动手学深度学习4.6 暂退法-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。
本节课程地址:丢弃法_哔哩哔哩_bilibili
本节教材地址:4.6. 暂退法(Dropout) — 动手学深度学习 2.0.0 documentation (d2l.ai)
本节开源代码:...>d2l-zh>pytorch>chapter_multilayer-perceptrons>dropout.ipynb
暂退法(Dropout)
在 4.5节 中, 我们介绍了通过惩罚权重的 𝐿2 范数来正则化统计模型的经典方法。 在概率角度看,我们可以通过以下论证来证明这一技术的合理性: 我们已经假设了一个先验,即权重的值取自均值为0的高斯分布。 更直观的是,我们希望模型深度挖掘特征,即将其权重分散到许多特征中, 而不是过于依赖少数潜在的虚假关联。
重新审视过拟合
当面对更多的特征而样本不足时,线性模型往往会过拟合。 相反,当给出更多样本而不是特征,通常线性模型不会过拟合。 不幸的是,线性模型泛化的可靠性是有代价的。 简单地说,线性模型没有考虑到特征之间的交互作用。 对于每个特征,线性模型必须指定正的或负的权重,而忽略其他特征。
泛化性和灵活性之间的这种基本权衡被描述为偏差-方差权衡(bias-variance tradeoff)。 线性模型有很高的偏差:它们只能表示一小类函数。 然而,这些模型的方差很低:它们在不同的随机数据样本上可以得出相似的结果。
深度神经网络位于偏差-方差谱的另一端。 与线性模型不同,神经网络并不局限于单独查看每个特征,而是学习特征之间的交互。 例如,神经网络可能推断“尼日利亚”和“西联汇款”一起出现在电子邮件中表示垃圾邮件, 但单独出现则不表示垃圾邮件。
即使我们有比特征多得多的样本,深度神经网络也有可能过拟合。 2017年,一组研究人员通过在随机标记的图像上训练深度网络。 这展示了神经网络的极大灵活性,因为人类很难将输入和随机标记的输出联系起来, 但通过随机梯度下降优化的神经网络可以完美地标记训练集中的每一幅图像。 想一想这意味着什么? 假设标签是随机均匀分配的,并且有10个类别,那么分类器在测试数据上很难取得高于10%的精度, 那么这里的泛化差距就高达90%,如此严重的过拟合。
深度网络的泛化性质令人费解,而这种泛化性质的数学基础仍然是悬而未决的研究问题。 我们鼓励喜好研究理论的读者更深入地研究这个主题。 本节,我们将着重对实际工具的探究,这些工具倾向于改进深层网络的泛化性。
扰动的稳健性
在探究泛化性之前,我们先来定义一下什么是一个“好”的预测模型? 我们期待“好”的预测模型能在未知的数据上有很好的表现: 经典泛化理论认为,为了缩小训练和测试性能之间的差距,应该以简单的模型为目标。 简单性以较小维度的形式展现, 我们在 4.4节 讨论线性模型的单项式函数时探讨了这一点。 此外,正如我们在 4.5节 中讨论权重衰减( 𝐿2 正则化)时看到的那样, 参数的范数也代表了一种有用的简单性度量。
简单性的另一个角度是平滑性,即函数不应该对其输入的微小变化敏感。 例如,当我们对图像进行分类时,我们预计向像素添加一些随机噪声应该是基本无影响的。 1995年,克里斯托弗·毕晓普证明了 具有输入噪声的训练等价于Tikhonov正则化 (Bishop, C. M. (1995). Training with noise is equivalent to tikhonov regularization. Neural computation, 7(1), 108–116.)。 这项工作用数学证实了“要求函数光滑”和“要求函数对输入的随机噪声具有适应性”之间的联系。
然后在2014年,斯里瓦斯塔瓦等人 (Bishop, C. M. (1995). Training with noise is equivalent to tikhonov regularization.Neural computation, 7(1), 108–116.) 就如何将毕晓普的想法应用于网络的内部层提出了一个想法: 在训练过程中,他们建议在计算后续层之前向网络的每一层注入噪声。 因为当训练一个有多层的深层网络时,注入噪声只会在输入-输出映射上增强平滑性。
这个想法被称为暂退法(dropout)。 暂退法在前向传播过程中,计算每一内部层的同时注入噪声,这已经成为训练神经网络的常用技术。 这种方法之所以被称为暂退法,因为我们从表面上看是在训练过程中丢弃(drop out)一些神经元。 在整个训练过程的每一次迭代中,标准暂退法包括在计算下一层之前将当前层中的一些节点置零。
需要说明的是,暂退法的原始论文提到了一个关于有性繁殖的类比: 神经网络过拟合与每一层都依赖于前一层激活值相关,称这种情况为“共适应性”。 作者认为,暂退法会破坏共适应性,就像有性生殖会破坏共适应的基因一样。
那么关键的挑战就是如何注入这种噪声。 一种想法是以一种无偏向(unbiased)的方式注入噪声。 这样在固定住其他层时,每一层的期望值等于没有噪音时的值。
在毕晓普的工作中,他将高斯噪声添加到线性模型的输入中。 在每次训练迭代中,他将从均值为零的分布 采样噪声添加到输入
, 从而产生扰动点
, 预期是
。
在标准暂退法正则化中,通过按保留(未丢弃)的节点的分数进行规范化来消除每一层的偏差。 换言之,每个中间活性值 ℎ 以暂退概率 𝑝 由随机变量 ℎ′ 替换,如下所示:

