基于Pytorch框架的深度学习EfficientNetV2神经网络中草药识别分类系统源码
第一步:准备数据
5种中草药数据:self.class_indict = ["百合", "党参", "山魈", "枸杞", "槐花", "金银花"]
,总共有900张图片,每个文件夹单独放一种数据

第二步:搭建模型
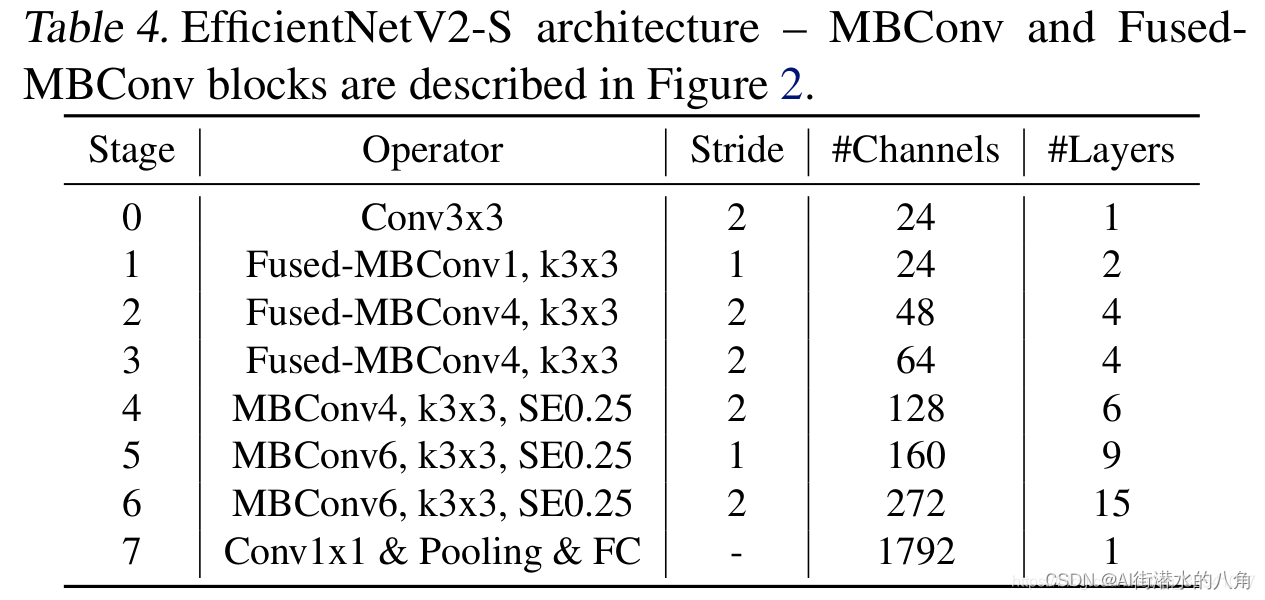
本文选择一个EfficientNetV2网络,其原理介绍如下:
该网络主要使用训练感知神经结构搜索和缩放的组合;在EfficientNetV1的基础上,引入了Fused-MBConv到搜索空间中;引入渐进式学习策略、自适应正则强度调整机制使得训练更快;进一步关注模型的推理速度与训练速度
与EfficientV1相比,主要有以下不同:
- V2中除了使用MBConv模块外,还使用了Fused-MBConv模块
- V2中会使用较小的expansion ratio,在V1中基本都是6。这样的好处是能够减少内存访问开销
- V2中更偏向使用更小的kernel_size(3 x 3),在V1中很多5 x 5。优于3 x 3的感受野是比5 x 5小的,所以需要堆叠更多的层结构以增加感受野
- 移除了V1中最优一个步距为1的stage
第三步:训练代码
1)损失函数为:交叉熵损失函数
2)训练代码:
import os
import math
import argparseimport torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import torch.optim.lr_scheduler as lr_schedulerfrom model import efficientnetv2_s as create_model
from my_dataset import MyDataSet
from utils import read_split_data, train_one_epoch, evaluatedef main(args):device = torch.device(args.device if torch.cuda.is_available() else "cpu")print(args)print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')tb_writer = SummaryWriter()if os.path.exists("./weights") is False:os.makedirs("./weights")train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)img_size = {"s": [300, 384], # train_size, val_size"m": [384, 480],"l": [384, 480]}num_model = "s"data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(img_size[num_model][0]),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]),"val": transforms.Compose([transforms.Resize(img_size[num_model][1]),transforms.CenterCrop(img_size[num_model][1]),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])}# 实例化训练数据集train_dataset = MyDataSet(images_path=train_images_path,images_class=train_images_label,transform=data_transform["train"])# 实例化验证数据集val_dataset = MyDataSet(images_path=val_images_path,images_class=val_images_label,transform=data_transform["val"])batch_size = args.batch_sizenw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,pin_memory=True,num_workers=nw,collate_fn=train_dataset.collate_fn)val_loader = torch.utils.data.DataLoader(val_dataset,batch_size=batch_size,shuffle=False,pin_memory=True,num_workers=nw,collate_fn=val_dataset.collate_fn)# 如果存在预训练权重则载入model = create_model(num_classes=args.num_classes).to(device)if