RT-DETR:端到端的实时Transformer检测模型(目标检测+跟踪)
博主一直一来做的都是基于Transformer的目标检测领域,相较于基于卷积的目标检测方法,如YOLO等,其检测速度一直为人诟病。
终于,RT-DETR横空出世,在取得高精度的同时,检测速度也大幅提升。
那么RT-DETR是如何做到的呢?
在研究RT-DETR的改进前,我们先来了解下DETR类目标检测方法的发展历程吧
- 首先是
DETR,该方法作为Transformer在目标检测领域的开山之作,一经推出,便引发了极大的轰动,该方法巧妙的利用Transformer进行特征提取与解码,同时通过匈牙利匹配方法完成预测框与真实框的匹配,避免了NMS等后处理过程。 - 随后
DAB-DETR引入了动态锚框作为查询向量,从而对DETR中的100个查询向量进行了解释。 Deformable-DETR针对Transformer中自注意力计算复杂度高的问题,提出可变形注意力计算,即通过可学习的选取少量向量进行注意力计算,大幅的降低了计算量。- DN-DETR认为匈牙利匹配的二义性是导致
DETR训练收敛慢的原因,因此提出查询降噪机制,即利用先前DAB-DETR中将查询向量解释为锚框的原理,给查询向量添加一些噪声来辅助模型收敛,最终大幅提升了模型的训练速度。 - DINO则是在DAB-DETR与DN-DETR的基础上进行进一步的融合与改进。
H-DETR为使模型获取更多的正样本特征,从而提升检测精度,因此提出混合匹配方法,在训练阶段,包含原始的匈牙利匹配分支与一个一对多的辅助匹配分支,而在推理阶段,则只有一个匈牙利匹配分支。
然而,上述方法尽管已经大幅提升了检测精度,降低了计算复杂度,但其受Transformer本身高计算复杂度的制约,DETR类目标检测方法的实时性始终令人难以满意,尤其是相较于YOLO等单阶段目标检测方法,其检测速度的确差别巨大。
为了解决这个问题,百度提出了RT-DETR,该方法依旧是在DETR的基础上改进生成的,从论文中给出的实验结果来看,该方法无论在检测速度还是检测精度方法都已经超过了YOLOv8,实现了真正的实时性。