根据此模型的设计,其期望值保持不变,即 𝐸[ℎ′]=ℎ 。
证明:
实践中的暂退法
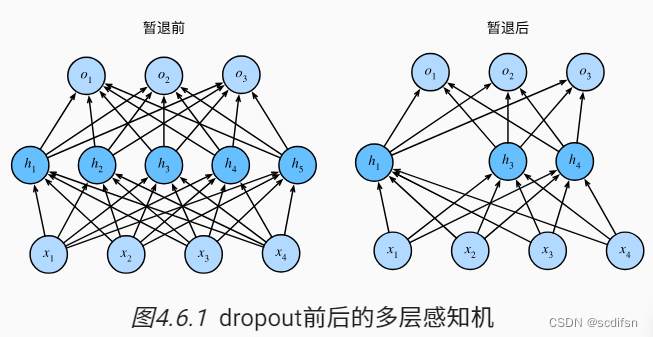
回想一下 图4.1.1 中带有1个隐藏层和5个隐藏单元的多层感知机。 当我们将暂退法应用到隐藏层,以 𝑝 的概率将隐藏单元置为零时, 结果可以看作一个只包含原始神经元子集的网络。 比如在 下图 中,删除了 和
, 因此输出的计算不再依赖于
或
,并且它们各自的梯度在执行反向传播时也会消失。 这样,输出层的计算不能过度依赖于
,…,
的任何一个元素。
通常,我们在测试时不用暂退法。 给定一个训练好的模型和一个新的样本,我们不会丢弃任何节点,因此不需要标准化。 然而也有一些例外:一些研究人员在测试时使用暂退法, 用于估计神经网络预测的“不确定性”: 如果通过许多不同的暂退法遮盖后得到的预测结果都是一致的,那么我们可以说网络发挥更稳定。
从零开始实现
要实现单层的暂退法函数, 我们从均匀分布 𝑈[0,1] 中抽取样本,样本数与这层神经网络的维度一致。 然后我们保留那些对应样本大于 𝑝 的节点,把剩下的丢弃。
在下面的代码中,(我们实现 dropout_layer 函数, 该函数以dropout的概率丢弃张量输入X中的元素), 如上所述重新缩放剩余部分:将剩余部分除以1.0-dropout。
import torch
from torch import nn
from d2l import torch as d2ldef dropout_layer(X, dropout):assert 0 <= dropout <= 1# 在本情况中,所有元素都被丢弃if dropout == 1:return torch.zeros_like(X)# 在本情况中,所有元素都被保留if dropout == 0:return X# 生成一个与输入张量形状相同的掩码 mask# 对于掩码中的每个元素:# 随机数> dropout 概率,对应的掩码元素为 1;随机数≤ dropout 概率,对应的掩码元素为 0。mask = (torch.rand(X.shape) > dropout).float()# 被保留的元素*缩放因子 1 / (1 - dropout),以抵消丢弃的元素所引起的缩放效果return mask * X / (1.0 - dropout)我们可以通过下面几个例子来[测试dropout_layer函数]。 我们将输入X通过暂退法操作,暂退概率分别为0、0.5和1。
X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 2., 4., 0., 0., 0., 0., 0.],[ 0., 18., 20., 0., 0., 0., 28., 30.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0.]])定义模型参数
同样,我们使用 3.5节 中引入的Fashion-MNIST数据集。 我们[定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元]。
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256定义模型
我们可以将暂退法应用于每个隐藏层的输出(在激活函数之后), 并且可以为每一层分别设置暂退概率: 常见的技巧是在靠近输入层的地方设置较低的暂退概率。 下面的模型将第一个和第二个隐藏层的暂退概率分别设置为0.2和0.5, 并且暂退法只在训练期间有效。
dropout1, dropout2 = 0.2, 0.5class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))# 只有在训练模型时才使用dropoutif self.training == True:# 在第一个全连接层之后添加一个dropout层H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.training == True:# 在第二个全连接层之后添加一个dropout层H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)[训练和测试]
这类似于前面描述的多层感知机训练和测试。
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)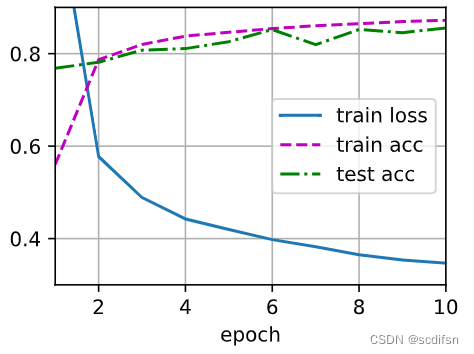
[简洁实现]
对于深度学习框架的高级API,我们只需在每个全连接层之后添加一个Dropout层, 将暂退概率作为唯一的参数传递给它的构造函数。 在训练时,Dropout层将根据指定的暂退概率随机丢弃上一层的输出(相当于下一层的输入)。 在测试时,Dropout层仅传递数据。
net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),# 在第一个全连接层之后添加一个dropout层nn.Dropout(dropout1),nn.Linear(256, 256),nn.ReLU(),# 在第二个全连接层之后添加一个dropout层nn.Dropout(dropout2),nn.Linear(256, 10))def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights);接下来,我们[对模型进行训练和测试]。
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)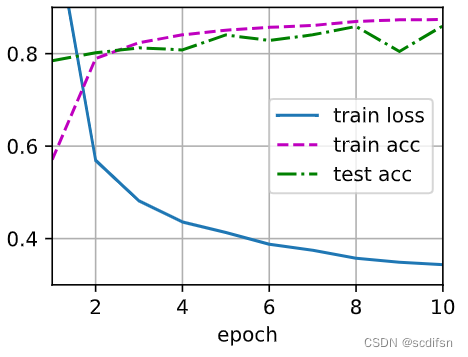
小结
- 暂退法在前向传播过程中,计算每一内部层的同时丢弃一些神经元。
- 暂退法可以避免过拟合,它通常与控制权重向量的维数和大小结合使用的。
- 暂退法将活性值 ℎ 替换为具有期望值 ℎ 的随机变量。
- 暂退法仅在训练期间使用。
练习
- 如果更改第一层和第二层的暂退法概率,会发生什么情况?具体地说,如果交换这两个层,会发生什么情况?设计一个实验来回答这些问题,定量描述该结果,并总结定性的结论。
解:
当第一层的dropout概率较低而第二层的dropout概率较高时,模型在训练集上可能更容易过拟合,训练损失相对较小,因为第一层的正则化较少,而第二层的正则化较多。这可能导致训练精度较高,但测试精度较低。
当第一层的dropout概率较高而第二层的dropout概率较低时,模型可能更加稀疏,模型被迫更多地进行正则化,可能导致训练损失相对较大,具有更好的泛化能力,因此训练和测试精度可能更加接近。
代码如下:
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)dropout1 = [0.2, 0.5]
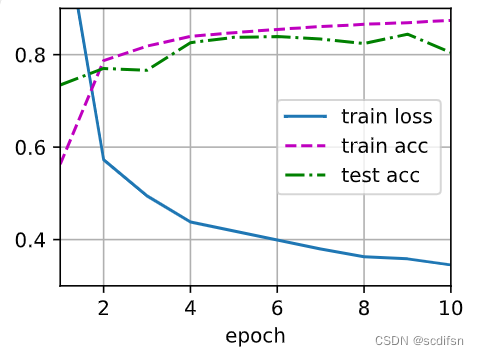
dropout2 = [0.5, 0.2]def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)def test4_6_1(i):net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),nn.Dropout(dropout1[i]),nn.Linear(256, 256),nn.ReLU(),nn.Dropout(dropout2[i]),nn.Linear(256, 10))net.apply(init_weights)trainer = torch.optim.SGD(net.parameters(), lr=lr)animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])trainer = torch.optim.SGD(net.parameters(), lr=lr)for epoch in range(num_epochs):train_metrics = d2l.train_epoch_ch3(net, train_iter, loss, trainer)test_acc = d2l.evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metricsprint(f'when dropout1 = {dropout1[i]} and dropout2 = {dropout2[i]}: \n train_loss = {train_loss}, \n train_acc = {train_acc}, \n test_acc = {test_acc} \n')
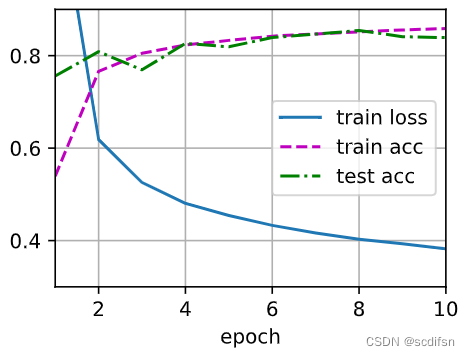
test4_6_1(0)when dropout1 = 0.2 and dropout2 = 0.5:
train_loss = 0.34520809008280434,
train_acc = 0.8740166666666667,
test_acc = 0.8048
test4_6_1(1)when dropout1 = 0.5 and dropout2 = 0.2:
train_loss = 0.38206317017873126,
train_acc = 0.8587,
test_acc = 0.839
2. 增加训练轮数,并将使用暂退法和不使用暂退法时获得的结果进行比较。
解:
当没有dropout层时,模型的容量较大,可以方便地拟合训练集中的噪声和异常数据,从而陷入过拟合的情况。这导致模型对训练数据的预测较准确,但对测试集或新数据的泛化能力较差,因此测试精度较低。
当增加dropout层时,通过在训练过程中以一定的概率随机将部分神经元的输出置为0,从而降低神经网络模型的复杂度,减少过拟合的风险,测试精度与训练精度接近,测试精度较高。其中,dropout扮演着随机删除神经元的角色,使得每个神经元都不依赖于其他特定的神经元,强制模型学习具有鲁棒性的特征。
代码如下:
num_epochs, lr, batch_size = 30, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)dropout1 = [0, 0.5]
dropout2 = [0, 0.2]def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)def test4_6_2(i):net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),nn.Dropout(dropout1[i]),nn.Linear(256, 256),nn.ReLU(),nn.Dropout(dropout2[i]),nn.Linear(256, 10))net.apply(init_weights)animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.0, 1.0],legend=['train loss', 'train acc', 'test acc'])trainer = torch.optim.SGD(net.parameters(), lr=lr)for epoch in range(num_epochs):train_metrics = d2l.train_epoch_ch3(net, train_iter, loss, trainer)test_acc = d2l.evaluate_accuracy(net, test_iter)if epoch == 0 or (epoch + 1) % 5 == 0:animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metricsprint(f'when dropout1 = {dropout1[i]} and dropout2 = {dropout2[i]}: \n train_loss = {train_loss}, \n train_acc = {train_acc}, \n test_acc = {test_acc} \n')
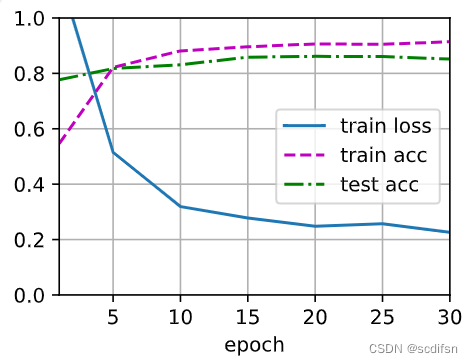
# 不应用暂退法
test4_6_2(0)when dropout1 = 0 and dropout2 = 0:
train_loss = 0.22578163261413575,
train_acc = 0.9141833333333333,
test_acc = 0.8517
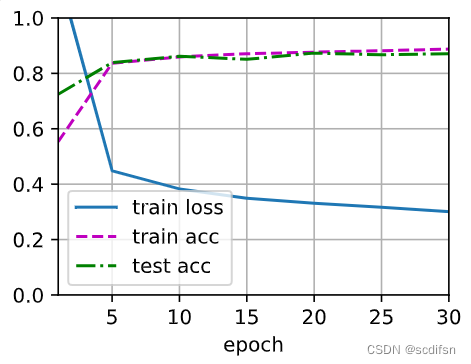
# 应用暂退法
test4_6_2(1)when dropout1 = 0.5 and dropout2 = 0.2:
train_loss = 0.3011401181856791,
train_acc = 0.8876666666666667,
test_acc = 0.8711
3. 当应用或不应用暂退法时,每个隐藏层中激活值的方差是多少?绘制一个曲线图,以显示这两个模型的每个隐藏层中激活值的方差是如何随时间变化的。
解:
应用暂退法后,每个隐藏层中激活值的方差均有所下降,说明应用暂退法会减少网络中神经元之间的相互依赖性,因此可以降低激活值的方差。
代码如下:
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
dropouts = [(0, 0),(0.5, 0.2)]class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))if self.training == True:H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))v1 = torch.var(H2)if self.training == True:H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)v2 = torch.var(out)return out, v1, v2def train_epoch_var(net, train_iter, loss, updater):if isinstance(net, torch.nn.Module):net.train()# 第一层方差总和、第二层方差总和、样本数metric = d2l.Accumulator(3)for X, y in train_iter:y_hat, v1, v2 = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.mean().backward()updater.step()else:l.sum().backward()updater(X.shape[0])metric.add(v1, v2, y.numel())return metric[0] / metric[2], metric[1] / metric[2]def test4_6_3():nodpv = []dpv =[]animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.0, 0.04],legend=['w/o dp-Var-H1', 'w/o dp-Var-H2', 'with dp-Var-H1', 'with dp-Var-H2'])for epoch in range(num_epochs):dropout1, dropout2 = dropouts[0]net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)trainer = torch.optim.SGD(net.parameters(), lr=lr)nodpv1, nodpv2 = train_epoch_var(net, train_iter, loss, trainer)nodpv.append((nodpv1, nodpv2))for epoch in range(num_epochs): dropout1, dropout2 = dropouts[1]net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)trainer = torch.optim.SGD(net.parameters(), lr=lr)dpv1, dpv2 = train_epoch_var(net, train_iter, loss, trainer)dpv.append((dpv1, dpv2))for epoch in range(num_epochs):nodpv1, nodpv2 = nodpv[epoch]dpv1, dpv2 = dpv[epoch]animator.add(epoch + 1, (nodpv1, nodpv2, dpv1, dpv2))print(f'when without the addition of dropout (dropout1=0, dropout2=0): \n Activation Variance of H1 = {nodpv1}, \n Activation Variance of H2 = {nodpv2} \n')print(f'when using dropout (dropout1=0.5, dropout2=0.2): \n Activation Variance of H1 = {dpv1}, \n Activation Variance of H2 = {dpv2} \n')
test4_6_3()when without the addition of dropout (dropout1=0, dropout2=0):
Activation Variance of H1 = 0.0005452420459284137,
Activation Variance of H2 = 0.0378428224458786
when using dropout (dropout1=0.5, dropout2=0.2):
Activation Variance of H1 = 0.0005301799479949599,
Activation Variance of H2 = 0.03501103252992422

