GPTQ 量化大模型
GPTQ 量化大模型
GPTQ 算法
GPTQ 算法由 Frantar 等人 (2023) 提出,它从 OBQ 方法中汲取灵感,但进行了重大改进,可以将其扩展到(非常)大型的语言模型。
步骤 1:任意顺序量化
OBQ 方法选择权重按特定顺序进行量化,该顺序由增加的额外误差最小决定。然而,GPTQ 观察到,对于大型模型,以任何固定顺序量化权重都可以获得同样好的效果。这是因为即使某些权重可能单独引入更多误差,但它们会在流程后期量化,此时剩下的其他权重很少,这可能会增加误差。所以顺序并不像我们想象的那么重要。
基于这一见解,GPTQ 旨在以相同的顺序量化矩阵所有行的所有权重。这使得该过程更快,因为某些计算只需对每列进行一次,而不是对每个权重进行一次。
步骤 2:惰性批量更新
这种方案速度不快,因为它需要更新一个巨大的矩阵,而每个块的计算量却很少。这种类型的操作无法充分利用 GPU 的计算能力,并且会因内存限制(内存吞吐量瓶颈)而变慢。
为了解决这个问题,GPTQ 引入了“惰性批量更新”。事实证明,列的最终量化仅受对该列更新的影响,而不会受后续列的影响。因此,GPTQ 可以一次将算法应用于一批列(例如 128 列),仅更新这些列和矩阵的相应块。在处理完一个块后,该算法会对整个矩阵执行全局更新。
步骤 3:Cholesky 重构
然而,还有一个问题需要解决。当算法扩展到非常大的模型时,数值不准确可能会成为一个问题。具体来说,重复应用某一操作可能会累积数值误差。
为了解决这个问题,GPTQ 使用了Cholesky 分解,这是一种解决某些数学问题的数值稳定方法。它涉及使用 Cholesky 方法从矩阵中预先计算一些所需信息。这种方法与轻微的“阻尼”(在矩阵的对角元素中添加一个小常数)相结合,有助于算法避免数值问题。
完整的算法可以概括为几个步骤:
GPTQ 算法首先对 Hessian 逆进行 Cholesky 分解(该矩阵有助于决定如何调整权重)
然后它循环运行,一次处理一批列。
对于批次中的每一列,它量化权重,计算误差,并相应地更新块中的权重。
处理批次后,它会根据块的错误更新所有剩余的权重。
使用 AutoGPTQ 库实现 GPTQ 算法并量化 GPT-2 模型
# 导入随机数模块
import random# 导入AutoGPTQ库中的类,用于量化模型
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig# 导入load_dataset函数,用于加载数据集
from datasets import load_dataset# 导入PyTorch库
import torch# 导入transformers库中的AutoTokenizer,用于文本编码
from transformers import AutoTokenizer# 定义基础模型名称和量化后模型的输出目录
model_id = "gpt2" # 使用gpt2作为基础模型
out_dir = model_id + "-GPTQ" # 输出目录为模型ID加上"-GPTQ"# 加载量化配置、模型和分词器
# 量化配置设置:4位量化,组大小为128,阻尼百分比为0.01,不使用激活函数量化
quantize_config = BaseQuantizeConfig(bits=4,group_size=128,damp_percent=0.01,desc_act=False,
)
# 从预训练模型加载并应用量化配置
model = AutoGPTQForCausalLM.from_pretrained(model_id, quantize_config)
# 加载与模型匹配的分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)# 加载数据并进行分词处理
# 使用allenai的c4数据集,限制加载的数据文件和数据条数
n_samples = 1024
data = load_dataset("allenai/c4", data_files="en/c4-train.00001-of-01024.json.gz", split=f"train[:{n_samples*5}]")
# 将文本数据连接并使用分词器进行编码
tokenized_data = tokenizer("\n\n".join(data['text']), return_tensors='pt')# 格式化分词后的样本
# 初始化一个空列表来存储格式化后的样本
examples_ids = []
# 遍历以创建n_samples个样本
for _ in range(n_samples):# 随机选择起始索引,确保序列长度不超过模型最大长度i = random.randint(0, tokenized_data.input_ids.shape[1] - tokenizer.model_max_length - 1)j = i + tokenizer.model_max_length # 计算结束索引# 提取输入ID和创建相应的注意力掩码input_ids = tokenized_data.input_ids[:, i:j]attention_mask = torch.ones_like(input_ids) # 注意力掩码全为1,表示所有token都需要被模型注意# 将输入ID和注意力掩码添加到样本列表中examples_ids.append({'input_ids': input_ids, 'attention_mask': attention_mask})# 计时开始
%%time# 使用GPTQ进行量化
# 使用前面准备的样本、指定的batch_size和启用Triton优化进行量化
model.quantize(examples_ids,batch_size=1,use_triton=True,
)# 保存量化后的模型和分词器到指定目录
# 使用safetensors格式保存模型权重,该格式更安全且更易于分享
model.save_quantized(out_dir, use_safetensors=True)
tokenizer.save_pretrained(out_dir) # 保存分词器到同一目录以便之后使用
量化后的效果
# 定义基础模型名称和量化后模型的输出目录
model_id = "gpt2" # 使用gpt2作为基础模型
out_dir = model_id + "-GPTQ" # 输出目录为模型ID加上"-GPTQ"# 设定设备为CUDA(如果可用)否则使用CPU
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# 这行代码检查是否有GPU可以使用,如果有,则在GPU上运行后续的模型操作,否则在CPU上运行。# 重新加载模型和分词器
model = AutoGPTQForCausalLM.from_quantized(out_dir, # 指定之前保存的量化模型目录device=device, # 使用之前设定的设备use_triton=True, # 启用Triton加速(如果安装并配置了Triton推理服务器)use_safetensors=True, # 指定使用safetensors格式加载模型权重
)
# 从量化模型的保存目录加载分词器
tokenizer = AutoTokenizer.from_pretrained(out_dir)# 导入transformers库中的pipeline功能
from transformers import pipeline# 创建一个文本生成的pipeline,使用刚加载的模型和分词器
generator = pipeline('text-generation', model=model, tokenizer=tokenizer)# 使用pipeline生成文本,输入为"I have a dream",开启采样以增加多样性,限制生成的最大长度为50
result = generator("I have a dream ", do_sample=True, max_length=50)[0]['generated_text']# 打印生成的文本结果
print(result)
相关文章:

GPTQ 量化大模型
GPTQ 量化大模型 GPTQ 算法 GPTQ 算法由 Frantar 等人 (2023) 提出,它从 OBQ 方法中汲取灵感,但进行了重大改进,可以将其扩展到(非常)大型的语言模型。 步骤 1:任意顺序量化 OBQ 方法选择权重按特定顺序…...

【GD32】05 - PWM 脉冲宽度调制
PWM PWM (Pulse Width Modulation) 是一种模拟信号电平的方法,它通过使用数字信号(通常是方波)来近似地表示模拟信号。在PWM中,信号的占空比(即高电平时间占整个周期的比例)被用来控制平均输出电压或电流。…...

JVM思维导图
帮助我们快速整理和总结JVM相关知识,有结构化认识和整体的思维模型 JVM相关详细知识和面试题...

Ollama+OpenWebUI+Phi3本地大模型入门
文章目录 Ollama+OpenWebUI+Phi3本地大模型入门一、基础环境二、Ollama三、OpenWebUI + Phi3Ollama+OpenWebUI+Phi3本地大模型入门 完全不懂大模型的请绕道,相信我李一舟的课程比较适合 Ollama提供大模型运行环境,OpenWebUI提供UI,Phi3就是那个大模型。 当然,Ollama支持超级…...
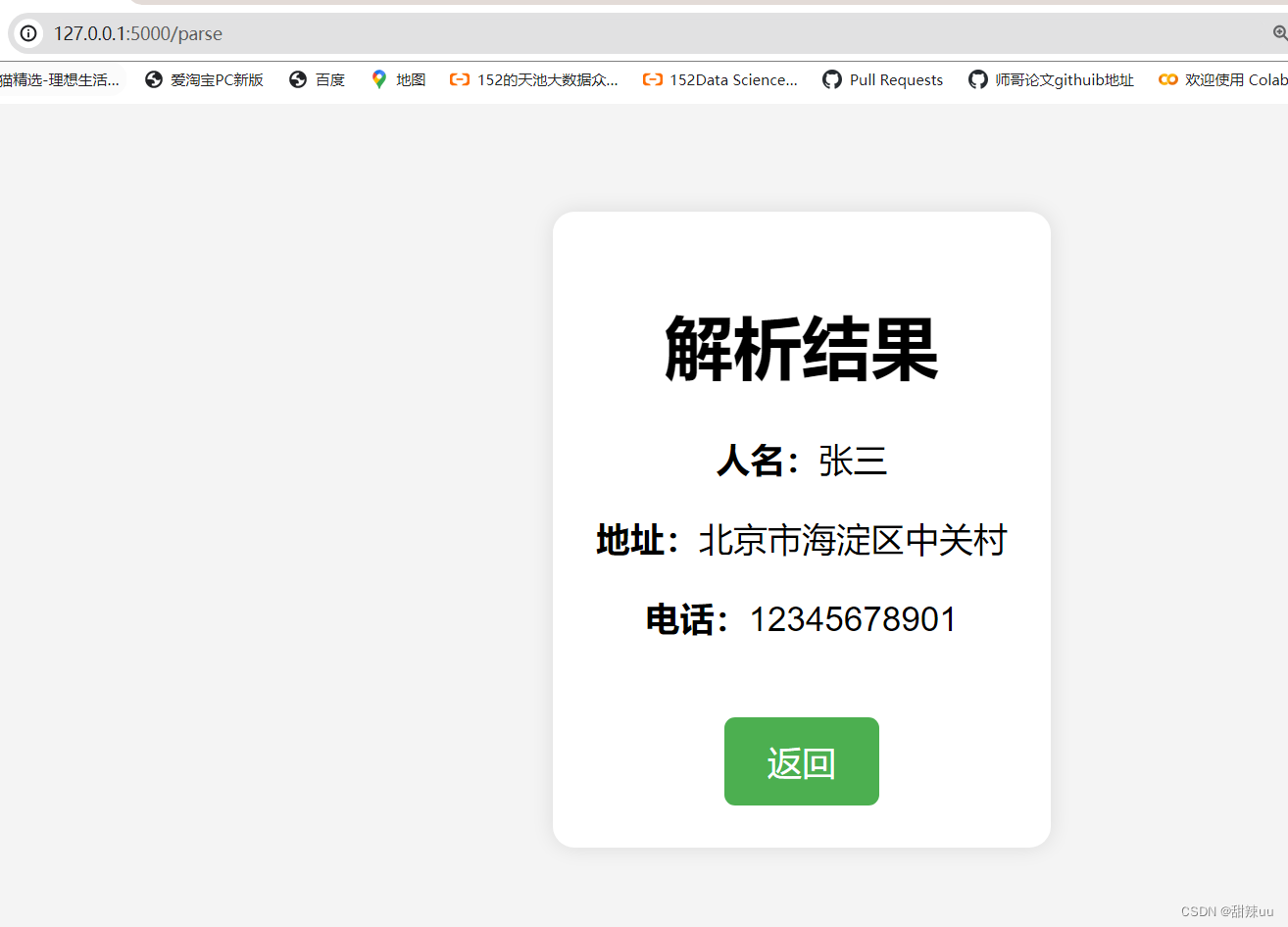
实战15:bert 命名实体识别、地址解析、人名电话地址抽取系统-完整代码数据
直接看项目视频演示: bert 命名实体识别、关系抽取、人物抽取、地址解析、人名电话地址提取系统-完整代码数据_哔哩哔哩_bilibili 项目演示: 代码: import re from transformers import BertTokenizer, BertForTokenClassification, pipeline import os import torch im…...

js 表格添加|删除一行交互
一、需求 二、实现 <div style"margin-bottom: 55px"><form action"" method"post" enctype"multipart/form-data" id"reportForm" name"sjf" style"margin-left: 25px;margin-bottom: 50px;&quo…...

