Python爬虫实战(实战篇)—16获取【百度热搜】数据—写入Ecel(附完整代码)
文章目录
- 专栏导读
- 背景
- 结果预览
- 1、爬取页面分析
- 2、通过返回数据发现适合利用lxml+xpath
- 3、继续分析【小说榜、电影榜、电视剧榜、汽车榜、游戏榜】
- 4、完整代码
- 总结
专栏导读
🔥🔥本文已收录于《Python基础篇爬虫》
🉑🉑本专栏专门
针对于有爬虫基础准备的一套基础教学,轻松掌握Python爬虫,欢迎各位同学订阅,专栏订阅地址:点我直达
🤞🤞此外如果您已工作,如需利用Python解决办公中常见的问题,欢
迎订阅《Python办公自动化》专栏,订阅地址:点我直达
的
🔺🔺此外《Python30天从入门到熟练》专栏已上线,欢迎大家订阅,订阅地址:点我直达
背景
-
我想利用爬虫获取【百度热搜页面】的全部热搜、包括
-
1、热搜榜
-
2、小说榜
-
3、电影榜
-
4、电视剧榜
-
5、汽车榜
-
6、游戏榜
结果预览


1、爬取页面分析
爬取URL:https://top.baidu.com/board?
爬取方法:GET
返回数据:整个页面(TXT)
-
代码
# -*- coding: UTF-8 -*-
'''
@Project :项目名称
@File :程序.py
@IDE :PyCharm
@Author :一晌小贪欢
@Date :2024/05/27 11:27
'''import json
import openpyxl
import requests
from lxml import etreeurl = 'https://top.baidu.com/board?'
cookies = {'Cookie': '填入自己的Cookie'
}headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',}params = {'platform': 'pc','tab': 'homepage','sa': 'pc_index_homepage_all',
}res_data = requests.get(url=url, params=params, headers=headers, cookies=cookies)
print(res_data.text)-
请求结果

2、通过返回数据发现适合利用lxml+xpath
-
我们发现返回的数据是整个网页,其中每一种热搜均在其页面中
-
热搜榜、小说榜、电影榜、电视剧榜、汽车榜、游戏榜、存在如下div中 ↓

-
获取该【div】(利用lxml+xpath)
-
通过分析得:
//div[@id="sanRoot"]//div[@class="list_1EDla"]//a//div[@class="c-single-text-ellipsis"]-
通过分析发现xpath没问题,但是获的值重复了,所以利用
range(0,len(hot_search),2),只要获取一个就行了

