Presto 从提交SQL到获取结果 源码详解(2)
逻辑执行计划:
//进入逻辑执行计划阶段
doAnalyzeQuery().new LogicalPlanner().plan(analysis);//createAnalyzePlan
createAnalyzePlan(analysis, (Analyze) statement);//返回RelationPlan,(返回root根节点,逻辑树上包含输出字段、meta与字段映射关系、索引等)
return createOutputPlan(planStatementWithoutOutput(analysis, statement), analysis);/*
逻辑执行计划是基于Visitor模型生成的,逻辑计划为受访者,优化器为访问者
逻辑执行计划的节点都是PlanNode的实现类:最核心的accept()方法,代表这个当前node接收访问,就是调用Visitor的visitPlan()方法LogicalPlanner 遍历各种优化器对应的 optimize()方法。对PlanTree 进行优化,并对生成的Plan 进行验证。
优化过程中,优化器会在 Plan中插入 Exchange 结点。之后planFragmenter会根据这些Exchange结点将 Plan切分成 SubPlan。
*/if (stage.ordinal() >= Stage.OPTIMIZED.ordinal()) {for (PlanOptimizer optimizer : planOptimizers) {root = optimizer.optimize(root, session, symbolAllocator.getTypes(), symbolAllocator, idAllocator, warningCollector);requireNonNull(root, format("%s returned a null plan", optimizer.getClass().getName()));}
}//optimizer.optimize方法中,以rewritewith形式,重写现有逻辑树
SimplePlanRewriter.rewriteWith优化器介绍:
常规优化器:
需要实现optimize()方法。且需要自定义和实现整个Visitor的角色,即重载vistor*()的相关方法,例如visitAggregation,visitTopN,visitOutput等(PlanVisitor中定义了各种visit*()方法)
大致流程:
PlanOptimizer
.optimize
.visitPlan
context.defaultRewrite
.rewrite
.replace
是否继续替换条件判断
否:生成PlanNode返回
当 PlanNode 接受 Rewriter时,会进行
1. PlanNode 类型匹配:Rewriter 中的每个 visit* 方法都是针对特定类型的 PlanNode 设计的。例如,visitProject 是处理 ProjectNode 类型的节点,visitOutput 是处理 OutputNode 类型的节点。当 PlanNode 的类型与某个 visit* 方法匹配时,该方法就会被调用。
2. 递归遍历:Rewriter 通常会递归地遍历查询计划树。当它访问到一个节点时,会根据节点的具体类型调用相应的 visit* 方法。如果该节点类型没有特定的 visit* 方法,通常会调用一个更通用的 visitPlan 方法。
3. 方法执行:在 visit* 方法中,Rewriter 可以根据需要修改或替换当前节点。例如,它可能会添加新的节点,修改节点的属性,或者调整子节点的结构。
示例
假设有一个查询计划树,其中包含 OutputNode, ProjectNode, 和 FilterNode。Rewriter 在处理这个树时,会:
对于 OutputNode,调用 visitOutput 方法。
对于 ProjectNode,调用 visitProject 方法。
对于 FilterNode(如果没有特定的 visitFilter 方法),调用 visitPlan 方法。
LimitPushDown
//Limit下推优化器, 功能:判断是否可以下推Limit条件,以筛除数据,提高运行速度,减少资源消耗public class LimitPushDown implements PlanOptimizer.visitPlan
PlanNode rewrittenNode = context.defaultRewrite(node);//遍历所有node,调用rewrite方法
node.getSources().stream().map(child -> rewrite(child, context))//获取当前node的全局Limit条件是否存在,!=null则不能直接替换,生成LimitNode对象,返回LimitContext limit = context.get();
if (limit != null) {// Drop in a LimitNode b/c we cannot push our limit down any furtherrewrittenNode = new LimitNode(idAllocator.getNextId(), rewrittenNode, limit.getCount(), limit.isPartial());
}//替换原树
replaceChildren(node, children);/*
如果 LimitNode 的上游还有一个 LimitNode 那么把这两个 LimitNode 进行合并。
如果合并之后要 LimitNode 的count 是 0,那么直接把这个 LimitNode 节点换成一个空的 Values 节点。
如果 LimitNode 的上游有一个 TopN 节点,那么把 Limit 和 TopN 节点进行合并。
如果碰到 Union 节点,那么把 Limit 节点推到 Union 下面去。*///谓词下推,与Limit逻辑基本一致
public class PredicatePushDown implements PlanOptimizer
AddExchanges
public class AddExchanges implements PlanOptimizer
plan.accept(new Rewriter(idAllocator, symbolAllocator, session), PreferredProperties.any());/*介绍:划分子图,为查询计划添加交换节点,确保任务正确分布在各个节点,直接影响SubPlan 的划分
功能:1.确保数据正确分布。例如 groupby 根据hash分布至不同节点上2.优化节点分布,减少网络传输,提高查询效率流程:1. 分析查询计划:优化器首先分析当前的查询计划,识别出需要数据交换的操作。这包括但不限于聚合、连接、排序等操作。2. 确定数据分布需求:对于每个操作,AddExchanges 确定数据需要如何分布以满足操作需求。例如,对于一个基于某个键的聚合操作,数据需要根据该键进行哈希分布。3. 插入交换节点:根据确定的数据分布需求,AddExchanges 在查询计划中适当的位置插入交换节点。这些节点负责在执行时将数据从一个节点传输到另一个节点。4. 优化数据路径:在添加交换节点的同时,AddExchanges 还会尝试优化数据传输的路径,减少跨节点的数据移动,优化整体查询性能。5. 递归处理:由于查询计划可能非常复杂,包含多层嵌套的操作,AddExchanges 通常需要递归地处理整个查询计划树,确保所有需要的数据交换都被正确处理。
