java高级——Collection集合之List探索(包含ArrayList、LinkedList、Vector底层实现及区别,非常详细哦)
java高级——Collection集合之List探索
- 前情提要
- 文章介绍
- 提前了解的知识点
- 1. 数组
- 2. 单向链表
- 3. 双向链表
- 4. 为什么单向链表使用的较多
- 5. 线程安全和线程不安全的概念
- ArrayList介绍
- 1. 继承结构解析
- 1.1 三个标志性接口
- 1.2 AbstractList和AbstractCollection
- 2. ArrayList底层代码实现
- 2.1 五个常量的作用
- 2.2 三个构造方法
- 2.3 解析add方法,初步了解扩容机制
- 2.4 解析扩容核心方法:grow()——1.5倍扩容
- 2.5 ensureCapacity方法动态扩容
- 2.6. subList()方法底层解析(重点)
- 2.7. indexOf与contains方法
- 2.8. fail-safe机制、modCount作用、checkForComodification方法
- 2.9 两种迭代器iterator和listIterator
- LinkedList介绍
- 1. 继承结构介绍
- 1.1 Queue接口
- 1.2 Deque接口
- 1.3 LinkedList和ArrayList的区别,如何选择使用哪个
- Vector介绍
- 1. 继承结构解析
- 2. Vector和ArrayList的区别
- 2.1. 扩容量不同(Vector为1倍,ArrayList为1.5倍)
- 2. 2 Vector是线程安全的
- 3 Collections工具类:synchronizedList()实现线程安全
- 4 Vector存在的问题
- 5 CopyOnWriteArrayList 写时复制策略
- 总结
- 下期预告
前情提要
上一篇文章我们探索了一下String字符串在jvm中的实现,这篇文章来了解一下java中最重要的知识点之一,Collection。
java高级——String字符串探索(在jvm底层中如何实现,常量池中怎么查看)
文章介绍
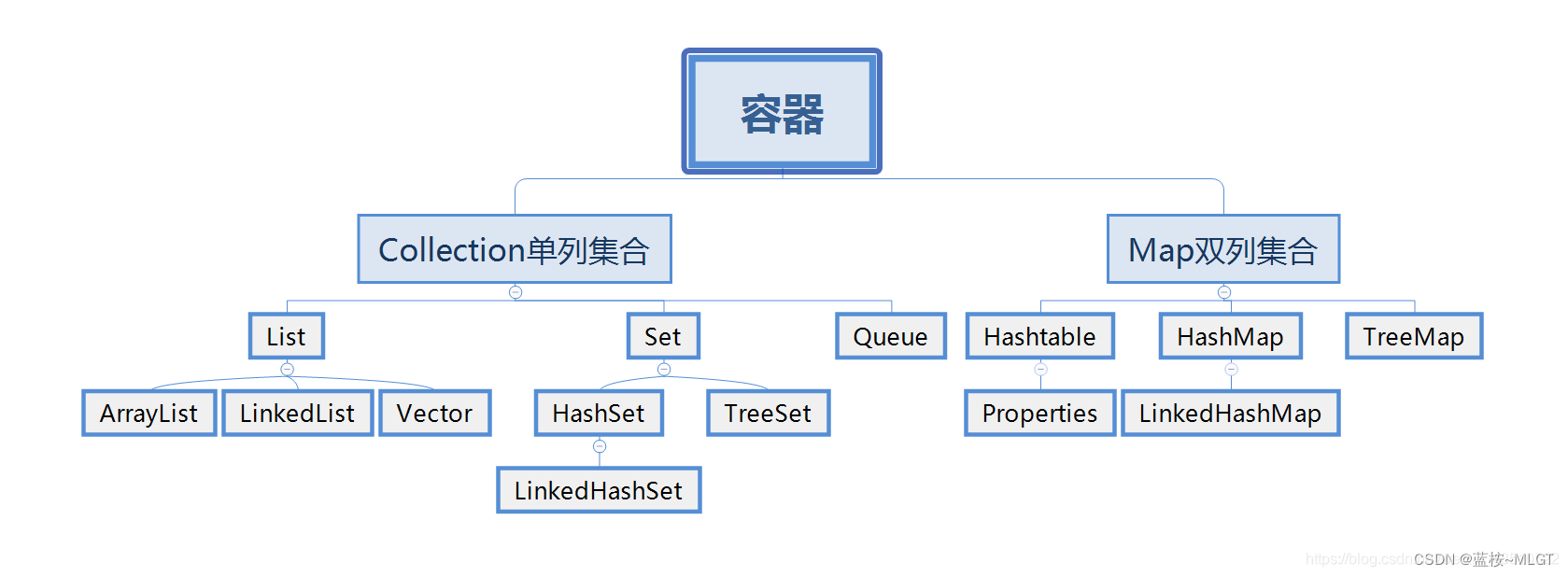
上图展现了java中容器的简化知识点,真实的继承图要更加复杂,上面只是列出了最重要和最常用的结构。本文主要的方向是Collection单列集合的List,而提起List,其中最常用的就是ArrayList,几乎占据了开发中80%的地位,本文将对ArrayList重点讲解,底层如何实现以及常用方法介绍。
提前了解的知识点
1. 数组
数组是有序的元素序列,有以下优点:
- 数组是
相同数据类型的元素的集合。 - 数组中各元素的存储是有先后顺序的,它们在内存中按照这个顺序连续存放到一起。
内存地址(连续存储) - 因为是随机访问,
查找效率高
缺点:
- 需要在申明时指定长度,
无法动态扩容。 增删数据效率较低,因为内存连续的原因,只要进行某个元素操作势必会带动其它元素的移动。无法存储float或double等基本类型的数据。
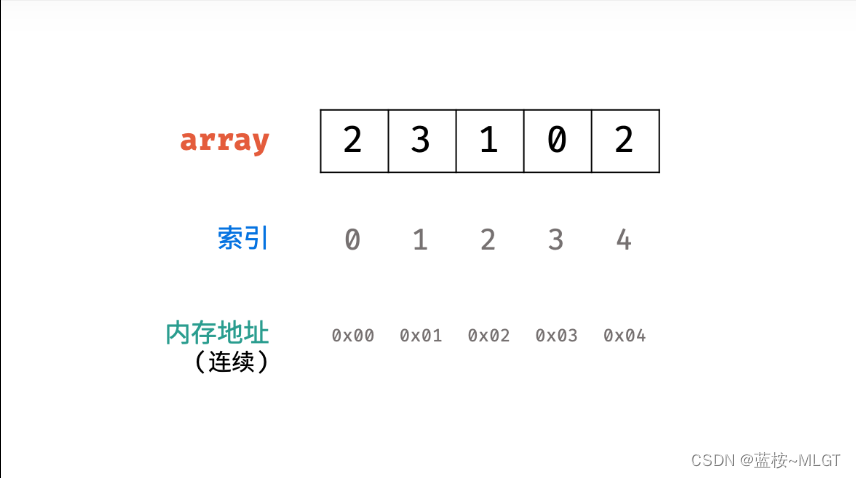
数组有着非常优秀的访问速度,因为内存连续的特性,访问速度出奇的快,但内存连续这也是一个致命的缺点,动态改变数组效率比较低。所以之后大多数人喜欢使用链表,也就是我们的List。
2. 单向链表
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列节点组成,节点可以在运行时动态生成,节点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。总结为以下特点:
- 物理地址无序且不连续;
- 逻辑层面是一个有序的链路结构;
- 可以动态生成节点;
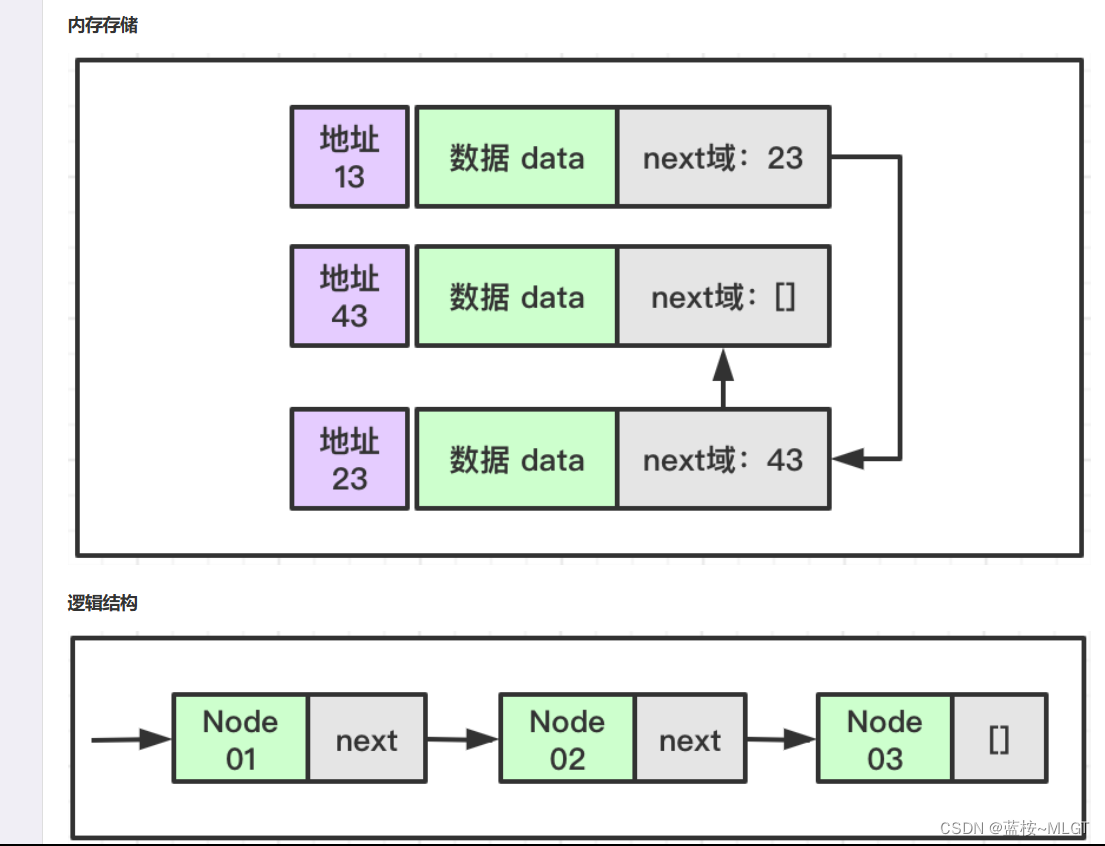
上面的三个特点解决了数组需要预先知道数据长度的短板,且可以灵活的运用内存空间,实现内存的动态管理。
而单向链表属于链表的一种,其特点是链表的链接方向是单向的,链表的遍历要从头部开始顺序读取;结点构成,head指针指向第一个成为表头结点,终止于最后一个指向NULL的指针。特点如下:
- 因为是顺序读取,每次查找都需要
从头开始遍历,速度稍慢; - 操作数据不方便,如果是在中间添加元素,则要移动很多个元素;
3. 双向链表
双向链表也叫双链表,是链表的一种,链表的每个数据结点中都有两个指针,分别指向直接后继和直接前驱,从双向链表中的任意一个结点开始,都可以很快速地访问它的前驱结点和后继结点,链表结构的使用多数都是构造双向循环链表。特点如下:
- 因为有直接后继和直接前驱,也就是任何一个节点都知道它的上一个和下一个节点的地址,所以
读取操作很快。 操作数据比较快,每当改变一个节点时,只需要改变相邻的前驱节点和后继节点。
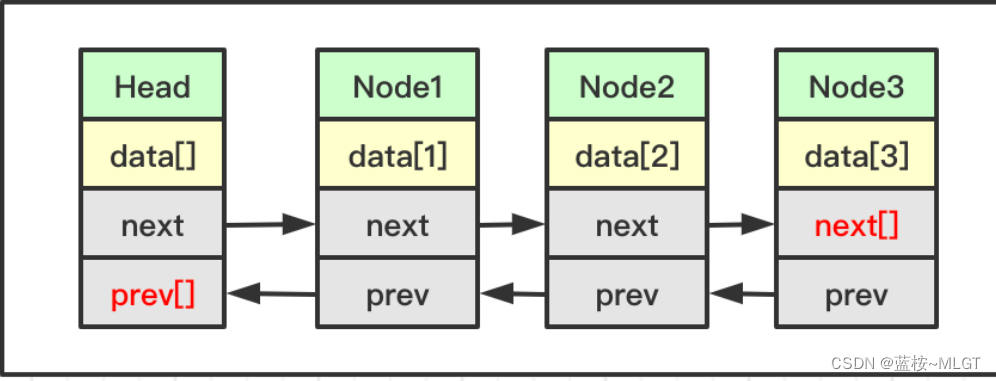
参考:单向链表和双向链表
4. 为什么单向链表使用的较多
上面说到双向链表怎么看都有优势,从操作上还是读取速度上,但是双向链表相对单向链表有两个指针,这就代表了存储空间的增大,而且维护成本较高,这就变相的印证了一句话,宁可慢点,也不能太麻烦哈哈哈。
5. 线程安全和线程不安全的概念
所谓线程安全就是加锁机制,这个和数据库打过交道的同学比较熟悉,当多个线程同时操作一条数据时,如果不进行加锁,就会导致数据错误(A修改为了1,B修改为了2,最后A可能看到的是2而不是1),加锁之后,当不同线程操作同一条数据时,一定保证那一刻只有一个线程操作那条数据,操作结束后交给下一个线程。举一个现实生活中的例子,比如你去租房子,那个房子有很多人在看,你相中了这个房间,准备明天去看看,结果有人提前你一步交了定金,这就相当于加了一把锁,虽然那个人还没有签合同,但定金保证了这个房子别人暂时不能看了,这就是线程安全的概念。而线程不安全则是相反,用专业属于来讲就是违背了下面三个条件之一:
原子性:一个或多个线程操作 CPU 执行的过程中被中断,互斥性称为操作的原子性。可见性:一个线程对共享变量的修改,其他线程不能立刻看到。有序性:程序执行的顺序没有按照代码的先后顺序执行。
ArrayList介绍
1. 继承结构解析
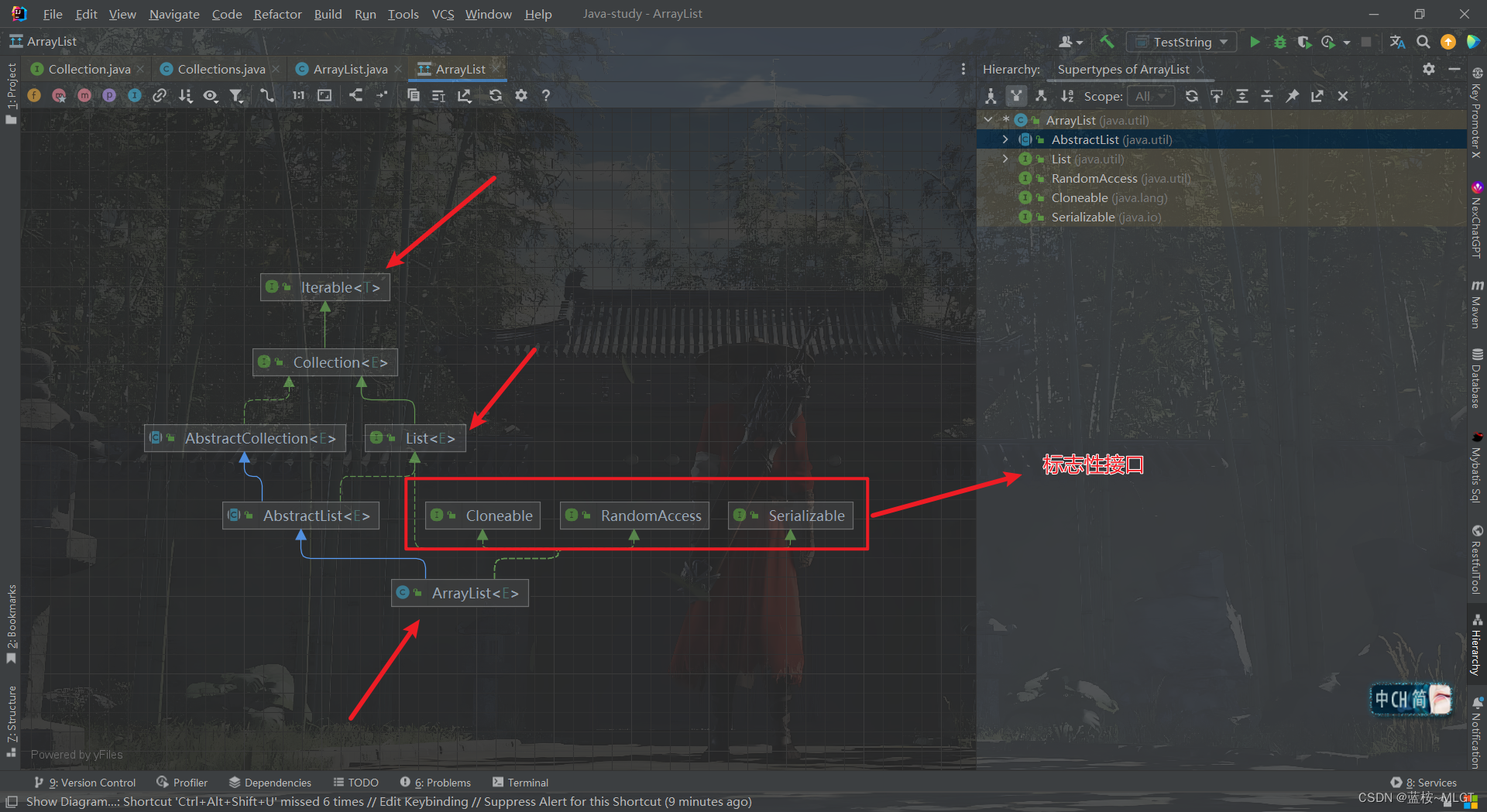
1.1 三个标志性接口
- RandomAccess:表示可以随机访问