3、继续分析【小说榜、电影榜、电视剧榜、汽车榜、游戏榜】
-
我们发现这几个排行榜,居然使用一个xpath就可以
-
通过分析得:
//div[@id="sanRoot"]//div[@class="list_1s-Px"]//a[@class="title_ZsyAw"]-
【热搜指数】通过分析得:
//div[@id="sanRoot"]//div[@class="list_1s-Px"]//div[@class="exponent_QjyjZ"]//span-
【热搜分类】通过分析得:
//div[@id="sanRoot"]//div[@class="list_1s-Px"]//div[@class="desc_2YkQx"]-
这三个长度都是【50】
-
所以写进列表,进行以10个元素拆分,然后分别写进Excel
4、完整代码
# -*- coding: UTF-8 -*-
'''
@Project :百度热搜爬虫
@File :程序.py
@IDE :PyCharm
@Author :一晌小贪欢
@Date :2024/05/27 11:27
'''import json
import openpyxl
import requests
from lxml import etreewb = openpyxl.Workbook()
ws = wb.active
# 修改sheet名
ws.title = '热搜榜'
ws.append(['热搜榜'])
ws2 = wb.create_sheet('小说榜')
ws2.append(['小说榜'])
ws3 = wb.create_sheet('电影榜')
ws3.append(['电影榜'])
ws4 = wb.create_sheet('电视剧榜')
ws4.append(['电视剧榜'])
ws5 = wb.create_sheet('汽车榜')
ws5.append(['汽车榜'])
ws6 = wb.create_sheet('游戏榜')
ws6.append(['游戏榜'])url = 'https://top.baidu.com/board?'
cookies = {'填入自己的Cookie'
}headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',}params = {'platform': 'pc','tab': 'homepage','sa': 'pc_index_homepage_all',
}res_data = requests.get(url=url, params=params, headers=headers, cookies=cookies)
tree = etree.HTML(res_data.text)'''
热搜榜
'''hot_search = tree.xpath('//div[@id="sanRoot"]//div[@class="list_1EDla"]//a//div[@class="c-single-text-ellipsis"]')
print(len(hot_search))for i in range(0,len(hot_search),2):print(hot_search[i].text)ws.append([hot_search[i].text])
'''
小说榜、电影榜、电视剧榜、汽车榜、游戏榜
'''
hot_search2 = tree.xpath('//div[@id="sanRoot"]//div[@class="list_1s-Px"]//a[@class="title_ZsyAw"]')
# print(len(hot_search))
# 热搜指数
hot_search3 = tree.xpath('//div[@id="sanRoot"]//div[@class="list_1s-Px"]//div[@class="exponent_QjyjZ"]//span')
# 分类
type_ = tree.xpath('//div[@id="sanRoot"]//div[@class="list_1s-Px"]//div[@class="desc_2YkQx"]')
count = 0a_list = []for i in range(len(hot_search2)):# print(hot_search2[i].text+' '+hot_search3[i].text+' '+type_[i].text)a_list.append(hot_search2[i].text+' '+hot_search3[i].text+' '+type_[i].text)# 将a_list 以10个元素拆分成小列表
a_list = [a_list[i:i+10] for i in range(0, len(a_list), 10)]
count = 0
for i in a_list:count+=1if count == 1:for j in i:ws2.append([j])elif count == 2:for j in i:ws3.append([j])elif count == 3:for j in i:ws4.append([j])elif count == 4:for j in i:ws5.append([j])elif count == 5:for j in i:ws6.append([j])wb.save("./整体热搜榜.xlsx")总结
-
希望对初学者有帮助
-
致力于办公自动化的小小程序员一枚
-
希望能得到大家的【一个免费关注】!感谢
-
求个 🤞 关注 🤞
-
此外还有办公自动化专栏,欢迎大家订阅:Python办公自动化专栏
-
求个 ❤️ 喜欢 ❤️
-
此外还有爬虫专栏,欢迎大家订阅:Python爬虫基础专栏
-
求个 👍 收藏 👍
-
此外还有Python基础专栏,欢迎大家订阅:Python基础学习专栏
相关文章:
Python爬虫实战(实战篇)—16获取【百度热搜】数据—写入Ecel(附完整代码)
文章目录 专栏导读背景结果预览1、爬取页面分析2、通过返回数据发现适合利用lxmlxpath3、继续分析【小说榜、电影榜、电视剧榜、汽车榜、游戏榜】4、完整代码总结 专栏导读 🔥🔥本文已收录于《Python基础篇爬虫》 🉑🉑本专栏专门…...
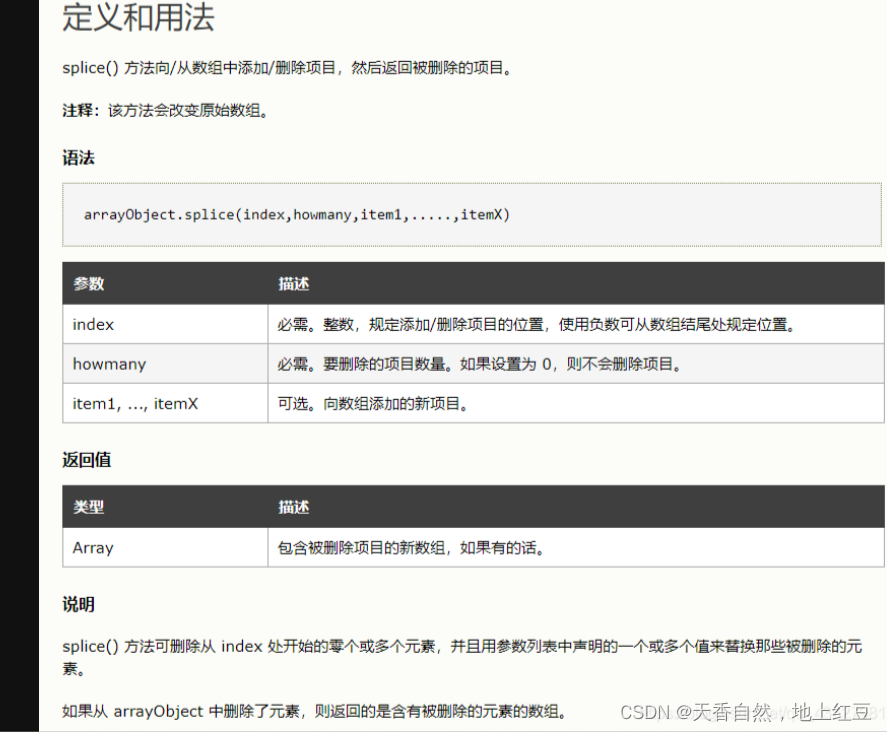
js切割数组的两种方法slice(),splice()
slice() 返回一个索引和另一个索引之间的数据(不改变原数组),slice(start,end)有两个参数(start必需,end选填),都是索引,返回值不包括end 用法和截取字符串一样 splice() 用来添加或者删除数组的数据,只返回被删除的数据,类型为数组(改变原数组) var heroes["李白&q…...

