【机器学习】智能选择的艺术:决策树在机器学习中的深度剖析
在机器学习的分类和回归问题中,决策树是一种广泛使用的算法。决策树模型因其直观性、易于理解和实现,以及处理分类和数值特征的能力而备受欢迎。本文将解释决策树算法的概念、原理、应用、优化方法以及未来的发展方向。
🚀时空传送门
- 🔍什么是决策树算法
- 📕决策树算法原理
- 🌹决策树算法参数
- 🚆决策树算法的应用及代码示例
- 💖决策树算法的优化
- 🍀决策树算法的未来发展
🔍什么是决策树算法
决策树算法是一种监督学习算法,用于分类和回归问题。它采用树状结构表示决策过程,其中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶节点代表一个类别(分类问题)或值(回归问题)。决策树的主要优点是直观易懂、易于解释,并且不需要对数据进行复杂的预处理。
📕决策树算法原理

决策树算法通过递归地选择最优特征进行划分数据集,并生成相应的决策规则。常见的决策树算法有ID3、C4.5和CART等。这里以CART(分类与回归树)算法为例进行解释。
CART算法的核心是“基尼不纯度”(Gini Impurity)或“平方误差”(Squared Error)作为划分标准。对于分类问题,CART选择基尼不纯度最小的特征进行划分;对于回归问题,则选择平方误差最小的特征进行划分。
算法流程大致如下:
- 从根节点开始,选择最优特征进行划分。
- 对该特征的每个可能取值,将数据集划分为若干个子集,并创建相应的子节点。
- 对每个子节点递归地执行步骤1和2,直到满足停止条件(如子节点包含的样本数过少、所有样本属于同一类别等)。
- 生成决策树。
🌹决策树算法参数

在实际应用中,我们可能需要调整一些参数来优化模型的性能。以下是一些常用的参数:
- criterion: 划分准则,可以是’gini’(基尼指数)或’entropy’(信息增益)。
- max_depth: 决策树的最大深度。
- min_samples_split: 划分内部节点所需的最小样本数。
- min_samples_leaf: 叶节点所需的最小样本数。
- max_features: 考虑用于划分节点的最大特征数。
- random_state: 随机数生成器的种子,用于控制特征的随机选择。
通过调整这些参数,我们可以控制决策树的复杂性和泛化能力,从而优化模型的性能。
🚆决策树算法的应用及代码示例

🚗医疗诊断中的应用
在医疗诊断中,决策树算法可以用于辅助医生根据患者的症状和体征进行疾病的分类和预测。例如,医生可以使用包含患者年龄、性别、病史、症状等特征的数据集来训练一个决策树模型,然后使用该模型对新患者的疾病进行分类预测。
以鸢尾花数据集(Iris dataset)为例,使用scikit-learn库中的决策树分类器:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score # 加载数据
iris = load_iris()
X = iris.data
y = iris.target # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 创建决策树分类器
clf = DecisionTreeClassifier() # 训练模型
clf.fit(X_train, y_train) # 预测测试集
y_pred = clf.predict(X_test) # 计算准确率
print("Accuracy:", accuracy_score(y_test, y_pred))
🚲回归问题
以波士顿房价数据集(Boston Housing dataset)为例,使用scikit-learn库中的决策树回归器:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error # 加载数据
boston = load_boston()
X = boston.data
y = boston.target # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 创建决策树回归器
reg = DecisionTreeRegressor() # 训练模型
reg.fit(X_train, y_train) # 预测测试集
y_pred = reg.predict(X_test) # 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
💴金融风险评估中的应用