4. 为什么在测试时通常不使用暂退法?
解:
因为dropout层在训练过程中起到了正则化和随机失活的作用,有助于减少过拟合问题。而在测试过程中,通常希望得到一个稳定而确定的预测结果,而不是随机性的结果。
5. 以本节中的模型为例,比较使用暂退法和权重衰减的效果。如果同时使用暂退法和权重衰减,会发生什么情况?结果是累加的吗?收益是否减少(或者说更糟)?它们互相抵消了吗?
解:
就以下代码设置的超参数测试结果来看,相比于不应用正则化:
只应用暂退法,由于一部分神经元的输出值被丢弃,训练损失相对上升,过拟合减少,训练精度和测试精度接近,训练精度相对下降,测试精度相对上升;
只应用权重衰减,结果与只应用暂退法类似,但是这里wd设置很小,为0.001,因为模型较简单,wd设置较大会导致参数减小到接近零,导致模型欠拟合,即模型无法很好地拟合训练数据,也无法泛化到测试数据,甚至出现参数为NaN的情况;
同时应用暂退法和权重衰减,训练损失更高了,过拟合也减少,但是训练和测试精度较单独应用暂退法和权重衰减都更低了,从测试精度而言,同时应用暂退法和权重衰减的结果不如单独应用。
代码如下:
num_epochs, lr, batch_size = 20, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)def test4_6_5():net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),nn.Dropout(dropout1),nn.Linear(256, 256),nn.ReLU(),nn.Dropout(dropout2),nn.Linear(256, 10))net.apply(init_weights)trainer = torch.optim.SGD(net.parameters(),lr = lr,weight_decay = wd)when not applying regularization: train_loss = 0.23261579389572143, train_acc = 0.91085, test_acc = 0.851animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.0, 1.0], legend=['train loss', 'train acc', 'test acc']for epoch in range(num_epochs):train_metrics = d2l.train_epoch_ch3(net, train_iter, loss, trainer)test_acc = d2l.evaluate_accuracy(net, test_iter)if epoch == 0 or (epoch+1)%5 == 0:animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metricsreturn train_loss, train_acc, test_acc
#不用正则化
dropout1, dropout2, wd = 0, 0, 0
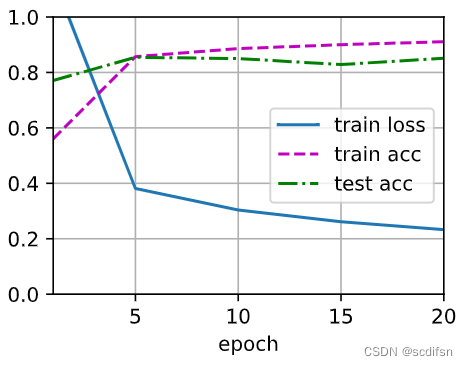
train_loss, train_acc, test_acc = test4_6_5()
print(f'when not applying regularization: \n train_loss = {train_loss}, \n train_acc = {train_acc}, \n test_acc = {test_acc} \n')when not applying regularization:
train_loss = 0.23261579389572143,
train_acc = 0.91085,
test_acc = 0.851
#只用暂退法
dropout1, dropout2, wd = 0.5, 0.2, 0
train_loss, train_acc, test_acc = test4_6_5()
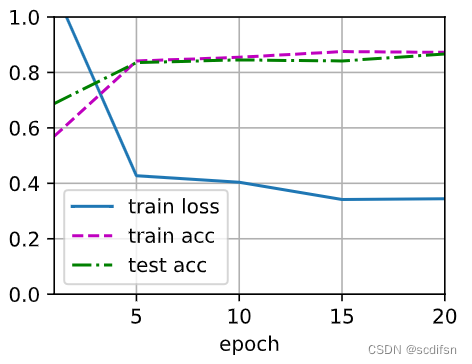
print(f'when only applying dropout: \n train_loss = {train_loss}, \n train_acc = {train_acc}, \n test_acc = {test_acc} \n')when only applying dropout:
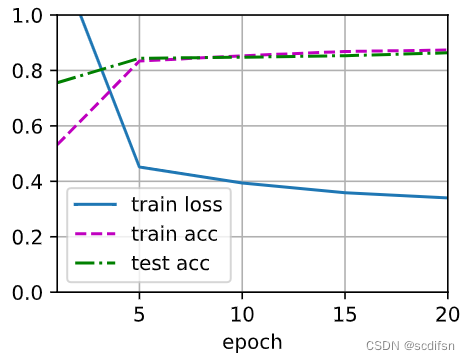
train_loss = 0.34002029434839887,
train_acc = 0.8737333333333334,
test_acc = 0.8637
#只用权重衰减
dropout1, dropout2, wd = 0, 0, 0.001
train_loss, train_acc, test_acc = test4_6_5()
print(f'when only applying weight decay: \n train_loss = {train_loss}, \n train_acc = {train_acc}, \n test_acc = {test_acc} \n')when only applying weight decay:
train_loss = 0.34449525162378947,
train_acc = 0.87245,
test_acc = 0.8665
#同时应用暂退法和权重衰减
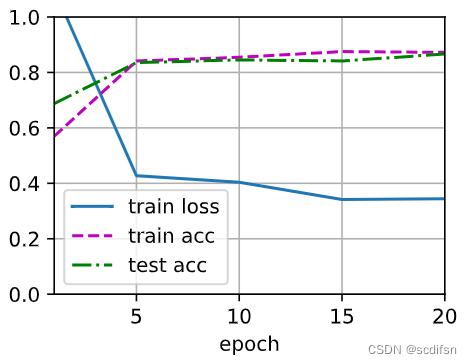
dropout1, dropout2, wd = 0.5, 0.2, 0.001
train_loss, train_acc, test_acc = test4_6_5()
print(f'when both applying dropout and weight decay: \n train_loss = {train_loss}, \n train_acc = {train_acc}, \n test_acc = {test_acc} \n')when both applying dropout and weight decay:
train_loss = 0.4087323947270711,
train_acc = 0.8492666666666666,
test_acc = 0.8424
6. 如果我们将暂退法应用到权重矩阵的各个权重,而不是激活值,会发生什么?