- 创新点1:高效混合编码器:RT-DETR使用了一种高效的混合编码器,通过解耦尺度内交互和跨尺度融合来处理多尺度特征。这种独特的基于视觉Transformer的设计降低了计算成本,并允许实时物体检测。
- 创新点2:IoU感知查询选择:RT-DETR通过利用IoU感知的查询选择改进了目标查询初始化。这使得模型能够聚焦于场景中最相关的目标,从而提高了检测精度。
- 创新点3:自适应推理速度:RT-DETR支持通过使用不同的解码器层来灵活调整推理速度,而无需重新训练。这种适应性便于在各种实时目标检测场景中的实际应用。
RT-DETR的代码有两个,一个是官方提供的代码,但该代码功能比较单一,只有训练与验证,另一个则是集成在YOLOv8中,该代码的设计就比较全面了
环境部署
conda create -n rtdetr python=3.8
conda activate rtdetr
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
cd RT-DETR-main/rtdetr_pytorch //这个路径根据你自己的改
pip install -r requirement.txt
该算法的环境为pytorch=2.0.1,注意,尽量要用pytorch2以上的版本,否则可能会报错:
AttributeError: module 'torchvision' has no attribute 'disable_beta_transforms_warning'
官方模型训练
参数配置
该算法的配置封装较好,我们只需要修改配置即可:train.py,指定要使用的骨干网络。
parser.add_argument('--config', '-c', default="/rtdetr_pytorch\configs/rtdetr/rtdetr_r18vd_6x_coco.yml",type=str, )
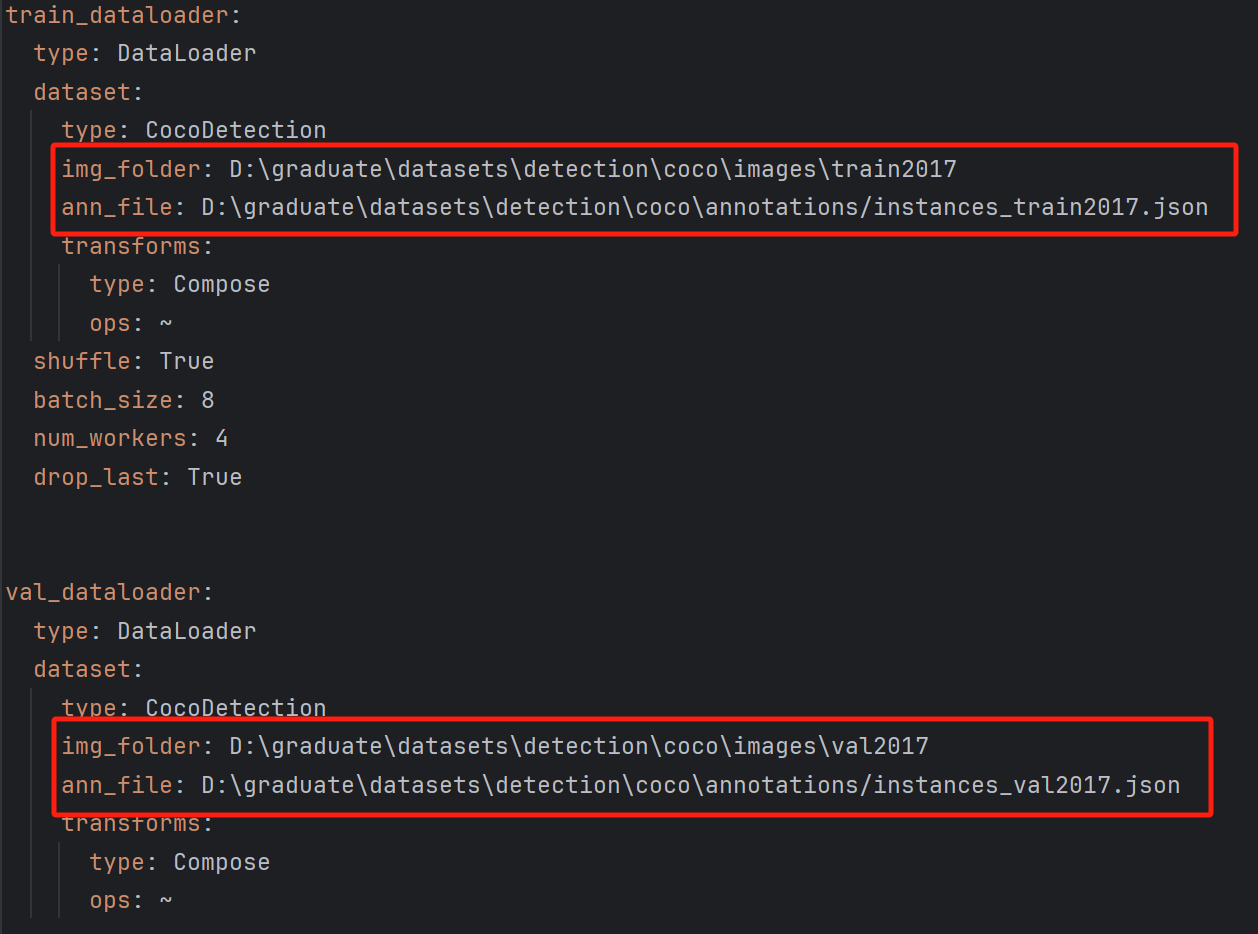
修改数据集配置文件:RT-DETR-main\rtdetr_pytorch\configs\dataset\coco_detection.yml
修改训练集与测试集路径,同时修改类别数。
随后便可以开启训练:该文件中指定 epochs
RT-DETR-main\rtdetr_pytorch\configs\rtdetr\include\optimizer.yml
首次训练,需要下载骨干网络的预训练模型

