详解 Spark 核心编程之 RDD 分区器
一、RDD 分区器简介
- Spark 分区器的父类是 Partitioner 抽象类
- 分区器直接决定了 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 后进入哪个分区,进而决定了 Reduce 的个数
- 只有 Key-Value 类型的 RDD 才有分区器,非 Key-Value 类型的 RDD 分区的值是 None
- 每个 RDD 的分区索引的范围:0~(numPartitions - 1)
二、HashPartitioner
默认的分区器,对于给定的 key,计算其 hashCode 并除以分区个数取余获得数据所在的分区索引
class HashPartitioner(partitions: Int) extends Partitioner {require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")def numPartitions: Int = partitionsdef getPartition(key: Any): Int = key match {case null => 0case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)}override def equals(other: Any): Boolean = other match {case h: HashPartitioner => h.numPartitions == numPartitionscase _ => false}override def hashCode: Int = numPartitions
}
三、RangePartitioner
将一定范围内的数据映射到一个分区中,尽量保证每个分区数据均匀,而且分区间有序
class RangePartitioner[K: Ordering: ClassTag, V](partitions: Int, rdd: RDD[_ <: Product2[K, V]], private var ascending: Boolean = true) extends Partitioner {// We allow partitions = 0, which happens when sorting an empty RDD under the default settings.require(partitions >= 0, s"Number of partitions cannot be negative but found $partitions.")private var ordering = implicitly[Ordering[K]]// An array of upper bounds for the first (partitions - 1) partitionsprivate var rangeBounds: Array[K] = {...}def numPartitions: Int = rangeBounds.length + 1private var binarySearch: ((Array[K], K) => Int) = CollectionsUtils.makeBinarySearch[K]def getPartition(key: Any): Int = {val k = key.asInstanceOf[K]var partition = 0if (rangeBounds.length <= 128) {// If we have less than 128 partitions naive searchwhile(partition < rangeBounds.length && ordering.gt(k, rangeBounds(partition))) {partition += 1}} else {// Determine which binary search method to use only once.partition = binarySearch(rangeBounds, k)// binarySearch either returns the match location or -[insertion point]-1if (partition < 0) {partition = -partition-1}if (partition > rangeBounds.length) {partition = rangeBounds.length}}if (ascending) {partition} else {rangeBounds.length - partition}}override def equals(other: Any): Boolean = other match {...}override def hashCode(): Int = {...}@throws(classOf[IOException])private def writeObject(out: ObjectOutputStream): Unit = Utils.tryOrIOException {...}@throws(classOf[IOException])private def readObject(in: ObjectInputStream): Unit = Utils.tryOrIOException {...}
}
四、自定义 Partitioner
/**1.继承 Partitioner 抽象类2.重写 numPartitions: Int 和 getPartition(key: Any): Int 方法
*/
object TestRDDPartitioner {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("partition")val sc = new SparkContext(conf)val rdd = sc.makeRDD(List(("nba", "xxxxxxxxxxx"),("cba", "xxxxxxxxxxx"),("nba", "xxxxxxxxxxx"),("ncaa", "xxxxxxxxxxx"),("cuba", "xxxxxxxxxxx")))val partRdd = rdd.partitionBy(new MyPartitioner)partRdd.saveAsTextFile("output")}
}class MyPartitioner extends Partitioner {// 重写返回分区数量的方法override def numPartitions: Int = 3// 重写根据数据的key返回数据所在的分区索引的方法override def getPartition(key: Any): Int = {key match {case "nba" => 0case "cba" => 1case _ => 2}}}
相关文章:

详解 Spark 核心编程之 RDD 分区器
一、RDD 分区器简介 Spark 分区器的父类是 Partitioner 抽象类分区器直接决定了 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 后进入哪个分区,进而决定了 Reduce 的个数只有 Key-Value 类型的 RDD 才有分区器,非 Key-Value 类型的 RDD 分区的值是 No…...

