SpringBoot如何缓存方法返回值?
Why?
为什么要对方法的返回值进行缓存呢?
简单来说是为了提升后端程序的性能和提高前端程序的访问速度。减小对db和后端应用程序的压力。
一般而言,缓存的内容都是不经常变化的,或者轻微变化对于前端应用程序是可以容忍的。
否则,不建议加入缓存,因为增加缓存会使程序复杂度增加,还会出现一些其他的问题,比如缓存同步,数据一致性,更甚者,可能出现经典的缓存穿透、缓存击穿、缓存雪崩问题。
HowDo
如何缓存方法的返回值?应该会有很多的办法,本文简单描述两个比较常见并且比较容易实现的办法:
- 自定义注解
- SpringCache
annotation
整体思路:
第一步:定义一个自定义注解,在需要缓存的方法上面添加此注解,当调用该方法的时候,方法返回值将被缓存起来,下次再调用的时候将不会进入该方法。其中需要指定一个缓存键用来区分不同的调用,建议为:类名+方法名+参数名
第二步:编写该注解的切面,根据缓存键查询缓存池,若池中已经存在则直接返回不执行方法;若不存在,将执行方法,并在方法执行完毕写入缓冲池中。方法如果抛异常了,将不会创建缓存
第三步:缓存池,首先需要尽量保证缓存池是线程安全的,当然了没有绝对的线程安全。其次为了不发生缓存臃肿的问题,可以提供缓存释放的能力。另外,缓存池应该设计为可替代,比如可以丝滑得在使用程序内存和使用redis直接调整。
MethodCache
创建一个名为MethodCache 的自定义注解
package com.ramble.methodcache.annotation;
import java.lang.annotation.*;@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD})
public @interface MethodCache {}MethodCacheAspect
编写MethodCache注解的切面实现
package com.ramble.methodcache.annotation;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
import java.util.Arrays;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;@Slf4j
@Aspect
@Component
public class MethodCacheAspect {private static final Map<String, Object> CACHE_MAP = new ConcurrentHashMap<>();@Around(value = "@annotation(methodCache)")public Object around(ProceedingJoinPoint jp, MethodCache methodCache) throws Throwable {String className = jp.getSignature().getDeclaringType().getSimpleName();String methodName = jp.getSignature().getName();String args = String.join(",", Arrays.toString(jp.getArgs()));String key = className + ":" + methodName + ":" + args;// key 示例:DemoController:findUser:[FindUserParam(id=1, name=c7)]log.debug("缓存的key={}", key);Object cache = getCache(key);if (null != cache) {log.debug("走缓存");return cache;} else {log.debug("不走缓存");Object value = jp.proceed();setCache(key, value);return value;}}private Object getCache(String key) {return CACHE_MAP.get(key);}private void setCache(String key, Object value) {CACHE_MAP.put(key, value);}
}- Around:对被MethodCache注解修饰的方法启用环绕通知
- ProceedingJoinPoint:通过此对象获取方法所在类、方法名和参数,用来组装缓存key
- CACHE_MAP:缓存池,生产环境建议使用redis等可以分布式存储的容器,直接放程序内存不利于后期业务扩张后多实例部署
controller
package com.ramble.methodcache.controller;
import com.ramble.methodcache.annotation.MethodCache;
import com.ramble.methodcache.controller.param.CreateUserParam;
import com.ramble.methodcache.controller.param.FindUserParam;
import com.ramble.methodcache.service.DemoService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.*;@Tag(name = "demo - api")
@Slf4j
@RequiredArgsConstructor
@RestController
@RequestMapping("/demo")