【计算机毕设】基于SpringBoot的医院管理系统设计与实现 - 源码免费(私信领取)
免费领取源码 | 项目完整可运行 | v:chengn7890 诚招源码校园代理! 1. 研究目的 本项目旨在设计并实现一个基于SpringBoot的医院管理系统,以提高医院管理效率,优化医疗服务流程,提升患者就诊体验…...

导线防碰撞警示灯:高压线路安全保障
导线防碰撞警示灯:高压线路安全保障 在广袤的大地上,高压线路如同血脉般纵横交错,然而,在这看似平静的电力输送背后,却隐藏着不容忽视的安全隐患。特别是在那些输电线路跨越道路、施工等区域的路段,线下超…...

【LeetCode 77. 组合】
1. 题目 2. 分析 本题有个难点在于如何保存深搜得到的结果?总结了一下,深搜处理的代码,关于返回值有三大类。 第一类:层层传递,将最深层的结果传上来;这类题有:【反转链表】 第二类࿱…...

element-ui组件table去除下方滚动条,实现鼠标左右拖拽移动表格
时隔多日,再次遇到值得记录的问题。 需求 项目前端使用vue框架,页面使用element-ui进行页面快速搭建。默认的table组件当表格过长时,下方会出现横向的滚动条,便于用户对表格进行左右滑动。考虑到页面美观问题,滚动条…...

【C++】list的使用(上)
🔥个人主页: Forcible Bug Maker 🔥专栏: STL || C 目录 前言🌈关于list🔥默认成员函数构造函数(constructor)析构函数(destructor)赋值运算符重载 …...

【代码随想录训练营】【Day 37】【贪心-4】| Leetcode 840, 406, 452
【代码随想录训练营】【Day 37】【贪心-4】| Leetcode 840, 406, 452 需强化知识点 python list sort的高阶用法,两个key,另一种逆序写法python list insert的用法 题目 860. 柠檬水找零 思路:注意 20 块找零,可以找3张5块升…...

concat是什么?前端开发者必须掌握的数组拼接利器
concat是什么?前端开发者必须掌握的数组拼接利器 在前端开发中,concat是一个极其重要的概念,它能够帮助我们实现数组之间的无缝拼接。那么,concat到底是什么?为什么它在前端开发中如此重要?接下来…...
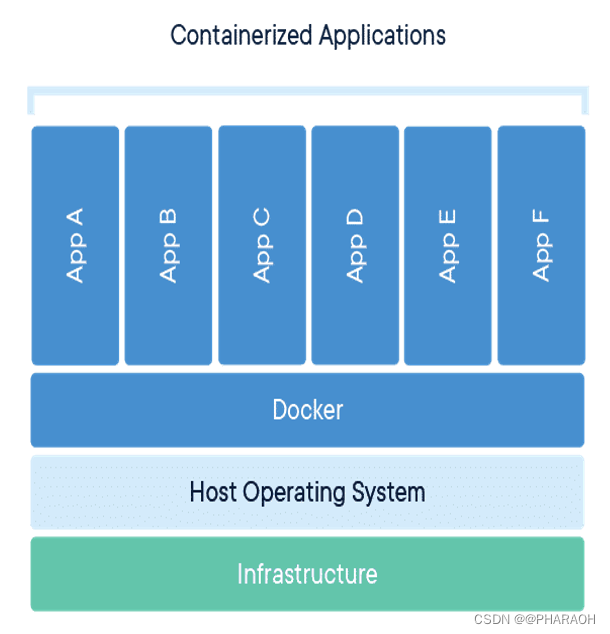
WHAT - 容器化系列(一)
这里写目录标题 一、什么是容器与虚拟机1.1 什么是容器1.2 容器的特点1.3 容器和虚拟机的区别虚拟机(VM):基于硬件的资源隔离技术容器:基于操作系统的资源隔离技术对比总结应用场景 二、容器的实现原理1. Namespace(命…...

