Mybatis第一讲——你会Mybatis吗?
文章目录
- 什么是Mybatis
- Mybatis的作用是什么
- Mybatis 怎么使用
- 注解的方式
- 注解的多种使用
- @Options注解
- ResultType注解
- XML的方式
- update标签
- #{} 和 ${}符号的区别
- #{}占位
- ${}占位
- ${}占位的危险性(SQL注入)
- 数据库连接池
什么是Mybatis
首先什么是Mybatis呢?Mybatis是一个持久层框架也就是用来操作数据库的一个框架,我们在最原始的时候使用jdbc进行数据库的操作这使得我们会有大量的重复操作需要进行,那么Mybatis把这些重复的操作进行了集合,使得我们的代码更见的简单,并且对于我们jdbc中需要连接数据库的这个操作也进行了优化,使用配置文件的方式来使得我们的操作变得更加的简单。
Mybatis的作用是什么
那么看了上面之后我们也就知道了Mybatis框架的作用了也就是简单易用,代码简单提供了很多强大且方便的功能帮助我们可以更好更快更方便的编写代码。操纵数据库。
Mybatis 怎么使用
那么有了上面的概念之后,我们来讲述一下Mybatis该怎么使用,首先我们要想使用Mybatis那么我们就要先将Mybatis配置到我们的Spring中也就是说要导入依赖导入什么依赖呢?如下
<dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>3.0.3</version></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter-test</artifactId><version>3.0.3</version><scope>test</scope></dependency>
当然这些还是不够因为我们只是把Mybatis引入了进来但是我们还是不能使用,我们可以想一下我们在使用jdbc的时候除了把jar包引入进来之后我们还做了什么工作吗?我们还有的工作就是使用jdbc给我们提供的接口来与我们的目标数据库建立了连接,那么我们这里也是需要建立连接的,那么连接如何建立呢?
spring:application:name: Spring_Mybaitsdatasource:url: jdbc:mysql://127.0.0.1:3308/mybatis_test?characterEncoding=utf8&useSSL=falseusername: rootpassword: ”写上自己的密码“driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:# 配置 mybatis xml 的文件路径,在 resources/mapper 创建所有表的 xml 文件mapper-locations: classpath:mybatis/**Mapper.xmlconfiguration: # 配置打印 MyBatis日志log-impl: org.apache.ibatis.logging.stdout.StdOutImplmap-underscore-to-camel-case: true #配置驼峰自动转换
这就是我们配置文件的书写格式我们发现我们的配置文件内定义了我们mybatis的日志信息并且害配置了mybatis如果进行了xml中写的话那么我们也配置了该xml文件的路径信息。那么配置好后我们来看看如何来写代码吧
注解的方式
首先是注解的方式我们的Mybatis写sql代码实在接口类中写的因此我们要先定义一个接口代码并且这个接口代码我们需要使用@Mapper注解来修饰代码如下
package com.example.spring_mybaits.mapper;import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Options;
import org.apache.ibatis.annotations.Update;
import java.util.List;
@Mapper
public interface UserInfoMapper {
}
这里我们定义了一个接口并且使用了Mapper注解进行了修饰那么接下来我们要来写代码了,那么代码该怎么去写呢?那么代码的书写我们先从最简单的查询所有数据开始吧,如何查询所有的数据呢?我们来写一下代码首先,先在接口中写一个select方法的声明
package com.example.spring_mybaits.mapper;import org.apache.ibatis.annotations.*;import java.util.List;@Mapper