在这里,博主使用ResNet18作为骨干特征提取网络
训练结果
开始运行,查看GPU使用情况,此时的batch-size=8,可以看到显存占用4.5G左右,相较于博主先前提出的方法或者DINO,其显存占用少了许多,DINO的batch-size=2时的显存占用将近16G.
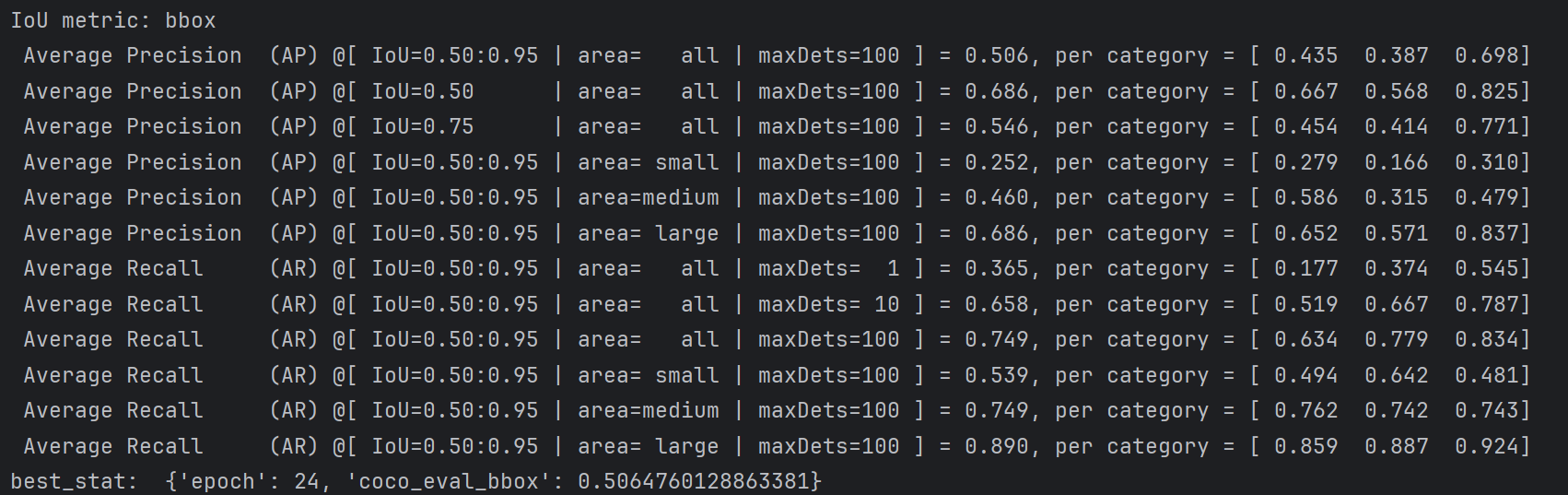
训练了24轮的结果。
训练的结果会保存在output文件夹内:
官方模型推理
在进行模型推理前,需要先导出模型,在官方代码的tools文件夹下有个export_onnx.py文件,只需要指定配置文件与训练好的模型文件:
parser.add_argument('--config', '-c', default="/rtdetr_pytorch\configs/rtdetr/rtdetr_r18vd_6x_coco.yml",type=str, )
parser.add_argument('--resume', '-r', default="rtdetr_pytorch/tools\output/rtdetr_r18vd_6x_coco\checkpoint0024.pth",type=str, )
导出的文件是onnx格式
ONNX(Open Neural Network Exchange)是一种开放式的文件格式,用于存储和交换训练好的机器学习模型。它使得不同的人工智能框架(如PyTorch、TensorFlow)可以共享模型,促进了模型在不同平台之间的迁移和复用。ONNX文件采用Protobuf序列化技术进行存储,具有高效、紧凑的特点。
随后开始推理,代码如下:
import torch
import onnxruntime as ort
from PIL import Image, ImageDraw
from torchvision.transforms import ToTensor
if __name__ == "__main__":##################classes = ['car','truck',"bus"]################### print(onnx.helper.printable_graph(mm.graph))#############img_path = "1.jpg"#############im = Image.open(img_path).convert('RGB')im = im.resize((640, 640))im_data = ToTensor()(im)[None]print(im_data.shape)size = torch.tensor([[640, 640]])sess = ort.InferenceSession("model.onnx")import timestart = time.time()output = sess.run(# output_names=['labels', 'boxes', 'scores'],output_names=None,input_feed={'images': im_data.data.numpy(), "orig_target_sizes": size.data.numpy()})end = time.time()fps = 1.0 / (end - start)print(fps)labels, boxes, scores = outputdraw = ImageDraw.Draw(im)thrh = 0.6for i in range(im_data.shape[0]):scr = scores[i]lab = labels[i][scr > thrh]box = boxes[i][scr > thrh]print(i, sum(scr > thrh))#print(lab)print(f'box:{box}')for l, b in zip(lab, box):draw.rectangle(list(b), outline='red',)print(l.item())draw.text((b[0], b[1] - 10), text=str(classes[l.item()]), fill='blue', )#############im.save('2.jpg')#############
YOLOv8集成RT-DETR训练
在YOLOv8中,给出了YOLO先前的诸多版本,此外还包含RT-DETR
其运行环境与官方的相同,这里就不再赘述了,另外,如果想要了解YOLO及其集成算法的更多功能,可以查看:
https://docs.ultralytics.com/
ultralytics集成了多种算法,已有将YOLO目标检测算法大一统的趋势,涵盖语义分割、目标检测、姿势估计、分类、跟踪等多个任务。
数据集配置
YOLO版本的RT-DETR的数据集支持的数据集格式有多种,这里博主选用的是YOLO格式的
cocoimagestrain2017val2017lablestrain2017val2017
开始训练
随后在根目录下新建一个run.py文件,文件中写入如下代码:
from ultralytics.models import RTDETR
if __name__ == '__main__':model = RTDETR(model='ultralytics/cfg/models/rt-detr/rtdetr-l.yaml')#model.load('rtdetr-l.pt') # 不使用预训练权重可注释掉此行model.train(pretrained=True, data='ultralytics\cfg\datasets\cocomine.yaml', epochs=200, batch=16, device=0, imgsz=320, workers=2,cache=False,)
运行报错:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
解决方法,这是由于Anconda的torch中的某个文件与环境中的某个文件冲突导致的,找到环境中的文件:
环境路径:
D:\softwares\Anconda\envs\detr\Library\bin
将下面的文件给重命名即可。
随后便开始训练了,如下:
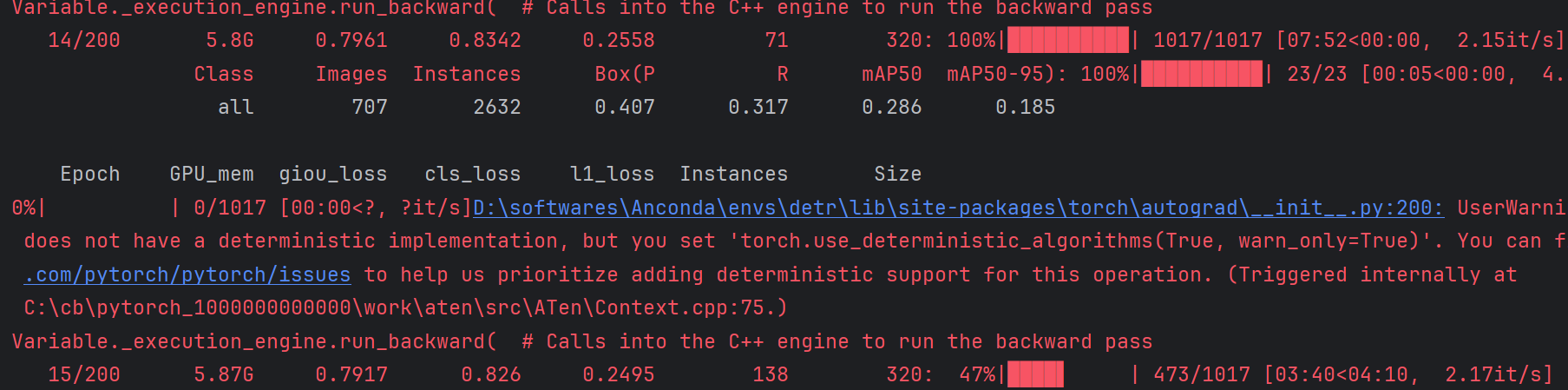
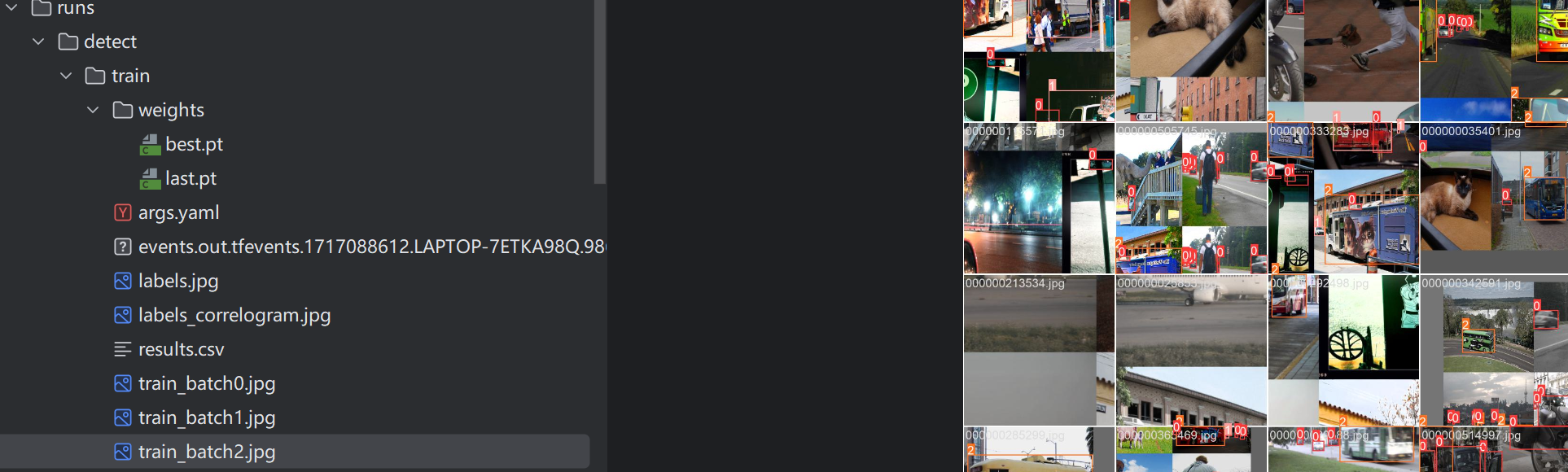
至此,RT-DETR的训练过程便完成了。博主设置训练200个epoch,但考虑到接下来的任务,因此训练到一半就停止了,生成的文件存放在run文件中,如下:
YOLOv8集成RT-DETR推理
在YOLOv8集成的RT-DETR中,其设计就非常完备了,我们只需要新建一个predict.py,里面的内容如下:
这里的images即为一个文件夹,里面可以放入多张图像,save代表保存
model=RTDETR("runs\detect/train\weights/best.pt")
model.predict(source="images",save=True)
推理结果、保存路径与推理速度都会显示在下面