在金融风险评估中,决策树算法可以帮助银行、保险公司等金融机构根据客户的信用历史、收入、负债等信息评估其信用风险等级。通过构建决策树模型,金融机构可以更加准确地预测客户的违约概率,从而制定更加合理的贷款政策或保险费率。
示例代码(使用scikit-learn库)
假设我们有一个包含客户信用信息和信用风险等级的数据集financial_risk_data.csv,其中包含了客户的年龄、收入、负债、信用历史等特征以及信用风险等级标签。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report # 加载数据
data = pd.read_csv('financial_risk_data.csv')
X = data.drop('RiskLevel', axis=1) # 特征
y = data['RiskLevel'] # 标签 # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 创建决策树分类器
clf = DecisionTreeClassifier(random_state=42) # 训练模型
clf.fit(X_train, y_train) # 预测测试集
y_pred = clf.predict(X_test) # 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}") # 计算分类报告
report = classification_report(y_test, y_pred)
print(f"Classification Report:\n{report}") # 导出模型以便使用
# 例如,可以将模型保存为PMML或pickle文件
# import pickle
# with open('financial_risk_model.pkl', 'wb') as f:
# pickle.dump(clf, f)
💖决策树算法的优化
虽然决策树算法简单有效,但仍然存在一些局限性,如过拟合、对噪声数据敏感等。为了克服这些问题,可以采取以下优化方法:
- 预剪枝(Pre-pruning):在决策树生成过程中,提前停止树的生长,防止过拟合。
- 后剪枝(Post-pruning):先生成完整的决策树,然后自底向上进行剪枝,去除不必要的子树。
- 特征选择:使用更合适的特征选择方法,如基于信息增益、增益比或基尼指数等进行特征选择。
- 集成方法:如随机森林(Random Forests)和梯度提升决策树(Gradient Boosting Decision Trees),通过集成多个决策树来提高模型的性能。
🍀决策树算法的未来发展

随着数据量的不断增长和计算能力的提升,决策树算法将继续发展并在更多领域得到应用。未来的研究方向可能包括:
- 与深度学习结合:将决策树与深度学习技术相结合,构建更加复杂和强大的模型。
- 可解释性增强:在保持模型性能的同时,提高模型的可解释性,使其更加适用于需要高解释性的领域。
- 处理大规模数据:优化算法以适应大规模数据集的训练和推理,提高计算效率。
总之,决策树算法作为一种简单而有效的机器学习算法,将在未来的发展中继续发挥重要作用。
相关文章:
【机器学习】智能选择的艺术:决策树在机器学习中的深度剖析
在机器学习的分类和回归问题中,决策树是一种广泛使用的算法。决策树模型因其直观性、易于理解和实现,以及处理分类和数值特征的能力而备受欢迎。本文将解释决策树算法的概念、原理、应用、优化方法以及未来的发展方向。 🚀时空传送门 &#x…...
电脑缺少运行库,无法启动程序
在我们使用一些软件的时候,由于电脑缺少一些运行库,导致无法启动应用软件,此时需要我们安装缺少的运行库。 比如当电脑提示: Cannot load library Qt5Xlsx.dll 我们就需要下载C得运行库,以满足软件运行需要。 下载链…...

【计算机软考_初级篇】每日十题2
各位老师大家好,软考对于日常的知识储备和企业中的考试,或者说在校大学生来说,那用处是非常大的!!那么下面我们进入正题,软考呢是分两种语言,java和C,对于其他语言目前还没ÿ…...
HR人才测评,如何做营销人员岗位素质测评?
营销人员是企业中的重要角色,他们直接负责企业产品或服务的销售和推广,是企业中最直接影响销售业绩的人才之一。因此,营销人员的基本素质测评非常重要,能够有效评估营销人员的能力和潜力,为企业招聘和培养优秀的营销人…...
LabVIEW调用第三方硬件DLL常见问题及开发流程
在LabVIEW中调用第三方硬件DLL时,除了技术问题,还涉及开发流程、资料获取及与厂家的沟通协调。常见问题包括函数接口不兼容、数据类型转换错误、内存管理问题、线程安全性等。解决这些问题需确保函数声明准确、数据类型匹配、正确的内存管理及线程保护。…...