public interface UserInfoMapper {List<UserInfo> selectAllUser();
}
第二步实现
package com.example.spring_mybaits.mapper;import org.apache.ibatis.annotations.*;import java.util.List;@Mapper
public interface UserInfoMapper {@Select(" select * from userinfo")List<UserInfo> selectAllUser();
}
第三步进行测验
我们需要进行实现test方法那么如何快速的实现test方法呢?我们要进行
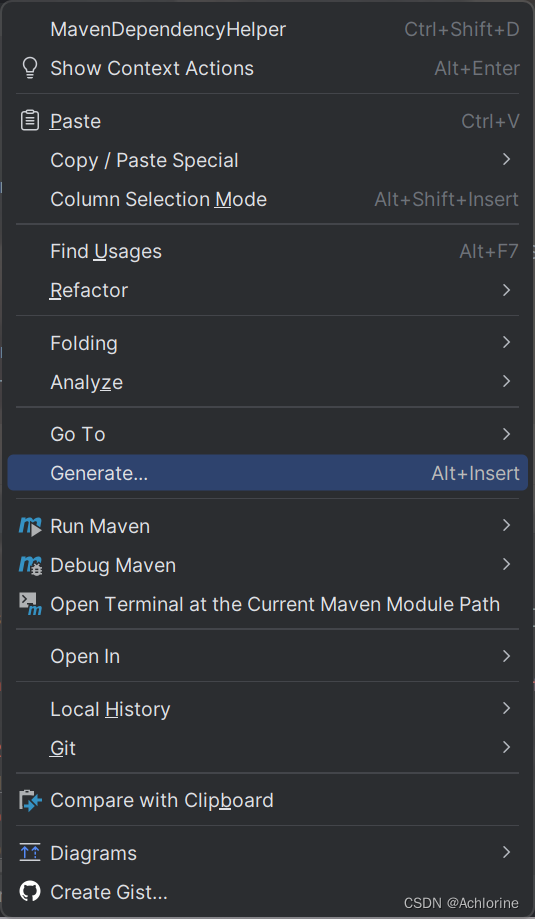
首先点击Generate 弹出下面的这个页面
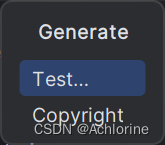
然后点击Test
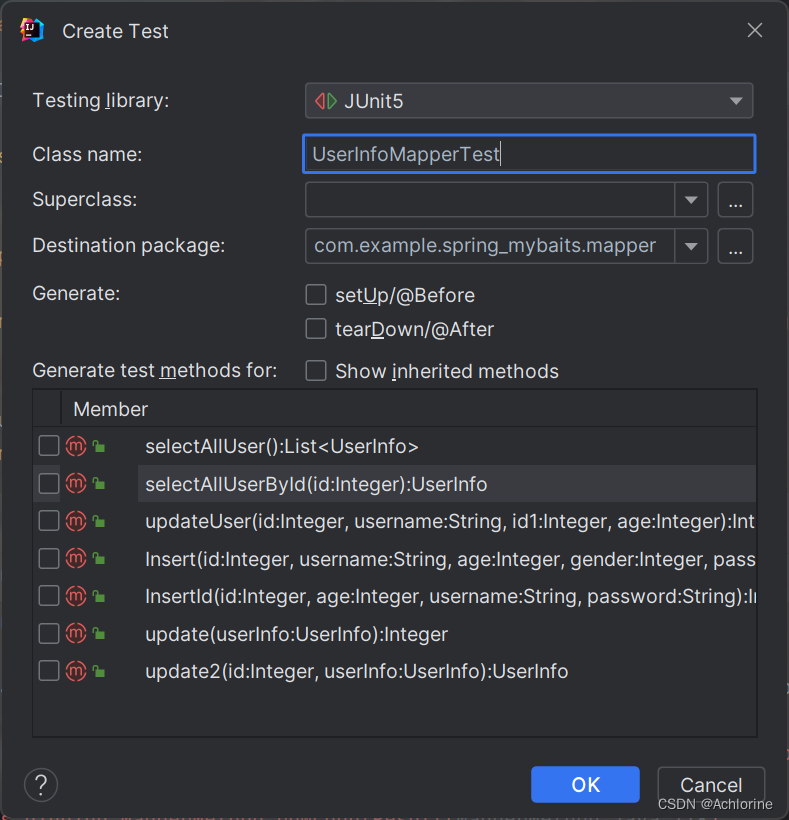
然后在下面选择你要进行测验的方法,然后光有这些也不够我们的测试代码也是需要进行进一步的书写的。
package com.example.spring_mybaits.mapper;import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.util.List;import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
class UserInfoMapperTest {@AutowiredUserInfoMapper userInfoMapper;@Testvoid selectAllUser() {List<UserInfo>list=userInfoMapper.selectAllUser();for (UserInfo u:list) {System.out.println(u);}}
}
我们通过查看上面的测试代码我们不难发现,我们实现的接口在这里使用了@Autowired注解进行了修饰,那么这个注解我们之前讲过这相当于是把spring容器中存储的Bean给注入了进去,那么既然如此我们就可以调用这个接口中的方法了。
注解的多种使用
@Options注解
这个注解可以帮助我们获取到查询到的目标主键,比如说我们使用insert插入了一行,然后我们想知道插入的这一行,所被分配到的自动递增的Id是多少,我们可以通过@Options注解进行实现。这个注解的使用方式如下首先这个注解我们需要传递进去两个参数代码如下我们来分别说一下他们的作用
@Options(useGeneratedKeys = true,keyProperty = "id")Integer InsertId(Integer id,Integer age,String username,String password);
useGeneratedKeys :它可以是的Mybatis使用JDBC的getGeneratedKeys方法取出由数据库内部生成的主键
keyProperty :指定能够唯一识别的对象属性,MyBatis 会使⽤ getGeneratedKeys 的返回值或insert 语句的 selectKey ⼦元素设置它的值,默认值:未设置(unset)
注意!注意! 设置 useGeneratedKeys=true 之后, ⽅法返回值依然是受影响的⾏数, ⾃增id 会设置在上
述 keyProperty 指定的属性中
ResultType注解
在我们注解方式去实现的时候我们需要注意到一些特殊的情况比如说我们想要设置其返回的形式,通常适用于我们在写查询语句的时候进行的我们来看一下示例代码
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.ResultType;public interface UserMapper {@Select("SELECT * FROM users")@ResultType(User.class)List<User> getAllUsers();
}
那么这里的映射其实就是将结果进行映射,那么这时候会有疑问假如说我们要进行复杂查询的话我们要对多个结果进行映射的话该怎么做呢?那么这时候需要用到新的注解叫做@Results,那么我们来举个例子
@Results({@Result(property = "id", column = "id"),@Result(property = "name", column = "name"),@Result(property = "email", column = "email")})
