Spark大数据 掌握RDD的创建
在Apache Spark中,弹性分布式数据集(Resilient Distributed Dataset,简称RDD)是一个核心的数据结构,用于表示不可变、可分区、可并行操作的元素集合。理解并掌握RDD的创建是使用Spark进行大数据处理的关键步骤之一。
以下是一些常用的方法来创建RDD:
- 从集合中创建RDD
在Spark程序中,你可以直接从一个Scala集合(如List、Set、Array等)创建一个RDD。这通常在本地测试或快速演示时使用。
import org.apache.spark.{SparkConf, SparkContext}val conf = new SparkConf().setAppName("RDD Creation Example").setMaster("local[*]")
val sc = new SparkContext(conf)val data = Array(1, 2, 3, 4, 5)
val rdd = sc.parallelize(data)rdd.collect().foreach(println)
- 从外部数据源创建RDD
Spark支持从多种外部数据源(如HDFS、S3、CSV文件、数据库等)读取数据并创建RDD。这通常通过sc.textFile()、sc.sequenceFile()等方法完成。
val inputPath = "hdfs://path/to/your/data.txt"
val rdd = sc.textFile(inputPath)rdd.map(line => line.split(" ")).flatMap(words => words).countByValue().foreachPrintln()
在上面的例子中,textFile方法从HDFS中读取了一个文本文件,并创建了一个包含文件各行字符串的RDD。然后,我们使用map和flatMap操作对数据进行了转换,并使用countByValue计算了词频。
3. 从其他RDD转换创建
你可以通过在一个已存在的RDD上应用转换操作(如map、filter、flatMap等)来创建新的RDD。这些转换操作是惰性的,意味着它们不会立即执行计算,而是返回一个新的RDD,这个新的RDD包含了所需的计算逻辑。
val rdd1 = sc.parallelize(Array(1, 2, 3, 4, 5))
val rdd2 = rdd1.map(x => x * x) // 创建一个新的RDD,其中每个元素是原RDD中元素的平方rdd2.collect().foreach(println)
- 从Hadoop InputFormat创建
对于支持Hadoop InputFormat的数据源,你可以使用sc.newAPIHadoopRDD或sc.hadoopRDD方法从Hadoop InputFormat创建RDD。这允许你与那些已经为Hadoop编写了InputFormat的数据源进行交互。
5. 从并行集合创建
虽然sc.parallelize方法可以用于从集合创建RDD,但当你已经有了一个并行集合(如ParArray)时,你也可以直接使用它来创建RDD。然而,在大多数情况下,直接使用sc.parallelize从普通集合创建RDD就足够了。
6. 从其他数据源创建
Spark还提供了与其他数据源(如Cassandra、Kafka、HBase等)的集成,你可以使用相应的Spark连接器或库来从这些数据源创建RDD。这些连接器和库通常提供了专门的方法来从特定数据源读取数据并创建RDD。
在技术上,关于Spark大数据中RDD(Resilient Distributed Dataset)的创建,我们可以从以下几个方面进行详细的补充和归纳:
RDD的创建方式
-
从集合中创建
- 使用
SparkContext的parallelize方法从Scala集合(如List、Array等)中创建RDD。例如:val data = Array(1, 2, 3, 4, 5) val rdd = sc.parallelize(data) parallelize方法默认将数据分成与集群中的core数量相同的分区数,但也可以指定分区数作为第二个参数。
- 使用
-
从外部数据源创建
- Spark支持从多种外部数据源读取数据并创建RDD,如HDFS、S3、CSV文件等。
- 使用
SparkContext的textFile方法从文本文件创建RDD。例如:val inputPath = "hdfs://path/to/your/data.txt" val rdd = sc.textFile(inputPath) - 对于其他格式的文件,可能需要使用额外的库或自定义方法来解析并创建RDD。
-
从其他RDD转换创建
- 通过对已存在的RDD应用转换操作(如
map、filter、flatMap等)来创建新的RDD。 - 这些转换操作是惰性的,意味着它们不会立即执行计算,而是返回一个新的RDD,包含所需的计算逻辑。
- 例如,从一个包含整数的RDD创建一个包含整数平方的新RDD:
val rdd1 = sc.parallelize(Array(1, 2, 3, 4, 5)) val rdd2 = rdd1.map(x => x * x)
- 通过对已存在的RDD应用转换操作(如
-
分区和分区数
- 在Spark中,数据被划分为多个分区(Partition),并在集群的不同节点上并行处理。
- 分区数对Spark作业的性能有很大影响。通常,每个CPU核心处理2到4个分区是比较合适的。
- 可以通过
rdd.partitions.size查看RDD的分区数,也可以手动设置parallelize的分区数。
-
缓存(Caching)
- 对于需要多次使用的RDD,可以将其缓存到内存中,以加快后续的计算速度。
- 使用
rdd.cache()或rdd.persist()方法进行缓存。
RDD的特性
- 不可变性:RDD一旦创建,就不能被修改。但可以通过转换操作来创建新的RDD。
- 可分区性:RDD可以划分为多个分区,并在集群的不同节点上并行处理。
- 容错性:通过RDD的血统(Lineage)信息,Spark可以在节点故障时重新计算丢失的数据。
总结
在Spark中,RDD是数据处理的核心数据结构。掌握RDD的创建方式以及理解其特性对于高效地使用Spark进行大数据处理至关重要。从集合、外部数据源、其他RDD转换以及自定义方式创建RDD,都是常见的RDD创建方法。同时,理解分区和分区数、缓存等概念,可以帮助我们更好地优化Spark作业的性能。
相关文章:

Spark大数据 掌握RDD的创建
在Apache Spark中,弹性分布式数据集(Resilient Distributed Dataset,简称RDD)是一个核心的数据结构,用于表示不可变、可分区、可并行操作的元素集合。理解并掌握RDD的创建是使用Spark进行大数据处理的关键步骤之一。 …...

Chrome谷歌浏览器如何打开不安全页面的禁止权限?
目录 一、背景二、如何打开不安全页面被禁止的权限?2.1 第一步,添加信任站点2.2 第二步,打开不安全页面的权限2.3 结果展示 一、背景 在开发过程中,由于测试环境没有配置 HTTPS 请求,所以谷歌浏览器的地址栏会有这样一…...
3D目标检测入门:探索OpenPCDet框架
前言 在自动驾驶和机器人视觉这两个飞速发展的领域中,3D目标检测技术扮演着核心角色。随着深度学习技术的突破性进展,3D目标检测算法的研究和应用正日益深入。OpenPCDet,这个由香港中文大学OpenMMLab实验室精心打造的开源工具箱,…...

JS异步编程
目录 概念定时器Promise对象概念 单线程模型指的是,JavaScript 只在一个线程上运行。也就是说,JavaScript 同时只能执行一个任务,其他任务都必须在后面排队等待。JavaScript 只在一个线程上运行,不代表 JavaScript 引擎只有一个线程。事实上,JavaScript 引擎有多个线程,…...
多元联合分布建模 Copula python实例
多元联合分布建模 Copula python实例 目录 库安装 实例可视化代码 库安装 pip install copulas 实例可视化代码 import numpy as np import pandas as pd from copulas.multivariate import GaussianMultivariate# Generate some example data np.random.seed(42) data = …...