datax实现MySQL数据库迁移shell自动化脚本
datax实现MySQL数据库迁移 (1)生成python脚本 # codingutf-8 import json import getopt import os import sys import MySQLdb#MySQL相关配置,需根据实际情况作出修改 mysql_host "xxxx" mysql_port "3306" mysql_u…...
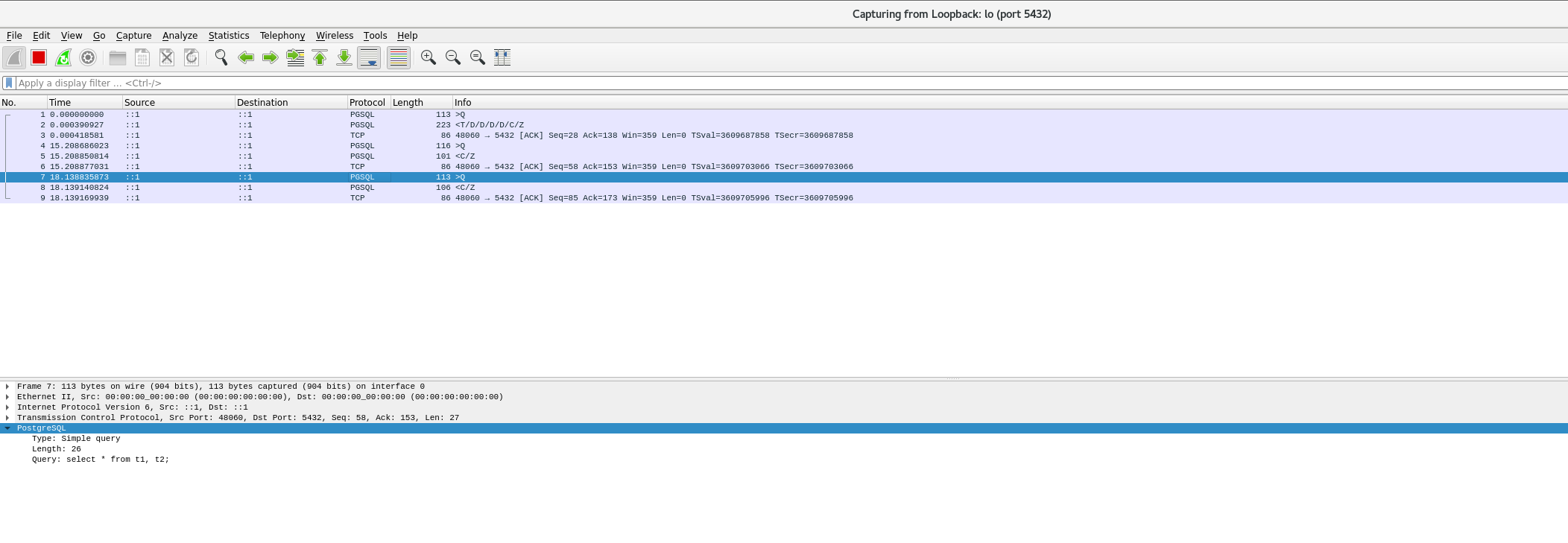
PostgreSQL的学习心得和知识总结(一百四十四)|深入理解PostgreSQL数据库之sendTuples的实现原理及功能修改
目录结构 注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下: 1、参考书籍:《PostgreSQL数据库内核分析》 2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》 3、PostgreSQL数据库仓库…...

C++数据结构之:链List
摘要: it人员无论是使用哪种高级语言开发东东,想要更高效有层次的开发程序的话都躲不开三件套:数据结构,算法和设计模式。数据结构是相互之间存在一种或多种特定关系的数据元素的集合,即带“结构”的数据元素的集合&am…...

10.Redis之set类型
谈到一个术语,这个术语很可能有多种含义~~ 1.Set 1) 集合. 2)设置 (和 get 相对应) 集合就是把一些有关联的数据放到一起~~ 1.集合中的元素是无序的! 【此处说的无序和 前面list这里的有序 是对应的, 有序: 顺序很重要. 变换一下顺序, 就是不同的 list 了 无序: 顺序不…...

SpringBoot + mongodb 删除集合中的数据
MongoTemplate是Spring Data MongoDB提供的一个工具类,用于与MongoDB进行交互。它提供了许多方法来执行数据库操作,包括删除数据。 本文将介绍如何使用Java MongoTemplate删除集合内的数据,并提供相应的代码示例。 1. 引入MongoTemplate 首…...

【日常记录】【JS】前端预览图片的两种方式,Base64预览和blob预览
文章目录 1、前言1、FileReader3、window.URL.createObjectURL4、参考链接 1、前言 一般来说,都是 后端返回给前端图片的url,前端直接把这个值插入到 img 的src 里面即可还有一种情况是前端需要预览一下图片,比如:上传头像按钮&a…...
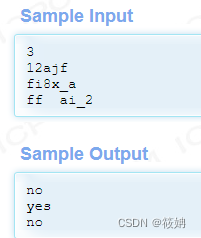
每日刷题——杭电2156.分数矩阵和杭电2024.C语言合法标识符
杭电2156.分数矩阵 原题链接:Problem - 2156 题目描述 Problem Description:我们定义如下矩阵: 1/1 1/2 1/3 1/2 1/1 1/2 1/3 1/2 1/1 矩阵对角线上的元素始终是1/1,对角线两边分数的分母逐个递增。请求出这个矩阵的总和。 Input…...
)
爬虫学习--18.反爬斗争 selenium(3)
操作多窗口与页面切换 有时候窗口中有很多子tab页面。这时候肯定是需要进行切换的。selenium提供了一个叫做switch_to.window来进行切换,具体切换到哪个页面,可以从driver.window_handles中找到。 from selenium import webdriver from selenium.webdri…...