它的名字和它的用法很像,指的就是多个result的集合。那么它的一个样例代码如下
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Results;
import org.apache.ibatis.annotations.Result;public interface UserMapper {@Select("SELECT id, name, email FROM users")@Results({@Result(property = "id", column = "id"),@Result(property = "name", column = "name"),@Result(property = "email", column = "email")})List<User> getAllUsers();
}
XML的方式
除了使用上述注解的方式之外我们还可以使用XML的方式,那么XML的方式该怎么实现呢?我们首先要先对前面的一个知识点做一个说明那就是我们在配置文件中的下面的这个属性我们可以根据意思去揣测出来这个意思是指路径
mapper-locations: classpath:mybatis/**Mapper.xml
那么这个路径其实就是我们的xml文件所配置的路径,那么接下来我们来写一下xml中的格式。首先是XML中的一些配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.spring_mybaits.mapper.UserInfoMapper">
</mapper>
那么我们来讲解一下这个配置首先第一个mapper,他是一个标签,我们接下来写的所有标签都是在这个标签内部进行写的,其次就是namespace这个英文的直译就是命名空间,也就是我们这个xml文件是对那一个java文件所进行的连接,那么接下里我们来用几个例子来写一下吧
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.spring_mybaits.mapper.UserInfoMapper"> <update id="updateUser">UPDATE userinfo set username=#{username},id=#{id1},age=#{age} WHERE id=#{id};</update>
</mapper>
Integer updateUser(Integer id,String username,Integer id1,Integer age);
然后我们用上面写的知识首先在方法的声明这里鼠标右键点击一下
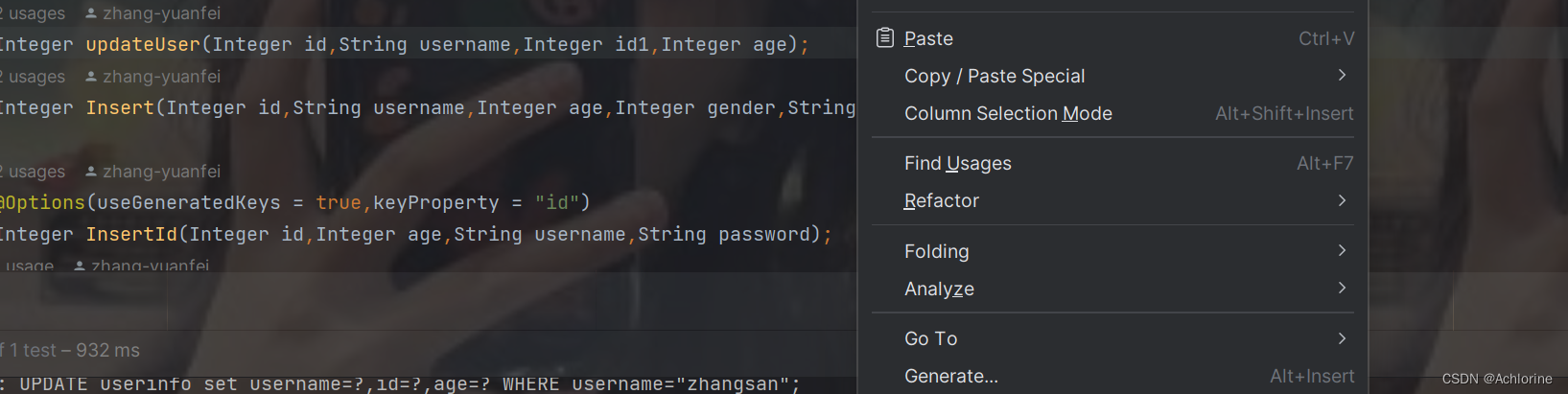
在弹出的页面中选择Generate
然后选择test
然后在生成的test方法中实现我们的测试方法。
@Testvoid updateUser() {UserInfo userInfo=new UserInfo();userInfo.id=11;userInfo.age=21;userInfo.phone="520134";userInfo.username="zyficl";int d= userInfoMapper.updateUser(2, userInfo.username,userInfo.id, userInfo.age );System.out.println(d);}
通过上面我们来回答一下上面代码中可能出现的部分疑问
update标签
首先就是update标签,通过这标签的内容我们可以指导这个标签中需要有一个参数那就是id这个id的值就是我们具体要实现的一个方法的名称,然后我们以此作为类推我们可以知道,其实我们的select标签也是同样的用法。
那么我们有了上面的了解后相信就可以写出比较简单的一些数据库sql语言的操作了,那么这些操作包括但不限于增删查改,但是接下来还有一些比较复杂的操作也是需要我们学习的比如说复杂查询,排序,等,包括一些动态的添加,动态的查找等,那么我们来一起学习一下这些该怎么进行那么接下来我们来讲一下本节重点知识那就是#和$符号的区别。
#{} 和 ${}符号的区别
那么在讨论区别之前我们需要先讨论一下他们的作用,那么他们的作用是什么呢?他们的作用其实都是对sql语句加上参数也就是一个占位符,但是他们在实现上又有区别,我们下面可以来看一下分别使用这两个符号的话会有什么不同
#{}占位
这是一个安全的占位当我们使用这个占位的时候我们发现我们打印出的日志中对于占位的内容并没有补充,也就是说此时的占位并不是直接补充的。我们输⼊的参数并没有在后⾯拼接,id的值是使⽤ ? 进⾏占位. 这种SQL 我们称之为预编译SQL

