6. MySQL 查询、去重、别名
文章目录
- 【 1. 数据表查询 SELECT 】
- 1.1 查询表中所有字段
- 使用 * 查询表的所有字段
- 列出表的所有字段
- 1.2 查询表中指定的字段
- 【 2. 去重 DISTINCT 】
- 【 3. 设置别名 AS 】
- 3.1 为表指定别名
- 3.2 为字段指定别名
- 【 5. 限制查询结果的条数 LIMIT 】
- 5.1 指定初始位置
- 5.2 不指定初始位置
- 5.3 LIMIT和OFFSET组合使用
- 【 6. 对查询结果排序 ORDER BY 】
- 6.1 单字段排序
- 6.2 多字段排序
- 【 7. 条件查询 WHERE 】
- 7.1 单一条件的查询
- 7.2 多条件的查询
- 【 8. 模糊查询 LIKE 】
- 8.1 带有 % 通配符的查询
- 8.2 带有 _ 通配符的查询
- 8.3 区分大小写 BINARY LIKE
- 8.4 查询内容中包含通配符
- 【 9. 范围查询 BETWEEN AND 】
- 【 10. 空值查询 IS NULL 】
- 【 11. 分组查询 GROUP BY 】
- 11.1 GROUP BY 单独使用
- 11.2 GROUP BY 与 GROUP_CONCAT()
- 11.3 GROUP BY 与 聚合函数
- 11.4 GROUP BY 与 WITH ROLLUP
- 【 12. 过滤分组 HAVING 】
- 【 13. 交叉连接 CROSS JOIN 】
- 【 14. 内连接 INNER JOIN 】
- 【 15. 外连接 OUTER JOIN 】
- 15.1 左连接 LEFT OUTER JOIN
- 15.2 右连接 RIGHT OUTER JOIN
- 【 16. 子查询 】
- 16.1 子查询嵌套在 SELECT 语句的 WHERE 子句
- IN | NOT IN
- EXISTS | NOT EXISTS
- 16.2 子查询嵌套在 SELECT 语句的 SELECT 子句中
- 16.3 子查询嵌套在 SELECT 语句的 FROM 子句
- 【 17. 正则表达式 REGEXP 】
- 17.1 ^查询以特定字符或字符串开头的记录
- 17.2 $查询以特定字符或字符串结尾的记录
- 17.2 .替代字符串中的任意一个字符
- 17.3 *和+匹配多个字符
- 17.4 匹配指定字符串 REGEXP
- 17.5 匹配指定字符串中的任意一个
- 17.6 匹配指定字符以外的字符
- 17.7 使用{n,}或者{n,m}来指定字符串连续出现的次数
【 1. 数据表查询 SELECT 】
- 基本语法
- {*|<字段列名>}包含星号通配符的字段列表,表示所要查询字段的名称。
- <表 1>,<表 2>…,表 1 和表 2 表示查询数据的来源,可以是单个或多个。
- WHERE <表达式> 是可选项,如果选择该项,将限定查询数据必须满足该查询条件。
- GROUP BY< 字段 >,该子句告诉 MySQL 如何显示查询出来的数据,并按照指定的字段分组。
- [ORDER BY< 字段 >],该子句告诉 MySQL 按什么样的顺序显示查询出来的数据,可以进行的排序有升序(ASC)和降序(DESC),默认情况下是升序。
- [LIMIT[,]],该子句告诉 MySQL 每次显示查询出来的数据条数。
SELECT
{* | <字段列名>}
[
FROM <表 1>, <表 2>…
[WHERE <表达式>
[GROUP BY <group by definition>
[HAVING <expression> [{<operator> <expression>}…]]
[ORDER BY <order by definition>]
[LIMIT[<offset>,] <row count>]
]
1.1 查询表中所有字段
- 查询所有字段是指查询表中所有字段的数据。MySQL 提供了以下 2 种方式查询表中的所有字段。
① 使用“*”通配符查询所有字段。
② 列出表的所有字段。
使用 * 查询表的所有字段
- 一般情况下,除非需要使用表中所有的字段数据,否则最好不要使用通配符 *。虽然使用通配符可以节省输入查询语句的时间,但是获取不需要的列数据通常会 降低查询和所使用的应用程序的效率。使用 * 的优势是,当不知道所需列的名称时,可以通过 * 获取它们。
- SELECT 可以使用 * 查找表中所有字段的数据,语法格式如下:
- 使用 * 查询时,只能按照数据表中字段的顺序进行排列,不能改变字段的排列顺序,数据列按照创建表时的顺序显示。
SELECT * FROM 表名;
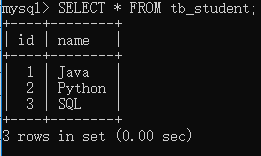
列出表的所有字段
- SELECT 关键字后面的字段名为需要查找的字段,因此可以将表中所有字段的名称跟在 SELECT 关键字后面。如果忘记了字段名称,可以使用 DESC 命令查看表的结构。有时,由于表的字段比较多, 不一定能记得所有字段的名称,因此该方法 很不方便,不建议使用。
- 如果需要 改变字段显示的顺序,只需调整 SELECT 关键字后面的字段列表顺序即可,这种查询方式相对于使用*查询所有字段比较灵活。
- 实例
SELECT id,name FROM tb_student;

1.2 查询表中指定的字段
- 基本语法
SELECT < 列名 > FROM < 表名 >;
- 使用 SELECT 声明可以获取多个字段下的数据,只需要在关键字 SELECT 后面指定要查找的字段名称,不同字段名称之间用逗号 , 分隔开,最后一个字段后面不需要加逗号,语法格式如下:
SELECT <字段名1>,<字段名2>,…,<字段名n> FROM <表名>;
- 实例1
查询 tb_students 表中 name 列所有信息。
SELECT name FROM tb_student;

- 实例2
SELECT id,name FROM tb_student;
【 2. 去重 DISTINCT 】
- 问题背景
在 MySQL 中使用 SELECT 语句执行简单的数据查询时,返回的是所有匹配的记录。如果表中的某些字段没有唯一性约束,那么这些字段就可能存在重复值。为了实现查询不重复的数据,MySQL 提供了 DISTINCT 关键字, DISTINCT 关键字 的主要作用就是对数据表中一个或多个字段重复的数据进行过滤,只返回其中的一条数据给用户。 - 基本语法
- 其中,“字段名”为需要消除重复记录的字段名称,多个字段时用逗号隔开。
- DISTINCT 关键字只能在 SELECT 语句中使用。
- 在对一个或多个字段去重时,DISTINCT 关键字必须在所有字段的最前面。
- 如果 DISTINCT 关键字后有多个字段,则会对多个字段进行组合去重,也就是说,只有多个字段组合起来完全是一样的情况下才会被去重。
SELECT DISTINCT <字段名> FROM <表名>;
- 实例
- 创建1个表tb_student;
CREATE TABLE tb_student
(
id INT(11),
name VARCHAR(25),
age INT(11)
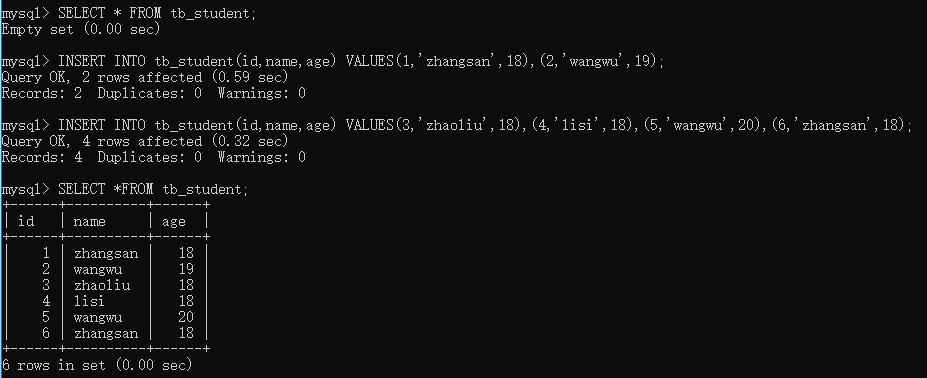
); - 插入数据
INSERT INTO tb_student(id,name,age) VALUES(1,'zhangsan',18),(2,'wangwu',19);
INSERT INTO tb_student(id,name,age) VALUES(3,'zhaoliu',18),(4,'lisi',18),(5,'wangwu',20),(6,'zhangsan',18); - 查看效果。
SELECT *FROM tb_student;
- 对 student 表的 age 字段进行去重。
SELECT DISTINCT age FROM tb_student;

- 对 tb_student 表的 name 和 age 字段进行去重,name和age都重复的记录被去重。
SELECT DISTINCT name,age FROM tb_student;