- Cloneable:可以克隆
- Serializable:可序列化
RandomAccess表示的是随机访问,这个接口点进去啥都没有,标志性接口作用就是赋予你一个标志,之后在操作的时候如果你有这个标志,可以进行特殊的操作,而RandomAccess就是随机访问的标志,因为ArrayList底层是用数组实现的,是动态数组的概念,所以有随机访问的特性。
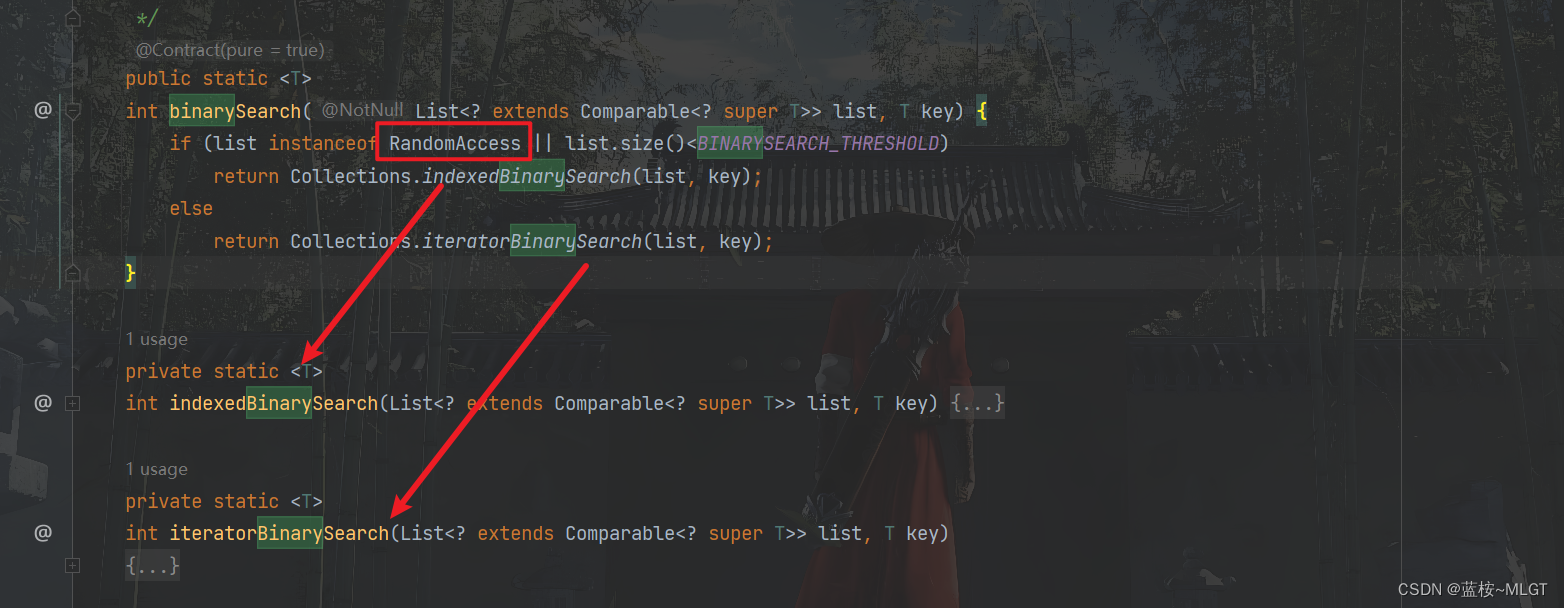
关于RandomAssess接口简单说几个结论,Collections类中有相关的实现,目前我们只需要知道,有这个标识的走indexedBinarySearch,也就是通过下标寻找对应的元素,相反则是通过iteratorBinarySearch迭代器,双向链表LinkedList使用迭代器相对快一些,详细了解看下面这篇。
RandomAccess详解
Cloneable同样,是一个可以克隆的标志。
Serializable表示可序列化,序列化说明一下,是将数据结构或对象转换成一种可存储或可传输格式的过程。在序列化后,数据可以被写入文件、发送到网络或存储在数据库中,以便在需要时可以再次还原成原始的数据结构或对象。序列化的过程通常涉及将数据转换成字节流或类似的格式,使其能够在不同平台和编程语言之间进行传输和交换。
说白了就是这玩意儿能在网络上传输和存储,我们应该用到过在接口调用时,直接将一个List作为传输的参数吧,或者包装在对象中,实际就是因为实现了这个接口。
1.2 AbstractList和AbstractCollection
这两个类是ArrayList的父类,其实研究意义并没有那么大,里面的方法基本和ArrayList相差不大,可以理解为ArrayList的前身,祖宗,后面儿子更牛逼一些。
2. ArrayList底层代码实现
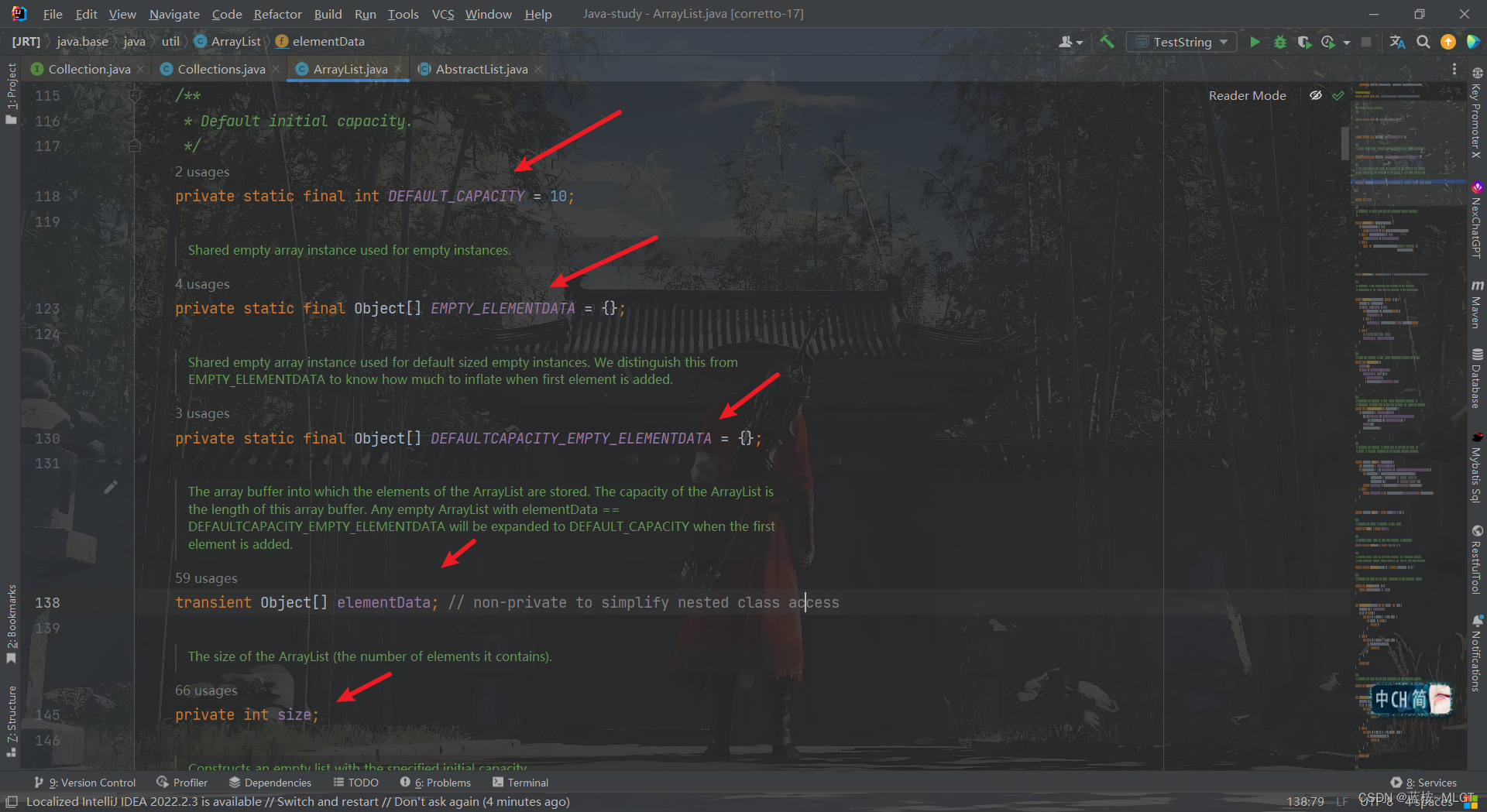
2.1 五个常量的作用
首先了解一下上面五个常量是什么意思。
DEFAULT_CAPACITY:默认初始化容量,也就是new ArrayList的初始容量;EMPTY_ELEMENTDATA:空数组的实例,用于有参构造;DEFAULTCAPACITY_EMPTY_ELEMENTDATA:空数组的实例,用于无参构造;elementData:实际存储元素的对象,后续扩容也操作的这个对象;size:数组的长度;
上面的五个常量唯一不好理解的就是第二和第三个,都是一个空数组,为什么要存在两个,除了一个是无参和有参的区别外,DEFAULTCAPACITY_EMPTY_ELEMENTDATA可以知道第一次add元素时需要的扩容数量。不着急,我们根据下面的几个构造方法就可以很清楚的了解了。
2.2 三个构造方法
/*** 构造一个初始容量为 10 的空列表。*/public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}
第一个无参构造,很清晰,只是给elementData赋值了一个空数组,长度为10,代码中看不到哪里的长度为10是吧,不用在意,最底层其实就是一个长度为10的数组。
/*** 构造具有指定初始容量的空列表。Params: initialCapacity – * 列表的初始容量 抛出: IllegalArgumentException – 如果指定的初始容量为负数*/public ArrayList(int initialCapacity) {if (initialCapacity > 0) {this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}}
第二个是有参构造,参数为指定容量的大小,上面的代码也很好理解,如果initialCapacity大于0则new一个指定大小的数组赋值,为0则赋值空数组,小于0报错。
一般在开发中,如果提前知道我们要操作的数组大小或者可以估计出大概的长度,建议使用这个有参构造,提前开辟出指定大小的ArrayList,后面就不用进行多次扩容了,可以提高代码的执行效率。
/*** 构造一个列表,其中包含指定集合的元素,按集合的迭代器返回这些元素的顺序排列** @param c the collection whose elements are to be placed into this list* @throws NullPointerException if the specified collection is null*/public ArrayList(Collection<? extends E> c) {Object[] a = c.toArray();if ((size = a.length) != 0) {if (c.getClass() == ArrayList.class) {elementData = a;} else {elementData = Arrays.copyOf(a, size, Object[].class);}} else {// replace with empty array.elementData = EMPTY_ELEMENTDATA;}}
这是一个参数为Collection的有参构造,一般我们是不会这么使用的,只有在某些特殊情况需要利用反射机制操作数组才这么使用。上面的代码看起来也很简单,就是将Collection通过toArray方法进行转换,之后赋值,只不过加了一个c.getClass() == ArrayList.class的判断,不成立自己会拷贝一份数组,其实通过追踪,toArray方法其实就在ArrayList中,到最后执行的还是Arrays类中的copyOf方法,复制数组。
2.3 解析add方法,初步了解扩容机制
public boolean add(E e) {
1 modCount++;
2 add(e, elementData, size);return true;}private void add(E e, Object[] elementData, int s) {
3 if (s == elementData.length)
4 elementData = grow();
5 elementData[s] = e;
6 size = s + 1;}
上面是直接往数组中添加元素的方法,第一个方法是暴露给开发者调用的,第二个方法是一个重载方法,用于真正执行添加的方法,通过六个点进行分析。
-