args.weights != "":if os.path.exists(args.weights):weights_dict = torch.load(args.weights, map_location=device)load_weights_dict = {k: v for k, v in weights_dict.items()if model.state_dict()[k].numel() == v.numel()}print(model.load_state_dict(load_weights_dict, strict=False))else:raise FileNotFoundError("not found weights file: {}".format(args.weights))# 是否冻结权重if args.freeze_layers:for name, para in model.named_parameters():# 除head外,其他权重全部冻结if "head" not in name:para.requires_grad_(False)else:print("training {}".format(name))pg = [p for p in model.parameters() if p.requires_grad]optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=1E-4)# Scheduler https://arxiv.org/pdf/1812.01187.pdflf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosinescheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)for epoch in range(args.epochs):# traintrain_loss, train_acc = train_one_epoch(model=model,optimizer=optimizer,data_loader=train_loader,device=device,epoch=epoch)scheduler.step()# validateval_loss, val_acc = evaluate(model=model,data_loader=val_loader,device=device,epoch=epoch)tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]tb_writer.add_scalar(tags[0], train_loss, epoch)tb_writer.add_scalar(tags[1], train_acc, epoch)tb_writer.add_scalar(tags[2], val_loss, epoch)tb_writer.add_scalar(tags[3], val_acc, epoch)tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--num_classes', type=int, default=5)parser.add_argument('--epochs', type=int, default=100)parser.add_argument('--batch-size', type=int, default=4)parser.add_argument('--lr', type=float, default=0.01)parser.add_argument('--lrf', type=float, default=0.01)# 数据集所在根目录# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgzparser.add_argument('--data-path', type=str,default=r"G:\demo\data\ChineseMedicine")# download model weights# 链接: https://pan.baidu.com/s/1uZX36rvrfEss-JGj4yfzbQ 密码: 5gu1parser.add_argument('--weights', type=str, default='./pre_efficientnetv2-s.pth',help='initial weights path')parser.add_argument('--freeze-layers', type=bool, default=True)parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')opt = parser.parse_args()main(opt)
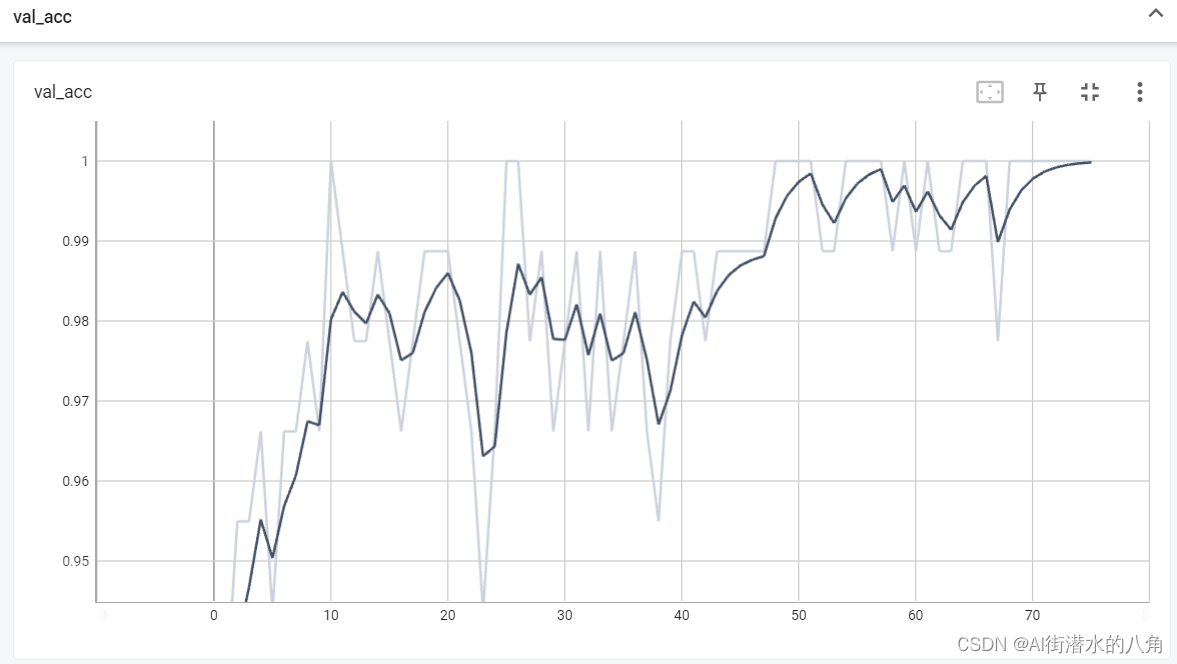
第四步:统计正确率
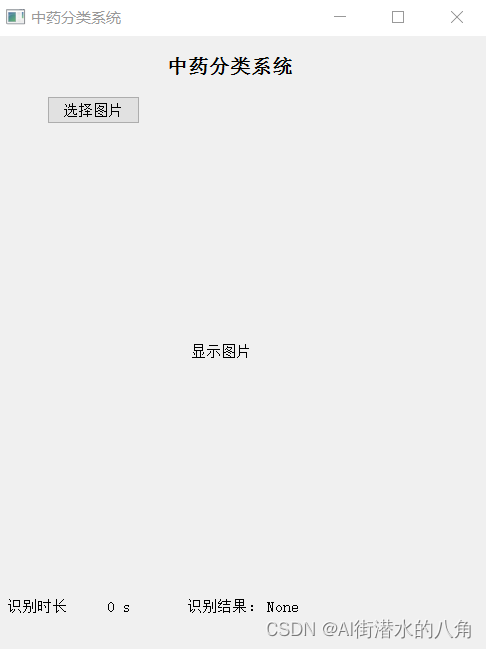
第五步:搭建GUI界面