解:
如果将 dropout 应用到权重矩阵的各个权重,而不是激活值,会导致模型学习过程中的权重被随机丢弃和缩放。
称为DropConnect方法,类似于Dropout,但是不是随机丢弃神经元的输出,而是随机丢弃连接权重。这样可以强制网络去学习更加鲁棒的特征,因为任何一个神经元都不能依赖于特定的输入。
就以下代码设置的超参数测试结果来看,将dropout应用于权重矩阵,结果图像与将dropout应用于激活值的结果图像较为接近,但训练损失较大,训练精度和测试精度也较低,运行速度变慢,且效果不如将dropout应用于激活值。
代码如下:
num_epochs, lr, batch_size = 20, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
dropout1, dropout2 = 0.5, 0.5class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):if self.training == True:W1 = dropout_layer(self.lin1.weight, dropout1)H1 = self.relu(torch.matmul(X.reshape((-1, self.num_inputs)), W1.t()) + self.lin1.bias)else:H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs)))) if self.training == True:W2 = dropout_layer(self.lin2.weight, dropout2)H2 = self.relu(torch.matmul(H1, W2.t()) + self.lin2.bias)else:H2 = self.relu(self.lin2(H1)) out = self.lin3(H2)return outdef test4_6_6():net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.0, 1.0], legend=['train loss', 'train acc', 'test acc'])trainer = torch.optim.SGD(net.parameters(), lr=lr)for epoch in range(num_epochs):train_metrics = d2l.train_epoch_ch3(net, train_iter, loss, trainer)test_acc = d2l.evaluate_accuracy(net, test_iter)if epoch == 0 or (epoch+1)%5 == 0:animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metricsprint(f'Applying dropout on Weight: \n train_loss = {train_loss}, \n train_acc = {train_acc}, \n test_acc = {test_acc} \n')
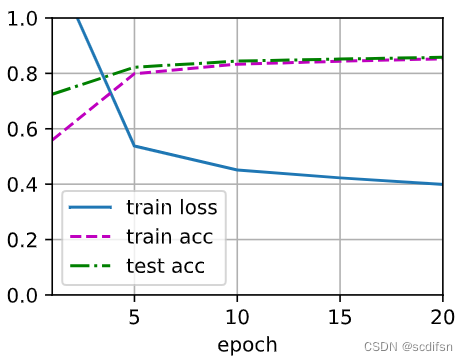
test4_6_6()Applying dropout on Weight:
train_loss = 0.3987879627863566,
train_acc = 0.85275,
test_acc = 0.8579
7. 发明另一种用于在每一层注入随机噪声的技术,该技术不同于标准的暂退法技术。尝试开发一种在Fashion-MNIST数据集(对于固定架构)上性能优于暂退法的方法。
解:
采用高斯噪声注入法,在每一层的输入中添加一个均值为0、标准差为某个小值的高斯噪声,以增加模型的鲁棒性和泛化能力。与应用暂退法相比,过拟合均减小,且训练损失更小,训练精度和测试精度更高。
代码如下:
num_epochs, lr, batch_size = 20, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
mean = 0
std = 0.1class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):if self.training == True: X = X + torch.randn_like(X)*std+meanH1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs)))) if self.training == True: H1 = H1 + torch.randn_like(H1)*std+meanH2 = self.relu(self.lin2(H1)) out = self.lin3(H2)return outdef test4_6_7():net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.0, 1.0], legend=['train loss', 'train acc', 'test acc'])trainer = torch.optim.SGD(net.parameters(), lr=lr)for epoch in range(num_epochs):train_metrics = d2l.train_epoch_ch3(net, train_iter, loss, trainer)test_acc = d2l.evaluate_accuracy(net, test_iter)if epoch == 0 or (epoch+1)%5 == 0:animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metricsprint(f'Applying Gaussian random noise on Weight: \n train_loss = {train_loss}, \n train_acc = {train_acc}, \n test_acc = {test_acc} \n')
test4_6_7()Applying Gaussian random noise on Weight:
train_loss = 0.24927903547286986,
train_acc = 0.9054166666666666,
test_acc = 0.8818