*/ExhangeNode.Type:GATHER 收集类型。出现在局部聚合或Coordinator OutPut REPARTITION shuffle类型。按hashcode分发至指定节点,出现在groupby或join时REPLICATE 拷贝类型。出现在小表join大表,广播时
ExhangeNode.Scope:LOCAL 预聚合REMOTE 任务切分,生成SubPlan迭代优化器 IterativeOptimizer
迭代优化器是在基础优化器开发基础上,做的代码重构。/*
Memo对象背景:
源码中,为保证程序稳定,避免潜在问题。PlanNode对象是不可变的(immutable),但每次修改则需要重构树,性能有所下降且修改麻烦。为解决这个问题,则声明了一个Memo可变对象。
Memo中,PlanNode被包装成 GroupReference(不可变),GroupReference包含Group(可变),Group包含PlanNode(用于修改优化)。通过遍历GroupReference修改PlanNode。
Group 伴随引用计数,如被优化或不被任何Group引用,则需要清理掉// 增加引用计数
incrementReferenceCounts(node, group);// 更新节点
getGroup(group).membership = node;// 减少引用计数,如果为0,则删除
decrementReferenceCounts(old, group);*///流程:
optimize:new Memo();new PlanNodeMatcher();exploreGroup(memo.getRootGroup(), context, matcher);//遍历Rule
Iterator<Rule<?>> possiblyMatchingRules = ruleIndex.getCandidates(node).iterator();
//Match getPattern()
Rule.Result result = transform(node, rule, matcher, context);
//对应规则逻辑 rule.apply()
result = rule.apply(match.value(), match.captures(), ruleContext(context));关于Join优化器
distributed_join 是否使用分布式Join
distributed_sort 是否使用分布式Sort
join_distribution_type 分布式Join策略类型
join_reordering_strategy 重排序策略
max_reordered_joins 重排序组内容许Join表的最大值
push_aggregation_through_join 是否在Join前预聚合
task.max-partial-aggregation-memory 预聚合HashTable内存大小,默认16M
ReorderJoins in Presto 重排序优化:影响Join执行顺序,基于CBO动态规划生成,有超时问题
1. 枚举所有可能的连接顺序
chooseJoinOrder 方法首先会枚举所有可能的连接顺序。(生成选择生成left-deep tree )
2. 计算每种连接顺序的成本
对于每一种可能的连接顺序,Presto 会计算其成本。成本的计算通常基于多个因素,如数据大小、过滤器的选择性、连接键的分布等。Presto 使用成本模型来估算不同连接顺序的执行成本。
3. 选择最低成本的连接顺序
在所有可能的连接顺序中,chooseJoinOrder 方法会选择成本最低的一个。这是通过比较每种连接顺序的预估成本来实现的。
4. 递归优化每个子连接
一旦选择了一个连接顺序,chooseJoinOrder 方法会递归地优化每个子连接。这意味着对于每个连接操作,它会再次调用自身来优化该连接操作中涉及的表的连接顺序。
5. 应用最优连接顺序
最后,选择的连接顺序会被应用到查询计划中。这可能涉及到重构原始的查询计划树,以便按照选择的顺序执行连接
注意:重排优化选择成本最低的顺序即最优顺序,Hive不支持直方图,因此无法使用该优化
EliminateCrossJoins : 对表之间的Join顺序重新排列,避免笛卡尔积问题
InnerJoin包裹CrossJoin 通过更改执行顺序,优化为InnerJoin包裹InnerJoin
DetermineJoinDistributionType 控制分布式优化规则:用于决定Join类型,基于CBO生成
Partial Aggregations 预聚合优化器
通过push_partial_aggregation_through_join配置使用(默认:关闭)。预聚合并不影响数据量。如果hash分布特别散时,反而会使查询变慢。
额外话题:
RBO(Rule-Based Optimization),基于规则的优化器。
- 谓词下推
- 列裁剪
- 常量折叠
- 表达式改写
- 最大最小消除
- 消除空算子
- 投影消除
- 函数下推
- 子查询去关联化
- 短路径优化查询
- 优化中断
- 其他
CBO(Cost-Based Optimization), 基于成本的优化器。
根据数据的统计信息、基数估计、算子代价模型等。在构造SQL搜索空间中的执行计划时,选择代价(CPU\内存\网络IO)最小的执行计划
大致流程:
1.根据转换规则,生成多个逻辑计划
2.根据逻辑计划,生成Operator物理计划
3.根据统计信息,生成多个方案,评估最小代价方案。
CBO的目的不是得到最优的方案,而是一个足够好的方案。
相关基础知识:数据库内核-CBO 优化器基本概念 - 知乎
总结:
基础优化器,通过vistor模式重写了各种方法。当对应PlanNode类型访问时,要执行的其自定义优化方法,最后判断是否符合更新规则,更新原树结构。
迭代优化器, 定义了各种规则(Rule),模式匹配(PlanNodeMatcher)当前树是否符合规则,符合则调用对应规则进行优化,输入原树,输出新树。
区别:
基础优化器需要定义各种Node类型,实现vistor对象,重新visit*方法
迭代优化器编写Rule,重写getPattern(匹配规则)、apply(优化方法)即可,同时还可以控制由Session参数,决定是否启用某个优化规则(EliminateCrossJoins只有在满足join条件时才运行)。
备注:
validate 验证
extract 提取
phase 阶段
SymbolAllocator 符号分配器
相关文章:
)
Presto 从提交SQL到获取结果 源码详解(2)
逻辑执行计划: //进入逻辑执行计划阶段 doAnalyzeQuery().new LogicalPlanner().plan(analysis);//createAnalyzePlan createAnalyzePlan(analysis, (Analyze) statement);//返回RelationPlan,(返回root根节点,逻辑树上包含输出字…...