第六步:整个工程的内容
有训练代码和训练好的模型以及训练过程,提供数据,提供GUI界面代码
代码的下载路径(新窗口打开链接):基于Pytorch框架的深度学习EfficientNetV2神经网络中草药识别分类系统源码

有问题可以私信或者留言,有问必答
相关文章:
基于Pytorch框架的深度学习EfficientNetV2神经网络中草药识别分类系统源码
第一步:准备数据 5种中草药数据:self.class_indict ["百合", "党参", "山魈", "枸杞", "槐花", "金银花"] ,总共有900张图片,每个文件夹单独放一种数据 第二步&a…...
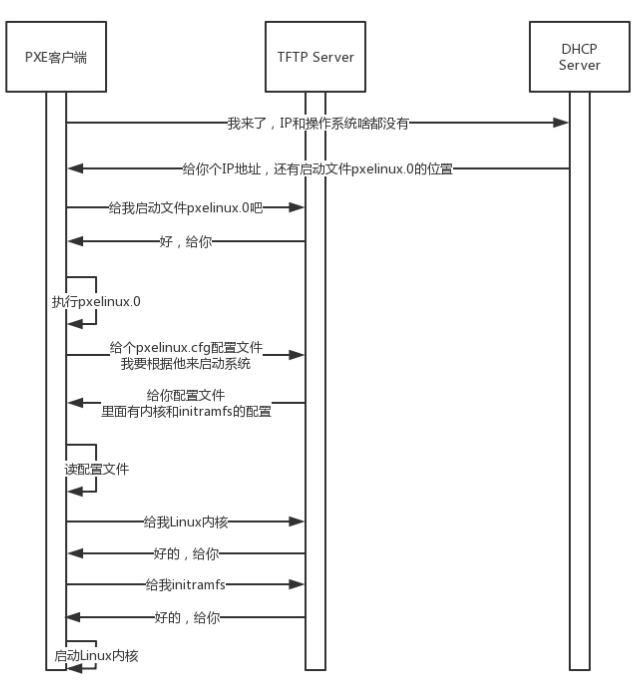
网络协议。
一、流程案例 接下来揭秘我要说的大事情,“双十一”。这和我们要讲的网络协议有什么关系呢? 在经济学领域,有个伦纳德里德(Leonard E. Read)创作的《铅笔的故事》。这个故事通过一个铅笔的诞生过程,来讲述…...

Excel单元格格式无法修改的原因与解决方法
Excel单元格格式无法更改可能由多种原因造成。以下是一些可能的原因及相应的解决方法: 单元格或工作表被保护: 如果单元格或工作表被设置为只读或保护状态,您将无法更改其中的格式。解决方法:取消单元格或工作表的保护。在Excel中…...