Selenium番外篇文本查找、元素高亮、截图、无头运行
Selenium根据文本查找元素 python def find_element_with_text(self, loc, attribute, text):try:WebDriverWait(self.driver, 5).until(EC.all_of(EC.text_to_be_present_in_element_attribute(loc, attribute, text)))element self.driver.find_element(*loc)if isinsta…...
Java 22的FFM API,比起Java 21的虚拟线程
哪个对Java未来的发展影响更大?两个 Java 版本中的重要特性:Java 21 的虚拟线程和 Java 22 的 FFM API。我这里有一套编程入门教程,不仅包含了详细的视频讲解,项目实战。如果你渴望学习编程,不妨点个关注,给…...

用c语言实现简易三子棋
本篇适用于C语言初学者。 目录 完整代码: 分步介绍: 声明: 代码主体部分: 模块功能实现: 完整代码: #include<stdio.h> #include <stdlib.h> #include <time.h>#define ROW 3 #d…...
)
2024年华为OD机试真题-执行时长-Python-OD统一考试(C卷D卷)
2024年OD统一考试(D卷)完整题库:华为OD机试2024年最新题库(Python、JAVA、C++合集) 题目描述: 为了充分发挥GPU算力,需要尽可能多的将任务交给GPU执行,现在有一个任务数组,数组元素表示在这1秒内新增的任务个数且每秒都有新增任务,假设GPU最多一次执行n个任务,一次执…...
对未知程序所创建的 PDF 文档的折叠书签层级全展开导致丢签的一种解决方法
对需要经常查阅、或连续长时间阅读的带有折叠书签的 PDF 文档展开书签层级,提高阅览导航快捷是非常有必要的。 下面是两种常用书签层级全展开的方法 1、 FreePic2Pdf 1 - 2 - 3 - 4 - 5 - 6,先提取后回挂 2、PdgCntEditor 载入后,直接保存…...
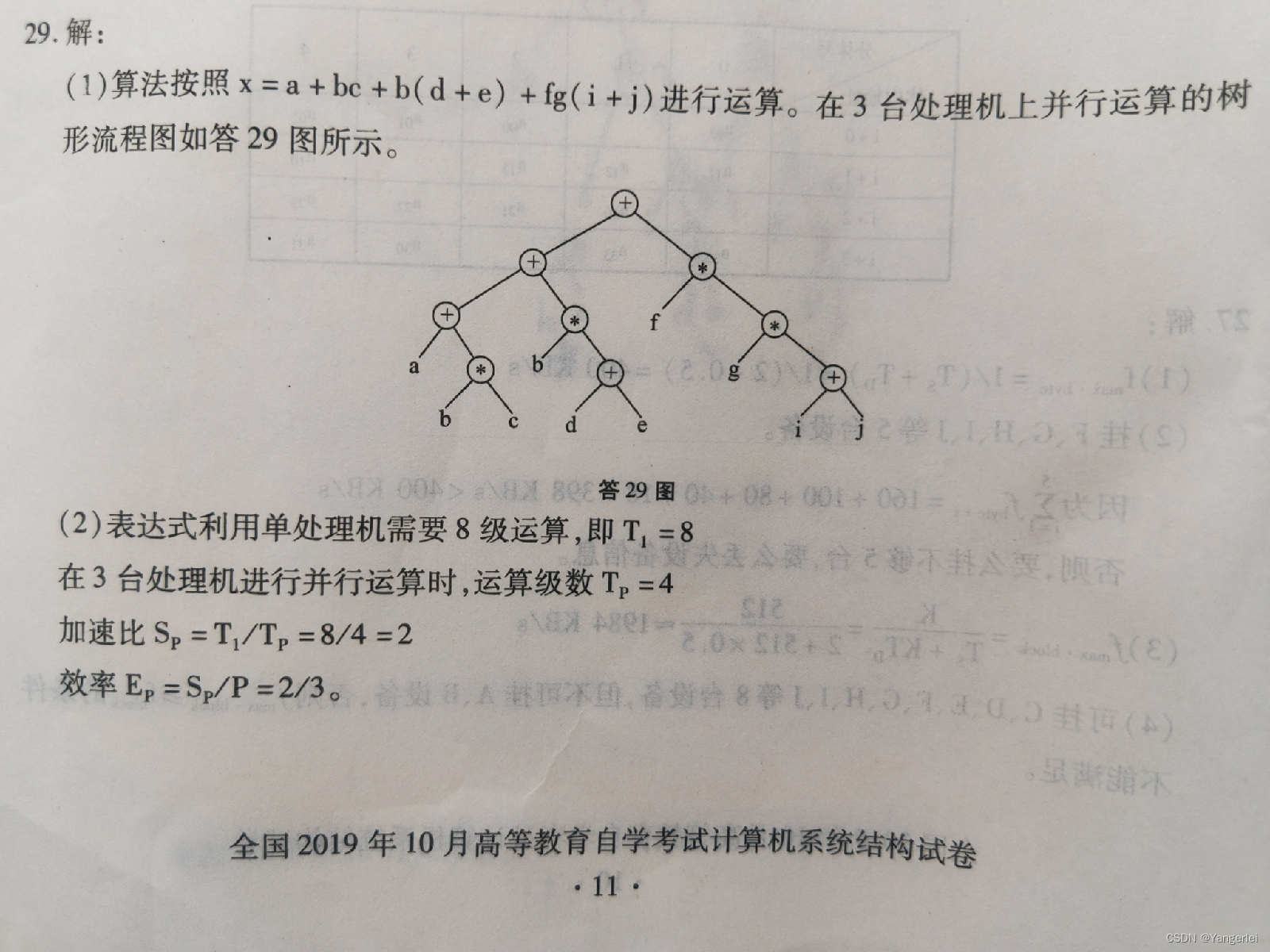
计算机系统结构之FORK和JOIN
程序语言中用FORK语句派生并行任务,用JOIN语句对多个并发任务汇合。 FORK语句的形式为FORK m,其中m为新领程开始的标号。 JOIN语句的形式为JOIN n,其中n为并发进程的个数。 例1:给定算术表达式ZEA*B*C/DF经并行编译得到如下程序…...