Python的类全面系统学习
文章目录 1. 基本概念1.1 类(Class)1.2 对象(Object) 2. 类的属性和方法3. 类的继承3.1 继承的概念3.2 单继承3.3 多重继承 4. 方法重写与多态4.1 方法重写4.2 多态 5. 特殊方法与运算符重载5.1 特殊方法(魔法方法&…...
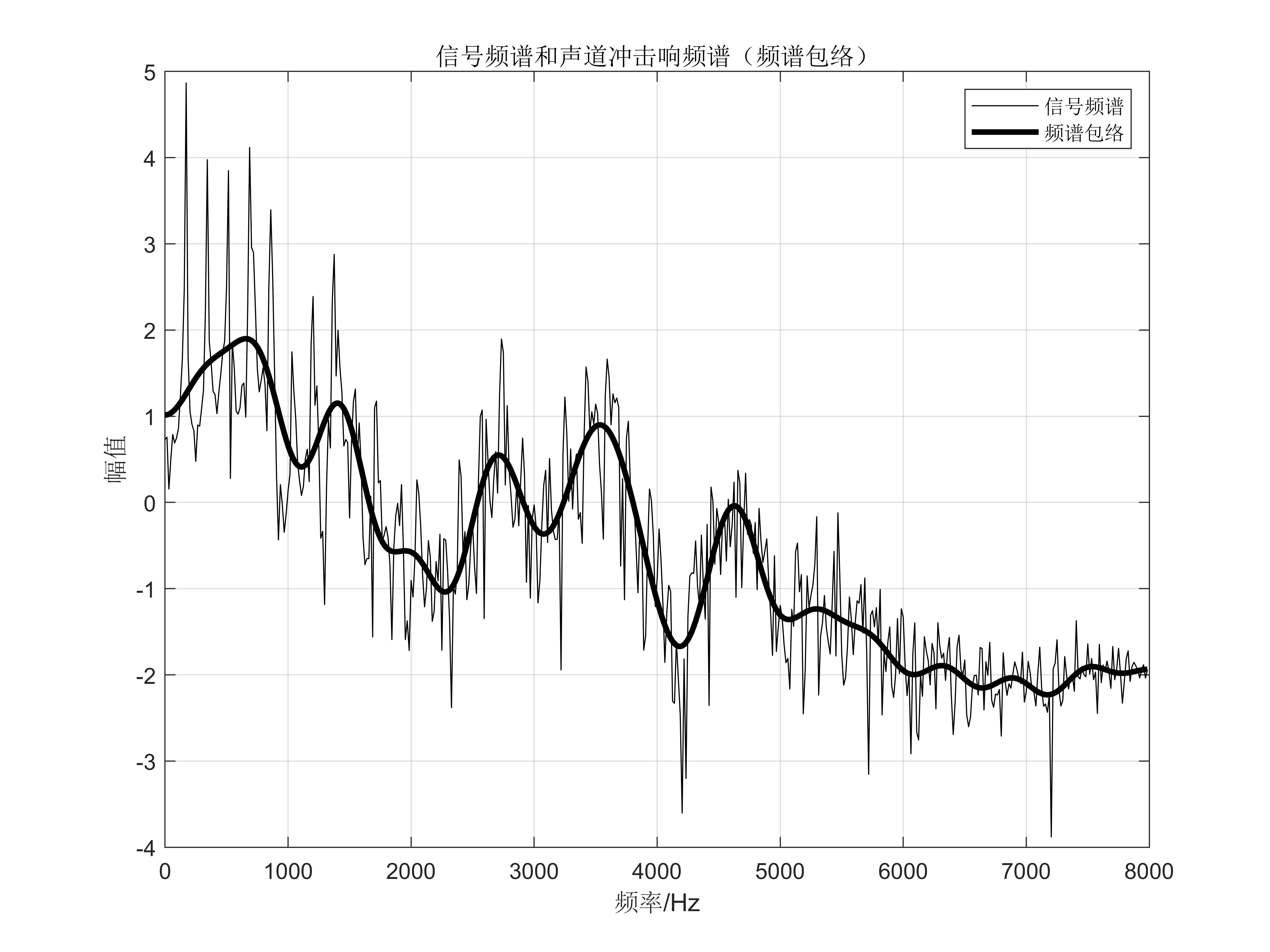
信号处理中简单实用的方法
最小二乘法拟合消除趋势项 消除趋势项函数 在MATLAB的工具箱中已有消除线性趋势项的detrend函数;再介绍以最小二乘法拟合消除趋势项的polydetrend 函数。 函数:detrend功能:消除线性趋势项 调用格式:ydetrend(x) 说明:输入参数x是带有线性趋势项的信号序列,输出…...