modCount++:这一行作用是记录我们对ArrayList操作了多少次,这里我们只需要知道干什么就行,具体什么作用会在本文最后进行详细讲解。 -
add(e, elementData, size):调用真正的添加方法,e为添加的元素,elementData为ArrayList数组对象,size为数组的长度(注意,如果是无参构造初始化,则size为0)。 -
if (s == elementData.length):这个判断就是看执行扩容还是不执行,一旦size的大小和集合中元素长度一致,就代表数组的容量不够了,需要进行扩容了。 -
grow():扩容的核心方法。 -
elementData[s] = e:扩容后给最后给数组的最后放入我们要添加的元素。 -
size = s + 1:集合中元素长度加1。
看上面的六步得出,其实只有第四步的扩容是最核心的,添加的元素就是在扩容后放到了数组的最后一个位置,接下来我们对grow方法进行跟踪。
2.4 解析扩容核心方法:grow()——1.5倍扩容
private Object[] grow() {return grow(size + 1);}/*** 增加容量以确保它至少可以容纳最小容量参数指定的元素数** @param minCapacity the desired minimum capacity* @throws OutOfMemoryError if minCapacity is less than zero*/private Object[] grow(int minCapacity) {int oldCapacity = elementData.length;if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
1 int newCapacity = ArraysSupport.newLength(oldCapacity,minCapacity - oldCapacity, /* minimum growth */oldCapacity >> 1 /* preferred growth */);
2 return elementData = Arrays.copyOf(elementData, newCapacity);} else {
3 return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];}}
- 获取扩容的大小;
public static int newLength(int oldLength, int minGrowth, int prefGrowth) {int prefLength = oldLength + Math.max(minGrowth, prefGrowth); // might overflowif (0 < prefLength && prefLength <= SOFT_MAX_ARRAY_LENGTH) {return prefLength;} else {// put code cold in a separate methodreturn hugeLength(oldLength, minGrowth);}}
上面是ArraysSupport.newLength方法,这个方法就是用来获取扩容长度,核心就是将最小增长量minGrowth和准备扩容的长度prefGrowth相加获取扩容后长度prefLength,下面的判断实际是为了防止数组长度超过最大值2147483639。
了解这个方法后我们就要知道要干什么了,就是计算准备扩容的大小prefGrowth,回到最开始的grow方法中,它传入的参数是oldCapacity >> 1 ,而oldCapacity是我们原始数组elementData的长度,假设我们是无参构造的集合,那这个值就是10,那10 >> 1是多少呢?
注意:>> 是位运算符,可以理解为除法,是编译原理中常见的考点,这里指的是向右移动一位,10的源码是00001010,右移一位就是00000101,也就是5,相当于除2。
那么扩容的大小计算出来了,加上原始的大小10,最后我们要扩容到15的大小,那也就是多少倍,1.5倍,这是ArrayList中扩容的结论,1.5倍扩容,这下知道怎么来的了吧!
- 根据扩容后大小获取新数组
@IntrinsicCandidatepublic static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {@SuppressWarnings("unchecked")T[] copy = ((Object)newType == (Object)Object[].class)? (T[]) new Object[newLength]: (T[]) Array.newInstance(newType.getComponentType(), newLength);System.arraycopy(original, 0, copy, 0,Math.min(original.length, newLength));return copy;}
上面是copyOf最终执行的方法,实际就是创建一个创建一个新长度的数组,然后将旧的数组内容复制进去,不要纠结System.arraycopy方法,这是一个native方法,用C实现的,你也看不到哈哈哈。
- 第三步可以理解为创建一个初始化长度为10的数组,也就是初始化扩容。
2.5 ensureCapacity方法动态扩容
public void ensureCapacity(int minCapacity) {if (minCapacity > elementData.length&& !(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA&& minCapacity <= DEFAULT_CAPACITY)) {modCount++;grow(minCapacity);}}
看代码也没啥,就是给ArrayList进行执行大小的扩容,那有人就疑惑了,底层有自动扩容的机制,要这个方法有啥用呢?
存在即合理,这个方法是在我们初始化完ArrayList后进行扩容操作,最开始不是说构造方法可以指定大小来优化效率嘛,如果我们最开始不知道到底要存多少个,那就不优化效率了吗,没办法了吗?那肯定不行,这个方法不就有作用了吗。
还有,自动扩容机制是1.5倍,如果你有个几千几万条数据,要是一直这么扩容下去相对肯定慢吧,我直接一次扩容个几千不香吗。