如何评价GPT-4o?
GPT-4o是OpenAI为聊天机器人ChatGPT发布的一款新语言模型,其名称中的“o”代表Omni,即全能的意思,凸显了其多功能的特性。这款模型在多个方面都有着显著的优势和进步。 首先,GPT-4o具有极强的多模态能力,它能够接受文本…...

算能BM1684+FPGA+AI+Camera推理边缘计算盒
搭载算丰智算芯片BM1684,是面向AI推理的边缘计算盒。高效适配市场上所有AI算法,实现视频结构化、人脸识别、行为分析、状态监测等应用,为智慧城市、智慧交通、智慧能源、智慧金融、智慧电信、智慧工业等领域进行AI赋能。 产品规格 处理器芯片…...
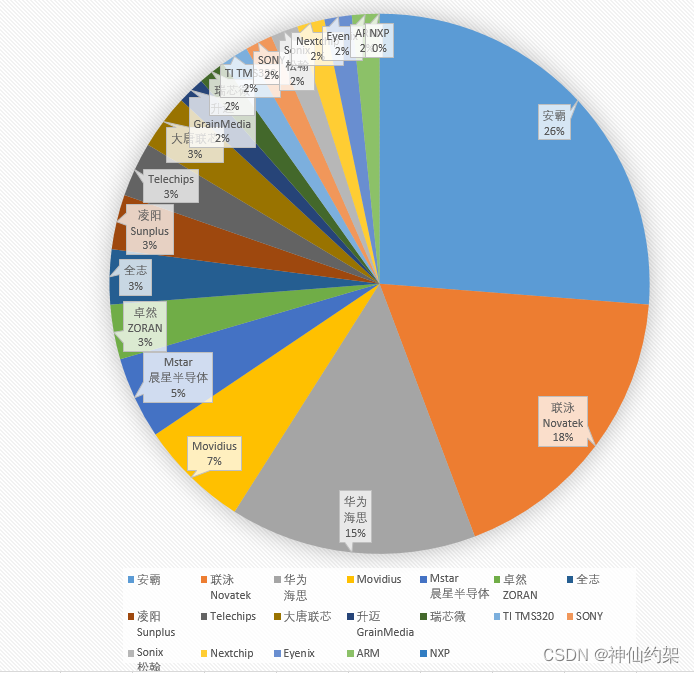
不同厂商SOC芯片在视频记录仪领域的应用
不同SoC公司芯片在不同产品上的应用信息: 大唐半导体 芯片型号: LC1860C (主控) LC1160 (PMU)产品应用: 红米2A (399元)大疆晓Spark技术规格: 28nm工艺,4个ARM Cortex-A7处理器,1.5GHz主频,2核MaliT628 GPU,1300万像…...
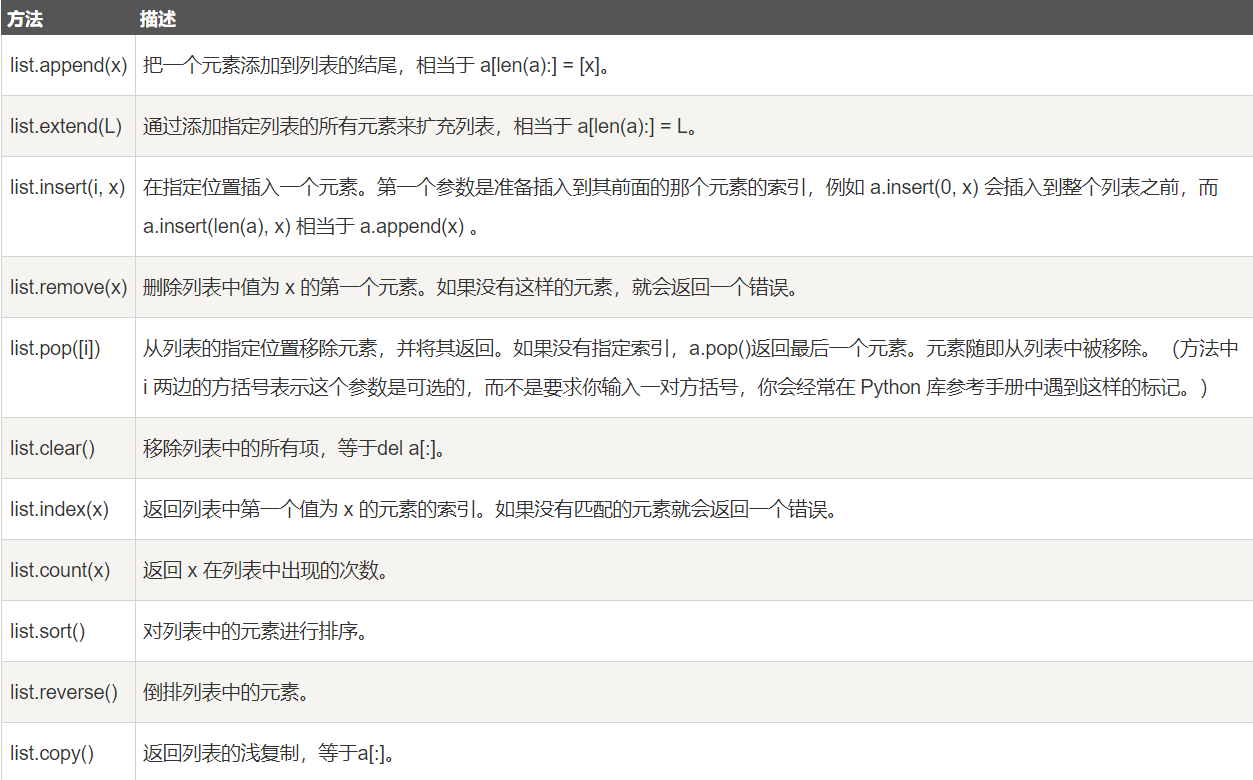
【Python入门学习笔记】Python3超详细的入门学习笔记,非常详细(适合小白入门学习)
Python3基础 想要获取pdf或markdown格式的笔记文件点击以下链接获取 Python入门学习笔记点击我获取 1,Python3 基础语法 1-1 编码 默认情况下,Python 3 源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串。 当然你也可以为源码文件指…...