- 对 tb_student 表中的所有字段进行去重,由于 id 都不同所以无效果。
SELECT DISTINCT * FROM tb_student;
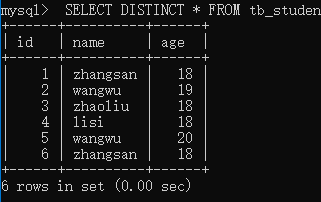
- 创建1个表tb_student;
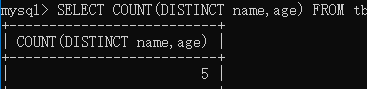
- 因为 DISTINCT 只能返回它的目标字段,而无法返回其它字段,所以在实际情况中,我们经常使用 DISTINCT 关键字来 返回不重复字段的条数。
SELECT COUNT(DISTINCT name,age) FROM tb_student;
【 3. 设置别名 AS 】
- 问题背景
当表名或字段名很长或者执行一些特殊查询的时候,为了方便操作,可以为表或字段指定一个别名,用这个 别名 代替表原来的名称,MySQL 提供了 AS 关键字 来为表和字段指定 别名 。 - 表的别名不能与该数据库的其它表同名 ;
字段的别名不能与该表的其它字段同名 ;
在条件表达式中不能使用字段的别名 ,否则会报错。
3.1 为表指定别名
- 表别名只在执行查询时使用,并不在返回结果中显示 。
- 基本语法
- <表名>:数据库中存储的数据表的名称。
- <别名>:查询时指定的表的新名称。
- AS关键字可以省略 ,省略后需要将表名和别名 用空格隔开。
<表名> [AS] <别名>
- 实例
为 tb_student 表指定别名 stu。
SELECT stu.name,stu.id FROM tb_student AS stu;

3.2 为字段指定别名
- 问题背景
在使用 SELECT 语句查询数据时,MySQL 会显示每个 SELECT 后面指定输出的字段。有时为了显示结果更加直观,我们可以为字段指定一个别名。 - 字段定义别名之后,会返回给客户端显示,显示的字段为字段的别名。
- 基本语法
- <字段名>:为数据表中字段定义的名称。
- <字段别名>:字段新的名称。
- AS关键字可以省略,省略后需要将字段名和别名用空格隔开。
<字段名> [AS] <别名>
- 实例
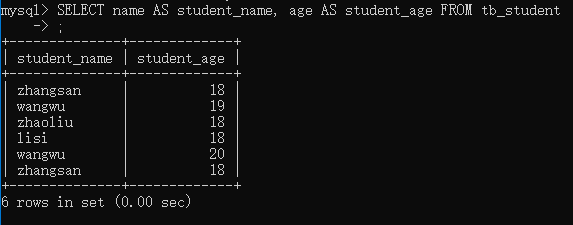
查询 tb_students 表,为 name 指定别名 student_name,为 age 指定别名 student_age。
SELECT name AS student_name, age AS student_age FROM tb_student;
【 5. 限制查询结果的条数 LIMIT 】
- 问题背景
当数据表中有上万条数据时,一次性查询出表中的全部数据会降低数据返回的速度,同时给数据库服务器造成很大的压力。这时就可以用 LIMIT 关键字 来 限制查询结果返回的条数,LIMIT 用于指定查询结果从哪条记录开始显示,一共显示多少条记录,LIMIT 关键字有 3 种使用方式,即指定初始位置、不指定初始位置以及与 OFFSET 组合使用。
5.1 指定初始位置
- LIMIT 关键字可以 指定查询结果从哪条记录开始显示,显示多少条记录。
- 基本语法
- 其中,“初始位置”表示从哪条记录开始显示;“记录数”表示显示记录的条数。第一条记录的位置是 0,第二条记录的位置是 1,后面的记录依次类推 。
- LIMIT 后的两个参数必须都是正整数。
LIMIT 初始位置,记录数
- 实例
在 tb_student 表中,使用 LIMIT 子句返回从第 4 条记录开始后的行数为 2 的记录。由结果可以看到,该语句返回的是从第 4 条记录开始的之后的 2 条记录。LIMIT 关键字后的第一个数字“3”表示从第 4 行开始(记录的位置从 0 开始,第 4 行的位置为 3),第二个数字 2 表示返回的行数。
SELECT * FROM tb_student LIMIT 3,2;

5.2 不指定初始位置
- LIMIT 关键字 不指定初始位置时,记录从第一条记录开始显示,显示记录的条数由 LIMIT 关键字指定。
- 基本语法
- 其中,“记录数”表示显示记录的条数。如果“记录数”的值小于查询结果的总数,则会从第一条记录开始,显示指定条数的记录。如果“记录数”的值大于查询结果的总数,则会直接显示查询出来的所有记录。
- 带一个参数的 LIMIT 指定从查询结果的首行开始,唯一的参数表示返回的行数,即 “LIMIT n”与“LIMIT 0,n”返回结果相同,带两个参数的 LIMIT 可返回从任何位置开始指定行数的数据。
LIMIT 记录数
- 实例1
显示 tb_student 表查询结果的前 4 行。结果中只显示了 4 条记录,说明“LIMIT 4”限制了显示条数为 4。
SELECT * FROM tb_student LIMIT 4;

- 实例2
显示 tb_students_info 表查询结果的前 15 行。
结果中只显示了 6 条记录。虽然 LIMIT 关键字指定了显示 15 条记录,但是查询结果中只有 6 条记录。因此,数据库系统就将这 6 条记录全部显示出来。
SELECT * FROM tb_student LIMIT 15;

5.3 LIMIT和OFFSET组合使用
- 基本语法
- 参数和 LIMIT 语法中参数含义相同,“初始位置”指定从哪条记录开始显示;“记录数”表示显示记录的条数。
LIMIT 记录数 OFFSET 初始位置
- 实例
在 tb_student 表中,使用 LIMIT OFFSET 返回从第 2 条记录开始的行数为 3 的记录。即“LIMIT 3 OFFSET 2”意思是获取从第 2 条记录开始的后面的 3 条记录,和 “LIMIT 2,3” 返回的结果相同。
SELECT * FROM tb_student LIMIT 3 OFFSET 2;

【 6. 对查询结果排序 ORDER BY 】
- 问题背景
通过条件查询语句可以查询到符合用户需求的数据,但是查询到的数据一般都是按照数据最初被添加到表中的顺序来显示。为了使查询结果的顺序满足用户的要求,MySQL 提供了 ORDER BY 关键字 来 对查询结果进行排序。
在实际应用中经常需要对查询结果进行排序,比如,在网上购物时,可以将商品按照价格进行排序;在医院的挂号系统中,可以按照挂号的先后顺序进行排序等。
- 基本语法
- 字段名:表示需要排序的字段名称,多个字段时用逗号隔开。
- ASC|DESC:ASC (ascending) 表示字段按升序排序; DESC (descending)表示字段按降序排序,默认 ASC升序排序。
- ORDER BY 关键字后可以跟子查询。
- 当排序的字段中存在空值时,ORDER BY 会将该空值作为最小值来对待。
- ORDER BY 指定多个字段进行排序时,MySQL 会按照字段的顺序从左到右依次进行排序。
ORDER BY <字段名> [ASC|DESC]
6.1 单字段排序
- 实例
查询 tb_student 表的所有记录,并对 age 字段进行排序
SELECT * FROM tb_student ORDER BY age;

6.2 多字段排序
- 在对多个字段进行排序时,排序的第一个字段必须有相同的值,才会对第二个字段进行排序。如果第一个字段数据中所有的值都是唯一的,MySQL 将不再对第二个字段进行排序。
- 默认情况下,查询数据按字母升序进行排序(A~Z),但数据的排序并不仅限于此,还可以使用 ORDER BY 中的 DESC 对查询结果进行降序排序(Z~A)。
- 实例
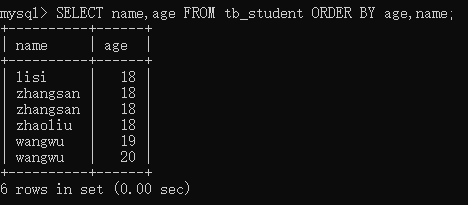
查询 tb_student 表,先按 age 排序,再按 name 排序
SELECT name,age FROM tb_student ORDER BY age,name;
- 实例2
查询 tb_student 表,先按 age 降序排序,再按 name 升序排序。
SELECT name,age FROM tb_student ORDER BY age DESC,name ASC;

【 7. 条件查询 WHERE 】
- 问题背景
在 MySQL 中,如果需要有条件的从数据表中查询数据,可以使用 WHERE 关键字 来 指定查询条件。 - 基本语法
- 查询条件可以是:
带比较运算符和逻辑运算符的查询条件;
带 BETWEEN AND 关键字的查询条件;
带 IS NULL 关键字的查询条件;
带 IN 关键字的查询条件;
带 LIKE 关键字的查询条件。
- 查询条件可以是:
WHERE 查询条件
- 如果根据指定的条件进行查询时,数据表中 没有符合查询条件的记录,系统会提示 Empty set(0.00sec)。
7.1 单一条件的查询
- 单一条件 指的是 在 WHERE 关键字后只有一个查询条件。
- 实例
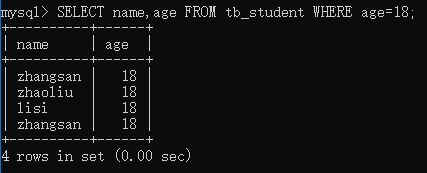
在 tb_student 数据表中查询年龄为 18 的学生姓名。
SELECT name,age FROM tb_student WHERE age=18;
7.2 多条件的查询
- 在 WHERE 关键词后可以有多个查询条件,这样能够使查询结果更加精确,多个查询条件时用逻辑运算符 AND(&&)、OR(||)或 XOR 隔开。
- AND:记录满足所有查询条件时,才会被查询出来。
- OR:记录满足任意一个查询条件时,才会被查询出来。
- XOR:记录满足其中一个条件,并且不满足另一个条件时,才会被查询出来。
- 实例
在 tb_student 表中查询 age = 18,并且 name 等于 “lisi” 的学生信息。
SELECT id,name,age FROM tb_student WHERE age=18 AND name='lisi';