Jeecg | 如何解决 ERR Client sent AUTH, but no password is set 问题
最近在尝试Jeecg低代码开发,但是碰到了超级多的问题,不过总归是成功运行起来了。 下面说说碰到的最后一个配置问题:连接redis失败 Error starting ApplicationContext. To display the conditions report re-run your application with deb…...
 更新啦!)
数据容器:set(集合) 更新啦!
数据容器:set(集合) 1.集合的定义方式 {元素, 元素, 元素} # 定义集合 my_set {"欣欣向荣", "嘉嘉", "red", "欣欣向荣", "嘉嘉", "red", "欣欣向荣", "嘉嘉…...
算法入门----小话算法(1)
下面就首先从一些数学问题入手。 Q1: 如何证明时间复杂度O(logN) < O(N) < O(NlogN) < O(N2) < O(2N) < O(N!) < O(NN)? A: 如果一个以整数为参数的不等式不能很容易看出不等的关系,那么最好用图示或者数学归纳法。 很显…...

Vue | 自定义组件双向绑定基础用法
Vue | 自定义组件双向绑定基础用法 vue 中,由于单向数据流,常规的父子组件属性更新,需要 在父组件绑定相应属性,再绑定相应事件,事件里去做更新的操作,利用语法糖 可以减少绑定事件的操作。 这里就简单的梳…...