相关文章:
动手学深度学习4.6 暂退法-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。 本节课程地址:丢弃法_哔哩哔哩_bilibili 本节教材地址:4.6. 暂退法(Dropout)…...

C++ 头文件优化
C 是一种灵活的语言,所以需要一种积极的方法来分析和减少编译时依赖。一种常见的达到这个目的的方法是,将依赖从头文件里转移到源代码文件里。实现这个目的的方法叫做提前声明。 简而言之,这些声明告诉编译器某个函数接受和返回哪些参数&…...

DataRockMan洛克先锋OZON选品工具
随着全球电子商务的飞速发展,跨境电商平台已成为越来越多企业和个人追逐市场红利的重要战场。在众多跨境电商平台中,OZON以其独特的市场定位和强大的用户基础,吸引了无数卖家的目光。然而,如何在OZON平台上成功选品,成…...
-全文解析器-MeCab)
【MySQL精通之路】全文搜索(9)-全文解析器-MeCab
主博客: 【MySQL精通之路】全文搜索功能-CSDN博客 目录 1.介绍 2.安装MeCab Parser插件 3.创建使用MeCab分析器的FULLTEXT索引 4.MeCab Parser空间处理 5.MeCab分析程序停止字处理 6.MeCab Parser术语搜索 7.MeCab分析程序通配符搜索 8.MeCab语法分析器短语…...

【工具】 MyBatis Plus的SQL拦截器自动翻译替换“?“符号为真实数值
【工具】 MyBatis Plus的SQL拦截器自动翻译替换"?"符号为真实数值 使用MyBatis的配置如下所示: mybatis-plus:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl调用接口,sql日志打印如下: 参数和sql语句不…...
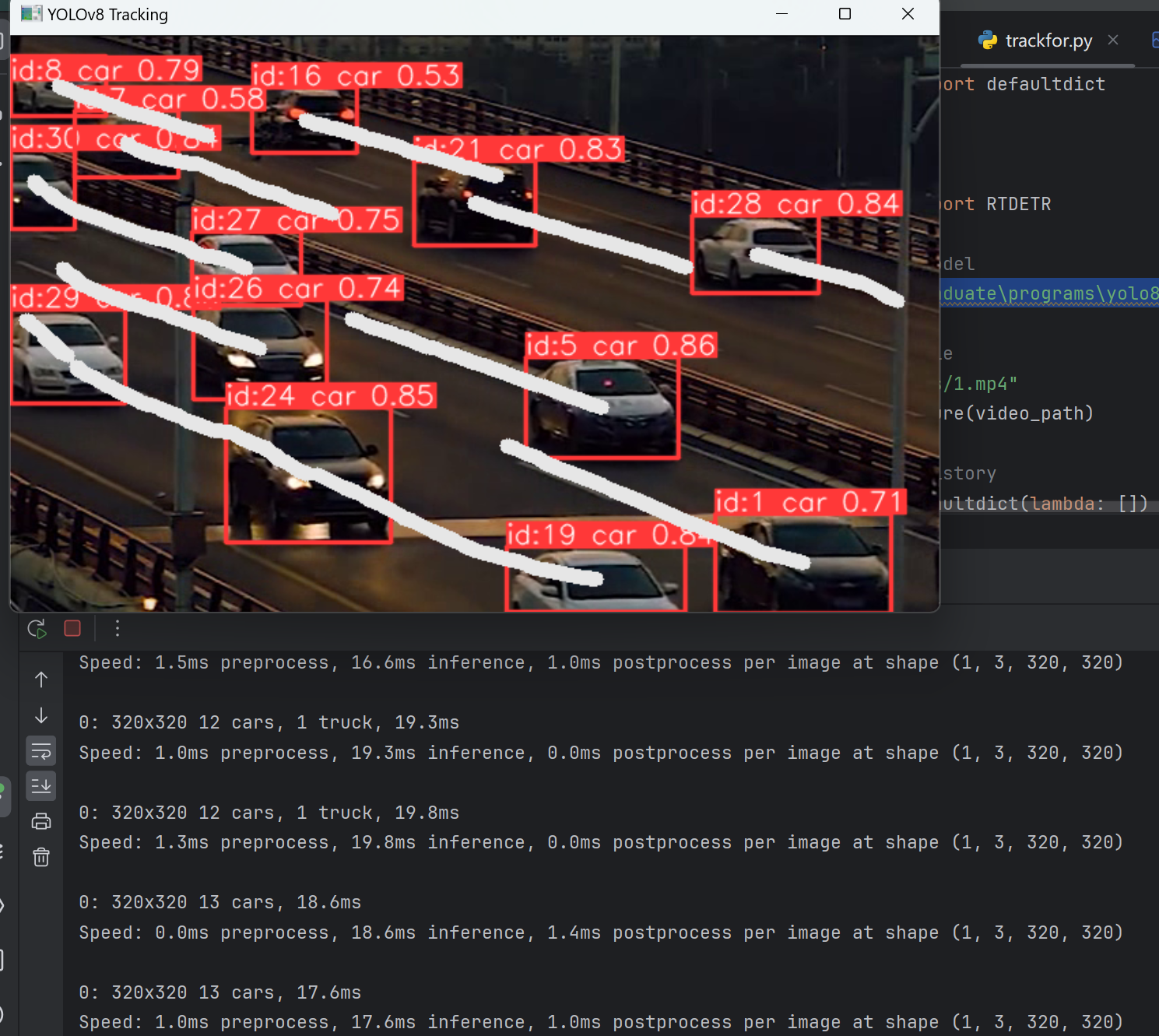
RT-DETR:端到端的实时Transformer检测模型(目标检测+跟踪)
博主一直一来做的都是基于Transformer的目标检测领域,相较于基于卷积的目标检测方法,如YOLO等,其检测速度一直为人诟病。 终于,RT-DETR横空出世,在取得高精度的同时,检测速度也大幅提升。 那么RT-DETR是如…...