通用代码生成器应用场景三,遗留项目反向工程
通用代码生成器应用场景三,遗留项目反向工程 如果您有一个遗留项目,要重新开发,或者源代码遗失,或者需要重新开发,但是希望复用原来的数据,并加快开发。 如果您的项目是通用代码生成器生成的,…...
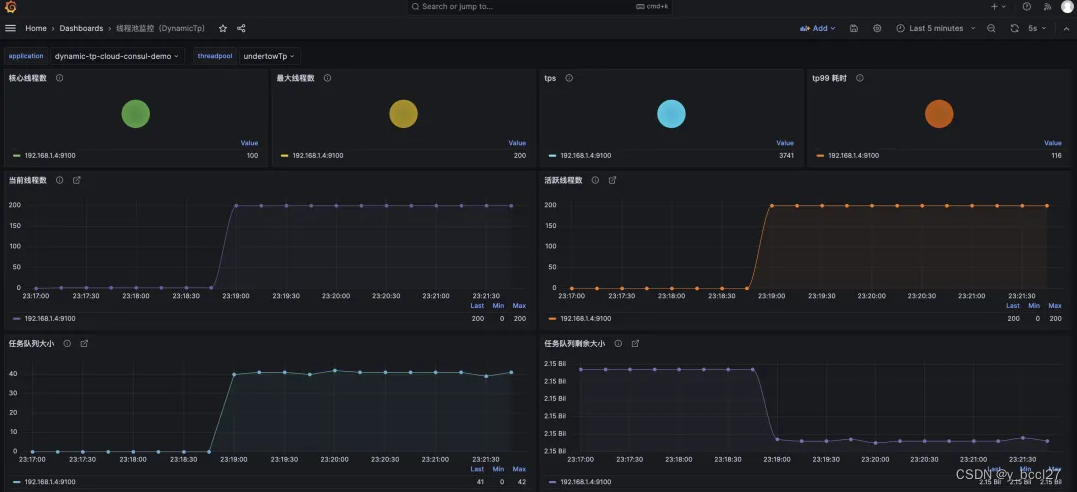
轻量级动态可监控线程池 - DynamicTp
一、背景介绍 使用线程池ThreadPoolExecutor的过程中你是否有以下痛点呢? 代码中创建了一个 ThreadPoolExecutor,但是不知道那几个核心参数设置多少比较合适凭经验设置参数值,上线后发现需要调整,改代码重新发布服务,…...
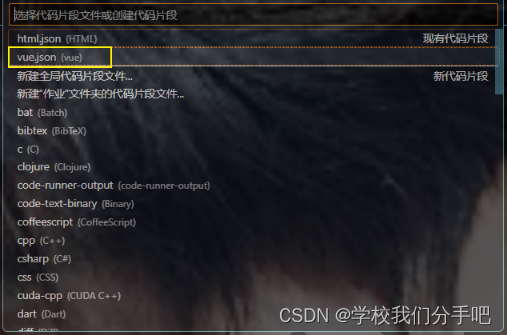
对于vsc中的vue命令 vue.json
打开vsc 然后在左下角有一个设置 2.点击用户代码片段 3.输入 vue.json回车 将此代码粘贴 (我的不一定都适合) { "vue2 template": { "prefix": "v2", "body": [ "<template>", " <…...