CasaOS玩客云安装全平台高速下载器Gopeed并实现远程访问
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

JAVA学习-练习试用Java实现“最长回文子串”
问题: 给定一个字符串 s,找到 s 中最长的回文子串。 示例 1: 输入:s "babad" 输出:"bab" 解释:"aba" 同样是符合题意的答案。 示例 2: 输入:s …...
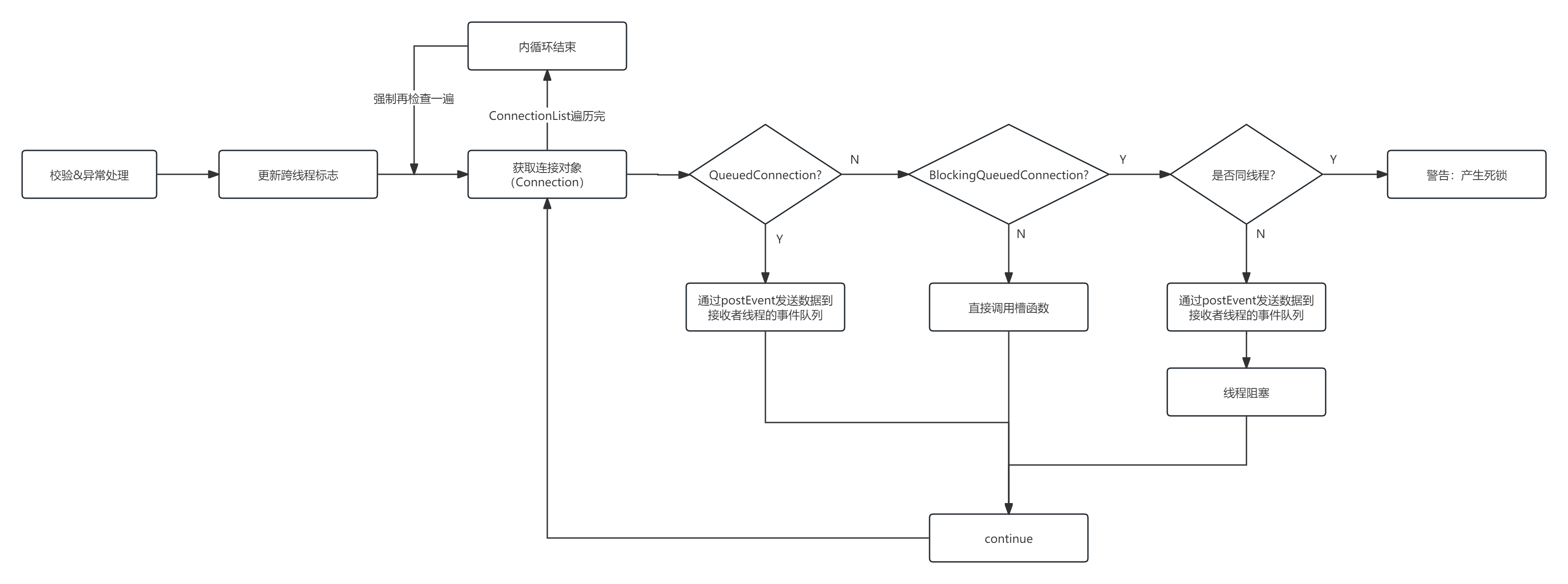
深入探索Qt框架系列之信号槽原理(三)
前面两篇分别介绍了QObject::connect和QMetaObject::Connection,那么信号槽机制的基础已经介绍完了,本文将介绍信号槽机制是如何从信号到槽的,以及多线程下是如何工作的。 信号槽机制源码解析 1. 信号的触发 以该系列的第一篇文章中的示例举…...