2.6. subList()方法底层解析(重点)
看这儿看这儿,这个方法慎用慎用,不然会导致很多bug的!!!
直接说几点结论:
- subList方法并
没有创建一个新的List,而是使用了原List的视图,这个视图使用内部类SubList表示。
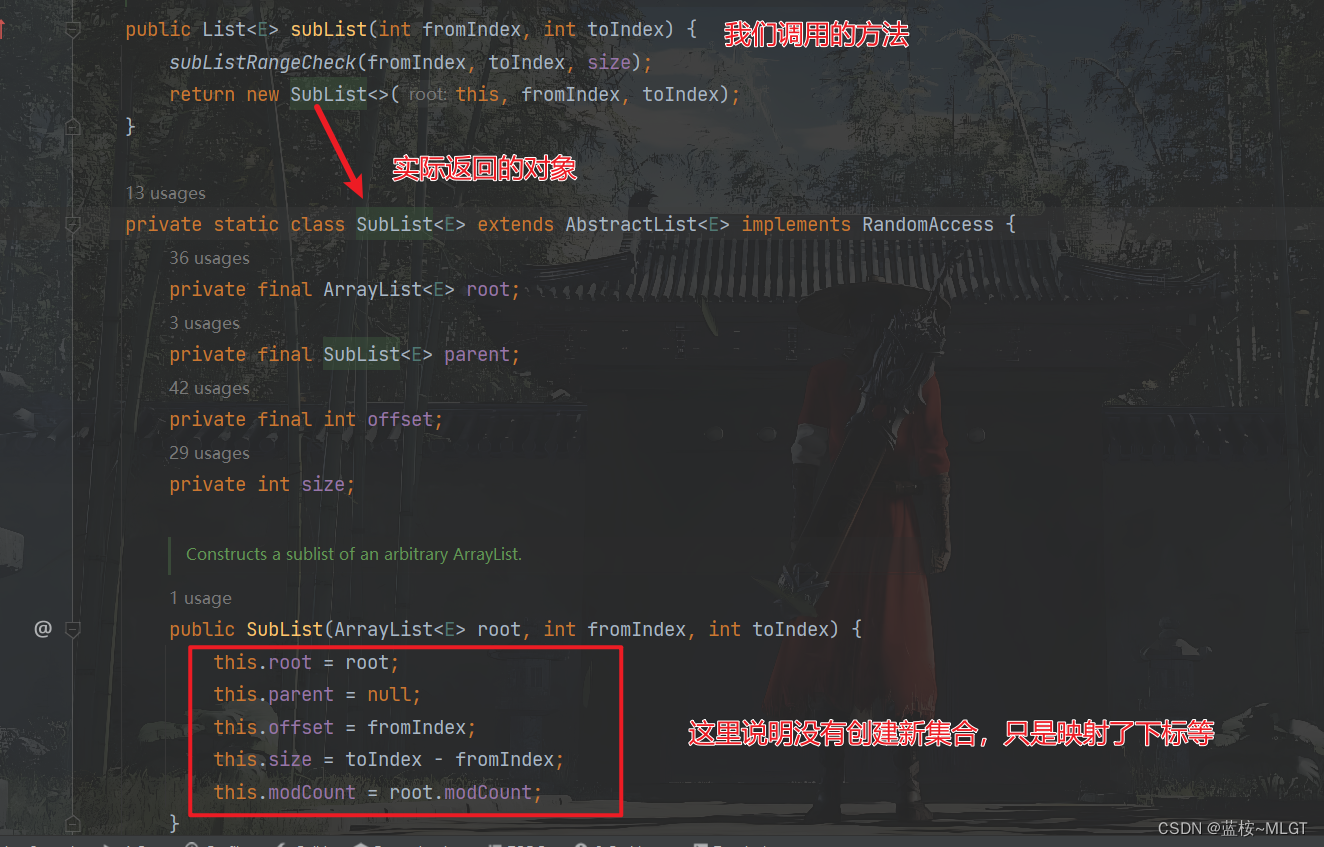
- 如果对
父List或子List中一个进行非线性操作(只改变元素的值,不改变集合的大小),两者都会改变。 - 如果对
子List进行非线性操作(改变集合大小如添加删除元素),父List会收到影响。 - 如果对
父List进行操作后,在操作子List(此时子List已经存在了),会报错ConcurrentModificationException。
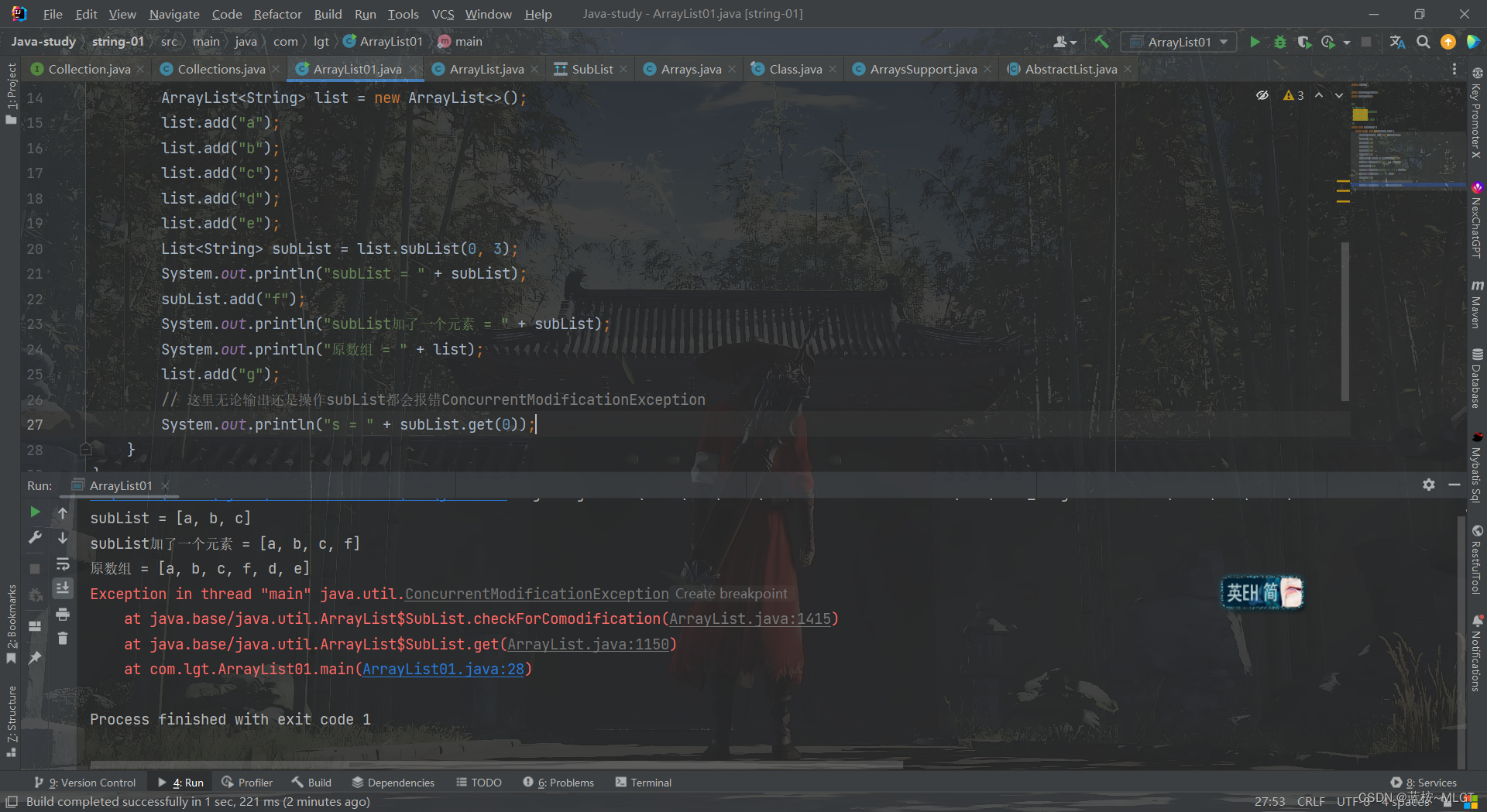
在使用subList的时候要注意,一旦操作不当就会导致报错,报错是小事,就怕不报错,你在subList中添加了一个元素,最后你返回了原数组,导致多了一条记录,误导了用户,这就严重了。所以一般在截取后都是新创建一个集合的。
参考:为什么阿里巴巴要求谨慎使用ArrayList中的subList方法
2.7. indexOf与contains方法
public boolean contains(Object o) {return indexOf(o) >= 0;}public int indexOf(Object o) {return indexOfRange(o, 0, size);}int indexOfRange(Object o, int start, int end) {Object[] es = elementData;if (o == null) {for (int i = start; i < end; i++) {if (es[i] == null) {return i;}}} else {for (int i = start; i < end; i++) {if (o.equals(es[i])) {return i;}}}return -1;}
contains方法实际调用的也是indexOf,所以我们看indexOf方法就行。
根据上面的代码可以得出,就是循环elementData中所有元素,如果o.equals某个元素则返回对应的下标,只不过我们要注意的是,对象o是可以为null的,一般参数给null会报错,这里可不会,所以在使用前一定要注意不能为null。
还有一点是equals方法,注意哈,这里的equals用的是Object类中的原始方法,只比较对象的内存地址,这个需求不能满足我们,实际开发中并不能保证两个对象的内存地址一样,但数据是一样的,这时候我们常用的手段是转为map,在map中找,或者使用stream流比较也很常见,不过还有一种更快的方法,既然我们知道这是通过equals方法比较的,那么我们能不能重写对象的equals方法呢?答案是可以,看下面的例子。
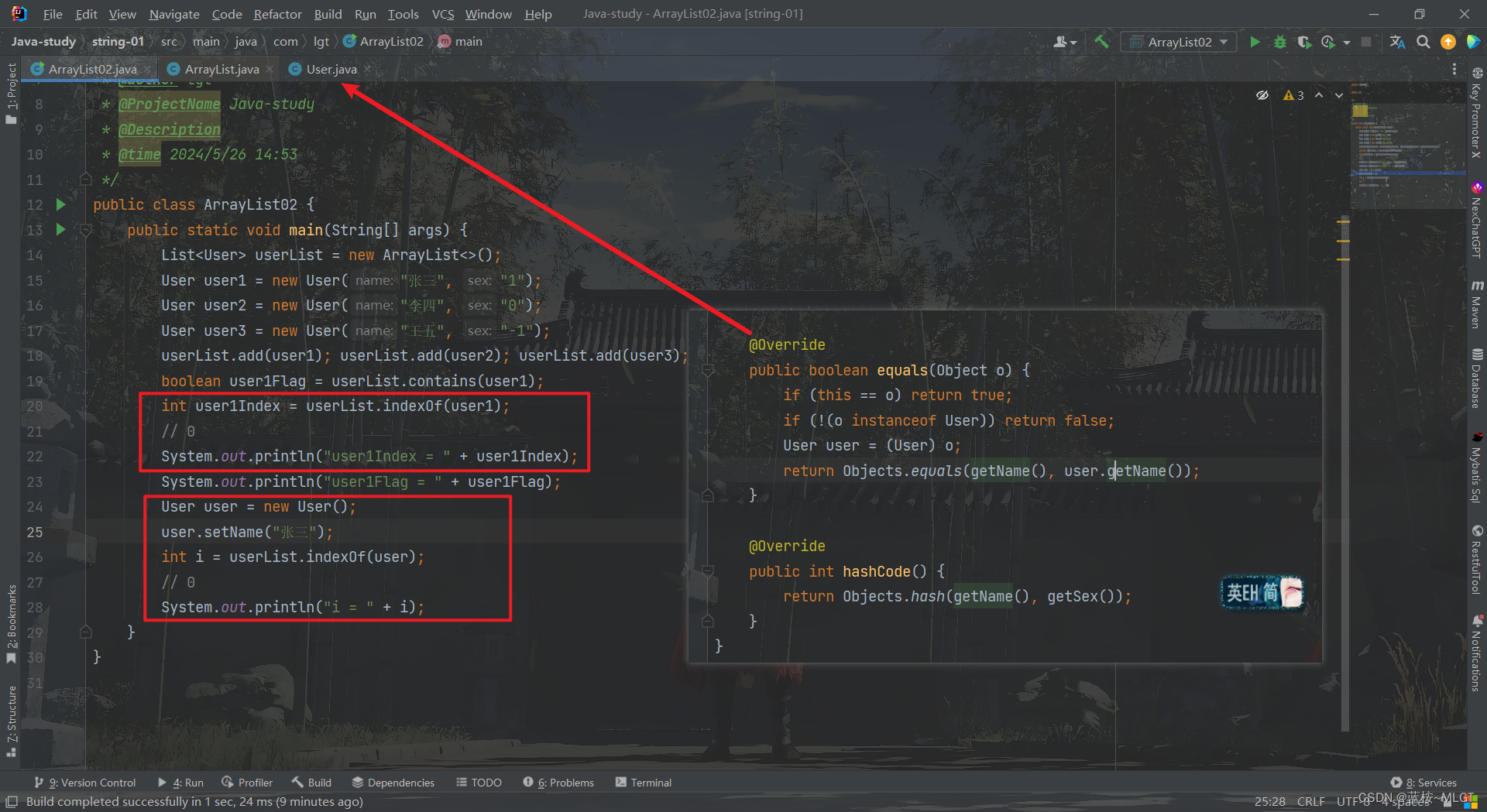
只要重写了equals方法,就可以满足我们在开发中的一些需求了,虽然stream流很方便,单从效率来讲,肯定最原始的是最快的。
顺带说一下,还有一个方法是lastIndexOf,和上面同理,实现方式稍有区别,也是for循环,只不过是倒序,也就是倒着循环,我最开始是以为定义一个变量,不断地赋值下标,最后循环结束返回呢,结果还是年轻了,要不说这是源码呢,怎么效率高怎么来。
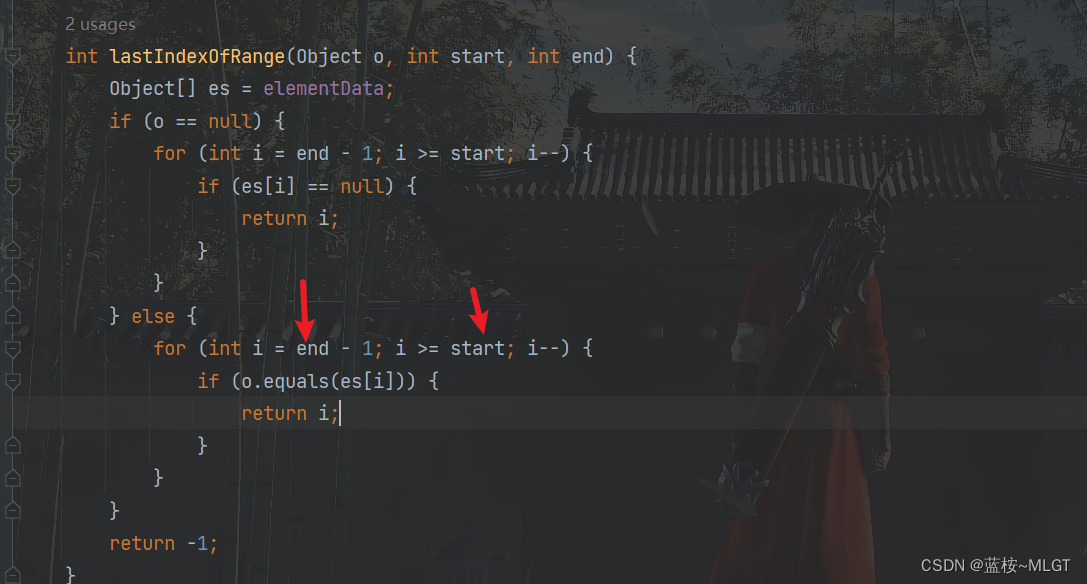
2.8. fail-safe机制、modCount作用、checkForComodification方法
fail-safe机制很常见,我们在开发中也经常使用,但就是不知道专业的名词。
public int divide(int divisor,int dividend){if(dividend == 0){throw new RuntimeException("dividend can't be null");}return divisor/dividend;
}
很简单,就是在某些执行逻辑前进行检查,如果有问题则进行报错,避免执行一些复杂逻辑或者说不应该执行的代码,导致一些不必要的结果。
modCount我们在之前讲过,当集合进行add或者remove操作时,modCount值会加一,到底有什么作用呢?其实就是给fail-safe机制使用的,而具体的实现方法就是checkForComodification,来我们简单看下。
private void checkForComodification(final int expectedModCount) {if (modCount != expectedModCount) {throw new ConcurrentModificationException();}}
这个方法在ArrayList源码中很多方法都有,比如迭代器、equals方法等等,具体作用就是为了防止多线程情况下操作同一个集合而导致的一些错误,我们常见的触发场景是在增强for循环中对集合进行add和remove操作时,就会触发这个错误,但是在普通for循环是不会有这个错误的哈,因为普通for循环只是在一个循环中多次操作同一个集合,每一次操作它的modCount值都是会同步的,而增强for循环(forEach)是基于迭代器的,具体看下面这篇文章。
一不小心就踩坑的fail-fast是个什么鬼
上面这篇文章对ArrayList的迭代器和上面所说的问题有详细的介绍,很清晰,想要了解的伙伴可以看看,或者记住一点。
要再循环中操作ArrayList的增删,就用迭代器,当然普通for循环也可以(经过测试),不过规范还是在迭代器中实现。
List<User> userList = new ArrayList<>();User user1 = new User("张三", "1");User user2 = new User("李四", "0");User user3 = new User("王五", "-1");userList.add(user1); userList.add(user2); userList.add(user3);// 会报错// for (User user : userList) {// if (user.getName().equals("李四")) {// userList.add(new User());// }// }int size = 0;for (int i = 0; i < userList.size(); i++) {User user = userList.get(i);if (user.getName().equals("李四")) {userList.add(new User("tese", "0"));}size += 1;}System.out.println("size = " + size); // 实际循环为4次System.out.println("userList = " + userList);