OrangePi Kunpeng Pro开发板初体验——家庭小型服务器
引言 在开源硬件的浪潮中,开发板作为创新的基石,正吸引着全球开发者的目光。它们不仅为技术爱好者提供了实验的平台,更为专业开发者带来了实现复杂项目的可能性。本文将深入剖析OrangePi Kunpeng Pro开发板,从开箱到实际应用&…...
AquaCrop农业水资源管理,模拟作物生长过程中水分的需求与消耗
AquaCrop是由世界粮食及农业组织(FAO)开发的一个先进模型,旨在研究和优化农作物的水分生产效率。这个模型在全球范围内被广泛应用于农业水管理,特别是在制定农作物灌溉计划和应对水资源限制方面显示出其强大的实用性。AquaCrop 不…...

爬虫之re数据清洗
文章目录 一、正则【Regular】二、重要语法1、获取内容: 左边(.*?)右边2、替换数据: re.sub(源数据|源数据, 目标数据, 字符串) 一、正则【Regular】 概念: 根据程序员的指示, 从<字符串>中提取数据 结果: 列表 使用频率: 正则跟xpath相比, 正则是弟弟 二、重要语法 …...

惯性动作捕捉与数字人实时交互/运营套装,对高校元宇宙实训室有何作用?
惯性动作捕捉与数字人实时交互/运营套装,可以打破时空限制,通过动捕设备写实数字人软件系统动捕设备系统定制化数字人短视频渲染平台,重塑课程教学方式,开展元宇宙沉浸式体验教学活动和参观交流活动。 写实数字人软件系统内置丰富…...

Leecode---栈---每日温度 / 最小栈及栈和队列的相互实现
栈:先入后出;队列:先入先出 一、每日温度 Leecode—739题目: 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温…...

Linux系统编程——动静态库
目录 一,关于动静态库 1.1 什么是库? 1.2 认识动静态库 1.3 动静态库特征 二,静态库 2.1 制作静态库 2.2 使用静态库 三,动态库 3.1 制作动态库 3.2 使用动态库一些问题 3.3 正确使用动态库三种方法 3.3.1 方法一&…...

json formatter哪个好用
在众多的JSON Formatter工具中,确实有几个相当出色的选择,它们各自拥有独特的特点和优势,可以满足不同用户群体的需求。下面就来为大家推荐几个好用的JSONFormatter工具: 1. JSON Formatter & Validator:这款工具…...

react的hooks是什么意思
React Hooks 是 React 16.8 版本引入的一个新特性,它允许你在不编写类组件的情况下使用状态和其他React特性。Hooks使得函数组件变得更加灵活和强大,因为你可以在其中添加状态逻辑、生命周期方法以及其他React功能。 在传统的React类组件中,…...
)
AVFrame相关接口(函数)
分配和释放 分配 AVFrame AVFrame *av_frame_alloc(void); 分配一个新的 AVFrame 并返回一个指向它的指针。返回的 AVFrame 需要手动释放。 释放 AVFrame void av_frame_free(AVFrame **frame); 释放由 av_frame_alloc 分配的 AVFrame。这个函数会释放帧的数据并将指针设为 …...
低代码与人工智能的深度融合:行业应用的广泛前景
引言 在当今快速变化的数字化时代,企业面临着越来越多的挑战和机遇。低代码平台和人工智能技术的兴起,为企业提供了新的解决方案,加速了应用开发和智能化转型的步伐。 低代码平台的基本概念及发展背景 低代码平台是一种软件开发方法&#x…...

嵌入式测试基础知识
1.白盒测试也称为结构测试,主要用于检测软件编码过程中的错误。 2.黑盒测试又称为功能测试,主要检测软件的每一个功能是否能够正常使用。 3.软件测试流程:根据测试需求编写测试计划、方案,测试用例,做测试分析&#…...

基于网关的ip频繁访问web限制
一、前言 外部ip对某一个web进行频繁访问,有可能是对web进行攻击,现在提供一种基于网关的ip频繁访问web限制策略,犹如带刀侍卫,审查异常身份人员。如发现异常或者暴力闯关者,即可进行识别管制。 二、基于网关的ip频繁访…...