如何选择合适的服务器硬件和配置?
业务需求 了解您的业务需求和负载。这将帮助您确定需要哪种类型的服务器(如文件服务器、数据库服务器、Web服务器等)以及所需的处理能力、内存、存储和网络性能。...
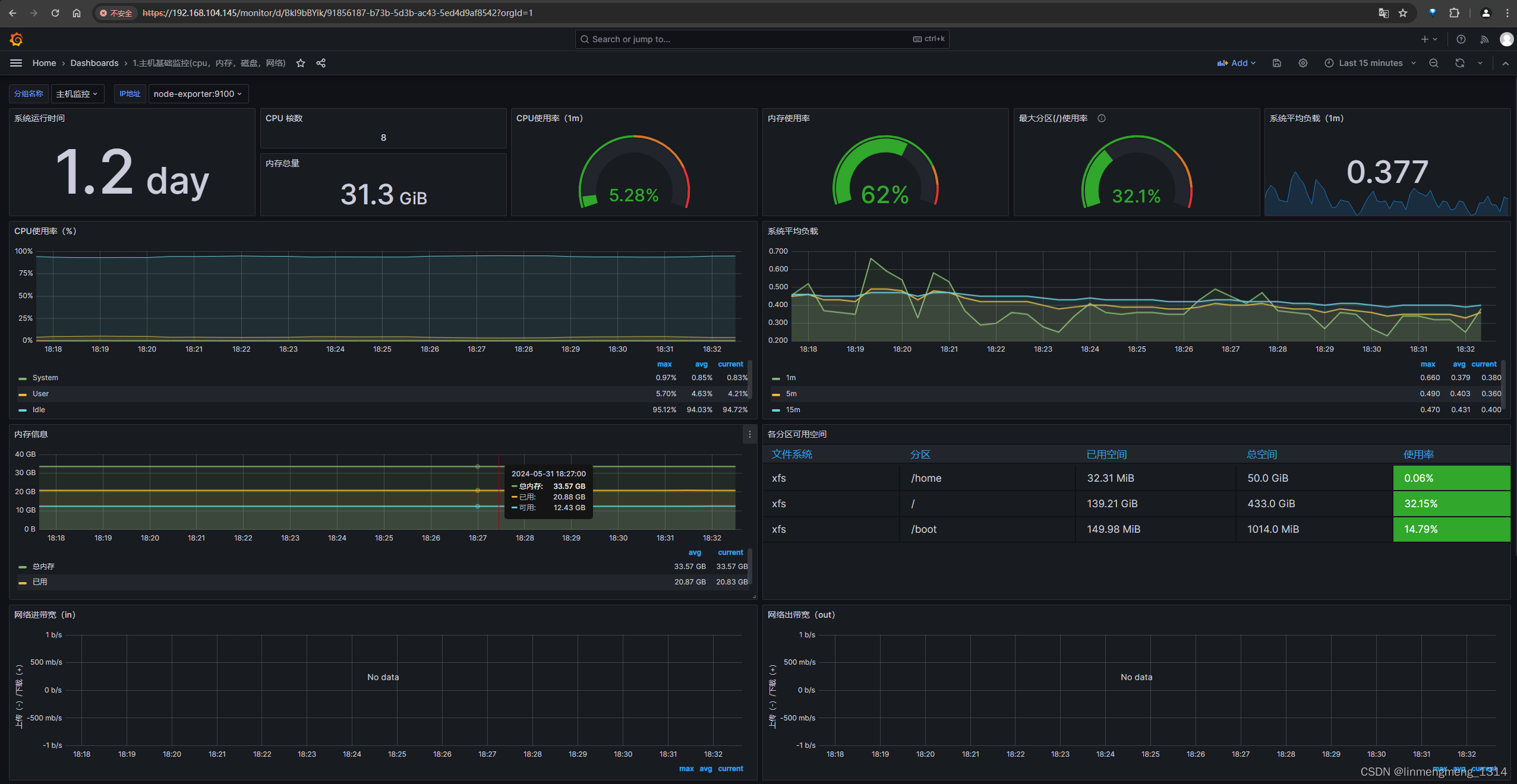
Prometheus + Grafana + Alertmanager 系统监控
PrometheusGrafana 系统监控 1. 简介1.1 Prometheus 普罗 米修斯1.2 Grafana 2. 快速试用2.1 Prometheus 普罗 米修斯2.2 Prometheus 配置文件2.3 Grafana 2. 使用 Docker-Compose脚本部署监控服务3. Grafana 配置3.1 配置数据源 Prometheus3.2 使用模板ID 配置监控模板3.3 使用…...

5.23R语言-参数假设检验
理论 方差分析(ANOVA, Analysis of Variance)是统计学中用来比较多个样本均值之间差异的一种方法。它通过将总变异分解为不同来源的变异来检测因子对响应变量的影响。方差分析广泛应用于实验设计、质量控制、医学研究等领域。 方差分析的基本模型 方差…...

rnn 和lstm源码学习笔记
目录 rnn学习笔记 lstm学习笔记 rnn学习笔记 import torchdef rnn(inputs, state, params):# inputs的形状: (时间步数量, 批次大小, 词表大小)W_xh, W_hh, b_h, W_hq, b_q paramsH stateoutputs []# 遍历每个时间步for X in inputs:# 计算隐藏状态 HH torch.tanh(torch.…...