Yocto - virtual/kernel介绍
在 Yocto 项目中,"virtual/kernel "是一个虚拟目标,作为 Linux 内核的抽象层。它是一种以灵活方式指定内核依赖关系的方法,允许实际的内核配方由特定构建中使用的机器配置和层决定。 下面是关于 "virtual/kerne"的含义和…...

如何在 DigitalOcean 云服务器上创建自定义品牌名称服务器
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 介绍 对于托管提供商或转售商来说,拥有自定义的名称服务器可以为客户提供更专业的外观。这消除了要求客户将其域名指向另一…...
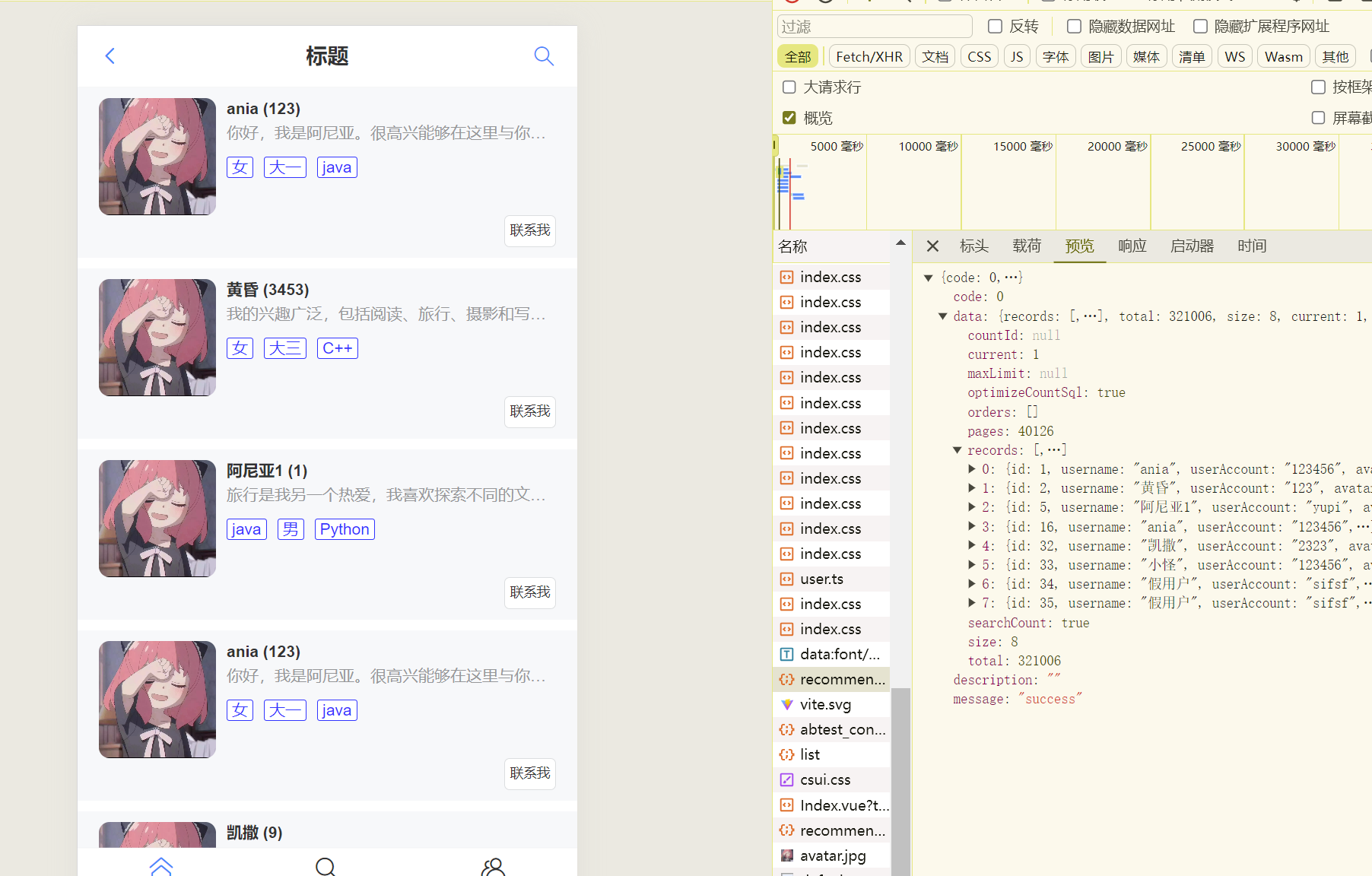
心链6----开发主页以及后端数据插入(多线程并发)定时任务