【 8. 模糊查询 LIKE 】
- 在 MySQL 中,LIKE 关键字主要用于搜索匹配字段中的指定内容。
基本语法- NOT :可选参数,字段中的内容与指定的字符串不匹配时满足条件。
- 字符串:指定用来匹配的字符串。“字符串”可以是一个很完整的字符串,也可以包含通配符。
- LIKE 关键字支持百分号“%”和下划线“_”通配符。 通配符 是一种特殊语句,主要用来模糊查询,当不知道真正字符或者懒得输入完整名称时,可以使用通配符来代替一个或多个真正的字符。
- 匹配的 字符串必须加单引号或双引号。
[NOT] LIKE '字符串'
- 注意事项
- 注意大小写,MySQL 默认是不区分大小写的。
- 注意尾部空格,尾部空格会干扰通配符的匹配。
例如,“T% ”就不能匹配到“Tom”。 - 注意 NULL。 % 通配符可以到匹配任意字符,但是不能匹配 NULL 。
- 不要过度使用通配符,如果其它操作符能达到相同的目的,应该使用其它操作符。因为相比于其他操作符,MySQL 对通配符的处理花费时间更长。
- 在确定使用通配符后,除非绝对有必要,否则不要把它们用在字符串的开始处。把通配符置于搜索模式的开始处,搜索起来是最慢的。
8.1 带有 % 通配符的查询
- % 通配符 能 代表任何长度的字符串除了包含NULL,字符串的长度可以为 0。
例如,a%b表示以字母 a 开头,以字母 b 结尾的任意长度的字符串。该字符串可以代表 ab、acb、accb、accrb 等字符串。 - 实例1
在 tb_student 表中,查找所有以字母 “w” 开头的学生姓名。
SELECT name FROM tb_student WHERE name LIKE 'w%';

- 实例2
NOT LIKE 表示字符串不匹配时满足条件。
在 tb_students 表中,查找所有不以字母“w”开头的学生姓名
SELECT name FROM tb_student WHERE name NOT LIKE 'w%';

- 实例3
在 tb_student 表中,查找所有包含字母“l”的学生姓名
SELECT name FROM tb_student WHERE name LIKE '%l%';

8.2 带有 _ 通配符的查询
- _ 通配符 只能代表单个字符,字符的长度不能为 0 。
例如,a_b可以代表 acb、adb、aub 等字符串。 - 实例
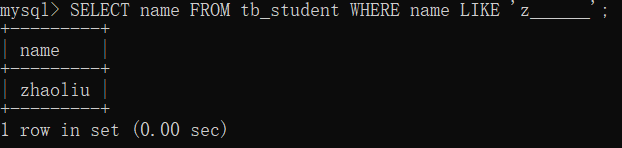
在 tb_student 表中,查找所有以字母“z”开头,且“z”后面只有 6个字母的学生姓名,
SELECT name FROM tb_student WHERE name LIKE 'z______';
8.3 区分大小写 BINARY LIKE
- 默认情况下,LIKE 关键字匹配字符的时候是不区分大小写 的。如果需要区分大小写,可以加入 BINARY 关键字 。
- 基本语法
SELECT 字段 FROM 表名 WHERE 字段 LIKE BINARY 'xx';
8.4 查询内容中包含通配符
- 如果查询内容中包含通配符,可以使用 \转义符 。
- 实例
tb_student 表中,将学生姓名“wangwu”修改为“wangwu%”后,查询以“%”结尾的学生姓名,SQL 语句如下:
SELECT NAME FROM tb_student WHERE NAME LIKE '%\%';
【 9. 范围查询 BETWEEN AND 】
- MySQL 提供了 BETWEEN AND 关键字 ,用来 判断字段的数值是否在指定范围内,包括起始值和终止值。。
- BETWEEN AND 需要两个参数,即范围的起始值和终止值。如果字段值在指定的范围内,则这些记录被返回;如果不在指定范围内,则不会被返回。
基本语法- NOT:可选参数,表示指定范围之外的值。如果字段值不满足指定范围内的值,则这些记录被返回。
- 取值1:表示范围的起始值。
- 取值2:表示范围的终止值。
[NOT] BETWEEN 取值1 AND 取值2
- 实例
在表 tb_student 中查询年龄在 18 到 19 之间的学生姓名和年龄
SELECT name,age FROM tb_student WHERE age BETWEEN 18 AND 19;

【 10. 空值查询 IS NULL 】
- MySQL 提供了 IS NULL 关键字 ,用来 判断字段的值是否为空值(NULL)。空值NULL 不同于 0,也不同于空字符串。如果字段的值是空值,则满足查询条件,该记录将被查询出来。如果字段的值不是空值,则不满足查询条件。
基本语法- “NOT”是可选参数,表示字段值不是空值时满足条件。此时,IS NOT NULL 表示查询字段值不为空的记录。
- IS NULL 是一个整体,不能将 IS 换成 = 。如果将 IS 换成 = 将不能查询出任何结果,数据库系统会出现“Empty set(0.00 sec)”这样的提示。同理,IS NOT NULL 中的 IS NOT 不能换成“!=”或“<>”。
IS [NOT] NULL
- 实例
查询 tb_student 表中 id 字段不为空的记录。
SELECT * FROM tb_student WHERE id IS NOT NULL;

【 11. 分组查询 GROUP BY 】
- 在 MySQL 中, GROUP BY 关键字 可以根据一个或多个字段 对查询结果进行分组。
多个字段分组查询时,会先按照第一个字段进行分组,如果第一个字段中有相同的值,MySQL 才会按照第二个字段进行分组。如果第一个字段中的数据都是唯一的,那么 MySQL 将不再对第二个字段进行分组。
基本语法- 其中,“字段名”表示需要分组的字段名称,多个字段时用逗号隔开。
GROUP BY <字段名>
11.1 GROUP BY 单独使用
- 单独使用 GROUP BY 关键字时,查询结果会只显示每个分组的第一条记录。
- 实例
根据 tb_students_info 表中的 age 字段进行分组查询
SELECT * FROM tb_student_info GROUP BY age;
11.2 GROUP BY 与 GROUP_CONCAT()
- GROUP BY 关键字可以和 GROUP_CONCAT() 函数一起使用。 GROUP_CONCAT() 函数 会 把每个分组的字段值都显示出来。
- 实例1
根据 tb_student 表中的 age 字段进行分组查询,使用 GROUP_CONCAT() 函数将每个分组的 name 字段的值都显示出来。
SELECT age, GROUP_CONCAT(name) FROM tb_student GROUP BY age;

- 实例2
根据 tb_student 表中的 age 和 name 字段进行分组查询,先按照 age 字段进行分组,当 age 字段值相等时,再把 age 字段值相等的记录按照 name 字段进行分组。
SELECT age, GROUP_CONCAT(name) FROM tb_student GROUP BY age,name;

11.3 GROUP BY 与 聚合函数
- 在数据统计时,GROUP BY 关键字经常和聚合函数一起使用。 聚合函数 包括 COUNT(),SUM(),AVG(),MAX() 和 MIN()。
- COUNT() 用来统计记录的条数;
- SUM() 用来计算字段值的总和;
- AVG() 用来计算字段值的平均值;
- MAX() 用来查询字段的最大值;
- MIN() 用来查询字段的最小值。
- 实例
根据 tb_students 表的 age 字段进行分组查询,使用 COUNT() 函数计算每一组的记录数。
SELECT age,COUNT(age) FROM tb_student GROUP BY age;

11.4 GROUP BY 与 WITH ROLLUP
- WITH POLLUP 关键字 用来 在所有记录的最后加上一条记录即统计记录数量,这条记录是上面所有记录的总和。
- 实例
根据 tb_student 表中的 age 字段进行分组查询,并使用 WITH ROLLUP 显示记录的总和。GROUP_CONCAT(name) 显示了每个分组的 name 字段值,同时,最后一条记录的 GROUP_CONCAT(name) 字段的值刚好是上面分组 name 字段值的总和。
SELECT age,GROUP_CONCAT(name) FROM tb_student GROUP BY age WITH ROLLUP;