python使用modbustcp协议与PLC进行简单通信
AI应用开发相关目录 本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧 适用于具备一定算法及Python使用基础的人群 AI应用开发流程概…...

mongodb在游戏开发领域的优势
1、分布式id 游戏服务器里的大部分数据都是要求全局唯一的,例如玩家id,道具id。之所以有这种要求,是因为运营业务上需要进行合服操作,保证不同服的数据在进行合服之后,也能保证id不冲突。如果采用关系型数据库&#x…...

大数据Scala教程从入门到精通第十篇:Scala在IDEA中编写Hello World代码的简单说明
一:代码展示 object Main {def main(args: Array[String]): Unit {//SCALA中可以不写;//绿色的小三角达标的是这个类中有一个MAIN方法代表是可以执行的。//ctrl shift f10可以直接运行println("Hello world!")//Java中的类库我们可以直接使用System.o…...

【SPSS】基于因子分析法对水果茶调查问卷进行分析
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
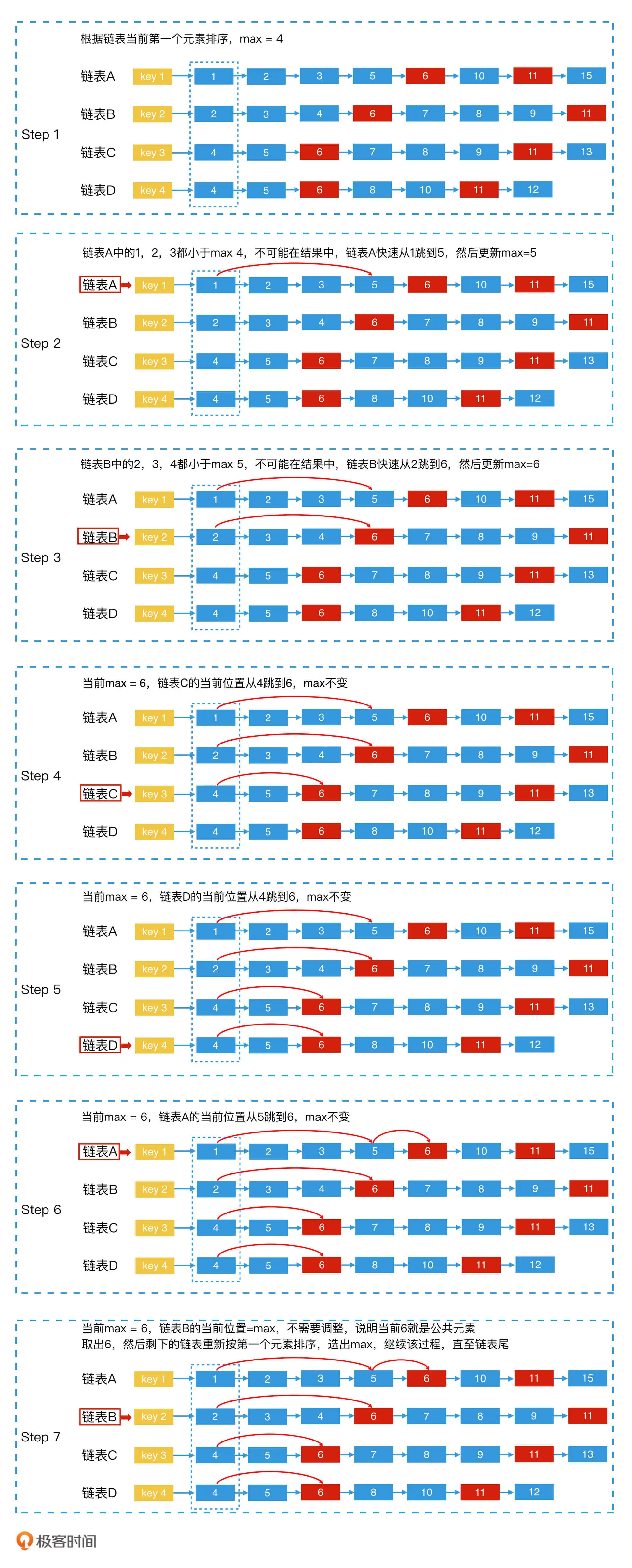
ElasticSearch学习篇12_《检索技术核心20讲》基础篇
背景 学习极客实践课程《检索技术核心20讲》https://time.geekbang.org/column/article/215243 课程分为基础篇、进阶篇、系统案例篇 主要记录企业课程学习过程课程大纲关键点,以文档形式记录笔记。 内容 检索技术:它是更底层的通用技术,…...
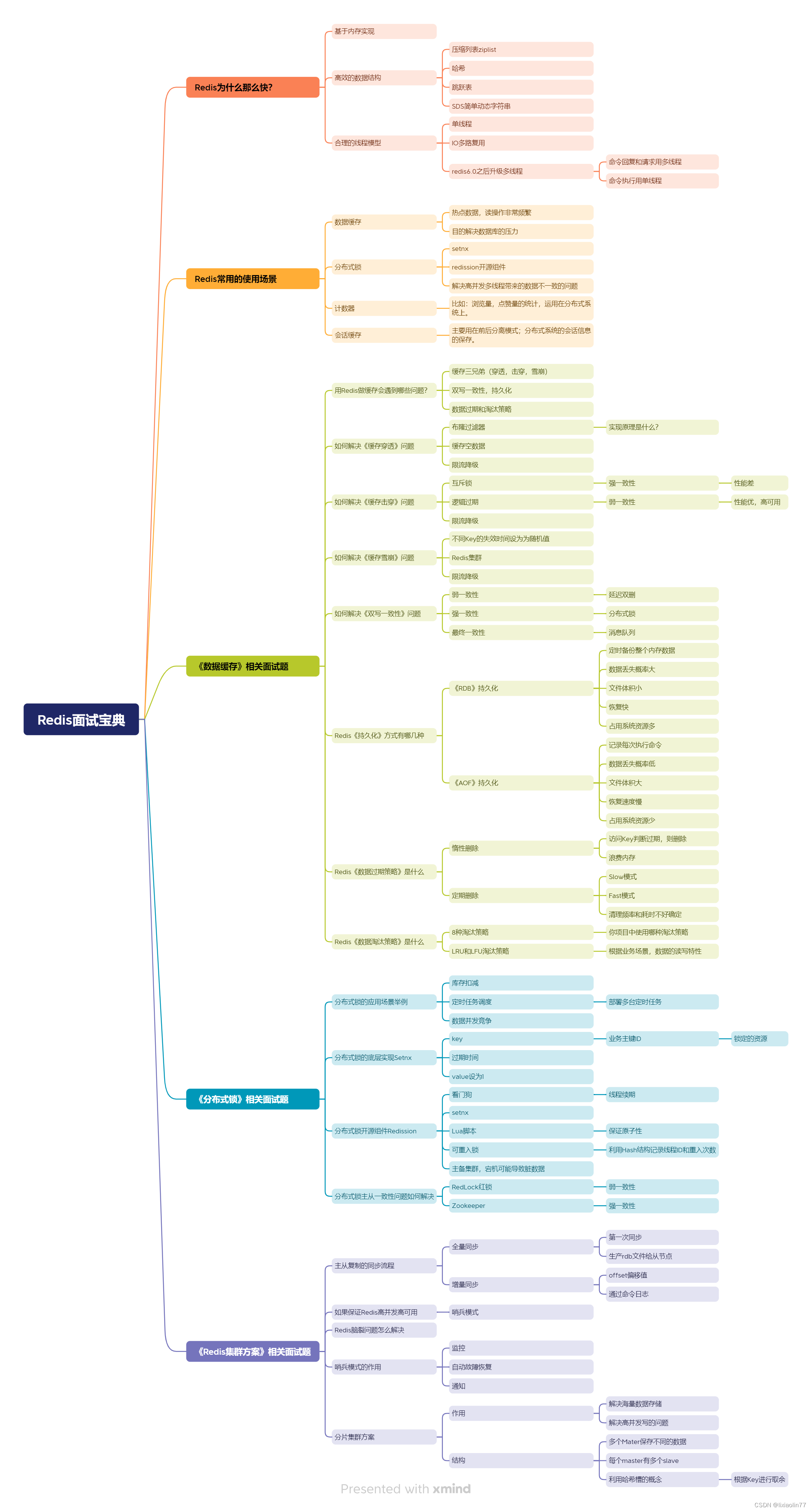
Reids高频面试题汇总总结
一、Redis基础 Redis是什么? Redis是一个开源的内存数据存储系统,它可以用作数据库、缓存和消息中间件。Redis支持多种数据结构,如字符串、哈希表、列表、集合、有序集合等,并提供了丰富的操作命令来操作这些数据结构。Redis的主要特点是什么? 高性能:Redis将数据存储在内…...
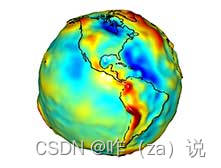
19 - grace数据处理 - 补充 - 地下水储量计算过程分解 - 冰后回弹(GIA)改正
