 org.apache.flink。 这是为了让项目更加社区中立,让各个公司的开发者共建时更方便。所以在maven仓库找 2.x 的包时,路径是 /com/ververica;找3.1及以上版本的包时,路径是/org/apache/flink
参考:
flink-cdc
flink-cdc docs
相关文章:
Flink-cdc更好的流式数据集成工具
What’s Flink-cdc? Flink CDC 是基于Apache Flink的一种数据变更捕获技术,用于从数据源(如数据库)中捕获和处理数据的变更事件。CDC技术允许实时地捕获数据库中的增、删、改操作,将这些变更事件转化为流式数据,并能够…...
|抽象工厂模式)
C++|设计模式(三)|抽象工厂模式
抽象工厂模式仍然属于创建型模式,我们在【简单工厂和工厂方法模式】这篇文章中,描述了简单工厂和工厂方法模式,并在文末,简单介绍了工厂方法模式的局限性。 本文将通过汽车工厂的例子继续来阐述使用抽象工厂模式相比较于工厂方法…...

AVB协议分析(一) FQTSS协议介绍
FQTSS协议介绍 一、AVB整体架构二、概述三、协议作用及作用对象四、协议的实现五、参考文献: 一、AVB整体架构 可见FQTSS位于MAC层的上面,代码看不懂,咱们就从最底层开始,逐层分析协议,逐个击破,慢就是快。…...
询问)
一个程序员的牢狱生涯(44)询问
星期一 询 问 在号子里开始了下午坐班的时候,过道内的大铁栅栏被管教打开,我听到开锁的声音后,心里变得激动起来。盼望着脚步声能停在我们的号子门口,然后打开铁门,喊一声“眼镜,出来!”。 通道内这次进来的是秦所,但他并没有在我们号子门口停留,只是在走过的时候,低…...
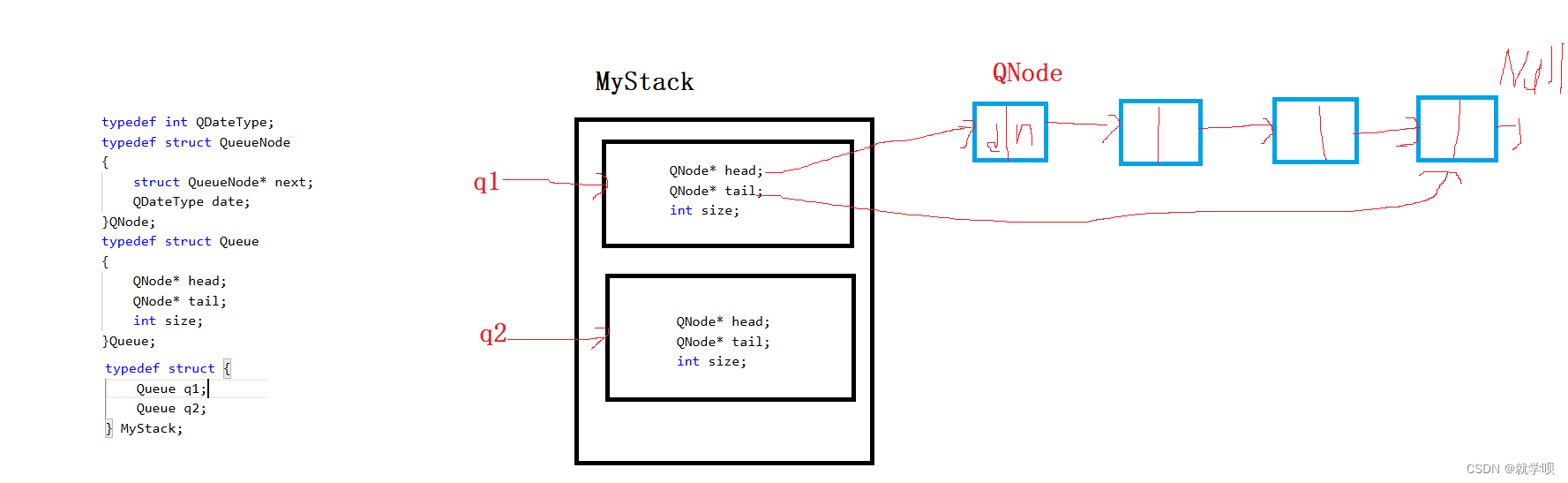
刷爆leetcode第六期
题目一 用队列实现栈 请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。 实现 MyStack 类: void push(int x) 将元素 x 压入栈顶。 int pop() 移除…...