当然我们还可以指定conf参数,即置信度,可以帮我们筛选一下结果:设置置信度为0.6,此时原本的汽车就不再框选了。


视频推理
视频推理也很简单,只需要将原来的图像换为视频即可
model=RTDETR("runs\detect/train\weights/best.pt")
model.predict(source="images/1.mp4",save=True,conf=0.6)

目标跟踪
在先前的目标跟踪中,都是通过先检测,后跟踪的方式,如采用YOLOv5+DeepSort的方式进行目标跟踪,而在YOLOv8中,他将该功能集成到里面,我们可以直接采用执行跟踪任务的方式完成目标跟踪。
from ultralytics.models import RTDETR
model=RTDETR("runs\detect/train\weights/best.pt")
results = model.track(source="images/1.mp4", conf=0.3, iou=0.5,save=True)
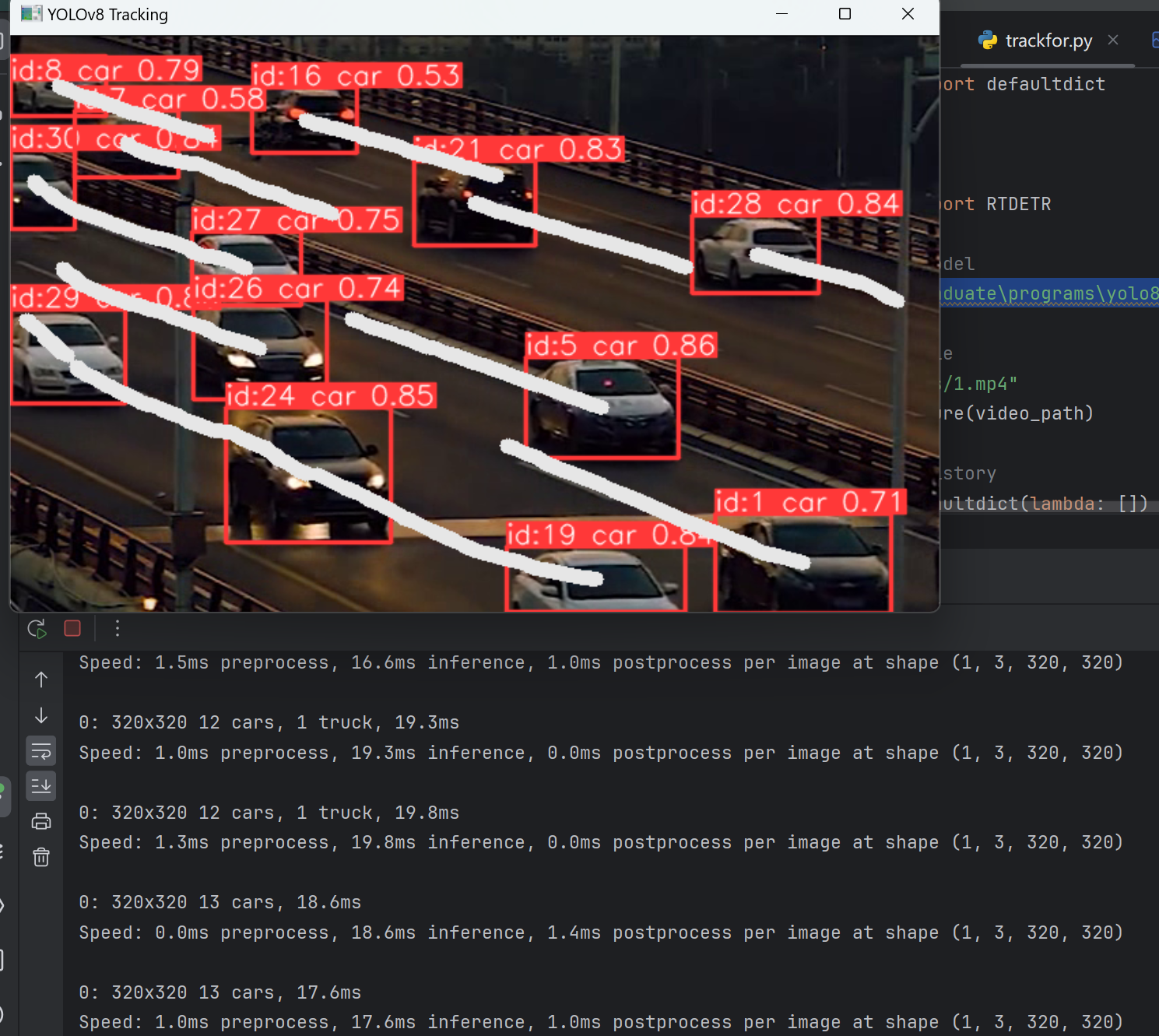
RT-DETR目标跟踪视频
轨迹绘制
from collections import defaultdictimport cv2
import numpy as np
from ultralytics import RTDETR# Load the YOLOv8 model
model=RTDETR("D:\graduate\programs\yolo8/ultralytics-main/runs\detect/train\weights/best.pt")# Open the video file
video_path = "images/1.mp4"
cap = cv2.VideoCapture(video_path)# Store the track history
track_history = defaultdict(lambda: [])# Loop through the video frames
while cap.isOpened():# Read a frame from the videosuccess, frame = cap.read()if success:# Run YOLOv8 tracking on the frame, persisting tracks between framesresults = model.track(frame, persist=True)# Get the boxes and track IDsboxes = results[0].boxes.xywh.cpu()track_ids = results[0].boxes.id.int().cpu().tolist()# Visualize the results on the frameannotated_frame = results[0].plot()# Plot the tracksfor box, track_id in