心链 — 伙伴匹配系统 开发主页 信息搜索页修改 主页开发(直接list用户) 在后端controller层编写接口去实现显示推荐页面的功能 /*** 推荐页面* param request* return*/GetMapping("/recommend")public BaseResponse<List<User>&…...
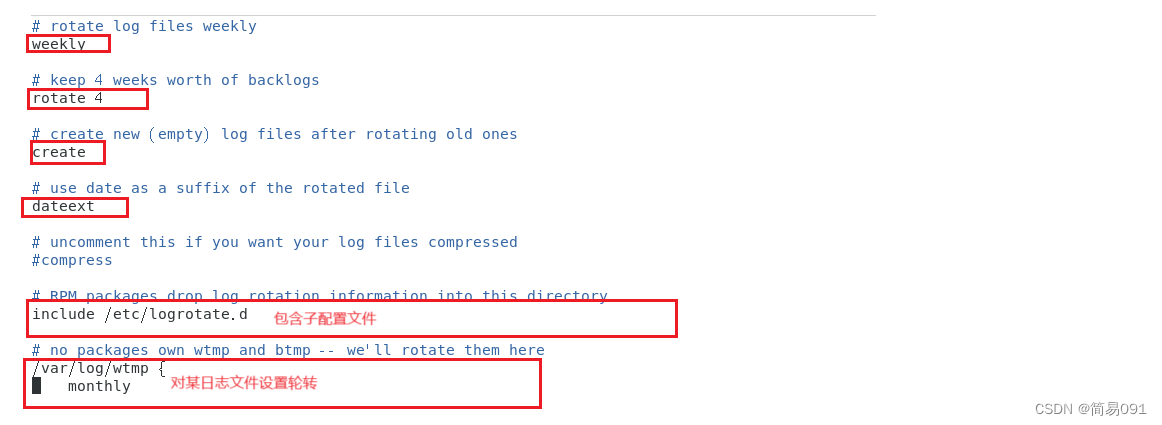
【Linux】日志管理
一、日志进程 1、处理日志的进程 rsyslogd:系统专职日志程序 观察rsyslogd程序: ps aux | grep rsyslogd 2、常见的日志文件 1、系统主日志文件: /var/log/messages 动态查看日志文件尾部: tail -f /var/log/messages 2、安全…...