2.9 两种迭代器iterator和listIterator
在ArrayList中存在两种迭代器,首先说一下迭代器的概念,这是为了集合而专门设计的一个类,就是说所有的集合都会实现这个接口,无论是List还是Set还是Map,都可以使用迭代器遍历操作,我们可以理解为专为集合设计的一个for循环工具,为什么要使用迭代器,迭代器有什么好处呢?
迭代器除了是一个规范外,还有我们上面所说的2.8,有很不错的fail-safe机制,里面的checkForComodification方法提供的保护作用。具体我们在上面已经说过,不懂的伙伴可以再看一看源码。接下来我们介绍一下这两种迭代器的区别和相同点:
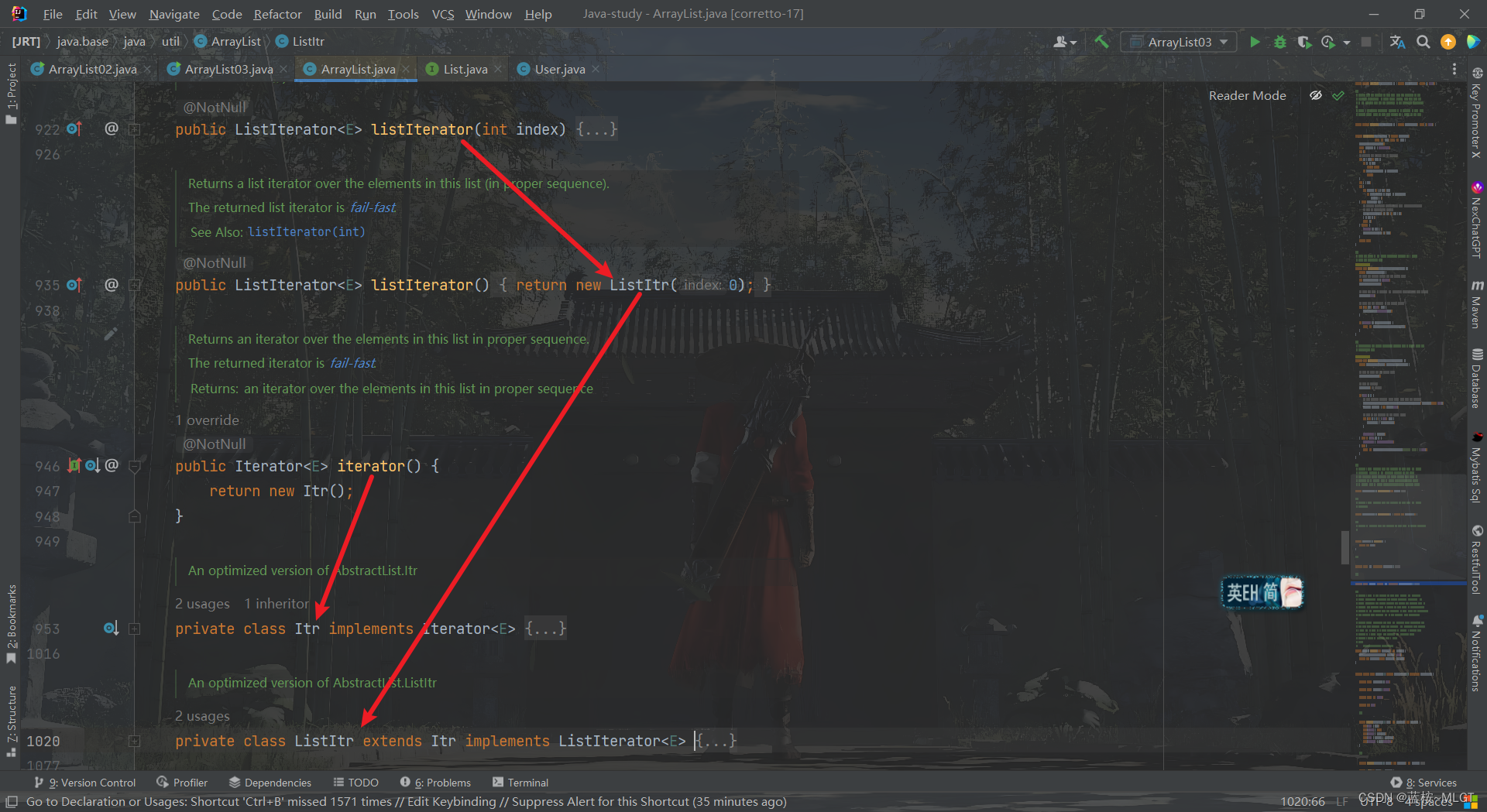
上面这张图说明了一个问题,两个方法最终返回的都是一个Itr对象,只是ListItr是继承自Itr,而在java中,继承一定能说明一个问题,子类肯定有比父类更多的功能,这里也是一样的,来瞅一下两个类中的方法:
Iterator迭代器:
-
hasNext():如果迭代器指向位置后面还有元素,则返回 true,否则返回false -
next():返回集合中Iterator指向位置后面的元素 -
remove():删除集合中Iterator指向位置后面的元素
ListIterator迭代器:
-
hasNext():如果迭代器指向位置后面还有元素,则返回 true,否则返回false
-
next():返回集合中Iterator指向位置后面的元素
-
remove():删除集合中Iterator指向位置后面的元素
-
add(E e): 将指定的元素插入列表,插入位置为迭代器当前位置之前 -
hasPrevious():如果以逆向遍历列表,列表迭代器前面还有元素,则返回 true,否则返回false -
nextIndex():返回列表中ListIterator所需位置后面元素的索引 -
previous():返回列表中ListIterator指向位置前面的元素 -
previousIndex():返回列表中ListIterator所需位置前面元素的索引 -
set(E e):从列表中将next()或previous()返回的最后一个元素返回的最后一个元素更改为指定元素e
// 首先有个ArrayList
ArrayList<Object> list = new ArrayList<>();
// 然后获取到迭代器
Iterator<Object> iterator = list.iterator();
// 再开始遍历ArrayList,使用hasNext()判断ArrayList中是否有下一个元素
while (iterator.hasNext()){// 如果ArrayList中有下一个元素,就使用next()方法获取下一个元素Object e = iterator.next();if ("条件".equals(e)){// 如果元素e满足某种条件就使用remove()删除该元素iterator.remove();}
} 上面就是我们常用的迭代器,不过listIterator明显更加强大,有6个新增的方法,分别能实现倒序遍历、获取前一个或者后一个元素的下标、新增元素或修改元素,这在有些场景下是非常有用的,毕竟list集合下标是我们经常使用的。
参考:ArrayList迭代器 JAVA中ListIterator和Iterator详解与辨析
LinkedList介绍
因为LinkedList和ArrayList在源码上差异并不大,所以这里不再分析源码,有兴趣的可以看看,主要是对继承结构中的两个接口进行分析,得出LinkedList的优势和缺点。
1. 继承结构介绍
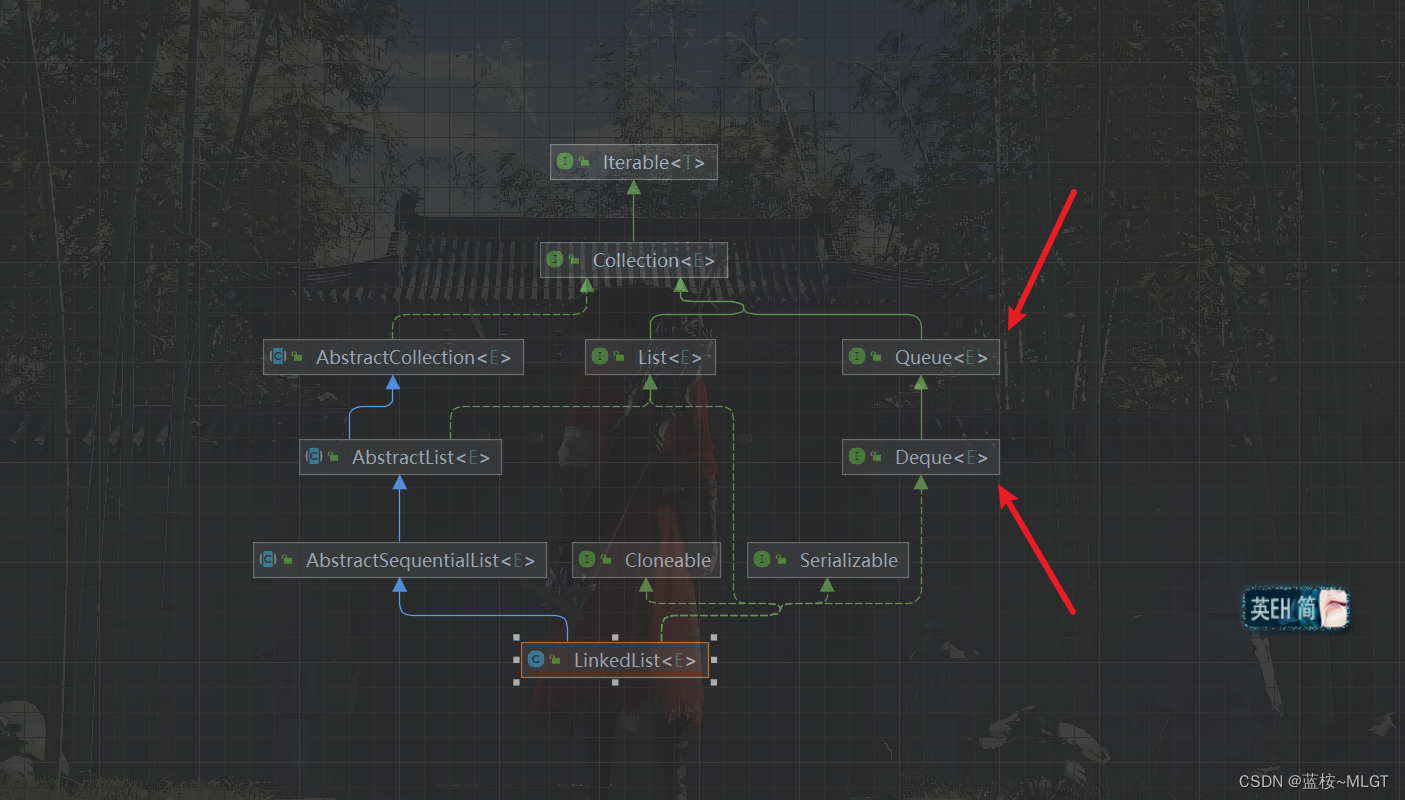
看图发现有两个没有在ArrayList中出现过的接口,这两个接口有什么作用呢?
首先Deque接口是继承Queue接口,所以Deque接口更有研究价值,不过我们先来了解一下Queue祖宗。
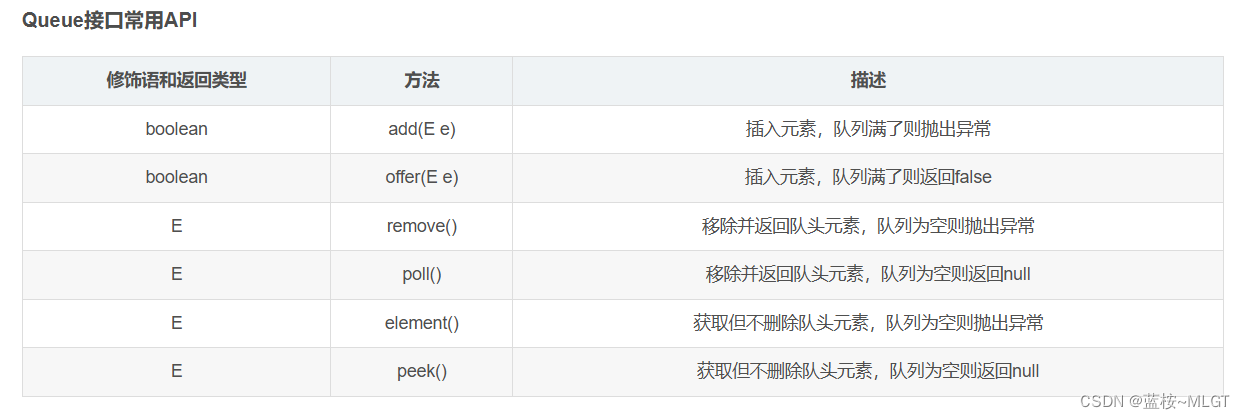
1.1 Queue接口
这是一个队列接口,队列有先进先出的特点,所以这个接口中就是为了这个特点而定义了几个方法(这儿借用一下别的博客图片),这个其实是为了Deque而准备的,有的人就疑惑了,为啥ArrayList没有实现,LinkedList是双向链表哦,而ArrayList是基于数组实现的。
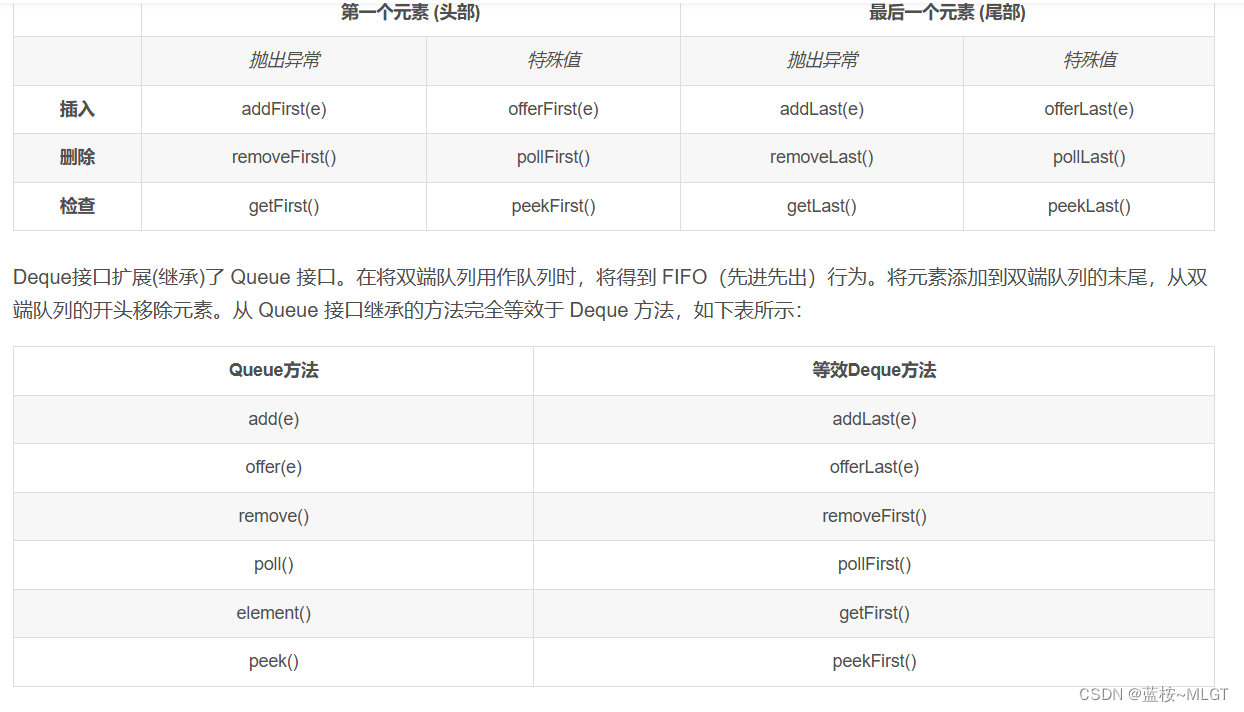
1.2 Deque接口
这是一个双端队列接口,所谓双端队列就是队列头和队列尾都可以进出,而上面所说的是普通队列,有了这个概念我们能得出什么结论呢?为什么说LinkedListList的添加和删除操作速度快呢?这个接口给了我们完美的答案。
参考:Java双端队列Deque使用详解
1.3 LinkedList和ArrayList的区别,如何选择使用哪个
区别:
LinkedList无法随机读取,速度相对于ArrayList较慢;LinkedList基于双向链表,增加和删除元素更快;
有了上面两个区别后,在实际开发中我们应该如何选择呢?一般在频繁读取操作时选用ArrayList,频繁操作中选择LinkedList,可是实际我们大多数还是使用ArrayList,也不会为了那点时间去用LinedList,不过在几个场景还是建议用LinkedList。
场景1:导出Excel时,这时候势必要频繁的操作集合(对于使用java原生API的开发者)。
场景2:对于数据量很大时,我们需要对集合进行删除操作,使用LinkedList。
场景3:当需要不断地new对象,后续进行赋值操作后放入集合时,使用LinkedList。
虽然开发中我们不太在意这个,可当数据量上来时这个时间差距就会被放大,千万不要小瞧,在一个大的系统中,效率一直是被人诟病的问题,而往往就是这些小的点会慢慢拉低整个系统的性能。