【 12. 过滤分组 HAVING 】
- 在 MySQL 中,可以使用 HAVING 关键字 和 WHERE 关键字 对分组后的数据进行过滤, HAVING 支持 WHERE 关键字所有的操作符和语法 。
| WHERE | HAVING |
|---|---|
| 一般情况下,WHERE 用于 过滤数据行。 | HAVING 用于 过滤分组。 |
| WHERE 查询条件中不可以使用聚合函数 | HAVING 查询条件中 可以使用聚合函数。 |
| WHERE 在数据 分组前进行过滤 | HAVING 在数据 分组后进行过滤 。 |
| WHERE 针对数据库文件进行过滤, 是 根据数据表中的字段直接进行过滤。 | HAVING 针对查询结果进行过滤, 是 根据前面已经查询出的字段进行过滤。 |
| WHERE 查询条件中不可以使用字段别名 | HAVING 查询条件中 可以使用字段别名。 |
- 基本语法
HAVING <查询条件>
- 实例1:过滤前查询要过滤的字段
使用 HAVING 和 WHERE 关键字查询出 tb_student 表中年龄大于 18 的学生姓名,id和年龄。
因为在 SELECT 关键字后已经查询出了 age 字段,所以 HAVING 和 WHERE 都可以使用。但是如果 SELECT 关键字后没有查询出 age 字段,MySQL 就会报错。
SELECT id,name,age FROM tb_student HAVING age>18;
SELECT id,name,age FROM tb_student WHERE age>18;
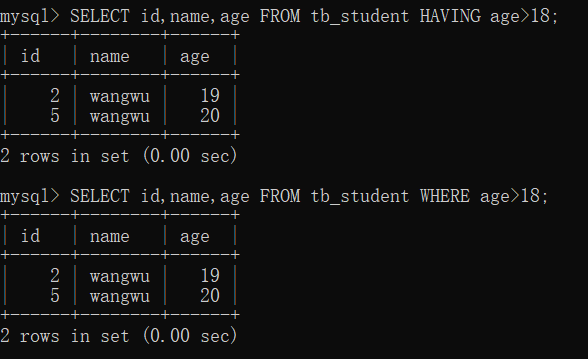
- 实例2:过滤前不查询要过滤的字段
使用 HAVING 和 WHERE 关键字分别出 tb_student 表中年龄大于 18 的学生姓名和 id (与实例1 相比,这次没有查询 age 字段)。
可以看到:如果 SELECT 关键字后没有查询出 HAVING 查询条件中使用的 age 字段,MySQL 会提示错误信息。
SELECT id,name FROM tb_student HAVING age>18;
SELECT id,name FROM tb_student WHERE age>18;

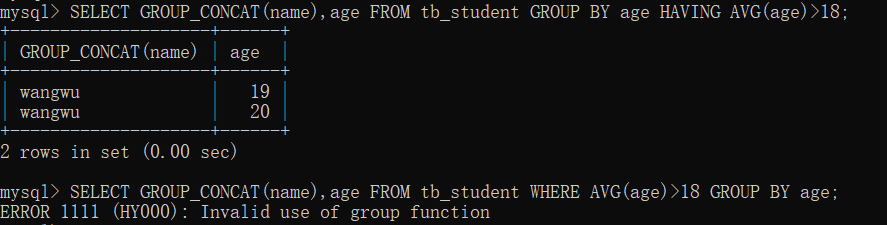
- 实例3:WHER不能使用聚合函数
根据 age 字段对 tb_student 表中的数据进行分组,并使用 HAVING 和 WHERE 关键字分别查询出分组后平均年龄大于 18 的学生姓名、性别和身高。
可以看出,如果在 WHERE 查询条件中使用聚合函数,MySQL 会提示错误信息:无效使用组函数。
SELECT GROUP_CONCAT(name),age FROM tb_student GROUP BY age HAVING AVG(age)>18;
SELECT GROUP_CONCAT(name),age FROM tb_student WHERE AVG(age)>18 GROUP BY age;
【 13. 交叉连接 CROSS JOIN 】
- 问题背景
前面所讲的查询语句都是针对一个表的,但是在关系型数据库中,表与表之间是有联系的,所以在实际应用中,经常使用多表查询, 多表查询 就是 同时查询两个或两个以上的表。在 MySQL 中,多表查询主要有交叉连接、内连接和外连接,多表查询一般使用内连接和外连接,它们的效率要高 于交叉连接。
笛卡尔积(Cartesian product) 是指两个集合 X 和 Y 的乘积。
例如,有 A 和 B 两个集合,它们的值如下:
A = {1,2}
B = {3,4,5}
集合 A×B 和 B×A 的结果就叫两个集合的笛卡尔积:
A×B={(1,3), (1,4), (1,5), (2,3), (2,4), (2,5) };
B×A={(3,1), (3,2), (4,1), (4,2), (5,1), (5,2) };从以上结果我们可以看出:
- 两个集合相乘,不满足交换率,即 A×B≠B×A。
- A 集合和 B 集合的笛卡尔积是 A 集合的元素个数 × B 集合的元素个数。
多表查询遵循的算法就是以上提到的笛卡尔积,表与表之间的连接可以看成是在做乘法运算。
在实际应用中,应 避免使用笛卡尔积,因为笛卡尔积中容易存在大量的不合理数据,简单来说就是容易导致查询结果重复、混乱。
- 交叉连接(CROSS JOIN)一般用来返回连接表的笛卡尔积。
基本语法- 字段名:需要查询的字段名称。
- <表1><表2>:需要交叉连接的表名。
- WHERE 子句:用来设置交叉连接的查询条件。如果在交叉连接时使用 WHERE 子句,MySQL 会先生成两个表的笛卡尔积,然后再选择满足 WHERE 条件的记录。因此,表的数量较多时,交叉连接会非常非常慢,一般情况下 不建议使用交叉连接 。
- 多个表交叉连接时,在 FROM 后连续使用 CROSS JOIN 或 逗号, 即可。
- 以下两种语法的返回结果是相同的,但是第一种语法才是官方建议的标准写法。
SELECT <字段名> FROM <表1> CROSS JOIN <表2> [WHERE子句]或者SELECT <字段名> FROM <表1>, <表2> [WHERE子句]
- 当 连接的表之间没有关系时,我们会省略掉 WHERE 子句,这时返回结果就是两个表的笛卡尔积,返回结果数量就是两个表的数据行相乘。
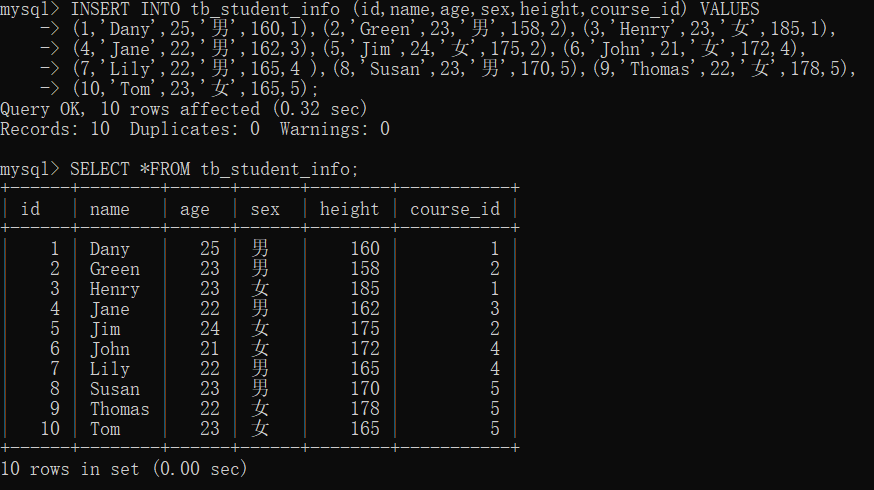
例如,如果每个表有 1000 行,那么返回结果的数量就有 1000×1000 = 1000000 行,数据量是非常巨大的。 - 实例1
- 创建数据表
CREATE TABLE tb_student_info(
id INT(11),
name VARCHAR(25),
age INT(11),
sex VARCHAR(25),
height INT(11),
course_id INT(11)
);
向数据表中插入数据
INSERT INTO tb_student_info (id,name,age,sex,height,course_id) VALUES
(1,'Dany',25,'男',160,1),(2,'Green',23,'男',158,2),(3,'Henry',23,'女',185,1),
(4,'Jane',22,'男',162,3),(5,'Jim',24,'女',175,2),(6,'John',21,'女',172,4),
(7,'Lily',22,'男',165,4 ),(8,'Susan',23,'男',170,5),(9,'Thomas',22,'女',178,5),
(10,'Tom',23,'女',165,5);
- 创建数据表 tb_course
CREATE TABLE tb_course(
id INT(11),
course_name VARCHAR(25)
);
向数据表中插入数据
INSERT INTO tb_course (id,course_name) VALUES
(1,'Java'),
(2,'MySQL'),
(3,'Python'),
(4,'Go'),
(5,'C++');

- 使用 CROSS JOIN 查询出两张表中的笛卡尔积
由运行结果可以看出,tb_course 和 tb_student_info 表交叉连接查询后,返回了 50 条记录。可以想象,当表中的数据较多时,得到的运行结果会非常长,而且得到的运行结果也没太大的意义。所以,通过交叉连接的方式进行多表查询的这种方法并不常用,我们应该尽量避免这种查询。
SELECT * FROM tb_course CROSS JOIN tb_student_info;

- 创建数据表
- 实例
查询 tb_course 表中的 id 字段和 tb_student_info 表中的 course_id 字段相等的内容, SQL 语句和运行结果如下:
SELECT * FROM tb_course CROSS JOIN tb_student_info WHERE tb_student_info.course_id = tb_course.id;

【 14. 内连接 INNER JOIN 】
- 内连接(INNER JOIN) 主要通过设置连接条件的方式,来移除查询结果中某些数据行的交叉连接;简单来说,就是 利用条件表达式来消除交叉连接的某些数据行。
- 内连接使用 INNER JOIN 关键字 连接两张表,并使用 ON 子句 来设置连接条件;如果没有连接条件,INNER JOIN 和 CROSS JOIN 在语法上是等同的,两者可以互换。
基本语法- 字段名:需要查询的字段名称。
- <表1><表2>:需要内连接的表名。
- INNER JOIN :内连接中可以省略 INNER 关键字,只用关键字 JOIN。
- ON 子句:用来设置内连接的连接条件。
- 多个表内连接时,在 FROM 后连续使用 INNER JOIN 或 JOIN 即可。
- INNER JOIN 也可以使用 WHERE 子句指定连接条件,但是 INNER JOIN … ON 语法是官方的标准写法,而且 WHERE 子句在某些时候会影响查询的性能。
SELECT <字段名> FROM <表1> INNER JOIN <表2> [ON子句]
- 实例
在 tb_student_info 表和 tb_course 表之间,使用内连接查询学生姓名和相对应的课程名称。两个表之间的关系通过 INNER JOIN 指定,连接的条件使用 ON 子句给出。
SELECT s.name,c.course_name FROM tb_student_info s INNER JOIN tb_course c
ON s.course_id = c.id;