${}占位
当我们把占位符更改一下更改为${}占位后我们再来看一下此时我们的代码会变成什么样子的呢?

这时候我们发现我们的代码变成了占位符的直接拼接,不像上面的那种使用占位符进行拼接那么这种方式我们叫做即时SQL。这也就是这两个的区别
${}占位的危险性(SQL注入)
$ 占位符用于直接替换字符串,这种方式不进行参数转义,因此存在SQL注入的风险。它通常用于传递表名、列名等SQL片段,但绝不应该用于传递用户输入的数据。那么什么时sql注入呢?比如说下面的这个语句
SELECT * FROM userinfo where id=?;
这里的问号是我们需要填写的内容那么既然如此假如说我们使用的时$占位符的话我们是不是也就是可以传进去这样一个内容呢?
SELECT * FROM userinfo where id=1;DELETE userinfo;
因为那个?表示并不是一个单一的字符因此我们完全可以将这个内容改成这个样子也正因此当我们执行的时候我们就会发现完了,sql语句被注入了,因此这样就会导致我们发生一个难以想象的一个损失。比如说被删库等操作。因此我们在实际开发中会尽量避开使用$符号。但是话又说回来了,为什么我们要保留这个符号呢?其实原因也很简单因为有些地方我们不可避免的要使用这个符号就比如说排序查询
使用 ${sort} 可以实现排序查询, ⽽使⽤ #{sort} 就不能实现排序查询了
除此之外还有别的吗?当然还有,也就是我们的模糊查询(like查询)
@Select("select id, username, age, gender, phone, delete_flag, create_time,
update_time " +"from userinfo where username like '%#{key}%' ")
List<UserInfo> queryAllUserByLike(String key);
但是这里我们会陷入一个非常纠结的地方那就是如果我们使用$符号会有sql注入的风险可是不适用的话又不能达到我们的需求,那这个该怎么办呢?我们需要借助一个方法来进行实现这个方法就是concat方法,这个方法的作用是什么呢这个方法的作用是进行字符串的拼接,也就是说我们可以使用字符串拼接的方式来避免这个风险那么样例如下
@Select("select id, username, age, gender, phone, delete_flag, create_time,
update_time " +"from userinfo where username like concat('%',#{key},'%')")
List<UserInfo> queryAllUserByLike(String key);
数据库连接池
池化技术相信我们都已经了解过了池化技术相当于一个中间商一样我们对有无池化技术来用一张图来说明一下
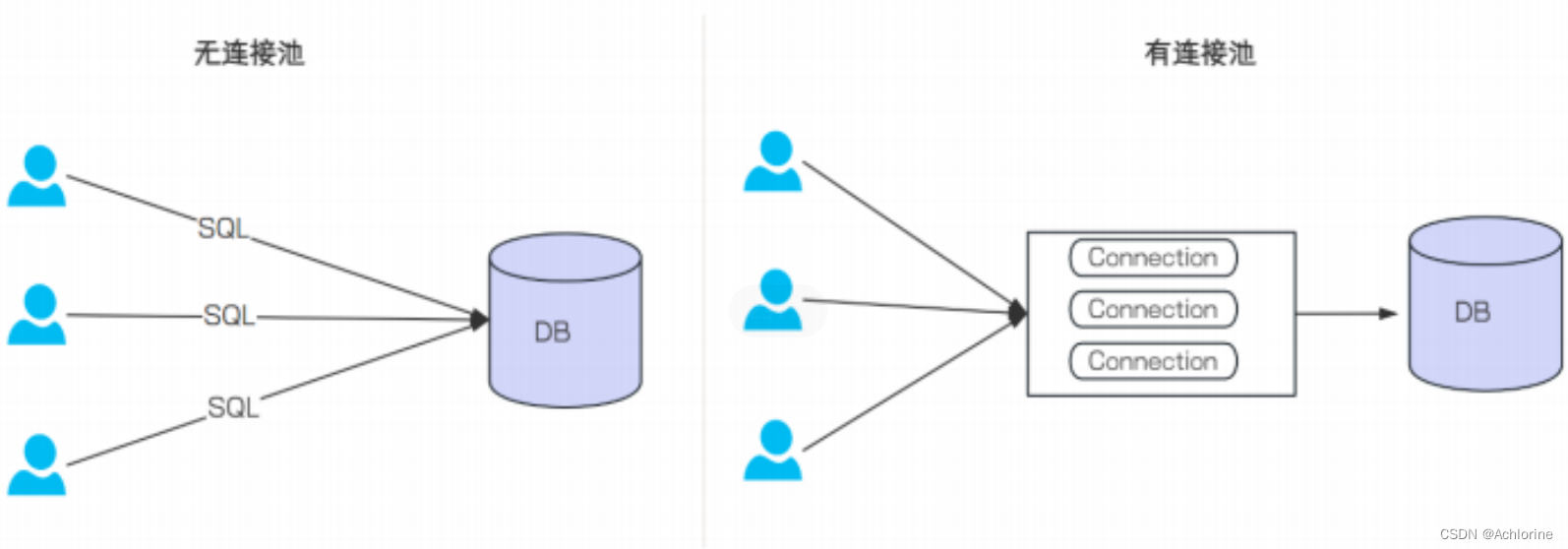
这张图可以有效的说明有无池化技术的区别。
没有使⽤数据库连接池的情况: 每次执⾏SQL语句, 要先创建⼀个新的连接对象, 然后执⾏SQL语句, SQL
语句执⾏完, 再关闭连接对象释放资源. 这种重复的创建连接, 销毁连接⽐较消耗资源
使⽤数据库连接池的情况: 程序启动时, 会在数据库连接池中创建⼀定数量的Connection对象, 当客⼾
请求数据库连接池, 会从数据库连接池中获取Connection对象, 然后执⾏SQL, SQL语句执⾏完, 再把
Connection归还给连接池
那么我们的连接池有哪些呢?如下
常⻅的数据库连接池:
• C3P0
• DBCP
• Druid
• Hikari
我们来看一下我们的Mybaits的日志信息我们是可以发现的