Vector介绍
1. 继承结构解析
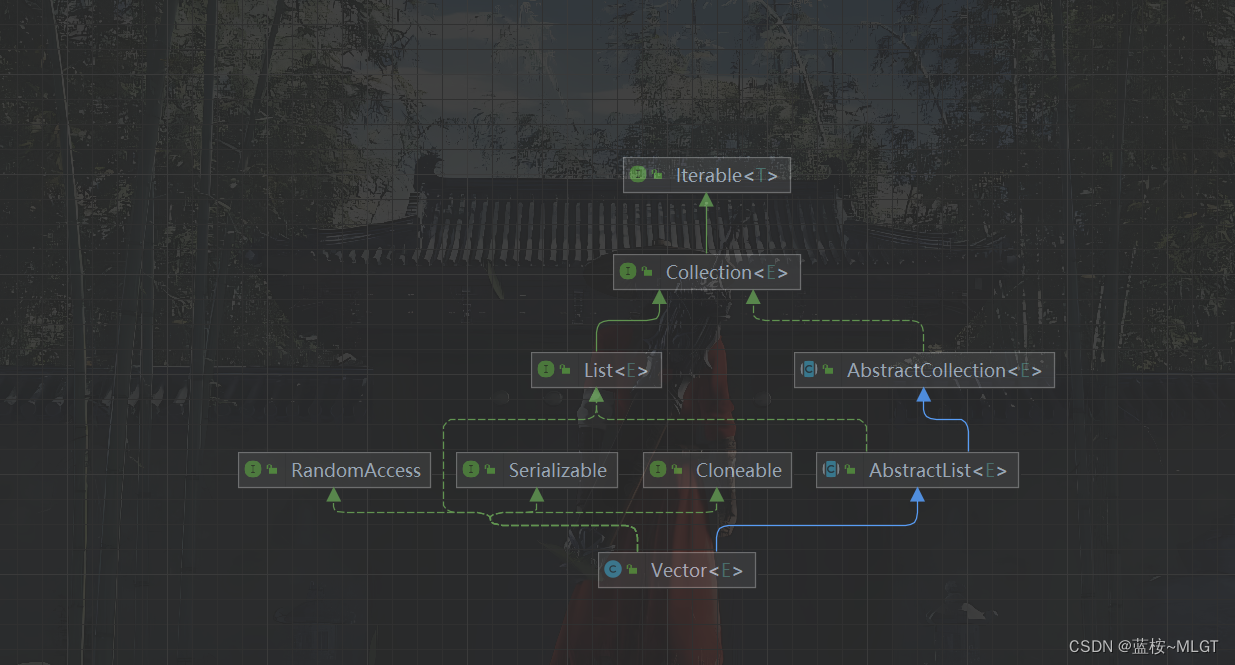
上图看着很熟悉对吧,Vector和ArrayList的继承结构基本相同的,只是在实现上Vector是线程安全的,而ArrayList则不是,所以重点还是对线程安全这个点进行讲解。
2. Vector和ArrayList的区别
2.1. 扩容量不同(Vector为1倍,ArrayList为1.5倍)
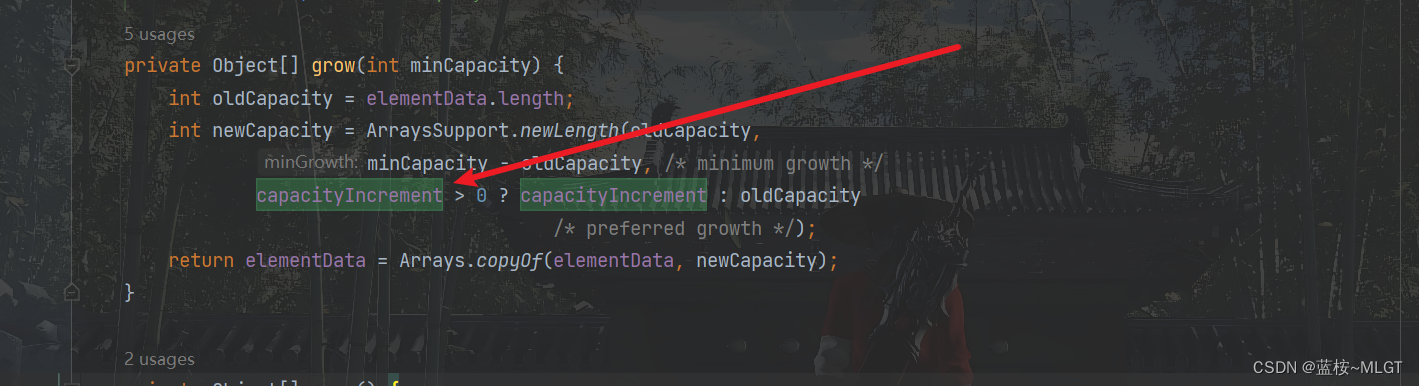
注意看上面这段代码,和ArrayList也很相似,不同点就在于ArraysSuport.newLength这个方法最后一个参数扩容的量是elementData的长度,也就是一倍的增长量,而capacityIncrement这个值是在构造方法复制的,当你new的时候不赋值,那就默认是1倍扩容。
2. 2 Vector是线程安全的
线程安全的概念我们在最开始就讲到了,直接通过代码验证一下ArrayList为什么不是线程安全的。
public static void main(String[] args) {List<String> list = new ArrayList<>();for (int i = 0; i < 30; i++) {String threadName = "threadName" + i;new Thread(() -> {renderList(threadName, list);}, threadName).start();}}public static void renderList(String threadName, List<String> list) {for (int i = 0; i < 50; i++) {list.add(threadName + String.valueOf(i));if (i == 20) {System.out.println("list = " + list);}}}
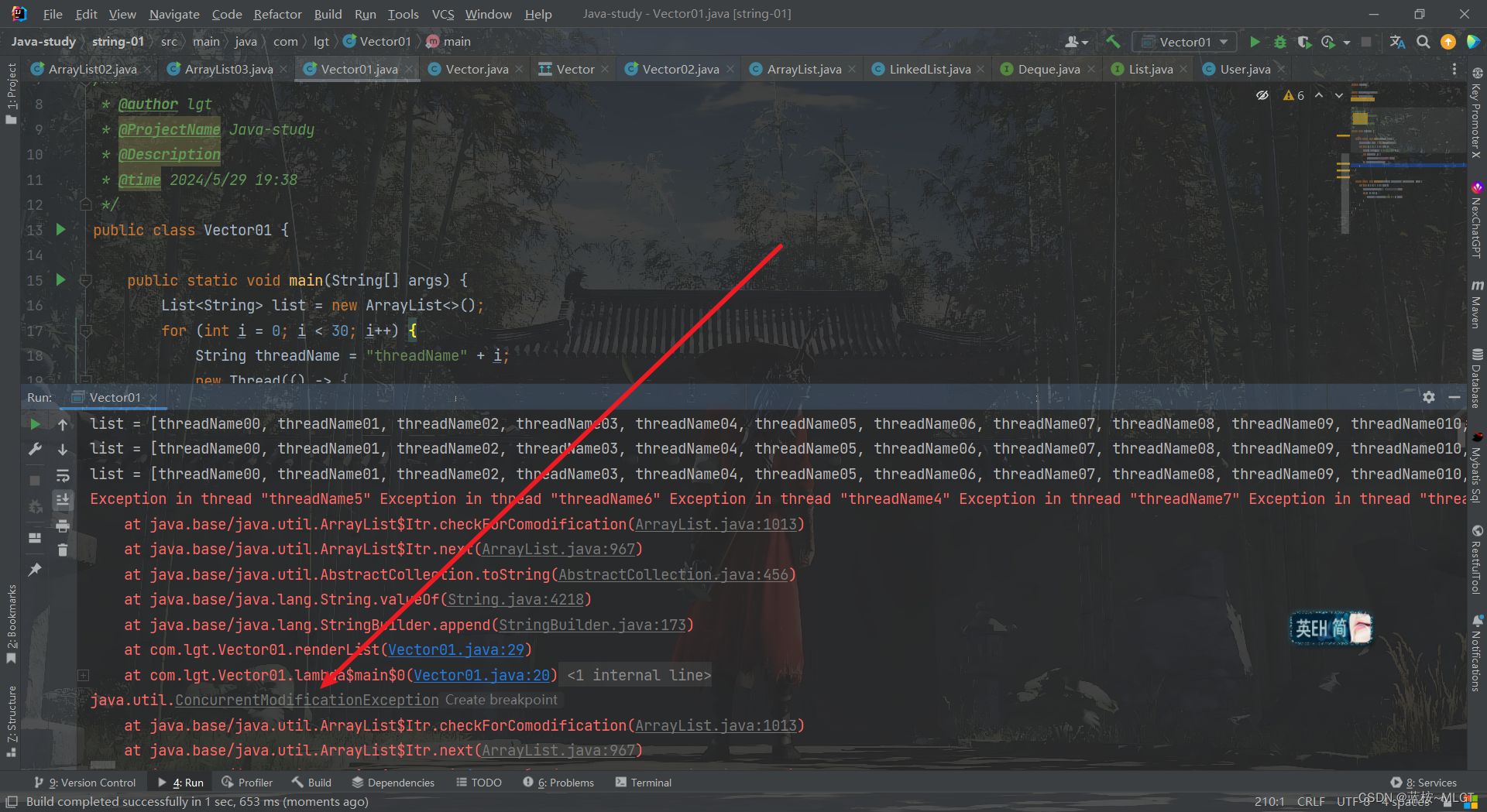
上面的代码和运行结果说明ArrayList确实不是线程安全的,这种例子呢网上也有很多,不过我要说的是这种写法在实际开发中很少出现,上面的例子无非就是模拟了一下多个线程调用同一个方法,而不同线程操作的都是1个List集合,所以肯定会出现报错,但是在实际开发中我们会这么用吗?
答案是肯定不会这么用的,每次肯定都会new一个List,所以线程不安全的问题也很少出现,开发中我们大多数都是对数据库进行锁的机制。这里为了搞懂这个概念和Vector为啥是线程安全的,所以这么举例子,大家也不要太纠结为什么这么写,毕竟我也确实纠结了好几天。
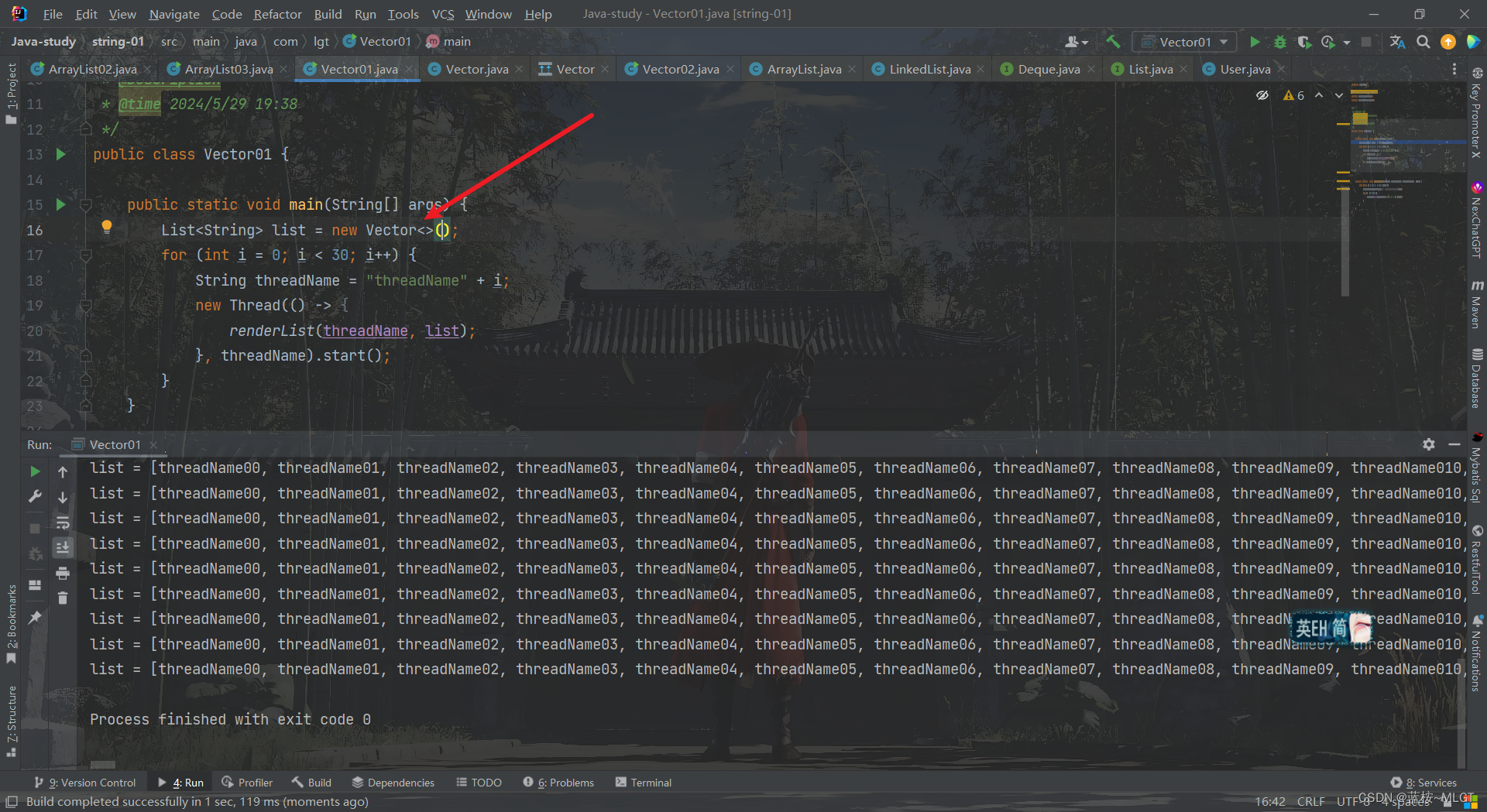
我们将ArrayList换为了Vector,程序就可以正常运行了,为什么呢?因为Vector在底层是用了synchronized关键字,也就是加锁机制,所以也不会出现报错。
3 Collections工具类:synchronizedList()实现线程安全
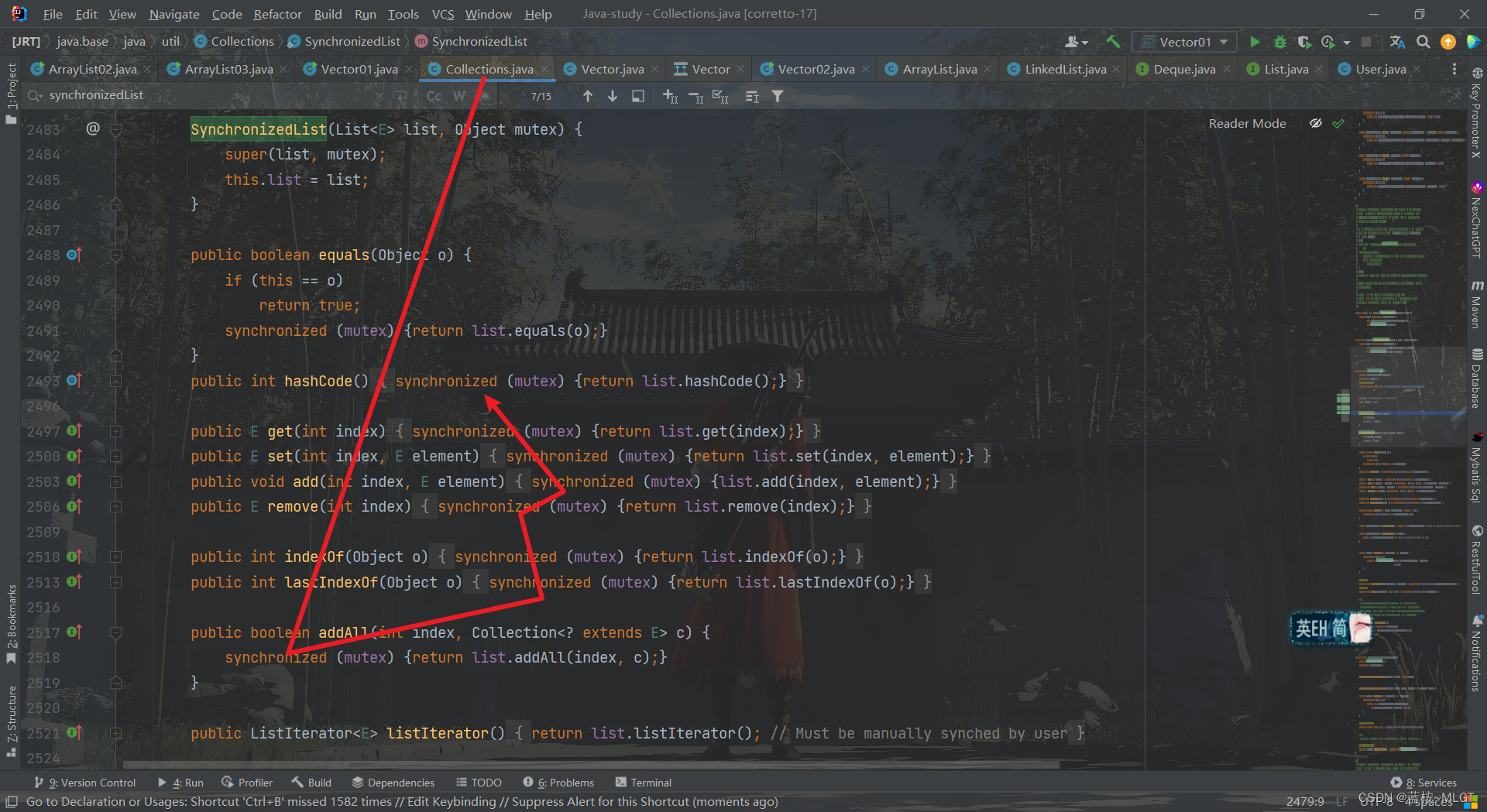
其实除了Vector外Collections中也提供了一个方法能实现线程安全,那么使用的话也很简单。
List<String> list = Collections.synchronizedList(new ArrayList<>());
同时也对Map、Set等都有类似的方法。
4 Vector存在的问题
有一点要注意,Vector的锁只是会限制同一种操作不会出现问题,也就是如果你的多个线程都只是新增操作那没啥事儿,如果不同线程中会出现一会儿添加一个,一会儿删除一个,那保不齐也会出问题,可能不报错,但数据最终不是你期望的结果。而且速度很慢。
速度慢在进行复杂操作时不能保证数据的一致性
为了解决Vector都不能解决的问题,就出现了一个新的类,既能加快速度,又能完全保证数据的一致性。
5 CopyOnWriteArrayList 写时复制策略
参考:集合中线程安全和不安全
List<String> list = new CopyOnWriteArrayList<>();
写时复制:我们要向一个文件中添加新数据时,先将原来文件拷贝一份,然后在这个拷贝文件上进行添加;而此时如果有别人读取数据,还是从原文件读取;添加数据完成后,再用这个拷贝文件替换掉原来的文件。这样做的好处是,读写分离,写的是拷贝文件,读的是原文件,可以支持多线程并发读取,而不需要加锁。
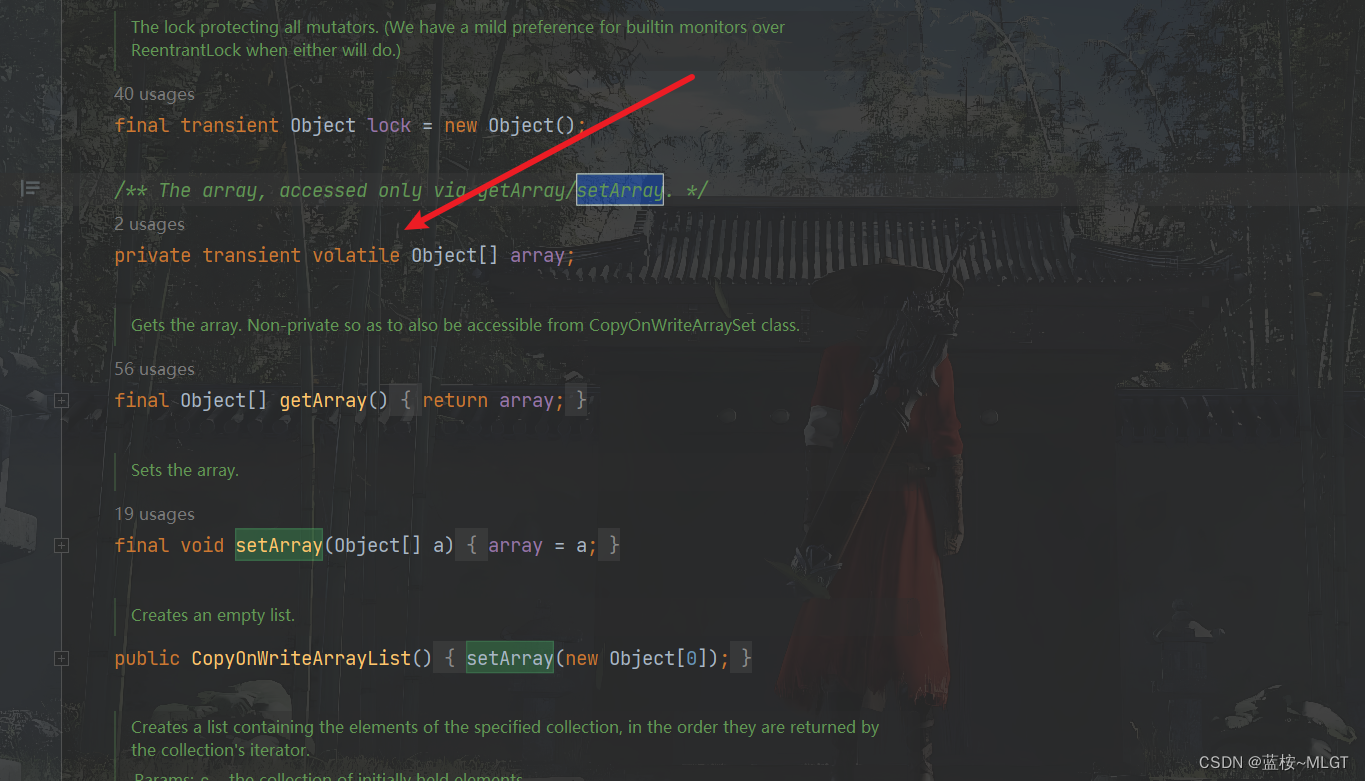
volatile关键字可以保证数据的可见性。
写时复制是一个解决并发很好的策略,有的人可能会疑惑,复制一份数据操作不是也比较慢吗?也不无道理,肯定有一定的影响,但是相对于加锁是很快了,当线程过多时,排队势必是最慢的,虽然我们这里复制了很多份数据,但是并发呀,同时操作呀,速度上肯定有优势。
但是,又有一个但是,这种方案也要慎用,如果你的线程并发太大,而且操作的数据比较大的时候(比如集合中动不动就几千几万条),这个操作有可能影响系统的整体性能,毕竟复制的数据不在少数,弄不好系统崩了也不是不可能,但加锁倒是不会,就是这一个功能会受到影响,具体怎么选择还是要根据实际情况来看。当然,如果你的系统内存足够大,而且有分流和集群的策略,那问题不大,并发也不会有太大影响。
总结
本文是对集合中List家族进行了整体的讲解,重点还是基于源码的分析和一些重要优化策略,在使用方面没有过多提及,后续会专门说一下常用的使用方法,本文参考了众多博客,同时也有自己的看法,经过了大量的佐证,如果有哪里不对的地方,大家可以在评论区提及。
下期预告
下一篇文章将围绕Arrays工具类说明,期待下次见面。
相关文章:
java高级——Collection集合之List探索(包含ArrayList、LinkedList、Vector底层实现及区别,非常详细哦)
java高级——Collection集合之List探索 前情提要文章介绍提前了解的知识点1. 数组2. 单向链表3. 双向链表4. 为什么单向链表使用的较多5. 线程安全和线程不安全的概念 ArrayList介绍1. 继承结构解析1.1 三个标志性接口1.2 AbstractList和AbstractCollection 2. ArrayList底层代…...