汇舟问卷:国外问卷调一天900
大家好,我是汇舟问卷,专注于国外问卷调查互联网项目。夏天已经来临,您是否在三伏天顶着大太阳上班,汗水浸湿了衣襟,却依然要面对繁琐的工作和无尽的压力? 在这个炎热的季节里,我们都渴望找到一…...

openresty完美替代nginx
OpenResty相较于Nginx,其优势主要体现在以下几个方面: 1、Lua脚本支持:OpenResty内置了LuaJIT(Lua的即时编译器),使得用户可以直接在Nginx配置文件中使用Lua脚本,这样可以实现更复杂的业务逻辑…...

深入解析:Element Plus 与 Vite、Nuxt、Laravel 的结合使用
在现代前端开发中,选择合适的工具和框架来提高开发效率和应用性能是至关重要的。 Element-Plus 是一个基于 Vue.js 3.0 的流行 UI组件库,它可以与多种前端和后端框架结合使用,如 Vite、Nuxt 和 Laravel。本文将深入探讨这三者与 Element Plus…...

使ssh连接Linux服务器一直不掉线
怎么可以使ssh连接Linux服务器一直不掉线 解决方法: vim /etc/profile在/etc/profile中的TMOUT改为0 export TMOUT0最后 source /etc/profile就可以了...
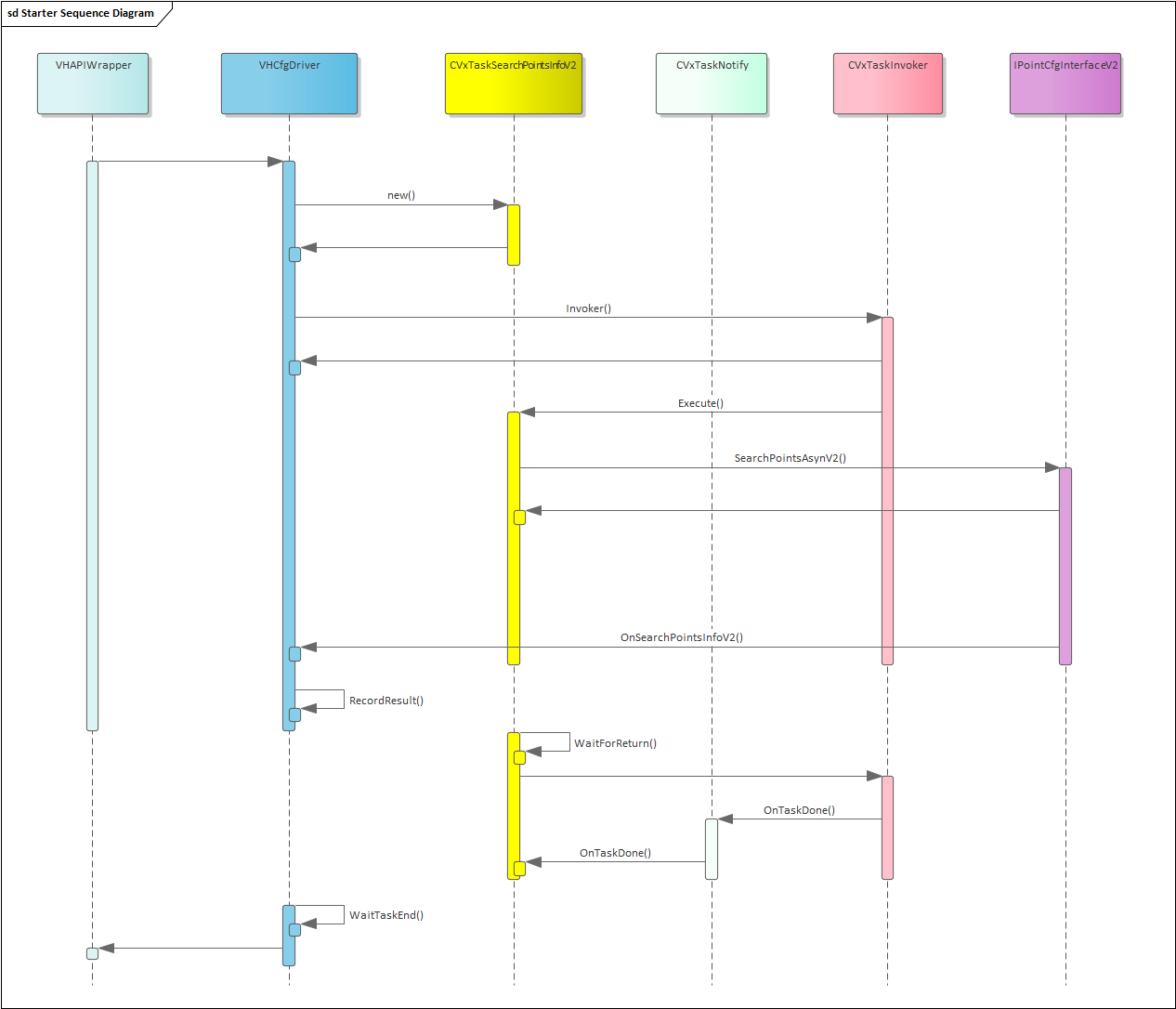
2024-05-29 blue-VH-driver-对外接口的并行调用-设计与思考
摘要: VH的driver的对外接口, 要做到可以并行,也就是两个不同的线程,分别调用,不能互相阻塞。 本文记录对其的思考和设计。 上下文: 2024-05-28 blue-VH-driver-需求分析及问题分析-CSDN博客 2024-05-27 blue-vh-问题点-CSDN博客 2024-05…...
ubuntu安装
1.下载镜像文件 2.打开VMware并新建虚拟机 版本选择Ubuntu 64位 磁盘容量改为40GB 点击自定义硬件,点击新CD/DVD(SATA),连接选择ISO映像文件,找到之前下载的Ubuntu镜像文件,然后关闭选项卡。 3.开启虚拟机…...