QT7_视频知识点笔记_67_项目练习(页面以及对话框的切换,自定义数据类型,DB数据库类的自定义及使用)
视频项目:7----汽车销售管理系统(登录,品牌车管理,新车入库,销售统计图表)-----项目视频没有,代码也不全,更改项目练习:学生信息管理系统。 学生信息管理系统࿱…...
windows10系统64位安装delphiXE11.2完整教程
windows10系统64位安装delphiXE11.2完整教程 https://altd.embarcadero.com/download/radstudio/11.0/radstudio_11_106491a.iso XE11.1 https://altd.embarcadero.com/download/radstudio/11.0/RADStudio_11_2_10937a.iso XE11.2 关键使用文件在以下内容:windows10…...

09.责任链模式
09. 责任链模式 什么是责任链设计模式? 责任链设计模式(Chain of Responsibility Pattern)是一种行为设计模式,它允许将请求沿着处理者对象组成的链进行传递,直到有一个处理者对象能够处理该请求为止。这种模式的目的…...

Amazon云计算AWS(一)
目录 一、基础存储架构Dynamo(一)Dynamo概况(二)Dynamo架构的主要技术 二、弹性计算云EC2(一)EC2的基本架构(二)EC2的关键技术(三)EC2的安全及容错机制 提供的…...
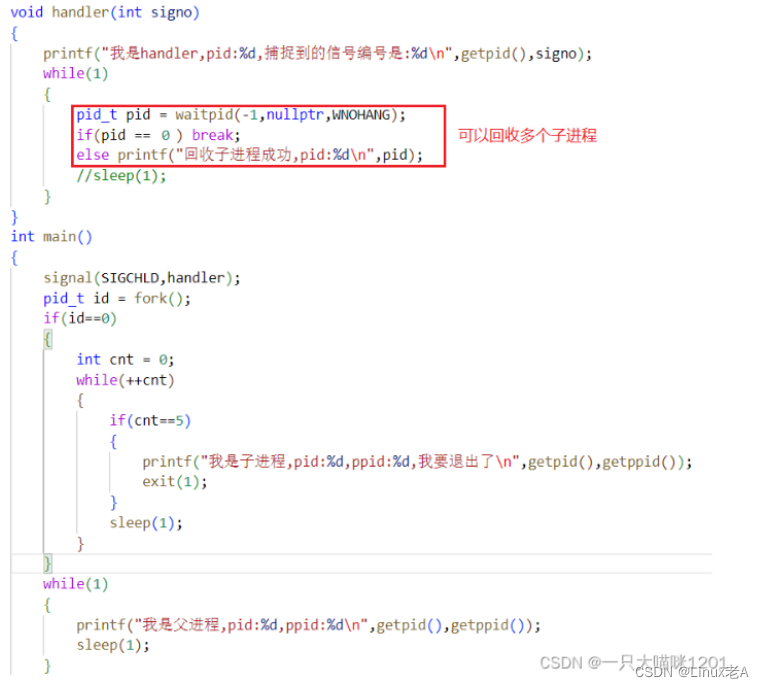
十_信号4-SIGCHLD信号
SIGCHLD信号 在学习进程控制的时候,使用wait和waitpid系统调用何以回收僵尸进程,父进程可以阻塞等待,也可以非阻塞等待,采用轮询的方式不停查询子进程是否退出。 采用阻塞式等待,父进程就被阻塞了,什么都干…...