单号日入50+,全自动挂机赚钱
大家好!今天我为大家精心挑选了一个极具潜力的副业项目——“游戏工作室自由之刃2:单号日入50,全自动挂机赚钱”。 传奇游戏,无疑是许多人心中那段青春时光的珍贵回忆。 即便是其手游版本,也依旧保持着极高的热度和人…...
LabVIEW老程序功能升级:重写还是改进?
概述:面对LabVIEW老程序的功能升级,开发者常常面临重写与改进之间的选择。本文从多个角度分析两种方法的利弊,并提供评估方法和解决思路。 重写(重新开发)的优势和劣势: 优势: 代码清晰度高&a…...
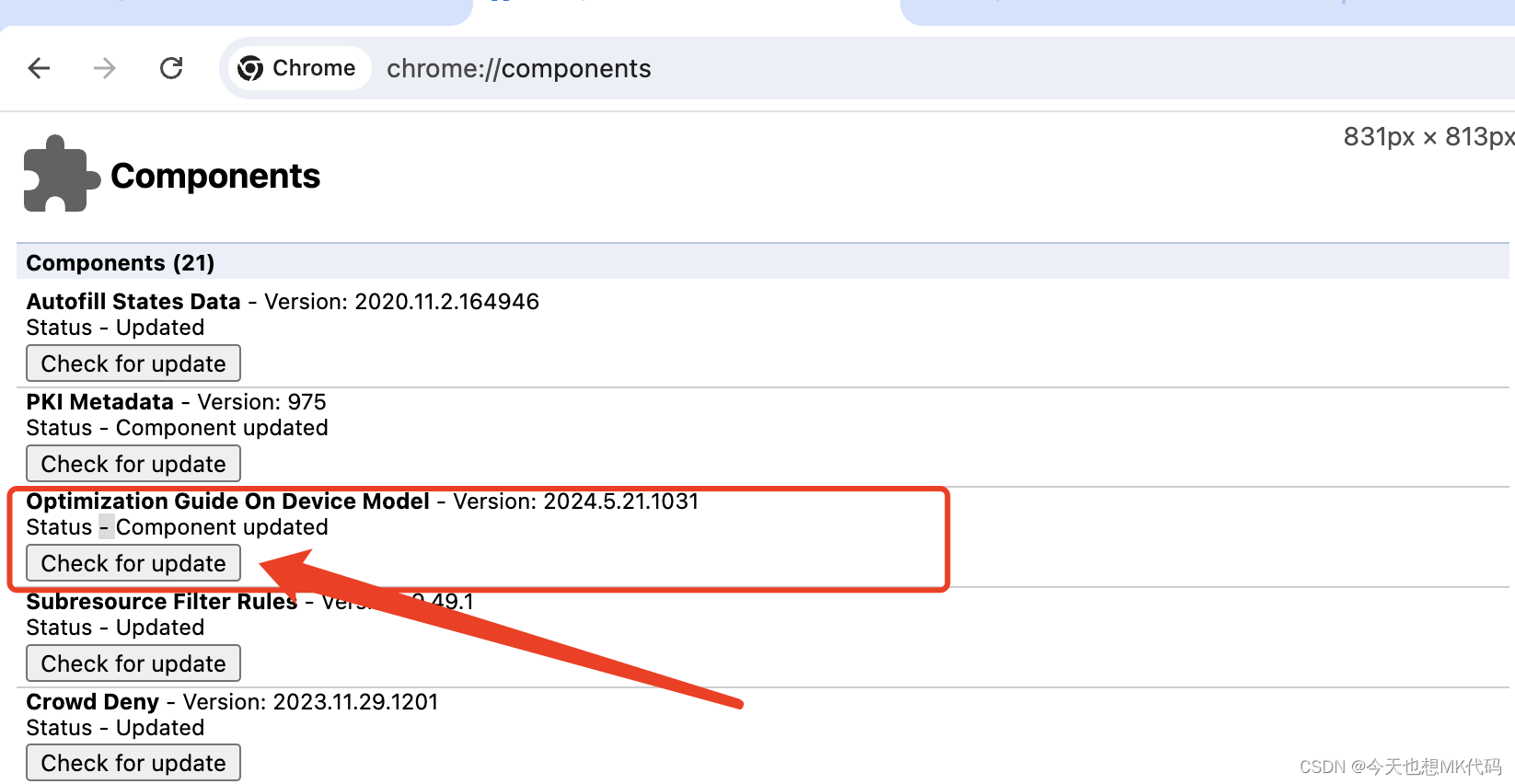
chrome谷歌浏览器开启Gemini Nano模型
前提 确保您的操作系统语言设置为英语(美国) 可能还需要将 Chrome 浏览器的语言更改为英语(美国)。 下载dev或Canary版本Chrome Chrome Canary Chrome Dev 注意:确认您的版本高于 127.0.6512.0。 其中一个Chrome版本…...