zip(boxes, track_ids):x, y, w, h = boxtrack = track_history[track_id]track.append((float(x), float(y))) # x, y center pointif len(track) > 30: # retain 90 tracks for 90 framestrack.pop(0)# Draw the tracking linespoints = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)# Display the annotated framecv2.imshow("YOLOv8 Tracking", annotated_frame)# Break the loop if 'q' is pressedif cv2.waitKey(1) & 0xFF == ord("q"):breakelse:# Break the loop if the end of the video is reachedbreak# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
相关文章:
RT-DETR:端到端的实时Transformer检测模型(目标检测+跟踪)
博主一直一来做的都是基于Transformer的目标检测领域,相较于基于卷积的目标检测方法,如YOLO等,其检测速度一直为人诟病。 终于,RT-DETR横空出世,在取得高精度的同时,检测速度也大幅提升。 那么RT-DETR是如…...

OrangePi Kunpeng Pro开发板初体验——家庭小型服务器
引言 在开源硬件的浪潮中,开发板作为创新的基石,正吸引着全球开发者的目光。它们不仅为技术爱好者提供了实验的平台,更为专业开发者带来了实现复杂项目的可能性。本文将深入剖析OrangePi Kunpeng Pro开发板,从开箱到实际应用&…...
AquaCrop农业水资源管理,模拟作物生长过程中水分的需求与消耗
AquaCrop是由世界粮食及农业组织(FAO)开发的一个先进模型,旨在研究和优化农作物的水分生产效率。这个模型在全球范围内被广泛应用于农业水管理,特别是在制定农作物灌溉计划和应对水资源限制方面显示出其强大的实用性。AquaCrop 不…...

爬虫之re数据清洗
文章目录 一、正则【Regular】二、重要语法1、获取内容: 左边(.*?)右边2、替换数据: re.sub(源数据|源数据, 目标数据, 字符串) 一、正则【Regular】 概念: 根据程序员的指示, 从<字符串>中提取数据 结果: 列表 使用频率: 正则跟xpath相比, 正则是弟弟 二、重要语法 …...

惯性动作捕捉与数字人实时交互/运营套装,对高校元宇宙实训室有何作用?
惯性动作捕捉与数字人实时交互/运营套装,可以打破时空限制,通过动捕设备写实数字人软件系统动捕设备系统定制化数字人短视频渲染平台,重塑课程教学方式,开展元宇宙沉浸式体验教学活动和参观交流活动。 写实数字人软件系统内置丰富…...