HCIP的学习(27)
RSTP—802.1W—快速生成树协议 STP缺陷: 1、收敛速度慢----STP的算法是一种被动的算法,依赖于计时器来进行状态变化 2、链路利用率低 RSTP向下兼容STP协议。(STP不兼容RSTP) 改进点1—端口角色 802.1D协议---根端口、指定端口…...
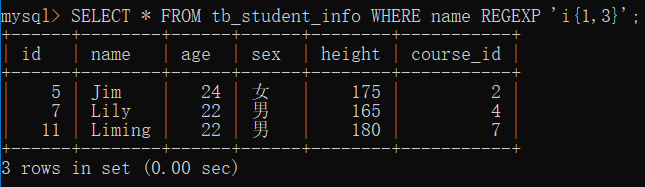
6. MySQL 查询、去重、别名
文章目录 【 1. 数据表查询 SELECT 】1.1 查询表中所有字段使用 * 查询表的所有字段列出表的所有字段 1.2 查询表中指定的字段 【 2. 去重 DISTINCT 】【 3. 设置别名 AS 】3.1 为表指定别名3.2 为字段指定别名 【 5. 限制查询结果的条数 LIMIT 】5.1 指定初始位置5.2 不指定初…...

Oracle导出clob字段到csv
使用UTL_FILE ref: How to Export The Table with a CLOB Column Into a CSV File using UTL_FILE ?(Doc ID 1967617.1) --preapre data CREATE TABLE TESTCLOB(ID NUMBER, MYCLOB1 CLOB, MYCLOB2 CLOB ); INSERT INTO TESTCLOB(ID,MYCLOB1,MYCLOB2) VALUES(1,Sample row 11…...
队列moodycamel::ConcurrentQueue)
C++无锁(lock free)队列moodycamel::ConcurrentQueue
moodycamel::ConcurrentQueue介绍 moodycamel::ConcurrentQueue一个用C++11实现的多生产者、多消费者无锁队列。 它具有以下特点: 1.快的让人大吃一惊,详见不同无锁队列之间的压测对比 2.单头文件实现,很容易集成到你的项目中 3.完全线程安全的无锁队列,支持任意线程数的并…...
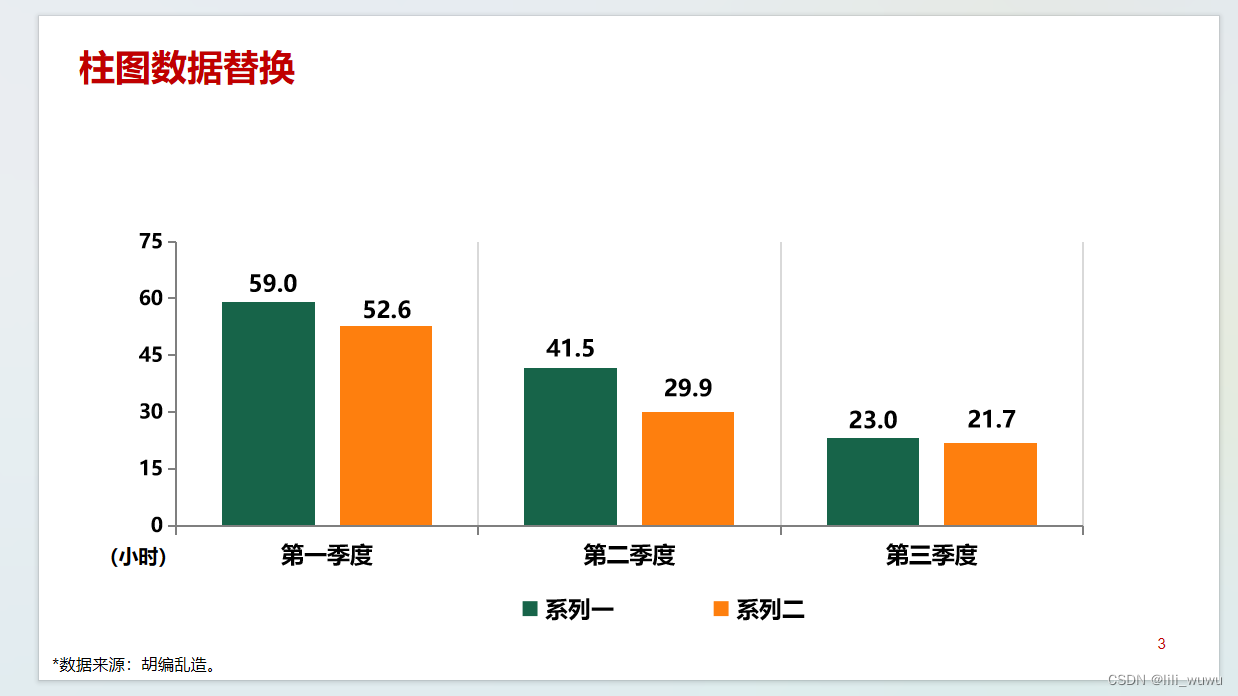
python办公自动化——(二)替换PPT文档中图形数据-柱图
效果: 数据替换前 : 替换数据后: 实现代码 import collections.abc from pptx import Presentation from pptx.util import Cm,Pt import pyodbc import pandas as pd from pptx.chart.data impo…...