C语言王国——内存函数
目录 1 memcpy函数 1.1 函数表达式 1.2 函数模拟 2 memmove函数 2.1 函数的表达式 2.2 函数模拟 3 memset函数 3.1 函数的表达式 3.2 函数的运用 4 memcmp函数 4.1函数的表达式: 4.2 函数的运用 5 结论 接上回我们讲了C语言的字符和字符串函数&#…...
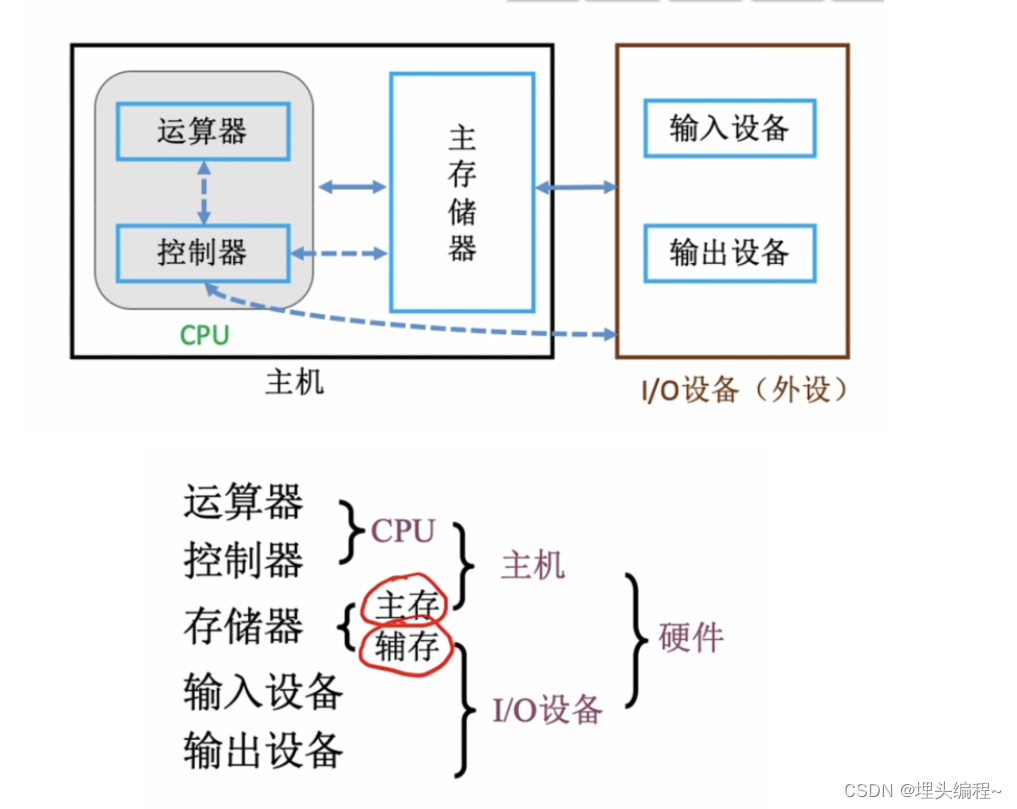
【计算机组成原理】1.1计算机的软硬件组成(记录学习计算机组成原理)
文章目录 1.早期的冯诺依曼机2.早期冯诺依曼机的基本运行框图3.早期冯诺依曼机的特点4.现代计算机的结构5. 小结 本次及以后有关于计算机组成原理的文章,旨在做学习时的记录和知识的分享。不论是应对期末考试,还是考研都是很有帮助的。希望大家多多支持更…...
Qt xml学习之calculator-qml