public class DemoController {private final DemoService demoService;@MethodCache@GetMapping("/{id}")public String getUser(@PathVariable("id") String id) {return demoService.getUser(id);}@Operation(summary = "查询用户")@MethodCache@PostMapping("/list")public String findUser(@RequestBody FindUserParam param) {return demoService.findUser(param);}
}通过反复调用被@MethodCache注解修饰的方法,会发现若缓存池有数据,将不会进入方法体。
SpringCache
其实SpringCache的实现思路和上述方法基本一致,SpringCache提供了更优雅的编程方式,更丝滑的缓存池切换和管理,更强大的功能和统一规范。
EnableCaching
使用 @EnableCaching 开启SpringCache功能,无需引入额外的pom。
默认情况下,缓存池将由 ConcurrentMapCacheManager 这个对象管理,也就是默认是程序内存中缓存。其中用于存放缓存数据的是一个 ConcurrentHashMap,源码如下:
public class ConcurrentMapCacheManager implements CacheManager, BeanClassLoaderAware {private final ConcurrentMap<String, Cache> cacheMap = new ConcurrentHashMap(16);......}此外可选的缓存池管理对象还有:
-
EhCacheCacheManager
-
JCacheCacheManager
-
RedisCacheManager
-
......
Cacheable
package com.ramble.methodcache.controller;
import com.ramble.methodcache.controller.param.FindUserParam;
import com.ramble.methodcache.service.DemoService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.web.bind.annotation.*;@Tag(name = "user - api")
@Slf4j
@RequiredArgsConstructor
@RestController
@RequestMapping("/user")
public class UserController {private final DemoService demoService;@Cacheable(value = "userCache")@GetMapping("/{id}")public String getUser(@PathVariable("id") String id) {return demoService.getUser(id);}@Operation(summary = "查询用户")@Cacheable(value = "userCache")@PostMapping("/list")public String findUser(@RequestBody FindUserParam param) {return demoService.findUser(param);}
}- 使用@Cacheable注解修饰需要缓存返回值的方法
- value必填,不然运行时报异常。类似一个分组,将不同的数据或者方法(当然也可以其他维度,主要看业务需要)放到一堆,便于管理
- 可以修饰接口方法,但是不建议,IDEA会报一个提示Spring doesn't recommend to annotate interface methods with @Cache* annotation
常用属性:
- value:缓存名称
- cacheNames:缓存名称。value 和cacheNames都被AliasFor注解修饰,他们互为别名
- key:缓存数据时候的key,默认使用方法参数的值,可以使用SpEL生产key
- keyGenerator:key生产器。和key二选一
- cacheManager:缓存管理器
- cacheResolver:和caheManager二选一,互为别名
- condition:创建缓存的条件,可用SpEL表达式(如#id>0,表示当入参id大于0时候才缓存方法返回值)
- unless:不创建缓存的条件,如#result==null,表示方法返回值为null的时候不缓存
CachePut
用来更新缓存。被CachePut注解修饰的方法,在被调用的时候不会校验缓存池中是否已经存在缓存,会直接发起调用,然后将返回值放入缓存池中。
CacheEvict
用来删除缓存,会根据key来删除缓存中的数据。并且不会将本方法返回值缓存起来。
常用属性:
- value/cacheeName:缓存名称,或者说缓存分组
- key:缓存数据的键
- allEntries:是否根据缓存名称清空所有缓存,默认为false。当此值为true的时候,将根据cacheName清空缓存池中的数据,然后将新的返回值放入缓存
- beforeInvocation:是否在方法执行之前就清空缓存,默认为false
Caching
此注解用于在一个方法或者类上面,同时指定多个SpringCache相关注解。这个也是SpringCache的强大之处,可以自定义各种缓存创建、更新、删除的逻辑,应对复杂的业务场景。
属性:
- cacheable:指定@Cacheable注解
- put:指定@CachePut注解
- evict:指定@CacheEvict注解
源码:
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Caching {Cacheable[] cacheable() default {};CachePut[] put() default {};CacheEvict[] evict() default {};
}相当于就是注解里面套注解,用来完成复杂和多变的场景,这个设计相当的哇塞。
CacheConfig
放在类上面,那么类中所有方法都会被缓存
SpringCacheEnv
SpringCache内置了一些环境变量,可用于各个注解的属性中。
-
methodName:被修饰方法的方法名
-
method:被修饰方法的Method对象
-
target:被修饰方法所属的类对象的实例
-
targetClass:被修饰方法所属类对象
-
args:方法入参,是一个 object[] 数组
-
caches:这个对象其实就是ConcurrentMapCacheManager中的cacheMap,这个cacheMap呢就是一开头提到的ConcurrentHashMap,即缓存池。caches的使用场景尚不明了。
-
argumentName:方法的入参
-
result:方法执行的返回值
使用示例:
@Cacheable(value = "userCache", condition = "#result!=null",unless = "#result==null")
public String showEnv() { return "打印各个环境变量";}表示仅当方法返回值不为null的时候才缓存结果,这里通过result env 获取返回值。
另外,condition 和 unless 为互补关系,上述condition = "#result!=null"和unless = "#result==null"其实是一个意思。
@Cacheable(value = "userCache", key = "#name")
public String showEnv(String id, String name) {return "打印各个环境变量";
}表示使用方法入参作为该条缓存数据的key,若传入的name为gg,则实际缓存的数据为:gg->打印各个环境变量
另外,如果name为空会报异常,因为缓存key不允许为null
@Cacheable(value = "userCache",key = "#root.args")
public String showEnv(String id, String name) {return "打印各个环境变量";
}表示使用方法的入参作为缓存的key,若传递的参数为id=100,name=gg,则实际缓存的数据为:Object[]->打印各个环境变量,Object[]数组中包含两个值。
既然是数组,可以通过下标进行访问,root.args[1] 表示获取第二个参数,本例中即 取 name 的值 gg,则实际缓存的数据为:gg->打印各个环境变量。
@Cacheable(value = "userCache",key = "#root.targetClass")
public String showEnv(String id, String name) {return "打印各个环境变量";
}表示使用被修饰的方法所属的类作为缓存key,实际缓存的数据为:Class->打印各个环境变量,key为class对象,不是全限定名,全限定名是一个字符串,这里是class对象。
可是,不是很懂这样设计的应用场景是什么......
@Cacheable(value = "userCache",key = "#root.target")
public String showEnv(String id, String name) {return "打印各个环境变量";
}表示使用被修饰方法所属类的实例作为key,实际缓存的数据为:UserController->打印各个环境变量。
被修饰的方法就是在UserController中,调试的时候甚至可以获取到此实例注入的其它容器对象,如userService等。
可是,不是很懂这样设计的应用场景是什么......
@Cacheable(value = "userCache",key = "#root.method")
public String showEnv(String id, String name) {return "打印各个环境变量";
}表示使用Method对象作为缓存的key,是Method对象,不是字符串。
可是,不是很懂这样设计的应用场景是什么......
@Cacheable(value = "userCache",key = "#root.methodName")
public String showEnv(String id, String name) {return "打印各个环境变量";
}表示使用方法名作为缓存的key,就是一个字符串。
如何获取缓存的数据?
ConcurrentMapCacheManager的cacheMap是一个私有变量,所以没有办法可以打印缓存池中的数据,不过可以通过调试的方式进入对象内部查看。如下:
@Tag(name = "user - api")
@Slf4j
@RequiredArgsConstructor
@RestController
@RequestMapping("/user")
public class UserController {private final ConcurrentMapCacheManager cacheManager;/*** 只有调试才课可以查看缓存池中的数据*/@GetMapping("/cache")public void showCacheData() {//需要debug进入Collection<String> cacheNames = cacheManager.getCacheNames();}}总结:
虽然提供了很多的环境变量,但是大多都无法找到对应的使用场景,其实在实际开发中,最常见的就是key的生产,一般而言使用类名+方法名+参数值足矣。
相关文章:

SpringBoot如何缓存方法返回值?
Why? 为什么要对方法的返回值进行缓存呢? 简单来说是为了提升后端程序的性能和提高前端程序的访问速度。减小对db和后端应用程序的压力。 一般而言,缓存的内容都是不经常变化的,或者轻微变化对于前端应用程序是可以容忍的。 否…...

C#的web项目ASP.NET
添加实体类和控制器类 using System; using System.Collections.Generic; using System.Linq; using System.Web;namespace WebApplication1.Models {public class Company{public string companyCode { get; set; }public string companyName { get; set; }public string com…...

Spring MVC 源码分析之 DispatcherServlet#getHandlerAdapter 方法
前言: 前面我们分析了 Spring MVC 的工作流程源码,其核心是 DispatcherServlet#doDispatch 方法,我们前面分析了获取 Handler 的方法 DispatcherServlet#getHandler 方法,本篇我们重点分析一下获取当前请求的适配器 HandlerAdapt…...

假设检验学习笔记
1. 假设检验的基本概念 1.1. 原假设(零假设) 对总体的分布所作的假设用表示,并称为原假设或零假设 在总体分布类型已知的情况下,仅仅涉及总体分布中未知参数的统计假设,称为参数假设 在总体分布类型未知的情况下&#…...

vue3 watch学习
watch的侦听数据源类型 watch的第一个参数为侦听数据源,有4种"数据源": ref(包括计算属性) reactive(响应式对象) getter函数 多个数据源组成的数组。 //ref const xref(0)//单个ref watch(x,(newX)>{console.…...

推荐的Pytest插件
推荐的Pytest插件 Pytest的插件生态系统非常丰富,以下是一些特别推荐的Pytest插件: pytest-sugar 这个插件改进了Pytest的默认输出,添加了进度条,并立即显示失败的测试。它不需要额外配置,只需安装即可享受更漂亮、更…...
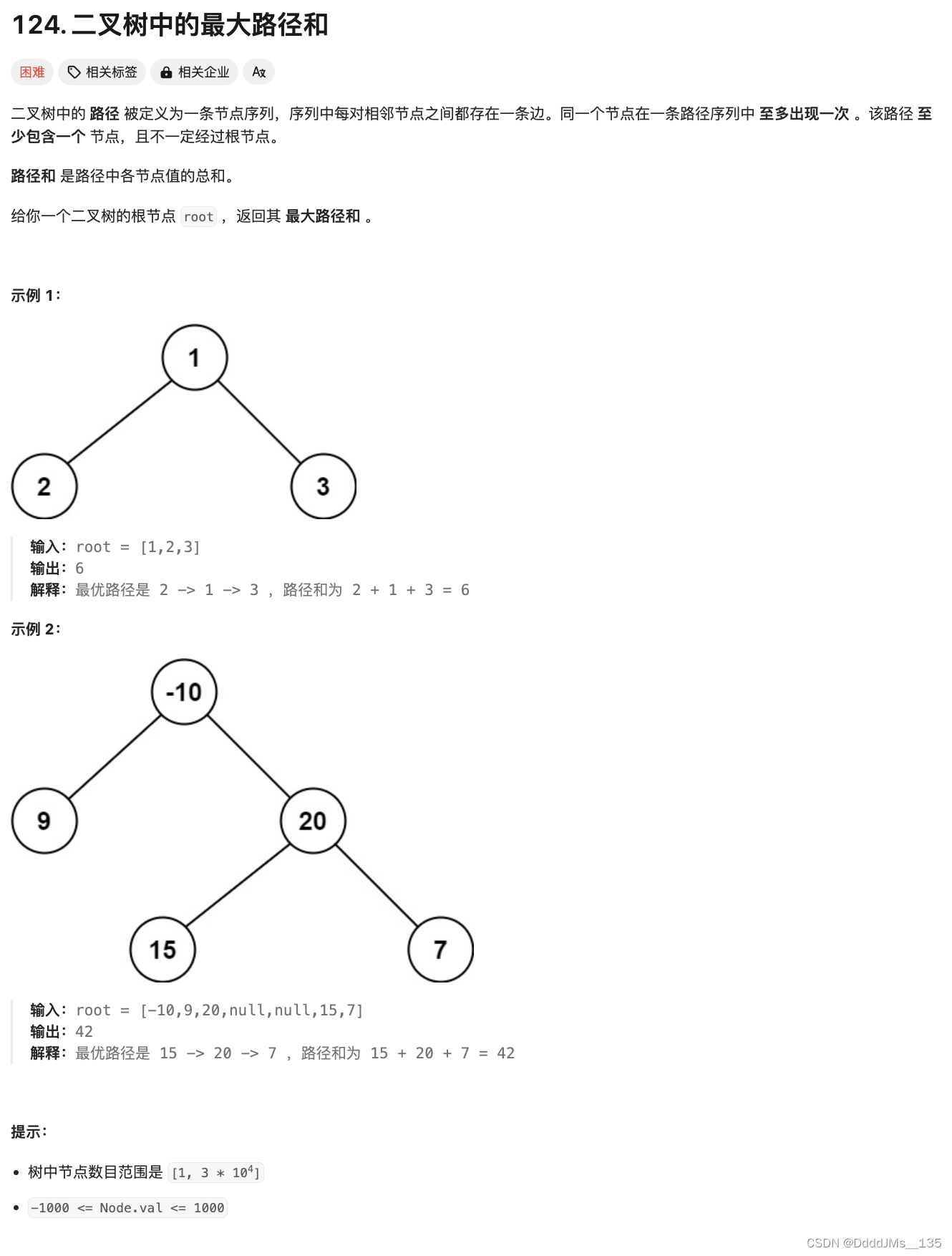
C语言 | Leetcode C语言题解之第124题二叉树中的最大路径和
题目: 题解: /*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/ int max; int dfs(struct TreeNode* root){if(!root) return 0;int left dfs(root->left…...