Leecode---栈---每日温度 / 最小栈及栈和队列的相互实现
栈:先入后出;队列:先入先出 一、每日温度 Leecode—739题目: 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温…...

Linux系统编程——动静态库
目录 一,关于动静态库 1.1 什么是库? 1.2 认识动静态库 1.3 动静态库特征 二,静态库 2.1 制作静态库 2.2 使用静态库 三,动态库 3.1 制作动态库 3.2 使用动态库一些问题 3.3 正确使用动态库三种方法 3.3.1 方法一&…...

json formatter哪个好用
在众多的JSON Formatter工具中,确实有几个相当出色的选择,它们各自拥有独特的特点和优势,可以满足不同用户群体的需求。下面就来为大家推荐几个好用的JSONFormatter工具: 1. JSON Formatter & Validator:这款工具…...

react的hooks是什么意思
React Hooks 是 React 16.8 版本引入的一个新特性,它允许你在不编写类组件的情况下使用状态和其他React特性。Hooks使得函数组件变得更加灵活和强大,因为你可以在其中添加状态逻辑、生命周期方法以及其他React功能。 在传统的React类组件中,…...
)
AVFrame相关接口(函数)
分配和释放 分配 AVFrame AVFrame *av_frame_alloc(void); 分配一个新的 AVFrame 并返回一个指向它的指针。返回的 AVFrame 需要手动释放。 释放 AVFrame void av_frame_free(AVFrame **frame); 释放由 av_frame_alloc 分配的 AVFrame。这个函数会释放帧的数据并将指针设为 …...
低代码与人工智能的深度融合:行业应用的广泛前景
引言 在当今快速变化的数字化时代,企业面临着越来越多的挑战和机遇。低代码平台和人工智能技术的兴起,为企业提供了新的解决方案,加速了应用开发和智能化转型的步伐。 低代码平台的基本概念及发展背景 低代码平台是一种软件开发方法&#x…...

嵌入式测试基础知识
1.白盒测试也称为结构测试,主要用于检测软件编码过程中的错误。 2.黑盒测试又称为功能测试,主要检测软件的每一个功能是否能够正常使用。 3.软件测试流程:根据测试需求编写测试计划、方案,测试用例,做测试分析&#…...

基于网关的ip频繁访问web限制
一、前言 外部ip对某一个web进行频繁访问,有可能是对web进行攻击,现在提供一种基于网关的ip频繁访问web限制策略,犹如带刀侍卫,审查异常身份人员。如发现异常或者暴力闯关者,即可进行识别管制。 二、基于网关的ip频繁访…...

GSM信令流程(附着、去附着、PDP激活、修改流程)
1、联合附着流程 附着包括身份认证、鉴权等 2、去附着流程 用户发起去附着 SGSN发起去附着 HLR发起去附着 GSSN使用S4发起去附着 3、Activation Procedures(PDP激活流程) 4、PDP更新或修改流程 5、Deactivate PDP Context 6、RAU(Routeing Area Update)流程 7、鉴权加…...
OAK相机如何将 YOLOv10 模型转换成 blob 格式?
编辑:OAK中国 首发:oakchina.cn 喜欢的话,请多多👍⭐️✍ 内容可能会不定期更新,官网内容都是最新的,请查看首发地址链接。 Hello,大家好,这里是OAK中国,我是Ashely。 专…...

【Python】解决Python报错:AttributeError: ‘class‘ object has no attribute ‘xxx‘
🧑 博主简介:阿里巴巴嵌入式技术专家,深耕嵌入式人工智能领域,具备多年的嵌入式硬件产品研发管理经验。 📒 博客介绍:分享嵌入式开发领域的相关知识、经验、思考和感悟,欢迎关注。提供嵌入式方向…...
反思 GTC 和 OFC 2024:没有一刀切的方法,但上市时间是关键!
在GTC 2024期间,英伟达宣布了最新的Blackwell B200张量核心GPU,旨在为万亿参数的AI大型语言模型提供支持。Blackwell B200需要先进的800Gbps网络,完全符合在AI工作负载的AI网络报告中概述的预测。随着人工智能工作负载的流量预计每两年增长10…...