1.功能说明:制作简易计算器 2.使用技术:qml,scxml 3.项目效果: 4.qml部分: import Calculator 1.0 //需要引用对应类的队友版本 import QtQuick 2.12 import QtQuick.Window 2.12 import QtQuick.Controls 1.4 import QtScxml…...
低代码开发系统是什么?它有那些部分组成?
低代码开发系统是什么?它有那些部分组成? 一、引言 在当今快速变化的商业环境中,企业对于快速响应市场需求、降低开发成本和提高开发效率的需求日益增强。低代码开发系统(Low-Code Development Platform)应运而生&am…...
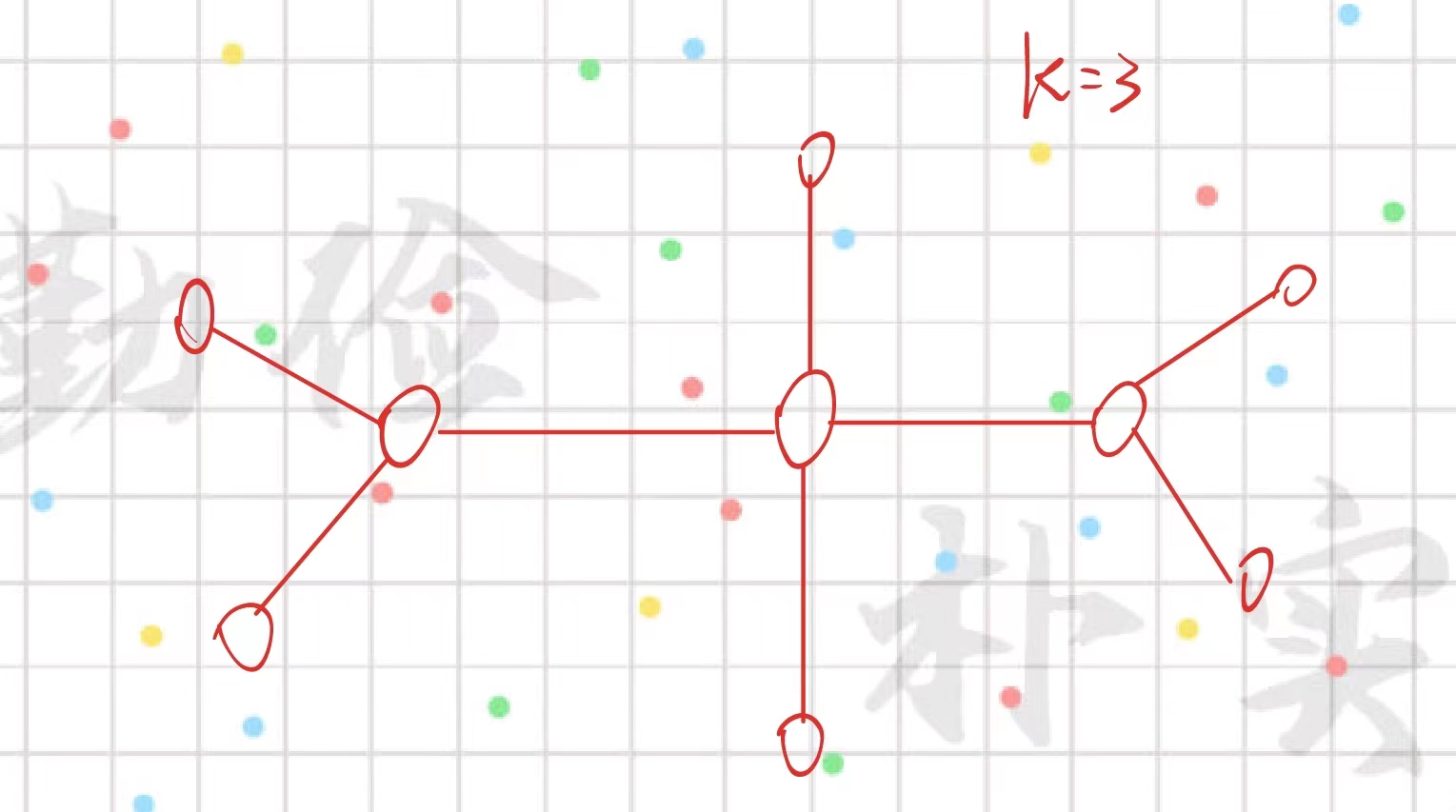
2024年西安交通大学程序设计竞赛校赛
2024年西安交通大学程序设计竞赛校赛 文章目录 2024年西安交通大学程序设计竞赛校赛D瑟莉姆的宴会E: 雪中楼I: 命令行(待补)J:最后一块石头的重量(待补)K: 崩坏:星穹铁道(待补)M:生命游戏N: 圣诞树 D瑟莉姆的宴会 解题思路: …...