- PS 题外话:当对多个表进行查询时,要在 SELECT 语句后面指定字段是来源于哪一张表。因此,在多表查询时,SELECT 语句后面的写法是
表名.列名。另外,如果表名非常长的话,也可以给表设置别名,这样就可以直接在 SELECT 语句后面写上表的别名.列名。
【 15. 外连接 OUTER JOIN 】
- 问题背景
内连接的查询结果都是符合连接条件的记录,而 外连接 会先将连接的表分为 基表 和 参考表 ,然后 以基表为依据返回满足和不满足条件的记录 。 - 使用外连接查询时,一定要分清需要查询的结果,是需要显示左表的全部记录还是右表的全部记录,然后选择相应的左连接和右连接。
15.1 左连接 LEFT OUTER JOIN
- 左外连接 又称为 左连接 ,使用 LEFT OUTER JOIN 关键字 连接两个表,并使用 ON 子句 来 设置连接条件。左连接查询时,可以查询出 表1 中的所有记录和 表2 中匹配连接条件的记录;如果 表1 的某行在 表2 中没有匹配行,那么在返回结果中, 表2 的字段值均为 空值(NULL)。
基本语法- 字段名:需要查询的字段名称。
- <表1><表2>:需要左连接的表名。表1”为基表,“表2”为参考表。
- LEFT OUTER JOIN:左连接中可以省略 OUTER 关键字,只使用关键字 LEFT JOIN。
- ON 子句:用来设置左连接的连接条件,不能省略。多个表左/右连接时,在 ON 子句后连续使用 LEFT/RIGHT OUTER JOIN 或 LEFT/RIGHT JOIN 即可。
SELECT <字段名> FROM <表1> LEFT OUTER JOIN <表2> <ON子句>
- 实例
- 先在数据表tb_student中插入一条新记录。LiMing 的 id =7,在 tb_course 表中没有 course_id 也等于7 的记录。
INSERT INTO tb_student_info(id,name,age,sex,height,course_id) VALUES(11,'Liming',22,'男',180,7); - 在 tb_student_info 表和 tb_course 表中查询所有学生姓名和相对应的课程名称,包括没有课程的学生。
name 为 LiMing 的学生目前没有课程,因为对应的 tb_course 表中没有该学生的课程信息,所以该条记录只取出了 tb_student_info 表中相应的值,而从 tb_course 表中取出的值为 NULL。
- 先在数据表tb_student中插入一条新记录。LiMing 的 id =7,在 tb_course 表中没有 course_id 也等于7 的记录。
SELECT s.name,c.course_name FROM tb_student_info s LEFT OUTER JOIN tb_course c
ON s.`course_id`=c.`id`;