在这里我们发现我们的Mybaits使用的一个数据库连接池是一个hikari,那么这其实也是可以更改的。
如果我们想把默认的数据库连接池切换为Druid数据库连接池, 只需要引⼊相关依赖即可
相关文章:
Mybatis第一讲——你会Mybatis吗?
文章目录 什么是MybatisMybatis的作用是什么 Mybatis 怎么使用注解的方式注解的多种使用Options注解ResultType注解 XML的方式update标签 #{} 和 ${}符号的区别#{}占位${}占位 ${}占位的危险性(SQL注入)数据库连接池 什么是Mybatis 首先什么是Mybatis呢?Mybatis是一…...

【HarmonyOS】List组件多层对象嵌套ForEach渲染更新的处理
【HarmonyOS】List组件多层对象嵌套ForEach渲染更新的处理 问题背景: 在鸿蒙中UI更新渲染的机制,与传统的Android IOS应用开发相比。开发会简单许多,开发效率提升显著。 一般传统应用开发的流程处理分为三步:1.画UI,…...

PostgreSQL基础(六):PostgreSQL基本操作(二)
文章目录 PostgreSQL基本操作(二) 一、字符串类型 二、日期类型 三、...
【前端部署——vercel】部署next.js使用了prisma的项目
部署流程参考 https://blog.csdn.net/qq_51116518/article/details/137042682 问题 PrismaClientInitializationError: Prisma has detected that this project was built on Vercel, which caches dependencies. This leads to an outdated Prisma Client because Prisma’s …...
Vue插槽与作用域插槽
title: Vue插槽与作用域插槽 date: 2024/6/1 下午9:07:52 updated: 2024/6/1 下午9:07:52 categories: 前端开发 tags:VueSlotScopeSlot组件通信Vue2/3插槽作用域API动态插槽插槽优化 第1章:插槽的概念与原理 插槽的定义 在Vue.js中,插槽(…...
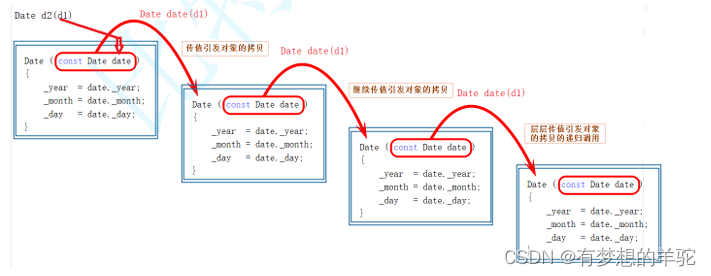