【学习Day5】操作系统
✍🏻记录学习过程中的输出,坚持每天学习一点点~ ❤️希望能给大家提供帮助~欢迎点赞👍🏻收藏⭐评论✍🏻指点🙏 学习编辑文章的时间不太够用,先放思维导图,后续复习完善细节。...
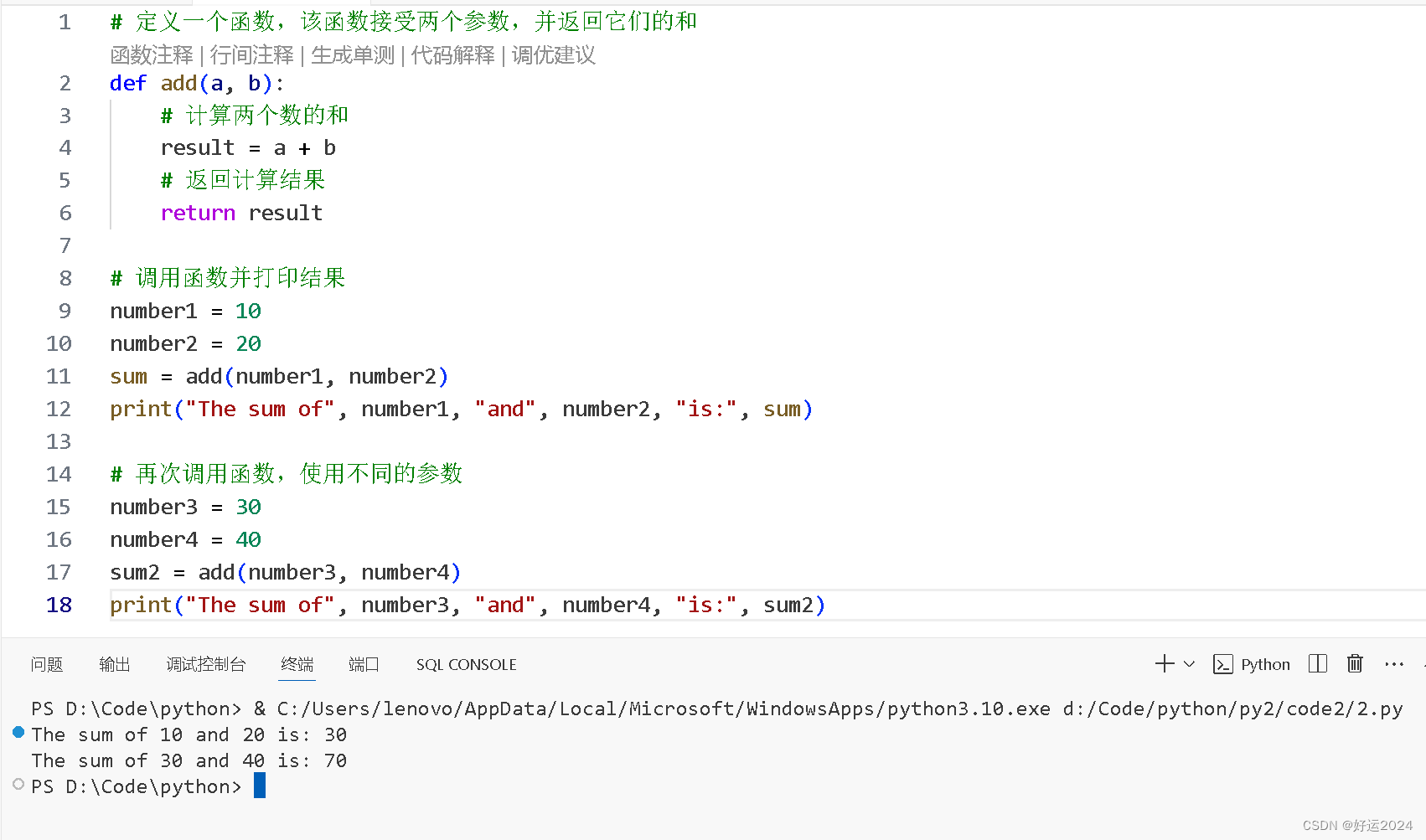
学习小记录——python函数的定义和调用
今日小好运,未来有好运。🎁💖🫔 分享个人学习的小小心意,一起来看看吧 函数的定义 函数通常来说就是带名字的代码块,用于完成具体的工作,需要使用的时候调用即可,这不仅提高代码的…...
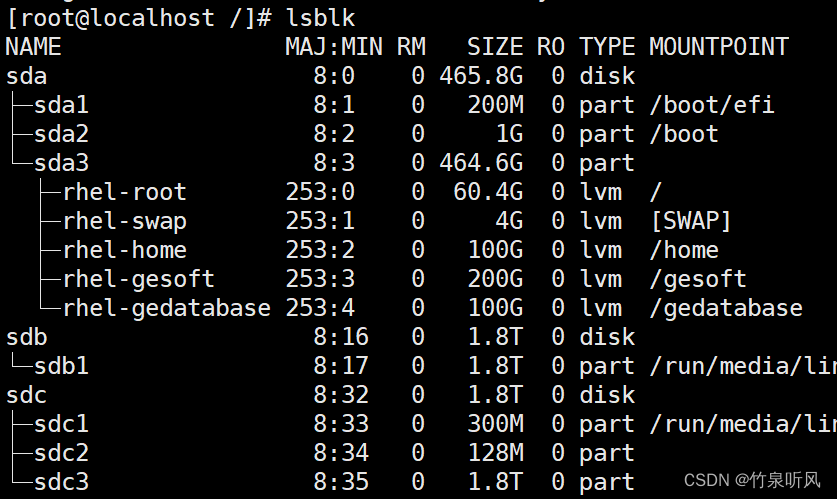
RHEL7.9修改分区
系统RHEL7.9 他因为安装软件,需要修改分区 进入超级用户root,输入lsblk 查看分区,可见465.8G系统盘sda下有三个物理卷,其中sda3下/home有410.6G,需要这部分拆分出200G软件和100G的数据库分区 备份/home 目录下文件 c…...