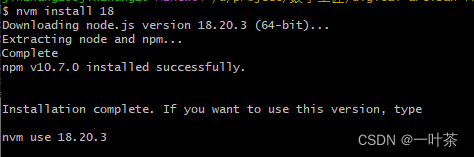
npm镜像源管理、nvm安装多版本node异常处理
查看当前使用的镜像源 npm config get registry --locationglobal 设置使用官方源 npm config set registry https://registry.npmjs.org/ --locationglobal 设置淘宝镜像源 npm config set registry https://registry.npm.taobao.org/ --locationglobal 需要更改淘宝镜像源地址…...
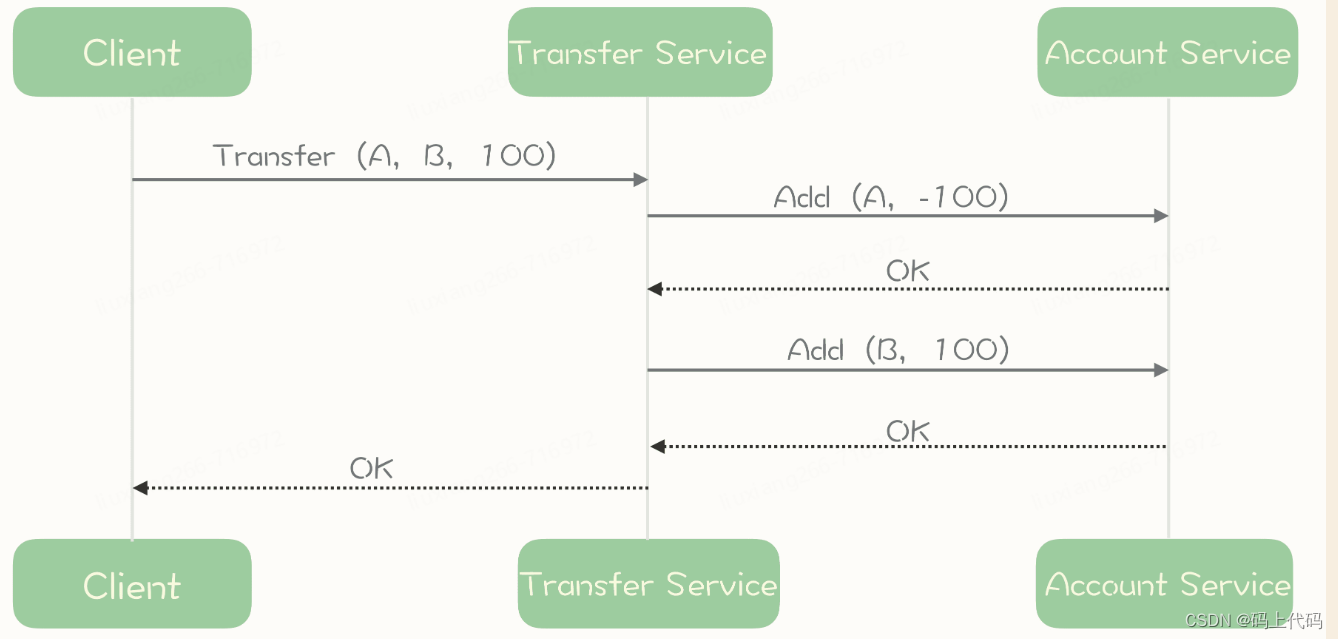
异步编程的魔力:如何显著提升系统性能
异步编程的魔力:如何显著提升系统性能 今天我们来聊聊一个对开发者非常重要的话题——异步编程。异步编程是提升系统性能的一种强大手段,尤其在需要高吞吐量和低时延的场景中,异步设计能够显著减少线程等待时间,从而提升整体性能。 异步设计如何提升系统性能? 我们通过…...
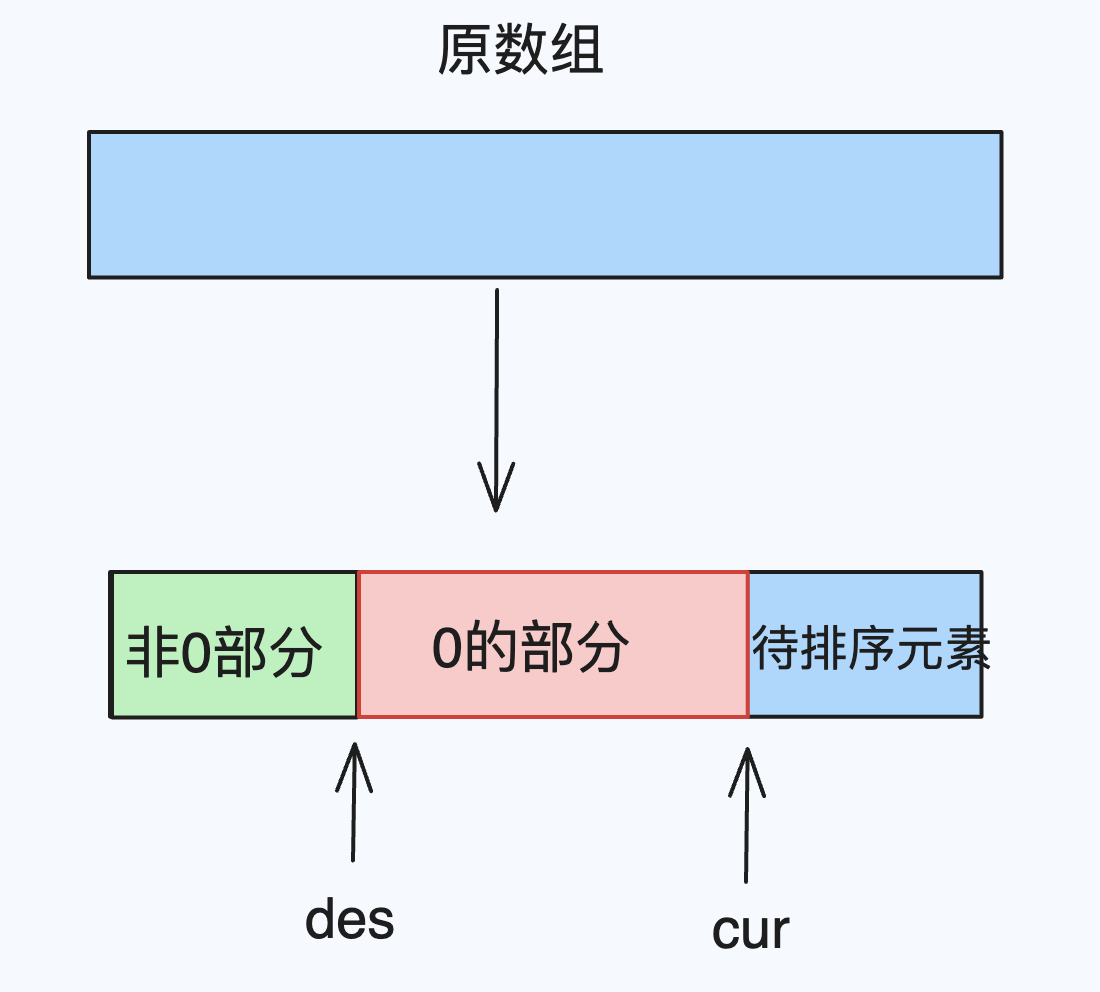
优选算法一:双指针算法与练习(移动0)
目录 双指针算法讲解 移动零 双指针算法讲解 常见的双指针有两种形式,一种是对撞指针,一种是快慢指针。 对撞指针:一般用于顺序结构中,也称左右指针。 对撞指针从两端向中间移动。一个指针从最左端开始,另一个从最…...