肿瘤样本SV分析避坑指南:Delly somatic检测中那些容易忽略的过滤与注释细节
肿瘤样本SV分析避坑指南:Delly somatic检测中那些容易忽略的过滤与注释细节 在癌症基因组学研究中,结构变异(SV)的准确检测对于理解肿瘤发生机制和寻找潜在治疗靶点至关重要。Delly作为一款广泛使用的SV检测工具,其som…...

3个实用技巧:如何彻底解决C盘爆红难题,让你的Windows系统重获新生
3个实用技巧:如何彻底解决C盘爆红难题,让你的Windows系统重获新生 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经遇到过这样的…...

AI写作检测规避:原理、工具与实践指南
1. 项目概述:为什么我们需要“AI写作检测规避”工具?在内容创作领域,尤其是技术博客、学术写作和日常办公文档中,AI辅助写作工具已经变得无处不在。它们能快速生成草稿、润色语言、甚至构建复杂的技术方案。然而,随之而…...

研扬EPIC-RPS9工控主板解析:4英寸板载13代酷睿,赋能边缘AI与机器视觉
1. 项目概述:当“小钢炮”遇上工业严苛环境在工业自动化、边缘计算和嵌入式视觉这些领域里,我们常常面临一个经典矛盾:既要强大的算力来处理海量数据、运行复杂算法,又要设备足够紧凑、坚固,能塞进各种空间受限、环境恶…...

Sunshine自托管游戏串流服务器:构建高性能私人云游戏平台的完整指南
Sunshine自托管游戏串流服务器:构建高性能私人云游戏平台的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款功能强大的自托管游戏串流服务器&am…...

Claude任务大师浏览器扩展:AI自动化工作流与Chrome插件开发实战
1. 项目概述与核心价值最近在折腾AI自动化工作流,发现一个痛点:虽然像Claude这样的AI助手能力很强,但每次想让它帮我处理网页内容,都得手动复制粘贴,效率实在太低。直到我发现了GitHub上一个名为“claude-task-master-…...

WarcraftHelper终极指南:魔兽争霸3优化工具完整教程
WarcraftHelper终极指南:魔兽争霸3优化工具完整教程 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸III》的陈旧限制而烦…...

LaTeX-PPT:3分钟学会在PowerPoint中快速插入专业数学公式的终极指南
LaTeX-PPT:3分钟学会在PowerPoint中快速插入专业数学公式的终极指南 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 你是否曾经在PowerPoint中为编辑复杂的数学公式而头疼?手动调整…...

GitHub仓库自动化同步工具xpull:原理、配置与实战应用
1. 项目概述:一个被低估的GitHub数据同步利器 如果你经常在GitHub上管理多个仓库,或者需要将某个仓库的特定分支、标签甚至整个提交历史同步到另一个仓库,那么你很可能经历过手动操作的繁琐。无论是为了备份、镜像、还是将上游的更新合并到自…...

树莓派Pico舵机控制库picoclaw:从PWM原理到多舵机机器人应用
1. 项目概述:一个为树莓派Pico量身打造的舵机控制库如果你玩过树莓派Pico,并且尝试过用它来控制舵机,那你大概率会遇到一个头疼的问题:Pico的MicroPython固件本身并没有内置专门的舵机控制库。这意味着你需要自己动手,…...