19 - grace数据处理 - 补充 - 地下水储量计算过程分解 - 冰后回弹(GIA)改正 0 引言1 gia数据处理过程0 引言 由水量平衡方程可以将地下水储量的计算过程分解为3个部分,第一部分计算陆地水储量变化、第二部分计算地表水储量变化、第三部分计算冰后回弹改正、第四部分计算地下…...
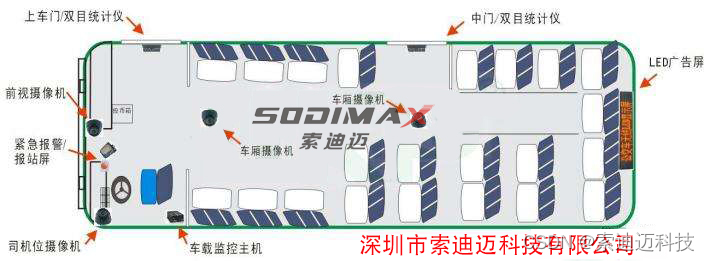
车载客流统计设备:双目3D还原智能统计算法的应用与优势
随着城市交通的日益繁忙和公共交通系统的不断完善,对公交车等交通工具的客流统计和分析变得越来越重要。传统的客流统计方法往往存在效率低下、精度不足等问题,难以满足现代城市交通管理的需求。而基于双目3D还原智能统计算法的车载客流统计设备…...
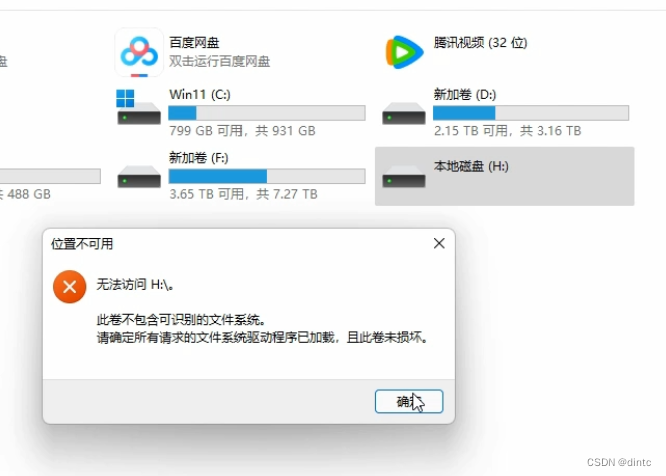
U盘无法打开?数据恢复与预防措施全解析
在日常生活和工作中,U盘已成为我们存储和传输数据的重要工具。然而,有时我们会遇到U盘无法打开的情况,这无疑给我们带来了诸多不便。本文将深入探讨U盘打不开的现象、原因及解决方案,并分享如何预防此类问题的发生。 一、U盘无法访…...