解析Java中1000个常用类:CharSequence类,你学会了吗?
在 Java 编程中,字符串操作是最常见的任务之一。为了提供一种灵活且统一的方式来处理不同类型的字符序列,Java 引入了 CharSequence 接口。 通过实现 CharSequence 接口,各种字符序列类可以提供一致的 API,增强了代码的灵活性和可扩展性。 本文将深入探讨 CharSequence 接…...

微服务远程调用之拦截器实战
微服务远程调用之拦截器实战 前言: 在我们开发过程中,很可能是项目是从0到1开发,或者在原有基础上做二次开发,这次是根据已有代码做二次开发,需要在我们微服务一【这里方便举例,我们后面叫模版微服务】调用…...

德人合科技——天锐绿盾内网安全管理软件 | -文档透明加密模块
天锐绿盾文档加密功能能够为各种模式的电子文档提供高强度加密保护,丰富的权限控制以及灵活的应用管理,帮助企业构建更严密的立体保密体系。 PC地址: https://isite.baidu.com/site/wjz012xr/2eae091d-1b97-4276-90bc-6757c5dfedee ————…...
超融合架构下,虚拟机高可用机制如何构建?
作者:SmartX 产品部 钟锦锌 虚拟机高可用(High Availability,简称 HA)是虚拟化/超融合平台最常用、关键的功能之一,可在服务器发生故障时通过重建业务虚拟机以降低故障对业务带来的影响。因此,为了充分保障…...