15.2 右连接 RIGHT OUTER JOIN
- 右外连接 又称为 右连接 ,右连接是左连接的反向连接。使用 RIGHT OUTER JOIN 关键字 连接两个表,并使用 ON 子句 来 设置连接条件。右连接查询时,可以查询出 表2 中的所有记录和 表1 中匹配连接条件的记录。如果“表2”的某行在“表1”中没有匹配行,那么在返回结果中,“表1”的字段值均为空值(NULL)。
基本语法- 字段名:需要查询的字段名称。
- <表1><表2>:需要右连接的表名。与左连接相反,右连接以“表2”为基表,“表1”为参考表。
- RIGHT OUTER JOIN:右连接中可以省略 OUTER 关键字,只使用关键字 RIGHT JOIN。
- ON 子句:用来设置右连接的连接条件,不能省略。
SELECT <字段名> FROM <表1> RIGHT OUTER JOIN <表2> <ON子句>
- 实例
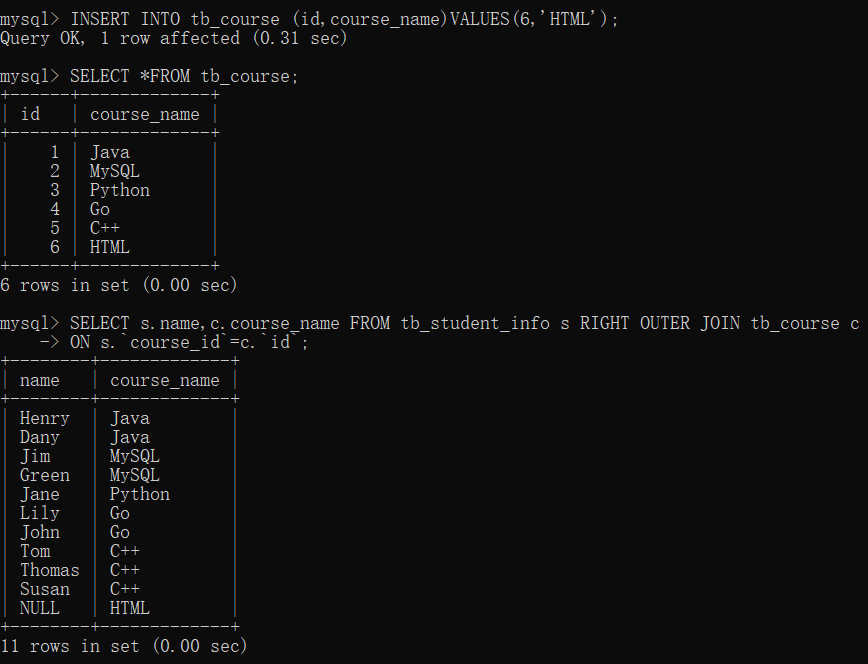
- 先在 tb_course 表中插入一条新记录。
INSERT INTO tb_course (id,course_name)VALUES(6,'HTML'); - 在 tb_student_info 表和 tb_course 表中查询所有课程,包括没有学生的课程。
可以看到,名称为 HTML 的课程目前没有学生,因为对应的 tb_student_info 表中并没有该学生的信息,所以该条记录只取出了 tb_course 表中相应的值,而从 tb_students_info 表中取出的值为 NULL。
- 先在 tb_course 表中插入一条新记录。
SELECT s.name,c.course_name FROM tb_student_info s RIGHT OUTER JOIN tb_course c
ON s.`course_id`=c.`id`;
【 16. 子查询 】
- 子查询 是指 将一个查询语句嵌套在另一个查询语句中,通过子查询可以实现多表查询。习惯上,外层的查询称为 父查询 ,圆括号中嵌入的查询称为 子查询 (子查询必须放在圆括号内)。MySQL执行流程为:先执行子查询,再执行父查询。
- 子查询语句可以嵌套在 SQL 语句中任何表达式出现的位置;子查询可以在 SELECT、UPDATE 和 DELETE 语句中使用,而且可以进行多层嵌套。
- 在 SELECT 语句中,子查询可以被嵌套在 SELECT 语句的列、表和查询条件中,即 SELECT 子句, FROM 子句、WHERE 子句、GROUP BY 子句和 HAVING 子句。
- 在实际开发时,子查询经常出现在 WHERE 子句中。
- 子查询的功能也可以通过表连接完成,但是子查询会使 SQL 语句更容易阅读和编写。一般来说,表连接(内连接和外连接等)都可以用子查询替换,但反过来却不一定,有的子查询不能用表连接来替换。子查询比较灵活、方便、形式多样,子查询适合作为查询的筛选条件,而表连接更适合于查看连接表的数据。
16.1 子查询嵌套在 SELECT 语句的 WHERE 子句
- 基本语法
- 其中,操作符可以是 比较运算符 和 IN、NOT IN、EXISTS、NOT EXISTS 等关键字 。
WHERE <表达式> <操作符> (子查询)
IN | NOT IN
- 当 表达式与子查询返回的结果集中的某个值相等 时,返回 TRUE;否则返回 FALSE;若使用关键字 NOT,则返回值正好相反。
- 实例1:嵌套查询
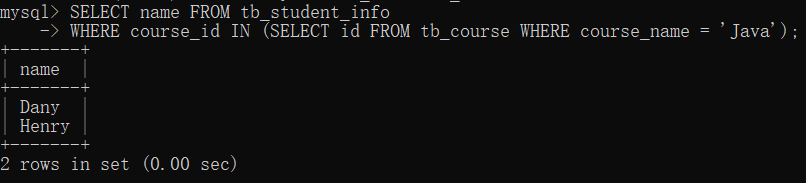
使用子查询在 tb_student_info 表和 tb_course 表中查询学习 Java 课程的学生姓名。
结果显示,学习 Java 课程的只有 Dany 和 Henry。
SELECT name FROM tb_student_info
WHERE course_id IN (SELECT id FROM tb_course WHERE course_name = 'Java');
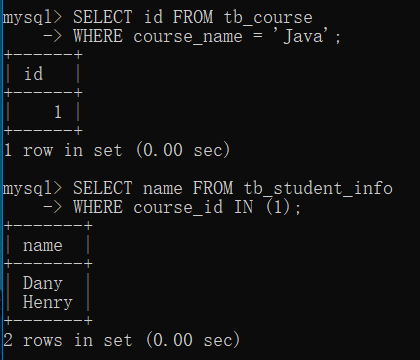
- 实例2:分开查询,最后效果和实例1一样。
- 首先单独执行内查询,查询出 tb_course 表中课程为 Java 的 id。
可以看到,符合条件的 id 字段的值为 1。
SELECT id FROM tb_course
WHERE course_name = 'Java'; - 然后执行外层查询,在 tb_student_info 表中查询 course_id 等于 1 的学生姓名。
SELECT name FROM tb_student_info
WHERE course_id IN (1);
- 首先单独执行内查询,查询出 tb_course 表中课程为 Java 的 id。
EXISTS | NOT EXISTS
- 用于 判断子查询的结果集是否为空,若子查询的结果集不为空,返回 TRUE;否则返回 FALSE;若使用关键字 NOT,则返回的值正好相反。
- EXISTS 关键字可以和其它查询条件一起使用,条件表达式与 EXISTS 关键字之间用 AND 和 OR 连接。
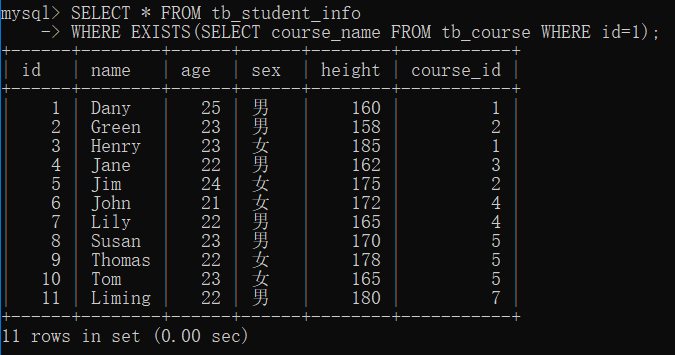
- 实例
查询 tb_course 表中是否存在 id=1 的课程,如果存在,就查询出 tb_student_info 表中的记录。
由结果可以看到,tb_course 表中存在 id=1 的记录,因此 EXISTS 表达式返回 TRUE,外层查询语句接收 TRUE 之后对表 tb_students_info 进行查询,返回所有的记录。
SELECT * FROM tb_student_info
WHERE EXISTS(SELECT course_name FROM tb_course WHERE id=1);
16.2 子查询嵌套在 SELECT 语句的 SELECT 子句中
- 基本语法
- 子查询结果为单行单列,但不必指定列别名。
SELECT (子查询) FROM 表名;
16.3 子查询嵌套在 SELECT 语句的 FROM 子句
- 基本语法
- 必须为表指定别名。一般返回多行多列数据记录,可以当作一张临时表。
SELECT * FROM (子查询) AS 表的别名;
- 只出现在子查询中而没有出现在父查询中的表不能包含在输出列中 。
- 多层嵌套子查询的最终数据集只包含父查询(即最外层的查询)的 SELECT 子句中出现的字段,而子查询的输出结果通常会作为其外层子查询数据源或用于数据判断匹配。
常见错误如:SELECT * FROM (SELECT * FROM result);
这个子查询语句产生语法错误的原因在于主查询语句的 FROM 子句是一个子查询语句,因此应该为子查询结果集指定别名。正确代码如下。
SELECT * FROM (SELECT * FROM result) AS Temp;
【 17. 正则表达式 REGEXP 】
- 正则表达式 主要用来 查询和替换符合某个模式(规则)的文本内容。
例如,从一个文件中提取电话号码,查找一篇文章中重复的单词、替换文章中的敏感语汇等,这些地方都可以使用正则表达式。正则表达式强大且灵活,常用于非常复杂的查询。
- MySQL 中,使用 REGEXP 关键字 指定正则表达式的字符匹配模式。
基本语法- “属性名”表示需要查询的字段名称;
- “匹配方式”表示以哪种方式来匹配查询;“匹配方式”中有很多的模式匹配字符,它们分别表示不同的意思。
属性名 REGEXP '匹配方式'
- MySQL 中的正则表达式与 Java 语言、PHP 语言等编程语言中的正则表达式基本一致。下表列出了 REGEXP 操作符中常用的匹配方式。
| 选项 | 说明 | 例子 | 匹配值示例 |
|---|---|---|---|
| ^ | 匹配文本的开始字符 | ‘^b’ 匹配以字母 b 开头的字符串 | book、big、banana、bike |
| $ | 匹配文本的结束字符 | ‘st$’ 匹配以 st 结尾的字符串 | test、resist、persist |
| . | 匹配任何单个字符 | ‘b.t’ 匹配任何 b 和 t 之间有一个字符 | bit、bat、but、bite |
| * | 匹配零个或多个在它前面的字符 | ‘f*n’ 匹配字符 n 前面有任意个字符 f | fn、fan、faan、abcn |
| + | 匹配前面的字符 1 次或多次 | ‘ba+’ 匹配以 b 开头,后面至少紧跟一个a | ba、bay、bare、battle |
| <字符串> | 匹配包含指定字符的文本 | ‘fa’ 匹配包含‘fa’的文本 | fan、afa、faad |
| [字符集合] | 匹配字符集合中的任何一个字符 | ‘[xz]’ 匹配 x 或者 z | dizzy、zebra、x-ray、extra |
| [^] | 匹配不在括号中的任何字符 | ‘[^abc]’ 匹配任何不包含 a、b 或 c 的字符串 | desk、fox、f8ke |
| 字符串{n,} | 匹配前面的字符串至少 n 次 | ‘b{2}’ 匹配 2 个或更多的 b | bbb、bbbb、bbbbbbb |
| 字符串 {n,m} | 匹配前面的字符串至少 n 次, 至多 m 次 | ‘b{2,4}’ 匹配最少 2 个,最多 4 个 b | bbb、bbbb |
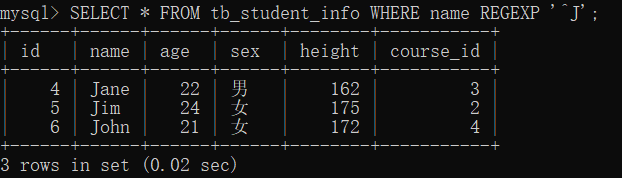
17.1 ^查询以特定字符或字符串开头的记录
- 字符^ 用来匹配以特定字符或字符串开头的记录。
- 实例
在 tb_students_info 表中,查询 name 字段以“J”开头的记录。
SELECT * FROM tb_student_info WHERE name REGEXP '^J';
17.2 $查询以特定字符或字符串结尾的记录
- 字符$ 用来匹配以特定字符或字符串结尾的记录。
- 实例
在 tb_student_info 表中,查询 name 字段以“y”结尾的记录。
SELECT * FROM tb_student_info WHERE name REGEXP 'y$';

17.2 .替代字符串中的任意一个字符
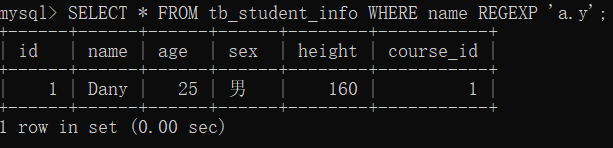
- 小数点字符. 用来替代字符串中的任意一个字符。
- 实例
SELECT * FROM tb_student_info WHERE name REGEXP 'a.y';
17.3 *和+匹配多个字符
- 字符*和+ 都可以匹配多个该符号之前的字符。不同的是,+表示至少一个字符,而*可以表示 0 个字符。
- 实例
在 tb_student_info 表中,查询 name 字段值包含字母“T”,且“T”后面出现字母“h”的记录。
SELECT * FROM tb_student_info WHERE name REGEXP '^Th*';

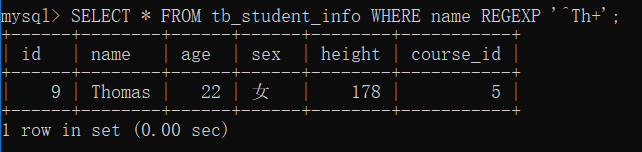
- 实例
在 tb_student_info 表中,查询 name 字段值包含字母“T”,且“T”后面至少出现“h”一次的记录,
SELECT * FROM tb_student_info WHERE name REGEXP '^Th+';
17.4 匹配指定字符串 REGEXP
- 正则表达式可以匹配字符串。当表中的记录包含这个字符串时,就可以将该记录查询出来。指定多个字符串时,需要用|隔开。只要匹配这些字符串中的任意一个即可。
- 实例
在 tb_student_info 表中,查询 name 字段值包含字符串“an”的记录。
SELECT * FROM tb_student_info WHERE name REGEXP 'an';