数据结构第二篇【关于java线性表(顺序表)的基本操作】
【关于java线性表(顺序表)的基本操作】 线性表是什么?🐵🐒🦍顺序表的定义🦧🐶🐵创建顺序表新增元素,默认在数组最后新增在 pos 位置新增元素判定是否包含某个元素查找某个…...

人工智能和大模型的区别
人工智能(AI)和大模型是两个相关但有区别的概念。理解它们之间的区别有助于更好地掌握现代科技的发展动态。 人工智能(AI) 人工智能(Artificial Intelligence, AI)是一个广义的概念,指的是通过…...

k8s处于pending状态的原因有哪些
k8s处于pending状态的原因 资源不足:集群中的资源(如CPU、内存)不足以满足Pod所需的资源请求,导致Pod无法调度。 调度器问题:调度器无法为Pod找到合适的节点进行调度,可能是由于节点资源不足或调度策略配置…...
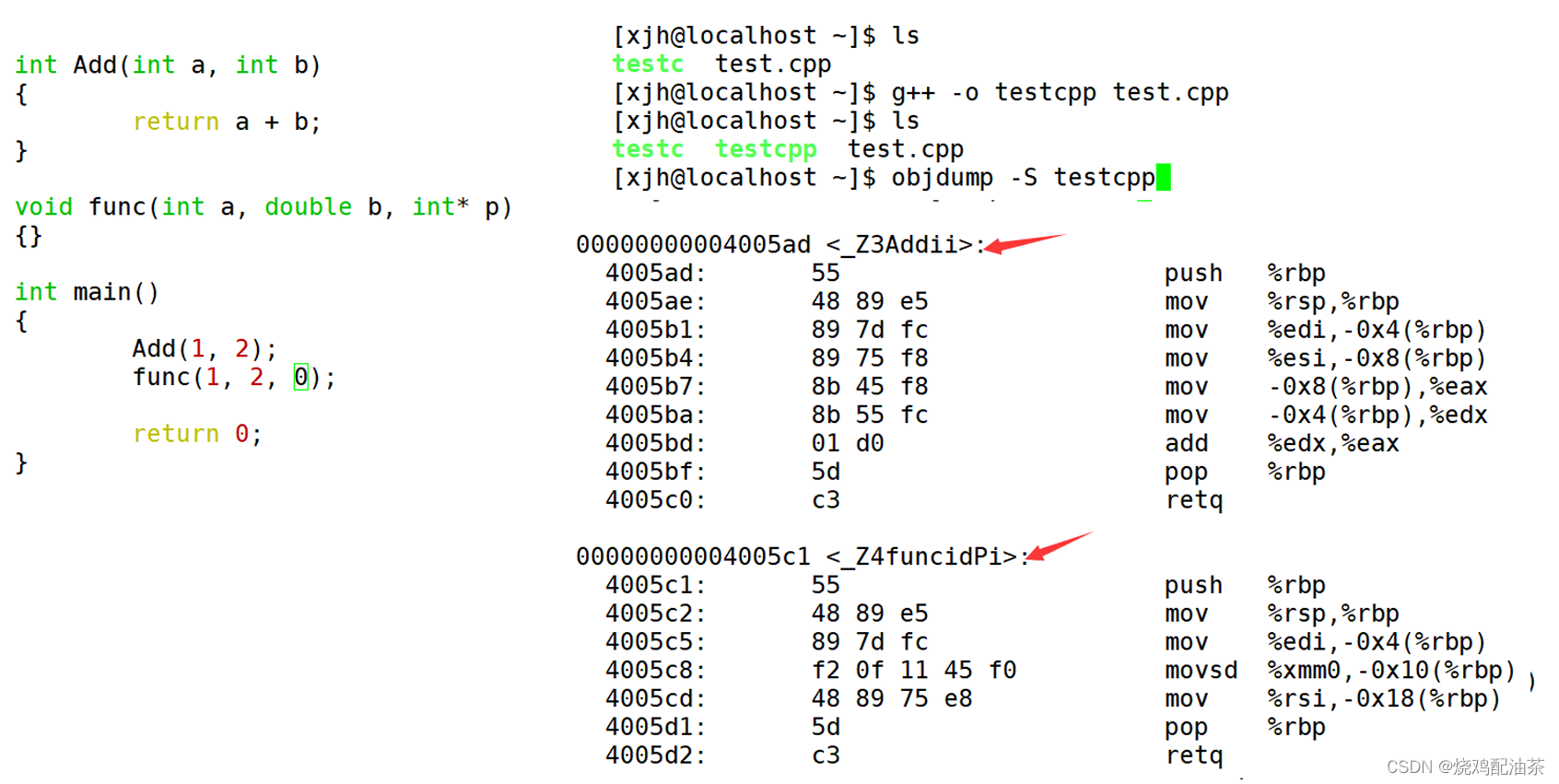
【C++】入门(一):命名空间、缺省参数、函数重载
目录 一、关键字 二、命名空间 问题引入(问题代码): 域的问题 1.::域作用限定符 的 用法: 2.域的分类 3.编译器的搜索原则 命名空间的定义 命名空间的使用 举个🌰栗子: 1.作用域限定符指定命名空间名称 2. using 引入…...

深入分析 Android Activity (四)
文章目录 深入分析 Android Activity (四)1. Activity 的生命周期详解1.1 onCreate1.2 onStart1.3 onResume1.4 onPause1.5 onStop1.6 onDestroy1.7 onRestart 2. Activity 状态的保存与恢复2.1 保存状态2.2 恢复状态 3. Activity 的启动优化3.1 延迟初始化3.2 使用 ViewStub3.…...
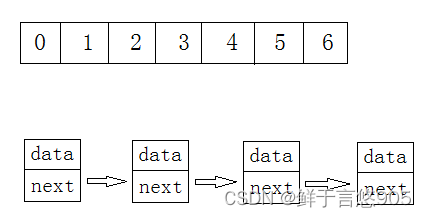
Java实现顺序表
Java顺序表 前言一、线性表介绍常见线性表总结图解 二、顺序表概念顺序表的分类顺序表的实现throw具体代码 三、顺序表会出现的问题 前言 推荐一个网站给想要了解或者学习人工智能知识的读者,这个网站里内容讲解通俗易懂且风趣幽默,对我帮助很大。我想与…...

刷题笔记1:如何科学的限制数字溢出问题
LCR 192. 把字符串转换成整数 (atoi) - 力扣(LeetCode) 我们以力扣的此题目为例,简述在诸如大数运算等问题中如何限制数字溢出问题。 先来直接看看自己的处理方式: class Solution { public:int myAtoi(string str) {int pcur0;…...