【Linux】命名管道
一、命名管道的原理 在前面的博客中,我们学习了匿名管道,了解到了两个具有血缘关系的进程之间是如何进行通信的?那么在没有血缘关系(毫不相关)的进程之间是如何进行通信的? 大致思路是一样的,我…...

IMX6Q基于linux4.1.15调试音频芯片tas2505
IMX6Q基于linux4.1.15调试音频芯片tas2505 1、开发环境2、初步想法3、开发过程4、tas2505重要的寄存器5、遇到的问题1、开发环境 芯片:IMX6Q (NXP系列) 内核版本:linux4.1.15 Ubuntu版本:16.04 目标模块:tas2505 2、初步想法 由于该电路是由外部晶振提供的时钟频率24.5…...
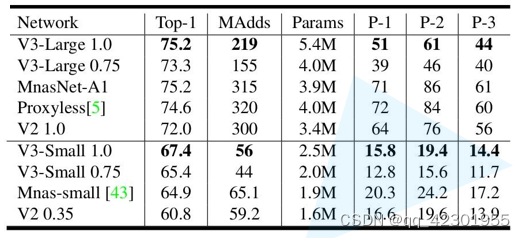
卷积常用网络
目录 1.AlexNet2.VGG3.GoogleNet4.ResNet5.MobileNet 1.AlexNet AlexNet是2012年ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军网络。 首次利用 GPU 进行网络加速训练。使用了 ReLU 激活函数,而不是传统的 Si…...