apollo版本更新简要概述
apollo版本更新简要概述 Apollo 里程碑版本9.0重要更新Apollo 开源平台 9.0 的主要新特征如下:基于包管理的 PnC 扩展开发范式基于包管理的感知扩展开发范式全新打造的 Dreamview Plus 开发者工具感知模型全面升级,支持增量训练 版本8.0版本6.0 Apollo 里…...

基于心电疾病分类的深度学习模型部署应用于OrangePi Kunpeng Pro开发板
一、开发板资源介绍 该板具有4核心64位的处理器和8TOPS的AI算力,让我们验证一下,在该板上跑深度学习模型的效果如何? 二、配网及远程SSH登录访问系统 在通过microusb连接串口进入开发板调试,在命令行终端执行以下命令 1&#…...

vue中axios的使用
1.get请求 axios.get(http://127.0.0.1:2333/show_course, {params: {param: choice} }) .then((response) > {this.list response.data; }) .catch((error) > {console.error(error); }); 2.post请求:当需要向服务器提交数据以创建新资源时使用。例如&…...

Spark SQL【Java API】
前言 之前对 Spark SQL 的影响一直停留在 DSL 语法上面,感觉可以用 SQL 表达的,没有必要用 Java/Scala 去写,但是面试一段时间后,发现不少公司还是在用 SparkSQL 的,京东也在使用 Spark On Hive 而不是我以为的 Hive O…...

如何免费下载百度文库文档:三步搞定PDF保存的终极指南
如何免费下载百度文库文档:三步搞定PDF保存的终极指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要下载券…...

STM32F407通过SPI接口高效读写SD卡:CubeMX配置与底层驱动实战
1. SD卡基础与SPI通信原理 SD卡作为嵌入式系统中最常用的存储介质之一,其SPI模式因其接线简单、协议清晰而广受欢迎。先说说我实际项目中遇到的坑:曾经因为没理解清楚SPI模式下SD卡的初始化时序,导致整整两天卡在设备无法识别的困境里。 SD卡…...

编程统计公司内部资料查阅使用数据,优化资料分类存储方式。提升职场员工工作查阅办事效率。
构建一个公司内部资料查阅使用统计与资料分类存储优化的商务智能示例项目,去营销化、中立化,仅用于学习与工程实践参考。一、实际应用场景描述在中大型企业中,内部资料(制度、流程文档、技术手册、项目档案)数量庞大&a…...

3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA
3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 还在为…...

Applite:告别命令行!macOS软件管理的图形化终极解决方案
Applite:告别命令行!macOS软件管理的图形化终极解决方案 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为Homebrew复杂的命令行操作而头疼吗&…...

UVa 366 Cutting Up
题目描述 拼布者经常需要将布料切割成 111 \times 111 的小正方形。他们有一种特殊工具(旋转切割刀),可以一次切割多层布料,切割层数的上限由布料类型决定(题目输入的第一个参数 KKK)。切割时,无…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...

别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额
别再让某个用户占满硬盘了!手把手教你用Linux quota给CentOS 7/8的/home目录设置磁盘限额 想象一下这样的场景:你管理的服务器上,十几个开发人员共享着同一个存储空间。某天突然收到警报——磁盘空间不足!调查后发现,一…...

OpenAgentsControl:构建多智能体协同系统的开源框架解析
1. 项目概述:一个面向智能体控制的开放框架最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的开源仓库:darrenhinde/OpenAgentsControl。这个项目名字直译过来就是“开放智能体控制”,听起来就很有搞…...

Windows上运行Swift代码的三种实战路径
1. 为什么Windows开发者需要Swift? Swift作为苹果生态的主力编程语言,近年来在服务端开发、机器学习等领域的应用越来越广泛。但很多刚接触Swift的Windows开发者会发现:官方文档里压根没提Windows支持!这其实是因为Swift最初就是…...