Linux综合实践(Ubuntu)
目录 一、配置任务 1.1 配置该服务器的软件源为中科大软件源 1.2 安装相关软件openssh-server和vim 1.3 设置双网卡,网卡1为NAT模式,网卡2为桥接模式(桥接模式下,使用静态ip,该网卡数据跟实验室主机网络设置相似,除…...

C++面试题其二
19. STL中unordered_map和map的区别 unordered_map 和 map 都是C标准库中的关联容器,但它们在实现和性能方面有显著区别: 底层实现:map 是基于红黑树实现的有序关联容器,而 unordered_map 是基于哈希表实现的无序关联容器。元素…...
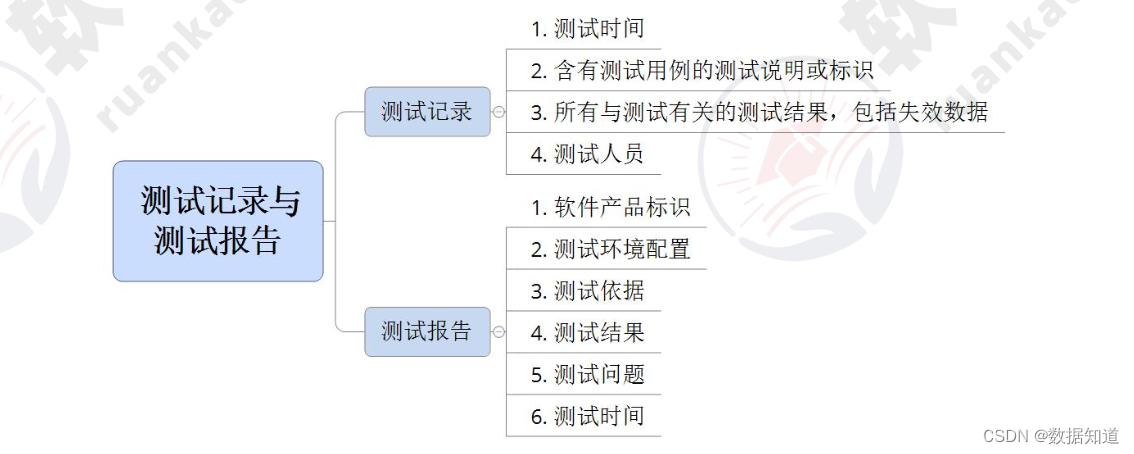
系统架构设计师【第9章】: 软件可靠性基础知识 (核心总结)
文章目录 9.1 软件可靠性基本概念9.1.1 软件可靠性定义9.1.2 软件可靠性的定量描述9.1.3 可靠性目标9.1.4 可靠性测试的意义9.1.5 广义的可靠性测试与狭义的可靠性测试 9.2 软件可靠性建模9.2.1 影响软件可靠性的因素9.2.2 软件可靠性的建模方法9.2.3 软件的可靠性模…...

x264 参考帧管理原理:i_poc_type 变量
x264 参考帧管理 x264 是一个开源的 H.264 视频编码软件,它提供了许多高级特性,包括对参考帧的高效管理。参考帧管理是视频编码中的一个重要部分,它涉及到如何存储、更新和使用已经编码的帧以提高编码效率。 x264 参考帧管理的一些关键点总结如下: 参考帧的初始化和重排序:…...