类和对象(一)(C++)
类和对象: 类的引入: C语言结构体中只能定义变量,在C中,结构体内不仅可以定义变量,也可以定义函数。比如: 之前在数据结构初阶中,用C语言方式实现的栈,结构体中只能定义变量&#…...
【免费Web系列】JavaWeb实战项目案例六
这是Web第一天的课程大家可以传送过去学习 http://t.csdnimg.cn/K547r 员工信息-删除&修改 前面我们已经实现了员工信息的条件分页查询以及新增操作。 关于员工管理的功能,还有两个需要实现: 删除员工 修改员工 除了员工管理的功能之外&#x…...
)
git分布式版本控制系统(四)
目前世界上最先进的分布式版本控制系统 官方网址:https://git-scm.com 学习目标: 1 了解 git 前世今生 2 掌握 git 基础概念、基础操作 3 各种 git 问题处理 4 互联网常用 gitflow(工作流程规范) 5 git 代码提交规范 6 git 分支管理及命名规范 常见问…...
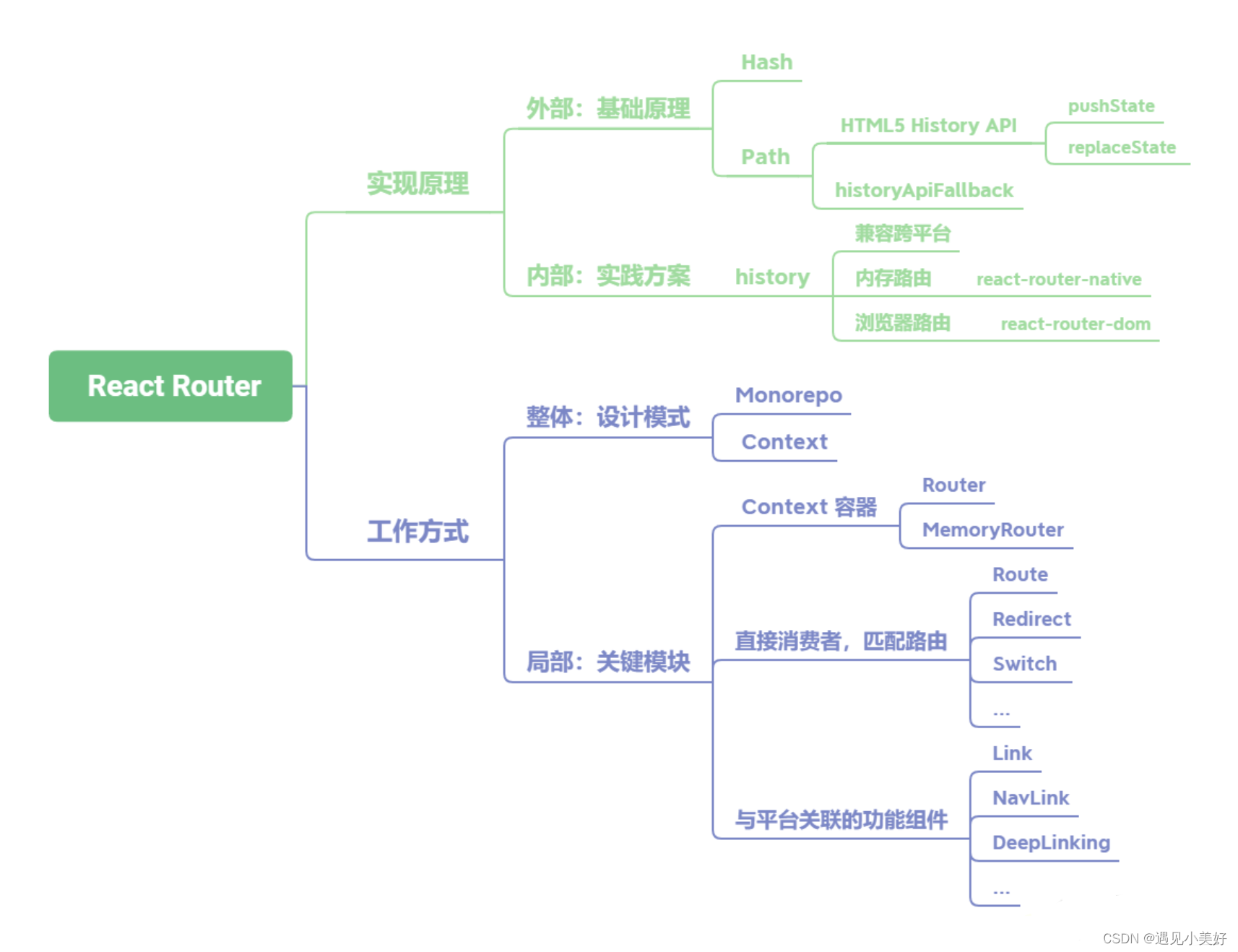
【React篇】简述React-Router 的实现原理及工作方式
React Router 路由的基础实现原理分为两种,如果是切换 Hash 的方式,那么依靠浏览器 Hash 变化即可;如果是切换网址中的 Path,就要用到 HTML5 History API 中的 pushState、replaceState 等。在使用这个方式时,还需要在…...
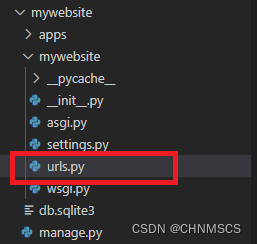
Django里多app
在 Django 里的某一个项目,里面得包含很多 App (功能),那么如何在该项目里管理这么多App呢? 先说明下背景:未先创建 apps 文件夹来存各个app文件夹,直接在项目文件目录里创建各个app。为了便于管理,得将各…...
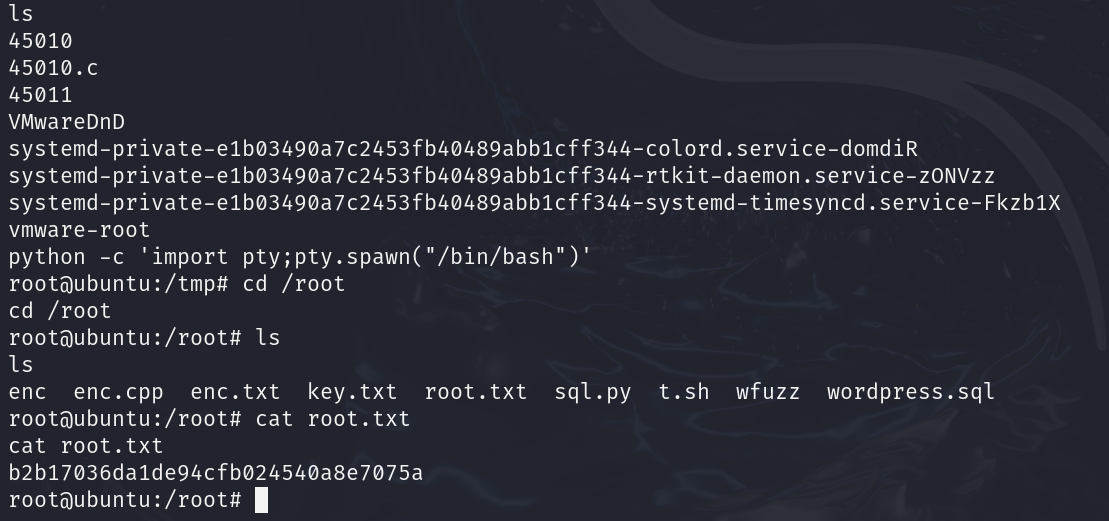
Prime1 - 信息收集和分析能力的试炼
主机发现 nmap扫描与分析 端口22、80 详细扫描;linux、ubuntu、 udp扫描 端口都是关闭的 脚本扫描 web渗透 打开只有一张图片;源码有图片和一个alt:hnp security不知道有啥用,先记录下来吧 继续web渗透思路走吧,目录…...