JAVA-->方法的使用详解
JAVA–>方法的使用详解 1.方法的概念及使用 1.1 什么是方法 : 方法就是一个代码片段. 类似于 C 语言中的 “函数”。 1.2 方法定义 / 方法定义 修饰符 返回值类型 方法名称([参数类型 形参 ...]){方法体代码;[return 返回值]; }判断是否为闰年 public class Method{ //…...
基于 vLLM 搭建 DeepSeek-V2 Chat 服务
直奔主题。 安装vLLM 官方实现的代码还没有 merge 到 vLLM 主分支,所以直接 git clone DeepSeek 的分支。 git clone https://github.com/zwd003/vllm.git cd vllm pip install -e .源码安装大概耗时 10 分钟。 OpenAI 接口规范启动 官方 Github 放的是单条推理…...

Kafka 安装教程和基本操作
一、简介 Kafka 是最初由 Linkedin 公司开发,是一个分布式、分区的、多副本的、多订阅者,基于 zookeeper 协调的分布式日志系统(也可以当做 MQ 系统),常见可以用于 web/nginx 日志、访问日志,消息服务等等…...

Java 五种内部类演示及底层原理详解
内部类 什么是内部类 在A类的内部定义B类,B类就被称为内部类 发动机类单独存在没有意义 发动机为独立个体 可以在外部其他类里创建内部类的对象去调用方法 类的五大成员 属性 方法 构造方法 代码块 内部类 内部类的访问特点 内部类可以直接访问外部类的成员&a…...