社区供稿丨GPT-4o 对实时互动与 RTC 的影响
以下文章来源于共识粉碎机 ,作者AI芋圆子 前面的话: GPT-4o 发布当周,我们的社区伙伴「共识粉碎机」就主办了一场主题为「GPT-4o 对实时互动与 RTC 的影响」讨论会。涉及的话题包括: GPT-4o 如何降低延迟(VAD 模块可…...
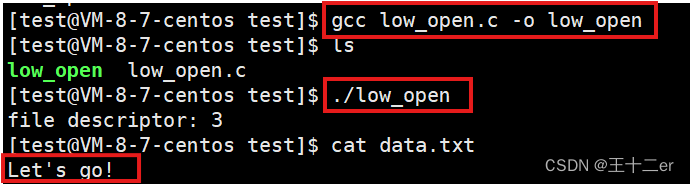
基于Linux的文件操作(socket操作)
基于Linux的文件操作(socket操作) 1. 文件描述符基本概念文件描述符的定义:标准文件描述符:文件描述符的分配: 2. 文件描述符操作打开文件读取文件中的数据 在linux中,socket也被认为是文件的一种ÿ…...
)
C++面试题记录(网络)
TCP与UDP区别 1. TCP面向连接,UDP无连接,所以UDP数据传输效率更高 2.UDP可以支持一对一、一对多、多对一、多对多通信,TCP只能一对一 3. TCP需要在端系统维护连接状态,包括缓存,序号,确认号,…...

YoloV8改进策略:卷积篇|基于PConv的二次创新|附结构图|性能和精度得到大幅度提高(独家原创)
摘要 在PConv的基础上做了二次创新,创新后的模型不仅在精度和速度上有了质的提升,还可以支持Stride为2的降采样。 改进方法简单高效,需要发论文的同学不要错过! 论文指导 PConv在论文中的描述 论文: 下面我们展示了可以通过利用特征图的冗余来进一步优化成本。如图3所…...
嵌入式LED色彩校正:Gamma原理与Arduino NeoPixel实战
1. 项目概述:为什么你的NeoPixel灯带颜色总是不对劲?如果你玩过像NeoPixel、WS2812B这类可编程LED灯带,并且尝试过自己调色,大概率遇到过这样的困惑:你在代码里设定了一个“橙色”——比如红色满值255,绿色…...

基于STM32单片机人体健康检测血糖检测监测无线蓝牙APP设计S312
本系统由STM32F103C8T6单片机核心板、OLED屏、无线模块、血糖模拟检测、蜂鸣器报警、电源电路、按键电路组成。【1】液晶显示:OLED液晶显示心率值、心率上下限、血氧值、血氧阈值、血压值、血压阈值、血糖值、血糖上下限值以及心率血氧是否在采集测算中、当前数据是…...

2026年实测推荐:10款思维导图工具,开发者效率翻倍
作为技术博主,我常年用思维导图拆解需求、梳理架构、记录学习笔记。2026年,工具们卷出了新高度:AI辅助、白板一体化、实时协作成了标配。本文从开发者视角出发,实测了10款热门工具,帮你选出最适合的那把“瑞士军刀”。…...

从MHC到MCC:PIC32项目迁移实战指南与问题排查
1. 项目概述:从MHC到MCC的迁移之路如果你是一位长期使用Microchip PIC32系列微控制器的嵌入式开发者,那么“MPLAB Harmony配置器(MHC)”这个名字你一定不陌生。它曾经是Harmony框架下图形化配置工具的核心,帮助我们快速…...

使用curl命令快速测试Taotoken大模型接口连通性与功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令快速测试Taotoken大模型接口连通性与功能 在接入大模型服务时,直接使用HTTP请求进行测试是一种高效且通用…...

AI编程助手Composer插件:无缝管理PHP依赖,提升结对编程效率
1. 项目概述:一个为AI编程助手量身定制的Composer工具如果你和我一样,日常重度依赖像Aider这样的AI编程助手来提升开发效率,那你一定遇到过这样的场景:你正和AI助手热火朝天地讨论一个功能实现,它为你生成了一段完美的…...

ant-design 1.x版本表格头部拖拽、可拖拽列实现
表格列宽拖拽调整 — 问题总结 版本 “vue”: “2.6.11”,“vue-draggable-resizable”: “^2.3.0”,"ant-design “:”1.7.0“ 问题 1:thDom 为 null 导致 getBoundingClientRect 报错 现象: TypeError: Cannot read properties of nul…...

观察Taotoken用量看板如何帮助团队控制API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken用量看板如何帮助团队控制API成本 作为团队的技术负责人,引入大模型API后,成本的可观测性与可…...

Bifrost三星固件下载器:跨平台技术实现深度解析
Bifrost三星固件下载器:跨平台技术实现深度解析 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 三星设备固件下载与解密过程历来存在技术门槛&#x…...

Proteus仿真PCA9685踩坑实录:示波器不显示PWM波?可能是I2C调试器惹的祸
Proteus仿真PCA9685实战避坑指南:从波形消失到高效调试 当你在Proteus中搭建好PCA9685电路,满心期待看到整齐的PWM波形时,示波器却一片空白——这种挫败感每个电子工程师都经历过。本文将带你深入Proteus仿真的底层逻辑,揭示I2C调…...