高级Web Lab2
高级Web Lab2 12 1 按照“Lab 2 基础学习文档”文档完成实验步骤 实验截图: 2 添加了Web3D场景选择按钮,可以选择目标课程或者学习房间。...
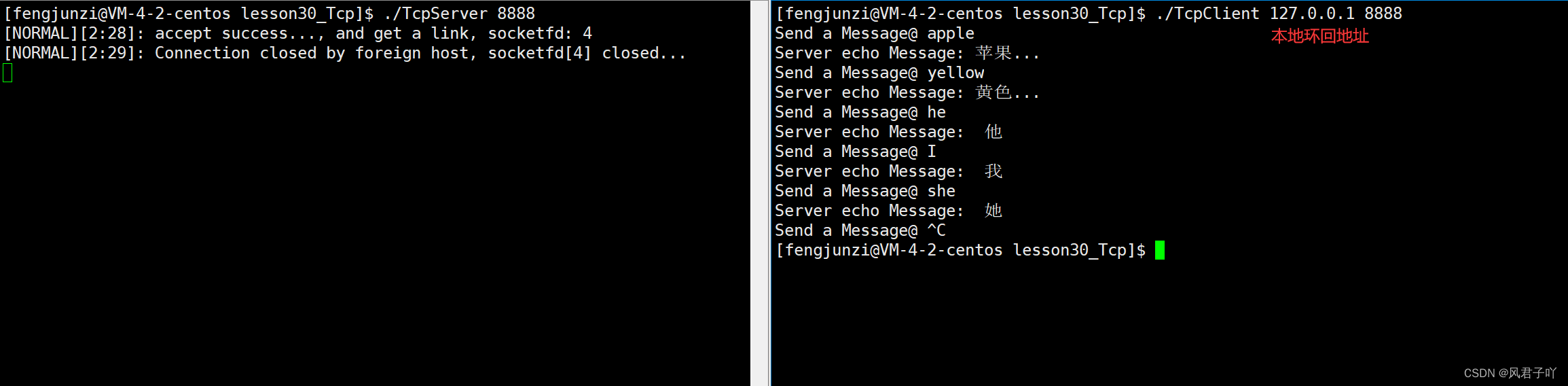
Linux网络-使用Tcp协议进行网络通信并通过网络接口实现远端翻译
文章目录 Tcp协议Tcp协议常见API接口1. int socket(int domain, int type, int protocol);2. int bind(int socket, const struct sockaddr *address, socklen_t address_len);struct sockaddr 3. int listen(int socket, int backlog);4. int accept(int socket, struct socka…...

实时数据传输:Django 与 MQTT 的完美结合
文章目录 准备工作创建 Django 项目与应用设置 MQTT 服务器编写 Django 视图编写前端模板发布 MQTT 消息运行 Django 项目 在当今互联网应用中,实时数据传输已经成为许多项目的核心需求。无论是社交媒体平台、在线游戏、金融交易还是物联网设备,都需要及…...

创建Django项目及应用
1 创建Project 1个Project可以对应多个app django-admin startproject myproject 2 创建App python manage.py startapp app01 INSTALLED_APPS [# ...app01,app02,# ... ] 如果要让这个应用在项目中起作用,需要在项目的 settings.py 文件的 INSTALLED_APPS 配置…...
)
Flutter课程分享 -(系统课程 基础 -> 进阶 -> 实战 仿京东商城)
前言 在移动应用开发的世界中,Flutter 作为一款由 Google 推出的开源 UI 软件开发工具包,正迅速赢得开发者们的青睐。其跨平台、高性能、丰富的组件库以及易于学习的特性,使得 Flutter 成为许多开发者的不二选择。然而,对于初学者…...