Rosetta PyRosetta 源码包 安装包 下载
--- pyrosetta_src.zip包含以下包: | --- PyRosetta4.Debug.python27.ubuntu.release-185.tar.bz2 | --- PyRosetta4.Release.python27.linux.release-215.tar.bz2 | --- PyRosetta4.Release.python38.ubuntu.release-349.tar.bz2 --- pyrosetta_whl.zip包含…...
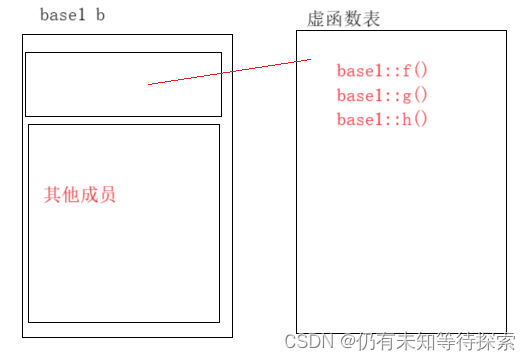
C++ 进阶(3)虚函数表解析
个人主页:仍有未知等待探索-CSDN博客 专题分栏:C 请多多指教! 目录 一、虚函数表 二、单继承(无虚函数覆盖) 继承关系表: 对于实例:derive d 的虚函数表: 对于实例:b…...
2024年新算法-秘书鸟优化算法(SBOA)优化BP神经网络回归预测
2024年新算法-秘书鸟优化算法(SBOA)优化BP神经网络回归预测 亮点: 输出多个评价指标:R2,RMSE,MSE,MAPE和MAE 满足需求,分开运行和对比的都有对应的主函数:main_BP, main_SBOA, main_BPvsBP_SB…...
kafka-主题创建(主题操作的命令)
文章目录 1、topic主题操作的命令1.1、创建一个3分区1副本的主题1.1.1、获取 kafka-topics.sh 的帮助信息1.1.2、副本因子设置不能超过集群中broker的数量1.1.3、创建一个3分区1副本的主题1.1.4、查看所有主题1.1.5、查看主题详细描述 1、topic主题操作的命令 kafka发送消息会存…...

[日常开发] 数据库主从延迟问题
MySQL数据库主从延迟问题 无论是学习还是工作中,MySQL数据库的使用都十分地广泛。在业务中,数据库也会以集群的形式使用,所以会涉及到主从问题。 问题描述 在使用MySQL数据库的时候,在service的方法中首先向A数据表批量插入了数…...

Python高层解雇和客户活跃度量化不确定性模型
🎯要点 🎯量化不确定性模型:🖊模型检测短信编写者行为变化 | 🖊确定(商业领域中)竞争性替代方案 | 🖊确定作弊供词真实比例 | 🖊学生考试作弊 | 🖊确定零部件…...
【IOT】OrangePi+HomeAssistant+Yolov5智能家居融合
前言 本文将以OrangePi AIpro为基础,在此基础构建HomeAssistant、YOLO目标检测实现智能家居更加灵活智能的场景实现。 表头表头设备OrangePi AIpro(8T)系统版本Ubuntu 22.04.4 LTSCPU4核64位处理器 AI处理器AI算力AI算力 8TOPS算力接口HDMI2、GPIO接口、Type-C、M.2…...