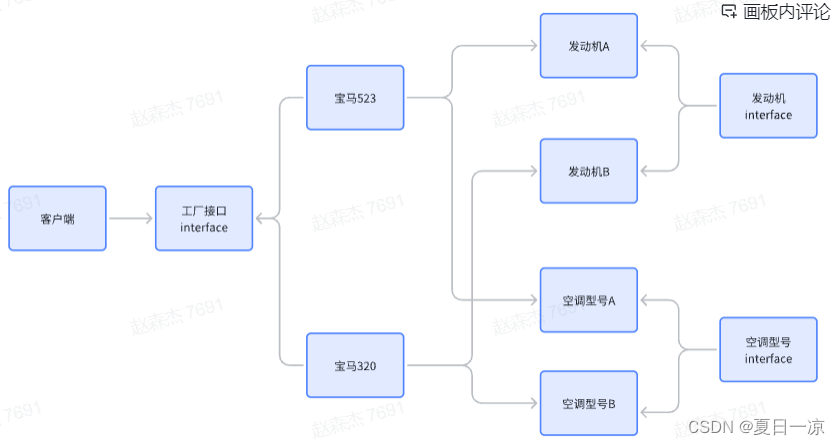
工厂模式详情
一.介绍工厂模式的用途与特点 工厂方法模式是一种创建型设计模式, 其在父类中提供一个创建对象的方法, 允许子类决定实例化对象的类型。定义工厂方法模式(Fatory Method Pattern)是指定义一个创建对象的接口,但让实现这个接口的类来决定实例…...
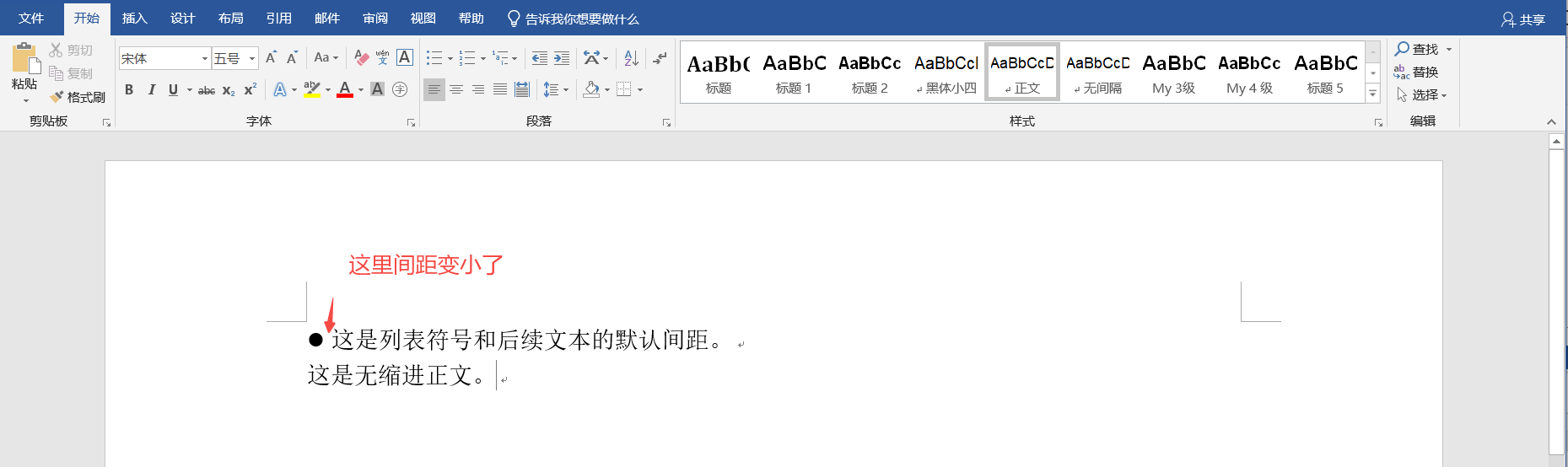
【Word】调整列表符号与后续文本的间距
1. 默认的列表格式: 2. 修改间距: ************************************************** 分割线 ************************************************************ 3. 效果...
匠心独运,B 端系统 UI 演绎华章之美
匠心独运,B 端系统 UI 演绎华章之美...
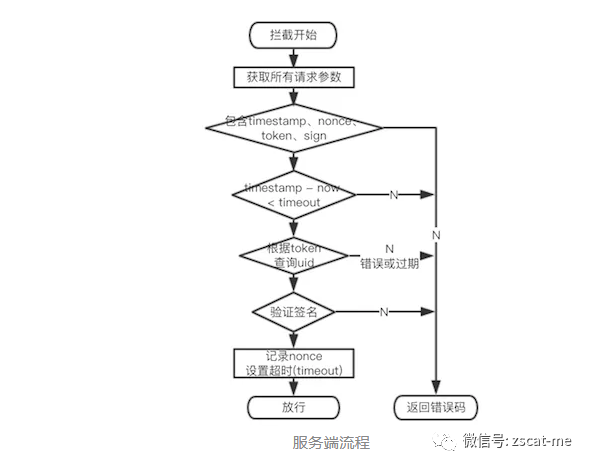
Java电商平台-开放API接口签名验证(小程序/APP)
说明:在实际的生鲜业务中,不可避免的需要对外提供api接口给外部进行调用. 这里就有一个接口安全的问题需要沟通了。下面是干货: 接口安全问题 请求身份是否合法? 请求参数是否被篡改? 请求是否唯一? AccessKey&am…...