3.location的写法
location的写法 一、location的写法1、 精确匹配2、~ 以正则表达式匹配请求,区分大小写3、~* 以正则匹配请求,不区分大小写4、^~ 不以正则的方式匹配请求 二、stub_status模块显示工作状态三、url地址重写 rewrite模块1、语法2、针对项目结构有变化3、网…...

AndroidStudio设置允许APP获取定位权限
1. 在AndroidManifest.xml中声明权限 常用的定位权限有以下两种: <uses-permission android:name"android.permission.ACCESS_FINE_LOCATION"/> <uses-permission android:name"android.permission.ACCESS_COARSE_LOCATION"/>2. …...
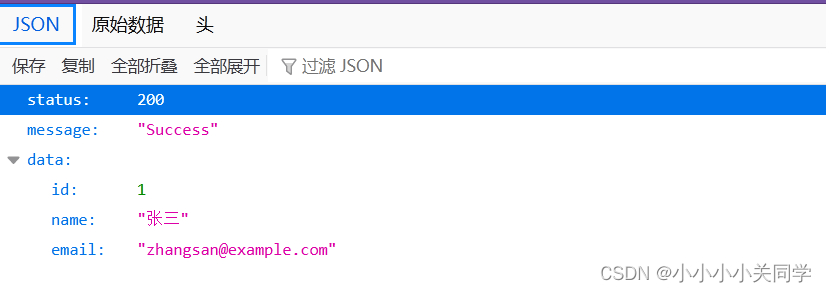
Spring Boot 统一数据返回格式
在 Spring Boot 项目中,统一的数据格式返回是一种良好的实践,它提高了代码的可维护性和一致性,并改善了客户端与服务端之间的通信。本文将介绍如何在 Spring Boot 中实现统一的数据格式返回。 1 为什么需要统一数据返回格式 ⽅便前端程序员更…...
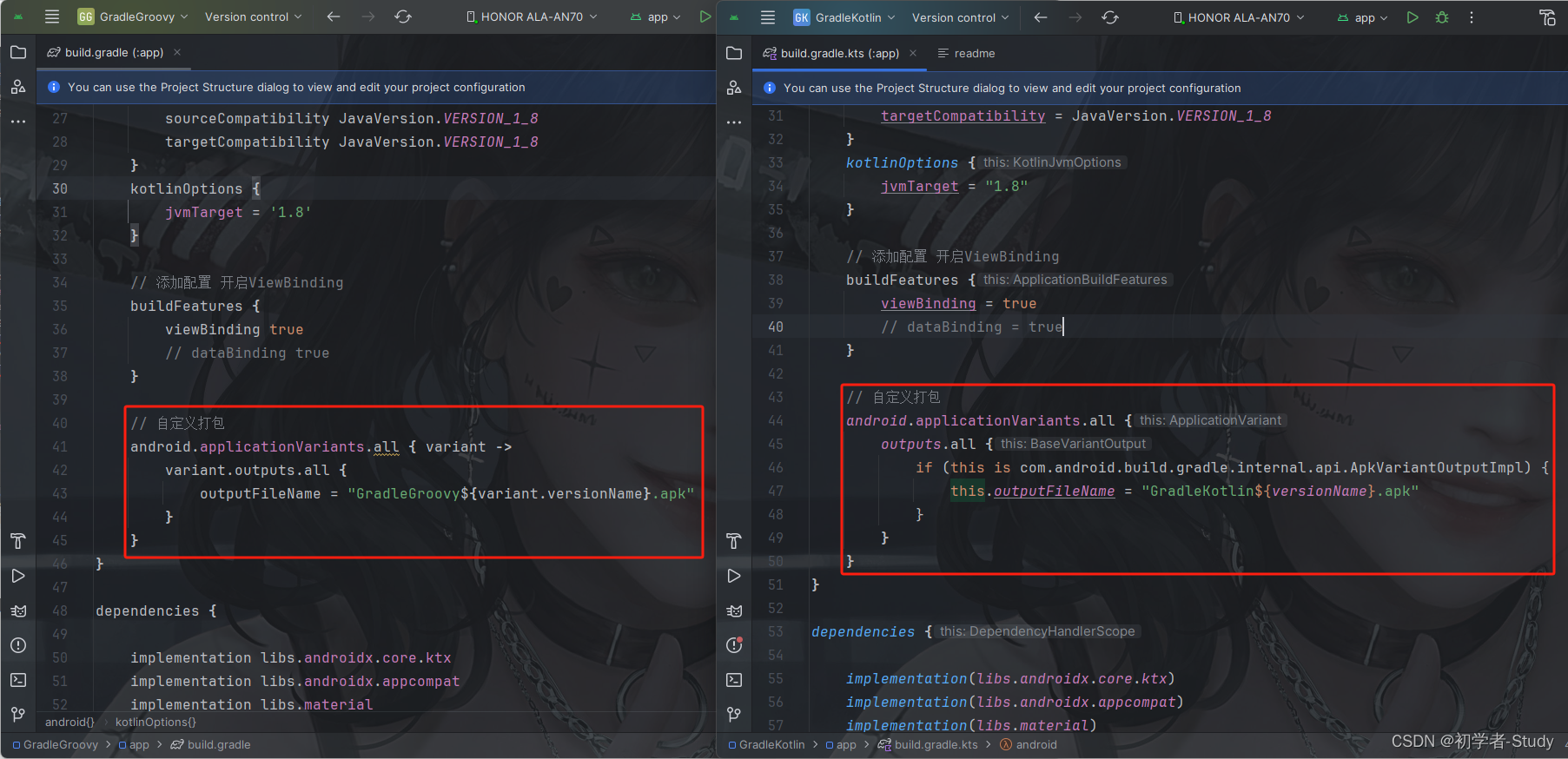
Android 项目Gradle文件讲解(Groovy和Kotlin)
Android 项目Gradle文件讲解(Groovy和Kotlin) 前言正文一、Gradle的作用二、Gradle的种类① 工程build.gradle② 项目build.gradle③ settings.gradle④ gradle.properties⑤ gradle-wrapper.properties⑥ local.properties 三、Groovy和Kotlin的语言对比…...