IDEA 中导入脚手架后该如何处理?
MySQL数据库创建啥的,没啥要说的!自行配置即可! 1.pom.xml文件,右键,add Maven Project …………(将其添加为Maven)【下述截图没有add Maven Project 是因为目前已经是Maven了!&…...

thinkphp6 queue队列的maxTries自定义
前景需求:在我们用队列的时候发现maxtries的个数时255次,这个太影响其他队列任务 我目前使用的thinkphp版本是6.1 第一部定义一个新的类 CustomDataBase(我用的mysql数据库存放的队列) 重写__make 和createPlainPayload方法 …...

【PHP项目实战训练】——laravel框架的实战项目中可以做模板的增删查改功能(2)
👨💻个人主页:开发者-曼亿点 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 曼亿点 原创 👨💻 收录于专栏:…...

Kotlin 对象
文章目录 对象表达式(匿名对象)对象的声明 对象表达式(匿名对象) 在 Kotlin 中可以使用object {}声明一个匿名的对象,我们无需声明这个对象的类: fun main() {val any object {fun greet() print("…...

30ms低延迟投屏终极指南:用QtScrcpy实现专业级手游直播
30ms低延迟投屏终极指南:用QtScrcpy实现专业级手游直播 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcpy…...

C++ mutable关键字深度解析:从const正确性到线程安全实践
1. 从一次线上调试的“诡异”现象说起 那天下午,我正盯着一个线上服务的监控面板,一个看似无关紧要的日志打印频率异常引起了我的注意。这是一个用C编写的多线程数据处理模块,其中有一个用于统计处理次数的成员变量,被声明为 con…...

基于NXP芯片的跳频技术如何构建高安全汽车无钥匙进入系统
1. 项目概述与核心价值最近几年,汽车的无钥匙进入与启动系统(PEPS)几乎成了新车的标配,但随之而来的安全挑战也日益严峻。你可能听说过,甚至亲身经历过,不法分子利用“中继攻击”设备,在车主不知…...

3步解锁任天堂控制器PC潜能:WiinUPro开源适配神器完全指南
3步解锁任天堂控制器PC潜能:WiinUPro开源适配神器完全指南 【免费下载链接】WiinUPro 项目地址: https://gitcode.com/gh_mirrors/wi/WiinUPro 还在为任天堂控制器无法在PC上使用而烦恼吗?WiinUPro开源项目为你解决这一难题!这是一款…...

[A2A协议与实现-01]借助A2A协议打破智能体孤岛
A2A协议是一个开放标准,它实现了Agent之间的无缝通信和协作。它为使用不同框架和由不同供应商构建的Agent提供了一种通用语言,从而促进了互操作性并打破了信息孤岛。A2A协议使得来自不同开发者、基于不同框架构建、并由不同组织拥有的Agent能够联合起来协…...

87456238
8637452...

终结摄像头依赖:深度拆解 RuView,用商品化 Wi-Fi 信号构建私密、实时的边缘空间智能
发布日期: 2026-02-15 标签: #无线感知 #WiFi感知 #边缘AI #CSI #生命体征监测 #空间智能 一、 引言 在智能家居、智慧医疗和工业安防的落地过程中,传统的“摄像头方案”始终面临着两大难以调和的工程痛点:隐私泄露的法律风险以…...

MATLAB集成大语言模型:架构设计与工程实践指南
1. 项目概述:当MATLAB遇见大语言模型如果你和我一样,是个长期泡在MATLAB环境里的工程师或研究员,面对这两年大语言模型(LLM)的狂潮,心里可能既兴奋又有点“隔岸观火”的疏离感。我们习惯了用MATLAB处理矩阵…...

ReID跨镜还在“找相似”,镜像视界无感定位已实现“定位置”
ReID跨镜还在“找相似”,镜像视界无感定位已实现“定位置”纵观当下视频跨镜追踪行业,技术路线早已形成鲜明代际差距。传统ReID行人重识别依旧固守视觉特征比对逻辑,全程停留在画面里反复“找相似”的浅层识别阶段;而依托国家十四…...
从零实现基础大语言模型:Transformer架构、训练流程与工程实践全解析
1. 项目概述:从零开始理解基础大语言模型最近在开源社区里,datawhalechina/base-llm这个项目标题引起了我的注意。乍一看,它像是一个预训练好的大语言模型(Large Language Model, LLM)的仓库,但深入探究后&…...