Tale全局函数对象base
目录 1、 Tale全局函数对象base 1.1、 * tale alert删除 1.2、 * 成功弹框 1.3、 * 弹出成功,并在500毫秒后刷新页面 1.4、 * 警告弹框 1.5、 * 询问确认弹框,这里会传入then函数进来...
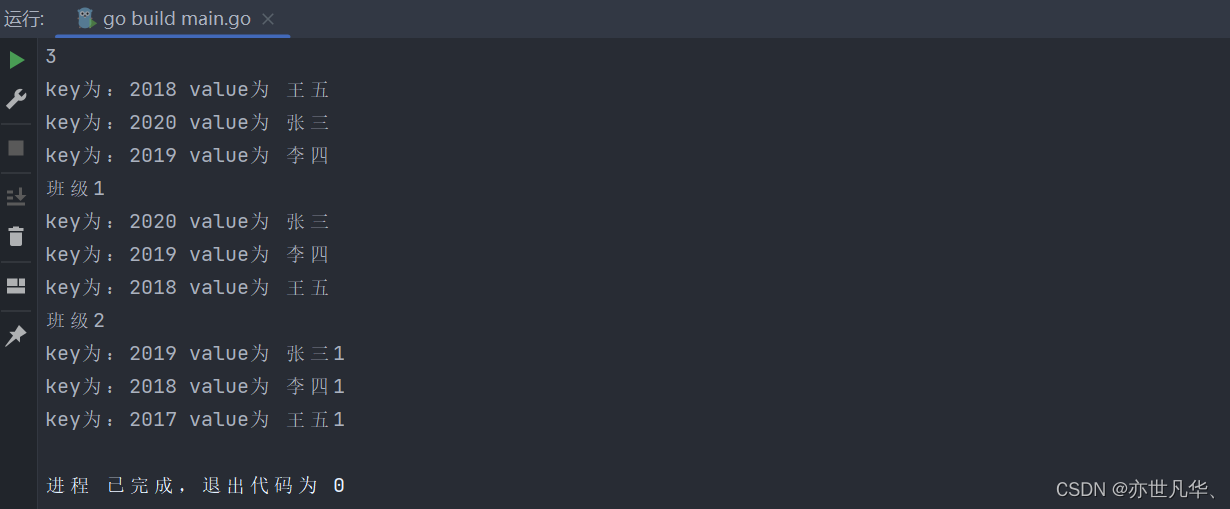
【启程Golang之旅】掌握Go语言数组基础概念与实际应用
欢迎来到Golang的世界!在当今快节奏的软件开发领域,选择一种高效、简洁的编程语言至关重要。而在这方面,Golang(又称Go)无疑是一个备受瞩目的选择。在本文中,带领您探索Golang的世界,一步步地了…...