5分钟搞定专业照片水印:Semi-Utils让你的摄影作品瞬间升级
5分钟搞定专业照片水印:Semi-Utils让你的摄影作品瞬间升级 【免费下载链接】semi-utils 一个批量添加相机机型和拍摄参数的工具,后续「可能」添加其他功能。 项目地址: https://gitcode.com/gh_mirrors/se/semi-utils 还在为照片添加水印而烦恼吗…...

DAG方法与自变量筛选 【9天实用统计学公益训练营Day3-3】
关注公众号的朋友都知道,郑老师我之前连续4年开设了“30天学会医学统计学”,从理论到实操,一步一步教会大家统计学、SPSS课程。2026年,我们对这门课程进行全新升级!课程时间大幅度缩短,内容大幅度提升&…...

Joy-Con Toolkit:深度解析开源手柄控制框架的技术实现与高级应用
Joy-Con Toolkit:深度解析开源手柄控制框架的技术实现与高级应用 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit Joy-Con Toolkit是一款基于hidapi库开发的开源手柄控制框架,专为任天堂Jo…...

终极ANI-RSS界面定制指南:打造专业级追番体验
终极ANI-RSS界面定制指南:打造专业级追番体验 【免费下载链接】ani-rss 基于RSS自动追番、订阅、下载、刮削、洗版 项目地址: https://gitcode.com/gh_mirrors/an/ani-rss ANI-RSS作为一款基于RSS的自动追番、订阅、下载工具,为动漫爱好者提供了强…...

WinUtil:一键解决Windows系统优化与软件安装的终极指南
WinUtil:一键解决Windows系统优化与软件安装的终极指南 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 你是否曾为新电脑安装系统…...

3个妙招突破百度网盘限速:baidu-wangpan-parse终极解析指南
3个妙招突破百度网盘限速:baidu-wangpan-parse终极解析指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否经历过这样的场景?急着下载一份重要的…...

【测试】一文读懂软件测试:新手真正需要的测试认知
📌 相关专栏 【Linux专栏】【C语言专栏】【测试专栏】 📌 相关文章推荐 【Linux】网络基础2---Socket编程预备【Linux 】网络基础1 哈喽~欢迎来到千余的小天地 ❤ 我会分享很多干货/日常,点个关注不迷路哦~ 👍 点赞 ⭐ 收藏 &…...

AI系统6%误差率为何触发链式崩溃?生产级监控实战指南
1. 项目概述:当6%的失误率成为系统性风险的临界点“The 6% Problem: Why AI Safety Monitoring Isn’t Optional Anymore”这个标题乍看像一篇科技评论,但在我过去十年参与过27个AI系统落地项目(涵盖金融风控、医疗辅助诊断、工业质检、政务智…...

工业智能网关:三菱FX3U PLC数据采集
调试准备: 需要准备的材料:HINET 智能网关、现场安装三菱 FX3U、网线等;网关和 PLC 的连接方式:网关 LAN 口直接和 PLC 网线连接; PLC 和网关的 IP 地址以及现场联网条件说明: 三菱 FX3U 的 IP:…...

E-Hentai Downloader:三步解决漫画批量下载与打包难题的实用指南
E-Hentai Downloader:三步解决漫画批量下载与打包难题的实用指南 【免费下载链接】E-Hentai-Downloader Download E-Hentai archive as zip file 项目地址: https://gitcode.com/gh_mirrors/eh/E-Hentai-Downloader 还在为手动保存上百张漫画图片而烦恼吗&am…...