速盾:bgp 静态 cdn
BGP(边界网关协议)是一种用于在互联网中交换路由信息的协议,它允许不同自治系统(AS)之间的路由器进行通信和交换路由信息。CDN(内容分发网络)是一种通过将内容分散放置在全球各地的服务器上&…...
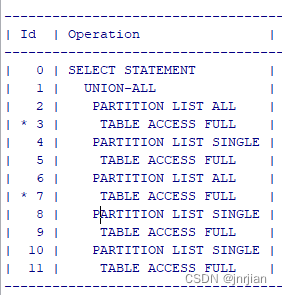
union all 以及标量子查询执行计划
SELECT 1, (SELECT ID1 FROM TE WHERE IDA.ID2) FROM .TA A WHERE COLA X UNION ALL SELECT 1, (SELECT ID2 FROM TD WHERE IDA.ID1) FROM .TB A WHERE COLA X UNION ALL SELECT 1,COL2 AS PARENT_UUID FROM .TC a WHERE COLA X 三个union all 看着像是5个table joi…...
上位机图像处理和嵌入式模块部署(f103 mcu和Qt上位机联动)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 之前我们写过一篇文章,上面说的是如何利用串口对mcu进行控制,即如果利用串口实现mcu led灯的点亮和熄灭。输入1的时候&…...

别再手动检查打印机了!用C#写个Windows服务,自动监控HP/Epson等打印机状态并微信通知
打造智能打印机监控系统:基于C#的Windows服务实战指南 打印机故障总是悄无声息地发生——当你急需打印合同时发现缺纸,演示前五分钟发现墨盒耗尽,或是批量打印时某个设备早已脱机。这些场景对IT运维人员来说再熟悉不过,而传统的人…...

基于DNS的TEE认证革新:原理、实现与性能优化
1. 项目概述:基于DNS的TEE认证革新在云计算安全领域,可信执行环境(TEE)技术正经历着从专用场景向通用基础设施的演进。传统TEE认证方案如RA-TLS存在两个根本性缺陷:一是依赖客户端主动验证硬件证明,导致非T…...

创业团队如何利用多模型聚合平台优化AI应用开发成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用多模型聚合平台优化AI应用开发成本 对于资源有限的创业团队或独立开发者而言,在开发智能客服、内容生…...

3个步骤打造专属机械键盘:Cherry MX键帽3D模型完全指南
3个步骤打造专属机械键盘:Cherry MX键帽3D模型完全指南 【免费下载链接】cherry-mx-keycaps 3D models of Chery MX keycaps 项目地址: https://gitcode.com/gh_mirrors/ch/cherry-mx-keycaps 你是否曾想过拥有独一无二的机械键盘键帽?现在&#…...

深度挖掘显卡潜能:NVIDIA Profile Inspector 高级调优完全指南
深度挖掘显卡潜能:NVIDIA Profile Inspector 高级调优完全指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾经对NVIDIA控制面板中有限的设置选项感到不够用?是否想要…...
)
NotebookLM+ElevenLabs+RSS 3.0 播客基建闭环(含Feed Validator校验失败率下降至0.3%)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM文档播客化教程 NotebookLM 是 Google 推出的基于可信文档源的 AI 助手,其“播客化”能力可将上传的 PDF、TXT 或网页内容自动转化为自然流畅的对话式音频脚本。该功能并非直接生…...

大模型的token究竟是什么?如何通俗易懂地解释?
说实话,最开始我第一次撞见「Token」这个词,第一反应还以为是武侠里的令牌,也像游乐场的游戏代币,得投币才能启动机器那种。 一直以来都没人直白地讲解过 Token 到底是什么,我也就稀里糊涂跟着用,始终一知…...

Audiveris终极指南:10分钟快速掌握开源乐谱识别技术
Audiveris终极指南:10分钟快速掌握开源乐谱识别技术 【免费下载链接】audiveris Latest generation of Audiveris OMR engine 项目地址: https://gitcode.com/gh_mirrors/au/audiveris 还在为纸质乐谱难以数字化而烦恼吗?Audiveris作为一款功能强…...

ESP32无代码物联网开发:WipperSnapper实战指南
1. 项目概述:当ESP32遇上无代码物联网如果你手头有一块ESP32-S2或ESP32-S3开发板,想快速做个物联网小项目,比如远程控制个LED灯,或者把家里的温湿度数据传到网上看看,但一看到要写代码、配网络、调API就头疼࿰…...

《C语言字符串与内存函数详解与模拟实现》
C语言字符串函数和内存函数字符串函数strcat详解模拟实现strcmp详解模拟实现strcpy详解模拟实现strstr详解模拟实现strtok详解strncat详解模拟实现strncmp详解模拟实现strncpy详解模拟实现内存函数memcpy详解模拟实现memmove详解模拟实现memset详解这篇博客我将讲解C语言中常见…...