杰理701N可视化SDK:从stream.bin生成到工程导入的EQ调音闭环
1. 杰理701N可视化SDK与EQ调音基础 第一次接触杰理701N的开发者可能会好奇,这个可视化SDK到底能做什么?简单来说,它就像给声学工程师配了一把"声音雕刻刀"。通过图形化界面,你可以实时调整蓝牙耳机、音箱等设备的音效表…...

Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程
Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾因为Adobe Creative Cloud高昂的订阅…...

网盘下载新革命:九大平台一键直链,告别客户端束缚
网盘下载新革命:九大平台一键直链,告别客户端束缚 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

5大优势解析:如何高效使用免费离线OCR工具
5大优势解析:如何高效使用免费离线OCR工具 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 项目…...
)
别再点‘忽略’了!开机弹出Visual C++ Runtime Library错误的终极排查指南(附Adobe软件关联排查)
Visual C Runtime Library错误:从崩溃到根治的全链路解决方案 每次开机时那个刺眼的Visual C Runtime Library错误弹窗,就像一位不请自来的访客,固执地打断你的工作节奏。对于依赖Adobe Creative Cloud或达芬奇等创意工具的专业人士来说&…...

Gitclaw:封装复杂Git操作,提升开发效率的命令行工具
1. 项目概述:一个为Git操作注入“爪牙”的命令行工具如果你和我一样,日常开发工作重度依赖Git,那你肯定也经历过这样的时刻:面对一个需要多步操作才能完成的复杂Git任务,比如清理多个已合并的分支、批量重写提交历史中…...
)
【Midjourney数字艺术风格终极指南】:20年AI视觉专家亲授7大核心风格参数调优法则(含V6.1新增Realism Mode实测数据)
更多请点击: https://intelliparadigm.com 第一章:Midjourney数字艺术风格演进与V6.1核心变革 Midjourney自V1发布以来,其图像生成范式经历了从纹理模拟到语义理解、从风格模仿到跨模态协同的深层跃迁。V6.1标志着模型首次在原生架构中集成…...

Faderwave合成器设计:从波形塑造到数字滤波的嵌入式音频实践
1. 项目概述:从推子到声音,Faderwave合成器的设计哲学如果你玩过硬件合成器,或者对数字音频合成感兴趣,那你肯定知道,声音设计的起点往往是一个简单的波形。但如何让这个波形“活”起来,变成你脑海中那个独…...

手把手教你用SystemVerilog Interface搭建一个可复用的DMA寄存器验证环境
基于SystemVerilog Interface构建模块化DMA验证环境的工程实践 在数字IC验证领域,DMA(直接内存访问)控制器作为关键IP核,其寄存器验证环境的搭建效率直接影响项目进度。传统验证方法中信号连接冗长、时序控制分散的问题ÿ…...

Git Worktree CLI工具:告别分支切换焦虑,实现高效并行开发
1. 项目概述与核心价值如果你和我一样,长期在多个Git分支间穿梭,同时维护着几个不同的功能特性或修复补丁,那你一定对那种在分支间反复切换、代码状态混乱、甚至不小心提交到错误分支的“切分支焦虑症”深有体会。传统的git checkout或git sw…...