Python 点云裁剪
点云裁剪 一、介绍1.1 概念1.2 函数讲解二、代码示例2.1 代码实现2.2 代码讲解三、结果示例一、介绍 1.1 概念 点云裁剪 :根据待裁剪对象的多边形体积(json文件)实现点云的裁剪。 1.2 函数讲解 下面代码示例中主要用到了两个函数。 读取待裁剪对象的多边形体积信息(json文…...
)
Presto 从提交SQL到获取结果 源码详解(2)
逻辑执行计划: //进入逻辑执行计划阶段 doAnalyzeQuery().new LogicalPlanner().plan(analysis);//createAnalyzePlan createAnalyzePlan(analysis, (Analyze) statement);//返回RelationPlan,(返回root根节点,逻辑树上包含输出字…...

多模态AI应用开发实战:GPT与图像生成的集成架构与优化
1. 项目概述与核心价值最近在折腾AI图像生成和智能对话的整合应用时,发现了一个挺有意思的仓库:bubblesslayyer-cmd/Awesome-GPT-Image-2-OpenAi。这个项目名字乍一看有点长,但拆解一下就能明白它的核心——“Awesome”系列通常代表精选资源集…...
)
极简风项目交付倒计时!:紧急修复MJ --v 6.2中隐藏的1.33倍宽高比偏移Bug,避免客户验收驳回(含补救Prompt包)
更多请点击: https://intelliparadigm.com 第一章:极简风项目交付倒计时! 当交付周期压缩至 72 小时,极简风不再是一种美学选择,而是工程效率的刚性约束。我们摒弃冗余文档、跳过非核心评审环节,聚焦于可…...

Go语言开源漏洞扫描器Abyss-Scanner:架构解析与CI/CD集成实践
1. 项目概述:一个为安全而生的开源漏洞扫描器最近在整理自己的开源项目工具箱,发现一个挺有意思的工具,叫 Abyss-Scanner。这名字起得挺有深意,“深渊扫描器”,听起来就有点探索未知、发现潜在风险的味道。简单来说&am…...

终极指南:如何使用Autoclick实现Mac自动点击900次/秒
终极指南:如何使用Autoclick实现Mac自动点击900次/秒 【免费下载链接】Autoclick A simple Mac app that simulates mouse clicks 项目地址: https://gitcode.com/gh_mirrors/au/Autoclick 你是否厌倦了重复性的鼠标点击工作?无论是游戏中的重复操…...

终极免费城通网盘直连解析工具:告别下载限速的完整指南
终极免费城通网盘直连解析工具:告别下载限速的完整指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载速度慢、等待时间长而烦恼吗?ctfileGet是一款专为城通…...

框架式幕墙与单元式幕墙的价格差异
框架式幕墙与单元式幕墙的价格差异 框架式幕墙与单元式幕墙由于结构及安装方式的不同,在价格方面存着很大的差异。主要表现在以下几个方面: 铝型材的用量: 框架式幕墙铝型材用量一般在7—9 kg/平方米左右。 单元式幕墙铝型材用量一般在13—15kg/平方米左右。 两者每平方…...

Nestia:基于TypeScript编译时分析的NestJS端到端类型安全实践
1. 项目概述:当NestJS遇上TypeScript的极致类型安全如果你正在用NestJS开发后端API,并且对TypeScript的类型安全有近乎偏执的追求,那么你很可能已经听说过,或者正在寻找一个能让你“写一次,安全两次”的工具。我说的“…...

终极指南:如何使用League-Toolkit英雄联盟工具箱快速提升游戏效率
终极指南:如何使用League-Toolkit英雄联盟工具箱快速提升游戏效率 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中…...

基于RAG的智能知识库问答系统:从原理到部署实战
1. 项目概述:当AI大模型遇见知识库,一个开源的智能问答解决方案 最近在折腾一个很有意思的开源项目,叫 zhimaAi/chatwiki 。光看名字,你大概能猜到它的核心: chat 代表对话, wiki 代表知识库。没错&a…...

AI智能体GUI交互实战:从原理到实现,让AI玩转桌面应用
1. 项目概述:一个能“玩”游戏的AI智能体最近在AI智能体(Agent)的圈子里,一个名为“ChattyPlay-Agent”的开源项目引起了我的注意。乍一看名字,你可能会觉得它又是一个基于大语言模型(LLM)的聊天…...