【UnityShader入门精要学习笔记】第十五章 使用噪声
本系列为作者学习UnityShader入门精要而作的笔记,内容将包括: 书本中句子照抄 个人批注项目源码一堆新手会犯的错误潜在的太监断更,有始无终 我的GitHub仓库 总之适用于同样开始学习Shader的同学们进行有取舍的参考。 文章目录 使用噪声上…...

C++ ─── string的完整模拟实现
本博客实现了string的常见接口实现 下面是用到的一些函数,供大家回顾复习 string.h #define _CRT_SECURE_NO_WARNINGS 1 #pragma once #include<iostream> #include<assert.h> using namespace std;namespace bit {class string{public:typedef char*…...

安卓中的图片压缩
安卓中如何进行图片压缩? 在安卓中进行图片压缩通常有以下几种方法: 质量压缩: 通过降低图片的质量来减小文件大小。这可以通过Bitmap的compress()方法实现,其中可以设置压缩质量(0-100)。 ByteArrayOutputStream baos…...

centOS7.9 DNS配置
1.DNS规划 dns.sohu.com192.168.110.111Awww.sohucom192.168.110.112Aoa.sohu.com 192.168.110.113A 2.安装 bind yum install -y bind bind-utils 3. 编辑主配置文件 vim /etc/named.conflisten- on port 53 { any; }; allow- query { any; }; 4.配置区域文件 …...

设计模式20——职责链模式
写文章的初心主要是用来帮助自己快速的回忆这个模式该怎么用,主要是下面的UML图可以起到大作用,在你学习过一遍以后可能会遗忘,忘记了不要紧,只要看一眼UML图就能想起来了。同时也请大家多多指教。 职责链模式(Chain …...

android13 差分包制作命令
./out/host/linux-x86/bin/ota_from_target_files -v -iCode/SourceCode/android13/ntls/userdebug/hpg2_24-target_files-38.zip --block -p ./out/host/linux-x86 Code/SourceCode/android13/ntls/userdebug/hpg2_24-target_files-39.zip update_ud.zip 脚本命令行参数 命令…...

Flink-cdc更好的流式数据集成工具
What’s Flink-cdc? Flink CDC 是基于Apache Flink的一种数据变更捕获技术,用于从数据源(如数据库)中捕获和处理数据的变更事件。CDC技术允许实时地捕获数据库中的增、删、改操作,将这些变更事件转化为流式数据,并能够…...
|抽象工厂模式)
C++|设计模式(三)|抽象工厂模式
抽象工厂模式仍然属于创建型模式,我们在【简单工厂和工厂方法模式】这篇文章中,描述了简单工厂和工厂方法模式,并在文末,简单介绍了工厂方法模式的局限性。 本文将通过汽车工厂的例子继续来阐述使用抽象工厂模式相比较于工厂方法…...

AVB协议分析(一) FQTSS协议介绍
FQTSS协议介绍 一、AVB整体架构二、概述三、协议作用及作用对象四、协议的实现五、参考文献: 一、AVB整体架构 可见FQTSS位于MAC层的上面,代码看不懂,咱们就从最底层开始,逐层分析协议,逐个击破,慢就是快。…...
询问)
一个程序员的牢狱生涯(44)询问
星期一 询 问 在号子里开始了下午坐班的时候,过道内的大铁栅栏被管教打开,我听到开锁的声音后,心里变得激动起来。盼望着脚步声能停在我们的号子门口,然后打开铁门,喊一声“眼镜,出来!”。 通道内这次进来的是秦所,但他并没有在我们号子门口停留,只是在走过的时候,低…...
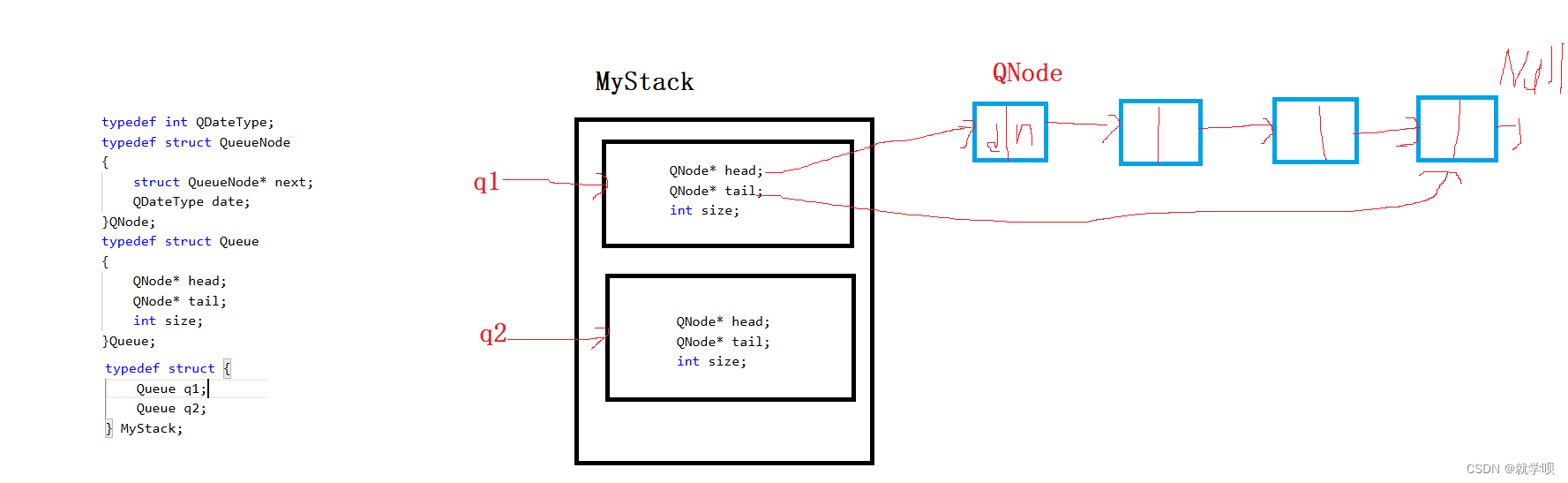
刷爆leetcode第六期
题目一 用队列实现栈 请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。 实现 MyStack 类: void push(int x) 将元素 x 压入栈顶。 int pop() 移除…...

汇舟问卷:国外问卷调一天900
大家好,我是汇舟问卷,专注于国外问卷调查互联网项目。夏天已经来临,您是否在三伏天顶着大太阳上班,汗水浸湿了衣襟,却依然要面对繁琐的工作和无尽的压力? 在这个炎热的季节里,我们都渴望找到一…...

openresty完美替代nginx
OpenResty相较于Nginx,其优势主要体现在以下几个方面: 1、Lua脚本支持:OpenResty内置了LuaJIT(Lua的即时编译器),使得用户可以直接在Nginx配置文件中使用Lua脚本,这样可以实现更复杂的业务逻辑…...

深入解析:Element Plus 与 Vite、Nuxt、Laravel 的结合使用
在现代前端开发中,选择合适的工具和框架来提高开发效率和应用性能是至关重要的。 Element-Plus 是一个基于 Vue.js 3.0 的流行 UI组件库,它可以与多种前端和后端框架结合使用,如 Vite、Nuxt 和 Laravel。本文将深入探讨这三者与 Element Plus…...

使ssh连接Linux服务器一直不掉线
怎么可以使ssh连接Linux服务器一直不掉线 解决方法: vim /etc/profile在/etc/profile中的TMOUT改为0 export TMOUT0最后 source /etc/profile就可以了...

Swagger2Word终极指南:3种方法实现API文档自动化转换
Swagger2Word终极指南:3种方法实现API文档自动化转换 【免费下载链接】swagger2word 项目地址: https://gitcode.com/gh_mirrors/swa/swagger2word 还在为手动编写API文档而烦恼吗?Swagger2Word为你提供了一站式自动化解决方案,将Swa…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...

百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案
百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字资源共享日益频繁的今天ÿ…...

如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南
如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾在寻找百度网盘资源时,被一个小小的提取码卡住,不得不花费…...

基于Docker构建标准化开发环境:原理、实践与VSCode集成指南
1. 项目概述:一个面向开发者的“开箱即用”环境在软件开发这条路上,我踩过最多的坑,往往不是来自复杂的业务逻辑,而是来自那句“在我机器上好好的”。环境配置,这个看似基础却又无比磨人的环节,消耗了无数开…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...

KMS智能激活终极指南:如何一键永久激活Windows和Office
KMS智能激活终极指南:如何一键永久激活Windows和Office 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次重装系统后都要重新激活Office&…...

嵌入式事件驱动框架Curtroller:模块化设计提升开发效率
1. 项目概述与核心价值最近在嵌入式开发社区里,一个名为“Curtroller”的项目引起了我的注意。这个项目由开发者KenWuqianghao在GitHub上开源,名字本身就是一个巧妙的组合——“Curt”(可能是“Current”电流的缩写或“Control”控制的变体&a…...

轻量级协作平台设计:集成Git与敏捷开发的项目管理实践
1. 项目概述与核心价值最近在团队协作和项目管理工具选型上,又和几个技术负责人聊了一圈。大家普遍的感受是,市面上的工具要么太重,像Jira、Confluence,配置复杂,学习成本高,小团队用起来像“杀鸡用牛刀”&…...

Camera Graph™相机拓扑图谱引擎技术白皮书
前言在数字孪生、全域感知、智能安防等领域快速发展的今天,多镜头协同感知已成为实现全域覆盖、精准识别、连续追踪的核心基础。然而,传统多相机部署模式下,各镜头始终处于“孤立工作”状态,数据互通存在壁垒、时空对齐精度不足、…...