python-最接近target的值
【问题描述】:给定一个数组,在数组中找到两个数,使它们的和最接近目标值的值但不超过目标值,然后返回它们的和。 【问题示例】:输入target15,array[1,3,5,11,7],输出14,31114。 完整代码如下: …...

转换张量形状:`nlc_to_nchw` 函数详解
在深度学习和计算机视觉领域,张量的形状转换是一个常见的操作。本文将详细讲解一个用于形状转换的函数 nlc_to_nchw,它能够将形状为 [N, L, C] 的张量转换为 [N, C, H, W] 的张量。 函数定义 def nlc_to_nchw(x, hw_shape):"""Convert …...

「架构」云上自动化运维及其应用
随着云计算的普及,自动化运维成为企业提升运营效率和降低成本的关键。本文通过分析一家中型企业实施云上自动化运维(CloudOps)的案例,探讨了自动化监控、配置管理和持续集成/持续部署(CI/CD)三个核心模块的实际应用。文章详细阐述了每个模块的技术选型、实施原因、优缺点…...

分布式和集群的区别
分布式系统(Distributed System)和集群(Cluster)是两个经常被提及的计算机科学概念,它们在提高系统性能和可靠性方面都扮演着重要角色,很多同学会觉得这俩个是同一种东西,但事实上它们之间有着本…...

最新h5st(4.7.2)参数分析与纯算法还原(含算法源码)
文章目录 1. 写在前面2. 加密分析3. 算法还原 【🏠作者主页】:吴秋霖 【💼作者介绍】:擅长爬虫与JS加密逆向分析!Python领域优质创作者、CSDN博客专家、阿里云博客专家、华为云享专家。一路走来长期坚守并致力于Python…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

终极指南:使用Python开源工具破解百度网盘限速,实现高速免费下载
终极指南:使用Python开源工具破解百度网盘限速,实现高速免费下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的下载速度而烦恼…...

终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能
终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专为NVIDIA显卡用户设计的免费优化工具&…...

百度网盘直链解析终极指南:如何实现高速下载的完整技术方案
百度网盘直链解析终极指南:如何实现高速下载的完整技术方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在云存储服务普及的今天,百度网盘作为国内用…...

MySQL 索引底层 B+ 树原理
聊 MySQL 索引,不讲 B 树,那就是在耍流氓。 大家好,我是乱码字符。今天咱们深入聊聊 MySQL 索引的底层数据结构——B 树。这篇文章能让你彻底搞明白,为什么有时候明明加了索引,查询却还是慢成狗。 先说说为什么要用树结…...

脉冲神经网络与神经形态计算的能效优化实践
1. 脉冲神经网络与神经形态计算基础脉冲神经网络(SNN)作为第三代神经网络模型,其核心在于模拟生物神经系统的信息处理机制。与传统人工神经网络(ANN)相比,SNN具有三个本质区别:首先,…...

基于GitHub Pages与Jekyll的静态博客搭建与深度定制指南
1. 项目概述:一个静态博客的诞生与演进如果你对搭建个人博客感兴趣,或者正在寻找一个轻量、高效、完全可控的线上空间,那么“RyansGhost/RyansGhost.github.io”这个项目仓库,很可能就是你一直在寻找的答案。这不仅仅是一个托管在…...

天学网口碑好不好?2026年最新用户实测反馈给你答案
作为深耕教育数字化落地领域5年的从业者,最近后台收到不少公立校电教组老师、学生家长的提问:主打AI英语教学的天学网口碑到底怎么样?刚好我们团队刚做完2026年第一季度的英语教育数字化工具落地效果调研,结合一手实测数据给大家客…...

Go语言SDK开发实战:为AI编程助手Cursor构建高效API客户端
1. 项目概述:一个为AI编程助手Cursor定制的Go语言SDK如果你和我一样,日常重度依赖Cursor这类AI编程助手来提升开发效率,同时又是个Go语言的忠实拥趸,那你肯定遇到过这样的场景:想用Go写个脚本,自动化处理一…...

IE11富文本兼容——政务系统前端的深渊
IE11富文本兼容——政务系统前端的深渊 背景:为什么还有 IE11 系统要求支持 IE11。 为什么不是 Chrome? 办公电脑全是 Windows 7 IE11单位统一采购,不能随便装浏览器部分内部网站只支持 IE(ActiveX) 现状&#x…...