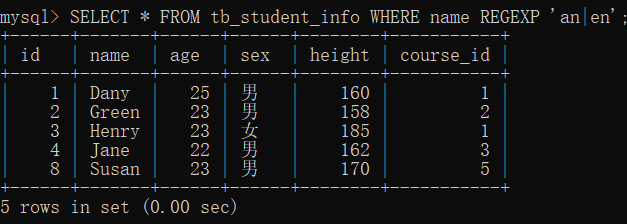
- 实例
在 tb_student_info 表中,查询 name 字段值包含字符串“an”或“en”的记录。
SELECT * FROM tb_student_info WHERE name REGEXP 'an|en';
17.5 匹配指定字符串中的任意一个
- 使用方括号[ ] 可以将需要查询的字符组成一个字符集合。只要记录中包含方括号中的任意字符,该记录就会被查询出来。
例如,通过“[abc]”可以查询包含 a、b 和 c 等 3 个字母中任意一个的记录。 - 实例1
在 tb_student_info 表中,查询 name 字段值包含字母“i”或“o”的记录。
从查询结果可以看到,所有返回记录的 name 字段值都包含字母 i 或 o,或者两个都有。
方括号[ ]还可以指定集合的区间。例如,“[a-z]”表示从 a~z 的所有字母;“[0-9]”表示从 0~9 的所有数字;“[a-z0-9]”表示包含所有的小写字母和数字;“[a-zA-Z]”表示匹配所有字符。
SELECT * FROM tb_student_info WHERE name REGEXP '[io]';

- 实例2
在 tb_student_info 表中,查询 name 字段值中包含 1、2 或 3 的记录。
SELECT * FROM tb_student_info WHERE name REGEXP '[123]';

17.6 匹配指定字符以外的字符
- [^字符集合]用来匹配 不在指定集合中的任何字符。
- 实例
在 tb_student_info 表中,查询 name 字段值包含字母 a~t 以外的字符的记录。
可以看到 Dany、Henrry、Lily、Susan 存在y这个指定范围以外的字符,所以被筛选出来。
SELECT * FROM tb_student_info WHERE name REGEXP '[^a-t]' ;

17.7 使用{n,}或者{n,m}来指定字符串连续出现的次数
- 字符串{n,}表示字符串连续出现 n 次;字符串{n,m}表示字符串连续出现至少 n 次,最多 m 次。
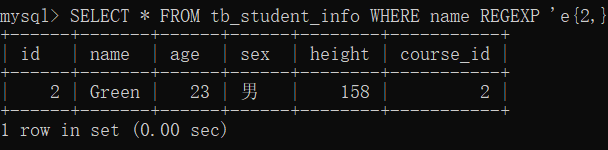
例如,a{2,} 表示字母 a 连续出现至少 2 次,也可以大于 2 次;a{2,4} 表示字母 a 连续出现最少 2 次,最多不能超过 4 次。 - 实例
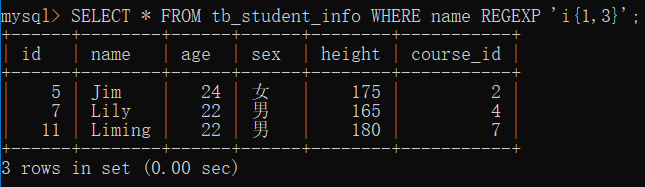
在 tb_student_info 表中,查询 name 字段值出现字母‘e’ 至少 2 次的记录。
SELECT * FROM tb_student_info WHERE name REGEXP 'e{2,}';
- 实例
在 tb_student_info 表中,查询 name 字段值出现字符串“i” 最少 1 次,最多 3 次的记录。
SELECT * FROM tb_student_info WHERE name REGEXP 'i{1,3}';
相关文章:
6. MySQL 查询、去重、别名
文章目录 【 1. 数据表查询 SELECT 】1.1 查询表中所有字段使用 * 查询表的所有字段列出表的所有字段 1.2 查询表中指定的字段 【 2. 去重 DISTINCT 】【 3. 设置别名 AS 】3.1 为表指定别名3.2 为字段指定别名 【 5. 限制查询结果的条数 LIMIT 】5.1 指定初始位置5.2 不指定初…...

Oracle导出clob字段到csv
使用UTL_FILE ref: How to Export The Table with a CLOB Column Into a CSV File using UTL_FILE ?(Doc ID 1967617.1) --preapre data CREATE TABLE TESTCLOB(ID NUMBER, MYCLOB1 CLOB, MYCLOB2 CLOB ); INSERT INTO TESTCLOB(ID,MYCLOB1,MYCLOB2) VALUES(1,Sample row 11…...
队列moodycamel::ConcurrentQueue)
C++无锁(lock free)队列moodycamel::ConcurrentQueue
moodycamel::ConcurrentQueue介绍 moodycamel::ConcurrentQueue一个用C++11实现的多生产者、多消费者无锁队列。 它具有以下特点: 1.快的让人大吃一惊,详见不同无锁队列之间的压测对比 2.单头文件实现,很容易集成到你的项目中 3.完全线程安全的无锁队列,支持任意线程数的并…...
python办公自动化——(二)替换PPT文档中图形数据-柱图
效果: 数据替换前 : 替换数据后: 实现代码 import collections.abc from pptx import Presentation from pptx.util import Cm,Pt import pyodbc import pandas as pd from pptx.chart.data impo…...
vue不同页面切换的方式(Vue动态组件)
v-if实现 <!--Calender.vue--> <template><a-calendar v-model:value"value" panelChange"onPanelChange" /></template> <script setup> import { ref } from vue; const value ref(); const onPanelChange (value, mod…...
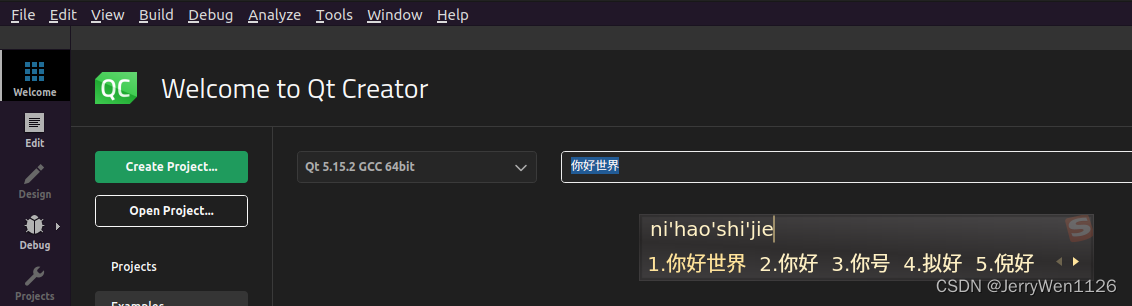
Linux下Qt Creator无法输入中文(已解决)
1. 首先确保安装了搜狗输入法,且能正常运行。 2.克隆源码到本地。 git clone https://gitcode.com/fcitx/fcitx-qt5.git 3.检查Qt Creator版本,如下图所示,为基于Qt6的。 4. 进入源码目录,建立build文件夹,修改CMak…...
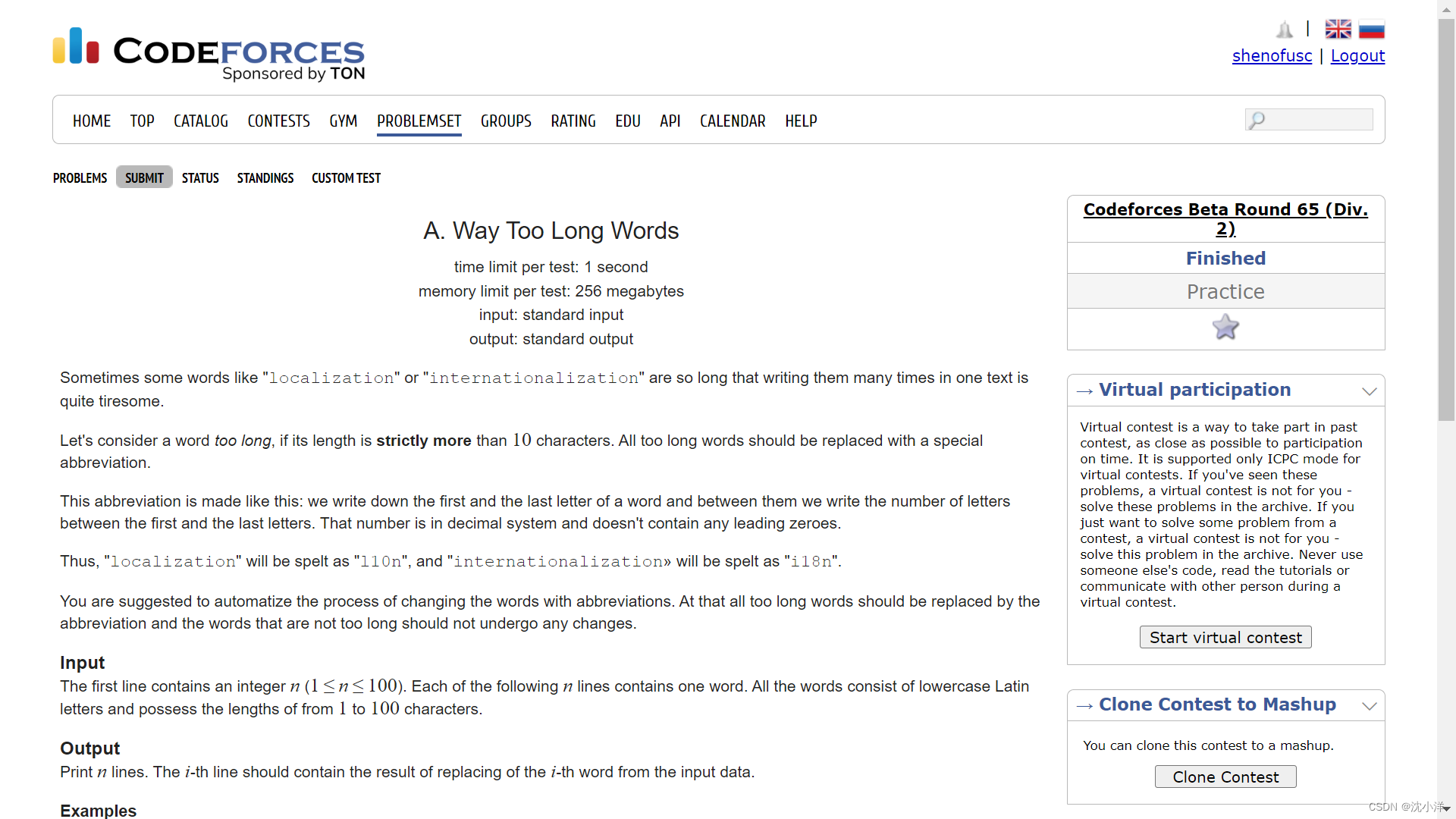
Codeforces 提交Java代码(自己处理输入输出)
示例一(A. Watermelon) 题目地址 Problem - 4A - Codeforces 题目截图 提交方式 可以提交本地文件,也可以在线提交。我们这里选择在线提交方式,点击上图中的 SUBMIT 按钮,会进入如下界面。 输入Java代码效果如下&a…...