Firebase Local Emulator Suite详解
文章目录 Firebase Local Emulator Suite 组件安装和使用步骤1. 安装 Firebase CLI2. 初始化 Firebase 项目3. 配置模拟器4. 启动模拟器5. 配置应用程序使用本地模拟器 常见用途 Firebase Local Emulator Suite 是一组本地服务,可以模拟 Firebase 平台的在线服务&am…...

LearningX:构建结构化开发者知识体系,从基础到架构的实践指南
1. 项目概述:一个面向开发者的系统性学习仓库最近在GitHub上看到一个挺有意思的项目,叫“LearningX”。光看名字,你可能会觉得这又是一个普通的“Awesome-XXX”列表,或者是一堆学习资料的简单堆砌。但当我点进去,花了一…...

别再只盯着wx.login了!SpringBoot后端实战:用getPhoneNumber接口搞定小程序用户手机号绑定
微信小程序用户手机号绑定:SpringBoot后端深度实践指南 在当今移动互联网生态中,微信小程序已成为连接用户与服务的重要桥梁。对于需要强实名认证或直接触达用户的业务场景(如电商交易、金融服务、政务办理等),仅依赖w…...
)
告别混乱信号!用CANdb++ Editor从零搭建汽车CAN网络DBC文件(保姆级图文教程)
告别混乱信号!用CANdb Editor从零搭建汽车CAN网络DBC文件(保姆级图文教程) 在汽车电子开发领域,CAN总线如同神经脉络般贯穿整车系统。我曾参与过一个新能源整车项目,由于早期缺乏规范的DBC文件,不同ECU厂商…...

Taotoken用量看板如何帮助个人开发者管理月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助个人开发者管理月度预算 对于独立工作的个人开发者而言,项目预算往往是决定技术选型与使用策…...

Redis增强工具包:封装分布式锁、缓存模板与监控的最佳实践
1. 项目概述:一个Redis开发者的“瑞士军刀”在分布式系统和高并发场景下,Redis几乎成了标配。但用久了你会发现,官方客户端虽然稳定,但在日常开发、调试、运维中,总有些“不够顺手”的地方。比如,想批量按模…...

Oracle数据库触发器概述
Oracle数据库触发器概述触发器介绍数据库触发器是一个 已编译的存储程序单元 ,使用 PL/SQL 或 Java 编写。 触发器是模式对象,类似于子程序;但其调用方法不同。 子程序由用户、应用程序、或触发器显式运行。而触发器是在触发的事件发生时由 数…...

基于NestJS与Next.js的自托管电影管理应用Story Flicks部署与实战
1. 项目概述:一个为影迷打造的私人观影档案库 如果你和我一样,是个重度电影爱好者,那么你一定经历过这样的时刻:看完一部好片子,内心澎湃,想写点什么记录一下,却发现豆瓣、IMDb的评论区要么太嘈…...

ComfyUI ControlNet Aux 终极指南:30+种预处理器让AI图像生成更精准
ComfyUI ControlNet Aux 终极指南:30种预处理器让AI图像生成更精准 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux 想让您的AI图像生成具备真实…...

Instagram视频下载终极指南:三分钟掌握免费下载技巧
Instagram视频下载终极指南:三分钟掌握免费下载技巧 【免费下载链接】instagram-video-downloader Simple website made with Next.js for downloading instagram videos with an API that can be used to integrate it in other applications. 项目地址: https:…...

【最新 v2.7.1 版本安装包】5 分钟搞定 OpenClaw,零基础无需命令一键部署保姆级教学
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟搭建专属数字员工【点击下载最新OpenClaw安装包】 前言 2026 年开源圈热门 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 …...