GSM信令流程(附着、去附着、PDP激活、修改流程)
1、联合附着流程 附着包括身份认证、鉴权等 2、去附着流程 用户发起去附着 SGSN发起去附着 HLR发起去附着 GSSN使用S4发起去附着 3、Activation Procedures(PDP激活流程) 4、PDP更新或修改流程 5、Deactivate PDP Context 6、RAU(Routeing Area Update)流程 7、鉴权加…...
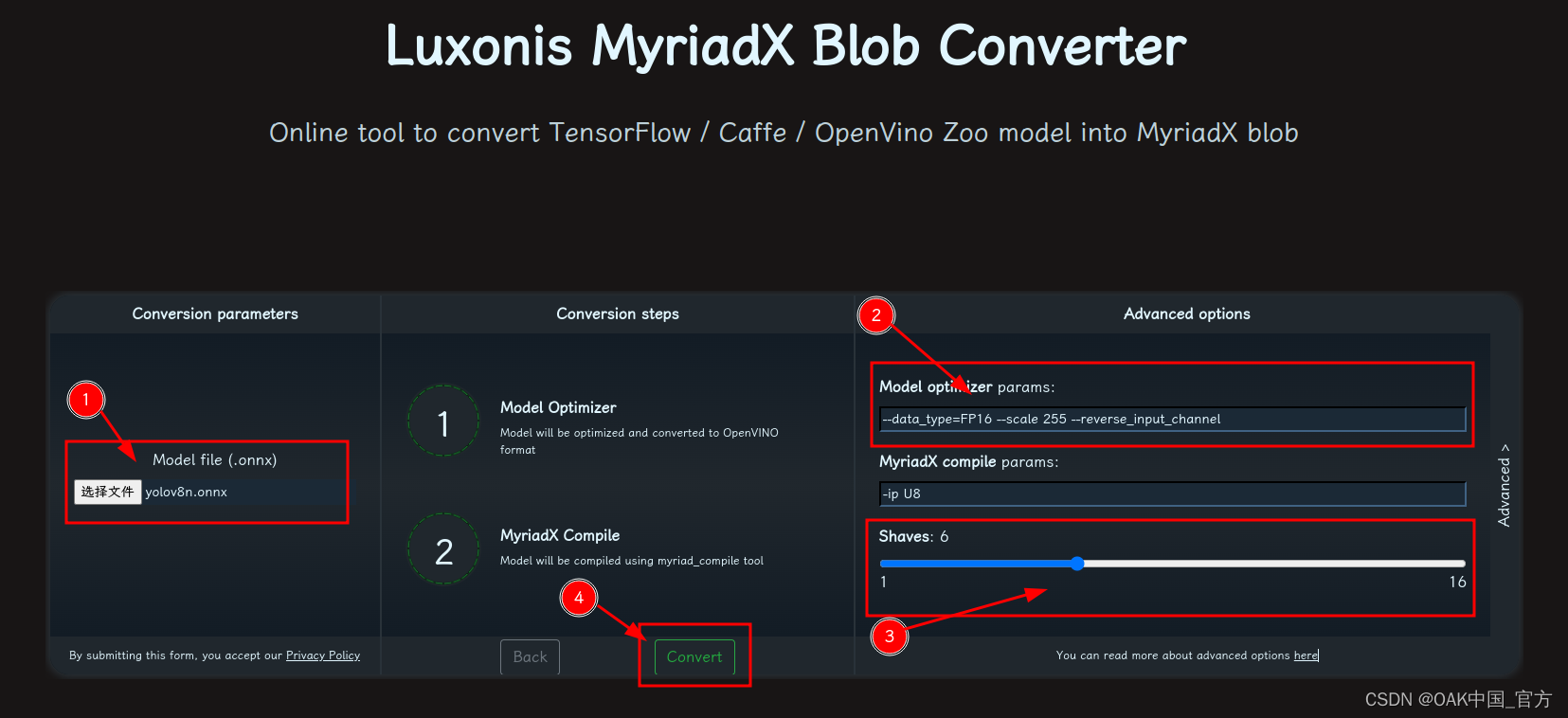
OAK相机如何将 YOLOv10 模型转换成 blob 格式?
编辑:OAK中国 首发:oakchina.cn 喜欢的话,请多多👍⭐️✍ 内容可能会不定期更新,官网内容都是最新的,请查看首发地址链接。 Hello,大家好,这里是OAK中国,我是Ashely。 专…...
)
Sora 2 × YouTube双平台协同工作流:自动生成多尺寸横竖版+智能章节标记+CC字幕同步(仅需1次Prompt)
更多请点击: https://intelliparadigm.com 第一章:Sora 2 YouTube双平台协同工作流全景概览 Sora 2 作为新一代多模态生成引擎,已原生支持高保真视频结构化输出与语义时间轴标注;YouTube 则通过 Creator Studio API 和 Data API…...

生产级 Agent Loop 的状态机设计:从 while 循环到可恢复执行引擎
摘要 很多人第一次写 Agent,都会写出类似下面的代码: while True:response llm(messages)if response.final:return response.textresult run_tool(response.tool_call)messages.append(result)这段代码能跑 demo,但很难上生产。真实系统需…...

ARM调试架构中DBGCLAIMCLR寄存器详解
1. ARM调试架构中的DBGCLAIMCLR寄存器深度解析在嵌入式系统开发领域,ARM架构的调试子系统一直是工程师们需要掌握的核心技术。作为调试功能的关键组成部分,DBGCLAIMCLR寄存器在调试器与目标系统的交互中扮演着重要角色。这个看似简单的32位寄存器&#x…...

GBase 8s 之 dbschema 导出数据库对象定义介绍
在数据库管理和开发过程中,经常需要导出数据库对象的定义,以便进行备份、迁移或分析。GBase 8s 提供了 dbschema 工具,能够方便地导出各种数据库对象的定义。本文将详细介绍 dbschema 的使用方法,帮助你快速掌握这一实用工具。…...

合宙ESP32C3 Flash模式进阶:从DIO到QIO的性能跃迁与实战避坑
1. ESP32C3 Flash模式基础:从DIO到QIO的本质差异 第一次接触ESP32C3的开发者可能会疑惑:为什么Flash访问模式会影响性能?这要从ESP32的XiP架构说起。XiP全称eXecute in Place,意味着代码直接从外部Flash执行,而不是像传…...

Smiley Sans字体如何在商业项目中合规使用?三步解决开源字体版权风险
Smiley Sans字体如何在商业项目中合规使用?三步解决开源字体版权风险 【免费下载链接】smiley-sans 得意黑 Smiley Sans:一款在人文观感和几何特征中寻找平衡的中文黑体 项目地址: https://gitcode.com/gh_mirrors/smi/smiley-sans 在商业项目中选…...

【Matlab】车牌识别与车辆属性提取系统设计与仿真实现
【Matlab】车牌识别与车辆属性提取系统设计与仿真实现 一、引言 在智能交通、安防监控、智能停车管理、交通违章稽查等领域,车牌识别与车辆属性提取是实现智能化管理、精准化管控的核心技术支撑。车牌作为车辆的唯一身份标识,其快速、精准识别是实现车辆动态追踪、身份核验…...

A公司B型汽车底盘装配线优化【附代码】
✨ 长期致力于装配线优化、IE方法、自适应遗传算法、SLP方法、Flexsim仿真研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于IE方法和自适应遗传算法…...

Design - 一些免费图标网站
一些有用的工具网站;除了直接AI生成外,仍然有些有用的Icon免费网站,比较适合游戏的有:1. icons8.com最适合综合型游戏项目图标、插画、UI 资源比较全风格统一,适合游戏界面、按钮、功能图标可在线调整颜色和尺寸&#…...

别再只会轮询了!STM32CubeMX配置USART中断,从原理到调试一条龙指南
STM32串口中断实战:从轮询到事件驱动的效率跃迁 在嵌入式开发中,串口通信就像系统的神经末梢,负责与外界交换关键信息。传统轮询方式如同不断拨打电话确认消息,而中断机制则像设置来电提醒——只有当数据真正到达时才会唤醒CPU。这…...