剖析vue中nextTick源码
代码逻辑梳理: callbacks 数组用于存储待执行的回调函数,waiting 变量用于标记是否有待执行的回调函数。 flushCallbacks 函数用于执行所有存储在 callbacks 数组中的回调函数,并在执行完成后将 waiting 设置为 false。 timer 函数根据环境…...
SSM牙科诊所管理系统-计算机毕业设计源码98077
目 录 摘要 1 绪论 1.1研究目的与意义 1.2国内外研究现状 1.3ssm框架介绍 1.4论文结构与章节安排 2 牙科诊所管理系统系统分析 2.1 可行性分析 2.1.1 技术可行性分析 2.1.2 经济可行性分析 2.1.3 法律可行性分析 2.2 系统功能分析 2.2.1 功能性分析 2.2.2 非功能…...

【C++进阶】深入STL之string:模拟实现走进C++字符串的世界
📝个人主页🌹:Eternity._ ⏩收录专栏⏪:C “ 登神长阶 ” 🤡往期回顾🤡:C模板入门 🌹🌹期待您的关注 🌹🌹 ❀STL之string 📒1. string…...

go语言linux安装
下载:https://go.dev/dl/ 命令行使用 wget https://dl.google.com/go/go1.19.3.linux-amd64.tar.gz解压下载的压缩包,linux建议放在/opt目录下 我放在/home/ihan/go_sdk下 sudo tar -C /home/ihan/go_sdk -xzf go1.19.3.linux-amd64.tar.gz 这里的参数…...

vi和vim有什么不同?
vi 和 vim 都是流行的文本编辑器,它们之间有以下主要区别: 历史: vi 是一个非常古老的文本编辑器,最初由 Bill Joy 在 1976 年为 Unix 系统编写。vim(Vi IMproved)是 vi 的一个增强版,由 Bram M…...
)
CSS动画效果(鼠标滑过按钮动画)
1.整体效果 https://mmbiz.qpic.cn/sz_mmbiz_gif/EGZdlrTDJa5SXiaicFfsrcric7TJmGO6YddqC4wFPdM7PGzPHuFgvtDS7MIvnLHB4WFaKia0Qh8VCyUaoyHMc2Zltg/640?wx_fmtgif&fromappmsg&tpwebp&wxfrom5&wx_lazy1&wx_co1 网页设计中的按钮不仅是用户交互的桥梁&#…...

数据结构(C):从初识堆到堆排序的实现
目录 🌞0.前言 🚈 1.堆的概念 🚈 2.堆的实现 🚝2.1堆向下调整算法 🚝2.2堆的创建(堆向下调整算法) ✈️2.2.1 向下调整建堆时间复杂度 🚝2.3堆向上调整算法 🚝2.…...
ChatGLM3-6B部署
ZhipuAI/chatglm3-6b 模型文件地址 chatglm3-6B-32k-int4 量化的模型地址 ChatGLM3 代码仓库 ChatGLM3 技术文档 cpolar http xxx 端口 /anaconda3/envs/chatglm2/lib/python3.8/site-packages/gradio$ networking.py 硬件环境 最低要求: 为…...

代码随想录35期Day54-JavaScript
Day54题目 ### LeetCode739每日温度 核心思想:今天主要是学会单调栈的使用.找到比元素更大的下一个元素,如果比栈顶元素小就入栈,否则就出栈顶元素,当前元素就是比栈顶元素大的"下一个更大的元素". /*** param {number[]} temperatures* return {number[]}*/ var …...

把自己的服务器添加到presearch节点
Presearch is a scam. Before, judging by the price of the token you should have been able to get between $150-$200 after 12-13 months of regular searches. "If you use this service for the next 11 years you will have earned $30!" Presearch大约需要…...

Open3D(C++) OTSU点云二值化
目录 一、算法原理二、代码实现三、结果展示1、原始点云2、二值化本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT。 一、算法原理 最大类间方差法(Between-class scatter method)是一种用于分割的方法,它通过计算图…...

浔川python社获得全网博主原力月度排名泸州地区第二名!
今日,浔川python社在查看全网博主原力月度排名泸州地区时,一看就震惊啦! 全网博主原力月度排名泸州地区排名榜单 全网博主原力月度排名泸州地区第二名为:浔川python社。 感谢粉丝们的支持!浔川python社还会继续努力&a…...
)
第二站:Java——集合框架的深邃海洋(续)
### Java——集合框架的深邃海洋(续) 在我们的Java集合框架探索之旅中,我们已经涉足了基本操作、高级特性,现在让我们深入探讨一些特定场景下的应用和进阶技巧,比如集合的分区操作、分组、并行流的性能考量࿰…...

自主智能体框架构建指南:从LLM工具调用到多任务规划系统
1. 项目概述:一个能“开疆拓土”的智能体框架最近在开源社区里,一个名为njbrake/agent-of-empires的项目引起了我的注意。光看这个名字,就充满了野心和想象力——“帝国的代理人”。这可不是一个简单的脚本工具,而是一个旨在构建能…...

Vibe Coding Playbook:从环境到心流,打造高效愉悦的编程系统
1. 项目概述:一个关于“氛围感编程”的实践指南最近在GitHub上看到一个挺有意思的项目,叫“Vibe Coding Playbook”。乍一看这个标题,可能会有点摸不着头脑——“Vibe Coding”是什么?是某种新的编程范式吗?还是某种神…...

5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南
5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南 【免费下载链接】SerialAssistant A serial port assistant that can be used directly in the browser. 项目地址: https://gitcode.com/gh_mirrors/se/SerialAssistant 你是否还在为串口调试工具…...

机械臂时间冲击最优轨迹规划【附代码】
✨ 长期致力于串联机械臂、时间-冲击最优、轨迹规划、多目标粒子群算法、非支配排序遗传算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)构建基于…...

PowerInfer:基于稀疏激活的LLM推理引擎,消费级GPU运行百亿大模型
1. 项目概述:当大模型推理遇见“热点激活”最近在折腾本地大模型部署的朋友,可能都绕不开一个核心痛点:显存。动辄几十GB的模型,配上动辄几十GB的推理显存需求,让消费级显卡(比如我们常见的24GB显存的RTX 4…...

U64JSON编码技术解析与Iris框架性能优化
1. Iris框架与U64JSON编码技术解析 在嵌入式系统和高性能计算领域,数据交换效率直接影响整体系统性能。传统JSON虽然具有可读性好、跨平台等优势,但其文本特性带来的解析开销和带宽占用成为性能瓶颈。Arm Iris框架采用的U64JSON编码方案,通过…...

dotAI:将AI能力环境化,打造可配置的智能开发工作流
1. 项目概述:当AI成为你的“数字管家”最近在GitHub上看到一个挺有意思的项目,叫udecode/dotai。乍一看这个标题,你可能和我最初的反应一样,有点摸不着头脑。dotai?是“点AI”的意思吗?它和.env文件那种“点…...

PPO 原理与应用
1. PPO 在 RLHF 里到底是干什么的? 在 RLHF 里,我们通常已经有了一个经过 SFT 的模型。这个模型已经比较会回答问题了,但还不一定最符合人类偏好。 于是我们再训练一个 奖励模型 Reward Model,让它模仿人类判断: 这个回…...

赛车电气系统设计的现代化转型与实践
1. 赛车电气系统设计的现状与挑战当人们谈论赛车技术时,脑海中浮现的往往是碳纤维车身、空气动力学套件或是大马力发动机。但在这光鲜亮丽的表象背后,电气系统才是现代赛车的"神经系统"。有趣的是,这个关键领域的设计方法却呈现出两…...

Akebi-GC游戏辅助工具:5个核心模块深度解析与实战应用指南
Akebi-GC游戏辅助工具:5个核心模块深度解析与实战应用指南 【免费下载链接】Akebi-GC (Fork) The great software for some game that exploiting anime girls (and boys). 项目地址: https://gitcode.com/gh_mirrors/ak/Akebi-GC Akebi-GC是一款专为特定游戏…...