AI 绘画爆火背后:扩散模型原理及实现
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。 针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 合集&#x…...

详解智慧互联网医院系统源码:开发医院小程序教学
本篇文章,笔者将详细介绍智慧互联网医院系统的源码结构,并提供开发医院小程序的详细教学。 一、智慧互联网医院系统概述 智慧互联网医院系统涵盖了预约挂号、在线咨询、电子病历、药品管理等多个模块。 二、系统源码结构解析 智慧互联网医院系统的源码…...
【技术实操】银河高级服务器操作系统实例分享,数据库日志文件属主不对问题分析
1. 问题现象描述 2023 年 06 月 30 日在迁移数据库过程中,遇到数据库 crash 的缺陷,原因如下:在数据库启动时候生成的一组临时文件中,有 owner 为 root 的文件, 文件权限默认为 640, 当数据库需要使用的时…...

函数的创建和调用
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 提到函数,大家会想到数学函数吧,函数是数学最重要的一个模块,贯穿整个数学学习过程。在Python中,函数…...

数模混合芯片设计中的修调技术是什么?
一、修调目的 数模混合芯片需要修调技术主要是因为以下几个原因: 工艺偏差(Process Variations): 半导体制造过程中存在不可避免的工艺偏差,如晶体管尺寸、阈值电压、电阻和电容值等,这些参数的实际值与…...
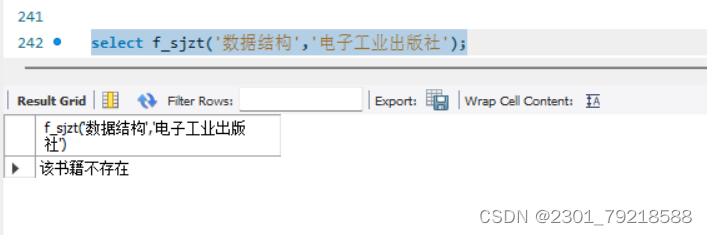
MySQL 自定义函数(实验报告)
一、实验名称: 自定义函数 二、实验日期: 2024年 6 月 1 日 三、实验目的: 掌握MySQL自定义函数的创建及调用; 四、实验用的仪器和材料: 硬件:PC电脑一台; 配置:内存&#…...

一次职业院校漏洞挖掘
这个是之前挖掘到的漏洞,目前网站进行重构做了全新的改版,但是这个漏洞特别经典,拿出来进行分享。看到src上面的很多敏感信息泄露,所以自己也想找一个敏感信息泄露,官网如图: 发现在下面有一个数字校园入口…...
洪师傅代驾系统开发 支持公众号H5小程序APP 后端Java源码
代驾流程图 业务流程图 管理端设置 1、首页装修 2、师傅奖励配置 师傅注册后,可享受后台设置的新师傅可得的额外奖励; 例:A注册了师傅,新人奖励可享受3天,第一天的第一笔订单完成后可得正常佣金佣金*奖励比例 完成第二笔/第三笔后依次可得正常佣金佣金*奖励比例 完成的第四…...

View->Bitmap缩放到自定义ViewGroup的任意区域(Matrix方式绘制Bitmap)
Bitmap缩放和平移 加载一张Bitmap可能为宽高相同的正方形,也可能为宽高不同的矩形缩放方向可以为中心缩放,左上角缩放,右上角缩放,左下角缩放,右下角缩放Bitmap中心缩放,包含了缩放和平移两个操作…...

用Logisim搞定Educoder交通灯实训:从数码管驱动到状态机集成的保姆级避坑指南
用Logisim征服Educoder交通灯实训:从零搭建到联调的全链路实战手册 第一次打开Educoder平台的交通灯实训项目时,我盯着那些闪烁的数码管和错综复杂的线路图,感觉像在破解某种外星密码。三小时后,当我的第一个状态机模块终于通过测…...

AI智能体密钥安全管理:AgentVault架构解析与实战指南
1. 项目概述:一个为AI智能体打造的“保险箱”最近在折腾AI智能体(Agent)应用开发的朋友,估计都绕不开一个核心痛点:如何安全、可靠地管理智能体运行过程中需要用到的各种密钥、凭证和敏感数据?无论是调用Op…...

构建本地化个人助理系统:事件驱动架构与模块化设计实践
1. 项目概述:一个高度可定制的个人助理系统最近在GitHub上看到一个挺有意思的项目,叫“Personal-Assistant”,作者是idk-man69。光看名字,你可能会觉得这又是一个类似Siri或Google Assistant的语音助手,但点进去仔细研…...

Performance-Fish:深度解析《环世界》400%性能优化核心技术
Performance-Fish:深度解析《环世界》400%性能优化核心技术 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance-Fish 是专为《环世界》(RimWorld&#…...

Seraphine终极指南:英雄联盟智能助手如何提升您的游戏胜率
Seraphine终极指南:英雄联盟智能助手如何提升您的游戏胜率 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的激烈对局中,错过对局接受、BP阶段犹豫不决、缺乏队友对手信息&a…...

AI智能体操作安卓设备:基于agent-droid-bridge的自动化实践
1. 项目概述:连接AI与安卓设备的桥梁 最近在折腾AI智能体(Agent)和自动化流程时,遇到了一个挺有意思的需求:如何让运行在服务器上的AI程序,直接去操作一台真实的安卓手机或模拟器,完成一些复杂的…...

多智能体强化学习环境PettingZoo:从核心概念到工程实践
1. 项目概述:从零理解PettingZoo如果你正在寻找一个能让你快速上手、高效构建多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)实验环境的工具,那么Farama Foundation旗下的PettingZoo项目,绝对是你绕不开…...
)
告别命令行恐惧:用Docker Compose一键部署EMQX集群(附Web控制台和端口映射配置)
告别命令行恐惧:用Docker Compose一键部署EMQX集群(附Web控制台和端口映射配置) 在物联网和分布式系统开发中,EMQX作为高性能的MQTT消息服务器,已经成为连接海量设备与后端服务的核心枢纽。然而,传统安装方…...

Git Worktree CLI工具:告别分支切换焦虑,实现高效并行开发
1. 项目概述与核心价值如果你和我一样,长期在多个Git分支间穿梭,同时维护着几个不同的功能特性或修复补丁,那你一定对那种在分支间反复切换、代码状态混乱、甚至不小心提交到错误分支的“切分支焦虑症”深有体会。传统的git checkout或git sw…...

氛围驱动开发:数据化提升开发者效率与团队协作的实践指南
1. 项目概述:当开发节奏遇上“氛围感”最近在GitHub上看到一个挺有意思的项目,叫“vibe-driven-dev”。光看名字,你可能会有点摸不着头脑——“氛围驱动开发”?这听起来不像是一个传统的技术框架或工具库。没错,它确实…...